





























Apache Spark is an open source powerful distributed distributed data processing engine designed for large-scale data workloads, excelling in parallel computation and in-memory processing. Kubernetes, also open source, is a powerful container orchestration platform. It automates the deployment, scaling, and management of containerized applications, making it easier to manage complex applications. Putting Spark and Kubernetes together means you get the best of both worlds. It helps you use your resources more efficiently, scale more easily, and run things more smoothly.
In this article, we will cover everything you need to know about running Apache Spark on Kubernetes. We will cover the benefits and architecture. Then, we will break down the process into steps. We will cover everything from setting up your Kubernetes cluster to managing Spark jobs.
What Is Apache Spark?
Apache Spark is an open source unified analytics engine designed for large-scale data processing. It is particularly adept at handling both batch and stream processing, providing a robust alternative to earlier big data frameworks, notably Apache Hadoop's MapReduce. One of Spark's key advantages is its speed, achieving performance up to 100x faster in memory and 10 times faster on disk compared to Hadoop. This efficiency is largely due to its in-memory computation capabilities and optimized execution engine. Spark supports high-level APIs in multiple programming languages, including Scala, Python, Java, and R, making it accessible to a wide range of developers.
What Is Apache Spark?
Architecture of Apache Spark
Apache Spark architecture is based on a master-worker model and is structured around several core components and abstractions that facilitate high-speed data processing, fault tolerance, and real-time analytics.
Apache Spark architecture relies on two main abstractions:
- Resilient Distributed Datasets (RDDs): RDDs are the fundamental data structure in Spark. They are immutable collections of objects that can be partitioned across a cluster, enabling parallel processing.
- Directed Acyclic Graphs (DAGs): When a Spark application is submitted, the driver program converts the user code into a DAG of stages and tasks. This DAG represents the sequence of computations and their dependencies, allowing Spark to optimize the execution plan.
Key components of Apache Spark architecture:
Driver is the master node of a Spark application, responsible for orchestrating the execution of the program. It converts user code into a DAG and schedules tasks to be executed on the cluster. The driver negotiates resources with the cluster manager and monitors the execution of tasks.
2) Executors
Executors are distributed agents that run on worker nodes in the cluster. They execute the tasks assigned by the driver and store the computation results in memory or on disk. Executors also handle data processing and interact with underlying storage systems, reporting results back to the driver.
Cluster manager is an external service that manages resources for the Spark cluster. It allocates CPU and memory resources to Spark applications and assigns them to executors. Spark can work with various cluster managers, including:
- Apache Hadoop YARN
- Apache Mesos
- Kubernetes
- Standalone cluster manager
The following diagram illustrates the Apache Spark architecture:
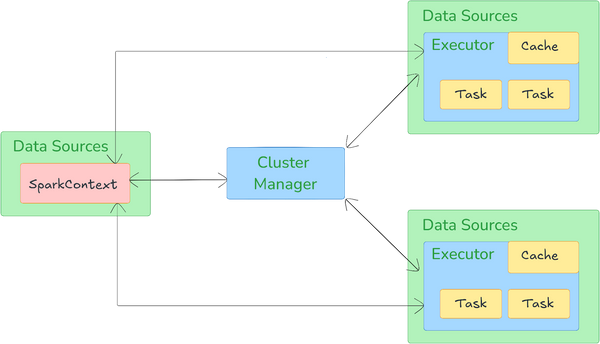
Check out this article on how Apache Spark works to learn more in-depth about Apache Spark architecture.
Save up to 50% on your Databricks spend in a few minutes!


What Is Kubernetes (k8s)?
Kubernetes, often abbreviated as K8s, is also an open source platform designed to automate the deployment, scaling, and management of containerized applications. Initially developed by Google, it has become the industry standard for container orchestration. Kubernetes supports the deployment and management of complex applications in a scalable, fault-tolerant manner.
Architecture of Kubernetes
Kubernetes (k8s) follows a master-worker architecture, consisting of two main types of nodes:
1) Master Node(s): These nodes form the control plane of the Kubernetes cluster and are responsible for maintaining the desired state of the cluster. They manage the scheduling of workloads and the overall health of the cluster.
2) Worker Nodes: These nodes run the actual application workloads. They host the Pods, which are the smallest deployable units in Kubernetes.
