





























Let’s say you’ve got a massive CSV file loaded into Databricks, packed with data ready for analysis. But as you dig in, you notice something’s off—tucked between the rows are bits of information that could throw a wrench in your analysis. Maybe it’s test data, metadata, duplicate headers, corrupted lines, or even empty rows. Handling such scenarios is an essential part of data preprocessing, and skipping irrelevant rows becomes a crucial step in maintaining data integrity.
In this article, we'll cover four practical techniques to skip rows when reading CSV files in Databricks. Each technique uses a different tool or API—PySpark, Spark SQL, RDDs, and Pandas—so you can choose the best approach for your specific use case.
Let's dive right in!
☣️The Issue: Why Skip Rows When Reading CSV Files?
When you handle CSV files in Databricks, skipping rows is often necessary to clean your data before analysis. Here's why:
➥ Metadata and Extra Headers — Some CSV files may include metadata or multiple header rows at the beginning that do not contain actual data. These rows are often descriptive and should be skipped to avoid confusion and errors in data interpretation.
➥ Test Data — Sometimes, CSV files might contain test data or examples that were included during data validation or development phases. These rows skew your results if included in your analysis.
➥ Comments or Notes — Occasionally, CSV files may contain rows that serve as comments or notes about the data. These rows are not part of the actual dataset and should be excluded to prevent misinterpretation.
➥ Corrupt or Incomplete Entries — Data corruption or partial records can introduce noise or errors into your dataset. Skipping these rows prevents your analysis from being compromised by inaccurate or incomplete data.
➥ Irrelevant Data — CSV files may sometimes include data that is irrelevant to your current analysis or project scope. Excluding these rows keeps your analysis focused and efficient.
If you skip these rows, you can maintain the integrity and relevance of your data, making your analysis in Databricks more accurate and effective.
To solve this issue, you can skip unnecessary rows when reading CSV files in Databricks.
Let's dive into the next section, where we will explore four techniques you can use to skip rows when reading CSV files in Databricks. Without further ado, let's get right into it!
Save up to 50% on your Databricks spend in a few minutes!


💡 The Solution: Skip Rows When Reading CSV Files in Databricks
There are four techniques you can use to skip rows when reading CSV files in Databricks:
- Technique 1—Skip Rows When Reading CSV Files in Databricks Using PySpark
- Technique 2—Skip Rows When Reading CSV Files in Databricks Using Spark SQL’s read_files function
- Technique 3—Skip Rows When Reading CSV Files in Databricks Using RDD transformations
- Technique 4—Skip Rows When Reading CSV Files in Databricks Using Pandas
Let’s dive deeper into these techniques and understand their use cases and implementation details.
Prerequisite:
- Access to a Databricks Workspace
- Necessary permissions for accessing Databricks DBFS paths
- Familiarity with Apache Spark concepts
- Basic understanding of:
- PySpark and Spark DataFrame API
- SQL (for SQL-based approaches)
- Python (for pandas-based approaches)
- Configured and running Databricks compute cluster
Before diving into these techniques, we need a CSV file for demo purposes. For this example, we’ll create a simple dataset with ~16 rows, including a header, to help you clearly understand the process. Here’s the dataset we’ll use:
| Name | Age | City | |
| Elon Musk | 53 | Austin | [email protected] |
| Jeff Bezos | 60 | Medina | [email protected] |
| Bernard Arnault | 75 | Paris | [email protected] |
| Mark Zuckerberg | 40 | Palo Alto | [email protected] |
| Larry Ellison | 79 | Lanai | [email protected] |
| Warren Buffett | 93 | Omaha | [email protected] |
| Bill Gates | 68 | Medina | [email protected] |
| Larry Page | 51 | Palo Alto | [email protected] |
| Sergey Brin | 50 | Los Altos | [email protected] |
| Mukesh Ambani | 67 | Mumbai | [email protected] |
| Steve Ballmer | 68 | Hunts Point | [email protected] |
| Francoise Bettencourt Meyers | 71 | Paris | [email protected] |
| Carlos Slim Helu | 84 | Mexico City | [email protected] |
| Amancio Ortega | 88 | La Coruña | [email protected] |
| Michael Bloomberg | 82 | New York | [email protected] |
After creating this file, upload it to Databricks DBFS. If you’re unfamiliar with the upload process, you can refer to this article: Step-by-Step Guide to Upload Files to Databricks DBFS.
