




























Ever heard of Apache Iceberg? If you're into big data, you might want to pay attention. It's an open table format designed for large-scale data management, offering features such as ACID transactions, schema evolution, time travel, and much more. Originally created by Netflix and later donated to the Apache Software Foundation, Iceberg is growing rapidly and addressing the limitations of traditional data lakes. Snowflake recognized the potential of Iceberg and has integrated support for Apache Iceberg tables into their platform. Now, you can enjoy the flexibility of an open format combined with the performance and reliability of Snowflake. And guess what? Recently, Snowflake announced that Iceberg table support is now generally available (GA).
In this article, we will cover everything you need to know about the Snowflake Iceberg table, covering Apache Iceberg table basics, the benefits of the Iceberg table in Snowflake, Snowflake standard table vs Iceberg table architecture, creation, and management of Iceberg table in Snowflake.
What is Apache Iceberg?
Apache Iceberg is an open source, high-performance table format designed to manage large analytic datasets typically stored in distributed file systems or object storage. Unlike traditional file formats used in data lakes, Iceberg introduces a higher level of abstraction—treating data as tables rather than individual files. This gives many benefits: performance, data reliability, and flexibility.
Features of Apache Iceberg
Let's dive into some of the standout features that make Apache Iceberg a game-changer in the world of big data:
1) ACID Transactions
Apache Iceberg supports full ACID (Atomicity, Consistency, Isolation, Durability) transactions, which guarantees that complex data operations are completed fully or not at all, maintaining data consistency and integrity even in the face of failures.
2) Data Versioning
Apache Iceberg's versioning system creates a new snapshot of the table's state with every change. This allows for point-in-time queries, making it easy to access historical data, facilitate auditing, and ensure compliance by tracking how data evolves over time.
3) Full Schema Evolution
Apache Iceberg supports extensive schema evolution, allowing users to add, drop, rename, and reorder columns without needing to rewrite existing data.
4) Hidden Partitioning
Apache Iceberg handles the painful and error-prone task of computing partition values for rows in a table and skips unnecessary partitions and files. No extra filters needed for fast queries and tables can be updated as data or queries change.
5) Time Travel and Rollback
Leveraging its versioning system, Apache Iceberg allows users to query data as it existed at any specific point in time.
6) Data Compaction
Iceberg supports data compaction techniques like bin-packing and sorting to optimize the layout and size of data files, improving query performance.
Save up to 30% on your Snowflake spend in a few minutes!


Core Architecture of Apache Iceberg
To truly appreciate the power and flexibility of Apache Iceberg, it's crucial to understand its underlying architecture. Iceberg's design is fundamentally different from traditional data lake file formats, offering a more sophisticated and efficient approach to data management. At a high level, Iceberg's architecture consists of three primary layers:
- Iceberg Catalog
- Metadata Layer
- Data Layer
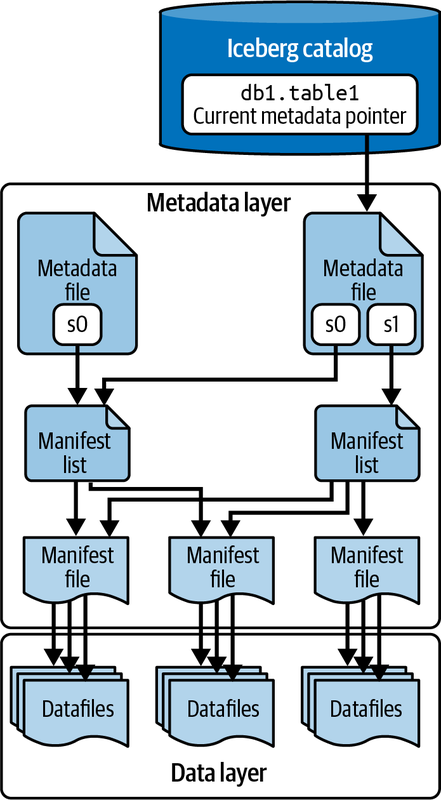
Let's explore each of these layers in detail:
1) Iceberg Catalog
The Iceberg Catalog manages the namespaces and tables, providing a consistent view of the table's metadata. This catalog is responsible for storing and organizing metadata, enabling operations such as listing tables, creating or deleting tables, and tracking table versions. Iceberg supports various catalog implementations like Hive Metastore, AWS Glue, and custom catalogs.
