





























Say you're dealing with data—tons of it. Maybe you're processing logs, training ML models, or running analytics. Whatever it is, you need a platform that can handle the load without making your life harder. There are many options available, but two that you might consider are Google Cloud Dataproc and Databricks. Databricks is a unified analytics platform built on Apache Spark that brings data engineering, data science, and machine learning together in one collaborative workspace. Google Cloud Dataproc is a managed service that lets you quickly spin up clusters to run Apache Hadoop, Apache Spark, and other open source frameworks on Google Cloud.
In this article, we will compare Dataproc vs Databricks by breaking down key differences across architecture, processing capabilities, ecosystem integration, developer experience, machine learning support, security, pricing, and more! Let’s dive right into it!
Table of Contents
What is Databricks?
Databricks is a unified cloud-based analytics platform that lets you manage, process, and analyze large volumes of data in one place. It was founded by the creators of Apache Spark in 2013 and combines tools for data engineering, data science, and machine learning into a single, collaborative Databricks workspace. You can use Databricks to run interactive notebooks in various programing languages (like Python, SQL, Scala, or R), set up distributed clusters on major clouds (like AWS, Azure, or Google Cloud), and process both structured and unstructured data without having to move it around.

At its very core, Databricks uses the “lakehouse” architecture—a hybrid model that mixes the best parts of data lakes and data warehouses. Because of this, you can store raw data in your preferred cloud storage and then apply transformations, run real-time analytics, or build custom ML models directly on that data. The platform also includes Delta Lake, which adds reliable, transactional capabilities to your data, MLflow, which helps track experiments and manage your models and integrations with various generative AI models.
TL;DR: Databricks is a unified platform that simplifies complex data operations while giving you the flexibility to build robust analytics and AI solutions—all without juggling multiple tools or platforms.
Check out this article for an in-depth look at the capabilities and features of Databricks.
Save up to 50% on your Databricks spend in a few minutes!


What is Google Cloud Dataproc?
Google Cloud Dataproc is a managed service that lets you run open source data tools and frameworks on Google Cloud with less hassle.
Google entered the cloud computing market in 2008 with the launch of App Engine, which laid the foundation for what would become Google Cloud Platform (GCP). Over the years, GCP expanded to include various services tailored to meet the needs of developers and enterprises.
Dataproc was introduced to address the need for scalable, cost-effective big data processing. It launched in beta in September 2015 and became generally available in February 2016. It was first developed to simplify running distributed computing frameworks like Apache Hadoop and Apache Spark. Before Dataproc, setting up and managing clusters for big data tasks meant dealing with complex configurations and significant manual work. Google introduced Dataproc to give you an easier way to start, scale, and shut down clusters on demand.
So, what is Google Cloud Dataproc?
Google Cloud Dataproc is a Platform as a Service (PaaS) designed to run batch processing and interactive queries using popular open source frameworks (Apache Hadoop, Apache Spark, Apache Flink, Presto, and 30+ more tools and frameworks). It uses virtual machines from Google Compute Engine for processing and relies on Google Cloud Storage for data. Dataproc automates the creation, management, and scaling of clusters, making it easier for you to process massive datasets without worrying about infrastructure overhead.

Here are some key features of Google Cloud Dataproc:
1) Fully Managed Service: You can rapidly create clusters that automatically scale based on workload demands.
2) Instant Cluster Provisioning: You can spin up and manage clusters in under 90 seconds—ideal for dynamic workloads.
3) Open Source Integration: Google Cloud Dataproc supports Apache Hadoop, Apache Spark, Apache Flink, Presto, and 30+ more tools and frameworks.
4) Integrates Natively with GCP services: Google Cloud Dataproc is built to work seamlessly with other Google Cloud services. It integrates directly with Cloud Storage, Google BigQuery, Dataplex, Google Vertex AI, Cloud Composer, Google BigTable, Cloud Logging, and Cloud Monitoring.
5) Serverless Spark: Google Cloud Dataproc offers a serverless option for running Apache Spark applications and pipelines.
6) Resizable Clusters: You can create and resize clusters quickly by customizing virtual machine (VM) types, disk sizes, node counts, and networking configurations.
7) Autoscaling Clusters: Dataproc’s autoscaling feature dynamically adjusts the number of worker nodes in your cluster. It automatically adds or removes cluster resources based on workload demands.
8) Flexible Virtual Machines: Dataproc supports custom machine types and preemptible VMs (low-cost instances).
9) Workflow Templates: You can define reusable workflow templates that map out a series of jobs. These templates let you manage and execute complex workflows by simply reusing a predefined configuration.
10) Dataproc on Google Distributed Cloud (GDC): For scenarios that require on-premises processing, you can run Apache Spark on the Google Distributed Cloud (GDC) Edge Appliance in your data center.
11) Smart Alerts: Dataproc comes with recommended alert configurations that help you monitor idle clusters, runaway jobs, or overutilized resources. You can adjust these thresholds and create custom alerts so that you’re informed about issues that may affect performance or cost.
What Is Google Cloud Dataproc Used For?
You can use GCP Dataproc for many big data tasks. Many organizations use it to process logs, perform ETL (Extract, Transform, Load) operations, and analyze data from Internet of Things (IoT) devices. You might use it when you need to process large data sets quickly or run machine learning jobs with Apache Spark. Dataproc fits well if you already work with Apache Hadoop or Apache Spark and want a managed environment to cut down on manual cluster maintenance.
Dataproc in a minute
Google Cloud Dataproc vs Databricks—Feature Breakdown
Need a quick rundown? Here’s a quick overview of the key differences between Google Cloud Dataproc vs Databricks!

Now, let's dive deeper into the comparison between these powerful platforms.
What Is the Difference Between Dataproc and Databricks?
Let's compare Google Cloud Dataproc vs Databricks by looking at 7 key features.
1) Google Cloud Dataproc vs Databricks—Architecture Breakdown
Google Cloud Dataproc Architecture
Google Cloud Dataproc is a fully managed big data service that simplifies running open source data processing frameworks—such as Apache Hadoop, Apache Spark, Apache Flink, and Presto—on Google Cloud. It abstracts the heavy lifting of cluster management while leveraging the scale, security, and performance of the Google Cloud Platform (GCP). Dataproc is engineered to provision clusters rapidly (often in under 90 seconds), decouple compute from persistent storage, and integrate seamlessly with a suite of GCP products and services.
Here is a detailed architectural breakdown of GCP Dataproc, focusing on its primary components and how they interact:
Core Architectural Components
Cluster Architecture
Google Cloud Dataproc cluster fundamentally comprises a master node and one or more worker nodes. These nodes are provisioned as Compute Engine virtual machines (VMs) and can be customized based on workload requirements.
➥ Master Node: Master node orchestrates cluster operations and serves as the control point for resource management and job scheduling. It runs essential components such as:
- YARN ResourceManager or the Apache Spark driver, depending on the workload.
- HDFS NameNode, if HDFS is used for temporary storage.
- Other services like JobHistoryServer for Apache Hadoop or Spark History Server for Spark.
Master node acts as the primary control plane for job scheduling, task coordination, and overall cluster health. For high availability, GCP Dataproc supports clusters with multiple master nodes.