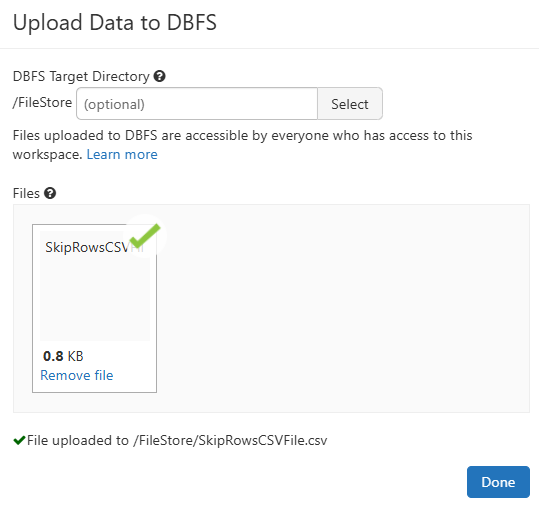
After uploading the file to Databricks DBFS, it’s important to verify whether the data was successfully uploaded. You can do this by executing the following command:
df = spark.read.csv("dbfs:/FileStore/SkipRowsCSVFile.csv")
display(df)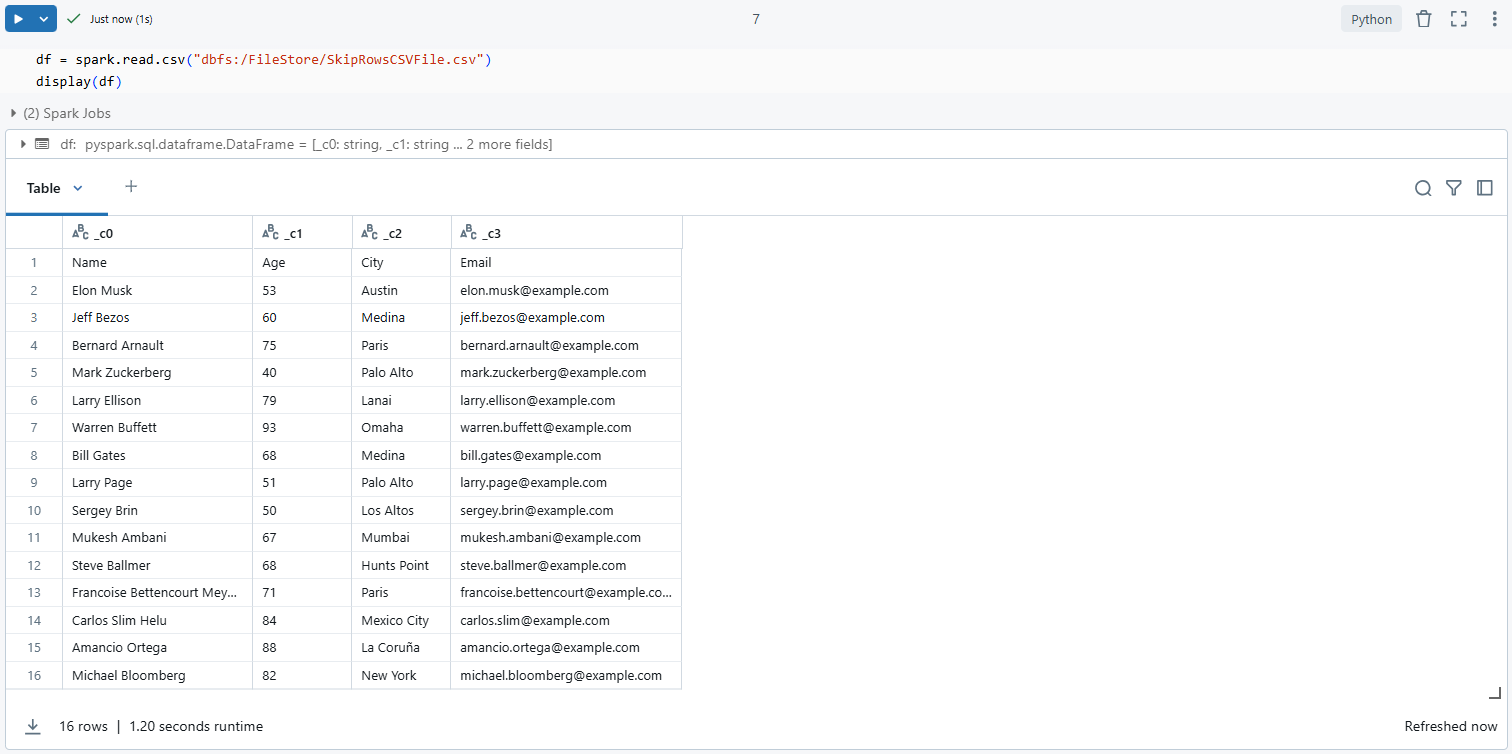
As you can see, this will load the CSV file into a DataFrame and display its contents. If the file was uploaded correctly, you should see 16 rows (15 data rows plus the header) in the output, confirming that the file has been successfully uploaded.
Now you’re ready to proceed with the following techniques described in this article. Let’s dive in!
🔮 Technique 1—Skip Rows When Reading CSV Files in Databricks Using PySpark read.csv with skipRows Option (Recommended)
Let’s explore the first of the four techniques: using PySpark’s read.csv method with the option("skipRows") to skip rows when reading CSV files in Databricks. This approach is highly recommended due to its efficiency and seamless integration with PySpark’s DataFrame API, making it ideal for processing large datasets.
Step 1—Configure Databricks Environment
First, make sure your Databricks environment is set up. You need access to a Databricks Workspace where you can manage your data.
Step 2—Set Up Databricks Compute Cluster
Launch a cluster in Databricks with the necessary configurations. Choose an appropriate runtime version that supports Spark 3.1.0 or later, as the skipRows option is only available in these versions.
Step 3—Open Databricks Notebook
Create or open a Databricks Notebook where you will write and execute your PySpark code. This will serve as your workspace for running the required commands.