2) Metadata Layer
Beneath the catalog layer is the Metadata Layer, which consists of:
- Metadata Files: These files store critical information about the table, such as its schema, partitioning information, and snapshots. They also track the history of changes and the current state of the table.
- Manifest Lists: These lists contain pointers to manifest files and include high-level statistics and partition information, enabling efficient data access and filtering.
- Manifest Files: These files list individual data files along with their statistics, such as record counts and column bounds. They enable fine-grained tracking and management of data at the file level.
3) Data Layer
Data Layer is the foundation of Iceberg tables, holding the actual data files. These files can be in formats like Parquet, Avro, or ORC. The data layer is optimized for efficient querying and data management, supporting operations like partitioning, which groups similar rows together to speed up queries.
What Are Snowflake Iceberg Tables?
Snowflake Iceberg tables represent an innovative fusion of Snowflake's powerful cloud data platform with the flexibility and interoperability of the Apache Iceberg table format. In essence, Snowflake Iceberg tables are a new type of table in Snowflake that adheres to the Apache Iceberg specification, allowing data to be stored in external cloud storage while still leveraging Snowflake's query engine and many of its advanced features.
When you create an Iceberg table in Snowflake, you're essentially telling Snowflake to manage a table whose data resides in external cloud storage (such as Amazon S3, Google Cloud Storage, or Azure Blob Storage) using the Iceberg format. This approach combines the best of both worlds: the performance and familiar SQL interface of Snowflake with the open format and interoperability of Iceberg.
Here's how Snowflake Iceberg tables work at a high level:
1) Data Storage: The actual data files (typically in Parquet format) are stored in your own cloud storage account, not within Snowflake's managed storage.
2) Metadata Management: Depending on the type of Iceberg table (which we'll discuss later), either Snowflake or an external system manages the Iceberg metadata.
3) Query Execution: When you query an Iceberg table, Snowflake's query engine reads the Iceberg metadata to determine which data files to access, then retrieves and processes those files to generate your results.
4) Write Operations: For Snowflake-managed Iceberg tables, write operations (inserts, updates, deletes) are handled by Snowflake, which updates both the data files in your external storage and the Iceberg metadata accordingly.
5) Access Control: Snowflake's robust security features, including role-based access control, can be applied to Iceberg tables just like any other Snowflake object.
To connect Snowflake to your external storage for Iceberg tables, you use two key Snowflake objects:
- External Volume: This is an account-level object that stores the necessary information for Snowflake to access your external cloud storage.
- Catalog Integration (for externally managed tables): This object defines how Snowflake interacts with an external catalog system (like AWS Glue) for managing Iceberg table metadata.
Benefits of Using Iceberg Tables in Snowflake
Here are the benefits of Iceberg tables in Snowflake:
1) Open Lakehouse Implementation
Apache Iceberg tables allow Snowflake users to implement a lakehouse architecture using open file and table formats. You can store your data in your own cloud storage and still get to use Snowflake’s query engine and features.
2) Interoperability
Since Iceberg tables are an open format, data in Snowflake Iceberg tables can be read and written by other tools that support Iceberg like Apache Spark or Trino. This interoperability means multi-engine workflows and no more data silos.
3) Performance
Snowflake's implementation of Apache Iceberg tables leverages the platform's high-performance query engine and optimizations. For many workloads, Iceberg tables can offer performance comparable to native Snowflake tables, especially for Snowflake-managed Iceberg tables.
4) Data Sharing and Collaboration
Snowflake Iceberg tables make it easier to share and collaborate on data across different platforms and teams. Data scientists using Spark and analysts using Snowflake can work on the same datasets without data duplication or complex ETL.
5) Cost Control
You have more control over storage costs since you’re storing data in your own cloud storage and can potentially optimize them independent of your Snowflake usage.
7) Flexibility
Iceberg tables provide more flexibility in terms of where and how you store your data, allowing you to build data architectures that best suit your organization's needs.
How Snowflake Iceberg Tables Work?