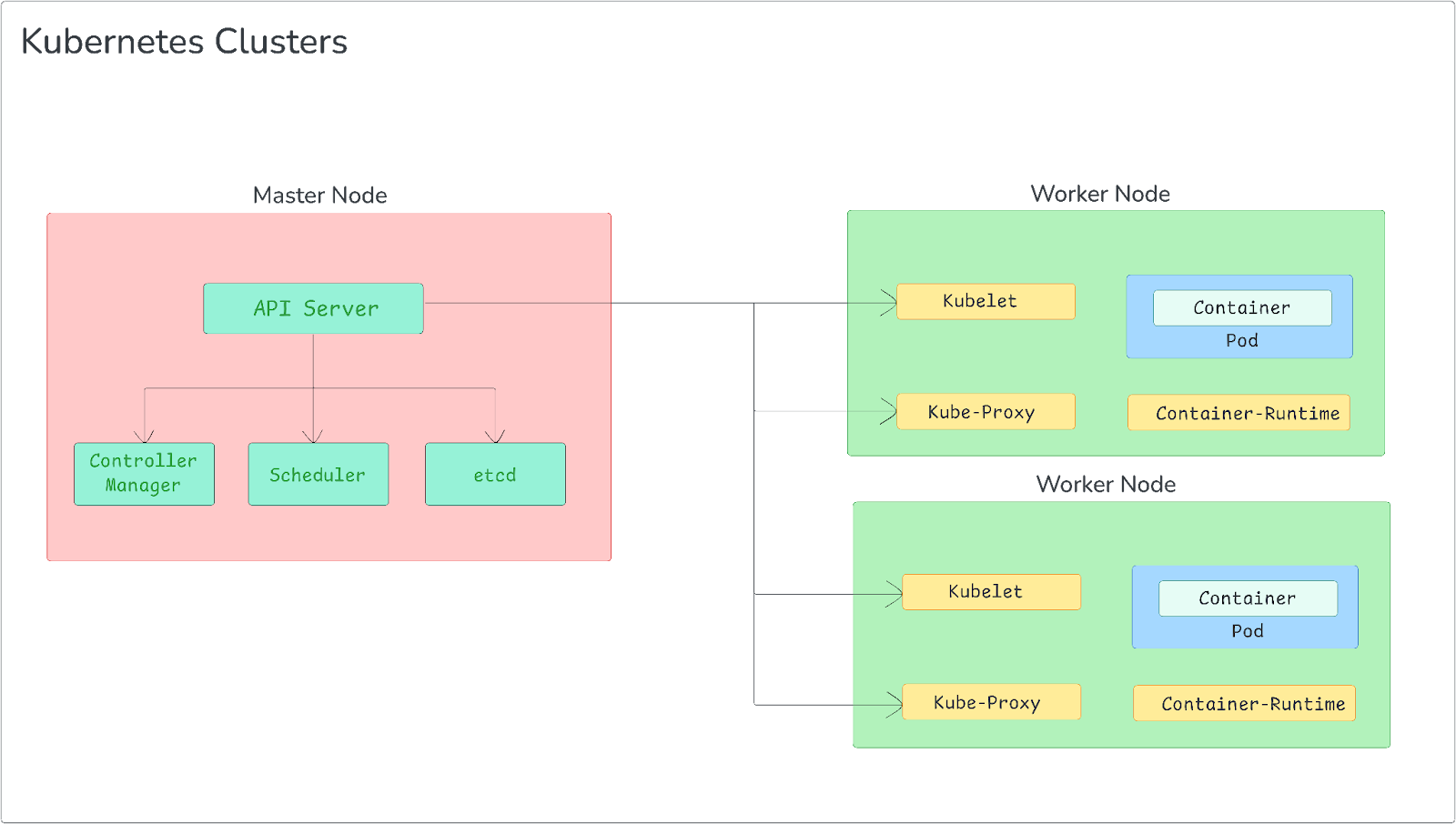
Let's dive deeper into the components of each:
Control Plane Components:
- API Server: API server is the front end for the Kubernetes control plane. All administrative tasks are coordinated through this component. It processes REST operations, validates them, and updates the corresponding objects in etcd.
- etcd: etcd is a distributed key-value store used as Kubernetes' backing store for all cluster data. It provides a reliable way to store configuration data and supports watch operations to notify clients of changes.
- Scheduler: Scheduler watches for newly created Pods that have no assigned node and selects a node for them to run on based on various factors, including resource requirements, hardware/software/policy constraints, and affinity/anti-affinity specifications.
- Controller Manager: Controller manager runs controller processes. Logically, each controller is a separate process, but to reduce complexity, they are all compiled into a single binary and run in a single process. These controllers include:
- Node Controller: Responsible for noticing and responding when nodes go down.
- Replication Controller: Responsible for maintaining the correct number of Pods for every replication controller object in the system. (Note: The Replication Controller has largely been superseded by Deployments, which provide a more robust way to manage Pods).
- Endpoints Controller: Populates the Endpoints object (that is, joins Services and Pods).
- Service Account & Token Controllers: Create default accounts and API access tokens for new namespaces.
Node Components:
- Kubelet: An agent that runs on each node in the cluster. It ensures that containers are running in a Pod and communicates with the API server to report the status of the node and the Pods it manages.
- Kube-proxy: Kube-proxy is a network proxy that runs on each node in your cluster, implementing part of the Kubernetes Service concept. It maintains network rules on nodes, allowing network communication to your Pods from network sessions inside or outside of your cluster.
- Container Runtime: Container runtime is the software responsible for running containers. Kubernetes supports several container runtimes, including Docker, containerd, CRI-O, and any implementation of the Kubernetes CRI (Container Runtime Interface).
Core Concepts to Understand:
- Pods: Pods are the smallest deployable unit in Kubernetes. A Pod encapsulates one or more containers that share network and storage resources, allowing them to communicate easily.
- Services: Services abstract the logic of how to access a group of Pods, enabling communication between different parts of an application. They provide stable endpoints for accessing Pods, which may change over time.
- Deployments: Deployments manage the lifecycle of applications by ensuring the correct number of Pod replicas are running. They provide declarative updates to Pods and ReplicaSets, allowing for easy rollbacks and scaling.
Features of Kubernetes (k8s)
Kubernetes (k8s) offers several key features that make it a powerful tool for managing containerized applications:
1) Container Orchestration: Kubernetes automates the deployment and management of containers across a cluster.
2) Automated Rollouts and Rollbacks: Kubernetes progressively rolls out changes to your application or its configuration while monitoring application health. If something goes wrong, Kubernetes can automatically roll back the change to maintain stability.
3) Self-Healing: Kubernetes automatically restarts failed containers and replaces or reschedules them as needed, ensuring high availability.