Step 4—Attach Databricks Compute to Notebook
Select the Databricks compute cluster you prepared to attach to your notebook. This links your code execution to the cluster's resources.
Step 5—Import PySpark Library
Let's start coding. First, import the necessary PySpark modules. At a minimum, you’ll need SparkSession to create and manage your Spark application:
from pyspark.sql import SparkSessionStep 6—Initialize Spark Session
Create a Spark session, which serves as the entry point for using PySpark functionalities:
spark = SparkSession.builder.appName("CSVRowSkipping").getOrCreate()Step 7—Use Spark header option or Spark skipRows option for skipping rows
Use the spark.read.csv method to read the CSV file while applying options to skip unnecessary rows:
header: Set this to "true" if your CSV file includes a header row.skipRows: Specify the number of rows to skip at the beginning of the file. This feature was introduced in Spark 3.1.0.
rows_to_skip = 3
dbfsPath = "dbfs:/FileStore/SkipRowsCSVFile.csv"
pysparkdf = spark.read.format("csv") \
.option("header", "true") \ # Treat the first row as headers
.option("skipRows", rows_to_skip) \ # Skip the specified number of rows
.load(dbfsPath)Note: If your Spark version is older than 3.1.0, the skipRows option will not be available. In such cases, consider alternative methods, such as filtering the rows after reading the data.
Step 8—Validate and Display Data
Finally, verify that the rows were skipped correctly by displaying a sample of the DataFrame:
pysparkdf.display();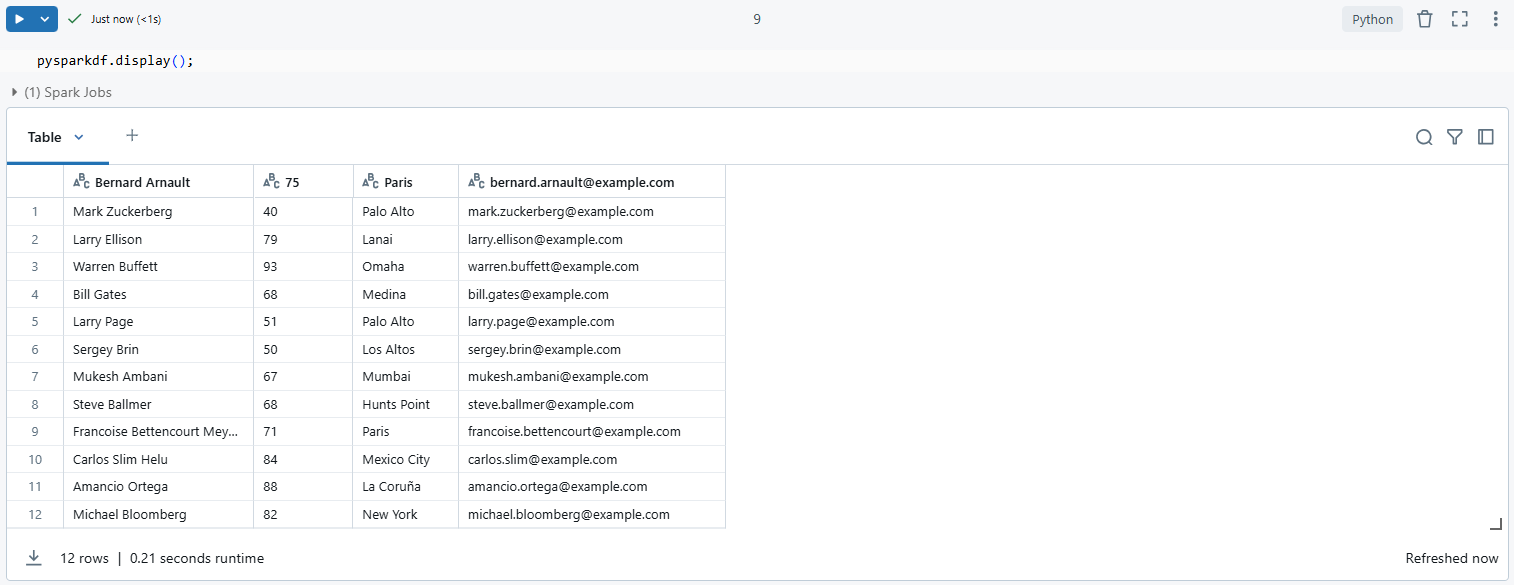
This technique is efficient for handling structured CSV files, especially when you know the exact number of rows to skip. PySpark’s flexibility makes it an excellent choice for preprocessing large datasets in Databricks.
🔮 Technique 2—Skip Rows When Reading CSV Files in Databricks Using Spark SQL's read_files Function with skipRows
In the previous section, we used PySpark to skip rows in a CSV file. Now, let’s move to another technique—using Spark SQL. Spark SQL is particularly useful if you prefer working with SQL queries or need to integrate row-skipping logic directly into your SQL-based workflows. Here in this technique, we will make use of Databricks' temporary views, providing a structured way to preprocess your data.
Step 1—Open Databricks Notebook
Start by opening a new or existing Databricks Notebook.
