





























Extracting useful info from a massive volume of data can be a real challenge. Data can be super tidy or a total mess. The issue isn’t finding the info; it’s just that digging through it, analyzing it, and pulling out what you need is a slow and painful process. Traditionally, turning messy/unstructured data like PDFs, emails, and reports into neat/structured forms required entering it all manually or using custom scripts, both of which were error-prone and inefficient. Structured data, on the other hand, can be easily queried, analyzed, and integrated. To solve this, Snowflake came up with Snowflake Document AI, which was released in public preview on May 17, 2023, and reached general availability on October 21, 2024. This tool is designed to tackle the messy data issue. Document AI uses advanced machine learning algorithms and large language models to automate the extraction, processing, and structuring of unstructured data.
In this article, we will explore everything you need to know about Snowflake Document AI in detail, covering its key features, capabilities, use cases, and cost considerations, along with step-by-step guides for configuring and using Snowflake Document AI from scratch.
What is Snowflake Document AI?
Snowflake Document AI is a Snowflake AI feature that utilizes the Arctic-TILT large language model (LLM) along with Snowflake Cortex for fine-tuning and customization. Arctic-TILT(Text Image Layout Transformer), developed by Snowflake, is a multimodal LLM specifically designed for document understanding tasks. This tool processes unstructured data from various document formats (like text-heavy paragraphs, logos, handwritten text, and checkmarks) and transforms it into structured data, facilitating its integration into operational workflows.
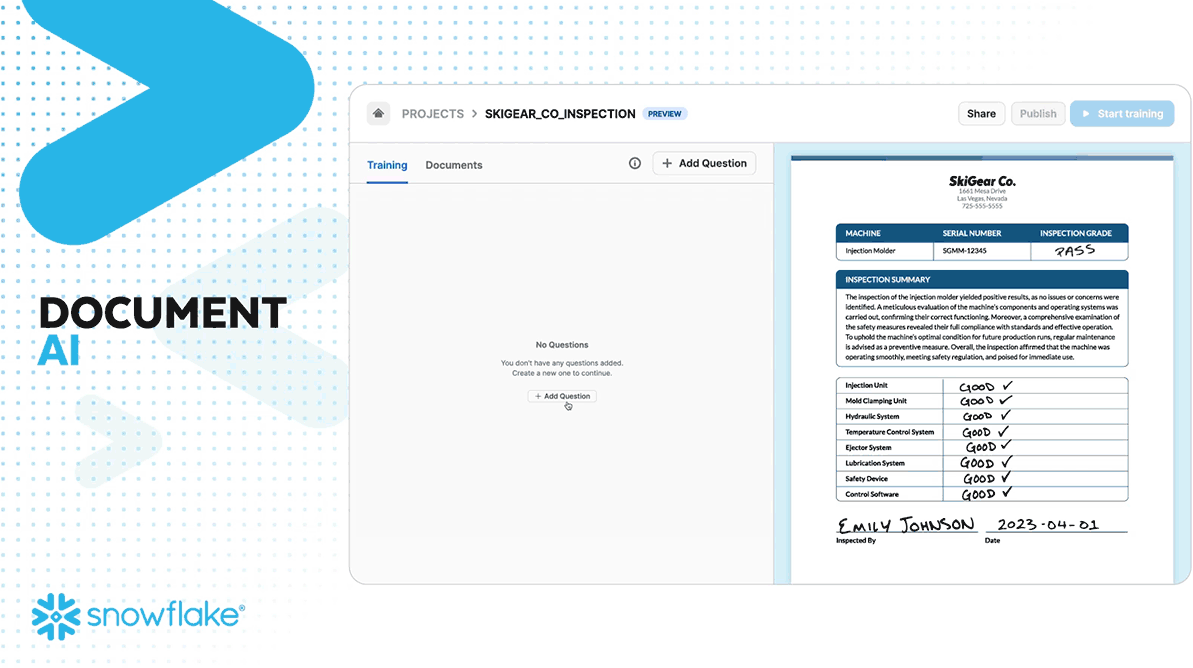
Snowflake Document AI provides two main functionalities: zero-shot extraction and fine-tuning. Zero-shot extraction allows the model to locate and extract relevant information even from document types it hasn't encountered before, leveraging its extensive training on diverse documents. Fine-tuning enables customization of the model to improve accuracy for specific use cases, guaranteeing that the model adapts to particular business needs.
The workflow with Snowflake Document AI involves two key stages:
- Model Preparation: Users upload sample documents and define the data points to extract through natural language queries. The model is then fine-tuned based on evaluation results. This stage involves creating a model build that includes the model, the documents for testing, and the data values to be extracted.
- Inference: The trained and fine-tuned model can process large volumes of documents at scale. Automated pipelines can be set up using Snowflake stages and the PREDICT function to continuously extract data from new documents.
Snowflake Document AI is designed to be extremely user-friendly, requiring no prior machine learning expertise. The platform offers an intuitive natural language interface, allowing users to set up models and extract information with just a few clicks.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Key Features and Capabilities of Snowflake Document AI
Snowflake Document AI offers a robust set of features and capabilities designed to process and extract information from various document types. Here are the key features and capabilities:
Feature 1: Document Scanning and Optical Character Recognition (OCR)
Snowflake Document AI uses Optical Character Recognition (OCR) to convert scanned documents, PDFs, images, and handwritten texts into editable and searchable text. This capability allows for the digitization of paper-based information, making it easier to process and search through large volumes of documents.
Snowflake Document AI supports limited document formats. They are:
- PNG
- DOCX
- EML
- JPEG
- JPG
- HTM
- HTML
- TEXT
- TXT
- TIF
- TIFF
Feature 2: Entity Recognition and Data Extraction
Snowflake Document AI can identify and extract key entities from documents, such as names, dates, monetary amounts, and more.
Feature 3: Natural Language Processing (NLP) Capabilities
Snowflake Document AI leverages Natural Language Processing (NLP) to identify and extract key entities from documents. This can include information such as invoice amounts, contractual terms, and other relevant data points, making the extracted data actionable for business workflows.
Feature 4: Zero-Shot Extraction Without Training
Zero-shot extraction means that the AI model can extract specific information from documents even if it has never seen that particular type of document before. This is possible because the foundation model is trained on a large variety of documents, giving it a broad understanding of different document types.
Feature 5: Fine-Tuning the Arctic-TILT Model
Users can fine-tune the Arctic-TILT model by training it on specific documents relevant to their use case.
Feature 6: Snowpark Integration for Developers
Snowflake Document AI integrates seamlessly with Snowpark, allowing developers to build applications that leverage Document AI’s functionalities using familiar languages like Java, Scala, and Python.
Feature 7: Security and Compliance Features
Snowflake Document AI adheres to strict security protocols, including end-to-end encryption and compliance with major regulatory standards, making sure the protection of sensitive information throughout the analysis process.
Feature 8: No-Code/Low-Code Interface
The user-friendly interface of Snowflake Document AI requires no coding or machine learning expertise. Business users can interact with the model through natural language queries, making it accessible to non-technical stakeholders.
Primary Use Cases for Snowflake Document AI
Snowflake Document AI transforms unstructured data into structured data, automates document processing, and enhances collaboration between business users and engineers. Here are some primary use case of Snowflake Document AI:
Use Case 1: Converting Unstructured Data to Structured Data
Snowflake Document AI uses Optical Character Recognition (OCR) and Natural Language Processing (NLP) a first party Large Language Model (LLM) to extract and organize data from various document formats, making it accessible and analyzable.
Use Case 2: Automating Document Processing Pipelines
Snowflake Document AI automates the extraction and processing of documents through continuous pipelines, reducing manual data entry and processing time.
Use Case 3: Enabling Business-Engineer Collaboration
Snowflake Document AI's user-friendly interface allows business users to prepare and fine-tune models without needing deep technical knowledge. Engineers can then integrate these models into automated pipelines using raw SQL or other Snowflake's tools, such as Snowpark, to ensure smooth and efficient data processing.
How to Estimate Snowflake Document AI Cost?
Using Snowflake Document AI incurs costs in several ways. Understanding these costs is crucial for effective cost management.
Cost Component 1: AI Services Compute Costs
Snowflake Document AI uses Snowflake-managed compute resources that scale automatically based on workload requirements. Costs are incurred based on the time spent using these resources. The credit consumption is measured on a per-second basis, rounded up to the nearest whole second. This model ensures efficient use of compute resources, as credits are consumed only when the resources are actively being used.
Cost Component 2: Virtual Warehouse Compute Costs
When running queries, including those involving the PREDICT method, you select a virtual warehouse. The size of the warehouse (X-Small, Small, Medium, etc.) affects the cost. While larger warehouses do not necessarily speed up query processing, they can handle more simultaneous operations, which might be necessary for high-demand scenarios.