➥ Worker Node: Worker nodes are the workhorses of the cluster, responsible for executing the actual data processing tasks. Each worker node runs:
- YARN NodeManagers to manage resources on individual nodes.
- DataNode (HDFS DataNode—if using HDFS)
- Executors for Apache Spark jobs or MapReduce tasks.
Worker nodes handle the bulk of the data processing workload. You can scale the number of worker nodes manually or utilize autoscaling to dynamically adjust capacity based on job demands.
➥ Secondary Worker Nodes (Preemptible Workers): Preemptible workers are cost-effective, short-lived virtual machines (VMs) that can be added to clusters to reduce costs. These VMs are ideal for fault-tolerant workloads because they may be terminated by Google Cloud at any time. GCP Dataproc automatically handles failures or preemptions by reassigning tasks to other nodes.
All nodes in a Google Cloud Dataproc cluster run on Google Compute Engine virtual machines (VMs) that can be customized in terms of CPU, memory, and disk configurations (including custom machine types) to match workload requirements.
Control Plane and Workflow Management
GCP Dataproc control plane simplifies cluster lifecycle management and job execution:
➥ Cluster Lifecycle Management: Users can create, scale, and delete clusters using the Google Cloud Console, gcloud CLI, or REST APIs. Clusters can be provisioned in under 90 seconds due to lightweight initialization scripts.
➥ Job Submission & Scheduling: Jobs can be submitted interactively or programmatically through APIs. Custom initialization actions allow fine-tuned configuration during cluster startup.
➥ Autoscaling: Integrated autoscaling dynamically adjusts the number of worker nodes based on workload demands. Autoscaling policies can be defined to optimize cost and performance. Preemptible VMs are often included in autoscaling policies to further reduce costs.
Storage and Data Processing
A foundational design principle of Dataproc is the decoupling of compute and storage:
➥ Persistent Storage: Unlike traditional Apache Hadoop clusters that rely on HDFS for persistent storage, Dataproc uses Google Cloud Storage (GCS) as its primary storage layer. This decoupling allows clusters to be ephemeral—clusters can be created for specific jobs and deleted afterward without losing data.
➥ Data Flow: Data can be ingested from various sources—including Pub/Sub and GCS—processed within the cluster, and then stored back in GCS or integrated with services like Google BigQuery (for analytics) or Google BigTable (for low-latency NoSQL storage).
Security Architecture
Dataproc employs a multi-layered security model:
➥ Virtual Private Cloud (VPC): Clusters run within a VPC network that provides network isolation and secure communication between nodes.
➥ Private Google Access & VPC Service Controls: These features enable secure access to GCP services without exposing traffic to the public internet.
➥ Encryption: Data in transit is encrypted using TLS/SSL protocols. Data at rest in GCS or Google BigQuery is encrypted by default using Google-managed encryption keys or customer managed keys via Cloud Key Management Service (KMS).
➥ Identity and Access Management (IAM): IAM policies control access to clusters, job submission permissions, and data stored in GCS or Google BigQuery. Fine-grained roles ensure that only authorized users can perform specific actions.
Monitoring and Logging
Clusters are integrated with Google Cloud’s operations suite (formerly Stackdriver) for logging, monitoring, and alerting. This integration simplifies the tracking of job progress, cluster health, and resource utilization.
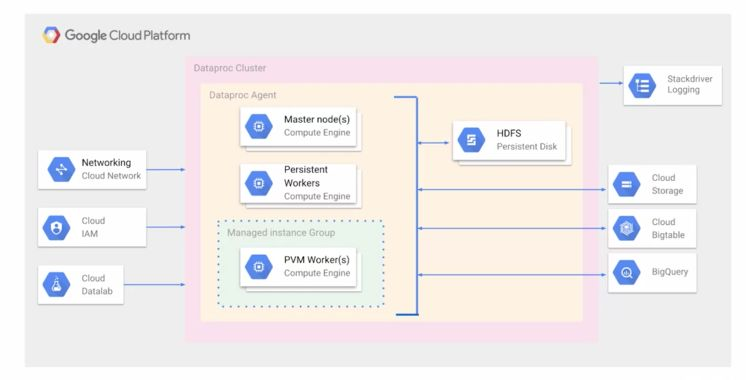
How Google Cloud Dataproc Works?
Here is how the overall GCP Dataproc works:
- Users define jobs (Apache Spark, Apache Hadoop MapReduce) with input parameters and execution instructions.
- The job is submitted via the GCP Dataproc API, gcloud CLI, or Google Cloud Console.
- The master node queues the job using YARN’s ResourceManager or Apache Spark’s scheduler.
- Tasks are distributed across worker nodes based on resource availability.
- Jobs execute in parallel across worker nodes.
- Progress is tracked through integrated monitoring tools like Cloud Logging.
- Upon completion:
- Results are stored in persistent storage (GCS).
- Transient clusters may be automatically torn down if configured.
Next, let's explore the architecture of Databricks in detail.
Databricks Architecture
Databricks is built on Apache Spark which is designed to run seamlessly on major cloud providers—including Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP). Its architecture decouples compute from storage, enabling elastic scalability, robust security, and streamlined operations. The Databricks architecture consists of three primary components: Control Plane, Compute Plane, and Storage Layer.
a) Control Plane:
Control Plane is fully managed by Databricks and handles orchestration, management, and administrative tasks. It operates outside the customer’s cloud account and includes the following key functionalities:
Cluster Management & Job Scheduling:
- Manages the provisioning, monitoring, auto-scaling, and lifecycle of clusters.
- Schedules batch jobs (ETL pipelines) and streaming jobs using Apache Spark Structured Streaming.
- Provides APIs for programmatic job submission and monitoring.
User Authentication & Authorization:
- Integrates with enterprise identity providers such as Microsoft Entra ID (formerly Azure Active Directory), AWS IAM, or Google Identity.
- Supports multi-factor authentication (MFA), single sign-on (SSO), and role-based access control (RBAC) to enforce fine-grained permissions.
Metadata & Workspace Management:
- Manages workspace configurations, including notebooks, libraries, job metadata, cluster settings, and system logs.
- Provides a collaborative web-based workspace for data scientists, engineers, and analysts to work together in real time.
Configuration & Security Policies:
- Centralizes security controls such as IP access lists, VPC/VNet peering configurations, encryption policies (e.g., at-rest encryption using customer managed keys), compliance auditing (e.g., SOC 2 Type II), and network security rules.
- Supports private link configurations to make sure secure communication between the control plane and compute resources.
The Control Plane abstracts infrastructure complexities by managing these operations outside the customer's cloud environment.
b) Compute Plane:
The Compute Plane is where all data processing tasks are executed. It operates within the customer’s cloud account to ensure data locality and compliance. Databricks supports two deployment modes:
1) Serverless Compute Plane:
- In this mode, Databricks fully manages compute resources on behalf of users.
- Clusters are provisioned automatically based on workload requirements and scale elastically to handle varying demand.
- Ideal for organizations seeking simplicity without needing control over infrastructure details.
2) Classic Compute Plane (Customer Managed Clusters):
- In this mode, clusters run within the user’s cloud account under their direct control.
- Offers enhanced configurability for networking (e.g., deploying clusters in private subnets), compliance with strict regulatory requirements (e.g., HIPAA or GDPR), and integration with custom virtual networks (VPCs or VNets).
- Allows users to configure advanced settings such as custom Apache Spark configurations or node types.