Step 2—Attach Databricks Compute to Databricks Notebook
Attach the notebook to an active Databricks compute cluster. The cluster should have Spark 3.1.0 or later installed to support the skipRows option in read_files. If your cluster is running an earlier version, you can use a workaround, as explained below.
Step 3—Initialize Spark Session
You don’t need additional imports for Spark SQL, but it’s good practice to initialize or verify your Spark session. This guarantees you can run both SQL and PySpark commands seamlessly in the notebook:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("CSVRowSkippingSQL").getOrCreate()Step 4—Write SQL Query to Skip Rows When Reading CSV File
Here, you have two approaches:
Option 1—Using a Temporary View with ROW_NUMBER()`
If your Databricks version doesn’t support the skipRows option in read_files, you can create a temporary view and use the ROW_NUMBER() function to filter out unwanted rows:
%sql
CREATE OR REPLACE TEMPORARY VIEW csv_row_skip_databricks AS
SELECT *
FROM (
SELECT *, ROW_NUMBER() OVER (ORDER BY 1) AS row_num
FROM csv.`dbfs:/FileStore/SkipRowsCSVFile.csv`
)
WHERE row_num > 5;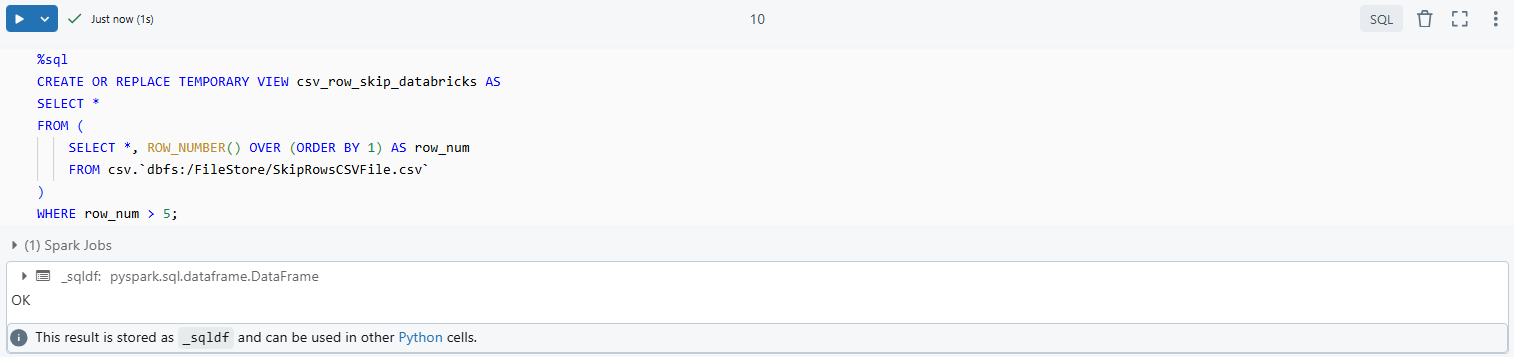
ROW_NUMBER(): Assigns a unique number to each row in the dataset, starting from 1.WHERE row_num > 5: Filters out the first five rows, skipping them during query execution.
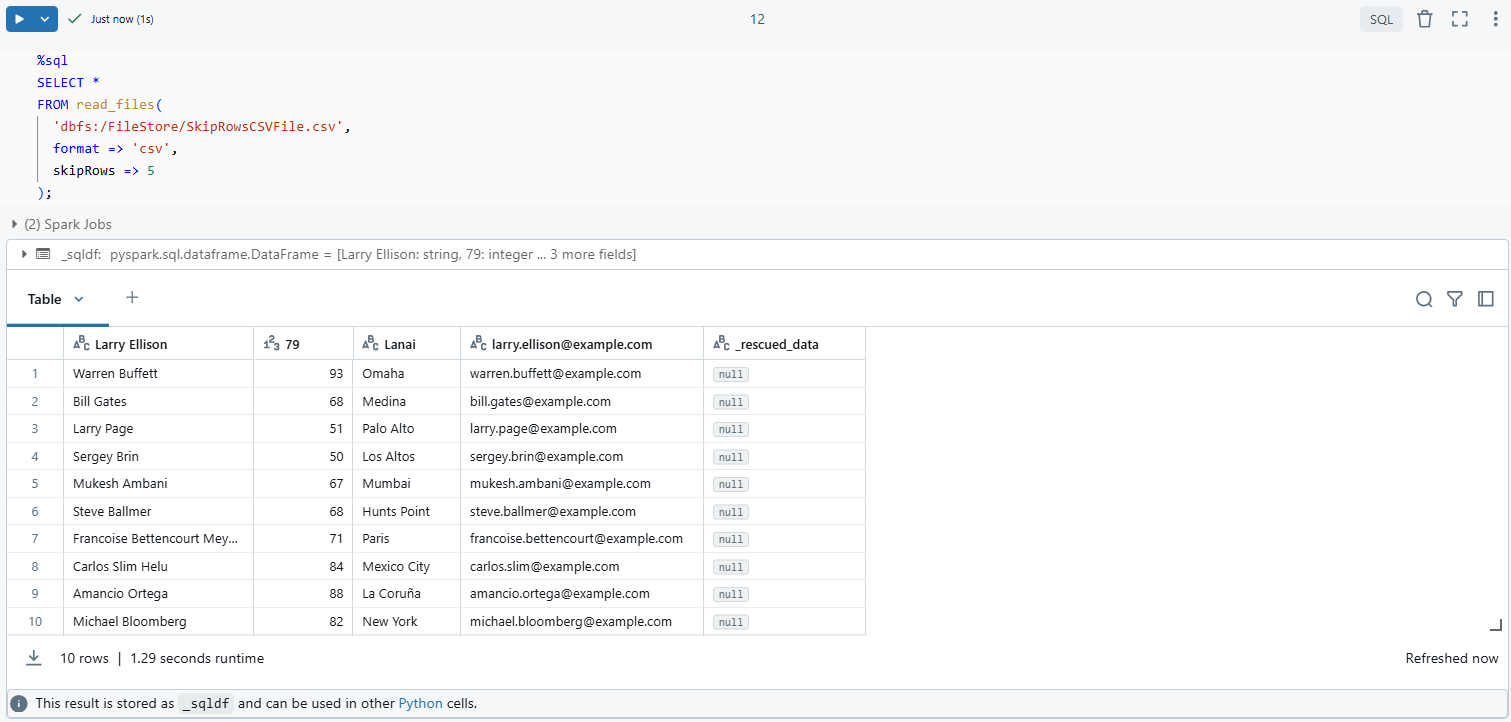
Option 2—Using the read_files Function
If your Databricks Runtime supports it (available from Databricks Runtime 13.3 LTS and above), you can use read_files function:
%sql
SELECT *
FROM read_files(
'dbfs:/FileStore/SkipRowsCSVFile.csv',
format => 'csv',
skipRows => 5
);
Step 5—Query the Databricks Temporary View
Once you’ve created the temporary view, you can query it like any standard SQL table to access the preprocessed data:
%sql
SELECT * FROM csv_row_skip_databricks;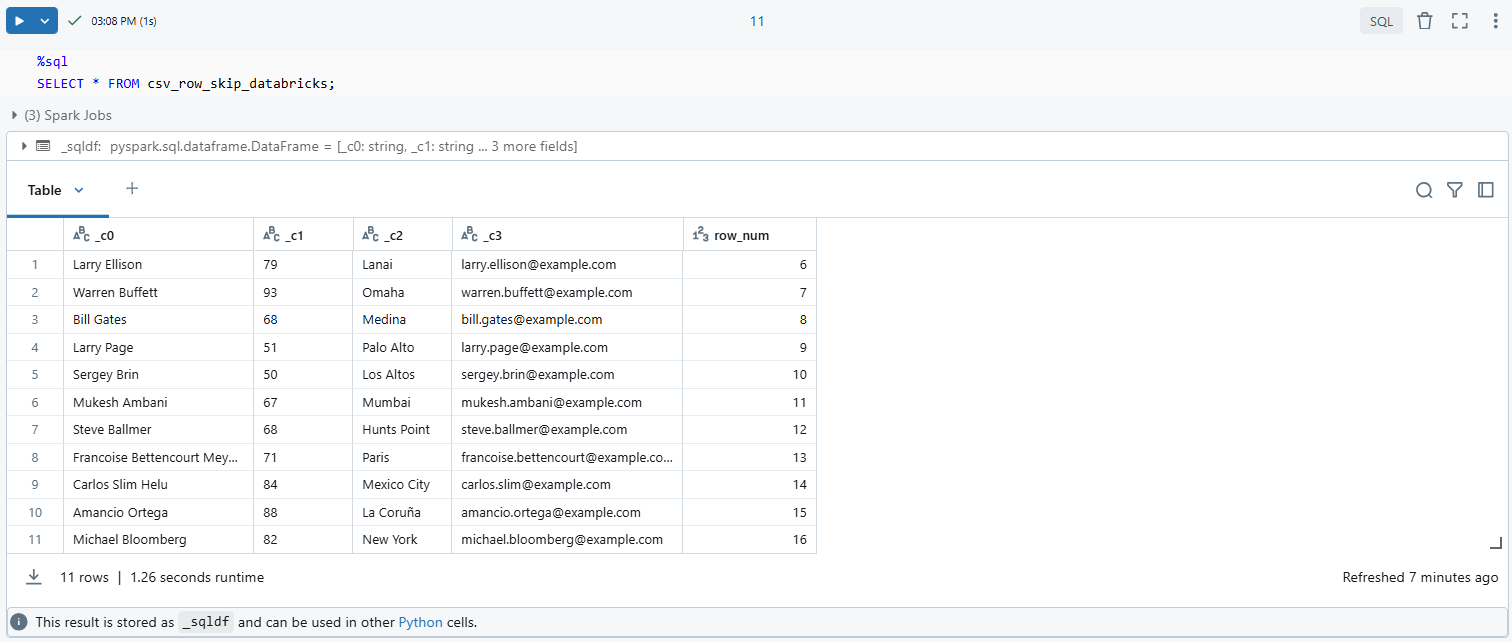
Step 6—Validate and Display Data
After querying the temporary view, visually inspect the output in the notebook to confirm the row-skipping worked as expected. You can also apply additional transformations or aggregations to ensure the dataset meets your requirements.