Snowflake Iceberg tables operate by storing data and metadata in external cloud storage (Amazon S3, Google Cloud Storage, or Azure Storage). Snowflake connects to this external storage using an external volume—a Snowflake object that securely manages access. Here’s a brief breakdown of how they work:
- Data Storage: Data and metadata are stored externally, not in Snowflake, which means Snowflake does not charge for storage—only for compute usage.
- External Volume: This is a named Snowflake object that connects to external cloud storage using identity and access management (IAM) credentials. It supports multiple Iceberg tables.
- Iceberg Catalog: Manages table metadata pointers and ensures atomic updates. You can use Snowflake as the catalog or integrate it with an external catalog like AWS Glue.
- Snapshot-Based Model: Iceberg uses snapshots to represent the state of the table at specific points in time, aiding in querying and data recovery.
- Cross-Cloud/Region Support: Supported when using an external catalog. Tables using Snowflake as the catalog must reside in the same cloud region as the Snowflake account.
- Billing: Only compute and cloud services are billed by Snowflake. Storage costs are billed by the cloud provider.
What Is the Difference Between Snowflake Standard Table and Iceberg Table?
To fully appreciate the unique characteristics of Snowflake Iceberg tables, it's helpful to compare them with Snowflake's standard tables. Here's a detailed comparison:
| Snowflake Standard Table | Snowflake Iceberg Table |
| Data storage location of Snowflake Standard Table is internally managed by Snowflake | Data storage location of Snowflake Iceberg Table is external cloud storage like S3, Blob Storage or GCS |
| Snowflake Standard Table uses a proprietary Snowflake format | Snowflake Iceberg Table uses the Apache Iceberg open table format |
| Metadata for Snowflake Standard Table is managed internally by Snowflake | Metadata can be managed by Snowflake or an external Iceberg catalog |
| Data is stored in a proprietary format optimized for Snowflake | Data in Snowflake Iceberg Table is stored in Parquet files |
| Full data lifecycle management (e.g., compaction, snapshot expiration) is automated by Snowflake | Lifecycle management can be automated by Snowflake or manually managed by the customer |
| Optimized for high performance within Snowflake's infrastructure | Performance is comparable to native tables when managed by Snowflake, potentially lower when using external catalogs |
| Storage costs are included in Snowflake's billing | Storage costs are billed directly by the cloud provider |
| Cross-cloud and cross-region support is limited to Snowflake's infrastructure | Cross-cloud/region support for Snowflake Iceberg Table is available when using an external catalog with potential egress costs |
| Full support for snapshots and time travel with Snowflake's built-in features | Snapshots and Time Travel for Snowflake Iceberg Table are supported with Iceberg’s snapshot-based model |
| Limited interoperability, optimized for use within the Snowflake ecosystem | Data Interoperability for Snowflake Iceberg Table is high, supporting integration with other tools and platforms that use Iceberg |
| Full support for multi-table transactions within Snowflake | Supported when using Snowflake as the catalog |
| Security features for Snowflake Standard Table include native capabilities like dynamic data masking and row-level security | Security features for Snowflake Iceberg Table are supported with Snowflake as the catalog; additional setup may be required for external catalogs |
| Ideal for general-purpose data warehousing | Suitable for big data analytics and scenarios requiring open formats and external storage. |
What Is the Difference Between External Table and Iceberg Table?
