




























Data is the new valuable mineral, but unrefined, it’s just ore. With multiple data sources and types, businesses need a platform to process the data into valuable insights. Enter the Data Lakehouse. But having data and a platform isn’t enough—management and organization is key to not turning a Data Lake into a chaotic and messy data swamp. The Medallion Architecture is the proven way for modern Data Lakehouses. This architecture has three layers: Bronze, Silver, and Gold. In them, data is stored and transformed into a reliable, structured asset ready for decision-making and innovation. Databricks invented the Medallion Architecture, which has gained traction. Microsoft has adopted it for their central data storage solution, One Lake. One Lake is in the Microsoft Fabric platform, which was launched last year. Databricks, Microsoft, and other big companies support this approach. So, it’s clear that Medallion Architecture is a trend that businesses can’t ignore.
In this article, we're going to cover everything you need to know about Medallion Architecture. Plus, we'll explore what it is, why it matters, and how it's impacting data management and organization in a big way.
The Modern Data Ecosystem
Before we get into the details of Medallion Architecture, let’s start by understanding the evolution of data storage and processing systems.
Data Lake, Data Warehouse, Data Lakehouse
Remember the good old days when all our data fit into neat tables? Yeah, those days are over. As data volumes grew and unstructured data became more common, traditional Data Warehouses started to show their cracks.
Enter the Data Lake. Delta Lake is an optimized storage layer on top of Apache Parquet. It has advanced features. These include ACID transactions, scalable metadata, and unified streaming and batch processing. It extends Parquet data files with a file-based transaction log to ensure data reliability and integrity. The structure of Delta Lake includes versioned Parquet files, a checkpoint file, and a transaction log stored in JSON format. These components enable ACID transactions and versioning. They ensure consistent and reliable data operations. This structure allows you to handle a variety of data types—structured, semi-structured, and unstructured—in their raw form.
Think of it as a big bucket where you can dump all kinds of data— structured, semi-structured, unstructured—in its raw form. Sounds great, right? Well, it was, until people realized that without proper management and organization, a Data Lake can quickly become a Data Swamp. Yikes!
This is where the Data Lakehouse comes in. It’s like the best of both worlds—combining the flexibility and scalability of Data Lakes with the structured, analytics-friendly nature of Data Warehouses.
Data Lakehouse combines the flexibility, low cost, and scalability of a Data Lake with the strong data management and ACID transactions of Data Warehouses. It addresses the limitations of both. Databricks, Apache Hudi, and Apache Iceberg are some of the implementations of this concept.
ETL and ELT—The Data Processing Duo
Now, let’s talk about how we actually get data from point A to point B. We’ve traditionally used ETL processes (Extract, Transform, Load processes). It’s like an assembly line for data—extract it from the source, transform it into the desired format, and then load it into the target system.
But with big data and cloud, we’ve seen a shift towards the ELT process (Extract, Load, Transform). In this approach, we load the raw data first and transform it later. This gives us more flexibility and we can keep the raw data for future use cases we might not have thought of yet.
The Data Lake Dilemma
While Data Lakes solved the problem of storing different data types, they introduced a new problem: how do we organize all this data so it’s manageable, accessible and actually useful?
Think of trying to find a specific fish in a big, muddy lake. That’s what Data Engineers, Data Scientists and analysts were facing with unorganized Data Lakes. They needed a way to structure the data without losing the flexibility that made Data Lakes so appealing in the first place.
Here's where Medallion Architecture comes to the rescue, helping you tidy up your data in a Data Lakehouse with a simple, structured approach.
Save up to 50% on your Databricks spend in a few minutes!


What Is Medallion Architecture?
Medallion Architecture is a data design pattern for organizing data in a Data Lakehouse. It’s like a blueprint for how to structure your data as it moves through different layers/stages of processing and refinement.
Medallion Architecture has three layers. They are bronze (raw), silver (filtered, cleaned, augmented), and gold (enriched)—each layer representing a progressive increase in data quality.
Medallion Architecture is also sometimes called “multi-hop” architecture.
