




























Snowflake zero copy clone feature allows users to quickly generate an identical clone of an existing database, table, or schema without copying the entire data, leading to significant savings in Snowflake storage costs and performance. The best part? You can do it all with just one simple command—the CLONE command. Gone are the days of copying complete structures, metadata, primary keys, and schemas to create a copy of your database or table.
In our previous article, we covered the basics of what is zero copy cloning in Snowflake. Now, in this article, we will dive into practical steps on how to set up databases, tables, and schemas, as well as insert dummy data for cloning purposes—and a lot more. Read on to find out more about how to create a Snowflake clone table using Snowflake zero copy clone!
So, let's get started!
How to Clone Table in Snowflake Using Zero Copy Clone?
Without further ado, let's get right to the juice of the article.
So to get started on cloning an object using Snowflake zero copy clone, you can use the following simple SQL statement:
CREATE <object_type> <object_name>
CLONE <source_object_name>This particular statement is in short form. It will create a brand-new object by cloning an existing one. Now, let's explore its complete syntax.
CREATE [ OR REPLACE ] { STAGE | FILE FORMAT | SEQUENCE | STREAM | TASK } [ IF NOT EXISTS ] <object_name>
CLONE <source_object_name>Creating a Sample Table
Let's explore a real-world scenario by creating a database, schema, and table. First, we'll create a database named "my_db", a schema named "RAW" in that database, and a table named "my_table" inside that particular "RAW" schema. The table will have three columns: "id" of type integer, "name" of type varchar with a max length of 50 char, and "age" of type integer. Here's the SQL query:
CREATE OR REPLACE DATABASE my_db;
CREATE OR REPLACE SCHEMA my_db.RAW;
CREATE OR REPLACE TABLE my_db.RAW.my_table (
id INT,
name VARCHAR(50),
age INT
);Next, we'll insert 300 randomly generated rows into the table:
INSERT INTO my_db.RAW.my_table (id, name, age)
SELECT
seq4(),
CONCAT('Some_Name', seq4()),
FLOOR(RANDOM() * 100) + 1
FROM TABLE(GENERATOR(ROWCOUNT => 300));Finally, we'll select the entire table:
SELECT COUNT(*) FROM my_db.RAW.my_table;Your final query should resemble something like this.
CREATE OR REPLACE DATABASE my_db;
CREATE OR REPLACE SCHEMA my_db.RAW;
CREATE OR REPLACE TABLE my_db.RAW.my_table (
id INT,
name VARCHAR(50),
age INT
);
INSERT INTO my_db.RAW.my_table (id, name, age)
SELECT
seq4(),
CONCAT('Some_Name', seq4()),
FLOOR(RANDOM() * 100) + 1
FROM TABLE(GENERATOR(ROWCOUNT => 300));
SELECT COUNT(*) FROM my_db.RAW.my_table;
Cloning the Sample Table
Now that we have our table, let's create a snowflake clone table of MY_DB.RAW.MY_TABLE and name it as MY_DB.RAW.MY_TABLE_CLONE.
