





























In this article, we will guide you through the process to convert a Pandas DataFrames to table in Databricks. Here we'll cover the essential steps, technical details, and best practices for a smooth transition from Pandas to PySpark DataFrames and, ultimately, to a Databricks table. Let’s dive right in!
What is a DataFrame?
A DataFrame is a two-dimensional, size-mutable, potentially heterogeneous tabular data structure with labeled axes (rows and columns).
- Rows are labeled with an index, which can be numerical or custom labels.
- Columns are named and can hold different types of data, like integers, floats, or strings.
DataFrame is similar to a spreadsheet or SQL table and is designed for efficient data manipulation and analysis.
In Databricks, you can work with both Pandas DataFrames and PySpark DataFrames.
But before diving into the step-by-step guide to convert Pandas DataFrame to table in Databricks, let's quickly dive into the difference between a Pandas DataFrame and a PySpark DataFrame.
To create a table from a Pandas DataFrame in Databricks, you first need to convert it into a PySpark DataFrame because Databricks leverages Apache Spark for data processing.
What Is the Difference Between Pandas DataFrame and PySpark DataFrame?
Here is a quick differences between Pandas and PySpark DataFrames.
| Pandas DataFrame | PySpark DataFrame |
| Pandas DataFrame is designed for single-node operation, making it suitable for smaller datasets. | PySpark DataFrame is built for distributed computing, allowing it to handle large-scale datasets across multiple nodes. |
| Pandas DataFrame processes data in-memory, which can lead to faster performance for small datasets. | PySpark DataFrame processes data in a distributed manner, which can optimize performance for large datasets but may introduce overhead. |
| Pandas DataFrame is limited by the memory capacity of a single machine. | PySpark DataFrame can manage massive datasets that exceed the memory limits of a single machine by leveraging cluster resources. |
| Pandas DataFrame has a simpler API and is generally easier to use, making it accessible for quick data analysis tasks. | PySpark DataFrame has a more complex API, reflecting its distributed nature and requiring additional configuration and understanding. |
| Pandas DataFrame does not support parallel processing natively; operations are executed sequentially. | PySpark DataFrame supports parallel processing, utilizing multiple cores and nodes in a cluster to execute tasks concurrently. |
| Pandas DataFrame lacks built-in fault tolerance; users must implement their own mechanisms for data integrity. | PySpark DataFrame includes built-in fault tolerance through resilient distributed datasets (RDDs), ensuring data reliability during processing. |
| Pandas DataFrame is typically faster for small to medium-sized datasets due to its in-memory operations. | PySpark DataFrame is optimized for distributed processing, making it more efficient for handling very large datasets. |
| Pandas DataFrame is compatible with NumPy and provides rich functionalities for data manipulation and analysis. | PySpark DataFrame offers SQL-like operations and is designed to integrate with big data tools and frameworks. |
| Pandas DataFrame is best suited for exploratory data analysis and prototyping on smaller datasets. | PySpark DataFrame is ideal for production-level big data processing tasks and batch processing workflows in cloud environments. |
What is a Databricks Table?
Table in Databricks is a structured dataset organized into rows and columns, stored in cloud object storage as a directory of files. Its metadata, including schema and properties, is maintained in the metastore within a specific catalog and database. Databricks uses Delta Lake by default as its storage layer, so tables created on the platform are Delta Lake tables unless specified otherwise. These tables offer features like ACID transactions, scalable metadata handling, time travel (data versioning), and support for both streaming and batch data processing.
Databricks offers two main types of tables: managed and unmanaged (external).
1) Managed Databricks Tables: Databricks fully controls these tables. The platform stores their data in a designated location, typically within the Databricks File System (DBFS) or a cloud storage area managed by Databricks. Managed tables simplify data lifecycle management, including tasks like replication, backups, and optimizations.
2) Unmanaged (External) Databricks Tables: These tables store their data outside of Databricks-managed storage, in external locations such as Amazon S3, Google Cloud Storage, Azure Data Lake Storage Gen2, or Blob Storage. You have full control over the data's location and management, which means you're responsible for maintaining and securing it.