Both modes leverage the Apache Spark engine for distributed data processing. Clusters can be configured with different instance types (GPU-enabled instances for deep learning) or optimized for specific workloads like AI/ML training or SQL analytics.
c) Workspace Storage and Data Abstraction:
Databricks integrates with cloud-native storage solutions provided by AWS (S3), Azure (Blob Storage or Data Lake Storage Gen2), and GCP (Google Cloud Storage). These storage services are used for both operational data (e.g., notebooks, logs) and analytical data. The Databricks File System (DBFS) serves as an abstraction layer that allows users to interact with data stored in these buckets seamlessly. It supports various data formats and provides a unified interface for data access.
Check out this article to learn more in-depth about Databricks architecture.
2) Google Cloud Dataproc vs Databricks—Data Processing Capabilities
Okay, now that we've unpacked all the architecture differences between Google Cloud Dataproc vs Databricks, let's move on to explore their strengths in data processing.
Google Cloud Dataproc Data Processing Capabilities
Google Cloud Dataproc is a fully managed service for running Apache Hadoop, Apache Spark, Apache Flink, Presto, and 30+ more tools and frameworks, making it a perfect choice for data lake modernization, ETL, and secure data science at scale. Its data processing capabilities are deeply integrated with the Google Cloud ecosystem, offering several key features:
1) Managed Open Source Frameworks…
Dataproc is a fully managed service for running Apache Spark, Apache Hadoop, Apache Hive, Pig, and other open source tools on Google Cloud Platform (GCP). It leverages the familiar Spark programming model—including RDDs, DataFrames, and Structured Streaming—to process both batch and streaming workloads.
2) Connects Smoothly with Other Google Cloud Services
Being part of the GCP ecosystem, GCP Dataproc integrates tightly with services like Google Cloud Storage, Google BigQuery, and Pub/Sub. Its design decouples storage from compute, allowing for rapid spin‑up of ephemeral clusters and autoscaling based on workload needs.
3) Full Customization
Users can customize cluster configurations, including choosing specific VM types, enabling autoscaling, and configuring Apache Spark settings for optimal performance. This gives you the flexibility to run custom Apache Spark jobs and leverage native Apache Spark libraries (MLlib, GraphX) for machine learning and graph processing.
4) Streaming & Batch Processing
GCP Dataproc supports Apache Spark Structured Streaming, which ingests data in micro‑batches. This makes it capable of real‑time analytics as well as large‑scale batch processing while benefiting from Spark’s unified engine.
5) Easy to Run on Google Cloud Platform
The managed nature of Dataproc reduces much of the DevOps overhead required to maintain clusters, while still exposing the full power of open source frameworks. Cost efficiency is achieved through on‑demand cluster provisioning and the ability to shut down clusters when not in use.
Let's jump into the Data processing capabilities of Databricks.
Databricks Data Processing Capabilities
1) Optimized Spark Runtime & Performance Enhancements
Databricks is built on Apache Spark but extends it with the Databricks Runtime and the Photon engine—both engineered to dramatically boost performance and resource utilization. These enhancements reduce query latencies and improve throughput for both batch and streaming jobs.
2) Unified Data Lakehouse with Delta Lake
A core feature of Databricks is its integration with Delta Lake. Delta Lake adds ACID transactions, schema enforcement, and time travel to data lakes, enabling reliable, consistent data processing across both streaming and batch workloads.
3) Integrated Machine Learning & Collaboration
Databricks offers built-in support for ML workflows via MLflow and collaborative notebooks, which streamline the development, tracking, and deployment of machine learning models.
4) Advanced Streaming Capabilities
Through Apache Spark Structured Streaming on an optimized platform, Databricks enables real‑time processing with lower latencies and enhanced fault tolerance. Automated operational tooling (such as job scheduling and cluster management) minimizes manual intervention and boosts productivity.
TL;DR: Dataproc vs Databricks—Data Processing Capabilities
So, choose Dataproc if you need a fully managed, open source friendly service tightly integrated with Google Cloud for running Spark, Hadoop, and other frameworks with flexible cluster customization. Choose Databricks if you want an optimized Spark runtime, advanced performance enhancements like Photon, Delta Lake for ACID-compliant data processing, and built-in ML and collaboration features.
3) Google Cloud Dataproc vs Databricks—Ecosystem Integration & Deployment Models
Now that we have gone over the complete details between the data processing architecture differences between Google Cloud Dataproc vs Databricks, let’s dive right into the Ecosystem Integration & Deployment Models of Dataproc vs Databricks.
Google Cloud Dataproc Ecosystem Integration & Deployment Models
Google Cloud Dataproc is a fully managed service built on Google Cloud Platform. It leverages the full suite of GCP services—such as Google Compute Engine for infrastructure, Google Cloud Storage as the data lake, Google BigQuery for interactive analytics,Google Vertex AI for an enterprise-grade unified AI development platform, Cloud Pub/Sub for real‑time messaging, and Dataplex to manage, monitor, and govern data & AI artifacts.
GCP Dataproc allows you to quickly set up clusters and use them for short-term batch processing or interactive workloads. Its support for ephemeral clusters enables clusters to be generated on demand and automatically terminated after job completion, reducing costs and maximizing resource utilization. These clusters are highly configurable via initialization steps and configuration settings, allowing you to install additional libraries or adjust performance parameters as needed.
GCP Dataproc supports industry-standard open source tools like Apache Spark, Apache Hadoop, Apache Hive, Pig, and 30+ more open source tools/frameworks, making it a natural choice if your workflows are built around these technologies.
Databricks Ecosystem Integration & Deployment Models
Databricks is a unified data analytics platform that offers a fully managed, cloud-native environment built on an optimized Apache Spark engine. It seamlessly integrates with multi-cloud services across Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP), providing extensive data connectivity and interoperability. Leveraging its proprietary Databricks Runtime, the platform delivers enhanced throughput, lower latency, and dynamic scaling capabilities that elevate performance beyond standard Apache Spark deployments.
With native support for Delta Lake, Databricks enables ACID transactions, schema enforcement, and time travel on data lakes—ensuring robust data governance and consistency for both batch and streaming workloads. The platform streamlines cluster management by automating provisioning, scaling, and termination of compute resources, whether for interactive sessions or scheduled job clusters.
Databricks also offers a collaborative workspace featuring interactive notebooks that support multiple languages (Python, SQL, Scala, or R), which is ideal for integrating data engineering, data science, and machine learning workflows. Its also has tight integration with MLflow facilitates comprehensive management of the machine learning lifecycle, from experiment tracking to model deployment, accelerating innovation and operational efficiency.
Also, Databricks provides extensive ecosystem connectivity, enabling seamless integration with popular business intelligence and data visualization tools.
TL;DR: Dataproc vs Databricks—Ecosystem Integration & Deployment Models
Dataproc offers deep native integration with Google Cloud’s suite, enabling flexible, cost-effective, and highly customizable ephemeral cluster deployments with broad open source support. In contrast, Databricks provides an optimized, unified analytics platform featuring advanced performance enhancements (like Delta Lake and Databricks MLflow integration), comprehensive multi-cloud connectivity, and robust enterprise security—making it ideal for sophisticated, collaborative data science and engineering workflows.
