




























The surge in big data has fundamentally transformed how data is managed, analyzed, and utilized. To deal with this data flood, various data processing architectures have popped up, each with its unique method of processing and interpreting data. One that sticks out is the Lambda Architecture—it's a strong, adaptable architecture. It strikes a balance between speed, capacity, and reliability. Nathan Marz, the creator of Apache Storm, first proposed the Lambda Architecture concept in 2011, initially referring to it as the "Batch/real time architecture". Marz's objective was to develop a data processing paradigm that could efficiently handle massive datasets while simultaneously supporting real time analytics and query capabilities.
In this article, we'll cover everything you need to know about Lambda Architecture, diving into its history, core components, and use cases.
The Data Processing Architectures
Before we go into the specifics of Lambda Architecture, let's take a broad view of data processing architecture. A data processing architecture serves as a blueprint for managing the flow of data—from its ingestion and storage to its processing and utilization. The primary objective of such an architecture is to transform raw data into actionable insights that align with business goals.
As data keeps getting bigger, faster, and more diverse, users/businesses need to pick the right system to fit their needs. There are a few popular options out there: Lambda, Kappa, and Delta Architectures. Each has its own approach to data processing, and they are meant to address various difficulties in big data.
This article will go into detail about Lambda Architecture while also providing an overview of Kappa and Delta architectures.
Save up to 30% on your Snowflake spend in a few minutes!


What Is Lambda Architecture?
Lambda (λ) Architecture is a data processing architecture designed to handle massive quantities of data by taking advantage of both batch and stream processing methods. This hybrid approach aims to balance the trade-offs between latency, throughput, and fault tolerance, making it particularly suitable for real time analytics on large datasets. The architecture processes data in a way that maximizes the strengths of both batch processing—known for its comprehensive and accurate computations—and real time stream processing, which provides low-latency updates.
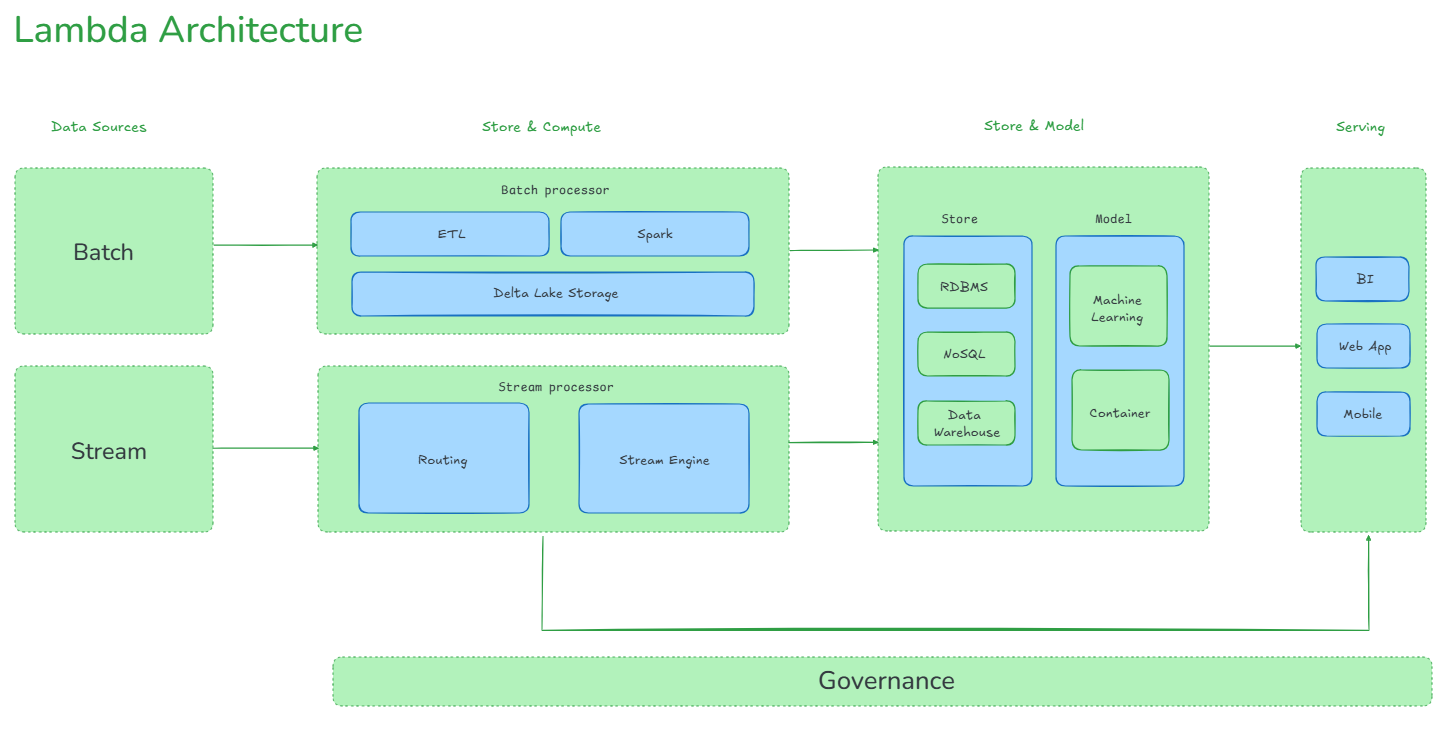
The primary purpose of Lambda Architecture is to enable the processing and analysis of both historical and real time data within a single framework. This dual approach allows organizations to capitalize on the advantages of both processing methods, offering a robust solution for a variety of data processing needs.
