





























Capturing changes within tables efficiently remains a critical challenge for data engineers. Traditional approaches to change data capture (CDC) can be critical, often relying on methods like updated timestamps, row versioning, or complex log scanning. These approaches can become difficult to manage and scale, especially for large datasets and real-time applications. Fortunately, Snowflake offers a simple and elegant solution: Snowflake Stream Objects, which take a fundamentally different approach to CDC by introducing three dedicated meta-columns to your existing tables. These columns seamlessly track all data modifications.
In this article, we will provide an in-depth overview of Snowflake streams. We will dive into key concepts, syntax, a step-by-step process for creating a Snowflake Stream, types of Snowflake streams, real-world examples, best practices, limitations, disadvantages of Snowflake Streams, distinction between stream vs task—and so much more!!
What Are Snowflake Streams and How They Work?
Snowflake streams are objects that track all DML operations against the source table. Under the hood, Snowflake streams add three metadata columns—METADATA$ACTION, METADATA$ISUPDATE and METADATA$ROW_ID—to the source table when created. These additional columns allow the stream to capture information about inserts, updates, and deletes without having to store all the table data. In essence, a stream sets an offset, which acts as a bookmark on the source table's version timeline. When the stream is queried, it accesses the native versioning history of the source table and returns only the minimal set of row changes that occurred after the stream's offset pointer, joining this data with the current table contents to reconstruct the changes.
The syntax for creating a Snowflake stream on a table is straightforward:
CREATE OR REPLACE STREAM my_stream ON TABLE my_table;Snowflake streams can be created on the following objects:
- Standard tables
- Directory tables
- External tables
- Views
Snowflake streams cannot be created on the following objects:
- Materialized views
- Secure objects (like Secure views, or Secure UDFs)
Some key things to know about Snowflake streams:
- There is no hard limit on the number of Snowflake streams you can create
- Standard tables, views, directory tables, and external tables are supported source objects
- The overhead for streams is minimal—they reference source table data
As previously mentioned, in addition to the data columns from the source table, Snowflake streams also add additional metadata. Let's delve into these extra columns in brief:
- METADATA$ACTION: Indicates the DML operation recorded (INSERT, DELETE, UPDATE)
- METADATA$ISUPDATE: Tracks UPDATEs as DELETE + INSERT pairs
- METADATA$ROW_ID: Unique row identifier
Save up to 30% on your Snowflake spend in a few minutes!


How Many Streams Can Be Created in Snowflakes?
Snowflake does not impose any kind of hard limit on the number of streams that can be created. BUT, there are some factors that may affect the performance and scalability of Snowflake streams, like:
- Size + frequency of the data changes in the source objects. If the source objects have a high volume or velocity of data changes, Snowflake streams may grow rapidly and consume more resources.
- Consumption rate and pattern of the streams. Streams are designed to be consumed in a transactional fashion, meaning that the stream advances to the next offset after each query or load operation. If the streams are not consumed regularly or completely, the change records may accumulate and cause the streams to lag behind the source objects, which may result in staleness.
- Number + complexity of the queries or tasks that use streams. Snowflake streams support querying and time travel modes, which allow you to access historical data and changes at any point in time. But remember that these modes may incur additional processing overhead and latency, especially if the streams have a large number of change records or a long retention period.
What is Offset in Snowflake Stream and how does it work?
An offset is a point in time that marks the starting point for a stream. When you create a stream, Snowflake takes a logical snapshot of every row in the source object and assigns a transactional version to it. This version is the offset for the stream. The stream then records information about the DML changes that occur after this offset. For example, if you insert, update, or delete rows in the source object, Snowflake stream will store the state of the rows before and after the change, as well as some metadata columns that describe the change event.
A stream does not store any actual data from the source object. It only stores the offset and returns the change records by using the versioning history of the source object. The versioning history is maintained by Snowflake using some hidden columns that are added to the source object when the first stream is created. These columns store the change tracking metadata. The change records returned by the stream depend on the combination of the offset and the change tracking metadata.
An offset is like a bookmark that indicates where you are in a book (i.e. the source object). You can move the bookmark to different places in the book by creating new streams or using Time Travel. This way, you can access the change records for the source object at different points in time. For example, you can create a stream with an offset of one hour ago, and see the changes that happened in the last hour. Or, you can use Time Travel to query a stream with an offset of yesterday, and see the changes that happened yesterday.
An offset is useful for consuming the change records in a consistent and accurate way. It ensures that the stream returns the same set of records until you consume or advance the stream. It also supports repeatable read isolation, which means that Snowflake stream does not reflect any concurrent changes that happen in the source object while you are querying the stream.
What Are the 3 Types of Streams in Snowflake?