4) Google Cloud Dataproc vs Databricks—Developer Experience & Workspace Environment
Having explored the differences in Ecosystem Integration and Deployment Models between Google Cloud Dataproc vs Databricks, let's dive into the Developer Experience and Workspace Environment of Dataproc vs Databricks. We will focus on the technical aspects that define how developers interact with these platforms, including usability, collaboration features, and the environments provided for building and managing data workflows.
Google Cloud Dataproc Developer Experience & Workspace Environment
1) When it comes to cluster management…
GCP Dataproc allows you to create clusters quickly using the Google Cloud Console, gcloud command-line tool, or RESTful APIs. You have full control over the cluster configuration, including the ability to customize the number of nodes, machine types, and software components.
2) For Job Submission…
You can submit jobs directly to the cluster using various methods (Google Cloud Console, CLI, APIs). It supports multiple job types like Apache Spark, Apache Hadoop MapReduce, Pig, and Apache Hive.
3) Integrating with Google Cloud Services…
Dataproc seamlessly integrates with other Google Cloud services such as Cloud Storage, Google BigQuery, and Google BigTable. Because of this you can easily build pipelines that leverage the strengths of different services without having to move to different platforms.
4) Customizing your environment…
Since GCP Dataproc uses standard open source tools, you can bring your existing scripts and workflows without significant modifications. You can install additional components and customize the environment as needed.
4) About that notebook interface…
Unlike Databricks, Dataproc doesn't come with an integrated notebook interface. Developers often have to use external tools like Jupyter Notebooks or Apache Zeppelin, which might require additional setup and management.
5) Scaling and performance…
Dataproc supports autoscaling, allowing clusters to grow and shrink based on workload.
6) Monitoring your workflows…
Dataproc integrates with Google Cloud's operations suite for logging and monitoring, providing insights into cluster performance and job execution.
Databricks Developer Experience & Workspace Environment
Databricks offers a unified analytics platform that emphasizes collaboration, ease of use, and advanced analytics capabilities. Here's what sets its developer experience apart:
1) Collaborating with your team…
Databricks Workspace offers an interactive environment where you can access a variety of tools for data engineering, data science, and analytics. You get Notebooks for coding, Dashboards for visualizing data, and an ML model development interface for building and deploying models. The workspace also includes data pipeline management tools, collaboration features, and governance tools to manage data security and compliance.
2) Using those built-in notebooks…
Databricks has a built-in notebook interface that allows developers to write code, visualize data, and document processes in one place. Notebooks support multiple languages, including Python, Scala, R, and SQL. Users can share and comment on work seamlessly. The Notebook interface also offers features like autocomplete, syntax highlighting, and a variety of other features.
3) Managing your Apache Spark environment…
Databricks takes the hassle out of cluster management. Creating, configuring, and auto-terminating clusters is a breeze, all managed through an intuitive UI.
4) Diving into advanced analytics and machine learning…
Databricks provides MLflow integration, which simplifies experiment tracking, model management, and deployment. It also comes with built-in tools like AutoML that accelerate machine learning workflows with automated model selection and hyperparameter tuning.
5) Version Control + CI/CD
Databricks integrates with Git repositories, enabling version control for notebooks and facilitating continuous integration and deployment pipelines.
6) Scheduling jobs and automating workflows…
Databricks has built-in tools to schedule notebooks as jobs, set up alerts, and automate workflows without external orchestration tools.
7) Libraries + Tools
Databricks provides easy integration of third-party libraries and support for popular data science and machine learning frameworks.
8) Connecting with various data sources…
Databricks can easily connect with various data sources and services, including cloud storage solutions, databases, and SaaS applications.
All these features come wrapped in robust security measures like role-based access control, data encryption, and compliance with industry standards.
TL;DR: Dataproc vs Databricks—Developer Experience & Workspace Environment
So the choice boils down to your team's needs and preferences. Dataproc provides a flexible, cost-effective way to run Apache Spark and Apache Hadoop clusters with full control over configurations and integration with Google Cloud services. But, it requires more hands-on management and doesn't offer an integrated collaborative workspace. Whereas, Databricks delivers a unified platform with a rich collaborative environment, streamlined workflows, and advanced analytics capabilities. It abstracts much of the complexity of cluster management, allowing developers to focus on writing code and deriving insights.
5) Google Cloud Dataproc vs Databricks—Data Science & Machine Learning Capabilities
Okay, we've explored the Developer Experience & Workspace Environment differences between GCP Dataproc vs Databricks. Now, let's dive right into the Data Science & Machine Learning Capabilities of each platform.
Google Cloud Dataproc Data Science & Machine Learning Capabilities
Dataproc provides a robust platform for data science and machine learning (ML) tasks. Its key ML/data science features include:
1) Open Source Framework Support
Dataproc comes preconfigured with popular ML libraries such as TensorFlow, PyTorch, Scikit-learn, and Keras—allowing you to run diverse ML workloads without additional setup.
2) RAPID Acceleration
With support for NVIDIA’s RAPIDS Accelerator for Apache Spark, Dataproc enables GPU-enabled processing to speed up ML tasks on large datasets.
3) Notebook Integration
Dataproc clusters can easily be integrated with Jupyter and Apache Zeppelin notebooks for interactive data exploration and iterative model development.
4) Google Vertex AI Integration
Dataproc works well with other Google Cloud services. You can integrate with Google Vertex AI—the unified ML platform—to orchestrate advanced model development and deployment pipelines.
5) Google BigQuery Integration
Dataproc can be seamlessly connected with Google BigQuery allowing you to efficiently query and process massive datasets in conjunction with Dataproc jobs.
6) Workflow Integration via GKE (Google Kubernetes Engine)/Kubeflow
While Dataproc itself isn’t an orchestrator, it can be a compute component in broader ML workflows. When Dataproc combined with Kubernetes, you can:
- Run containerized data preprocessing (leveraging Apache Spark jobs),
- Perform distributed hyperparameter tuning (using tools like Katib),
- And deploy models via KFServing or Google Vertex AI endpoints.
Note that the orchestration is managed by GKE (Google Kubernetes Engine)/Kubeflow, with Dataproc providing scalable compute for batch jobs.
Databricks Data Science & Machine Learning Capabilities
Databricks delivers an end-to-end, collaborative platform built on Apache Spark and Delta Lake that streamlines the complete ML lifecycle. Its principal ML capabilities include:
1) Collaborative Notebooks
Support for interactive notebooks in Python, R, Scala, and SQL fosters real-time collaboration and rapid experimentation among teams.
2) ML Lifecycle Management with MLflow
Deep integration with Databricks MLflow enables experiment tracking, model versioning, and seamless deployment. This unifies the entire ML workflow—from training to production.
3) AutoML and Feature Store
Built-in Databricks AutoML tools help automate model selection and tuning, while the integrated Databricks Feature Store facilitates feature sharing, governance, and reuse across projects.
4) Native Model Serving
Databricks Model Serving offers low-latency REST endpoints for real-time inference, automatic scaling, and A/B testing, all integrated with Databricks MLflow for performance monitoring.
5) Generative AI Support
Databricks supports generative AI workflows, including fine-tuning large language models and deploying them (for example, via Mosaic AI), enabling cutting-edge AI applications.
6) Delta Lake for Data Reliability
Delta Lake in Databricks provides ACID transactions, data versioning, and lineage tracking—ensuring that the data feeding your ML models is high quality and reproducible.
