




























The idea of a data lakehouse has fundamentally changed how we handle and analyze big data. The data lakehouse architecture blends the best of data warehouses and data lakes. It provides high speed and flexibility, which are vital for modern data analytics. At the heart of a data lakehouse are the table formats used to store and manage data. These formats ensure data integrity. They support ACID transactions and have features like time travel and schema evolution. Two table formats are popular in this space: Apache Iceberg and Delta Lake. They have different origins and capabilities. Apache Iceberg was developed by Netflix. It is now a project of the Apache Software Foundation. It is fully open source, community-driven, and works with multiple query engines. Delta Lake was created by Databricks. It is now part of the Linux Foundation. It has deep integration with Databricks and Apache Spark. Selecting the appropriate table format is crucial to unlock the full potential of a data lakehouse.
In this article, we will compare Apache Iceberg and Delta Lake across several areas: origin, architecture, metadata management, query engine compatibility, and ACID transactions.
What is Apache Iceberg?
Apache Iceberg is open source. It’s a high-performance table format for large analytic datasets in data lakes. It brings the reliability and simplicity of SQL tables to big data. It supports many data engines like Spark, Trino, Flink, Presto, Hive and Impala. Iceberg fixes performance, usability and correctness issues that are built into older table formats like Hive. It’s a modern data lake solution.

Why should I use Apache Iceberg?
Here are some key reasons why you should choose Apache Iceberg:
1) ACID Transactions: Apache Iceberg ensures correctness with atomicity, consistency, isolation, and durability (ACID) transactions. Multiple concurrent transactions can happen without data corruption or conflicts.
2) Schema Evolution: Allows schema changes over time without pausing queries or doing complex migrations. Supports adding, dropping, and renaming columns seamlessly.
3) Hidden Partitioning: Manages partitioning internally. So you can optimize queries and avoid full table scans.
4) Time Travel: Lets you query old data. For auditing and debugging. You can access old versions of the dataset.
5) Partition Evolution: Supports changes to a table’s partitioning scheme. So you can change how data is organized and accessed. Without rewriting the whole dataset.
6) Optimized Metadata Management: Uses a multi-layer metadata system with manifest files, manifest lists, and metadata files to improve query planning and execution. This structure avoids expensive operations like file listing and renaming.
7) Support Multiple File Formats: Works with many file formats. Apache Parquet, Avro, Apache ORC. So you can use your existing data infrastructure and workflows.
8) Compatibility with Multiple Engines: Works with various data processing engines like Apache Spark, Apache Flink, Presto, Trino, Apache Hive, Apache Impala, Dremio.
9) Advanced Data Compaction: Uses data compaction to reduce storage and speed up reads. Merges small files into big ones.
10) Built-in Catalog: Has an internal catalog for table metadata. Also integrates with external catalogs like Hive Metastore and AWS Glue.
For more in-depth info on Delta Lake use cases, see Snowflake Iceberg Table 101.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

What is Delta Lake?
Delta Lake is an open source storage layer that provides reliable and high-performance storage for data lakes. Built by Databricks, it extends Parquet data files with a transaction log, ensuring ACID transactions and scalable metadata handling. Delta Lake supports both batch and streaming data so you can handle all your data workloads in one place. It is fully compatible with Apache Spark APIs and integrates with many data processing engines.

Why Delta Lake Is Better?
Here are some key reasons why Delta Lake is better:
1) ACID Transactions: Guarantees data reliability and consistency through serializability, the highest level of isolation for transactions. No conflicts, no data loss even in case of system failures.
2) Scalable Metadata Handling: Manages metadata for petabyte-scale tables with billions of partitions and files, using Spark’s distributed processing.
3) Time Travel: Lets you go back in time and access previous versions of your data, for audits, rollbacks and reproducibility of data states.