Snowflake offers three flavors of streams to match different needs for capturing data changes:
- Standard streams
- Append-only streams
- Insert-only streams
Let's quickly cover what each one does.
1) Standard Snowflake Streams
First up is the Standard Snowflake stream. As its name suggests, this type tracks all modifications made to the source table including inserts, updates, and deletes. If you need full change data capture capability, standard Snowflake streams are a way to go.
To create a standard stream, you can use the following syntax:
CREATE OR REPLACE STREAM my_stream ON TABLE my_table; 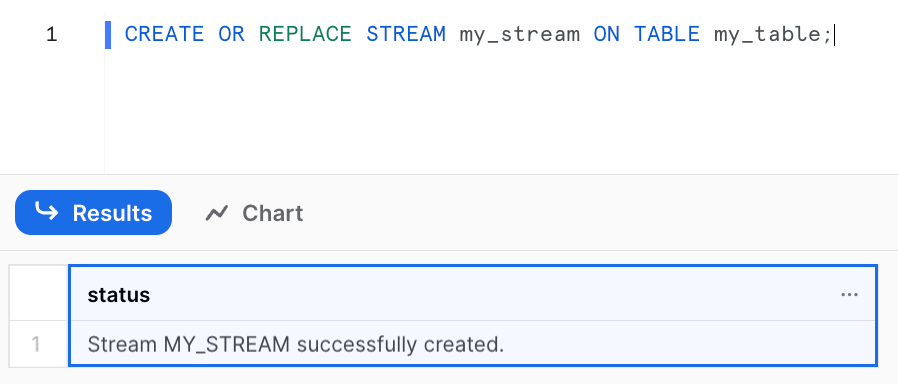
TLDR; Track inserts, updates, deletes (full CDC) for tables and views
2) Append-Only Streams
Next is append-only Snowflake streams. These types of Snowflake streams strictly record new rows added to the table—so just INSERTS. Update and delete operations (including table truncates) are not recorded. Append-only streams are great when you just need to see new data as it arrives.
To create an append-only stream, you can use the following syntax:
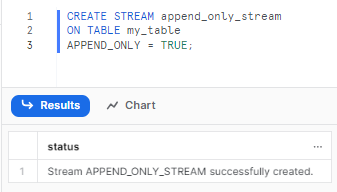
CREATE STREAM append_only_stream
ON TABLE my_table
APPEND_ONLY = TRUE;Snowflake Stream Example
TLDR; Only track INSERT events on standard tables, directory tables, or views.
3) Insert-Only Snowflake Streams
Last but not least is insert-only Snowflake streams which are supported on external tables only. As the name hints, these only track row inserts only; they do not record delete operations that remove rows from an inserted set.
To create an insert-only stream on an external table, you can use the following syntax:
CREATE STREAM insert_only_stream
ON EXTERNAL TABLE external_table
INSERT_ONLY = TRUE;Snowflake Stream Example
TLDR; Only track INSERT events for external tables.
How to Clone a Snowflake Stream?
Cloning Snowflake streams is a piece of cake! You can clone a stream to create a copy of an existing stream with the same definition and offset. A clone inherits the current transactional table version from the source stream, which means it returns the same set of records as the source stream until the clone is consumed or advanced.
Here's how you can clone Snowflake streams:
Step 1—Create your first stream on a table like usual
CREATE STREAM first_stream ON TABLE my_table;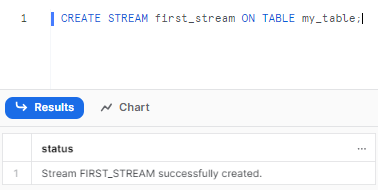
Step 2—Use the CLONE syntax to make your clone!
CREATE STREAM clone_stream CLONE first_stream;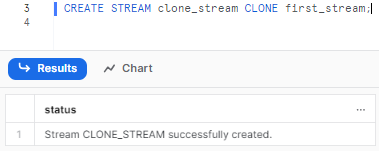
Bam—clone created! As you can see, we provide the clone keyword and then reference the existing stream by name.
Step 3—Check if it worked
SHOW STREAMS;Snowflake Stream Example

You should see the number of created Snowflake streams now.
Step 4—Use and query the streams separately
SELECT * FROM first_stream;
SELECT * FROM clone_stream;Snowflake Stream Example
And there you have it—a carbon copy of Snowflake stream tracking the same data changes in just a few lines of SQL.
Check out this comprehensive video to learn more in-depth about Snowflake Streams.
Step-By-Step Process of Creating a Snowflake Stream
Working with Snowflake streams is super easy once you get familiar with it. Let’s walk you through different examples to showcase how to create and use Snowflake streams on tables. We'll start from the absolute basics.