CREATE TABLE my_db.RAW.my_table_clone
CLONE my_db.RAW.my_table;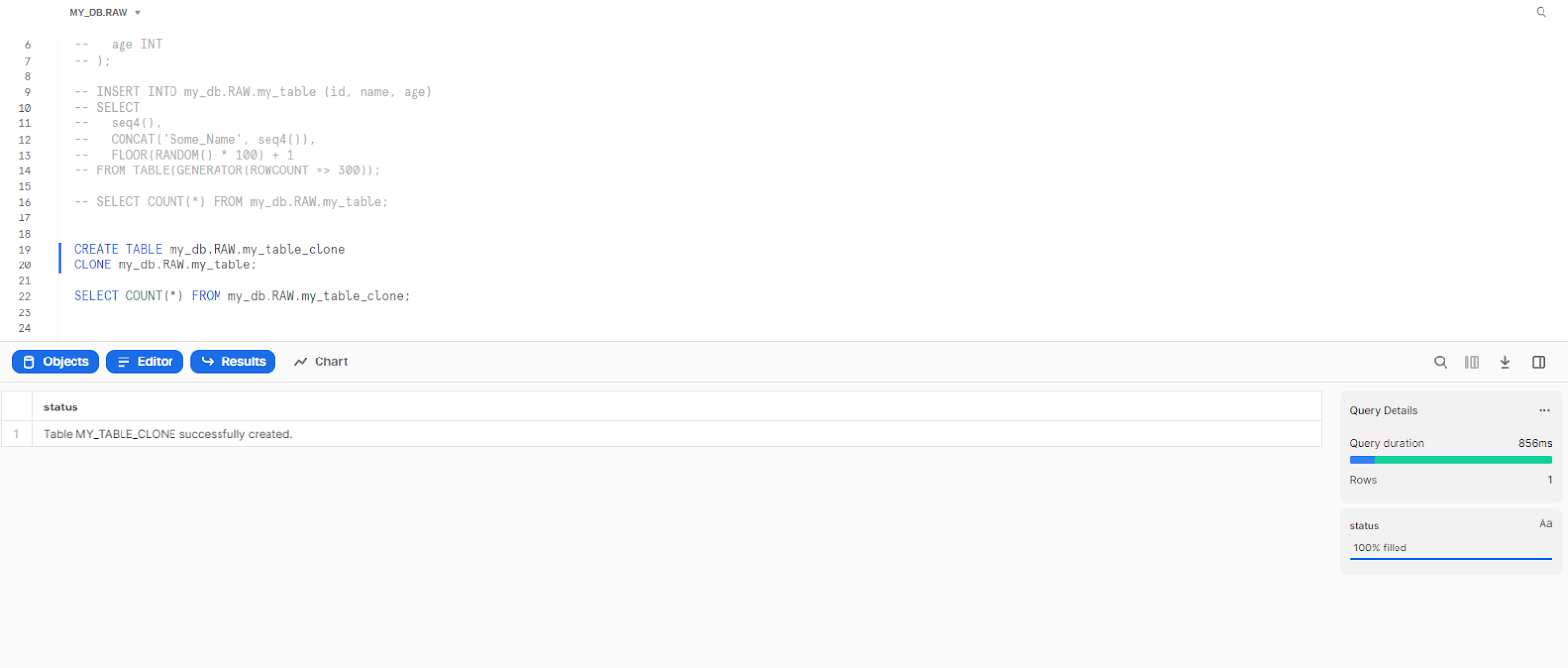
Finally, let's select the entire cloned table:
SELECT COUNT(*) FROM my_db.RAW.my_table_clone;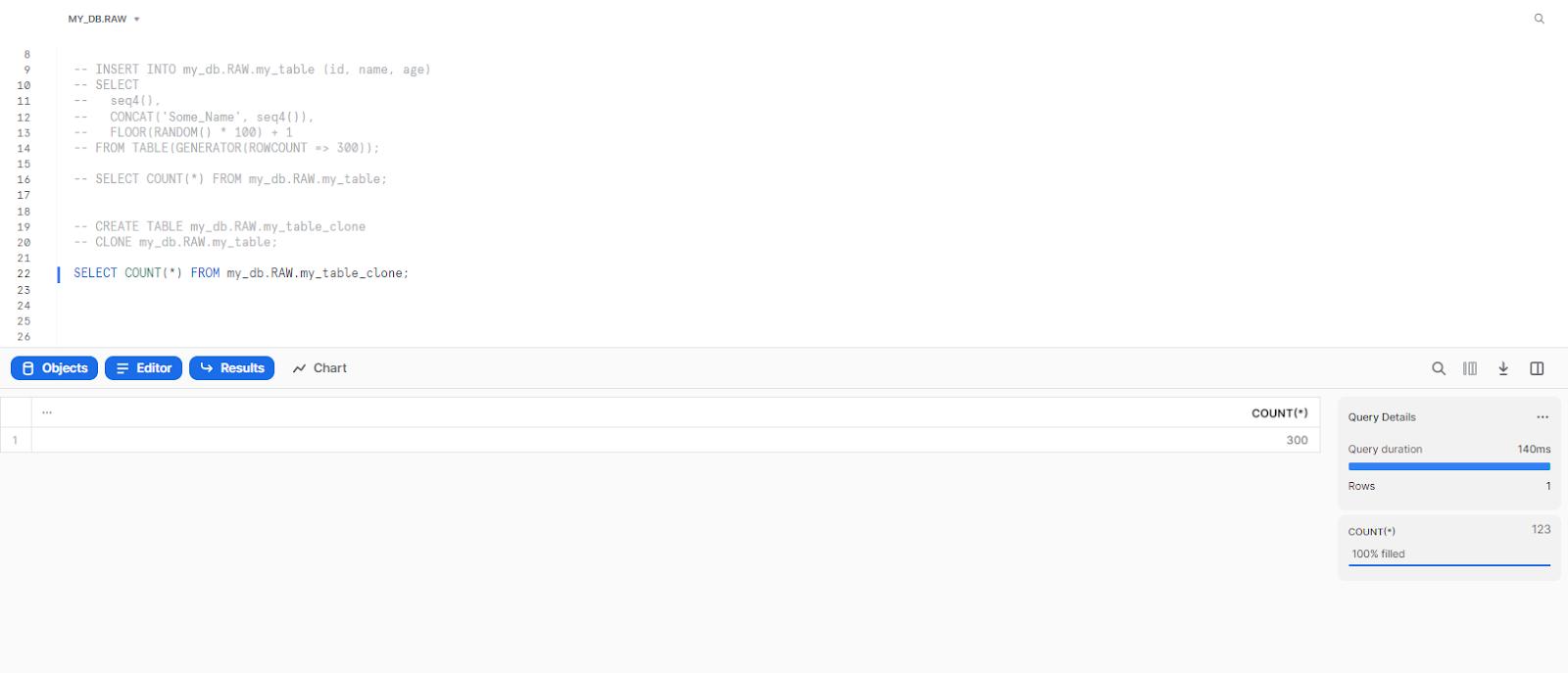
As you can see in the screenshot above, the count of MY_DB.RAW.MY_TABLE_CLONE matches the count of our main table, meaning that we have successfully created a snowflake clone table of the MY_DB.RAW.MY_TABLE table. But both of these tables are accessing the same storage since the data is the same in the original and cloned tables.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Understanding Table-Level Storage
If you require more comprehensive information on table-level storage, you can obtain it by executing the following query against the information schema view.
Note: Accessing this view requires the use of an ACCOUNTADMIN role.
USE ROLE ACCOUNTADMIN;
SELECT TABLE_NAME,
ID,
CLONE_GROUP_ID
FROM MY_DB.INFORMATION_SCHEMA.TABLE_STORAGE_METRICS
WHERE TABLE_CATALOG = 'MY_DB'
AND TABLE_SCHEMA = 'RAW'
AND TABLE_DROPPED IS NULL
AND CATALOG_DROPPED IS NULL
AND TABLE_NAME IN ('MY_TABLE', 'MY_TABLE_CLONE');
This particular query retrieves information about the storage of the tables in the MY_DB.RAW schema. The query result contains the table names, unique table IDs, and CLONE_GROUP_IDs. Each table has a unique identifier represented by the ID column, while the clone group ID is a unique identifier assigned to groups of tables that have identical data. In this scenario, MY_TABLE and MY_TABLE_CLONE have the same clone group ID, indicating that they share the same data.