4) Schema Enforcement and Evolution: Enforces schemas to prevent data corruption and supports schema evolution, so you can add, drop or modify columns without disrupting existing data flows.
5) Batch and Streaming: Binds batch and streaming data processing together, with exactly-once processing semantics and incremental data processing.
6) Audit History: Keeps a complete audit trail of all changes to the data, for transparency and data governance.
7) Optimized Performance: Improves query performance with data skipping and Z-ordering which co-locates similar data to reduce query times. Also supports liquid clustering for flexible and cost-effective data layout management.
8) Open Source: Delta Lake is an open source project. It is open to contributions and follows open standards.
For more in-depth info on Delta Lake use cases, see Databricks Delta Lake 101.
Delta Lake transforms traditional data lakes. It adds better reliability, speed, and management.
Apache Iceberg vs Delta Lake—High-level Summary
If you're in a hurry, here is a quick high-level summary of Apache Iceberg vs Delta Lake:
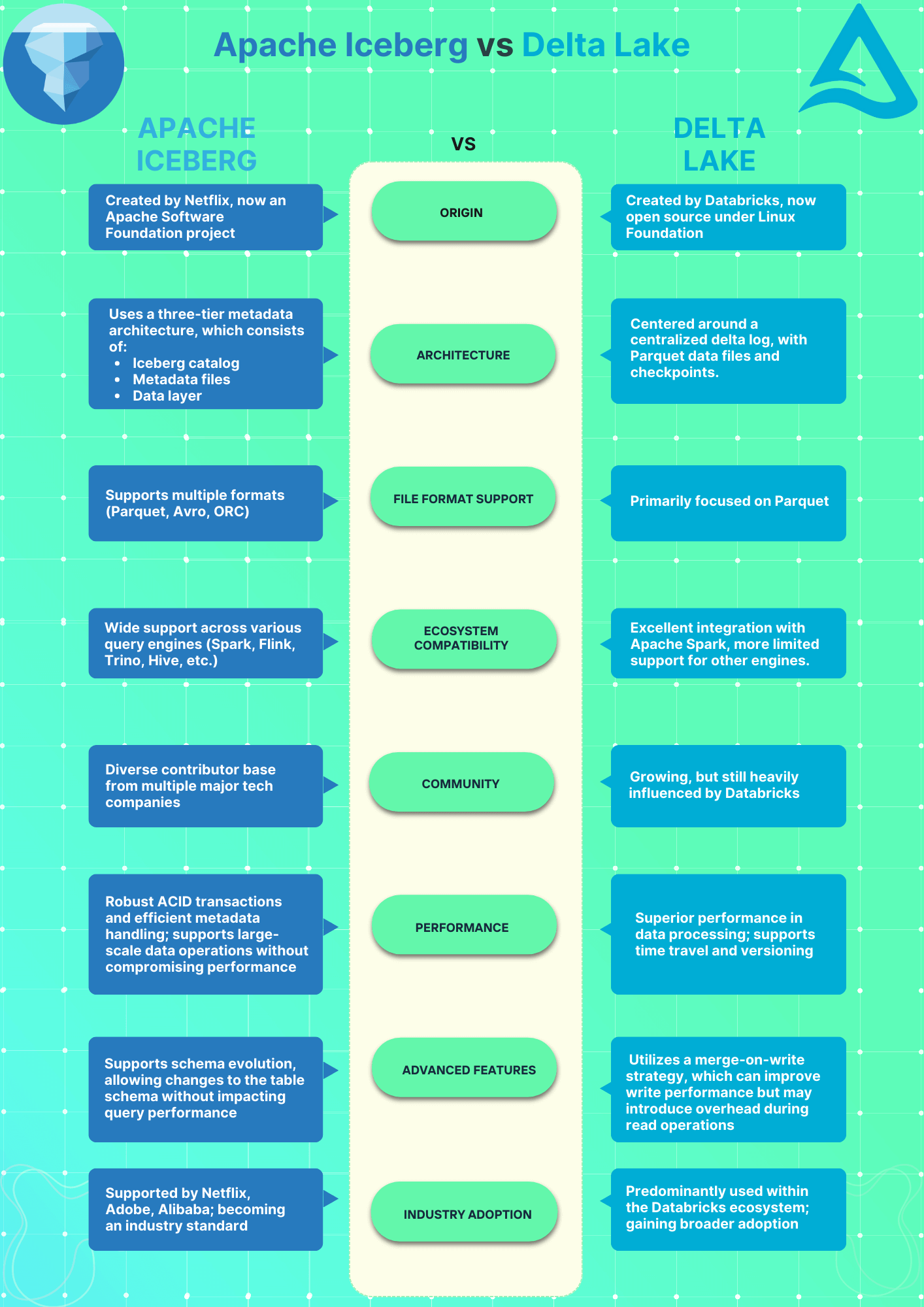
Origins and Development—Apache Iceberg vs Delta Lake
Let's go back to the start and understand how these technologies came to be. So, how did Apache Iceberg vs Delta Lake get their start?