Step 7—Dropping the Databricks Temporary View
It’s good practice to clean up temporary views when you’re done, especially in collaborative environments where multiple users might interact with shared resources:
DROP VIEW IF EXISTS csv_row_skip_databricks;
This technique leverages Spark SQL's capabilities, offering a different approach to data preprocessing in Databricks. It's particularly handy if you're more comfortable with SQL or if your data processing pipeline benefits from SQL's declarative nature. Remember, the availability of skipRows in read_files depends on your Databricks runtime version, so always check your environment's capabilities.
🔮 Technique 3—Skip Rows When Reading CSV Files in Databricks Using RDD Transformations (Less Recommended)
Previously, we explored skipping rows using PySpark and Spark SQL. Now, let’s look at an alternative method—using RDD transformations. While RDDs are foundational to Spark, this method is less commonly recommended for most Databricks workflows due to its verbosity and lower efficiency compared to DataFrame APIs. But understanding it can be useful for scenarios requiring custom transformations at the RDD level.
Assuming you've already configured your Databricks environment, set up your compute cluster, opened your notebook, and attached your compute to the notebook, here's how you can proceed with this technique:
Step 1—Import PySpark
Start by importing the necessary PySpark libraries to work with RDDs:
from pyspark import SparkContext
Step 2—Initialize Spark Context
Spark context (sc) is the entry point for working with RDDs. Initialize or retrieve an existing context:
sc = SparkContext.getOrCreate()
Step 3—Read CSV as RDD
Use the textFile() method to load your CSV file as an RDD. This method reads the file line by line, making each line an element of the RDD:
rdd = sc.textFile('dbfs:/FileStore/SkipRowsCSVFile.csv')
Step 4—Skip Rows with RDD Operations
To skip specific rows, you can use the zipWithIndex() method to attach an index to each row and then filter out rows based on their index. For example, to skip the first five rows:
number_of_rows_to_skip = 5 # Skip first 5 rows
filtered_rdd = rdd.zipWithIndex().filter(lambda x: x[1] >= number_of_rows_to_skip).map(lambda x: x[0])
Here:
zipWithIndex(): Assigns a unique index to each row in the RDD.filter(): Removes rows where the index is less than or equal to 5 (skipping the first five rows).map(): Extracts the original row content after filtering.
Step 5—Convert RDD Back to DataFrame
Once you’ve filtered the RDD, you’ll need to convert it back into a DataFrame for further processing. Use the spark.read.csv() method to create a DataFrame:
from pyspark.sql import Row
# Split rows into columns
row_rdd = filtered_rdd.map(lambda line: line.split(","))
# Convert to DataFrame
convertdf = row_rdd.map(lambda row: Row(*row)).toDF()
Or
If your RDD transformations retain the original CSV format, you can directly pass the filtered RDD to spark.read.csv():
