





























Data doesn't come in one flavor anymore. Today's data ecosystem is a mix of formats, from structured data to unstructured data , and semi-structured data. Excel files sit right in the middle, blending elements of both structured and unstructured data and is widely used in business intelligence and data analysis. However, integrating and importing these seemingly straightforward .xlsx excel files into advanced platforms like Databricks often presents a technical challenge, requiring a clear understanding of tools and workflows to bridge the gap effectively.
In this article, we walk you through the step-by-step guide to import, process and read Microsoft Excel files in Databricks, covering two main techniques: using Pandas with PySpark and leveraging the com.crealytics.spark.excel library.
Why Work with Microsoft Excel Files in Databricks?
Microsoft Excel files are everywhere—used for reporting, ad hoc analysis, and data sharing. Here’s why importing Excel files into Databricks can be valuable:
- Databricks, powered by Apache Spark, processes large datasets that Microsoft Excel alone cannot handle.
- Automate data transformations, cleaning, and enrichment for Microsoft Excel data.
- Merge Microsoft Excel data with other data sources in your pipeline.
- Apply machine learning models and other analytics directly to Microsoft Excel datasets.
Save up to 50% on your Databricks spend in a few minutes!


Step-by-Step Guide to Import and Read Excel Files in Databricks
Now, let's dive straight into the main content of this article. We will dive into an in-depth, step-by-step guide on how to import and read Excel files in Databricks. Here, we'll cover two approaches: one using Pandas and another leveraging the com.crealytics.spark.excel library. So, let's dive right in.
Prerequisites
But wait, before you start, make sure you have the following:
- Databricks account and access to a Databricks workspace.
- Familiarity with Python programming and Apache Spark is essential for working with Databricks.
- Make sure the necessary libraries are installed. If not, don't worry; we will cover this in detail later. The required libraries are:
Pandas—A powerful data manipulation and analysis library for Python.OpenPyxl—A library used to read and write Excel 2010 xlsx/xlsm/xltx/xltm files.com.crealytics.spark.excel— A Spark plugin that allows you to read and write Excel files.
- Permissions to interact with the Databricks File System (DBFS) to manage and access your files.
- Make sure you have the correct file path details in DBFS to locate and manage your files effectively.
With these prerequisites in place, you are now ready to import, process, and read Excel files in Databricks.
🔮 Technique 1—Using Pandas and PySpark to Import Excel Files
Let's first start with our first technique. This approach is straightforward and Pythonic, which is perfect for small to medium-sized Microsoft Excel files.
Step 1—Log in to Databricks Workspace
First, log in to your Databricks account and open your Databricks workspace.

Step 2—Set Up Databricks Compute
Next, you need to set up Databricks compute clusters. You can create a new one or use an existing one that will run your Databricks Notebook.
Step 3—Open Databricks Notebook
Now it's time to create a new Databricks Notebook. This is where you will write all your code and install the necessary libraries.
Once you have created your Databricks Notebook, let's attach the Databricks compute that you created earlier and attach it to that particular Databricks Notebook.
Step 4—Install and Import Necessary Libraries
You need the openpyxl library for reading Excel files and pandas for data manipulation and analysis. Install it using the following command:
%pip install pandas openpyxl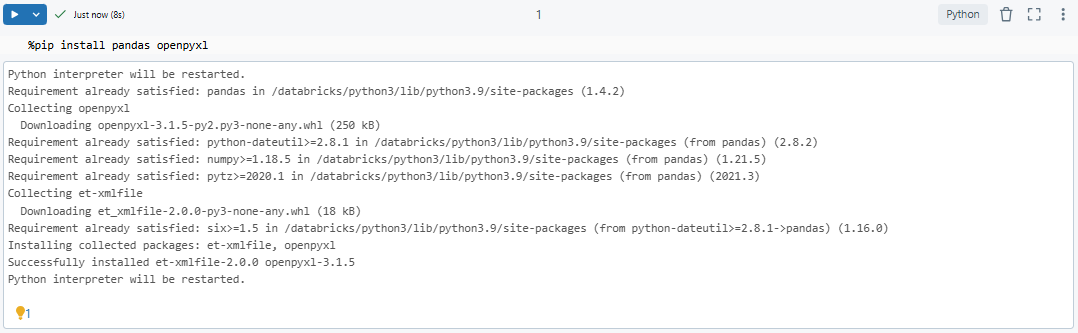
You can also install it directly on your cluster through the Libraries interface.
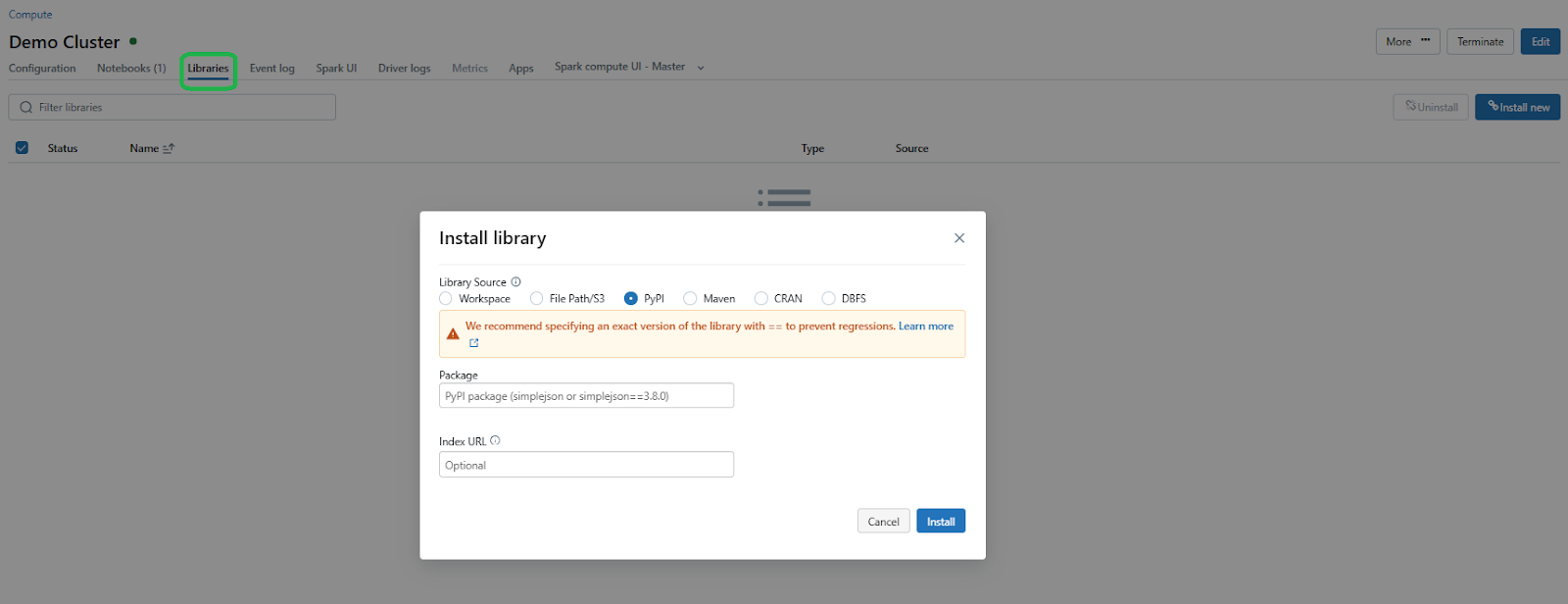
Step 5—Configure Databricks File System (DBFS)
Let's move on to the next step, where we'll configure the Databricks File System, also known as DBFS. DBFS allows you to manage files within Databricks.