TL;DR: Dataproc vs Databricks—Data Science & ML Capabilities
🔮 Google Cloud Dataproc excels in cost efficiency and deep integration with Google Cloud’s ecosystem. It is ideally suited for organizations that favor an open source, batch-oriented processing environment—especially if you already leverage other Google Cloud services like Google BigQuery and Google Vertex AI.
🔮 Databricks shines with its unified, collaborative platform that tightly integrates ML lifecycle management, advanced AutoML, feature management, and support for generative AI. It’s best for enterprises seeking state-of-the-art tooling, multi-cloud flexibility, and robust MLOps capabilities.
Choose Dataproc if your strategy is centered on Google Cloud and you need a budget-friendly solution for batch ML workloads with seamless integration into Google’s broader data ecosystem. Opt for Databricks when you require a next-generation, collaborative ML platform that supports end-to-end MLOps—including real-time model serving and advanced generative AI workflows.
6) Google Cloud Dataproc vs Databricks—Security and Governance
We have gone over the Data Science & Machine Learning Capabilities difference between Dataproc vs Databricks; let’s dive right into the Security and Governance Capabilities of Dataproc vs Databricks.
Google Cloud Dataproc Security and Governance
Dataproc's security capability is largely inherited from both Google Cloud’s robust security framework and the native security features of its underlying open source components.
1) Network Security Features
➥ Dataproc allows clusters to be deployed within a dedicated VPC, isolating them from other networks and the public internet for enhanced security.
➥ Clusters in Dataproc can be configured with private IPs, protecting them from exposure to the public internet and improving network isolation.
➥ Dataproc supports the implementation of strict firewall rules to control inbound and outbound traffic, allowing only necessary ports and protocols.
➥ Dataproc integrates with Google Cloud's VPC Network Peering, allowing for restricted and isolated connectivity between the Dataproc VPC and other critical virtual private clouds.
➥ Dataproc Component Gateway provides secure access to Apache Hadoop ecosystem UIs (YARN, HDFS, or Spark server UI) without the need to open firewall ports.
2) Identity and Access Management (IAM) Features
➥ Dataproc integrates with Google Cloud IAM, allowing the use of different data plane service accounts for different clusters, each assigned only the permissions required for specific workloads.
➥ Dataproc uses IAM to ensure that service accounts and users are only allowed the minimum rights required, lowering the risk of illegal access.
➥ Dataproc supports RBAC, enabling fine-grained IAM permissions to be set for each cluster based on user roles and responsibilities.
➥ Users can define custom IAM roles tailored to specific job functions within the Dataproc environment, providing precise access control.
➥ Dataproc uses Google Cloud's auditing features to analyze IAM permissions and roles, assisting in identifying and removing excessive or unnecessary privileges.
3) Encryption Features
➥ Dataproc supports encryption of data at rest using Cloud Key Management Service (KMS) or Customer Managed Encryption Keys (CMEK).
➥ Dataproc allows the use of organizational policies to mandate encryption at rest during cluster creation, providing an additional layer of enforcement.
4) Secure Cluster Configuration Features
➥ Dataproc supports Apache Hadoop Secure Mode with Kerberos authentication to prevent unauthorized access to cluster resources, enhancing cluster security.
➥ Dataproc automatically applies security hardening features to all open source components in Kerberos-enabled clusters, boosting overall security without requiring manual configuration.
➥ Dataproc enables OS Login, adding an extra layer of security for managing cluster nodes via SSH.
➥ Dataproc allows users to specify separate staging and temporary buckets on Google Cloud Storage (GCS) for each cluster, facilitating permission isolation and data security.
➥ Dataproc integrates with Google Cloud Secret Manager to securely store and manage sensitive data such as API keys, passwords, and certificates, with built-in access and audit capabilities.
➥ Dataproc supports the use of custom organization policies in Google Cloud to allow or deny specific operations on clusters, enforcing security policies at an organizational level.
Databricks Security and Governance
1) Identity and Access Management
➥Databricks provides Single Sign-On (SSO) and Unified Login for centralized and secure user authentication across all workspaces.
➥ Databricks integrates with your identity provider (IDP) to leverage Multi-Factor Authentication (MFA) for verifying users and applications.
➥ Databricks allows separation of admin and user accounts to reduce security risks.
➥ Databricks provides token management for secure authentication.
➥ Databricks supports SCIM synchronization for automated provisioning and management of users and groups.
➥ Databricks enables limiting cluster creation rights to authorized users only.
➥ Databricks integrates with cross-account IAM roles for secure permission management across different accounts.
➥ Databricks provides customer-approved workspace login to restrict access to only approved users.
➥ Databricks supports user isolation in clusters to prevent unauthorized access between users.
➥ Databricks allows the use of service principals for running production jobs securely without user-based access.
2) Data Protection
➥ Databricks integrates with cloud storage to secure access through controls like S3 bucket policies and Azure storage firewalls.
➥ Databricks provides data exfiltration settings in the admin console to prevent unauthorized data exports.
➥ Databricks supports bucket versioning on storage to maintain data integrity and recover from changes.
➥ Databricks enables encryption and access restriction for storage resources.
➥ Databricks allows adding customer managed keys for encrypting managed services.
3) Network Security and Endpoint Protection
➥ Databricks can be deployed within a customer managed VPC/VNet for network isolation.
➥ Databricks provides IP access lists to restrict access to trusted IP addresses for workspaces and accounts.
➥ Databricks offers network exfiltration protections to prevent unauthorized data transfers out of the network.
➥ Databricks integrates with VPC service controls (e.g., on GCP) for additional network perimeter security.
➥ Databricks allows defining VPC endpoint policies to regulate traffic through VPC endpoints.
➥ Databricks supports PrivateLink configuration (AWS, Azure, GCP) for private, secure connectivity to Databricks services.
4) Monitoring and Compliance
➥ Databricks provides audit log delivery to track user activities and system events for auditing.
➥ Databricks supports resource tagging for monitoring usage and enabling charge-back..
➥ Databricks enables monitoring of provisioning activities to maintain oversight.
➥ Databricks provides enhanced security monitoring or compliance security profiles for advanced security assurance.
6) Additional Security Features and Capabilities
➥ Databricks provides Unity Catalog for fine-grained data access controls and time-bound, down-scoped credentials.
➥ Databricks offers Mosaic AI Gateway (Public Preview) for monitoring and controlling AI model usage across the enterprise.
➥ Databricks supports Private Link for both frontend (user) and backend (workload) connectivity, including Azure Private Link for Databricks SQL Serverless.
TL;DR: Dataproc vs Databricks—Security & Governance
🔮 Google Cloud Dataproc offers strong network security with private VPC deployment, strict firewall rules, and Kerberos authentication. It’s ideal if you’re deeply integrated into the Google Cloud ecosystem and prioritize network isolation and basic IAM via service accounts and RBAC. But, it lacks advanced features like SSO and MFA.
🔮 Databricks provides a broader and deeper security toolkit, including SSO, MFA, SCIM synchronization, and detailed IAM controls. It excels in data governance with Unity Catalog, AI model security via Mosaic AI Gateway, and advanced monitoring. It’s better for companies needing robust IAM, compliance, and AI-driven workflows.
So choose Databricks if you require comprehensive identity management, data governance, or AI security features. Opt for Google Cloud Dataproc if you value seamless Google Cloud integration and strong network security over advanced IAM or governance tools.