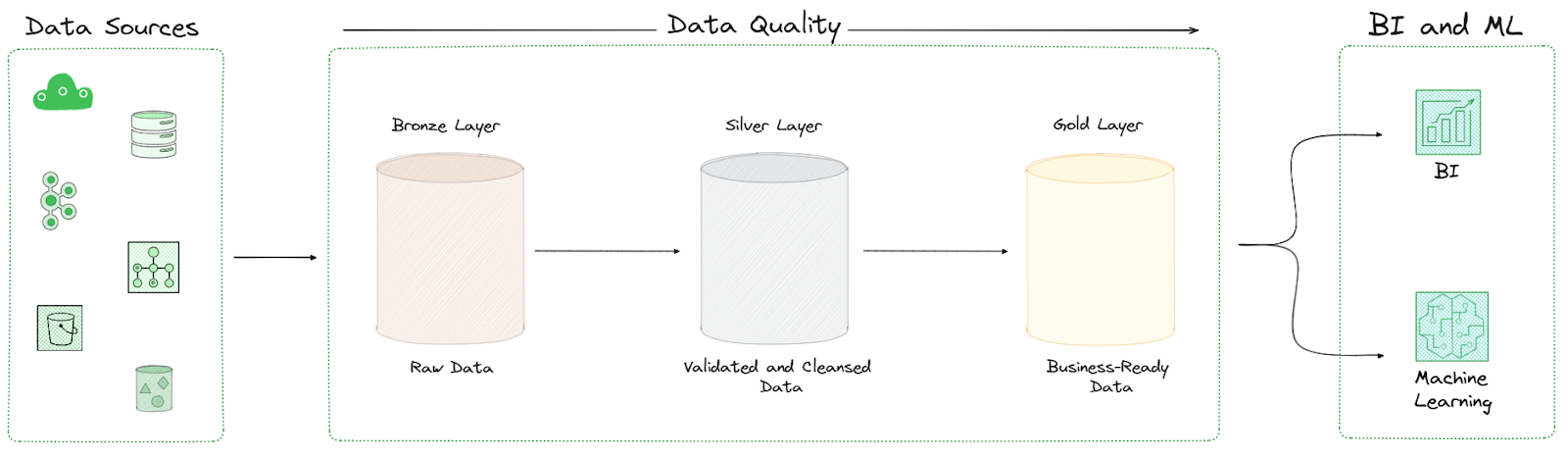
Medallion Architecture is grounded in the following fundamental principles:
1) Data Maturity: The quality of data improves as it progresses through the layers.
2) Agility: The architecture can adapt to changing business needs and new data sources.
3) Modularity: Data at each layer is designed to be reusable for multiple purposes.
4) Auditable Data Path: The system ensures transparency by providing a clear trail of data origin and movement.
5) High-Performance Capacity: The architecture is designed to efficiently process large volumes of data and complex operations.
Why Is It Needed?
We've got a Big Data problem.
So, what's the big deal with big data? We've got four major issues to tackle.
First, there's just too much of it. We need a way to make sense of it all. Next, it comes in all shapes and sizes—from structured database tables to unstructured messy text files and everything in between. Then, there's the speed at which it's coming at us. We need to process it fast to keep up. And lastly, with so many data sources, we've got to make sure the data is accurate and trustworthy.
Medallion Architecture addresses these challenges. It provides a structured but flexible approach to data organization and processing.
The Three Layers of Medallion Architecture
Now, let's delve into the core of Medallion Architecture: its three layers—bronze, silver, and gold. Think of these as distinct stages in a data refinement process, each with its own purpose and characteristics.
🥉 Bronze Layer (Raw Data)
The bronze layer is where it all begins. The Bronze layer is essentially a landing zone or foundational repository for raw data. It is designed to store data in its original, unaltered state, directly sourced from its origin. This data may originate from various formats, including JSON files obtained from web APIs or CSV exports from legacy systems.
The Bronze layer is characterized by the following attributes:
- Unmodified data: The data is stored in its exact original form, without alteration.
- Append-only storage: New data is added to the layer without modifying existing data.
- Full historical retention: All historical data is preserved, enabling point-in-time analysis and data reprocessing as required.
Data Ingestion Processes and Data Sources
So, how do we get data into the Bronze layer? Well, we've got a few methods.
One way is through batch data ingestion—think of it like a nightly data dump from our database.
Another way is real-time streaming data ingestion, which is like a steady stream of data, like the clicks and interactions on our website.