For a practical demo, refer to this article: Step-by-Step Guide to Create a Table in Databricks.
For more detailed guide on creating managed and external tables, check out this video:
Now, let’s dive into the core purpose of this article—how to convert a Pandas DataFrame to Table.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Step-By-Step Guide to Convert Pandas Dataframe to Table in Databricks
Prerequisites
Before converting a Pandas Dataframe to table in Databricks, confirm the following prerequisites:
- An active Databricks account with permissions to create Databricks Notebooks and clusters.
- Basic knowledge of Python, SQL, and familiarity with Apache Spark architecture.
- A running Databricks cluster ready for use.
Step 1—Log in to Databricks
Start by logging into your Databricks account through your web browser.
Step 2—Navigate to the Databricks Workspace
Once logged in, navigate through your Databricks workspace dashboard. Here you can create new Databricks Notebooks or access existing ones where you will perform your operations.
Step 3—Configure Databricks Cluster
Check if your Databricks cluster is properly configured. You may need to install libraries like pandas if they are not already available. Databricks Runtime versions 10.4 LTS and above include the pandas library pre-installed, so manual installation is unnecessary. However, for Runtime versions below 10.4, you may need to install it manually.
To install pandas:
Navigate to “Compute” on the sidebar.
If needed, click “Create Compute” to set up a new cluster or select an existing one.
Check whether the cluster is running or set it to start automatically if idle.
Go to "Libraries" > "Install New" > "PyPI" > enter pandas > click “Install”.
Step 4—Open Databricks Notebook
Create or open an existing Databricks Notebook within your workspace where you will execute Python code for converting your DataFrame. Then, attach your Databricks Notebook to this cluster or an existing one that's running.
Step 5—Import Required Libraries
Now, in your Databricks Notebook cell, import the necessary libraries:
import pandas as pd
from pyspark.sql import SparkSessionStep 6—Create a Pandas DataFrame
You can create a simple Pandas DataFrame as follows:
data = {
'Name': ['Elon Musk', 'Jeff Bezos', 'Mark Zukerberg', 'Bill Gates', 'Larry Page'],
'Age': [55, 58, 35, 60, 50]
}
pandas_df = pd.DataFrame(data)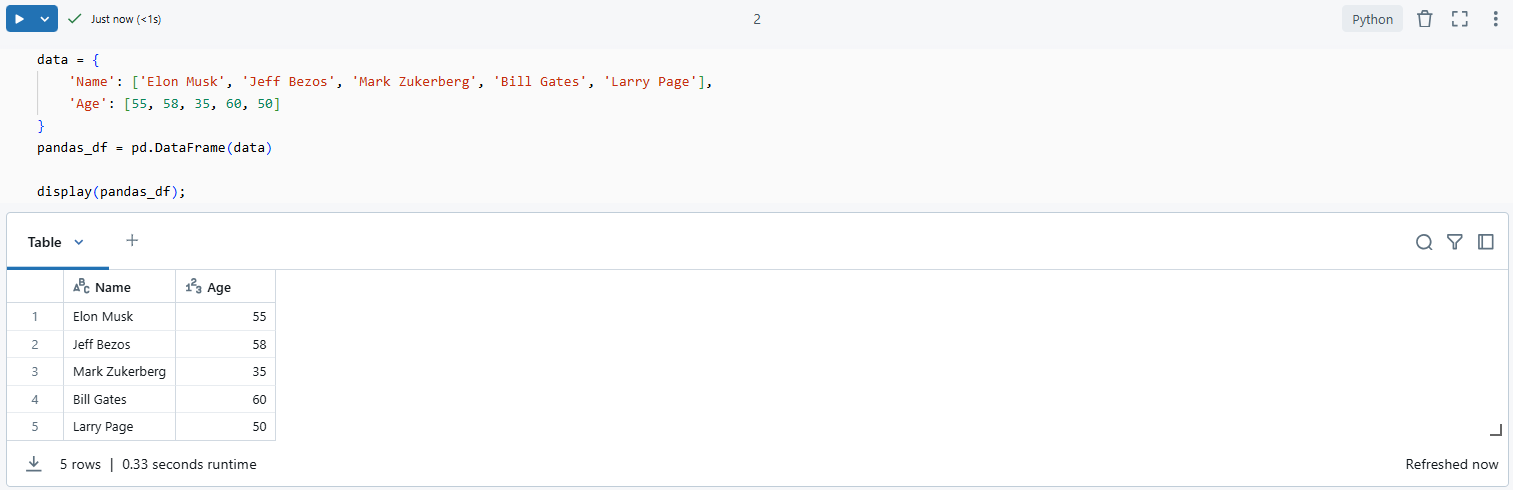
Step 7—Load Data into a Pandas DataFrame (Optional)
Or, you can load data from Databricks DBFS:
pandas_df = pd.read_csv('/dbfs/FileStore/<path-to-file>/data.csv')Make sure that your dataset fits into memory when using Pandas.