Apache Iceberg—Netflix's Gift to the Big Data World
Apache Iceberg was started at Netflix by Ryan Blue and Dan Weeks in 2017 to fix the problems with existing data lake solutions, particularly Apache Hive. It was designed to ensure data correctness, ACID transactions, and performance for large data lakes. Netflix donated Iceberg to the Apache Software Foundation (ASF) in 2018.
Delta Lake—Databricks' Journey from Proprietary to Open Source
Meanwhile, as Netflix was developing Apache Iceberg, Databricks was whipping up its own big data game-changer. Founded by the geniuses behind Apache Spark, the company was tackling the same big data storage and processing headaches.
Delta Lake started as a proprietary technology. It was tightly integrated with Databricks' cloud platform and was designed to bring ACID transactions, scalable metadata handling, and time travel capabilities to data lakes built on cloud storage. In an unexpected turn of events, Databricks chose to make Delta Lake open source in 2019.
Architecture Differences—Apache Iceberg vs Delta Lake
Now that we know the origins of these technologies, let's pop the hood and take a look at how they're built.
Apache Iceberg—A Three-Tiered Approach
Iceberg uses a three-tier metadata architecture, which consists of the Iceberg catalog, metadata files, and data files.
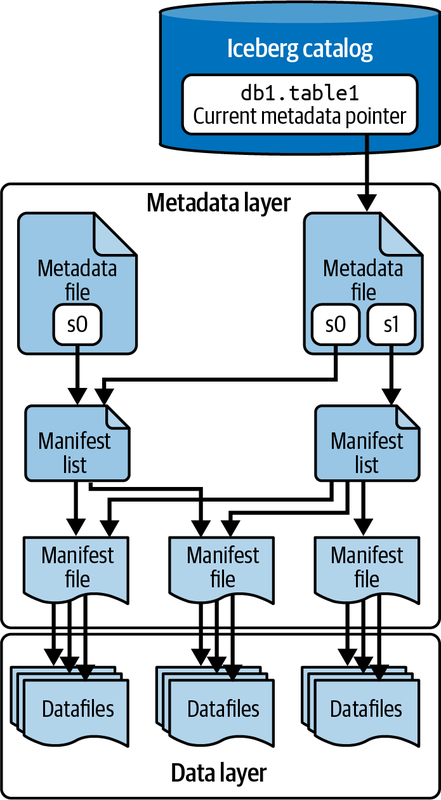
1) Iceberg Catalog: The Iceberg Catalog manages the namespaces and tables, it provides a consistent view of the table’s metadata. This catalog is responsible for storing and organizing metadata, so you can list tables, create or delete tables and track table versions. Iceberg supports multiple external catalog implementations like Hive Metastore, AWS Glue and custom catalogs.
2) Metadata Layer: Below the catalog layer is the Metadata Layer which consists of:
- Metadata Files: These files store information about the table, schema, partitioning info and snapshots. They also track the history of changes and the current state of the table.