And then there's API-based data ingestion, where we pull data from other data sources.
Metadata Management
The raw data remains unchanged, but metadata is added to enable efficient data management. This metadata typically comprises:
- Ingestion Timestamp, which records the exact time of data loading into the system.
- Source Identifier, indicating the origin of the data.
- Batch Identifier, a unique identifier assigned to each batch load.
The addition of this metadata is crucial for tracking data lineage and managing the data lifecycle.
🥈 Silver Layer (Validated and Cleansed Data)
Silver layer is where the raw data from the Bronze layer undergoes cleansing, filtering, deduplication, and basic transformation processes to make it more usable for analysis. However, complex aggregations are avoided at this stage. If the Bronze layer is our rough diamond, the Silver layer is where we start to cut and polish it.
The Silver layer is characterized by the following attributes:
1) Data quality improvement: Basic data quality issues are addressed and resolved.
2) Data structuring: Data is organized in a format that facilitates querying and analysis.
3) Data validity: Fundamental data validation rules are applied to ensure accuracy.
4) Data enrichment: Additional context or metadata may be added to enhance the data.
🥇 Gold Layer (Business-Ready Data)
Finally, the Gold layer is where our data truly shines. This layer contains highly refined, aggregated, and enriched data. Data in the Gold layer is often transformed into formats that optimize query performance and provide ready-to-use datasets for business users.
The Gold layer is characterized by the following attributes:
1) Aggregated data: Data is often pre-aggregated for common analysis patterns.
2) Enriched Data: Data in the Gold layer is extensively processed, cleaned, and enriched.
3) Business-Level Aggregation: Data in this layer is aggregated according to business requirements.
3) Denormalized Structure: Data is typically denormalized to facilitate easier querying and improved performance.
4) Query optimization: Data is structured for fast query performance.
Additional Layers—Landing and Presentation
1) Landing
In some cases you may need extra layers beyond Bronze, Silver and Gold. One common extra layer is the Landing layer. This is where data from source systems drops before it goes into the Bronze layer.
2) Presentation Layer(s)
Some implementations may also have a presentation layer or multiple presentation layer(s) for different audiences. The presentation layer contains different views of the data from the Gold layer. If you have multiple presentation layers they will each contain a subset of the data relevant to that audience.
ACID Transactions in the Context of Medallion Architecture
Medallion Architecture often leverages ACID (Atomicity, Consistency, Isolation, Durability) transactions to maintain data integrity throughout the refinement process.
Atomicity ensures that data movements between layers are all-or-nothing operations.
Consistency guarantees that data meets defined rules and constraints at each layer.
Isolation allows multiple processes to work on the data simultaneously without interfering with each other.
Durability ensures that once data is committed to a layer, it's safely stored.
These properties are especially important when dealing with large-scale data processing and real-time data streams.
What Is the Difference Between ETL and Medallion Architecture?
Here's a quick comparison between ETL process and Medallion Architecture:
| ETL (Extract Transform Load Process) | Medallion Architecture |
| ETL is a data integration process that extracts data from various sources, transforms it, and loads it into a target database or warehouse. | Medallion architecture is a data design pattern for organizing data in a lakehouse with incremental quality improvements across three layers: Bronze, Silver, and Gold. |
| Stages of ETL are Extract, Transform, Load. | Stages of Medallion architecture are Bronze (raw data), Silver (cleansed and conformed data), and Gold (curated business-level tables). |
| The main purpose of ETL is to move data from source systems to a target system with transformation for analytics. | The main purpose of Medallion architecture is to structure and refine data through multiple stages for better quality and usability. |
| ETL ensures data quality during the transformation stage before loading into the target system. | Medallion architecture improves data quality incrementally across Bronze, Silver, and Gold layers. |
| Data is transformed before being loaded into the target system. | Initial light transformations occur in the Silver layer; advanced transformations happen in the Gold layer. |
| Data is loaded after transformation into the target system. | Data is loaded through various layers, each serving a different purpose and increasing data quality. |
| Often handles structured data from various sources. | Can handle both structured and unstructured data. |
| Can be complex to scale, especially with large volumes of data. | Designed to scale with data lakes and supports large data volumes. |
| Less flexible; transformation logic must be defined upfront. | More flexible; supports incremental transformation and quality improvement. |
| Commonly used in traditional data warehouses, business intelligence, and reporting. | Used in modern data lakehouses, advanced analytics, machine learning, and BI. |
| Requires significant upfront planning and setup. | Incremental and modular, easier to adapt and extend. |
What Is the Difference Between ELT and Medallion Architecture?