4) Load Balancing: Kubernetes can expose a container using a DNS name or its own IP address. If traffic to a container is high, Kubernetes can load balance and distribute the network traffic to stabilize the deployment.
5) Horizontal Scaling: Kubernetes allows you to scale your application up and down easily with a simple command, through a UI, or automatically based on CPU usage or other metrics.
6) Service Discovery: Kubernetes provides mechanisms for containers to discover and communicate with each other, typically through Services that abstract access to a set of Pods.
7) Secret and Configuration Management: Kubernetes allows you to store and manage sensitive information, such as passwords, OAuth tokens, and SSH keys. You can deploy and update secrets and application configurations without rebuilding container images and without exposing secrets in your stack configuration.
8) Storage Orchestration: Kubernetes allows you to automatically mount a storage system of your choice, such as local storage, public cloud providers, and more, facilitating data persistence.
9) Batch Execution: In addition to services, Kubernetes can manage your batch and CI workloads, replacing containers that fail, if desired.
What Are the Benefits of Spark on Kubernetes?
Running Spark on Kubernetes provides a lot of advantages, especially if you're already using containers and orchestration. Here are some key benefits:
1) Native Containerization and Docker Support
Kubernetes is designed to work with containers, typically Docker containers. This allows Spark applications to be packaged as container images, including all necessary dependencies.
Here are some few key benefits:
- Consistency: The same container image can be used across development, testing, and production environments, which guarantees consistency and reducing "it works on my machine" issues.
- Isolation: Each Spark application runs in its own container, providing better isolation from other applications and the underlying system.
- Versioning: Container images can be versioned, making it easy to roll back to previous versions of a Spark application if needed.
2) Dynamic Resource Allocation and Efficient Utilization
Kubernetes excels at managing cluster resources efficiently. When running Spark on Kubernetes:
- Apache Spark can request resources (CPU, memory) dynamically as needed, and Kubernetes can allocate these resources from the cluster.
- When a Spark job completes, Kubernetes can quickly reclaim these resources and make them available for other applications.
- Kubernetes can bin-pack applications onto nodes efficiently, improving overall cluster utilization.
3) Improved Isolation of Spark Applications
Each Spark application runs in its own set of containers, providing better isolation between different Spark applications running on the same cluster, which allows for application-specific configurations without affecting other applications.
4) Enhanced Portability Across Environments
Kubernetes provides a consistent platform across different environments. Spark applications packaged as containers can run on any Kubernetes cluster, whether on-premises, in the cloud, or in hybrid environments. This portability makes it easier to move Spark workloads between development, testing, and production environments or even between different cloud providers.
5) Simplified Resource Sharing with Other Applications
In a Kubernetes cluster, Spark applications can coexist with other types of applications, all managed by the same orchestration system. This allows for more efficient use of cluster resources, as the same infrastructure can be used for both batch Spark jobs and other services.
6) Seamless Integration with Kubernetes Ecosystem
Running Spark on Kubernetes allows you to leverage the rich ecosystem of Kubernetes tools and services:
- Monitoring: Use tools like Prometheus and Grafana for monitoring Spark applications alongside other Kubernetes workloads.
- Logging: Integrate with logging solutions like Fluentd or the ELK (Elasticsearch, Logstash, Kibana) stack.
- Service Mesh: Leverage service mesh solutions like Istio for advanced networking features and observability.
- CI/CD: Integrate Spark applications into Kubernetes-native CI/CD pipelines using tools like Jenkins X or GitLab CI.
7) Enhanced Security Features
Kubernetes provides several security features that benefit Spark applications:
- RBAC (Role-Based Access Control): Fine-grained control over which users or services can perform specific actions on Kubernetes resources.
- Network Policies: Control traffic flow between Pods, improving the security posture of Spark applications.
- Secrets Management: Securely manage sensitive information like database credentials or API keys.
8) Cost-effectiveness through Better Resource Management
The combination of Spark and Kubernetes can lead to cost savings. One way this happens is by using resources more efficiently, which means you can run more workloads on the same hardware. The ability to easily scale up or down as needed also helps you make the most of your resources and keep costs in check, especially when you're running things in the cloud.
If you tap into these benefits, you can easily set up more flexible, streamlined data pipelines using Spark on Kubernetes.
Apache Spark Architecture on Kubernetes: An Overview
When deploying Apache Spark on Kubernetes, the architecture adapts to leverage Kubernetes' container orchestration capabilities. The Spark driver and executors are encapsulated as Kubernetes pods, with Kubernetes assuming the role of the cluster manager instead of traditional options like YARN or Spark's standalone cluster manager.
Here’s a breakdown of how the execution model works:
1) Spark Driver: Spark driver runs inside a Kubernetes pod and is responsible for the overall management of the Spark application. It communicates directly with the Kubernetes API to request resources for executors and manage their lifecycle. The driver orchestrates task execution, monitors progress, and handles failure recovery.
2) Executor Pods: Executors are deployed as individual Kubernetes pods. Each executor pod runs tasks and processes data in parallel, as part of a distributed computation framework. These pods are dynamically provisioned based on the resource requirements specified by the application, allowing for efficient scaling.
3) Kubernetes as Cluster Manager: Kubernetes replaces YARN or Spark's standalone cluster manager, taking on the responsibility of resource scheduling and management. It handles pod allocation for both the driver and executor, offering advantages like improved isolation, horizontal scaling, and integration with Kubernetes-native features like service discovery, networking, and storage.