To enable Databricks DBFS, click on the user icon located in the top right corner. Then, select the Settings option, which will redirect you to the Settings page.
From there, head over to the Advanced section and search for “DBFS” in the search bar. You should now see an option to enable DBFS.
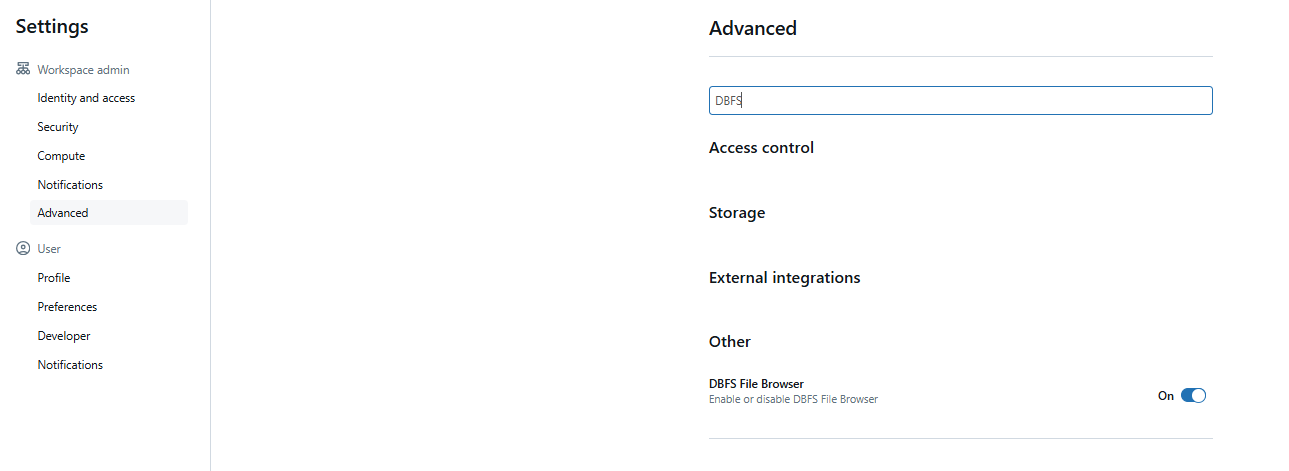
Check the box next to Enable DBFS File Browser and then refresh the page for the change to take effect.
You should see a new tab called “DBFS” in the Catalog section, located next to Database tables.
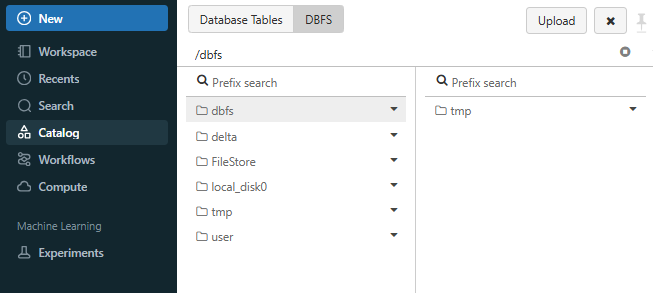
Check out this article, for more indepth info on setting up and configuring Databricks DBFS.
Now that we have successfully activated DBFS, let's upload an Microsoft Excel file.
Step 6—Upload Microsoft Excel Files to Databricks File System (DBFS)
Now that DBFS is configured for file uploads, here’s how to get started:
In the DBFS tab, look for the Upload button—it’s typically located in the top-right corner. Click on it, and a popup window will appear, navigate to your desktop (or wherever your file is stored on your local machine), and select the file you want to upload.