Here's a quick comparison between ELT and Medallion Architecture:
| ELT (Extract, Load, Transform) | Medallion Architecture |
| ELT is a data integration process where data is extracted from source systems, loaded into a target system, and then transformed. | Medallion architecture is a data design pattern for organizing data in a lakehouse with incremental quality improvements across three layers: Bronze, Silver, and Gold. |
| Data is first loaded into the target system (like a data warehouse or data lake) and then transformed as needed. | Data moves through three layers: Bronze (raw data), Silver (cleansed and conformed data), and Gold (curated business-level tables). |
| The main purpose of ELT is to leverage the scalability and processing power of modern data warehouses to transform data. | The main purpose of Medallion architecture is to structure and refine data through multiple stages for better quality and usability. |
| ELT is commonly used for high-volume data sets and real-time data use environments, such as stock exchanges and large-scale distributors. | Medallion architecture is used in modern data lakehouses, supporting advanced analytics, machine learning, and BI by incrementally improving data quality. |
| In ELT, data transformations occur within the target system, utilizing its processing capabilities. | In Medallion architecture, light transformations occur in the Silver layer, and advanced transformations happen in the Gold layer. |
| ELT is designed to handle both structured and unstructured data, making it flexible for various data types. | Medallion architecture also handles both structured and unstructured data, organizing it into progressively refined layers. |
| ELT provides faster data availability and can scale efficiently with cloud-based data warehouses. | Medallion architecture provides a structured approach to data quality improvement, with each layer serving a distinct purpose. |
| Examples of tools supporting ELT include Amazon Redshift, Google BigQuery, Snowflake, and Microsoft Azure SQL Data Warehouse. | Examples of tools supporting Medallion architecture include Databricks Delta Lake, Snowflake, and Azure Synapse. |
Note: Medallion Architecture follows an ELT process (Extract, Load, Transform) approach, not ETL process:
- Data is extracted from source systems and loaded into the Bronze layer without transformation.
- Transformations happen as data moves from Bronze to Silver, and from Silver to Gold.
This allows for more flexibility and reprocessing of data if business logic changes.
When to use Medallion Architecture?
Medallion Architecture is great for:
- When dealing with large volumes of diverse data types
- When flexibility is needed to accommodate changing business requirements
- When raw data needs to be retained for compliance or reprocessing
- When implementing a Data Lakehouse strategy
But for smaller, purely structured data scenarios, the traditional ETL process is still the simpler choice.
What Are the Benefits of Medallion Architecture?
Medallion Architecture offers several compelling benefits that make it an attractive choice for modern data management.
1) Better Data Quality
Medallion Architecture separates raw and processed data into different layers, making sure that each layer is processed, cleaned, and validated.
2) Simple Data Model
Medallion Architectures offer a straightforward data model familiar to many who have used tools like dbt or warehouse data staging techniques.
3) Logical Order of Data Cleanliness
Each stage in a medallion architecture follows a logical sequence, the gold stage for analytics is separate from the bronze stage for data ingestion, so there is a clear and logical order of data cleanliness and quality.
4) Recreate Downstream Tables from Raw Sources
Since all data is in raw tables (Bronze layer), you can recreate downstream tables to add columns, rebuild incremental models or recover from a disaster.
5) Scalability
The layered approach allows you to scale data processing and storage for each layer independently, so you can use resources efficiently and manage.
6) Flexibility for Changing Business Needs
Medallion Architecture supports different types of data processing and analytics workloads, so it’s adaptable to your organization and use cases.
7) Strong Foundation for Data Governance
The layered approach enforces schema evolution, data lineage and access controls at each layer, so data is more governable and Data Lakes don’t turn into data swamps.
8) Transaction Support
The architecture ensures data integrity and consistency during simultaneous read or write operations, supporting ACID transactions across the data layers.
What Are the Disadvantages of Medallion Architecture?