Here is a full comparison between Snowflake External Table and Snowflake Iceberg Table:
| Snowflake External Table | Snowflake Iceberg Table |
| Data Storage Location for Snowflake External Table is external cloud storage (Amazon S3, Google Cloud Storage, or Azure) | Data Storage Location for Snowflake Iceberg Table is also external cloud storage supplied by the customer |
| Snowflake External Table references data stored in an external stage, without moving the data into Snowflake | Snowflake Iceberg Table uses the Apache Iceberg format, storing both data and metadata in external cloud storage |
| Metadata Management for Snowflake External Table involves storing file-level metadata within Snowflake | Metadata Management for Snowflake Iceberg Table can be managed by Snowflake or an external Iceberg catalog |
| Snowflake External Table supports querying data in a data lake as if it were in a Snowflake table | Snowflake Iceberg Table combines the performance and query semantics of regular Snowflake tables with external cloud storage |
| Data in Snowflake External Table is accessed and queried directly from the external stage using file paths and metadata | Data in Snowflake Iceberg Table is stored in Parquet files, with metadata and snapshots managed by Iceberg |
| Performance for Snowflake External Table depends on the efficiency of the external data lake and metadata refresh operations | Performance for Snowflake Iceberg Table is optimized when managed by Snowflake, potentially lower with external catalogs |
| Cost for Snowflake External Table includes compute billed by Snowflake and potential storage costs from the cloud provider | Cost for Snowflake Iceberg Table includes compute billed by Snowflake and storage billed by the cloud provider |
| Cross-cloud/region support for Snowflake External Table allows for querying data across different cloud providers and regions | Cross-cloud/region support for Snowflake Iceberg Table is available when using an external catalog with potential egress costs |
| Data Interoperability for Snowflake External Table is designed to integrate with existing data lakes and cloud storage systems | Data Interoperability for Snowflake Iceberg Table supports integration with tools and platforms that use the Iceberg format |
| Use cases for Snowflake External Table include augmenting existing data lakes and running ad-hoc analytics on raw data | Use cases for Snowflake Iceberg Table include big data analytics, regulatory constraints, and leveraging open format |
Types of Snowflake Iceberg Tables
Snowflake supports two main types of Iceberg tables, each with its own characteristics and use cases.
1) Snowflake Managed Iceberg Tables
In Snowflake-managed Iceberg tables, Snowflake handles the table's metadata and lifecycle. These tables offer full Snowflake support, including read and write access, simplified maintenance, and operational tasks managed by Snowflake. They are ideal for users who want the performance and management capabilities of Snowflake.
