




























PySpark is essentially the Python API you use to pass instructions to Apache Spark. It enables you to perform real-time, large-scale data processing in a distributed environment using Python. If you're not familiar, Apache Spark is like a super powerful fully open source engine that's made to handle massive volumes of data quickly and easily. You can run it on your own machine, or scale it up with platforms like Databricks to tackle anything from simple data transformations to complex machine-learning tasks. If you're working with a massive volume of data, chances are you'll need to clean up your data, keep it accurate, or analyze what's unique in your dataset. Finding unique values in column does more than just cut down on repetition; it helps make your data more insightful, your analyses more targeted, and your findings more reliable.
In this article, we'll cover the most effective ways to find and extract unique values in a table column using PySpark, with four practical examples and some performance optimization techniques.
PySpark in a Nutshell
PySpark is the Python API for Apache Spark. It allows you to process large datasets using Python, leveraging Spark's capabilities for distributed computing and data processing. PySpark provides a rich set of libraries and tools for data analysis, machine learning, and stream processing.

Here are some key features of PySpark:
- PySpark processes data in memory, which is faster than disk-based methods.
- PySpark supports multiple languages, including Python, Java, Scala, and R.
- PySpark offers disk and memory caching to boost performance during data processing tasks.
- PySpark scales from a single machine to thousands of nodes, handling data of any size.
- Integration with Python Libraries: PySpark integrates with popular Python libraries like Pandas, NumPy and more, allowing for enhanced data manipulation and analysis capabilities.
- PySpark supports advanced analytics through modules like MLlib for machine learning and GraphFrames for graph processing.
- PySpark works with Spark Streaming to handle real-time data inputs from multiple sources.
Check out the video below to learn more in-depth about PySpark.
PySpark Tutorial - PySpark Unique Values in Column
Save up to 50% on your Databricks spend in a few minutes!