Why use Lambda Architecture?
Lambda Architecture addresses several key challenges in big data processing:
1) Handling both historical and real time data: Lambda Architecture allows to process and analyze large volumes of historical data while simultaneously dealing with incoming real time data streams. It achieves this by separating the processing into distinct layers—batch processing for historical data and stream processing for real time data.
2) Balancing latency and accuracy: Lambda Architecture strikes a balance between the high accuracy of batch processing (which handles all data with perfect accuracy) and the low latency of stream processing (which provides near-instant insights with potentially less accuracy).
3) Fault tolerance: Lambda Architecture is designed to be resilient to hardware failures and human errors, guaranteeing data integrity and system reliability.
4) Scalability: Lambda Architecture can handle growing data volumes and increasing processing demands by leveraging distributed computing principles.
Core Key Principles of Lambda Architecture
Lambda Architecture is built on several key principles:
1) Immutable Data: All data entering the system is treated as immutable and append-only. This approach preserves the integrity of the historical record and simplifies data processing by avoiding the complexities associated with data mutations.
2) Recomputation: Lambda Architecture supports the ability to recompute results from raw data. This ensures accuracy and allows for corrections in the data processing pipeline. The architecture maintains consistent and reliable results by recomputing data from the master dataset.
3) Separation of Batch and Speed Layers: Lambda Architecture separates the batch layer (which processes historical data) from the speed layer (which processes real time data). This separation allows for optimized processing in each layer.
4) Serving Layer: The final results from both the batch and speed layers are merged in the serving layer. This layer provides low-latency access to processed data by indexing and storing precomputed views, which can be queried efficiently.
5) Polyglot Persistence: Lambda Architecture supports the use of multiple data storage technologies, optimizing storage solutions based on the specific characteristics of the data (e.g., type, access patterns).
If you want a more in-depth overview of Lambda Architecture, watch this comprehensive video:
What Are the Three Layers of the Lambda Architecture Pattern?
Lambda Architecture consists of three primary layers, each serving a specific purpose in the data processing pipeline.
Let's explore each of these layers in detail:
🗂️ Batch Layer (Batch Processing)
Batch layer, also known as the batch processing layer, is responsible for storing the complete dataset and pre-computing batch views. It operates on the principle of immutability, meaning that once data is ingested, it is never updated or deleted; only new data is appended. This layer processes large volumes of historical data at scheduled intervals, which can range from minutes to days, depending on the application's requirements.
Key characteristics of the batch layer are:
- It handles extensive historical data.
- It allows for comprehensive data analysis and complex computations.
- Data is stored immutably, ensuring a reliable historical record.
- It processes data in scheduled batches.
Technologies commonly used in the batch layer are:
⚡ Speed Layer (Real time / Speed Processing)
Speed layer, also known as the real time or streaming layer, is designed to handle data that needs to be processed with minimal latency. Unlike the batch layer, it doesn't wait for complete data and provides immediate views based on the most recent data.
In the speed layer, incoming data is processed in real time to generate low-latency views. This layer aims to bridge the gap between the arrival of new data and its availability in the batch layer’s views. While the speed layer's results may be less accurate or comprehensive, they offer timely insights.