Check out this article to learn more in-depth on data loading via Databricks DBFS.
Step 8—Convert Pandas DataFrame to PySpark DataFrame
Now, to convert Pandas DataFrame to table in Databricks first you need to convert the created Pandas DataFrame into a PySpark DataFrame:
To do so, first, create an instance of SparkSession if not already done:
spark = SparkSession.builder.appName('Example App').getOrCreate()
Then convert the Pandas DataFrame:
pyspark_df = spark.createDataFrame(pandas_df)
Note that when converting a Pandas DataFrame to a PySpark DataFrame in Databricks, you might encounter several issues:
➥ Schema mismatches — Complex data types in Pandas, such as lists or dictionaries, do not directly map to Spark data types.
➥ Databricks Cluster configuration issues — Your Databricks Notebook must be connected to an active cluster; otherwise, code execution will not proceed.
➥ Memory errors — Handling large datasets in Pandas before conversion can lead to memory issues. It is advisable to process data in chunks or use alternative methods.
To address schema mismatches during conversion, explicitly defining the schema can be helpful:
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
# Define the schema
schema = StructType([
StructField("Name", StringType(), True),
StructField("Age", IntegerType(), True)
])
# Convert Pandas DataFrame to PySpark DataFrame with the defined schema
pyspark_df = spark.createDataFrame(pandas_df.values.tolist(), schema)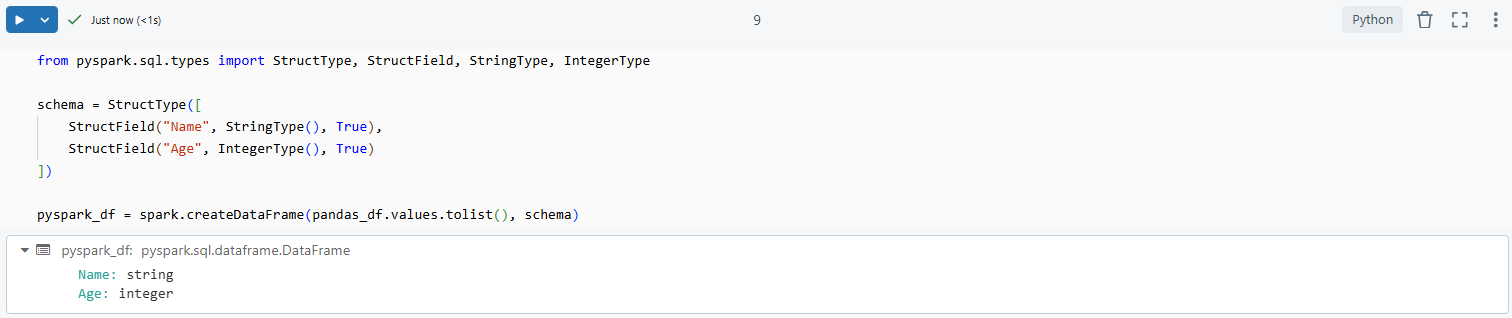
Step 9—Enable Apache Arrow (Optional)
Also, you can enable Apache Arrow can optimize the conversion between Pandas and PySpark DataFrames. Arrow facilitates efficient data transfer between JVM and Python processes. To enable Arrow-based columnar data transfers:
# Enable Arrow-based columnar data transfers
spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "true")
# Convert Pandas DataFrame to PySpark DataFrame using Arrow
pyspark_df = spark.createDataFrame(pandas_df)
# Convert PySpark DataFrame back to Pandas DataFrame using Arrow
pandas_df = pyspark_df.toPandas()Be aware that Arrow-based conversion has some limitations. For instance, certain data types like ArrayType of TimestampType aren't supported. Also, MapType and ArrayType of nested StructType are only supported with PyArrow 2.0.0 and above.