Cost Component 3: Storage Costs
Storage costs are incurred for storing documents and results within Snowflake. Documents uploaded for testing and training the model, as well as those stored in internal or external stages for extraction, contribute to storage costs. These costs are based on the amount of data stored and the duration for which it is stored.
How to Calculate Snowflake Document AI Credit Usage?
Here are some factors Affecting Credit Consumption:
- Number of Pages: More pages mean more compute resources are needed, which increses credit consumption.
- Number of Documents: Processing more documents simultaneously will require more compute resources.
- Page Density: Documents with more text or complex content (e.g., legal documents, research papers) take longer to process.
- Data Values Extracted: Extracting more data points from each document increases the processing time and resource usage.
Here is a brief overview of credit consumption for different workload types in Snowflake Document AI:
| Number of Pages | Number of Documents | Page Density | Estimated Credits (10 values) | Estimated Credits (20 values) | Estimated Credits (40 values) |
| 1000 | 10 | Low | 3 - 5 | 4 - 6 | 6 - 8 |
| 1000 | 100 | Low | 5 - 7 | 7 - 10 | 10 - 12 |
| 1000 | 1000 | Low | 10 - 12 | 11 - 13 | 12 - 14 |
| 1000 | 10 | Medium | 4 - 6 | 7 - 9 | 12 - 14 |
| 1000 | 100 | Medium | 7 - 9 | 10 - 12 | 16 - 18 |
| 1000 | 1000 | Medium | 10 - 12 | 12 - 14 | 15 - 17 |
| 1000 | 10 | High | 5 - 7 | 9 - 11 | 16 - 18 |
| 1000 | 100 | High | 8 - 10 | 12 - 14 | 21 - 23 |
| 1000 | 1000 | High | 11 - 13 | 13 - 15 | 17 - 19 |
Note: These estimated credit ranges are provided as general guidelines, and actual credit consumption may vary based on the specific characteristics of your workload and documents. Also, doubling the number of values or documents is likely to double the credit consumption accordingly.
To monitor and manage the costs associated with Snowflake Document AI, you can leverage the METERING_DAILY_HISTORY view in the ORGANIZATION_USAGE schema. This view provides insights into credit consumption for AI services, allowing you to track and optimize your usage to align with your budgetary requirements.
Complete Step-by-Step Guide to Configure Snowflake Document AI
Now that you have a decent understanding of what Snowflake Document AI is and its capabilities, let's dive right in and go through the step-by-step guide to configure and use Snowflake Document AI.
Prerequisites:
- Snowflake Account: Make sure you have an active Snowflake account.
- Necessary Roles and Privileges: Make sure you have the required roles and privileges.
- Warehouse, Database, and Schema: Make sure you have the proper privilege to set up a warehouse, database, and schema.
- Documents to Process: Gather the documents you intend to process.
Step 1—Sign in to Snowflake/Snowsight
Log in to your Snowflake account and navigate to Snowsight.
Step 2—Create Dedicated Warehouse, Database, and Schema
First, create a dedicated warehouse for Snowflake Document AI tasks.
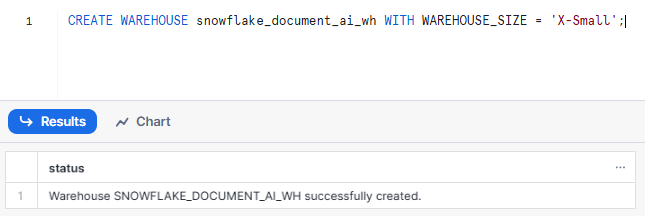
CREATE WAREHOUSE snowflake_document_ai_wh WITH WAREHOUSE_SIZE = 'X-Small';Syntax to create Snowflake Warehouse - Snowflake Document AI
Then, create a database and schema to store the documents and results.
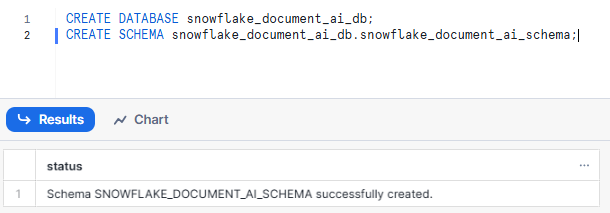
CREATE DATABASE snowflake_document_ai_db;
CREATE SCHEMA snowflake_document_ai_db.snowflake_document_ai_schema;Syntax to create Snowflake Database and Schema - Snowflake Document AI
Step 3—Grant Required Roles and Privileges
First, create custom role snowflake_document_ai_role to prepare the Snowflake Document AI model build. To do so, make sure to use ACCOUNTADMIN role.
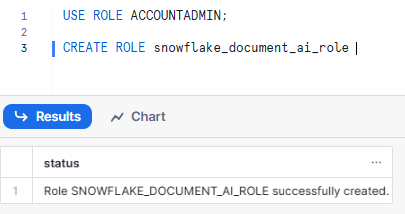
USE ROLE ACCOUNTADMIN;
CREATE ROLE snowflake_document_ai_role Syntax to create Snowflake Role - Snowflake Document AI
Note: Using the ACCOUNTADMIN role is not enough to have access to Snowflake Document AI. You must grant the SNOWFLAKE.DOCUMENT_INTELLIGENCE_CREATOR database role and the required privileges to your account role.
Now, lets grant the SNOWFLAKE.DOCUMENT_INTELLIGENCE_CREATOR database role to snowflake_document_ai_role role, run the following commands:
GRANT DATABASE ROLE SNOWFLAKE.DOCUMENT_INTELLIGENCE_CREATOR TO ROLE snowflake_document_ai_role;Syntax to grant Snowflake Role - Snowflake Document AI

Grant warehouse usage and operating privileges to the snowflake_document_ai_role role:
GRANT USAGE, OPERATE ON WAREHOUSE snowflake_document_ai_wh TO ROLE snowflake_document_ai_role;Syntax to Snowflake warehouse usage and operating privilege - Snowflake Document AI
Make sure that the snowflake_document_ai_role role can use the database and the schema:
GRANT USAGE ON DATABASE snowflake_document_ai_db TO ROLE snowflake_document_ai_role;
GRANT USAGE ON SCHEMA snowflake_document_ai_db.snowflake_document_ai_schema TO ROLE snowflake_document_ai_role;Syntax to grant Snowflake database and schema usage to specific role - Snowflake Document AI

Allow the snowflake_document_ai_role role to create a stage to store the documents for extraction:
GRANT CREATE STAGE ON SCHEMA snowflake_document_ai_db.snowflake_document_ai_schema TO ROLE snowflake_document_ai_role;Syntax to grant Snowflake stage to specific role - Snowflake Document AI
Make sure that the snowflake_document_ai_role role can create model builds (instances of the DOCUMENT_INTELLIGENCE class):
GRANT CREATE SNOWFLAKE.ML.DOCUMENT_INTELLIGENCE ON SCHEMA snowflake_document_ai_db.snowflake_document_ai_schema TO ROLE snowflake_document_ai_role;Syntax to grant model building to specific role - Snowflake Document AI

Allow the snowflake_document_ai_role role to create processing pipelines:
GRANT CREATE STREAM, CREATE TABLE, CREATE TASK, CREATE VIEW ON SCHEMA snowflake_document_ai_db.snowflake_document_ai_schema TO ROLE snowflake_document_ai_role;
GRANT EXECUTE TASK ON ACCOUNT TO ROLE snowflake_document_ai_role;Syntax to grant Snowflake Stream, Snowflake Task to specific role - Snowflake Document AI

Finally, grant the snowflake_document_ai_role role to the user:
GRANT ROLE snowflake_document_ai_role TO USER <username>;Syntax to grant Snowflake role to user - Snowflake Document AI
Step 4—Preparing Documents
Once you have granted roles and privileges, it's time to check that the documents you uploaded meet size and format requirements. Here is the list of requirements for Snowflake Document AI:
- Documents must be no more than 125 pages long.
- Documents must be in one of the following formats:
- PNG
- DOCX
- EML
- JPEG
- JPG
- HTM
- HTML
- TEXT
- TXT
- TIF
- TIFF
- Documents must be 50 MB or less in size.
- Document pages must have dimensions of 1200 x 1200 mm or less.
- Images must be between 50 x 50 px and 10000 x 10000 px.
Step 5—Building Snowflake Document AI Model
First—Sign in to Snowsight using an account role that is granted the SNOWFLAKE.DOCUMENT_INTELLIGENCE_CREATOR role.
Second—Navigate to AI & ML > Document AI in Snowsight.
Third—Select a warehouse and click on + Build.