2) Externally Managed Iceberg Tables
Externally managed Iceberg tables use an external catalog (e.g., AWS Glue) to manage the table's metadata. These tables support interoperability with external catalogs and tools, allowing integration with existing data lakes and external storage solutions. They provide flexibility for organizations using multiple data platforms but only support read access within Snowflake.
| Features | Snowflake Managed Iceberg Tables | Externally Managed Snowflake Iceberg Tables |
| Read Access | ✔ | ✔ |
| Write Access | ✔ | ❌ |
| Use of Warehouse Cache | ✔ | ✔ |
| Automatic Metadata Refresh | ✔ | ❌ |
| Interoperability | Good | Excellent |
| Nested Datatype Support | ✔ | ✔ |
| Support of Table Clustering | ✔ | ❌ |
| Snowflake Platform Features (Masking, Time Travel) | ✔ All features | ❌ Limited |
Performance Implications of Snowflake Iceberg Tables
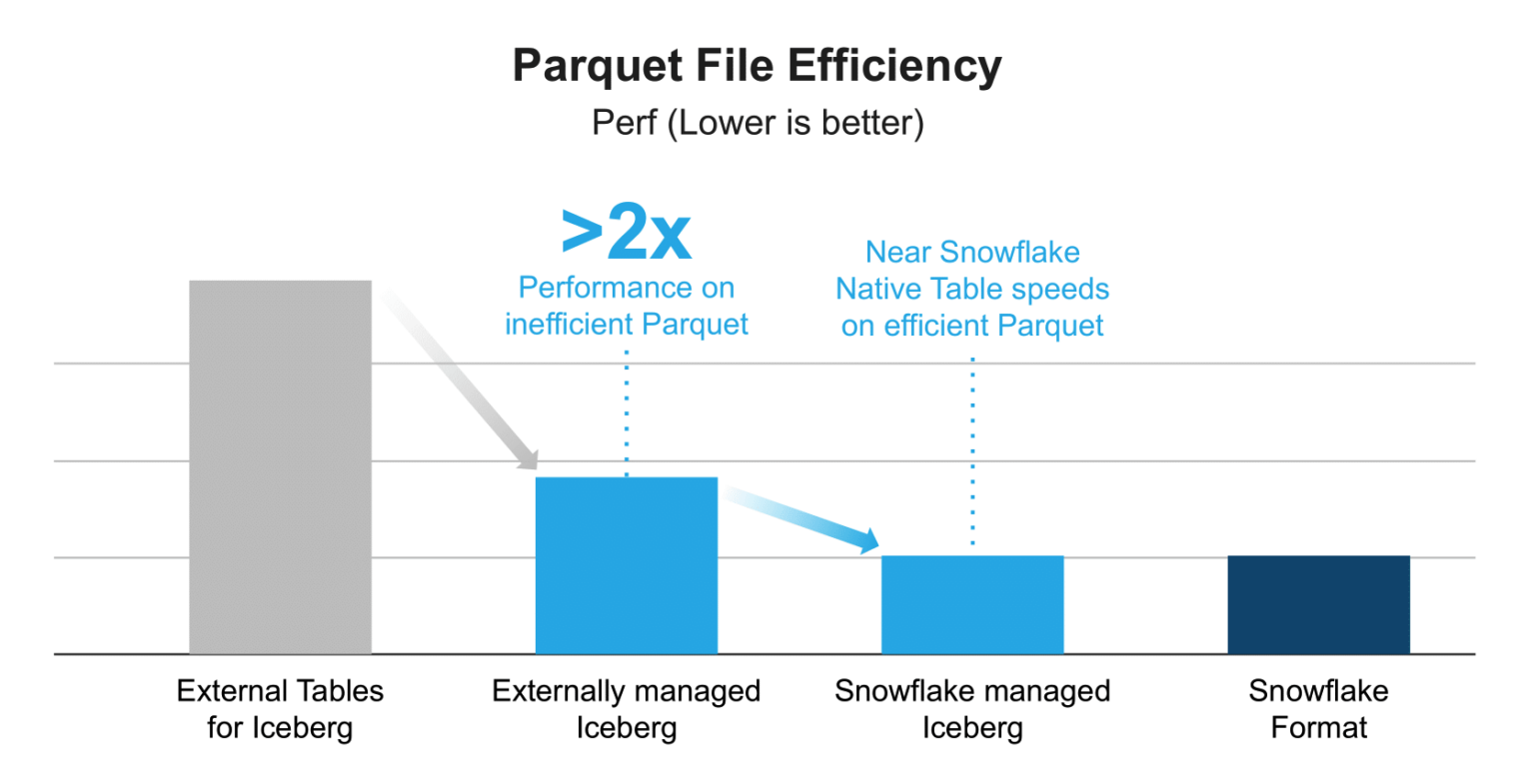
Optimized Parquet Scanner:
Snowflake's highly optimized Parquet scanner is now used for Iceberg Tables, resulting in a 2x performance improvement over External Tables. This scanner leverages full statistics from both Parquet and Iceberg, enhancing query efficiency.
Local Data Caching:
Iceberg Table data is cached locally on the warehouse, boosting performance for concurrent workloads. This caching is not available with External Tables, giving Iceberg Tables a distinct advantage.
Performance Gap Between Catalog Types:
A performance gap exists between Snowflake-managed and externally managed Iceberg Tables. This gap is primarily due to the efficiency of Parquet file writing. If external engines write Parquet files without full statistics, Snowflake's performance is negatively impacted. Efficient Parquet file handling is crucial for optimal performance in Snowflake-managed Iceberg Tables.
How to Create Iceberg Tables in Snowflake?
Creating Iceberg tables in Snowflake involves using the CREATE ICEBERG TABLE command. Users must specify an external volume and a catalog (either Snowflake or an external one like AWS Glue). The process requires a running warehouse and can be done using SQL commands.
For a more in-depth detailed tutorial, you can check out this youtube video:
How Iceberg Tables Work In Snowflake
Limitations of Snowflake Iceberg Table
While Snowflake Iceberg tables offer many advantages, it's important to be aware of their current limitations:
1) Availability Region
Snowflake Iceberg tables are available on all cloud platforms and regions except SnowGov regions.
2) Cross-Cloud and Cross-Region Limitations
Cross-cloud and cross-region Snowflake Iceberg tables are supported when using an external catalog. But there are limitations if the active storage location is not in the same cloud provider or region as your Snowflake account.
3) Data Format Support
Snowflake Iceberg tables in Snowflake only support data storage in the Parquet format.
4) Third-Party Client Modifications
Third-party clients cannot modify data in Snowflake Iceberg tables, restricting some integration possibilities.