7) Google Cloud Dataproc vs Databricks—Pricing Breakdown
Finally, we have covered a lot of differences in this article. Now, let's deep dive into the pricing breakdown between GCP Dataproc vs Databricks and actually see which one is the most affordable platform for your choice.
Google Cloud Dataproc Pricing Breakdown
GCP Dataproc automates the deployment, scaling, and management of compute clusters, making it ideal for batch processing, querying, streaming, and machine learning tasks. It supports multiple deployment modes:
1) Standard Dataproc on Compute Engine: Traditional clusters using virtual machines (VMs).
2) Dataproc on Google Kubernetes Engine (GKE): Clusters running on GKE (Google Kubernetes Engine) node pools.
3) Dataproc Serverless: A fully managed, auto-scaling option for Apache Spark workloads.
Each mode has a distinct pricing structure, but all share a common trait: costs are split between Dataproc-specific charges and underlying resource usage (Compute Engine, storage).
1) Google Cloud Dataproc on Compute Engine Pricing—Dataproc Pricing
Dataproc on Compute Engine pricing is based on the size of Dataproc clusters and the duration of time that they run. The size of a cluster is based on the aggregate number of virtual CPUs (vCPUs) across the entire cluster, including the master and worker nodes. The duration of a cluster is the length of time between cluster creation and cluster stopping or deletion.
The base charge is calculated as:
Cost = $0.01 × (# of vCPUs) × (hours of cluster runtime)Although the formula is expressed on an hourly basis, actual billing is per second, with a minimum of 1 minute per cluster. Usage is represented in fractional hours (e.g. 30 minutes is 0.5 hours).
The “size” of a cluster is the aggregate of virtual CPUs (vCPUs) across all nodes (both master and workers). For example, a cluster with one n1‑standard‑4 master (4 vCPUs) and five n1‑standard‑4 workers (4 vCPUs each) totals 24 vCPUs.
Additional Resource Charges:
Beyond the Dataproc-specific cost, clusters incur separate charges for underlying resources:
Compute Engine VMs: Billed on a per-second basis (with a 1-minute minimum) and subject to sustained use discounts.
Persistent Disks: Charged based on provisioned space.
Cloud Monitoring and Networking: Billed separately as per Google Cloud’s pricing for those services.
Note: Charges begin when nodes are active and continue until they are removed—even during autoscaling or when clusters are in an error state.
For example:
A 24‑vCPU cluster running for 2 hours would incur a Dataproc-specific charge of:
24 vCPUs × 2 hours × $0.01 = $0.48 (excluding additional Compute Engine, storage, and network costs).2) Google Cloud Dataproc on GKE (Google Kubernetes Engine) Pricing
Dataproc on GKE (Google Kubernetes Engine) uses the same fundamental pricing formula as on Compute Engine—$0.01 per vCPU per hour—but applies it to vCPUs running in Dataproc-created node pools on a user-managed Kubernetes cluster.
- Billing is per second, with a minimum of 1 minute per VM instance.
- Node pools may persist beyond cluster deletion if not explicitly scaled to zero, continuing to accrue charges.
Check out GKE (Google Kubernetes Engine) pricing to learn about the added charges that apply to the user-managed GKE cluster.
3) Google Cloud Dataproc Serverless Pricing
GCP Dataproc Serverless for Spark offers a fully managed, serverless environment for running Apache Spark workloads, with pricing determined by three main components:
a) Data Compute Units (DCUs)—which encapsulate vCPU and memory usage,
b) Accelerators—optional GPU or other accelerator resources, and
c) Shuffle Storage—temporary storage used for shuffling data during Apache Spark operations.
All these resources are billed on a per-second basis with specific minimum charges, and costs can vary by region and service tier (Standard or Premium). Also, workloads may incur charges for other Google Cloud services, such as Cloud Storage or Google BigQuery, which are billed separately. Let’s dive into each component in detail.
a) Data Compute Units (DCUs)
What are DCUs? DCUs are the fundamental unit for measuring compute capacity in Dataproc Serverless. They abstract away the underlying infrastructure (vCPUs and RAM) into a unified pricing metric.
vCPU to DCU Conversion: Each vCPU is equivalent to 0.6 DCUs.
RAM to DCU Conversion (Tiered): RAM contribution to DCUs is not linear and is tiered around an 8GB threshold per vCPU:
- RAM below 8GB per vCPU: Each GB contributes 0.1 DCU.
- RAM above 8GB per vCPU: Each GB contributes 0.2 DCU (more expensive for higher memory configurations).
Memory used by Apache Spark drivers, executors, and system memory are all included in the DCU calculation.
| Type | Price per hour |
|---|---|
| Standard DCU | $0.06 |
| Premium DCU | $0.089 |
b) Shuffle storage pricing
Shuffle storage refers to the intermediate data written to disk during Apache Spark operations (shuffling data between stages). Pricing is calculated per second with a minimum charge of 1 minute for standard shuffle storage and 5 minutes for premium shuffle storage.
| Type | Price per GB per month |
|---|---|
| Shuffle Storage (Standard) | $0.04 |
| Shuffle Storage (Premium) | $0.1 |
c) Accelerator pricing
- Accelerators such as NVIDIA GPUs (A100 or L4) are billed separately.
- Minimum charge: 5 minutes.
- GPU types and their hourly rates vary based on region.
Accelerators are optional but can significantly increase costs for machine learning or GPU-intensive tasks.
| Type | Price per hour |
|---|---|
| a100 40GB | $3.52069 |
| a100 80GB | $4.713696 |
| L4 | $0.672048 |
Default Resource Configuration
By default, each GCP Dataproc Serverless workload uses:
- Driver: 4 vCPUs and 16GB RAM (4 DCUs).
- Executors: Two executors, each with 4 vCPUs and 16GB RAM (8 DCUs total).
This results in a minimum of 12 DCUs for any workload unless explicitly configured using Apache Spark properties.
Additional Costs:
GCP Dataproc Serverless workloads may also incur charges for other Google Cloud services used concurrently, such as:
- Cloud Storage for input/output data.
- Networking for data transfer between regions.
- Monitoring via Cloud Monitoring or logging services like Google BigQuery or Google BigTable.
Each service follows its own pricing model, which must be factored into total cost estimates.
Google Cloud Platform also provides a pricing calculator tool to help estimate costs.
Check out these articles to learn more about Google Cloud Dataproc pricing in depth:
- Dataproc Pricing Details on Google Cloud
- Dataproc Serverless Pricing Information
- Compute Engine Pricing Overview
Databricks Pricing
Databricks employs a consumption‑based pricing model—users pay only for what they use. At its core is the Databricks Unit (DBU)—a composite metric aggregating CPU, memory, and I/O—to run workloads. Below is a detailed breakdown of DBU pricing and the cost structure across Databricks’ key products.
Databricks’ pricing is built on a pay‑as‑you‑go basis. Costs are determined by multiplying the number of DBUs consumed by the applicable DBU rate. This rate varies based on several factors, including cloud provider, region, edition, instance type, compute workload, and any committed usage contracts.
Formula for Cost Calculation:
Databricks DBU Consumed × Databricks DBU Rate = Total CostDatabricks provides a 14‑day free trial on AWS, Azure, and GCP—with no upfront cost. Also, Databricks offers the Community Edition, a free, limited-feature version that includes a small Apache Spark cluster and a collaborative Databricks Notebook environment—perfect for learning Apache Spark, experimenting with Databricks Notebooks, and testing basic workloads.