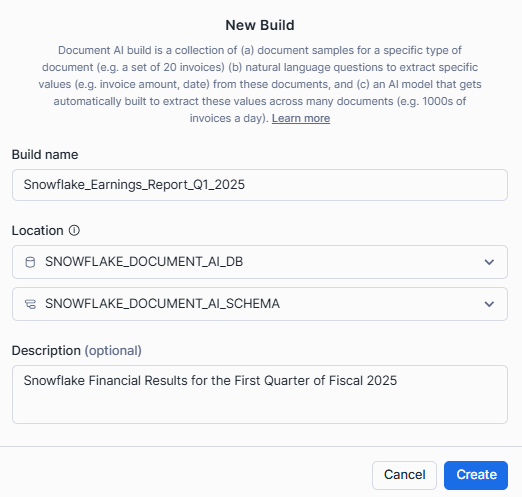
Fourth—Enter a name for your model, select the location (database and schema), and click Create.
Step 6—Uploading Documents to the Model Build
Head over to the Build Details section, and click on Upload documents.
If you want to follow along with this guide, you can download the PDF here.
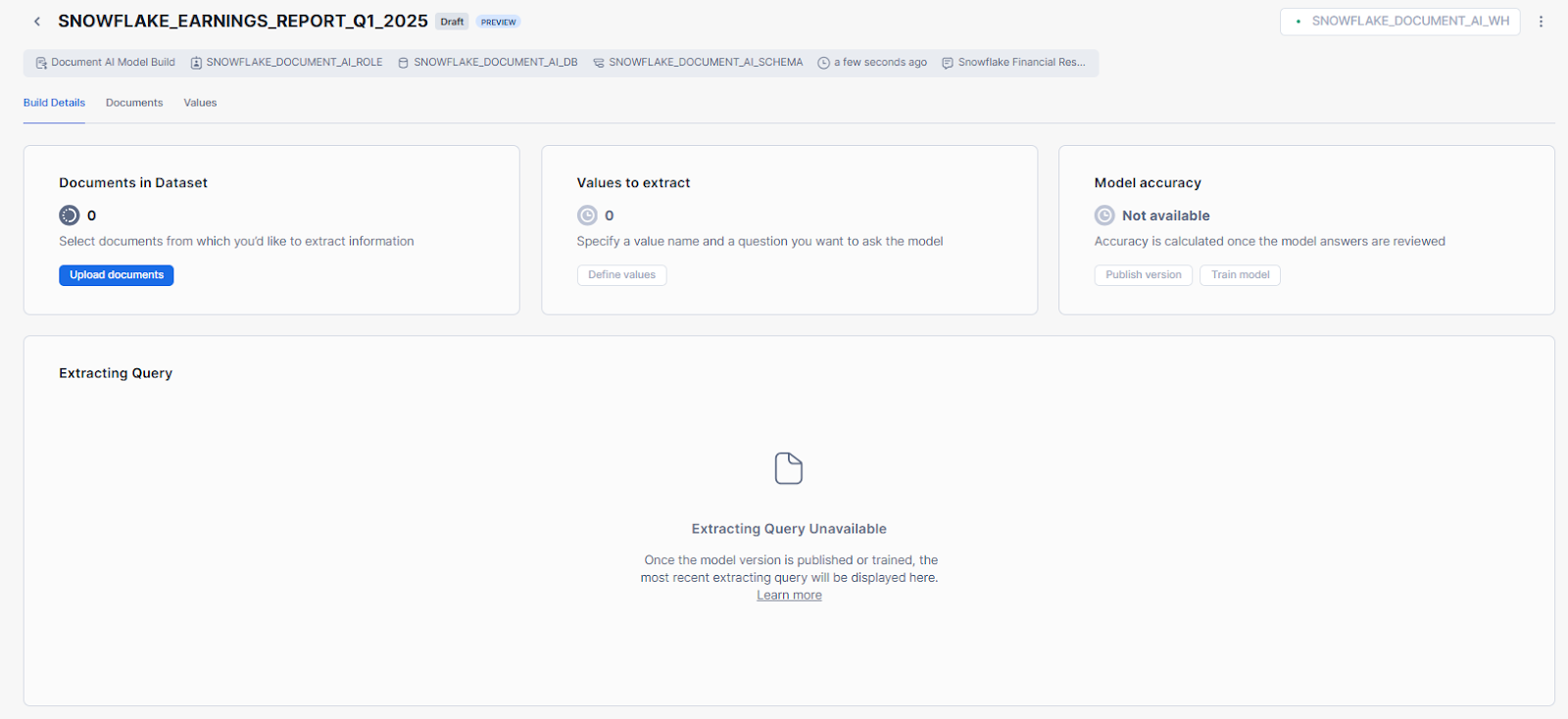
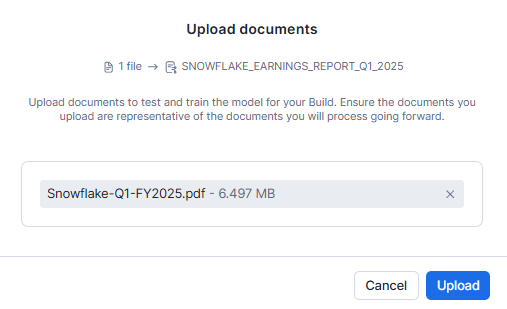
Select Browse or drag and drop files to upload.
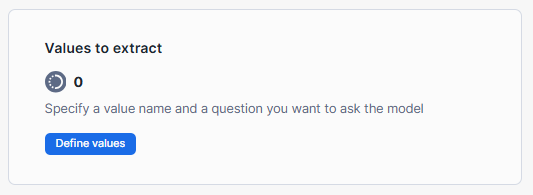
Step 7—Defining Data Values for Extraction
In this step, you define the specific data values or entities you want Snowflake Document AI to extract from your documents:
In the model build view, go to the "Build Details" tab and click on "Define values".
In the "Documents review" view, click on the "Add Value" button.
For each data value you want to extract, enter a value name and a question in natural language that represents the information you're seeking. Snowflake Document AI will attempt to answer these questions based on the content of your uploaded documents.
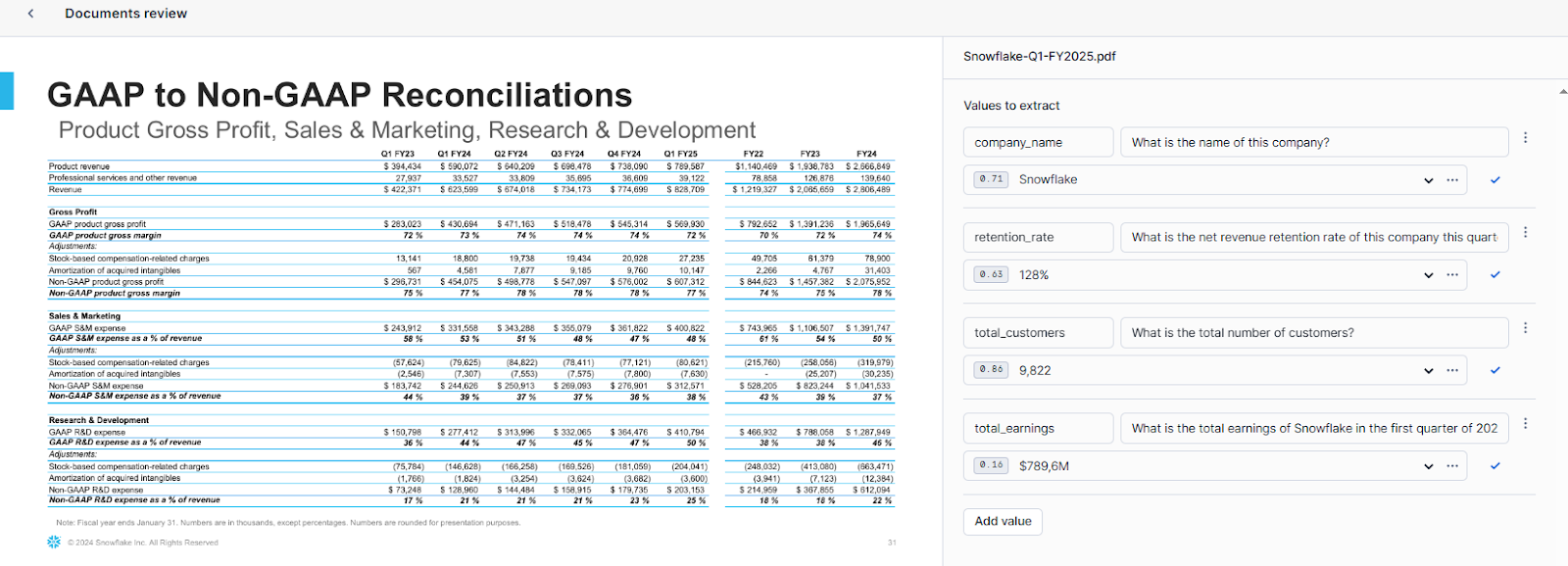
Step 8—Carefully Reviewing and Evaluating Model Results
After defining the data values, Snowflake Document AI will provide answers based on its understanding of your documents. Carefully review these answers and take the following actions:
- If an answer is correct, select “Accept all and close”.