The basic flow of a Spark application on Kubernetes is as follows:
➥ A user/client submits a Spark application to Kubernetes using spark-submit or a similar client with the Kubernetes master set as the cluster manager.
➥ Kubernetes provisions a pod for the Spark driver, which acts as the central coordinator of the Spark application.
➥ The Spark driver communicates with the Kubernetes API to request resources for executor pods.
➥ Kubernetes schedules and creates the executor pods based on the resource requests (e.g., CPU, memory, or node affinity) made by the driver.
➥ The driver and executors communicate over the Kubernetes network (typically using service discovery) to coordinate task execution and data shuffling.
➥ After the Spark application completes, both the driver and executor pods are terminated, and the associated resources are freed back to the Kubernetes cluster.
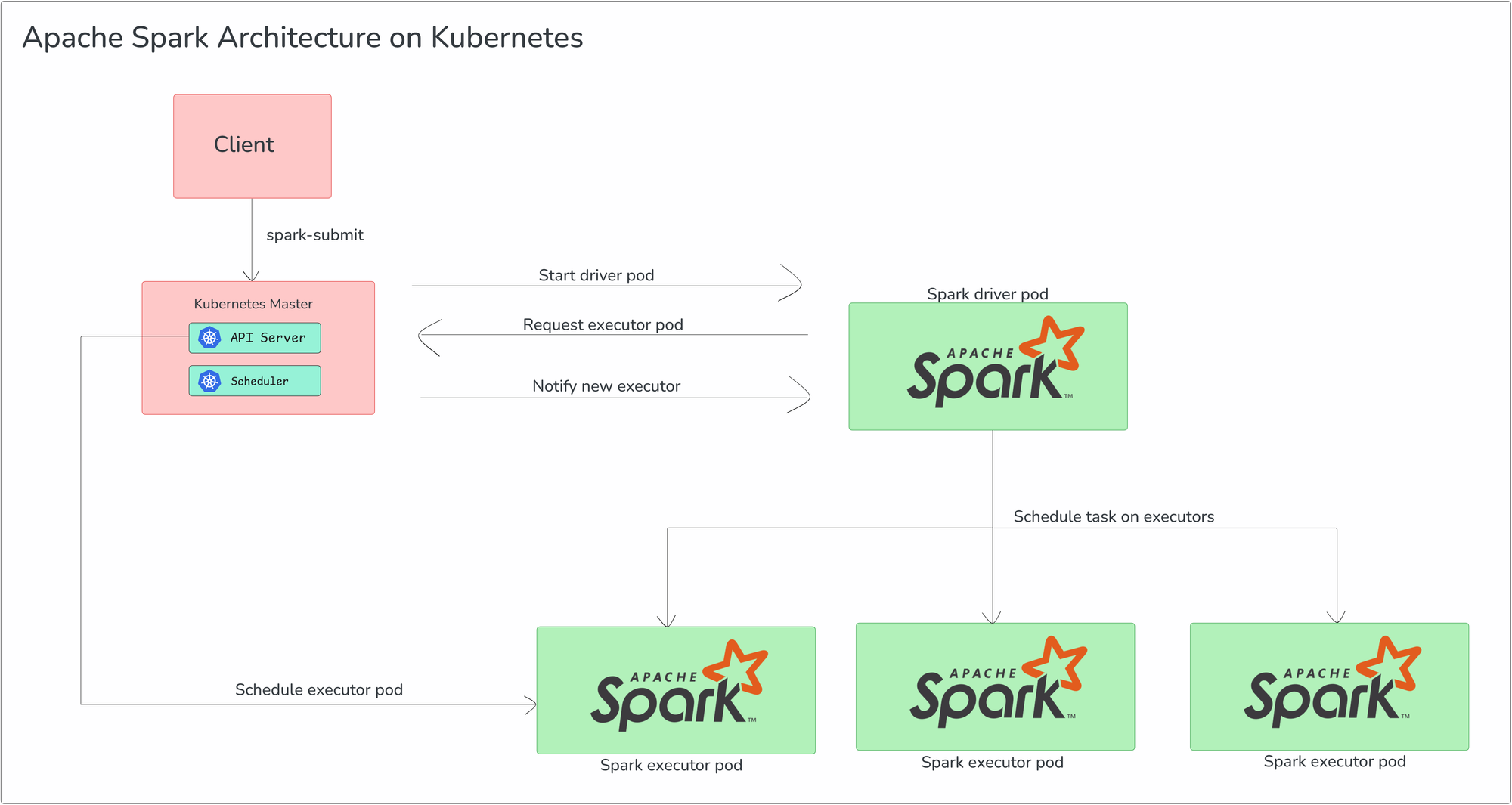
Step-By-Step Guide to Run and Deploy Apache Spark on Kubernetes (k8s)
Here's a detailed step-by-step guide to deploying Apache Spark on Kubernetes. We'll walk you through setting up your environment and show you how to submit and manage Spark applications.
Prerequisites:
Before deploying Spark on Kubernetes, ensure you have the following prerequisites:
- A Kubernetes cluster (version 1.24 or later)
- kubectl CLI tool installed and configured to communicate with your cluster
- Appropriate permissions to create and manage Pods, Services, and other Kubernetes resources
- Docker installed (for building custom Spark images)
- Apache Spark 3.0 or later installed on your local machine. Download it from Apache Spark’s official page.
Step 1—Set Up Your Kubernetes Cluster
Before running Spark on Kubernetes, you must first have a Kubernetes cluster up and running. This step assumes you have basic Kubernetes knowledge.