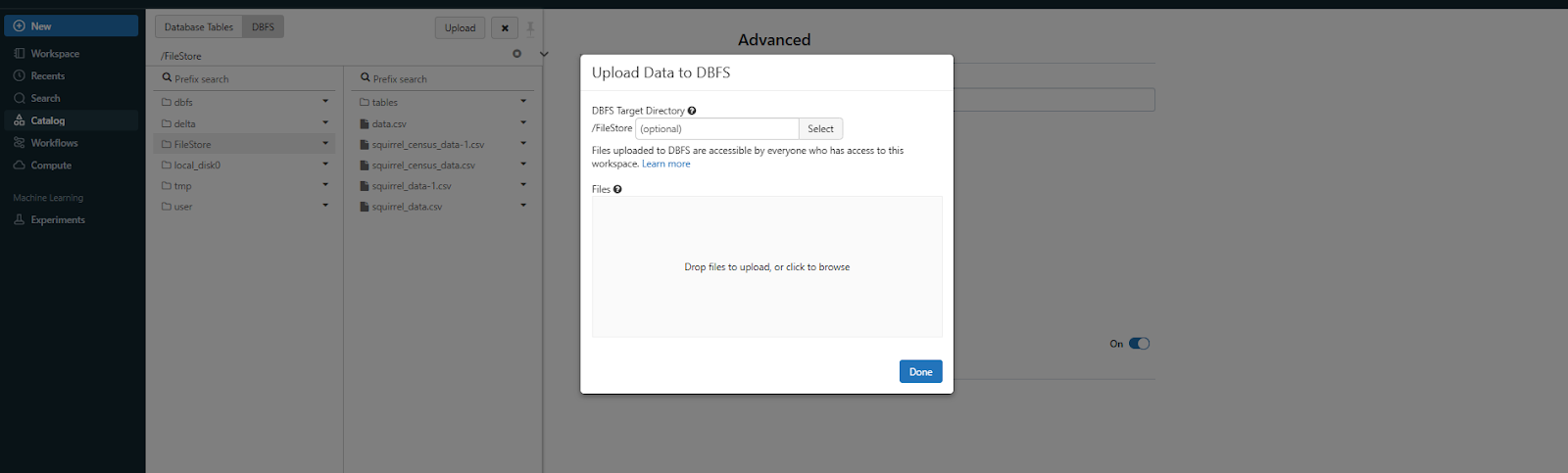
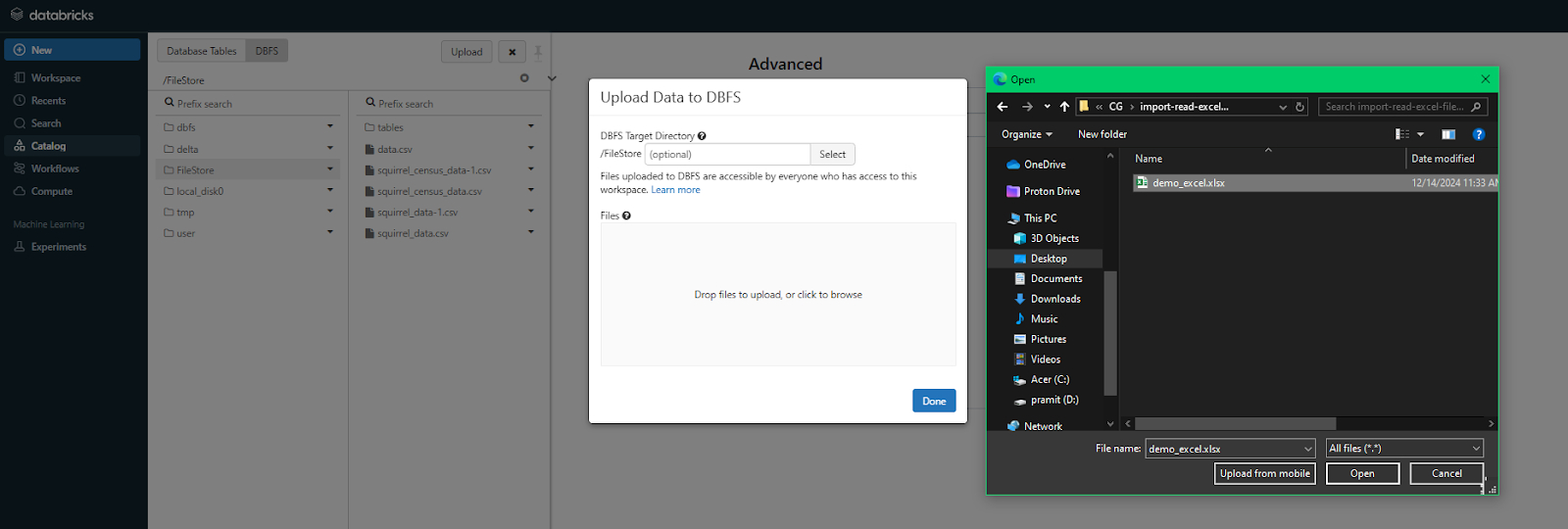
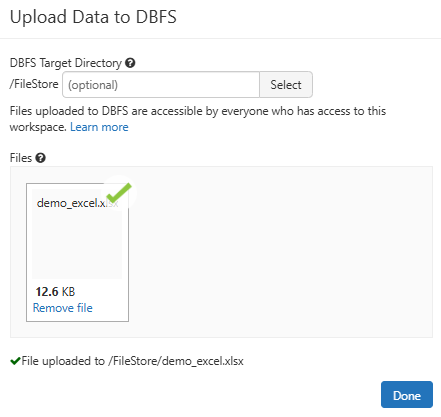
Step 7—Verify Uploaded Excel File
Once the Excel file is uploaded, head back to the Databricks Notebook and write the following line of code.
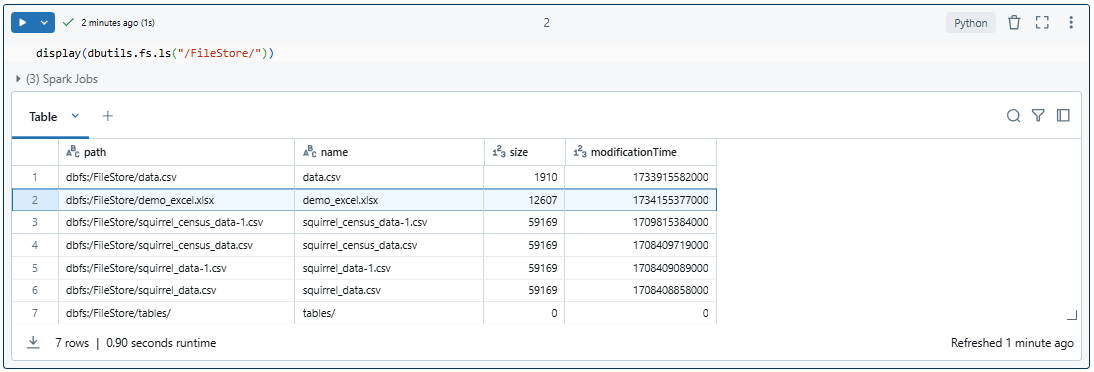
As you can see, it will show the user all the files available in /FileStore of Databricks File System (DBFS).
Step 8—Read Microsoft Excel File Using Pandas
Now that we know the File Format API location, lets read the file using Pandas. Here’s how to load a Microsoft Excel file into a Pandas DataFrame:
import pandas
import openpyxl
df = pandas.read_excel("/dbfs/FileStore/demo_excel.xlsx", engine='openpyxl')As you can see, pandas.read_excel() can automatically handle Excel files. Note that explicitly importing openpyxl is generally not needed.