- If an answer is incorrect, enter the correct value manually.
- If there are multiple answers provided, review and remove any incorrect ones or add additional correct answers as needed.
- If no answer is provided and the document contains the information, enter the correct value manually.

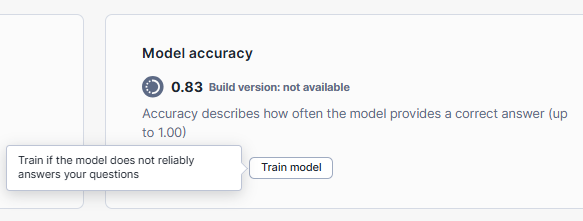
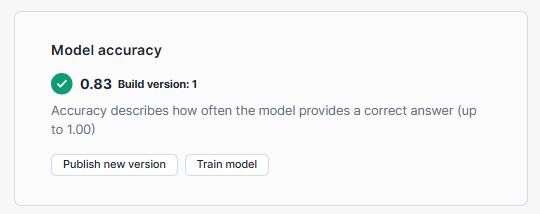
Step 9—Train the Snowflake Document AI Model (Optional)
If the accuracy and results of the Snowflake Document AI model are not satisfactory, you can choose to train the model by fine-tuning it on your specific set of documents. This process can improve the model's understanding and extraction capabilities. So for that:
- In the model build view, go to the "Build Details" tab and select "Train model" under "Model accuracy".
- Confirm the training process by selecting "Start training" in the dialog.
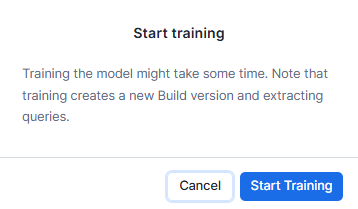
- The training process may take some time, depending on the number of documents and values being trained.
Once the training is complete, you can re-evaluate the model's performance by reviewing the results on a separate set of documents.
Step 10—Publish the Snowflake Document AI Model Build
If you're satisfied with the model's accuracy and results, you can publish the model build to make it available for use in production:
- In the model build view, go to the "Build Details" tab.
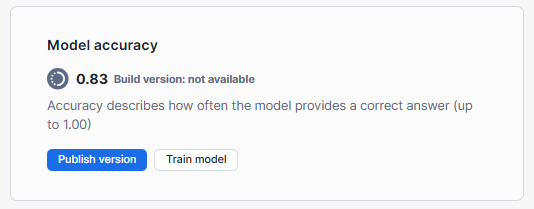
- Under "Model accuracy", select "Publish version".
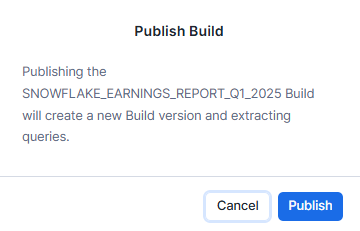
- Confirm the publishing process by selecting "Publish" in the dialog.
Step 11—Extracting Information Using Document AI
With the model build published, you can now use the extracting query (<model_build_name>!PREDICT) to extract information from staged documents.
We will dive even deeper in the next section. Continue reading to find out more.
That's it! Done! If you have successfully followed these steps, you can now effectively configure and use Snowflake Document AI for your document-processing needs.
Complete Step-by-Step Guide to Automate Document Processing via Document AI
Prerequisites:
- Same prerequisites as the previous section (Snowflake account, necessary roles and privileges, warehouse, database, schema, and documents to process).
- Have a warehouse ready for use with Snowflake Document AI, sized appropriately based on the expected workload.
Step 1—Configuring Required Objects and Privileges
Follow the same steps outlined in the previous section to create a warehouse, database, schema, and custom role with the necessary privileges for working with Snowflake Document AI.
1) Create a Dedicated Warehouse for Snowflake Document AI Tasks
CREATE OR REPLACE WAREHOUSE snowflake_document_ai_wh
WAREHOUSE_SIZE='X-SMALL'
WAREHOUSE_TYPE='STANDARD'
AUTO_SUSPEND=600
AUTO_RESUME=TRUE;Syntax to create Snowflake warehouse - Snowflake Document AI
2) Create a Database and Schema to Store the Documents and Results
CREATE DATABASE demo_snowflake_document_ai_db;
CREATE SCHEMA demo_snowflake_document_ai_db.demo_snowflake_document_ai_schema;
Syntax to create Snowflake Database and Schema - Snowflake Document AI
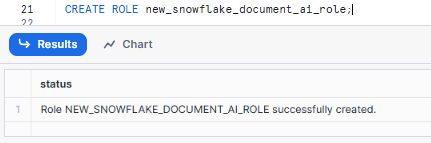
3) Create a Custom Role for Document AI Model Building
Make sure you are using the ACCOUNTADMIN role.
USE ROLE ACCOUNTADMIN;
CREATE ROLE new_snowflake_document_ai_role;Syntax to create Snowflake Role - Snowflake Document AI
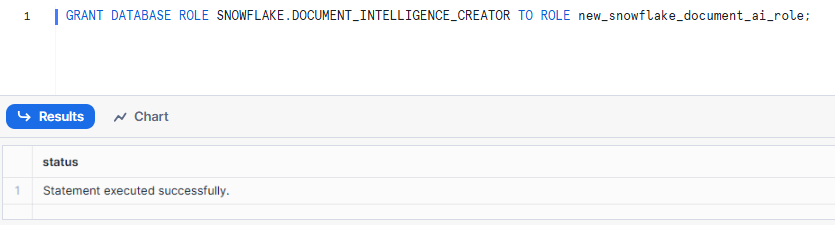
4) Grant the SNOWFLAKE.DOCUMENT_INTELLIGENCE_CREATOR database role to your custom role.
GRANT DATABASE ROLE SNOWFLAKE.DOCUMENT_INTELLIGENCE_CREATOR TO ROLE new_snowflake_document_ai_role;Syntax to grant Snowflake Role - Snowflake Document AI
5) Grant Warehouse Usage and Operating Privileges to the Custom Role
GRANT USAGE, OPERATE ON WAREHOUSE snowflake_document_ai_wh TO ROLE new_snowflake_document_ai_role;Syntax to Snowflake warehouse usage and operating privilege - Snowflake Document AI
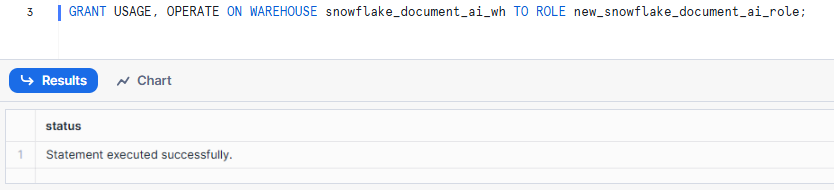
6) Allow the Custom Role to Use the Database and Schema
GRANT USAGE ON DATABASE demo_snowflake_document_ai_db TO ROLE new_snowflake_document_ai_role;
GRANT USAGE ON SCHEMA demo_snowflake_document_ai_db.demo_snowflake_document_ai_schema TO ROLE new_snowflake_document_ai_role;Syntax to grant Snowflake database and schema usage to specific role - Snowflake Document AI
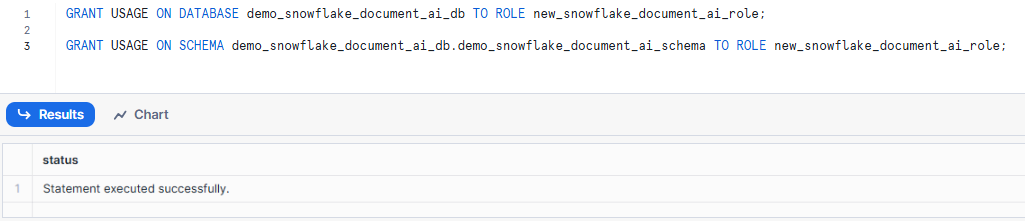
7) Allow the Custom Role to Create a Stage for Document Storage
GRANT CREATE STAGE ON SCHEMA demo_snowflake_document_ai_db.demo_snowflake_document_ai_schema TO ROLE new_snowflake_document_ai_role;Syntax to grant Snowflake stage to specific role - Snowflake Document AI
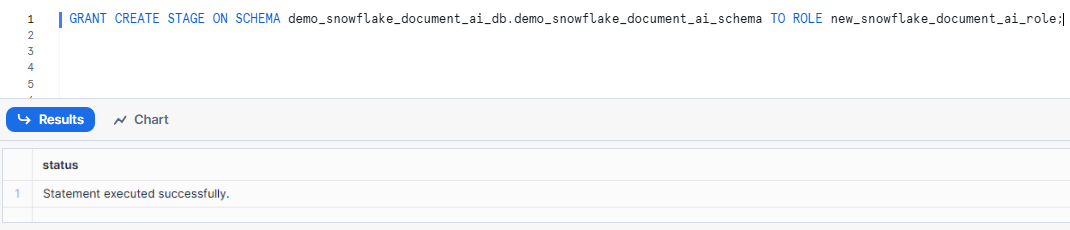
8) Make sure the Custom role can create model builds (instances of the DOCUMENT_INTELLIGENCE class):
GRANT CREATE SNOWFLAKE.ML.DOCUMENT_INTELLIGENCE ON SCHEMA demo_snowflake_document_ai_db.demo_snowflake_document_ai_schema TO ROLE new_snowflake_document_ai_role;Syntax to grant model building to specific role - Snowflake Document AI

9) Allow the custom role to create processing pipelines
GRANT CREATE STREAM, CREATE TABLE, CREATE TASK, CREATE VIEW ON SCHEMA demo_snowflake_document_ai_db.demo_snowflake_document_ai_schema TO ROLE new_snowflake_document_ai_role;
GRANT EXECUTE TASK ON ACCOUNT TO ROLE new_snowflake_document_ai_role;Syntax to grant Snowflake Stream, Snowflake Task to specific role - Snowflake Document AI

10) Grant the Custom Role to the User
GRANT ROLE snowflake_document_ai_role TO USER <your_username>;Syntax to grant Snowflake role to user - Snowflake Document AI

Step 2—Setting Up a New Snowflake Document AI Model Build
1) Sign In to Snowsight
Use an account role that has been granted the SNOWFLAKE.DOCUMENT_INTELLIGENCE_CREATOR role.