Start by choosing a Kubernetes distribution—Minikube for local development, or a cloud provider's managed Kubernetes service, such as Google Kubernetes Engine or Amazon EKS, for production environments.
Next, install kubectl, the Kubernetes command-line tool.
For this example, we'll use Minikube for local development. Here’s how to install Minikube on macOS (with ARM architecture). First, download the latest stable binary:
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-darwin-arm64Apache Spark on Kubernetes - Spark on k8s

Once downloaded, move the binary to a directory in your system's PATH:
sudo install minikube-darwin-arm64 /usr/local/bin/minikubeApache Spark on Kubernetes - Spark on k8s
Please note that these instructions apply to macOS with an ARM architecture. For installation steps on other platforms, refer to the official Minikube documentation.
Step 2—Starting Kubernetes Cluster
Launch Minikube, allocating resources for Spark workloads:
minikube start --memory 3100 --cpus 4Apache Spark on Kubernetes - Spark on k8s
To verify the cluster is up and running, use:
kubectl cluster-infoApache Spark on Kubernetes - Spark on k8s

Also, make sure kubectl is configured to communicate with your cluster:
kubectl get nodesApache Spark on Kubernetes - Spark on k8s

This should return details about the nodes in your cluster.
Step 3—Prepare Apache Spark for Kubernetes
With your Kubernetes cluster ready, let's download, install and configure Apache Spark. Start by downloading the Spark distribution and then run the following command to unzip it and move the unzipped folder to <your-directory> directory.
tar -xzvf spark-3.5.2-bin-hadoop3.tgz
mv spark-3.5.2-bin-hadoop3.tgz <your-directory>Apache Spark on Kubernetes - Spark on k8s
Set up environment variables (optional):
export SPARK_HOME=<your-directory>
export PATH=$PATH:$SPARK_HOME/binApache Spark on Kubernetes - Spark on k8s
Add these lines to your ~/.bashrc or ~/.zshrc file for permanent configuration. Finally, verify the Spark installation:
spark-submit --versionApache Spark on Kubernetes - Spark on k8s
You should see the Spark version details displayed.
Step 4—Set up Kubernetes for Spark
To run Spark on Kubernetes, you'll need to build Docker images that include Spark and its dependencies. Here's a basic Dockerfile Example:
FROM openjdk:11-jre-slim
ENV SPARK_VERSION=3.5.2
ENV HADOOP_VERSION=3
RUN apt-get update && apt-get install -y curl
RUN curl -O https://downloads.apache.org/spark/spark-${SPARK_VERSION}/spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz && \
tar -xzf spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz && \
mv spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION} /spark && \
rm spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz
ENV SPARK_HOME /spark
ENV PATH $PATH:$SPARK_HOME/bin
WORKDIR /spark/work-dir
ENTRYPOINT ["/spark/bin/spark-submit"]
Apache Spark on Kubernetes - Spark on k8s
Build and tag the Docker image:
docker build -t spark:v3.5.2 .Apache Spark on Kubernetes - Spark on k8s

If you're using a remote Kubernetes cluster, push the image to a container registry:
docker tag spark:v3.5.2 yourusername/spark:v3.5.2
docker push <yourusername>/spark:v3.5.2Apache Spark on Kubernetes - Spark on k8s
Step 5—Configure Spark Applications for Kubernetes
Now we need to configure Spark to use Kubernetes as its cluster manager.
Create a spark-defaults.conf file in your Spark configuration directory:
touch $SPARK_HOME/conf/spark-defaults.confApache Spark on Kubernetes - Spark on k8s
Add the following configurations to this file:
spark.master k8s://https://<kubernetes-api-server-url>
spark.kubernetes.container.image <your-spark-image>
spark.kubernetes.namespace spark
spark.kubernetes.authenticate.driver.serviceAccountName spark
spark.kubernetes.authenticate.executor.serviceAccountName sparkApache Spark on Kubernetes - Spark on k8s
Replace <kubernetes-api-server-url> with your Kubernetes API server URL (you can get this from ‘kubectl cluster-info’) and <your-spark-image> with the name of the Docker image you created in Step 3.
Step 6—Preparing Kubernetes Resources for Spark
Before running Spark applications, set up the necessary resources. First, create a namespace:
kubectl create namespace sparkApache Spark on Kubernetes - Spark on k8s
Namespaces are ways to divide cluster resources between multiple users (via resource quota).
Next, define a service account and role binding for Spark. Save this configuration as spark-rbac.yaml:
apiVersion: v1
kind: ServiceAccount
metadata:
name: spark
namespace: spark
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: spark-role
subjects:
- kind: ServiceAccount
name: spark
namespace: spark
roleRef:
kind: ClusterRole
name: edit
apiGroup: rbac.authorization.k8s.ioSave this as spark-rbac.yaml and apply it:
kubectl apply -f spark-rbac.yamlApache Spark on Kubernetes - Spark on k8s

Step 7—Submitting Spark Applications to Kubernetes
Now we're ready to submit Spark applications to our Kubernetes cluster.
Prepare a simple Spark application.
$ ./bin/spark-submit \
--master k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port> \
--deploy-mode cluster \
--name <spark-app-name> \
--class org.apache.spark.examples.<...> \
--conf spark.executor.instances=5 \
--conf spark.kubernetes.container.image=<spark-image> \
local:///path/to/examples.jarLet's use the built-in SparkPi example:
$SPARK_HOME/bin/spark-submit \
--master k8s://https://<kubernetes-api-server-url> \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=3 \
--conf spark.kubernetes.container.image=<your-spark-image> \
--conf spark.kubernetes.namespace=spark \
local:///spark/examples/jars/spark-examples_2.12-3.5.2.jarApache Spark on Kubernetes - Spark on k8s
Replace <kubernetes-api-server-url> and <your-spark-image> as before and run the application.