Step 9—Check DataFrame properties
You can check the properties of your DataFrame using:
print("Shape:", df.shape) # Returns number of rows and columns
print("Columns:", df.columns) # Returns column names
print("Data Types:", df.dtypes) # Returns data types of each column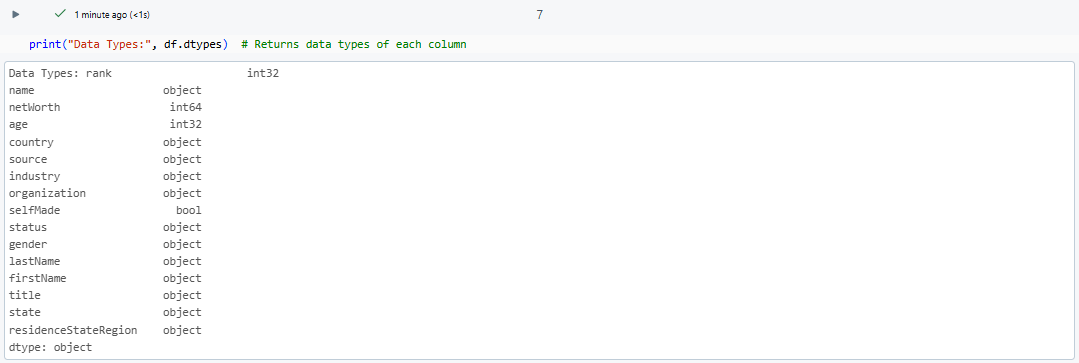
print("First 5 rows:\n", df.head()) # Returns first 5 rows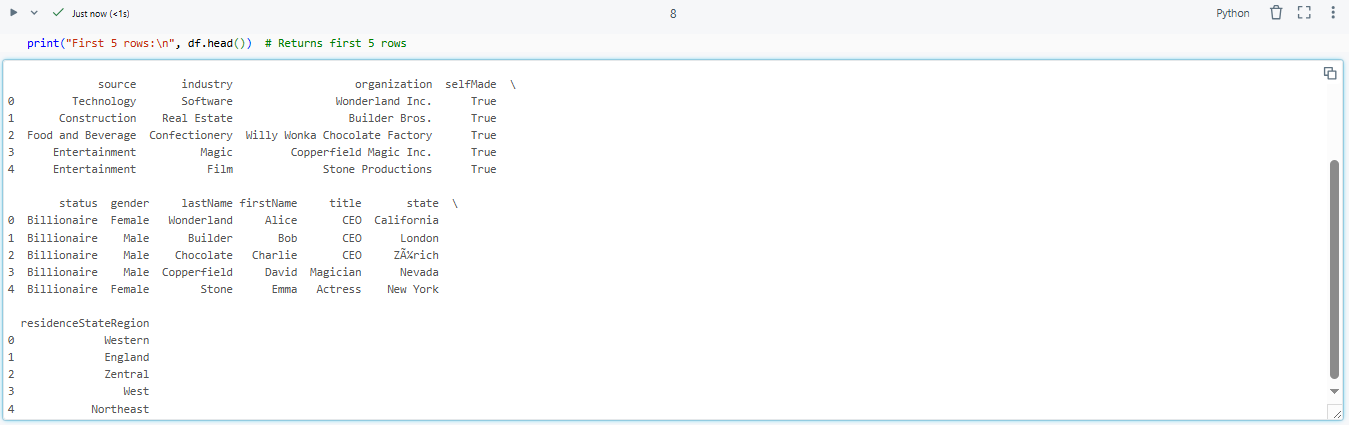
print("Last 5 rows:\n", df.tail()) # Returns last 5 rows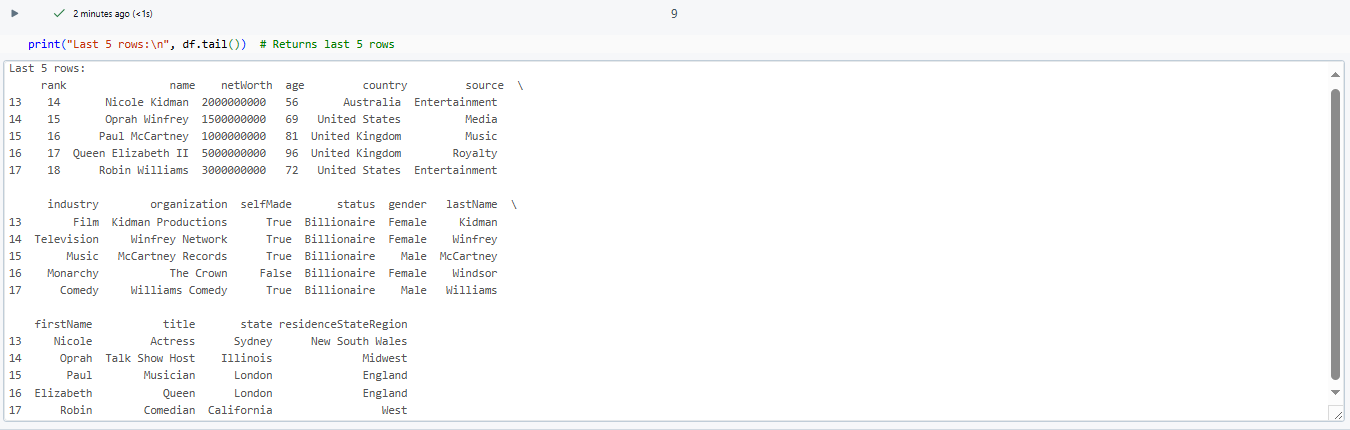
print("Summary statistics:\n", df.describe()) # Summary statistics (for numerical columns)
Step 10—Convert Pandas DataFrame to Spark DataFrame
To leverage Spark's or Databricks capabilities, convert your Pandas DataFrame into a PySpark DataFrame using spark.createDataFrame() command. Here is what your final code should look like:
import pandas as pd
import openpyxl
df = pd.read_excel("/dbfs/FileStore/demo_excel.xlsx", engine='openpyxl')
# Converting Pandas DataFrame to PySpark DataFrame
spark_df = spark.createDataFrame(df)
spark_df.show()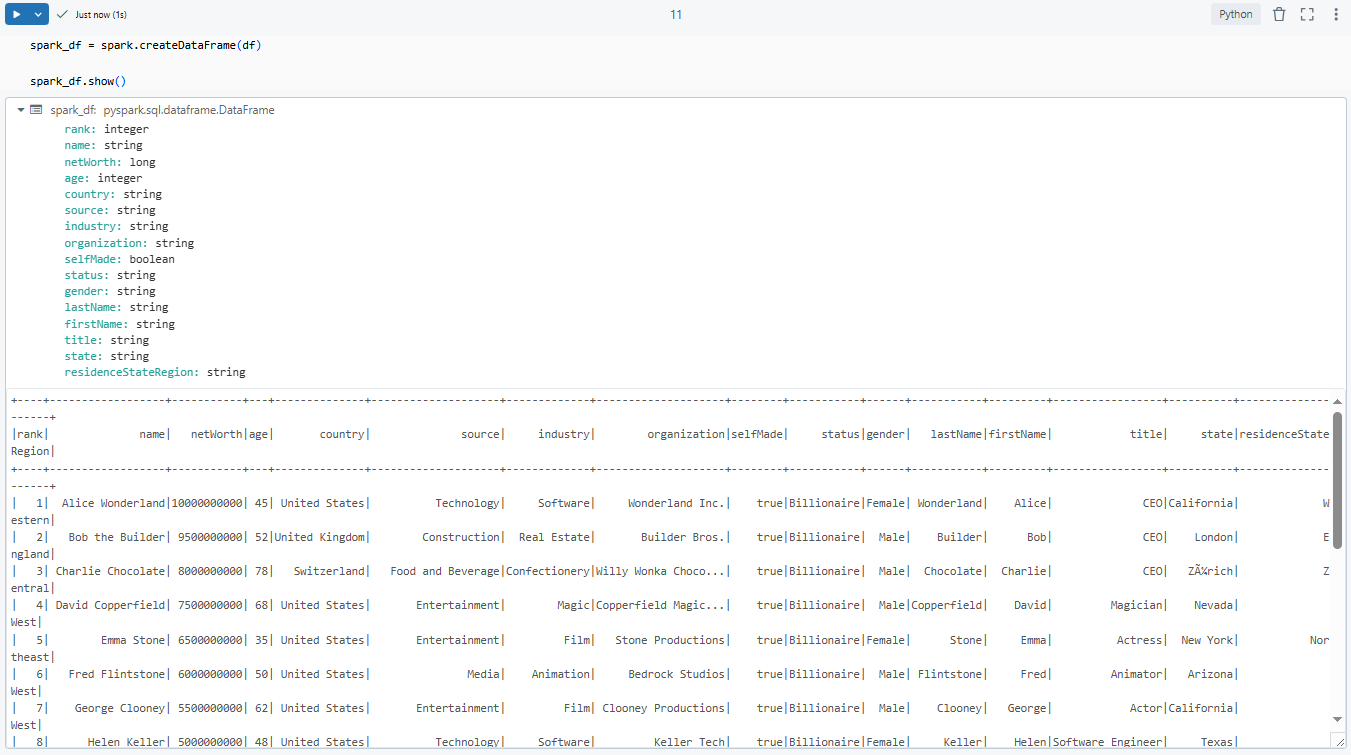
When working with Excel files, this technique uses Pandas to get the initial data, then converts it into a PySpark DataFrame for easier processing with Spark. Just keep in mind that Pandas can struggle with complex Excel features and formats. Before using this method, make sure it works with your specific data and Excel files.