Pre-step—First let’s make a simple table and add some initial data:
CREATE TABLE my_table (
id INT,
name VARCHAR,
created_date DATE
);
INSERT INTO my_table VALUES
(1, 'Chaos', '2023-12-11'),
(2, 'Genius', '2023-12-11');Snowflake Stream Example
There's our starter data set with unique IDs, names, and created dates for each user.
Example 1—Snowflake Stream on Standard Table
Let's start easy by streaming a normal standard table:
CREATE OR REPLACE STREAM my_standard_stream ON TABLE my_table;Snowflake Stream Example
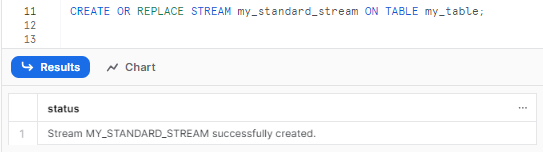
Boom! This stream will now track inserts, updates, deletes on my_table. We can easily query it to see changes:
INSERT INTO my_table VALUES (3, 'Johnny', '2023-12-11');
SELECT * FROM my_standard_stream;Snowflake Stream Example

As you can see, it returns the inserted row! The stream captures every DML change after its offset pointer.
Example 2—Append-Only Snowflake Stream
For our next trick, let's create an append-only Snowflake stream:
CREATE STREAM my_append_stream ON TABLE my_table APPEND_ONLY = TRUE;Snowflake Stream Example
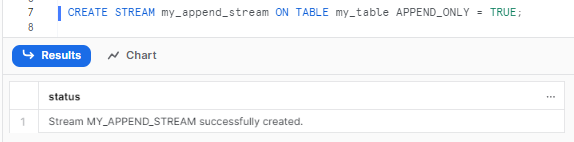
This type ignores updates/deletes and is more lightweight. To test, we update an existing row then query:
UPDATE my_table SET name = 'Elon' WHERE id = 1;
SELECT * FROM my_append_stream;Snowflake Stream Example
As you can see, there are no rows! Since it only handles appends, the update is skipped. Pretty nifty for ingest-only feeds.
Example 3—Snowflake Stream on Transient Table
Streams work nicely on transient tables too. Transient tables are similar to permanent tables with the key difference that they do not have a Fail-safe period.
CREATE TRANSIENT TABLE my_temp_table AS SELECT * FROM my_table;Snowflake Stream Example
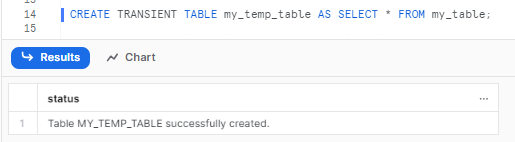
Let’s create a Stream on the transient table
CREATE STREAM my_temp_stream ON TABLE my_temp_table; Snowflake Stream Example
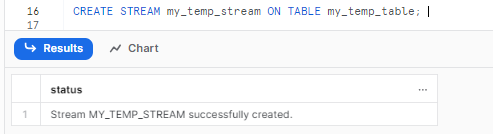
This stream will now track inserts, updates, deletes on my_temp_table. We can query it to see changes:
INSERT INTO my_temp_table VALUES (4, 'Elon Musk', '2023-12-11');
SELECT * FROM my_temp_stream;Snowflake Stream Example

As you can see, the inserted row returned even for transient source tables!
Example 4—Insert-Only Snowflake Stream on External Tables
Next up, we'll demonstrate streaming an external table. To do this, you'll need an existing external table. The query process remains mostly the same as the standard table, with the exception of replacing the TABLE keyword with EXTERNAL TABLE.
CREATE EXTERNAL TABLE ext_table
LOCATION = @MY_AWS_STAGE
FILE_FORMAT = my_format;
CREATE STREAM my_ext_stream
ON EXTERNAL TABLE ext_table
INSERT_ONLY = TRUE;Snowflake Stream Example
This special insert-only external stream will log additions and changes to underlying source files without tracking deletions.
Limitations of Snowflake Streams
While streams are quite capable, they do have some limitations:
- Scalability: Creating and querying many streams concurrently could impact performance. Throttling may be required.
- Data Volumes + Throughput: Ingesting high volumes of data into source tables could overload stream change tracking capabilities leading to lag or data loss scenarios.
- Latency: There is often a slight delay in change data appearing in streams due to transactional and consistency model differences. Tuning may help produce lower latency CDC.
- Complexity: Managing many Snowflake streams, monitoring for issues, and maintaining robust change consuming pipelines requires strong data engineering skills.
- Support: Streams don't work for all data types and formats. Semi-structured, geospatial, etc may not fully capture all changes.
Make sure to carefully test Snowflake streams against your specific data and use case.
For a more in-depth guide on Snowflake Streams, check out this comprehensive video playlist by Rajiv Gupta.
What Are the Disadvantages of Streams in Snowflake?
Snowflake streams also have some disadvantages that you should be aware of before using them. Some of these disadvantages are:
- Snowflake streams are not compatible with some types of objects and operations in Snowflake. For example, streams cannot track changes in materialized views.