- Manifest Lists: These lists contain references to manifest files and high level statistics and partition information so you can access and filter data efficiently.
- Manifest Files: These files list individual data files along with their statistics like record count and column bounds. They allow you to track and manage data at file level.
3) Data Layer: Data Layer is the bottom of Iceberg tables, it holds the actual data files. These files can be in Parquet, Avro or ORC format. The data layer is optimized for querying and data management, it supports partitioning which groups similar rows together to speed up queries.
Delta Lake—The Power of the Delta Log
The Delta architecture consists of three core components:
1) Delta Table: Delta tables are like giant spreadsheets optimized for big analysis. They store data in columnar format for fast querying. But unlike regular tables, Deltas are transactional – every change is recorded in time order. This keeps data consistent as schemas evolve over time.
2) Delta Log: Keeping track of all transactions is the job of the Delta log. Think of them as a digital ledger that records every edit to the tables. No matter how big or complex the changes, the log ensures data integrity by recording every change. They also allow for easy rollbacks if something goes wrong.
3) Cloud Object Storage Layer: The storage layer is where data is stored in Delta Lake. It’s compatible with various object storage systems like HDFS, S3 or Azure Data Lake. This layer ensures the durability and scalability of the data in Delta Lake. Users can store and process big data without having to manage the underlying infrastructure.
Metadata Management—Apache Iceberg vs Delta Lake
Apache Iceberg
Apache Iceberg features a multi-layer metadata system that includes manifest files, manifest lists, and metadata files. This system optimizes query planning and execution and avoids expensive operations like file listing and renaming.
Delta Lake
Delta Lake uses a log based approach where each transaction is written to the Delta log. The log is then compacted into Parquet checkpoint files which store the entire state of the table to improve query performance and reduce log file management.
Query Engine Compatibility and Platform Support—Apache Iceberg vs Delta Lake
In the world of big data, no technology exists in isolation. Working with multiple query engines and data processing frameworks is key. Let’s see how Apache Iceberg vs Delta Lake stack up.
Apache Iceberg—Diverse Support
Apache Iceberg was designed to be engine-agnostic from the ground up. And it’s paid off. Iceberg has impressive support across many query engines and data processing frameworks, like:
This is one of Apache Iceberg’s biggest strengths. It allows organizations to pick the right tool for the job without being locked into a specific ecosystem.
Delta Lake—Spark-Centric but Expanding
Delta Lake being Databricks born is tightly coupled with Apache Spark. While this has allowed for deep integration and optimization with Spark, it has also limited Delta Lake’s broader ecosystem support:
Delta Lake’s ecosystem is currently expanding. There is work to improve support for other engines but for now, it trails Iceberg.
ACID Transaction—Apache Iceberg vs Delta Lake
One great thing about Apache Iceberg vs Delta Lake is that they both support ACID transactions, which stands for Atomicity, Consistency, Isolation, and Durability. Now, let's see how each of them handles these important features:
Atomicity
- Apache Iceberg
When you make a change to an Iceberg table, it's an all-or-nothing affair. Iceberg achieves atomicity through its clever use of metadata files. When a transaction completes, Iceberg atomically replaces the old metadata file with a new one that reflects the changes. If anything goes wrong during the transaction, the old metadata file remains in place, effectively rolling back the change. - Delta Lake
Delta Lake takes a log-based approach to atomicity. Each transaction is recorded as an ordered sequence of actions in the delta log. The transaction is complete only when all actions are successfully logged. If a failure happens midway, the partial transaction is ignored during table loading
Consistency and Isolation
Both Apache Iceberg vs Delta Lake provide serializable isolation, the highest level of transaction isolation, which guarantees that concurrent transactions appear sequential.
- Apache Iceberg
Apache Iceberg uses optimistic concurrency control. When committing changes, Iceberg checks if the table has been modified since the transaction started. If not, changes are committed; otherwise, the transaction is retried - Delta Lake
Similarly, Delta Lake also uses optimistic concurrency control. It checks for conflicts at commit time and retries transactions if necessary. This approach allows for high concurrency while maintaining strong consistency guarantees.