Run the command below to get the details about your pods:
kubectl get pods -n sparkApache Spark on Kubernetes - Spark on k8s
You should see driver and executor pods being created and running. To see the application output, find the driver pod name and use:
kubectl logs <driver-pod-name> -n sparkApache Spark on Kubernetes - Spark on k8s
Step 8—Monitor and Debug Your Apache Spark Application
Monitoring and managing your Spark applications on Kubernetes is crucial for maintaining a healthy and efficient data processing environment.
To monitor your Spark applications, you can use kubectl:
- List all pods in the Spark namespace:
kubectl get pods -n sparkApache Spark on Kubernetes - Spark on k8s
- Get detailed information about a specific pod
kubectl describe pod <pod-name> -n sparkApache Spark on Kubernetes - Spark on k8s
- Stream logs from a pod
kubectl logs -f <pod-name> -n sparkApache Spark on Kubernetes - Spark on k8s
You can also enable the Minikube dashboard for a graphical interface:
minikube addons enable dashboardApache Spark on Kubernetes - Spark on k8s
Now that you have enabled dashboard addons you can easily access it via following command.
minikube dashboardApache Spark on Kubernetes - Spark on k8s

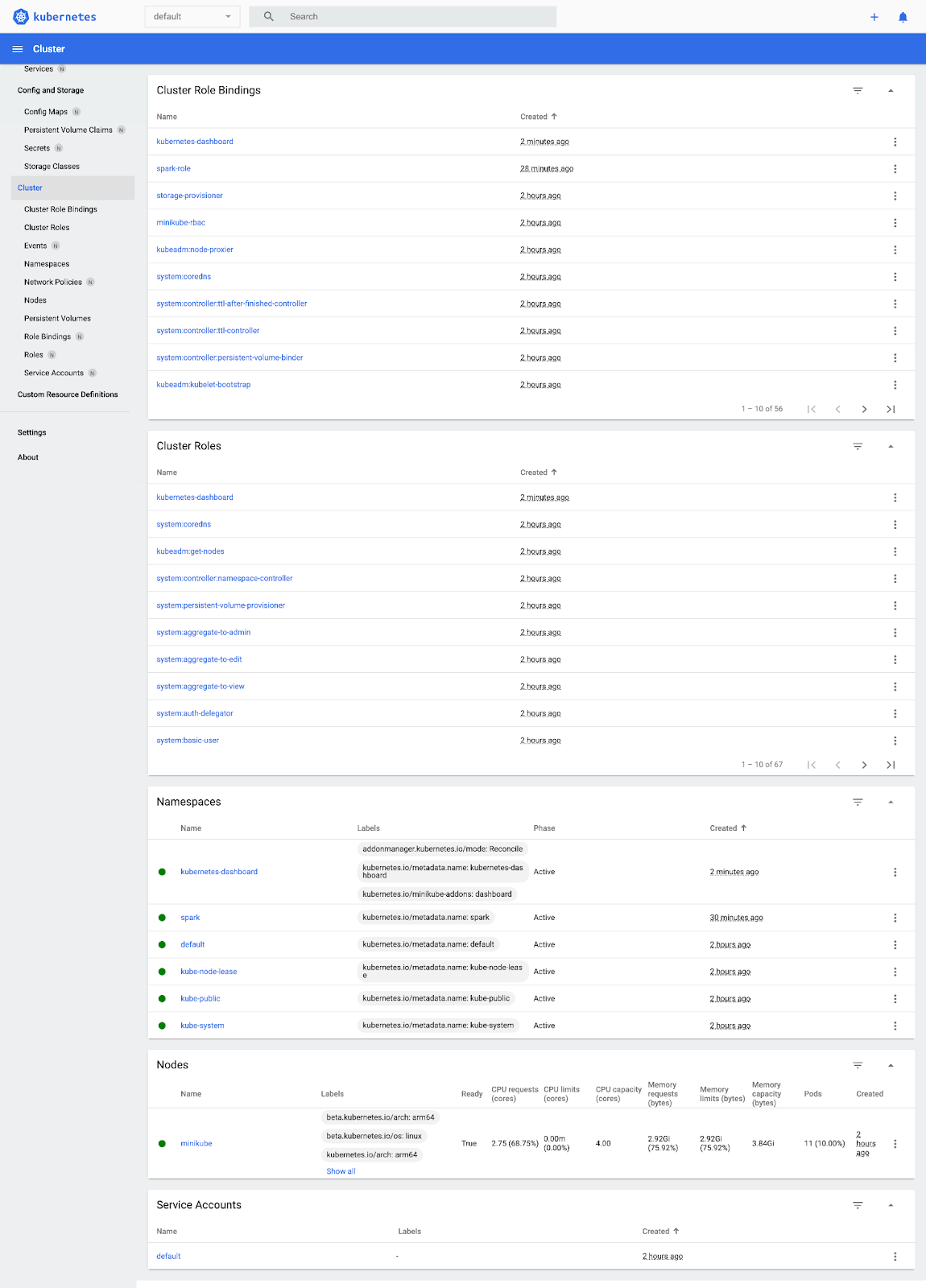
For more advanced monitoring, consider setting up Prometheus and Grafana.