2) Navigate to Document AI
Go to the AI & ML section and select Document AI in Snowsight.
3) Initiate the Model Build
Select a warehouse and click on + Build.
4) Create the Model
Enter a name for your model, select the location (database and schema), and click Create.
Step 3—Defining Data Values and Reviewing Results
Now, head over to the Build Details section, and click on Upload documents.
Select Browse or drag and drop files to upload.
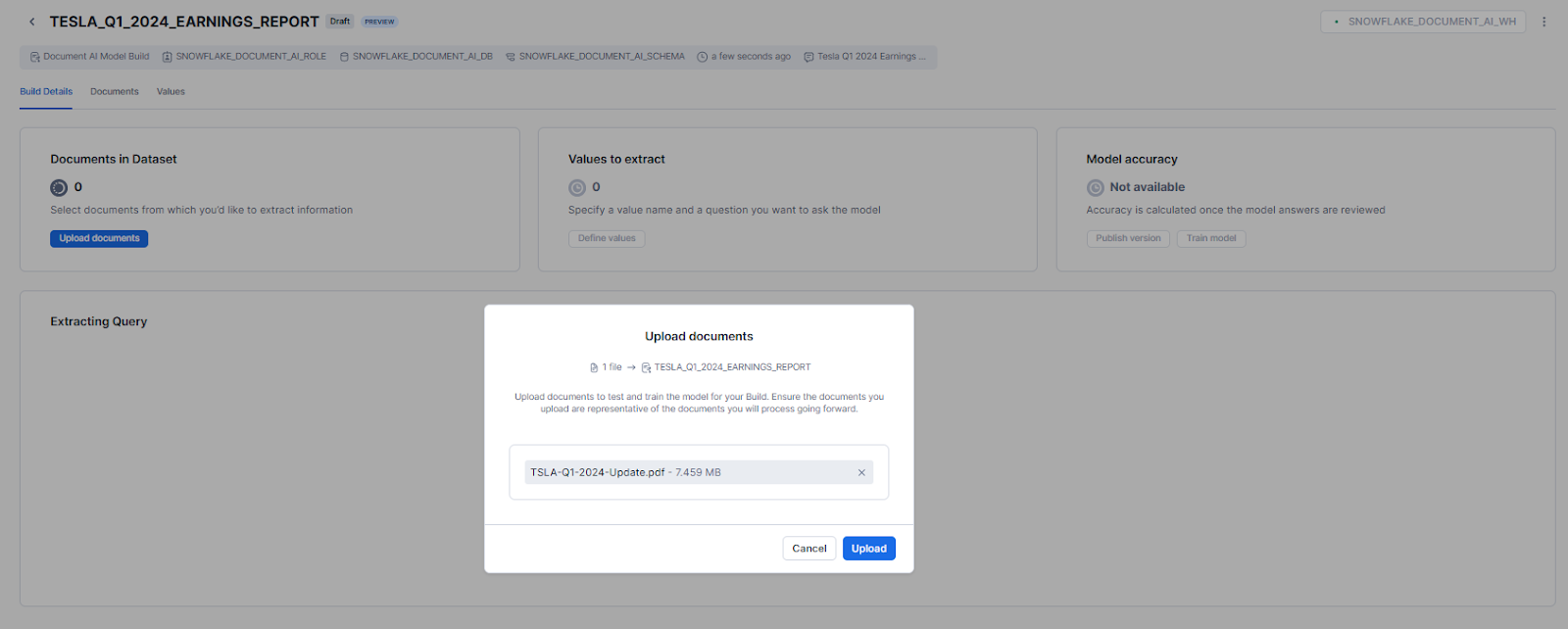
Now, define the specific data values or entities you want Snowflake Document AI to extract from your documents:
In the model build view, go to the "Build Details" tab and click on "Define values".
In the "Documents review" view, click on the "Add Value" button.
For each data value you want to extract, enter a value name and a question in natural language that represents the information you're seeking.
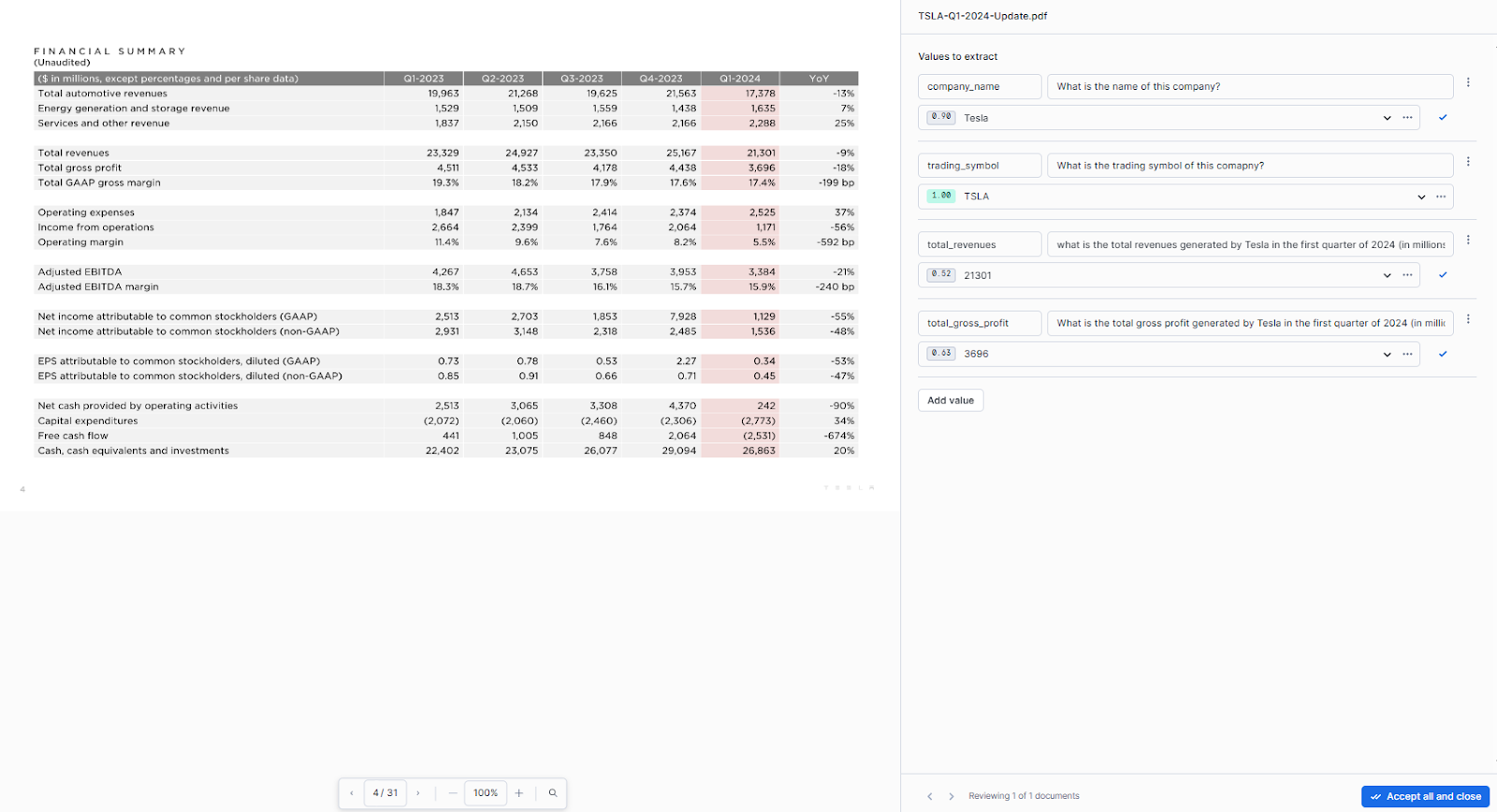
After defining the data values, Snowflake Document AI will provide answers based on its understanding of your documents. Carefully review these answers and take appropriate actions: if an answer is correct, select "Accept all and close"; if incorrect, manually enter the correct value. For multiple answers, review and remove any incorrect ones or add additional correct answers as needed. If no answer is provided but the document contains the information, manually enter the correct value.