- Snowflake streams may incur additional storage and performance costs. Streams store the offset and change tracking metadata for the source object in hidden internal tables, which consume some storage space.
- Streams can only track DML changes, such as insert, update, or delete, but not DDL changes
- Streams may require more maintenance and monitoring. Streams are designed to be consumed regularly and completely, meaning that the stream advances to the next offset after each query or load operation. If the streams are not consumed or advanced, the change records may accumulate and cause the streams to lag behind the source object.
What Is the Difference Between Stream and Snowflake Task in Snowflake?
| Snowflake Streams | Snowflake Tasks |
| Snowflake streams are objects that track the changes made to tables, views, external tables, and directory tables using simple DML statements | Tasks are objects that execute a single SQL command or call a stored procedure on a schedule |
| Snowflake streams do not have any schedule or trigger, but they can be consumed or advanced manually or by Snowflake tasks | Tasks can be scheduled using CRON expressions or triggered by other tasks or external events |
| Snowflake streams can only track DML changes, such as insert, update, or delete, but not DDL changes | Tasks can execute any type of SQL code, including DML, DDL, or Snowflake Scripting |
| Snowflake streams also have some limitations and unsupported features, such as materialized views | Snowflake task tree can accommodate up to 1000 Snowflake tasks in total. Individual parent tasks can have a maximum of 100 child Snowflake tasks. |
Monitoring Snowflake Stream Staleness
Snowflake stream can become stale if its offset moves outside the data retention period for the source table/view.
At that point, the historical changes required to recreate stream results are no longer accessible. Any unconsumed records in the stream are lost.
To avoid staleness, Snowflake streams should be read frequently enough to keep the offset within the table's retention window. If the data retention period for a table is less than 14 days, and a stream has not been consumed, Snowflake temporarily extends this period to prevent it from going stale. The period is extended to the stream’s offset, up to a maximum of 14 days by default.
The STALE_AFTER metadata field predicts when a stale state will occur based on consumption patterns. Monitor and consume streams prior to that timestamp.
If a stream does go stale, it must be dropped and recreated to reset the offset to the end of the current table timeline. The stream will then resume change capture from that point forward.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Conclusion
And that’s a wrap! Snowflake streams provide a really slick way to stay on top of your ever-changing data. Instead of confusing custom solutions, Snowflake streams give you full access to changes happening across your tables/views.
In this article, we covered:
- What are Snowflake Streams and How They Work?
- What are the 3 types of streams in Snowflake?
What is Offset in a snowflake stream and how does it work? - How to clone a Snowflake Stream?
- Step-by-Step Process of Creating a Snowflake Stream
- Limitations and Disadvantages of Snowflake Streams
- What is the difference between stream and task in Snowflake?
…and so much more!!
Snowflake streams are like smart bookmarks—they remember a position in the ongoing history of your table. So by storing just this tiny offset metadata rather than duplicating masses of data, streams let you travel through time to fetch row changes on demand!
FAQs
What are Snowflake streams?
Snowflake streams are objects that track DML changes to source tables or views by adding metadata columns. They act as a bookmark to access the native versioning history.
What source objects can have Snowflake streams?
Snowflake streams can be created on standard tables, directory tables, external tables and views.
What are the three metadata columns added by Snowflake streams?
METADATA$ACTION, METADATA$ISUPDATE, and METADATA$ROW_ID
Is there a limit on the number of streams in Snowflake?
No, there is no hard limit on the number of streams but performance may degrade with a very high number.
How do you query a stream and see the change records?
You can query a stream just like a table, using the SELECT statement. You can apply filters, predicates, and joins on the stream columns.
What are the three types of Snowflake streams?
Standard streams track inserts, updates and deletes. Append-only streams only track inserts. Insert-only streams track inserts for external tables.
How can you clone an existing Snowflake stream?
You can use the CLONE syntax to create a copy of stream which inherits the offset and returns the same change records.
How can transient tables have streams?
Yes, both permanent and transient tables support Snowflake streams to track DML changes.
Can Snowflake streams become stale?
Yes, if a stream's offset moves outside the source table's fail-safe retention period, it can become stale and must be recreated.
Why should Snowflake streams be consumed regularly?
To prevent accumulation of change records which causes streams to lag behind source tables as the offset is only advanced upon consumption.
What are the benefits of using Snowflake streams?
Snowflake streams enable you to query and consume the changed data in a transactional and consistent manner, ensuring data accuracy and freshness.
Can Snowflake tasks help manage stream consumption?
Yes, Snowflake tasks can be created to automatically consume streams on schedules or triggers to advance offsets.
How can stream staleness be predicted?
STALE_AFTER metadata field provides a timestamp for predicted staleness based on past consumption.