newdf = spark.read.csv(filtered_rdd)
Step 6—Validate and Display Data
Finally, inspect the DataFrame to verify that the unwanted rows were successfully skipped:
convertdf.display();
newdf.display();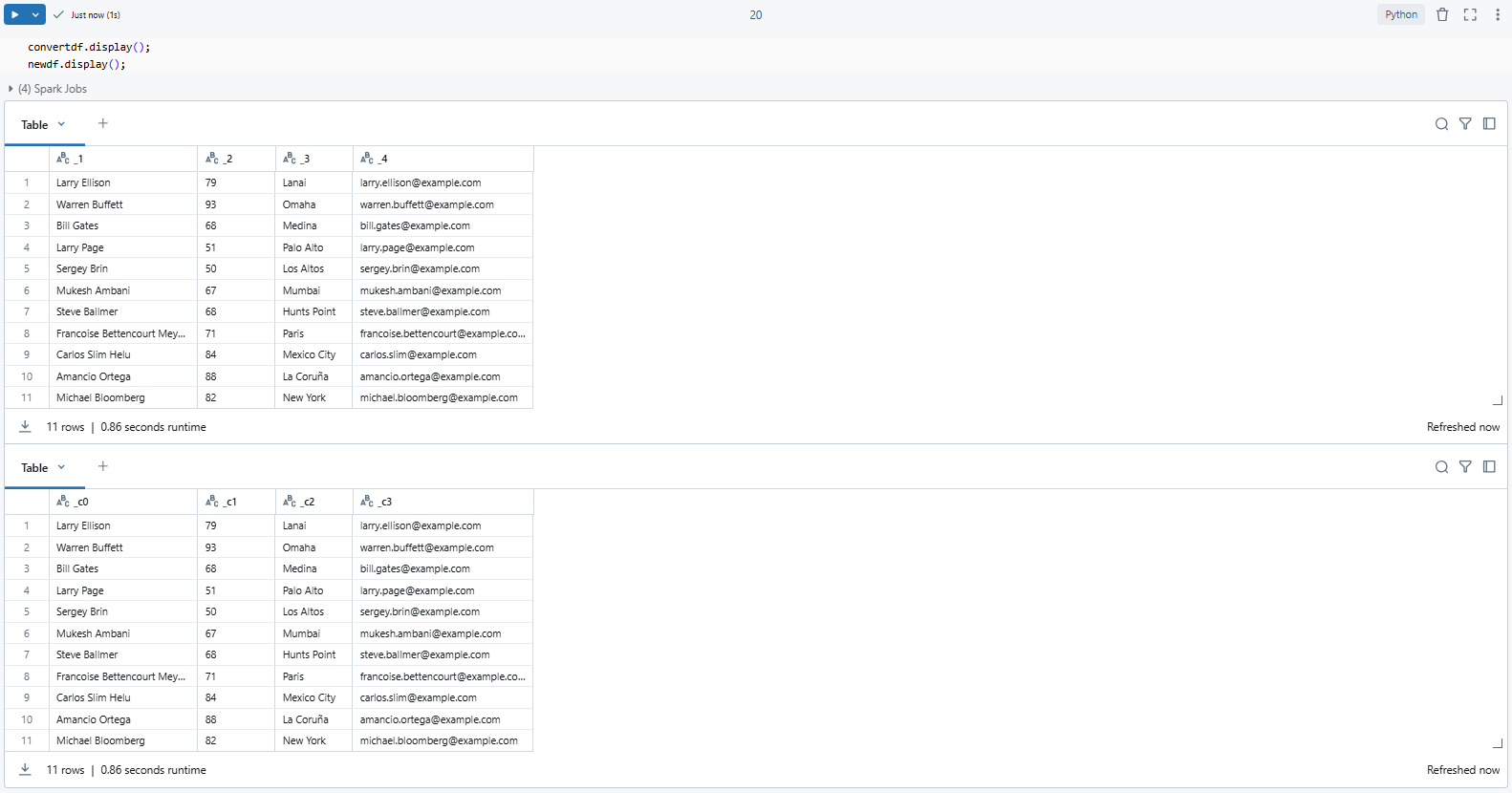
Why Use RDDs for Skipping Rows?
This technique, while functional, involves more manual handling compared to DataFrame methods. RDDs provide low-level control which might be necessary if you're dealing with very specific data processing needs or custom transformations. However, for most use cases, you're better off using DataFrame APIs or Spark SQL for simplicity and performance. Remember, RDD transformations can be less performant and harder to optimize than DataFrame operations in Databricks.
🔮 Technique 4—Skip Rows When Reading CSV Files in Databricks Using Pandas (For Smaller Datasets)
We've covered techniques using PySpark, Spark SQL, and RDDs. Now, let's dive into using Pandas for smaller datasets where you might prefer simplicity over distributed processing. This technique works well for smaller datasets—Pandas processes data in memory, so it’s not ideal for large-scale files commonly handled in Databricks.
Assuming you've already configured your Databricks environment, set up your compute cluster, opened your notebook, and attached your compute to the notebook, here's how you proceed:
Step 1—Import Pandas
First, import Pandas to your Databricks Notebook. Pandas is a popular Python library for data manipulation and analysis:
import pandas as pd
Step 2—Read CSV with skiprows
Pandas provides the skiprows parameter to exclude rows from the beginning of a CSV file. This is useful when the initial rows contain metadata or unwanted information:
# Skip the first 5 rows
pandas_df = pd.read_csv('/dbfs/FileStore/SkipRowsCSVFile.csv', skiprows=5)You can also skip rows at the bottom of the file using the skipfooter parameter:
# Skip the last 3 rows
pandas_df = pd.read_csv('/dbfs/FileStore/SkipRowsCSVFile.csv', skipfooter=3)Step 3—Manually Specify Headers parameter
Sometimes, your header row isn’t the first row in the file. Adjust the header parameter to specify which row contains the column names. For example, if your headers are on the fourth row (index 3):
pandas_df = pd.read_csv('/dbfs/FileStore/SkipRowsCSVFile.csv', header=3)header: Index of the row to use as column headers (0-based indexing).skiprows: Combine with header for dynamic row skipping.
Step 4—Data Validation
After loading the data, inspect the first few rows to confirm the correct rows were skipped:
print(pandas_df.head())
Step 5—Convert Pandas to PySpark DataFrame
Pandas is efficient for smaller datasets, but for distributed processing, convert your Pandas DataFrame to a PySpark DataFrame:
converted_spark_df = spark.createDataFrame(pandas_df)By doing this it allows you to leverage the distributed nature of Spark for further transformations and analyses.