Note: Although MY_TABLE and MY_TABLE_CLONE share the same data, they are still separate tables. Any sort of changes made to one table will not affect the other one.
For more on Zero Copy Cloning in Snowflake, check out this video that shows how to test and experiment with your data without actually copying it.
Snowflake Zero Copy Clone
That's it! Congrats, with just a few simple steps, you have successfully created a Snowflake clone table using zero copy clone.
Save up to 30% on your Snowflake spend in a few minutes!


Conclusion
Snowflake zero copy clone feature is a powerful feature that enables users to efficiently generate identical clones of their existing databases, tables, and schemas without duplicating the data or creating separate environments. This article provided practical steps for setting up databases, tables, and schemas, inserting dummy data, and cloning data from scratch. We hope this article was informative and helpful in exploring the potential of the Snowflake zero copy clone feature to create a Snowflake clone table.
Interested in learning more about Snowflake zero copy clone? Be sure to check out our previous article, where we provided an in-depth overview of its inner workings, potential use cases, limitations, key features, benefits—and more!!
FAQs
Can the cloned table be modified independently from the original table?
Yes, the cloned table is a separate table, and changes made to one table will not affect the other.
Can we clone temporary tables in Snowflake?
No, cloning is not supported for temporary tables in Snowflake because the data in temporary tables is automatically deleted at the end of the session.