🔮 Technique 2—Using com.crealytics.spark.excel Library
Now that we've covered the first technique, let's move on to the second. This one's a bit longer to set up, but it's actually pretty simple to use. We'll be working with the Spark Excel library to read Excel files in Databricks, so let's take a closer look.
Step 1—Log in to Databricks Workspace
As before, the first step is to log in to your Databricks account and navigate to your workspace. Once logged in, make sure you have access to the Databricks workspace where you want to process the Microsoft Excel file.
Step 2—Set Up Databricks Compute
Next, set up a Databricks compute cluster. You can either select an existing Databricks compute or create a new one. Make sure the cluster has sufficient resources to handle your workload and is configured with the necessary runtime version.
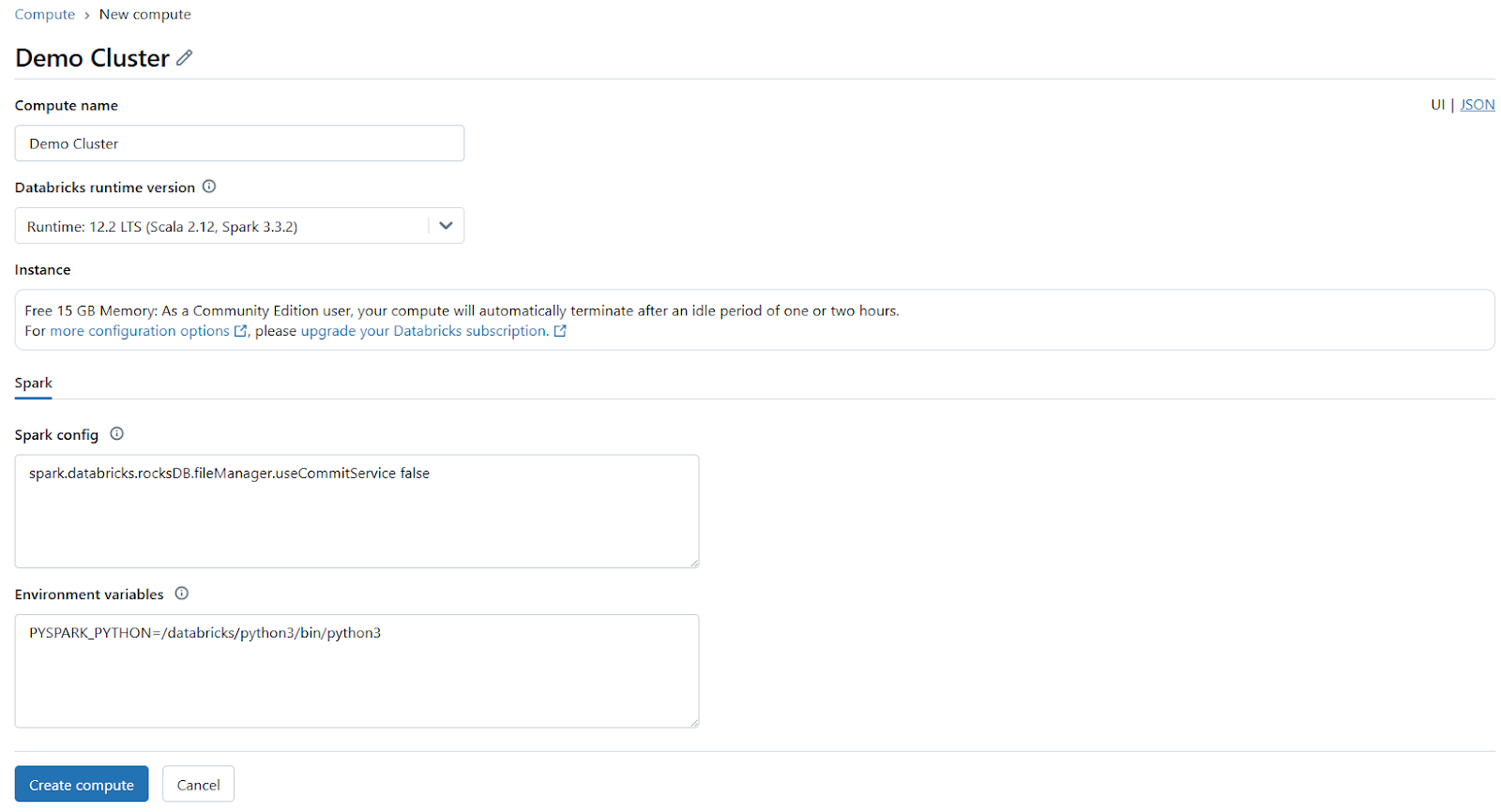
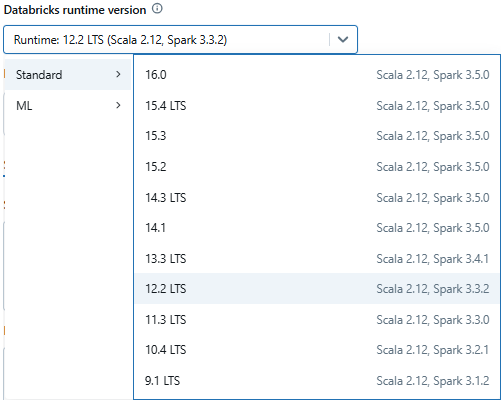
Step 3—Navigate to Compute and Select Your Running Cluster
After setting up the cluster, navigate to the Compute section in your Databricks workspace and select the Databricks compute you plan to use. Check that the cluster is running before proceeding further.