Step 4—Publishing Snowflake Document AI Model Build
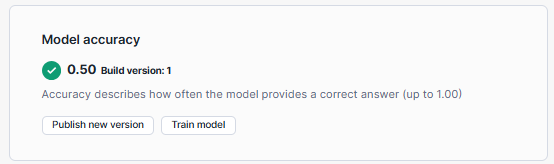
Once you're satisfied with the model's accuracy and results, you can publish the model build to make it available for use in production:
- Navigate to the "Build Details" tab.
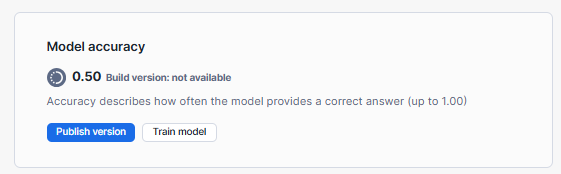
- Under "Model accuracy", select "Publish version".
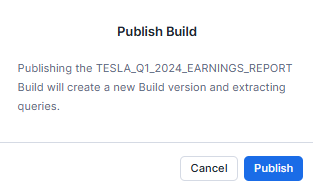
- Confirm the publishing process by selecting "Publish" in the dialog.
Step 5—Configuring Automated Document Processing Pipeline
Now that you have your model build published, you can set up an automated processing pipeline using Snowflake's streaming and task capabilities.
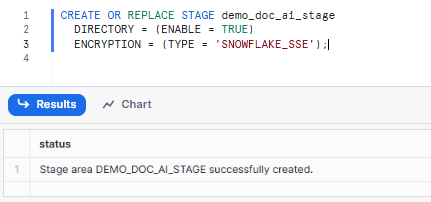
First, you need to create a Snowflake stage. You can either create a Snowflake external stage or a Snowflake internal stage. For the sake of this article, we will be creating an internal stage.
To create a Snowflake internal stage to store the documents you want to process, use the CREATE STAGE command.
CREATE OR REPLACE STAGE demo_doc_ai_stage
DIRECTORY = (ENABLE = TRUE)
ENCRYPTION = (TYPE = 'SNOWFLAKE_SSE');Syntax to create Snowflake Stage - Snowflake Internal Stage - Snowflake Document AI
Now that our stage is created, let's create a Snowflake stream on the Snowflake internal stage to monitor for new documents. To do this, use the CREATE STREAM command.
CREATE STREAM demo_doc_ai_stream ON STAGE demo_doc_ai_stage;Syntax to create Snowflake Stream - Snowflake Internal Stage - Snowflake Document AI
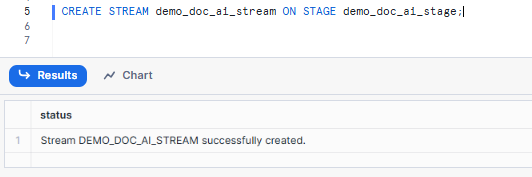
Now that you have created the Snowflake stream, refresh the metadata of the directory table to store the staged document files:
ALTER STAGE demo_doc_ai_stage REFRESH;Syntax to alter and refresh Snowflake Stage - Snowflake Internal Stage - Snowflake Document AI
Next, specify the database and schema:
USE DATABASE snowflake_document_ai_db;
USE SCHEMA snowflake_document_ai_schema;Syntax to select Database and Schema - Snowflake Internal Stage - Snowflake Document AI
Create a snowflake_doc_reviews table to store information about the documents. You can then create columns such as file_name, file_size, last_modified, snowflake_file_url, json_content , and any other data you want to extract from the PDF documents.
CREATE OR REPLACE TABLE snowflake_doc_reviews (
file_name VARCHAR,
file_size VARIANT,
last_modified VARCHAR,
snowflake_file_url VARCHAR,
json_content VARCHAR
);Syntax to create Snowflake Table - Snowflake Internal Stage - Snowflake Document AI
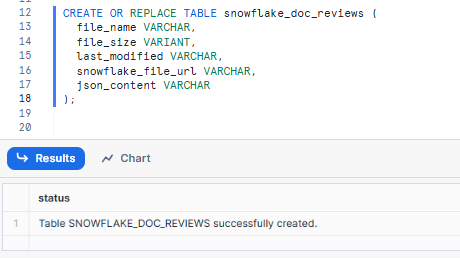
json_content column will include the extracted information in JSON format.
To process new documents in the stage, create a continuous_load_new_document task:
CREATE OR REPLACE TASK continuous_load_new_document
WAREHOUSE = snowflake_document_ai_wh
SCHEDULE = '1 minute'
COMMENT = 'Continuously load new docs on stage.'
WHEN SYSTEM$STREAM_HAS_DATA('demo_doc_ai_stream')
AS
INSERT INTO snowflake_doc_reviews (
SELECT
RELATIVE_PATH AS file_name,
size AS file_size,
last_modified,
file_url AS snowflake_file_url,
TESLA_Q1_2024_EARNINGS_REPORT!PREDICT(GET_PRESIGNED_URL('@demo_doc_ai_stage', RELATIVE_PATH), 1) AS json_content
FROM demo_doc_ai_stream
WHERE METADATA$ACTION = 'INSERT'
);Syntax to create Snowflake Task - Snowflake Internal Stage - Snowflake Document AI
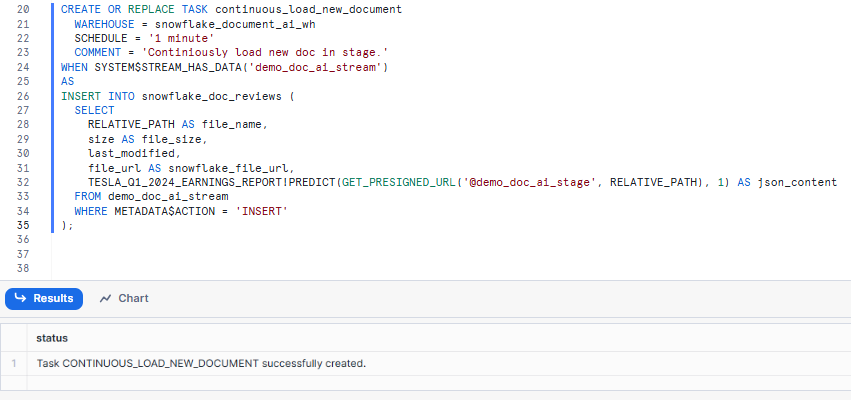
Newly created tasks are automatically suspended. So make sure to start the newly created task:
ALTER TASK continuous_load_new_document RESUME;Syntax to alter and resume Snowflake Task - Snowflake Internal Stage - Snowflake Document AI
Step 6—Upload New Documents to Snowflake Internal Stage
It is now time to upload the new documents you want to process to the Snowflake internal stage you created. You can do this through Snowsight.
To do so, first head over to the homepage of Snowsight, navigate to Data, and then to Databases.
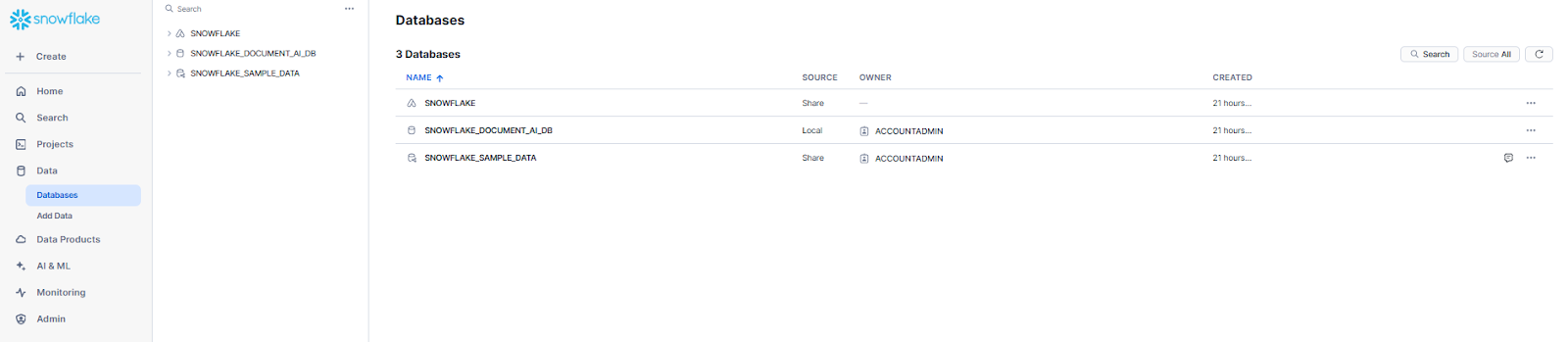
Then, select the snowflake_document_ai_db database, the snowflake_document_ai_schema, and the demo_doc_ai_stage stage.