For large datasets, consider using PySpark's distributed computing capabilities instead of converting large Pandas DataFrames to PySpark.
Check out this video if you want to learn more about converting Pandas to PySpark DataFrame:
How to Convert Pandas to PySpark DataFrame | Databricks |
Step 10—Write the PySpark DataFrame to Databricks Table
Now that you have converted your Pandas DataFrame into a PySpark DataFrame, you can write it as a table in Databricks:
pyspark_df.write.saveAsTable("students_table")
This command creates a managed table named students_table.
If you want it as an unmanaged table pointing at specific storage paths instead:
pyspark_df.write.format("parquet").save("/mnt/<file-path>/students_table")Step 10—Verify the Created Table
To check that your table has been created successfully:
Run this command to display all tables available in your current database:
display(spark.sql("SHOW TABLES"))
To query the contents of your newly created table:
%sql
SELECT * FROM students_table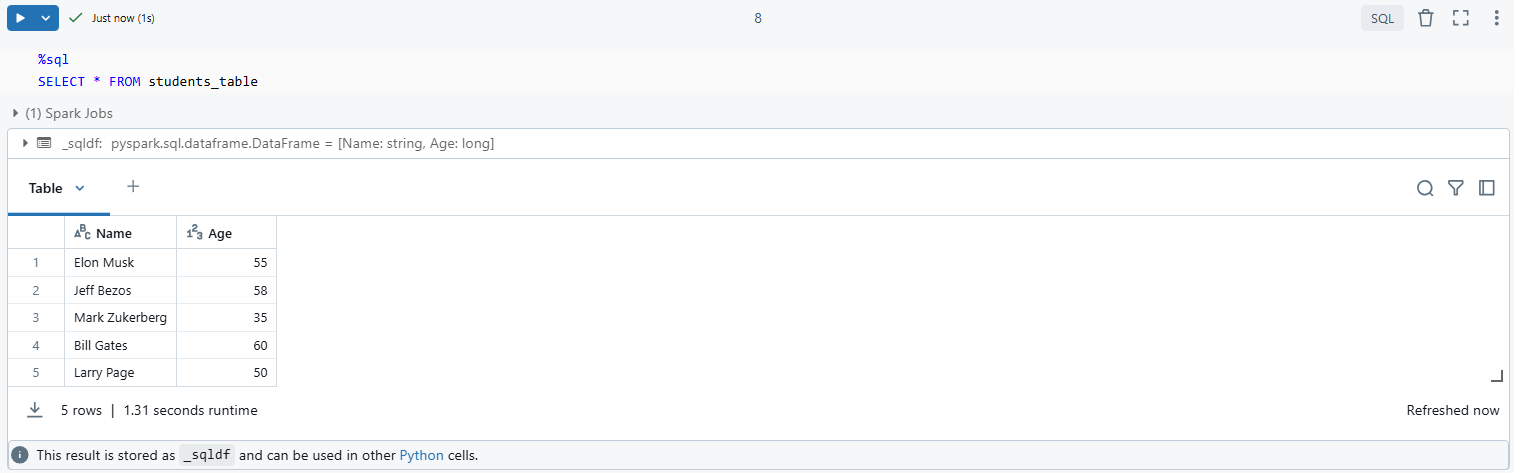
As you can see, this command retrieves all records from students_table, confirming that it was written correctly.
There you have it! You have successfully converted Pandas DataFrame to table in Databricks.
Save up to 50% on your Databricks spend in a few minutes!