Step 4—Go to Libraries and Install Maven
To install the required library, go to the Databricks compute details page and navigate to the Libraries tab.
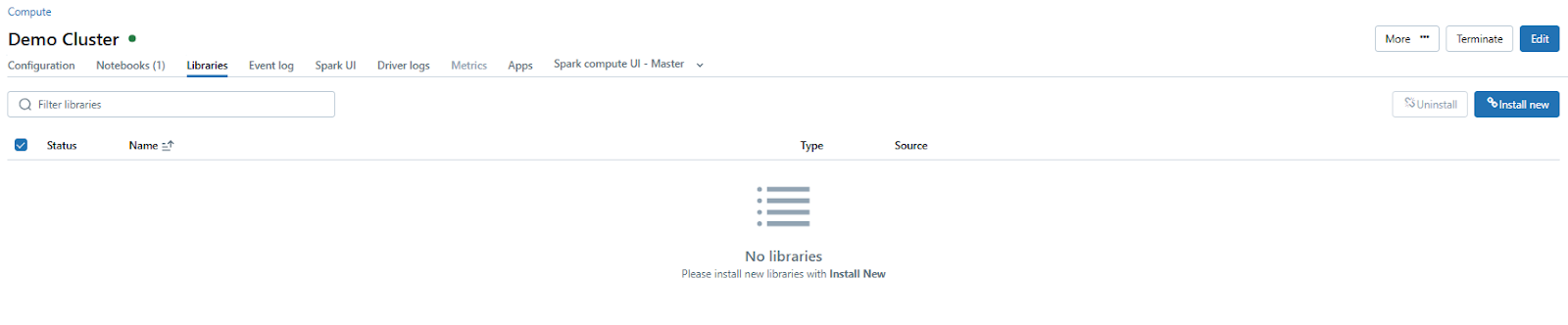
Click on Install New and choose Maven as the library source. Maven Library source is a tool for installing external libraries and packages on a Databricks cluster using Maven Coordinates.
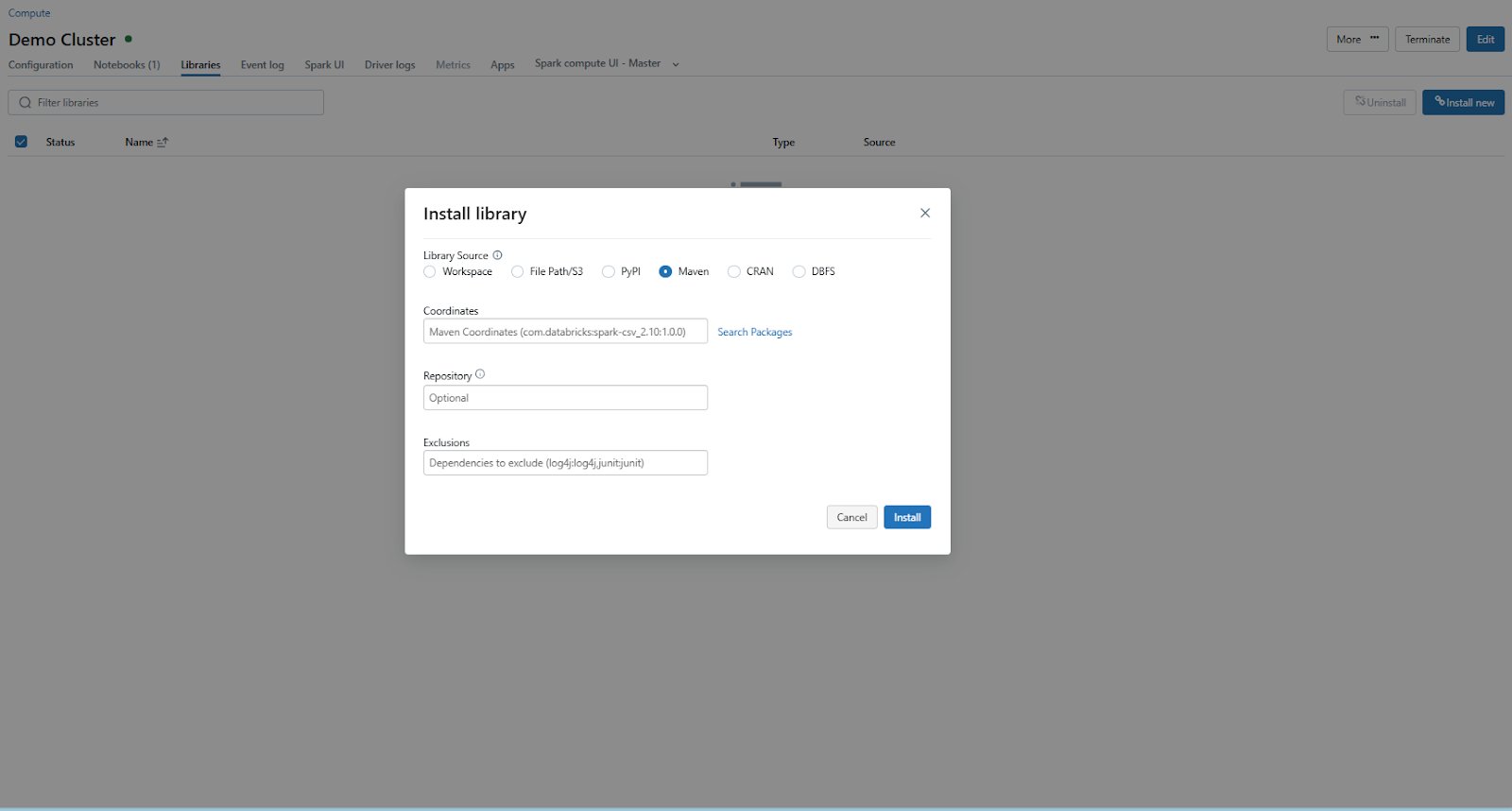
In the Maven tab, click on Search Packages, which will open a package search window.