While the Medallion Architecture has many benefits, there are also several drawbacks to consider:
1) More Storage Required
Medallion Architecture typically triples the amount of storage used, as it keeps data in its raw (Bronze), cleaned (Silver), and enriched (Gold) forms. This can be expensive, especially for data-heavy applications.
1) Doesn’t Replace Dimensional Modeling
Although the architecture provides a framework for data cleaning. But, it doesn't replace the need for dimensional modeling. Schemas and tables within each layer still need to be modeled and managed separately. This can add complexity to the data management process.
3) Additional Downstream Processing
The architecture often necessitates additional downstream processing to build business-focused transformations. Analysts or analytics engineers may need to develop further transformations in the Gold layer. This can complicate data processing workflows and require additional resources.
4) Complexity and Extreme Learning Curve
Implementing and understanding the Medallion Architecture can be hard. This is especially true for teams not already familiar with similar data systems. Setting up can take time and be complex. It needs much effort from Data Engineers and other technical staff.
5) Only Valid/Works for Data Lakehouse Architecture
Medallion Architecture is designed with a Data Lakehouse in mind. This architecture might not be easy for organizations that don't find a lakehouse practical. Or, for those using traditional Data Warehouses, it might not be helpful.
6) High Cost of Implementation
Beyond storage, the overall cost of implementing a Medallion Architecture can be high. This includes costs for infrastructure and data processing. Ongoing maintenance costs are also included. They can be prohibitive for smaller organizations or projects with limited budget.
Considering these limitations is crucial. It will help you decide if the Medallion Architecture fits your needs and resources.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Conclusion
And that’s a wrap! Medallion Architecture is a way to organize and manage data in this data driven world. It’s a structured yet flexible framework to refine data and addresses many of the big data challenges. The Bronze, Silver and Gold layers are a logical progression of data quality and usability from raw ingest to business ready datasets. This improves data quality and accessibility and provides a foundation for data governance and lineage tracking. But implementing Medallion Architecture isn’t easy. To get the full benefit you need to plan, have expertise and ongoing management. If you fully understand Medallion Architecture, it might help you get value from your data assets and improve data management and analytics.
In this article, we have covered:
- What is Medallion Architecture?
- The three layers of Medallion Architecture
- Difference between ETL process and Medallion Architecture
- Difference between ELT process and Medallion Architecture
- Benefits of Medallion Architecture
- Disadvantages of Medallion Architecture
…and so much more!
FAQs
What is Medallion Architecture?
Medallion Architecture is a data design pattern used in Data Lakehouses to organize data into three distinct layers—Bronze, Silver, and Gold. Each layer represents a step of data refinement from raw to highly processed state.
What is the Medallion design approach?
Medallion design approach involves processing data through multiple stages—Bronze (raw, unprocessed data), Silver (cleaned, conformed data), and Gold (aggregated, business-ready data). This ensures data quality, consistency and readiness for advanced analytics and machine learning.
What else is Medallion Architecture called?
Medallion Architecture is also known as “multi-hop” architecture due to its multi-layered approach.
Who created Medallion Architecture?
Medallion Architecture was coined and popularized by Databricks.
How does Medallion Architecture support data quality?
Medallion Architecture supports data quality by refining data incrementally at each layer. Bronze layer captures raw data, Silver layer cleans and transforms it and Gold layer aggregates and enriches it for business use.
Can Medallion Architecture be used outside of Data Lakehouse?
While medallion architecture is designed for Data Lakehouses, its principles of staged data refinement can be applied to hybrid environments combining Data Lakes and Data Warehouses.
What is the purpose of Medallion Architecture?
The purpose of medallion architecture is to incrementally improve data quality and organization so it’s good for analytics, reporting and machine learning.
How does the Silver layer differ from the Gold layer?
Silver layer has cleaned and validated data, good for intermediate analysis and processing. Gold layer has highly refined, aggregated data for specific business use cases like reporting and advanced analytics.
What does Medallion Architecture solve in the cloud?
Medallion Architecture solves data quality management, scalability, performance optimization, simplified data governance in the cloud, issues like lack of transaction support complexities in Data Lake operations, and more.
How does Medallion Architecture ensure data quality?
Data quality is ensured through the staged refinement process. At each layer data is cleaned, transformed and enriched with strict validation checks and quality rules applied at every stage.