Conclusion
And that's a wrap! In this article, we’ve explored everything from the basics of DataFrames to the unique features of Pandas and PySpark DataFrames. We’ve broken down the key differences between the two, introduced the concept of Databricks Tables, and even walked through a step-by-step guide to converting a Pandas DataFrame into a Databricks table.
FAQs
Does databricks use pandas?
Yes! While primarily built around spark’s capabilities for big data processing via pyspark, users can also utilize pandas for smaller-scale operations within Databricks Notebooks.
Is spark table a dataframe?
Yes! In spark’s context, tables can be accessed as dataframes allowing users familiar with SQL syntax flexibility while leveraging distributed computing power under-the-hood.
Does pyspark have dataframe?
Absolutely! The core component of working with structured big datasets within apache spark relies heavily on its implementation of distributed-friendly versions called “dataframes”.
Can I use large pandas dataframes directly in databricks?
Not recommended! Large datasets should be converted into pyspark format before processing due their memory limitations inherent within standard pandas usage patterns which May lead errors or inefficiencies otherwise encountered during execution phases.
What are the limitations of pyspark dataframes compared to pandas?
Pyspark dataframes can handle vast amounts of data efficiently via distributed systems; But they May lack some advanced features found readily available within pandas like intuitive indexing options or certain built-in aggregation functions designed primarily around smaller workloads instead!
How do you save a pyspark dataframe as a table in databrick?
Use .write.saveAsTable() Function call directing output towards desired destination specifying whether managed/Unmanaged based upon requirements outlined throughout article!
Can I convert a PySpark DataFrame back to a Pandas DataFrame in Databricks?
Yes, you can convert a PySpark DataFrame back to a Pandas DataFrame using the toPandas() method. But, be very cautious with large datasets, as this operation collects all data into memory on the driver node, which may lead to memory errors if the dataset is too large.
What is Apache Arrow, and how does it relate to DataFrame conversions in Databricks?
Apache Arrow is an in-memory columnar data format that optimizes the transfer of data between JVM and Python processes. In Databricks, enabling Arrow can significantly speed up conversions between PySpark and Pandas DataFrames. You can enable it by setting spark.sql.execution.arrow.pyspark.enabled to true.
spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "true")What should I do if I encounter schema mismatches when converting between Pandas and PySpark DataFrames?
If you face schema mismatches, explicitly define the schema using Spark's StructType and StructField classes when creating a PySpark DataFrame from a Pandas DataFrame.
How can I append data from a Pandas DataFrame to an existing table in Databricks?
To append data from a Pandas DataFrame to an existing table, first convert the Pandas DataFrame to a PySpark DataFrame using createDataFrame(), then use the write method with the mode("append") option to insert the new data into the existing table.
Is it possible to use SQL queries on PySpark DataFrames in Databricks?
Yes, you can run SQL queries on PySpark DataFrames by creating a temporary view using the createOrReplaceTempView() method.
What are some performance considerations when converting large Pandas DataFrames to PySpark?
When dealing with large datasets, consider enabling Apache Arrow for faster conversion. Additionally, ensure your cluster has enough resources (CPU and memory) allocated, and try to optimize your data by filtering or aggregating before conversion.
Can I use complex data types in my Pandas DataFrame when converting to PySpark?
While you can include complex data types in your Pandas DataFrame, they may not directly translate to PySpark's schema without proper handling. It's best to flatten or convert these types into simpler structures (e.g, separate columns) before conversion.
What happens if I try to write incompatible data types from a Pandas DataFrame into a Databricks table?
If you attempt to write incompatible data types (e.g, trying to insert a string into a numeric column), Spark will raise an AnalysisException. You must ensure that your column types in the DataFrame match those of the target table schema.
How do I handle missing values in my Pandas DataFrame before converting it to PySpark?
You can handle missing values in your Pandas DataFrame using methods like fillna() or dropna(). It's important to clean your data before conversion to avoid issues with null values in Spark.
Can I use Databricks Notebooks for both Python and SQL operations simultaneously?
Yes, Databricks Notebooks support multiple languages within the same notebook, allowing you to run Python code for data manipulation and SQL queries for analysis seamlessly. You can switch languages by using %python or %sql magic commands at the beginning of each cell.