Step 9—Using Kubernetes Volumes with Spark
You can mount various types of Kubernetes volumes into your driver and executor pods. To mount a volume of any of the types above into the driver pod, use the following configuration property:
--conf spark.kubernetes.driver.volumes.[VolumeType].[VolumeName].mount.path=<mount path>
--conf spark.kubernetes.driver.volumes.[VolumeType].[VolumeName].mount.readOnly=<true|false>
--conf spark.kubernetes.driver.volumes.[VolumeType].[VolumeName].mount.subPath=<mount subPath>
Apache Spark on Kubernetes - Spark on k8s
Replace [VolumeType] with hostPath, emptyDir, nfs, or persistentVolumeClaim, depending on the type of volume you're using.
VolumeName is the name you want to use for the volume under the volumes field in the pod specification.
Each supported type of volume may have some specific configuration options, which can be specified using configuration properties of the following form:
spark.kubernetes.driver.volumes.[VolumeType].[VolumeName].options.[OptionName]=<value>Apache Spark on Kubernetes - Spark on k8s
Supported Volume Types:
- hostPath: Mounts a file or directory from the host node’s filesystem.
- emptyDir: An initially empty volume created when a pod is assigned.
- nfs: Mounts an existing NFS into a pod.
- persistentVolumeClaim: Mounts a PersistentVolume into a pod.
Step 10—Optimizing Spark on Kubernetes
Optimizing Spark on Kubernetes requires tuning both Spark and Kubernetes configurations for enhanced performance and resource efficiency.
1) Spark Configuration Optimization:
- Adjust executor resources:
spark.executor.cores=5
spark.executor.memory=4gApache Spark on Kubernetes - Spark on k8s
- Configure dynamic allocation:
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.shuffleTracking.enabled=true
spark.dynamicAllocation.minExecutors=2
spark.dynamicAllocation.maxExecutors=10Apache Spark on Kubernetes - Spark on k8s
- Optimize shuffle service:
spark.shuffle.service.enabled=true
spark.kubernetes.shuffle.namespace=spark
spark.kubernetes.shuffle.labels="app=spark-shuffle-service"Apache Spark on Kubernetes - Spark on k8s
2) Kubernetes Configuration Optimization:
- Use node selectors to schedule Spark pods on appropriate nodes:
spark.kubernetes.node.selector.spark=enabledApache Spark on Kubernetes - Spark on k8s
- Implement pod affinity/anti-affinity rules:
spark.kubernetes.executor.podTemplateFile=/path/to/executor-template.yamlApache Spark on Kubernetes - Spark on k8s
First, create a executor-template file in your Spark configuration directory:
touch executor-template.yamlApache Spark on Kubernetes - Spark on k8s
Add the following configurations to this file:
apiVersion: v1
kind: Pod
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: spark-app-selector
operator: In
values:
- spark-app-1
topologyKey: kubernetes.io/hostname- Use Kubernetes Vertical Pod Autoscaler (VPA) to Right-Size Pods:
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: spark-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: spark-worker
updatePolicy:
updateMode: "Auto"Step 11—Cleaning Up Resources
After your Spark application finishes, it's essential to clean up any resources:
- Delete the driver Pod (if it's still running):
kubectl delete pod <driver-pod-name>Apache Spark on Kubernetes - Spark on k8s
- Delete the Namespace (when all applications are completed):
kubectl delete namespace <spark-apps>Apache Spark on Kubernetes - Spark on k8s
Step 12—Troubleshooting Common Issues
When running Spark on Kubernetes, you might encounter various issues. Here are some common issues when running Spark on Kubernetes and how to resolve them:
1) Pod creation failures
- Check pod events:
kubectl describe pod <pod-name> -n spark- Make sure you have sufficient cluster resources
- Verify correct image names and tags
2) Application failures
- Check driver logs:
kubectl logs <driver-pod-name> -n spark- Ensure Spark configurations are correct.
- Verify that all dependencies are included in the Spark image.
3) Performance issues
- Monitor resource usage:
kubectl top pods -n spark- Adjust executor resources and counts.
- Optimize data partitioning and caching strategies.
4) Networking issues
- Verify proper network policies and DNS configurations.
- Ensure service account permissions are set correctly.
5) Image pull errors
- Make sure the image exists in the specified repository.
- Check image pull secrets if using a private repository.
- Verify network connectivity to the repository.
Remember to always check the Kubernetes events for the namespace:
kubectl get events -n sparkApache Spark on Kubernetes - Spark on k8s
This can provide valuable information about what's happening in your cluster.