The speed layer is crucial for applications requiring real time analytics, such as fraud detection, recommendation systems, or monitoring systems where immediate data insights are essential.
Key characteristics of the speed layer are:
- It processes data in real time or near real time.
- It provides low-latency updates to users and applications.
- It handles continuously generated data, such as logs or sensor data.
Technologies commonly used in the speed layer are:
🍴 Serving Layer (Data Access and Queries)
Serving Layer indexes and stores the precomputed batch views from the Batch Layer and the near real time views from the Speed Layer. It provides a unified view for querying and analysis, allowing users to access both historical and real time data efficiently.
Key characteristics of the serving layer are:
- It merges results from the Batch and Speed Layers.
- It provides low-latency access to processed data.
- It supports ad-hoc queries and data exploration.
Technologies commonly used in the serving layer are:
When to Use Lambda Architecture?
Lambda Architecture is particularly useful in scenarios where you need to process and analyze large volumes of data in real time while retaining the ability to run complex queries on historical data. It is most appropriate in environments where data is generated at high velocity and needs to be processed quickly to extract actionable insights—such as in streaming data pipelines.
Lambda Architecture is particularly valuable in the following scenarios:
- When apps need immediate data processing, the low-latency speed layer of Lambda Architecture is useful. This applies to fraud detection systems, network monitoring, and real time recommendation engines.
- When data volumes are huge and traditional frameworks struggle, Lambda Architecture addresses this by dividing the workload between the batch and speed layers. This approach balances trade-offs between accuracy and latency.
- For compliance, audits, or complex analyses, the batch layer of Lambda Architecture maintains an immutable, append-only dataset, ensuring a complete history of data.
Use Cases of Lambda Architecture
1) IoT Data Processing
Lambda Architecture can be effective for processing data from IoT devices, particularly when both real time and historical analysis are required. It allows for immediate processing of sensor data for real time monitoring and control, while also storing data for long-term analysis and machine learning.
2) Customer Analytics
E-commerce platforms can leverage Lambda Architecture to process real time customer interactions (like clicks and purchases) in the speed layer for immediate personalization. Concurrently, the batch layer can analyze long-term customer behavior and trends, enabling businesses to refine their marketing strategies and enhance user experiences based on comprehensive data insights.
3) Log Analytics
Analyzing logs in real time helps you catch and fix issues as they happen. Lambda Architecture is well-suited for log analytics, providing real time alerting and troubleshooting capabilities through the speed layer, while the batch layer handles long-term storage and processing for compliance, historical analysis—and more.
4) Machine Learning Operations (MLOps)
In machine learning, Lambda Architecture facilitates model training on historical data while applying these models to new data streams in real time.
5) Financial Services
In financial services, Lambda Architecture can be used for real time fraud detection and transaction processing (speed layer) while also maintaining accurate, consistent records for reporting and auditing (batch layer).
6) Event Processing
In event-driven systems, such as financial trading platforms, the speed layer handles real time event processing for immediate decision-making. The batch layer can perform comprehensive analyses of historical events, allowing for improved strategy development and risk management.
6) Data Transformation
In environments where you need to transform and enrich data in real time, Lambda Architecture is a lifesaver. It also handles bulk processing for reporting, ETL, or other data tasks.
What Are the Benefits of Lambda Architecture?
Lambda Architecture is a top pick for big data processing because it has several advantages.
1) Fault Tolerance and Data Accuracy
Lambda Architecture ensures high fault tolerance by combining batch and real time processing. If real time data processing encounters errors, the batch layer, which processes data comprehensively, can correct these errors, ensuring data integrity. The immutable, append-only nature of the batch layer also allows for easy recovery in case of failures.
2) Flexible Scaling
Lambda Architecture is built to handle large volumes of data efficiently. The distributed nature of its components allows for easy horizontal scaling by adding more nodes to the system.
3) Versatility
Lambda Architecture supports both real time and historical data analysis, making it ideal for applications that require timely insights while still being able to perform deep analysis on historical data.
4) Business Agility
Lambda Architecture allows users/businesses to react quickly to changing conditions by processing data in real time, which is crucial for dynamic environments like e-commerce, finance, and IoT.
5) Automated High Availability
Lambda Architecture can be designed to ensure high availability and fault tolerance, minimizing the risk of downtime and ensuring consistent data processing.
6) No Server Management
Lambda Architecture eliminates the need for manual server management, reducing the operational overhead related to the installation, maintenance, and administration of the infrastructure.