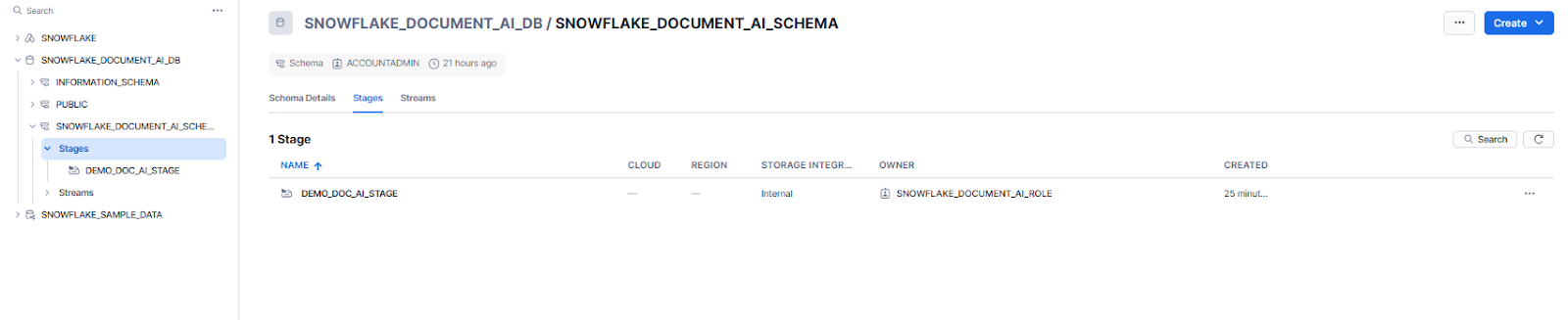
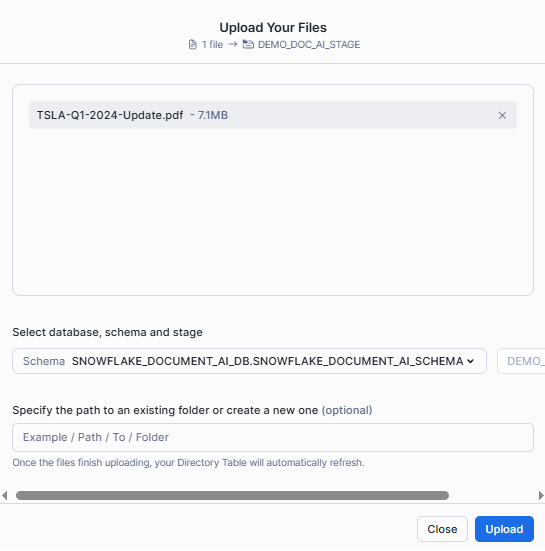
After that, click on the + Files button. In the "Upload Your Files" dialog that appears, select the pdf document and click Upload.

Step 7—View Extracted Unstructured Data Into Structured Format
If you select the data it will give you the data in unstructured format.
SELECT SNOWFLAKE_DOCUMENT_AI_DB.SNOWFLAKE_DOCUMENT_AI_SCHEMA.TESLA_Q1_2024_EARNINGS_REPORT!PREDICT(get_presigned_url('@demo_doc_ai_stage', RELATIVE_PATH ), 1) as json from directory(@demo_doc_ai_stage);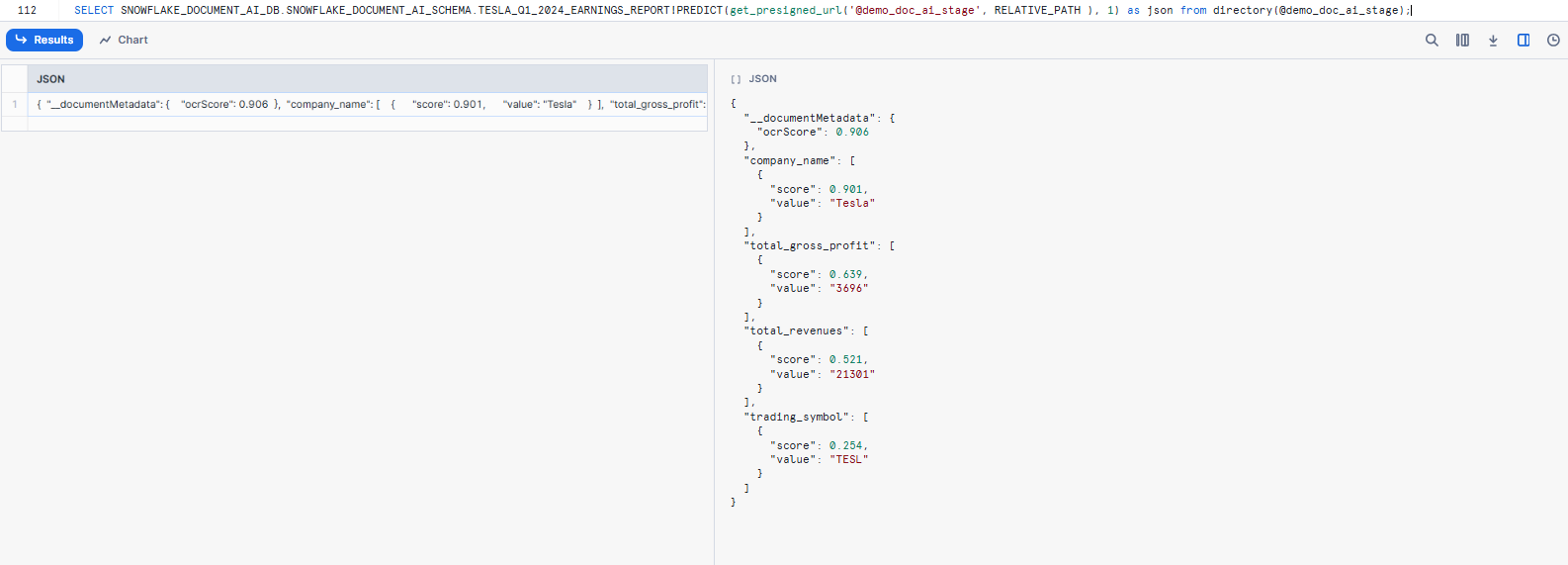
Now to structure the data into table format write the following SQL, this will create a table, snowflake_structured_data, that will contain the extracted values and the scores of the extractions. Execute the SQL, this will take a couple of minutes.
First—Create a table with all values
CREATE OR REPLACE TABLE snowflake_document_ai_db.snowflake_document_ai_schema.snowflake_structured_data AS (
WITH temp AS (
SELECT
Relative_path AS file_name,
size AS file_size,
last_modified,
file_url AS snowflake_file_url,
SNOWFLAKE_DOCUMENT_AI_DB.SNOWFLAKE_DOCUMENT_AI_SCHEMA.TESLA_Q1_2024_EARNINGS_REPORT!PREDICT(get_presigned_url('@demo_doc_ai_stage', RELATIVE_PATH), 1) AS json_content
FROM directory(@demo_doc_ai_stage)
)
SELECT
file_name,
file_size,
last_modified,
snowflake_file_url,
json_content:__documentMetadata.ocrScore::FLOAT AS ocrScore,
c.value:value::STRING AS company_name,
r.value:value::STRING AS total_revenues,
g.value:value::STRING AS total_gross_profit,
FROM temp,
LATERAL FLATTEN(INPUT => json_content:company_name) c,
LATERAL FLATTEN(INPUT => json_content:total_revenues) r,
LATERAL FLATTEN(INPUT => json_content:total_gross_profit) g,
GROUP BY ALL
);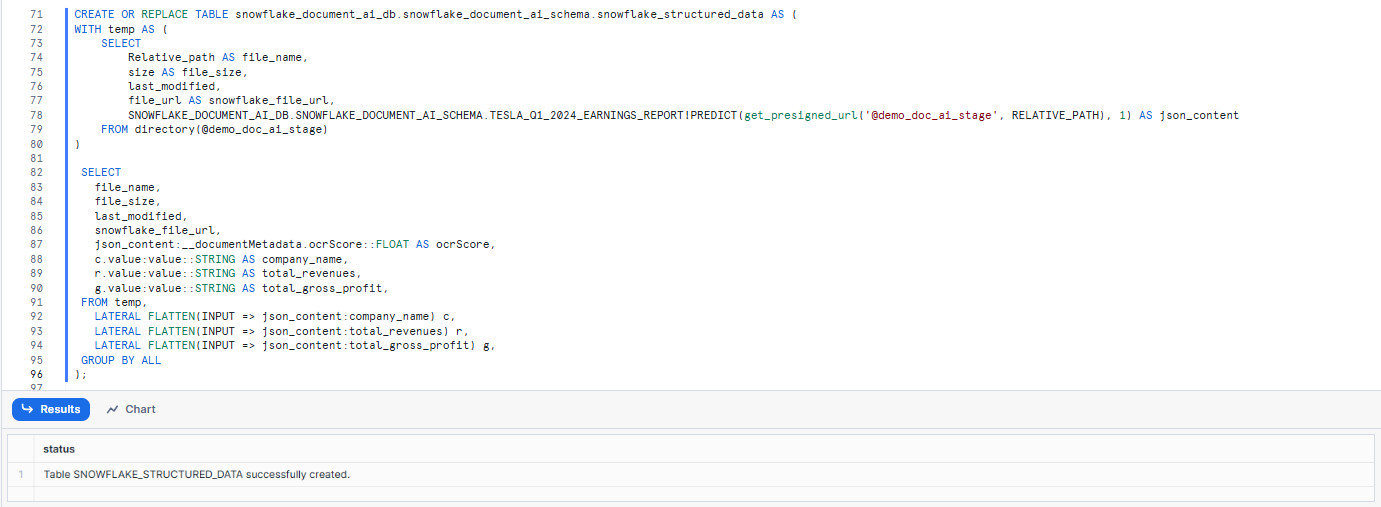
As you can see, first we create a table with all the values and then we extract the values as well as total ocr score from the JSON into columns. The table uses the FLATTEN function to parse the json_content JSON into separate columns for easier viewing.