1) Databricks Pricing for Jobs
Databricks Jobs pricing is available in two main models: Classic/Classic Photon Clusters and Serverless (Preview).
a) Classic/Classic Photon Clusters
Classic and Classic Photon clusters provide a massively parallelized environment for demanding data engineering pipelines and large-scale data lake management. Pricing is DBU-based, varying by Databricks plan and cloud provider.
| Plan | AWS Databricks Pricing (AP Mumbai region) | Azure Databricks Pricing (US East region) | GCP Databricks Pricing |
| Standard | - | $0.15 per DBU | - |
| Premium | $0.15 per DBU | $0.30 per DBU | $0.15 per DBU |
| Enterprise | $0.20 per DBU | - | - |
b) Serverless (Preview)
Serverless Jobs offer a fully managed, elastic platform for job execution, including compute costs in the DBU price.
| Plan | AWS Databricks Pricing (AP Mumbai region) | Azure Databricks Pricing | GCP Databricks Pricing |
| Premium | $0.20 per DBU | $0.30 per DBU | $0.20 per DBU |
| Enterprise | $0.20 per DBU | - | - |
2) Databricks Pricing for Delta Live Tables
Delta Live Table pricing is based on Jobs Compute DBUs and is tiered by features: DLT Core, DLT Pro, and DLT Advanced.
Delta Live Table Core
| Plan | AWS Databricks Pricing (AP Mumbai region) | Azure Databricks Pricing | GCP Databricks Pricing |
| Premium | $0.20 per DBU | $0.30 per DBU | $0.20 per DBU |
| Enterprise | $0.20 per DBU | - | - |
Delta Live Table Pro
|
Plan |
AWS Databricks Pricing (AP Mumbai region) |
Azure Databricks Pricing |
GCP Databricks Pricing |
|
Premium |
$0.25 per DBU |
$0.38 per DBU |
$0.25 per DBU |
|
Enterprise |
$0.36 per DBU |
- |
- |
Delta Live Table Advanced
|
Plan |
AWS Databricks Pricing (AP Mumbai region) |
Azure Databricks Pricing |
GCP Databricks Pricing |
|
Premium |
$0.36 per DBU |
$0.54 per DBU |
$0.36 per DBU |
|
Enterprise |
$0.25 per DBU |
- |
- |
3) Databricks SQL Pricing
Databricks SQL is optimized for interactive analytics on massive datasets within the lakehouse architecture. It enables high‑performance SQL querying without the need for data movement. Databricks SQL pricing comes in SQL Classic, SQL Pro, and SQL Serverless options.
| Cloud Platform | Plan | SQL Classic ($/DBU) | SQL Pro ($/DBU) | SQL Serverless ($/DBU, includes cloud instance cost) |
|---|---|---|---|---|
| AWS (US East (N. Virginia)) | Premium | 0.22 | 0.55 | 0.70 |
| AWS (US East (N. Virginia)) | Enterprise | 0.22 | 0.55 | 0.70 |
| Azure (US East (N. Virginia)) | Premium (Only plan available) | 0.22 | 0.55 | 0.70 |
| GCP | Premium (Only plan available) | 0.22 | 0.69 | 0.88 (Preview) |
5) Databricks Pricing for Data Science & ML
Databricks supports full‑cycle data science and machine learning workloads with collaborative notebooks, Databricks MLflow, and Delta Lake integration. Pricing here reflects the cost of running interactive and automated ML workloads.
Databricks offers pricing options for running data science and machine learning workloads, which vary based on the cloud provider (AWS, Azure, or Google Cloud Platform) and the chosen plan (Standard, Premium, or Enterprise).
| Cloud Provider (Region) | Plan | Classic Clusters ($/DBU) | Serverless ($/DBU) |
|---|---|---|---|
| AWS (AP Mumbai) | Premium | 0.55 | 0.75 (Preview; includes compute; 30% discount from May 2024) |
| AWS (AP Mumbai) | Enterprise | 0.65 | 0.95 (Preview; includes compute; 30% discount from May 2024) |
| Azure (US East) | Standard | 0.40 | N/A |
| Azure (US East) | Premium | 0.55 | 0.95 (Preview; includes compute; 30% discount from May 2024) |
| GCP | Premium | 0.55 | N/A |
6) Databricks Pricing for Model Serving
Databricks Model Serving allows for low-latency, auto-scaling deployment of ML models for inference, enabling integration with applications. Pricing varies based on serving type and Databricks plan, and includes cloud instance costs.
Model Serving and Feature Serving
| Plan | AWS Databricks Pricing (US East (N. Virginia)) | Azure Databricks Pricing (US East region) | GCP Databricks Pricing |
| Premium | $0.070 per DBU (includes cloud instance cost) | $0.07 per DBU (includes cloud instance cost) | $0.088 per DBU (includes cloud instance cost) |
| Enterprise | $0.07 per DBU (includes cloud instance cost) | - | - |
GPU Model Serving
| Plan | AWS Databricks Pricing (US East (N. Virginia)) | Azure Databricks Pricing (US East region) | GCP Databricks Pricing |
| Premium | $0.07 per DBU (includes cloud instance cost) | $0.07 per DBU (includes cloud instance cost) | - |
| Enterprise | $0.07 per DBU (includes cloud instance cost) | - | - |
Databricks provides a pricing calculator tool to help estimate costs based on your specific use case, service selections, and anticipated workload.
Check out this article to learn more in-depth about Databricks pricing.
Google Cloud Dataproc vs Databricks—Pros & Cons
Google Cloud Dataproc Pros and Cons:
🔮 Google Cloud Dataproc Pros:
- Google Cloud Dataproc clusters typically launch in ~90 seconds, enabling near-immediate processing.
- Google Cloud Dataproc seamlessly connects with Cloud Storage, Google BigQuery, Google BigTable, and other GCP services.
- Google Cloud Dataproc supports Apache Hadoop, Apache Spark, Flink, Presto, and over +30 open source tools for versatile data workflows.
- Google Cloud Dataproc offers per-second billing and auto-scaling, optimizing cost for dynamic workloads.
- Google Cloud Dataproc allows precise tuning of machine types, network settings, and software versions.
- Google Cloud Dataproc leverages integrated IAM, VPC Service Controls, and encryption to secure data and operations.
- Google Cloud Dataproc automates provisioning, maintenance, and updates, reducing operational overhead.
- Google Cloud Dataproc dynamically scales compute resources based on workload demand.
- Google Cloud Dataproc provides a serverless option that abstracts infrastructure management for transient Apache Spark jobs.
- Google Cloud Dataproc supports ephemeral clusters that terminate automatically after job completion, minimizing idle costs.
🔮 Google Cloud Dataproc Cons:
- Google Cloud Dataproc demands a deep understanding of distributed frameworks like Apache Hadoop and Apache Spark.
- Google Cloud Dataproc’s tight integration with GCP can complicate migration to other cloud providers.
- Google Cloud Dataproc may lack some advanced collaborative and data management features found in platforms such as Databricks.
- Google Cloud Dataproc’s serverless mode can experience delays when scaling from an idle state.
- Google Cloud Dataproc can increase administrative overhead when managing clusters across multiple regions.