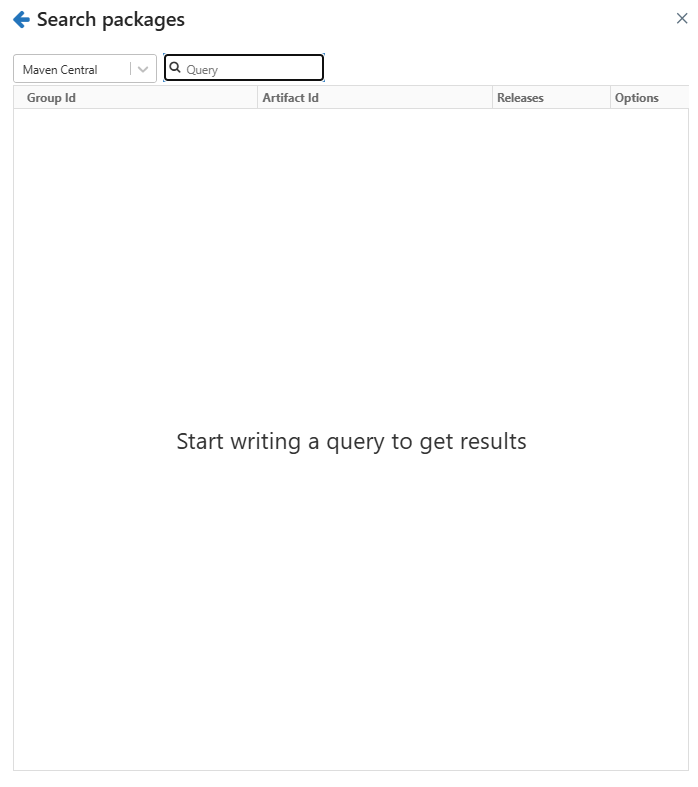
Step 5—Search for and Install com.crealytics.spark.excel Library
In the package search window, search for spark-excel and select the appropriate version of the library that matches your Databricks runtime and Scala version. For instance, if you are using Databricks Runtime 12.2 LTS (Apache Spark 3.3.2, Scala 2.12), select the compatible Scala 2.12 version of the library. Once you have selected the correct version, install the library. After successful installation, the library will appear in the cluster's library list.
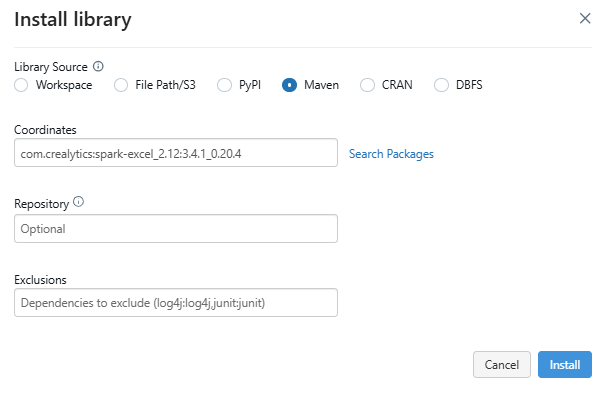

Step 6—Read Excel File Directly into a Spark DataFrame
With the library installed, you can now read the Excel file into a Spark DataFrame. Use the following code snippet to load your Excel file:
spark_df = spark.read.format("com.crealytics.spark.excel") \
.option("header", "true") \
.option("inferSchema", "true") \
.load("/dbfs/FileStore/demo_excel.xlsx")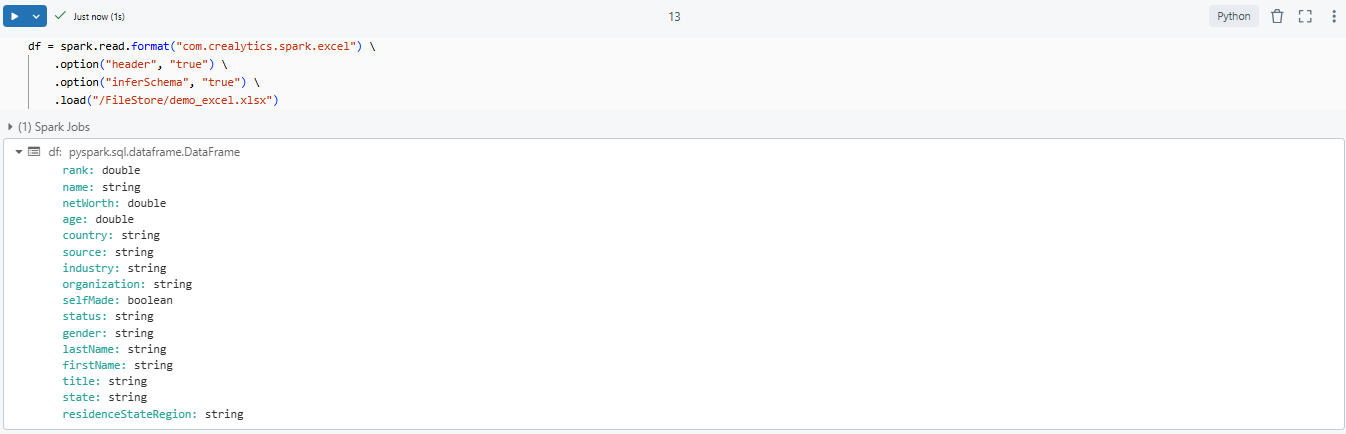
As you can see, here:
format("com.crealytics.spark.excel")— Specifies the library to use for reading Excel files..option("header", "true")— Indicates that the first row of the Excel file contains column headers..option("inferSchema", "true")— Automatically infers the schema of the data..load("/<file_path>/<file_name>.xlsx")— Specifies the file path of the Excel file.