Check that there is a result by running the following SQL:
SELECT * FROM snowflake_structured_data;
That's it! If you follow these steps, you can easily set up an automated document processing pipeline using Snowflake Document AI, streams, and tasks. This pipeline will continuously monitor the internal stage for new documents, process them using the published Document AI model build, and store the extracted information in a table for further analysis and integration with other data sources.
This automated approach streamlines the document processing workflow, eliminating the need for manual intervention and enabling efficient extraction of valuable insights from unstructured data sources.
What Are the Limitations of Document AI in Snowflake?
Here are some key limitations of Snowflake Document AI to be aware of:
Limitation 1: Language Support Restrictions
Currently, Snowflake Document AI only supports processing documents in English, Spanish, French, German, Portuguese, Italian, and Polish.
Limitation 2: Document Processing Volume Limits
There is a limit of processing a maximum of 1000 documents in a single query using Snowflake Document AI. If you need to process more documents at once, you will need to split them into multiple queries or use automated pipelines.
Limitation 3: Table Extraction Limitations
Snowflake Document AI does not support extracting data and populating an entire table in a single query. The extracted data is returned in a JSON format, which can then be parsed and inserted into a table using additional SQL statements or data processing steps.
Limitation 4: Role Inheritance Restrictions
Snowflake Document AI does not support privilege inheritance between roles, which means that if you have multiple roles with different privileges, you cannot inherit privileges from one role to another when working with Document AI.
Limitation 5: Concurrent Model Building Restrictions
Multiple users cannot work on the same Document AI model build simultaneously within the Snowsight web interface. Only one user at a time can make changes to a specific model build.
Limitation 6: Document Format and Size Restrictions
Snowflake Document AI supports a limited set of document formats (PDF, PNG, DOCX, EML, JPEG, JPG, HTM, HTML, TEXT, TXT, TIF, TIFF) and has size restrictions, such as a maximum file size of 50 MB and a maximum of 125 pages per document. Image dimensions must be between 50x50 px and 10000x10000 px.
Limitation 7: Regional Availability Restrictions
Snowflake Document AI is currently available in the following regions:
Amazon Web Services (AWS):
| Cloud region |
|---|
| US East (N. Virginia) |
| US East (Ohio) |
| US West (Oregon) |
| Canada (Central) |
| South America (Sao Paulo) |
| Europe (London) |
| EU (Stockholm) |
| EU (Ireland) |
| EU (Frankfurt) |
| Asia Pacific (Mumbai) |
| Asia Pacific (Tokyo) |
| Asia Pacific (Seoul) |
| Asia Pacific (Sydney) |
| Asia Pacific (Jakarta) |
Microsoft Azure:
| Cloud region |
|---|
| East US 2 (Virginia) |
| West US 2 (Washington) |
| South Central US (Texas) |
| Canada Central (Toronto) |
| UK South (London) |
| North Europe (Ireland) |
| West Europe (Netherlands) |
| Southeast Asia (Singapore) |
| UAE North (Dubai) |
| Australia East (New South Wales) |
| Central India (Pune) |
| Japan East (Tokyo) |
Google Cloud Platform (GCP):
| Cloud region |
|---|
| US East4 (N. Virginia) |
| Europe West2 (London) |
| Europe West3 (Frankfurt) |
| Europe West4 (Netherlands) |
Limitations aside, Snowflake Document AI is a strong tool that effectively extracts structured data from unstructured documents.
Save up to 30% on your Snowflake spend in a few minutes!


Conclusion
And that’s a wrap! Snowflake Document AI is a production-grade intelligent document processing feature that turns messy, unstructured documents into clean, queryable Snowflake data. You and your teams can now easily automate document processing and embed extracted data into operational workflows. It is powered by Snowflake’s Arctic-TILT model and is generally available to accounts in AWS, Microsoft Azure, and GCP commercial regions.
In this article, we have covered:
- What is Snowflake Document AI?
- What Is the Primary Use Case of Snowflake Document AI?
- How to Estimate Snowflake Document AI Costs?
- Understanding Document AI Costs
- Calculating Snowflake Document AI Credit Usage
- Step-By-Step Guide to Configure and Use Snowflake Document AI
- Step-By-Step Guide to Automate Document Processing via Document AI
- What Are the Limitations of Snowflake Document AI?
…and so much more!
FAQs
What is Snowflake Document AI?
Snowflake Document AI is a feature within the Snowflake Data Cloud that uses AI to extract and process data from various document formats.
What document formats are supported by Snowflake Document AI?
Supported formats include PDF, PNG, DOCX, EML, JPEG, JPG, HTM, HTML, TEXT, TXT, TIF, and TIFF.
Can I fine-tune the AI model in Snowflake Document AI?
Yes, you can fine-tune the Arctic-TILT model by training it on documents specific to your use case.
What is the primary use case of Snowflake Document AI?
The primary use case of Snowflake Document AI is turning unstructured data into structured data, automating document processing with continuous pipelines, and boosting seamless collaboration between business users and engineers.
What roles and privileges are required to use Snowflake Document AI?
Users need the SNOWFLAKE.DOCUMENT_INTELLIGENCE_CREATOR database role, privileges to create warehouses, databases, schemas, stages, and model builds, and permissions to create streams, tables, tasks, and views.
What are the document size and page limitations for Snowflake Document AI?
Documents must be no more than 125 pages long, 50 MB or less in size, and with page dimensions of 1200 x 1200 mm or less. Images must be between 50 x 50 and 10000 x 10000 pixels.
How is the Snowflake Document AI model built and trained?
Users upload sample documents, define data values to extract, review and evaluate model results, and optionally fine-tune the model through training before publishing it for use.
How is information extracted using a published Snowflake Document AI model?
The <model_build_name>!PREDICT query is used to extract information from staged documents based on the published model.
What are the language limitations of Snowflake Document AI?
Currently, Snowflake Document AI only supports processing documents in English, Spanish, French, German, Portuguese, Italian, and Polish.
What is the maximum number of documents that can be processed in a single query?
The limit is 1000 documents in a single query using Snowflake Document AI. For more documents, multiple queries are required.
Can Snowflake Document AI extract data and populate an entire table in a single query?
No, Snowflake Document AI does not support extracting data and populating an entire table in a single query. The extracted data is returned in JSON format and must be parsed and inserted into a table using additional SQL statements or data processing steps.
Does Snowflake Document AI support role inheritance?
No, Snowflake Document AI does not support privilege inheritance between roles.
Can multiple users work on the same Document AI model build simultaneously?
No, only one user at a time can make changes to a specific model build within the Snowsight web interface.
How is Snowflake Document AI integrated with Snowpark?
Snowflake Document AI integrates seamlessly with Snowpark, allowing developers to build applications that leverage Document AI's functionalities using familiar languages like Java, Scala, and Python.
What is the no-code/low-code nature of Snowflake Document AI?
Snowflake Document AI's user-friendly interface requires no coding or machine learning expertise. Business users can interact with the model through natural language queries, making it accessible to non-technical stakeholders.