- Google Cloud Dataproc’s auto-scaling policies require careful tuning to prevent resource under- or over-provisioning.
- Google Cloud Dataproc may need additional manual configuration to integrate niche or custom frameworks.
- Google Cloud Dataproc’s tight coupling with the GCP ecosystem can hinder seamless integration with on-premises or multi-cloud environments.
- Google Cloud Dataproc may introduce latency during data transfers across regions or external systems.
- Google Cloud Dataproc often requires extensive tuning of distributed processing parameters to achieve optimal performance.
Databricks pros and cons:
🔮 Databricks Pros:
- Databricks streamlines data engineering, analytics, and AI/ML into one cohesive environment.
- Databricks works flawlessly on AWS, Azure, and Google Cloud, allowing you to use your favorite cloud while avoiding vendor lock-in.
- Databricks offers interactive notebooks that support Python, SQL, R, and Scala.
- Databricks' Delta Lake adds ACID transactions and versioning to data lakes, ensuring data consistency and making data governance easier.
- Databricks integrates enterprise-grade security features, including fine-grained access control and encryption, to protect sensitive data.
- Databricks' native integration with Databricks MLflow, as well as its rich ML libraries, enables end-to-end machine learning lifecycle management.
- Databricks clusters can automatically scale up or down based on workload demands.
- Databricks supports a wide range of connectors and integrations with BI tools, data sources, and third-party platforms.
- Databricks has a large user community, comprehensive tutorials, and detailed documentation to help users quickly ramp up and troubleshoot challenges.
🔮 Databricks Cons:
- Databricks can be expensive for large-scale deployments if workloads and clusters are not carefully optimized.
- Databricks' variable workloads and varied pricing models make overall costs difficult to estimate and control.
- Beginners may struggle with the advanced concepts of Apache Spark and distributed computing inherent in the platform.
- Databricks is primarily optimized for Apache Spark, which can restrict its flexibility for non-Spark or alternative processing frameworks.
- Databricks offers auto-scaling, fine-tuning, and cluster management for optimal performance, although this typically necessitates extensive technical knowledge.
- Databricks is a cloud-native solution, therefore performance and availability are dependent on the underlying cloud architecture.
- Some advanced features are proprietary, potentially increasing the risk of vendor lock-in and limiting portability.
- Databricks has fewer no-code/low-code interfaces than some competitors, which may limit its adoption by non-technical users.
- Databricks excels at batch processing, but ad hoc query performance might be variable and may require more tuning.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Conclusion
And that's a wrap! So, how do you decide between Google Cloud Dataproc vs Databricks? It all comes down to your workload needs, your team's preferences, and the cloud ecosystem you're rooted in. If you're heavily invested in Google Cloud and need a cost-effective solution that uses a variety of open source frameworks/tools, Dataproc is likely your top choice. Its fast setup, per-second billing, and seamless integration with GCP services are big advantages. But if you want a unified platform that brings data processing, analytics, and machine learning together—and you need it to work with multiple cloud providers—Databricks is probably the way to go.
In this article, we have covered:
- What is Databricks?
- What is Google Cloud Dataproc?
- What Is the Difference Between Dataproc vs Databricks?
- Google Cloud Dataproc vs Databricks—Architecture Breakdown
- Google Cloud Dataproc vs Databricks—Data Processing Capabilities
- Google Cloud Dataproc vs Databricks—Ecosystem Integration & Deployment Models
- Google Cloud Dataproc vs Databricks—Developer Experience & Workspace Environment
- Google Cloud Dataproc vs Databricks—Data Science & Machine Learning Capabilities
- Google Cloud Dataproc vs Databricks—Security and Governance
- Google Cloud Dataproc vs Databricks—Pricing Breakdown
… and so much more!
FAQs
Is Dataproc similar to Databricks?
No. Dataproc is Google Cloud’s managed service for open source tools (Apache Hadoop, Apache Spark, Apache Hive, etc.) with flexible, on‑demand cluster provisioning, whereas Databricks is a unified analytics platform built atop Apache Spark that adds optimized runtimes, collaborative notebooks, Delta Lake (for ACID transactions), and built‑in ML tools.
What is the equivalent of Dataproc in AWS?
Amazon EMR (Elastic MapReduce) is the AWS equivalent—a managed cluster service that supports Apache Hadoop, Apache Spark, Apache Hive, and related frameworks with integration to AWS storage (S3) and other native services.
What is the purpose of Dataproc?
Dataproc is designed for quickly provisioning and managing clusters that run Apache Hadoop, Apache Spark, and other open source tools. It is ideal for batch processing, ETL, and real-time streaming when you work within the Google Cloud ecosystem.
Who is Databricks' biggest competitor?
In the unified analytics space, Snowflake is often cited as a major rival—especially as its data lakehouse capabilities grow. Also, platforms like GCP Dataproc and Amazon EMR compete in the broader big‑data processing market.
How does Databricks improve Spark performance?
Databricks enhances Apache Spark through the use of the Photon engine, which speeds up SQL queries, and Delta Lake, which provides reliable, ACID-compliant storage for data transformations and streaming applications.
Can I run Databricks on multiple cloud platforms?
Yes. Databricks is available on AWS, Azure, and GCP.
How do security features compare between Dataproc vs Databricks?
Dataproc relies on GCP’s native security tools like Cloud IAM, VPC Service Controls, and encryption protocols. Databricks integrates security into its workspace with features such as Unity Catalog, cloud IAM integration (AWS IAM, Azure AD, Google Cloud IAM), and secure cluster connectivity and more check out the above article.
Which platform is better: Dataproc or Databricks for collaborative data science?
Databricks. It provides a unified workspace with interactive notebooks, version control, and collaborative tools, making it highly suitable for teams that need to work together on data projects.
What is Dataproc used for?
Dataproc is used to run large‑scale data processing workloads on Google Cloud. It supports batch processing, streaming, ETL, and machine learning by provisioning clusters that run Apache Hadoop, Apache Spark, Flink, Presto, and over 30 open‑source tools—all while integrating with Google Cloud Storage and other native services.
Is Dataproc an ETL tool?
Not exactly—it is an infrastructure service that lets you run ETL workflows using open‑source tools.
What is the difference between Dataproc and Google BigQuery?
Dataproc is a managed cluster service for processing data with Apache Spark/Apache Hadoop jobs, offering full control over the runtime environment. In contrast, Google BigQuery is a fully managed, serverless data warehouse optimized for fast, SQL‑based analytics on structured and semi‑structured data without requiring cluster provisioning.
What are the job types in Dataproc?
Dataproc supports various job types including:
- Apache Spark jobs (e.g. PySpark, Spark SQL, Scala/Java applications)
- Apache Hadoop MapReduce jobs
- Apache Hive queries
- Pig scripts
- Presto jobs
and more!
Is Dataproc serverless?
Classic Dataproc service requires provisioning clusters; however, Google has introduced Dataproc Serverless for Apache Hive and Apache Spark jobs—abstracting cluster management for certain workloads while still charging per job execution
Is Dataproc the same as EMR?
No. They serve similar purposes, but Dataproc is Google Cloud's offering and tightly integrated with its ecosystem. Amazon EMR is AWS's managed service for Apache Hadoop/Apache Spark workloads. The two differ in pricing models, operational details, and how they integrate with their respective cloud services.