Step 7—Validate Data
Finally, use the display() function to visualize the loaded DataFrame and validate that the data has been read correctly. You can perform additional transformations or analysis on the DataFrame as needed.
display(spark_df);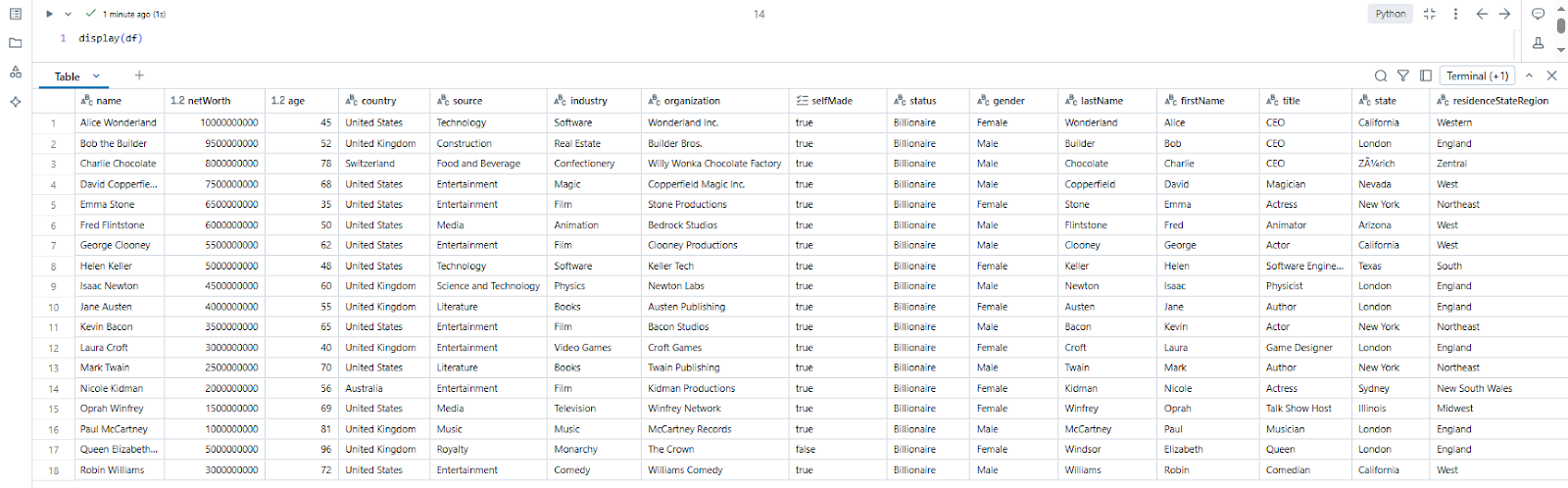
Technique 1 vs Technique 2: Which One Should You Choose?
| 🔮 | Technique 1 (using Pandas) | Technique 2 (using spark-excel library) |
| Pros |
|
|
| Cons |
|
|
TL;DR: Use Pandas with openpyxl for smaller files and com.crealytics.spark.excel for larger or more complex workloads.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Conclusion
And that's a wrap! Importing and reading Excel files in Databricks is surprisingly easy. This opens up a world of possibilities for data analysis, automation, and integration within your data pipelines. You can tackle anything from small datasets to large, complex workloads with Databricks' robust tools and libraries that make incorporating Excel data into your workflows a breeze.
In this article, we have covered two effective techniques for handling Excel files in Databricks—using Pandas for straightforward tasks and the com.crealytics.spark.excel library for optimized, scalable processing. You're all set to integrate Excel files into your analytics and machine learning workflows. From setup to data validation, you now have a solid understanding of how to handle Excel files with confidence in Databricks.
FAQs
Can Databricks read Excel files directly?
Yes, Databricks can read Excel files directly by using libraries such as com.crealytics.spark.excel for Spark-based processing or Pandas with OpenPyxl for smaller datasets.
How do I import an Excel file into Databricks?
You can import an Excel file by uploading it to DBFS (Databricks File System) and then reading it using either the com.crealytics.spark.excel library for Spark DataFrames or Pandas for smaller data loads.
How do I upload files to DBFS?
To upload files to DBFS, use the following steps:
- Navigate to the Catalog section.
- Switch to the DBFS tab, click Upload, and choose Upload File.
- Select your file and upload it. The file will be stored in the /FileStore directory of DBFS.
- Or, you can use the Databricks CLI or REST API for programmatic uploads.
Can you import a file into Databricks?
Yes, Databricks allows you to import various file types, including Excel, CSV, and JSON. Files can be uploaded to DBFS or accessed via mounted external storage systems like AWS S3, Azure Blob Storage, or Google Cloud Storage.
What library is best for large Excel files?
For large Excel files, com.crealytics.spark.excel is recommended because it leverages Spark’s distributed computing capabilities, enabling efficient processing of large datasets.
Can Databricks export data back to Excel?
Yes, Databricks can export data to Excel. Convert the DataFrame to a Pandas DataFrame and then save it to an Excel file using Pandas’ to_excel() method with libraries like OpenPyxl.
How do I handle missing data in Excel files?
After loading the Excel file into a DataFrame, use Spark or Pandas functions to handle missing data:
- Fill missing values: Use .fillna(value) to replace missing values with a default value.
- Drop missing rows: Use .dropna() to remove rows with missing values.
- Custom handling: Apply transformations or conditional logic based on your analysis requirements.
How do I read an Excel file in Databricks using PySpark?
Use either Pandas with OpenPyxl or the com.crealytics.spark-excel library for direct reading into Spark DataFrames.
How can I install necessary libraries like Pandas and OpenPyxl in Databricks?
To install libraries in Databricks, use one of the following methods:
- Via Databricks Notebook command: Use
%pip install <library_name>in a notebook cell. - Via Databricks Cluster libraries: Navigate to the Libraries tab in the cluster details page, click Install New, and choose PyPI or Maven to install the desired library.
Can I read multiple Excel files from a directory into a single DataFrame?
Yes, you can read multiple Excel files by iterating through the directory and concatenating the data into a single DataFrame. Here is an example using Pandas:
import pandas
import os
path = "/path/to/directory"
all_files = [os.path.join(path, file) for file in os.listdir(path) if file.endswith('.xlsx')]
# Read and concatenate files
dataframes = [pandas.read_excel(file) for file in all_files]
final_df = pandas.concat(dataframes, ignore_index=True)
Can I use R to read Excel files in Databricks?
Yes, you can use R to read Excel files in Databricks by installing the readxl or openxlsx package. For example:
library(readxl)
data <- read_excel("/dbfs/FileStore/path_to_file.xlsx")