Durability
- Apache Iceberg
In Apache Iceberg, all transactions are permanent once committed. However, Iceberg's snapshot model allows for easy rollbacks if needed. Each write creates a new snapshot, and you can easily revert to a previous snapshot if issues arise. - Delta Lake
Delta Lake inherits durability guarantees from the underlying storage system (like S3 or HDFS). Once a transaction is committed to the delta log, it's considered durable. Delta Lake’s use of Parquet-formatted checkpoint files ensures that historical data changes are preserved and can be reliably accessed.
Save up to 50% on your Databricks spend in a few minutes!


Conclusion
And that’s a wrap! Both of these open table formats are great additions to the data lakehouse and the choice between them should be based on your project needs and ecosystem. Choosing between Apache Iceberg vs Delta Lake really depends on your specific use case.
Now, in the second part, we will cover schema evolution, partition evolution, data skipping and indexing, performance, scalability, ecosystem support, and various use cases of these two open table formats.
FAQs
What are two popular table formats used in data lakehouses?
Apache Iceberg and Delta Lake are two popular table formats used in data lakehouses.
Who developed Apache Iceberg?
Apache Iceberg was developed by Netflix and is now a project of the Apache Software Foundation.
Who created Delta Lake?
Delta Lake was created by Databricks and is now part of the Linux Foundation.
What are the key characteristics of Delta Lake?
Key characteristics of Delta Lake include ACID transactions, scalable metadata handling, time travel, schema enforcement and evolution, and support for both batch and streaming data processing.
What is the difference between Apache Iceberg and Hive Metastore?
Apache Iceberg is an open table format designed for large analytic datasets, offering features like ACID transactions, efficient partitioning, and schema evolution. In contrast, Hive Metastore is a central metadata repository for Hive tables and partitions. It focuses on data discoverability and schema management but lacks advanced transaction support.
What file formats does Apache Iceberg support?
Apache Iceberg supports Apache Parquet, Apache Avro, and Apache ORC file formats.
What is Apache Iceberg famous for?
Apache Iceberg is famous for its high-performance table format, schema and partition evolution capabilities, and compatibility with multiple query engines.
What is Apache Iceberg used for?
Apache Iceberg is primarily used for managing large analytic datasets in data lakes, providing ACID transactions, schema evolution, and efficient querying across multiple data processing engines.
What is the difference between Apache Iceberg and Parquet?
Apache Iceberg is an open table format designed for managing large analytic datasets with features like ACID transactions, schema evolution, and time travel. Parquet is a columnar storage file format optimized for efficient data storage and retrieval. Iceberg manages metadata and provides advanced table-level operations, while Parquet focuses on data compression and query performance at the file level
Does Apache Iceberg support indexing?
Yes, Apache Iceberg supports indexing through partitioning and hidden partitioning, which allows for efficient query performance by reducing the amount of data scanned.
What are the limitations of Apache Iceberg?
Apache Iceberg's limitations include its relatively complex setup and configuration, potential integration challenges with older data processing tools, and the need for proper maintenance of metadata tables. Also, while Iceberg is highly performant, it may require tuning and optimization for specific workloads.
What is scalable metadata handling in Delta Lake?
Delta Lake leverages Spark distributed processing power to handle all the metadata for petabyte-scale tables with billions of files at ease
How does Delta Lake store data?
Delta stores all your data in the Parquet file format.
What problems does Apache Iceberg solve?
Apache Iceberg solves problems related to data reliability, schema evolution, efficient querying of large datasets, and compatibility across different data processing engines.
Is Delta Lake part of Databricks?
While Delta Lake was created by Databricks, it is now an open source project under the Linux Foundation, though it maintains deep integration with Databricks.