5) Partitioning Impact on Performance
Certain partitioning methods, such as the bucket transform function, can negatively impact performance for queries with conditional clauses.
6) Time Travel in Spark
Time travel features in Spark are not supported for Snowflake-managed Iceberg tables.
7) Table Types
Only permanent Snowflake Iceberg tables can be created; transient or temporary Snowflake Iceberg tables are not supported.
8) Cloning and Replication
Cloning and replicating Snowflake Iceberg tables are not possible.
9) Write Access with External Catalogs
Externally managed Iceberg tables only support read access in Snowflake. Write access requires converting them to Snowflake-managed tables.
10) Storage Costs
Storage costs for Iceberg tables are billed by the cloud provider, not Snowflake, which can complicate cost management.
11) Row-Level Deletes
Row-level deletes are not supported by the Apache Iceberg specification. However, Snowflake supports its own DELETE statements for tables using Snowflake as the catalog.
12) Identity Partition Column Limitations
Identity partition columns cannot exceed 32 bytes.
13) Metadata Refresh for External Catalogs
Metadata refresh with external catalogs can be less efficient compared to using Snowflake as the catalog.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Conclusion
And that’s a wrap! Snowflake Iceberg tables are a big deal in data management, combining the power of Apache Iceberg with the performance and simplicity of Snowflake. They’re a flexible high performing way to manage big data, so you can have the best of both data lakes and data warehouses. There are some caveats but the benefits of Snowflake Iceberg tables are worth it for modern data driven companies.
In this article, we have covered:
- What is Apache Iceberg?
- Core Architecture of Apache Iceberg
- What Are Snowflake Iceberg Tables?
- What Is the Difference Between Snowflake Standard Table and Iceberg Table?
- What Is the Difference Between External Table and Iceberg Table?
- Types of Snowflake Iceberg Tables
- Snowflake Iceberg Table Performance
- How to Create Iceberg Tables in Snowflake?
- Limitations of Snowflake Iceberg Table
… and so much more!
FAQs
What is Apache Iceberg?
Apache Iceberg is an open-source, high-performance table format for managing large analytic datasets in distributed file systems or object storage.
What are Snowflake Iceberg tables?
Snowflake Iceberg tables are a type of table in Snowflake that use the Apache Iceberg format, storing data externally in cloud object storage while allowing Snowflake to manage and query the data.
What are the benefits of using Iceberg tables in Snowflake?
Benefits include ACID transactions, full schema evolution, time travel, hidden partitioning, data compaction, and interoperability with multiple data processing engines.
How do Snowflake Iceberg tables differ from Snowflake native tables?
Snowflake Iceberg tables store data externally and use either Snowflake or an external catalog for metadata management, while native tables store data and metadata within Snowflake.
What is the difference between Snowflake-managed and Externally managed Iceberg tables?
Snowflake-managed tables have their metadata managed by Snowflake and support full read/write access, while Externally managed tables use an external catalog for metadata and only support read access within Snowflake.
Can Snowflake Iceberg tables support cross-cloud or cross-region data?
No, Snowflake Iceberg tables do not support cross-cloud or cross-region configurations.
What data formats are supported by Snowflake Iceberg tables?
Currently, Snowflake Iceberg tables only support the Parquet data format.
Can third-party clients modify data in Snowflake Iceberg tables?
No, third-party clients cannot modify data in Snowflake Iceberg tables.
Are temporary or transient Snowflake Iceberg tables supported?
No, only permanent Snowflake Iceberg tables can be created.
Can Snowflake Iceberg tables be cloned or replicated?
No, cloning and replicating Snowflake Iceberg tables are not possible.’
How are storage costs handled for Snowflake Iceberg tables?
Storage costs for Iceberg tables are billed by the cloud provider, not Snowflake.
Does Snowflake support row-level deletes for Iceberg tables?
Row-level deletes are not supported by the Apache Iceberg specification, but Snowflake supports its own DELETE statements for tables using Snowflake as the catalog.
Can Snowflake Iceberg tables be used with other tools that support Iceberg?
Yes, data in Snowflake Iceberg tables can be read and written by other tools that support Iceberg, like Apache Spark or Trino.