Step 6—Validate and Display Data
Finally, validate the data in the PySpark DataFrame to ensure it aligns with your expectations:
converted_spark_df.show()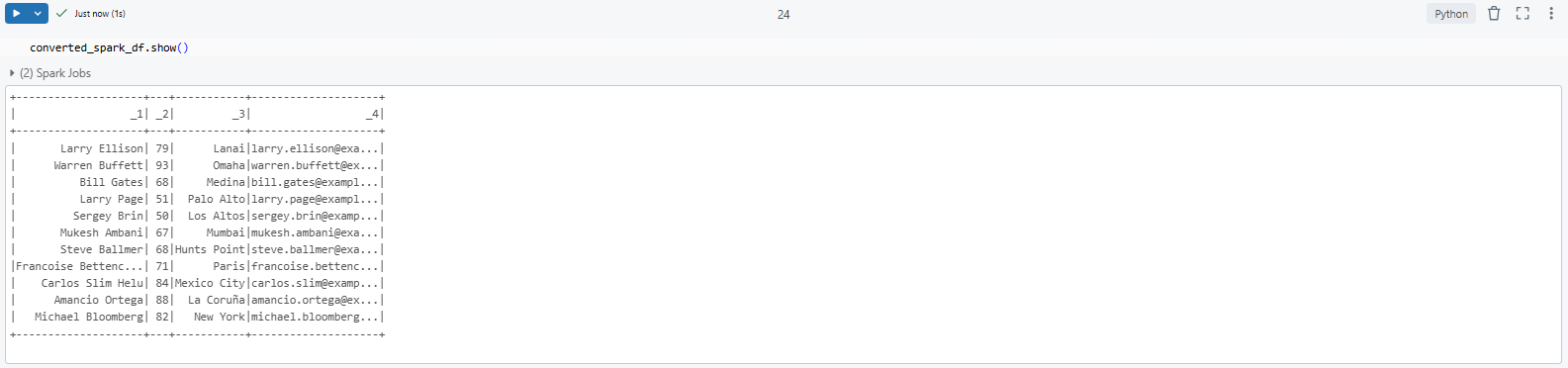
Using Pandas in Databricks is a great option for smaller datasets or when you need to quickly tweak some data. However, for big data processing, it's better to use Spark's distributed capabilities. In Databricks, Pandas operations are handled by the driver node, which can be a problem for really large datasets.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Conclusion
And that's a wrap! We've navigated through various techniques to skip rows in CSV files within Databricks, offering you multiple tools to clean your data efficiently. Whether you’re working with massive datasets or smaller files, knowing the right approach can save you time and improve your workflow efficiency. From PySpark to Pandas, each method offers unique strengths tailored to specific scenarios, making it easier for you to handle your data with precision and confidence.
In this article, we have covered:
☣️ The Issue: Why Skip Rows When Reading CSV Files?
💡 The Solution: Skip Rows When Reading CSV Files in Databricks
- Technique 1—Skip Rows When Reading CSV Files in Databricks Using PySpark
- Technique 2—Skip Rows When Reading CSV Files in Databricks Using Spark SQL’s read_files function
- Technique 3—Skip Rows When Reading CSV Files in Databricks Using RDD Transformations
- Technique 4—Skip Rows When Reading CSV Files in Databricks Using Pandas
… and so much more!
FAQs
Can I skip rows based on content rather than just by number?
Yes, you can skip rows based on content in both PySpark and Pandas. In PySpark, you can use DataFrame operations or RDD transformations with filter functions:
df = df.filter(df['column_name'] != 'some_content')Or in RDD:
rdd = rdd.filter(lambda line: 'specific_content' not in line)For Pandas, use a conditional statement within read_csv:
df = pd.read_csv('file.csv', skiprows=lambda x: 'content_to_skip' in x)What if I need to skip different numbers of rows for different files?
If you have multiple CSV files, each requiring a different number of rows to be skipped, you'll need to handle each file individually. In PySpark, you can specify the number of rows to skip using the skipRows option when reading each file:
df1 = spark.read.option('skipRows', 5).csv('dbfs:/<file-path>/file1.csv')
df2 = spark.read.option('skipRows', 10).csv('dbfs:/<file-path>/file2.csv')Is there a performance impact from skipping rows?
Skipping rows can improve performance by reducing the amount of data you process. However, the impact depends on where the skipping occurs:
- Reading phase: Skipping rows during reading reduces I/O, potentially speeding up data ingestion.
- Post-read filtering: If you filter after reading all data, you'll process unnecessary data first, which could be less efficient for large datasets.
Does skipping rows affect the header row when reading CSV files?
Yes, skipping rows can affect how you read headers. If you skip rows before the header, you must specify the correct header position.
Can I skip rows dynamically based on their content in PySpark?
Yes, you can dynamically skip rows based on their content in PySpark by applying a filter after reading the data. For instance, to skip rows where a specific column contains a certain value:
df = spark.read.csv('dbfs:/<file-path>/file.csv', header=True)
filtered_df = df.filter(df['column_name'] != 'unwanted_value')What's the difference between skiprows in Pandas and skipRows in PySpark?
Both serve similar purposes but are implemented differently; skiprows is used directly in Pandas while skipRows is an option within the read function in PySpark.
How does skipping rows impact performance in large datasets?
In large datasets, skipping rows can lead to increased processing time, as each row must be read and assessed to determine if it should be skipped. This overhead can affect overall performance, so it's advisable to use row-skipping very carefully and consider alternative data preprocessing methods when dealing with substantial data volumes.
Are there any limitations with skipRows in Databricks?
Yes there are some limitation with skipRows in Databricks, they are:
skipRowsis available from Spark 3.1.0, so older Databricks runtimes might not support this feature.skipRowsskips a fixed number of rows at the start; it doesn't dynamically adjust based on content unless combined with other methods like filtering.skipRowsworks specifically with CSV data sources; other formats might not support it directly.
What happens if I skip rows in a CSV file that has no header?
When skipping rows in a CSV without headers, all columns are named _c0, _c1, etc., by default. You'll need to manually rename them.
What happens if the number of rows to skip exceeds the total rows in a file?
If the skipRows value exceeds the total number of rows in a file, PySpark will return an empty DataFrame or return "OK" for that file.