Step 13—Best Practices and Advanced Configurations
To maximize Spark’s performance on Kubernetes, consider these best practices:
1) Use Kubernetes Secrets for sensitive information:
kubectl create secret generic spark-secret --from-literal=key=valueApache Spark on Kubernetes - Spark on k8s

Mount the secret in Spark by adding the following options to your spark-submit command:
--conf spark.kubernetes.driver.secrets.spark-secret=/etc/secrets \
--conf spark.kubernetes.executor.secrets.spark-secret=/etc/secretsApache Spark on Kubernetes - Spark on k8s
2) Implement proper logging:
Use pod templates for logging:
--conf spark.kubernetes.driver.podTemplateFile=driver-template.yaml \
--conf spark.kubernetes.executor.podTemplateFile=executor-template.yamlApache Spark on Kubernetes - Spark on k8s
In your template files, configure volume mounts for logs:
apiVersion: v1
kind: Pod
spec:
containers:
- name: spark
volumeMounts:
- name: spark-logs
mountPath: /opt/spark/logs
volumes:
- name: spark-logs
emptyDir: {}3) Leverage Kubernetes Namespaces for Multi-Tenancy:
Create separate namespaces for different teams or applications:
kubectl create namespace team-a-spark
kubectl create namespace team-b-sparkApache Spark on Kubernetes - Spark on k8s
Specify the appropriate namespace when submitting Spark jobs:
--conf spark.kubernetes.namespace=team-a-sparkApache Spark on Kubernetes - Spark on k8s
4) Implement resource quotas to prevent resource hogging:
apiVersion: v1
kind: ResourceQuota
metadata:
name: spark-quota
namespace: spark
spec:
hard:
requests.cpu: "20"
requests.memory: 100Gi
limits.cpu: "40"
limits.memory: 200Gi5) Use Persistent Volumes for data that needs to persist between job runs:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: spark-data
namespace: spark
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10GiThen in your Spark submit command:
--conf spark.kubernetes.driver.volumes.persistentVolumeClaim.data.options.claimName=spark-data \
--conf spark.kubernetes.driver.volumes.persistentVolumeClaim.data.mount.path=/data \
--conf spark.kubernetes.executor.volumes.persistentVolumeClaim.data.options.claimName=spark-data \
--conf spark.kubernetes.executor.volumes.persistentVolumeClaim.data.mount.path=/dataApache Spark on Kubernetes - Spark on k8s
6) Implement proper RBAC (Role-Based Access Control):
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: spark
name: spark-role
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["create", "get", "list", "watch", "delete"]
- apiGroups: [""]
resources: ["services"]
verbs: ["create", "get", "list", "watch", "delete"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: spark-role-binding
namespace: spark
subjects:
- kind: ServiceAccount
name: spark
namespace: spark
roleRef:
kind: Role
name: spark-role
apiGroup: rbac.authorization.k8s.io
7) Use Kubernetes NetworkPolicies to control traffic flow:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: spark-network-policy
namespace: spark
spec:
podSelector:
matchLabels:
app: spark
policyTypes:
- Ingress
- Egress
ingress:
- from:
- podSelector:
matchLabels:
app: spark
egress:
- to:
- podSelector:
matchLabels:
app: spark
8) Implement proper security measures:
Use Pod Security Policies:
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: spark-psp
spec:
privileged: false
seLinux:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
runAsUser:
rule: RunAsAny
fsGroup:
rule: RunAsAny
volumes:
- 'emptyDir'
- 'configMap'
- 'secret'
- Enable Kubernetes API server authentication and authorization
- Use TLS for all communications
- Regularly update and patch all components
If you follow these best practices and implement these advanced configurations, you can create a robust, secure, and efficient Spark on Kubernetes environment.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

References and Further Reading
- Apache Spark Documentation
- Kubernetes Documentation
- "Running Spark on Kubernetes" - Spark Official Documentation
- "Kubernetes Patterns" by Bilgin Ibryam and Roland Huß
- "Learning Spark" by Jules S. Damji, Brooke Wenig, Tathagata Das, and Denny Lee
- CNCF (Cloud Native Computing Foundation) Blog
- Run a Spark job on Dataproc on Google Kubernetes Engine
- "Kubernetes in Action" by Marko Lukša
Conclusion
Apache Spark on Kubernetes is a powerful and top-notch combo for big data processing. This guide has walked you through the process of setting up, configuring, and optimizing Spark on Kubernetes, from basic setup to advanced configurations and best practices.
In this article, we have covered:
- What Is Apache Spark?
- What Is Kubernetes (k8s)?
- What Are the Benefits of Spark on Kubernetes?
- Apache Spark Architecture on Kubernetes: An Overview
- Step-By-Step Guide to Run and Deploy Apache Spark on Kubernetes (k8s)
… and so much more!
FAQs
Can you run Spark on Kubernetes?
Yes, Apache Spark has native support for running on Kubernetes since version 2.3, with significant improvements in subsequent versions.
What are the benefits of Spark on Kubernetes?
Benefits include improved resource utilization, easier management of dependencies through containers, better isolation between applications, and seamless integration with cloud-native technologies.
Is Spark on Kubernetes production-ready?
Yes, many organizations are successfully running Spark on Kubernetes in production. However, it requires careful configuration and management.
Can Spark be containerized?
Yes, Spark can be containerized. In fact, when running on Kubernetes, Spark applications run in containers.
How does Spark on Kubernetes compare with traditional cluster managers like YARN?
Spark on Kubernetes offers more flexibility, better resource isolation, and easier integration with cloud-native tools compared to YARN. However, YARN may still be preferred in some Hadoop-centric environments.
What are the challenges of running Spark on Kubernetes?
Challenges include increased configuration complexity, potential for resource over-provisioning, and the need for expertise in both Spark and Kubernetes.
How do you handle data locality in Spark on Kubernetes?
Data locality can be handled through careful pod scheduling using node selectors, pod affinity rules, and by using appropriate storage solutions.
Can you use GPUs with Spark on Kubernetes?
Yes, Kubernetes supports GPU resources, and Spark can be configured to use GPUs when running on Kubernetes.
How do you scale Spark applications on Kubernetes?
Spark applications can be scaled by adjusting the number of executor pods. This can be done manually or automatically using Kubernetes Horizontal Pod Autoscaler.
What monitoring tools can be used for Spark on Kubernetes?
Popular choices include Prometheus and Grafana for metrics, and tools like Kibana for log analysis. The Kubernetes dashboard and Spark UI are also useful for monitoring.