What Are the Disadvantages of Lambda Architecture?
Despite its benefits, Lambda Architecture also has some disadvantages:
1) Complexity
One of the main disadvantages of Lambda Architecture is its inherent complexity. The architecture consists of multiple layers—batch, speed, and serving—each requiring distinct technologies and frameworks. This complexity can pose significant challenges for admins, who often need to maintain two separate code bases for the batch and streaming layers. The operational overhead of managing these diverse components can be daunting, leading to increased maintenance burdens.
2) Logic Duplication
Another issue with Lambda Architecture is the duplication of logic. Since the batch and speed layers often require similar processing logic, engineers may find themselves maintaining redundant code across both layers. This duplication not only consumes additional time and resources but also complicates updates and debugging, as changes must be replicated in multiple places.
3) Inefficient Batch Processing
In certain scenarios, the need to reprocess entire batch cycles can lead to inefficiencies. Running both the batch and speed layers in parallel may waste computing resources, particularly if the batch processing is not optimized. This inefficiency can slow down the overall data pipeline, negating some of the benefits of real time processing offered by the speed layer.
4) Difficulty Reorganizing Data
Data management can also be challenging within Lambda Architecture. Once a data set is modeled using this architecture, reorganizing or migrating that data can be extremely difficult.
5) Maintenance and Support
The maintenance and support of a Lambda Architecture can be quite challenging due to the need to keep the batch and speed layers in sync. Ensuring consistent and accurate results when queries touch both pipelines requires ongoing effort and can lead to increased costs. This synchronization is crucial but can be difficult to achieve, especially as the system scales.
6) Skill Issue
Finally, the skill requirements for implementing and managing a Lambda Architecture can be a barrier. Organizations may struggle to find personnel with the necessary expertise in the various technologies that need to be mastered to construct a Lambda-driven system. This skills gap can hinder the successful deployment and operation of the architecture.
Want to Learn More?
- Lambda Architecture Basics (Databricks)
- Lambda Architecture (Snowflake)
- Lambda Architecture (Wikki)
- Databricks Delta Lake 101
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Conclusion
And that’s a wrap! Lambda Architecture is a super powerful and flexible way to process data. It combines the best of both worlds: batch and real time processing. You get major benefits like scalability, fault tolerance, and real time insight. But, it can get pretty complex and be a pain to maintain. If you get how it works and when to use it, you can harness its power to crunch massive amounts of data and uncover valuable insights.
In this article, we have covered:
- A brief overview of data processing architectures
- What is Lambda Architecture?
- What are the three layers of the Lambda Architecture pattern?
- When to use Lambda Architecture
- What is the difference between Lambda Architecture and Kappa Architecture?
- What is the difference between Delta and Lambda Architecture?
- What are the benefits of Lambda Architecture?
- What are the disadvantages of Lambda Architecture?
… and so much more!
FAQs
What is the Lambda Architecture concept?
Lambda Architecture is a data processing architecture designed to handle massive quantities of data by using both batch-processing and stream-processing methods.
What are the 4 characteristics of Lambda Architecture?
The four main characteristics of Lambda Architecture are scalability (handling large data volumes), fault-tolerance (ensuring data processing continues despite failures), extensibility (easily adapting for new use cases), and low-latency (providing real time data processing capabilities).
What is Lambda and Kappa architecture?
- Lambda Architecture uses both batch and stream processing to handle large-scale data processing. It consists of three layers: Batch Layer, Speed Layer, and Serving Layer.
- Kappa Architecture simplifies the data processing pipeline by using only stream processing. It treats all data as streams, eliminating the need for a separate batch layer.
What are the three layers of the Lambda Architecture pattern?
The three main layers of the Lambda Architecture pattern are the Batch Layer, Speed Layer(or real time), and Serving Layer.
Why is it called Kappa architecture?
Kappa Architecture is named to differentiate it from Lambda Architecture. It focuses solely on stream processing, eliminating the batch layer to simplify the architecture and reduce latency.
What is delta architecture?
Delta Architecture is a data processing architecture that combines the best features of data warehouses, data lakes, and streaming. It uses Delta Lake to provide ACID transactions, scalable metadata handling, and unifies batch and streaming data processing.
Can Lambda Architecture be used with cloud services?
Yes, it can be implemented using cloud services
How does Lambda Architecture scale?
Lambda Architecture scales horizontally by adding more nodes to handle increased data volume.