Inside PySpark Architecture
To dig into PySpark, we need to first explore its architecture. So, what happens behind the scenes of PySpark? PySpark wraps the Apache Spark engine in a Python-friendly API. When you run a PySpark program, your Python code is translated into Spark tasks that are scheduled and executed across multiple nodes in a cluster.
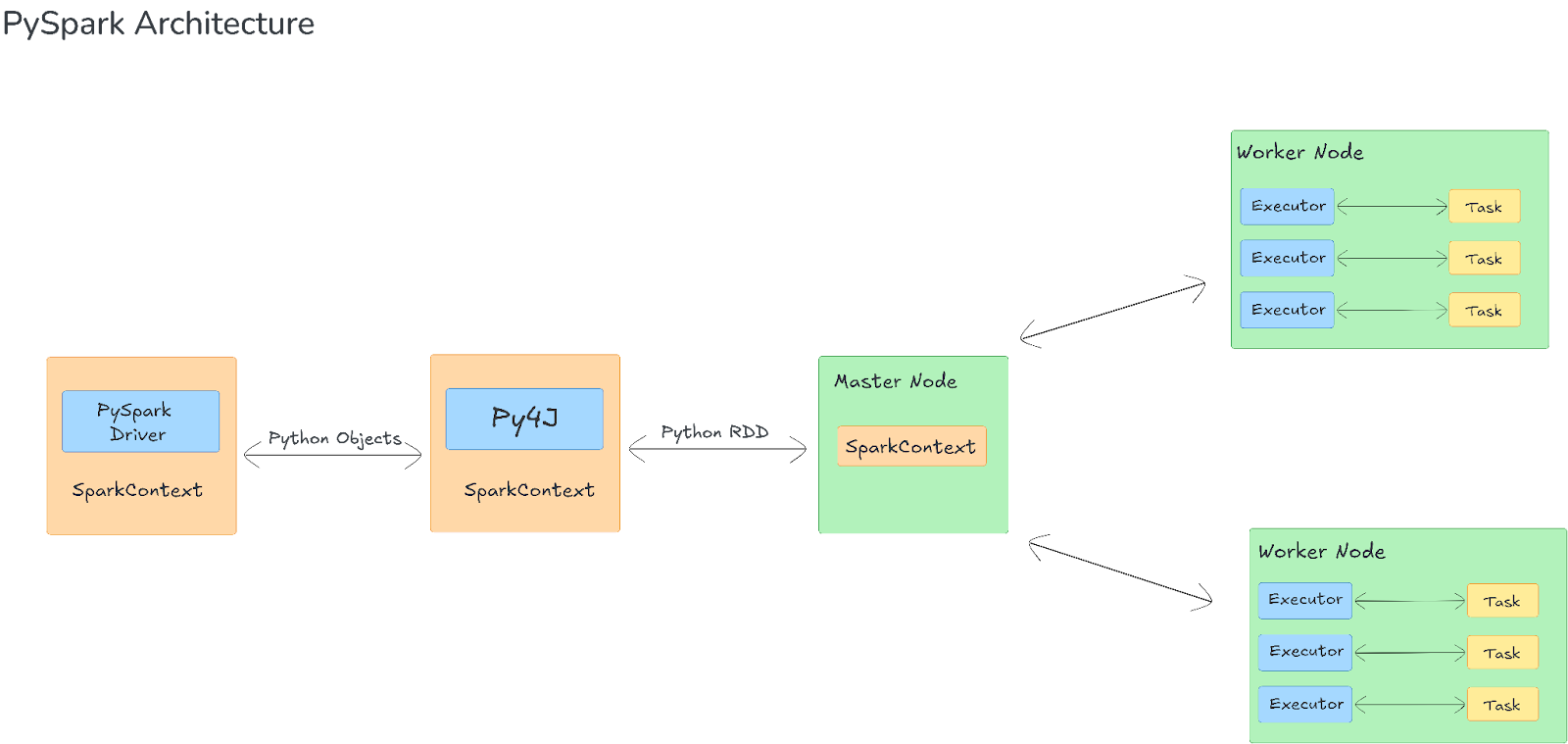
1) Driver Program and SparkContext
In PySpark, the driver program serves as the application's entry point. It defines transformations and actions on distributed datasets (RDDs or DataFrames) and orchestrates the overall execution by communicating with worker nodes.
SparkContext (and, in Spark 2.0 and later, the unified SparkSession) is the primary entry point for Spark’s functionality. During initialization, SparkContext starts a Java Virtual Machine (JVM) process on the local machine and establishes communication via Py4J—a library that facilitates bidirectional calls between Python and the JVM. This mechanism creates a corresponding JavaSparkContext on the JVM side, making sure that Spark operations run within the JVM while the application logic is written in Python.
2) Cluster Manager Integration
PySpark seamlessly integrates with various cluster managers—YARN, Mesos, Kubernetes, and Spark’s own standalone mode. The cluster manager is responsible for resource allocation (CPU, memory) and task distribution across the cluster. When the driver program submits an application, the cluster manager:
- Assigns executors to worker nodes.
- Monitors node health and restarts failed tasks (fault tolerance).
- Dynamically scales resources based on workload demands.
3) Executors and Task Execution
Executors are JVM processes running on worker nodes. They perform the actual data processing on individual data partitions. Each worker node can run one or more executors, which apply operations—such as filtering, mapping, and aggregating data—and store intermediate results in memory or on disk as required. The executors then communicate the results back to the driver.
PySpark leverages Spark’s lazy evaluation model: transformations (map, filter) are not executed immediately. Instead, Spark builds a Directed Acyclic Graph (DAG) of these transformations. When an action (count, collect) is invoked, Spark divides the DAG into stages, each containing multiple tasks. These tasks are executed in parallel across worker nodes, maximizing efficiency for large-scale data processing.
4) Communication Between Python and JVM (Py4J and TCP Sockets)
PySpark uses Py4J to enable communication between the Python driver and the JVM-based Spark engine. Py4J handles control messages—such as function calls and task orchestration—by allowing Python to invoke methods on JVM objects.
For actual data processing, Python objects are serialized—typically using Pickle or cloudpickle—and sent to the JVM. Spark executes the computations on the JVM side, and the results are serialized back to Python for further use. Data transfers between Python and JVM processes occur over TCP sockets, ensuring an efficient exchange of large serialized payloads even in distributed settings.
When you call a PySpark transformation like map or flatMap, PySpark serializes the Python function and sends it to the worker nodes. These transformations are housed in PythonRDD objects on the JVM side. These objects manage the serialization and execution of Python code on the workers.
On each worker node, a separate Python process (a Python worker) is spawned. This process deserializes the received function and data, executes the transformation locally on the data partitions, and then serializes the results back to the JVM. Worker nodes send results to the driver through TCP sockets, allowing parallel and distributed processing of Python-based transformations.
Now that you have a complete understanding of what PySpark is and how it works behind the scenes, let's dive in and understand what a PySpark DataFrame actually is.
PySpark DataFrames 101
PySpark DataFrame is a distributed collection of data organized into named columns—similar to a relational database table but optimized for large-scale, distributed processing. They are built atop Apache Spark’s resilient distributed dataset (RDD) abstraction, providing a high-level API for data manipulation and transformation. This API supports declarative SQL queries and functional programming paradigms.
DataFrames can ingest and process data from multiple sources. They handle structured file formats such as CSV, JSON, and Parquet; connect seamlessly to relational databases; and even accommodate streaming inputs. They leverage Spark’s Catalyst optimizer for query planning and optimization, and the Tungsten execution engine for efficient memory management and CPU utilization, ensuring performance and scalability in distributed environments.
Pyspark Dataframe Tutorial - PySpark Unique Values in Column
TLDR: PySpark DataFrames function as high-performance, distributed spreadsheets designed to process massive datasets seamlessly.
Creating a PySpark DataFrame
You can create a PySpark DataFrame from different sources:
- From a list of tuples (manual creation)
- From a structured file (CSV, JSON, Parquet, etc.)
- From an existing database or external data source
Let’s start with a very basic example.
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, IntegerType, StringType
# Initialize Spark Session
spark = SparkSession.builder.appName("PySparkDataFrameExample").getOrCreate()
# Define schema
schema = StructType([
StructField("ID", IntegerType(), True),
StructField("Name", StringType(), True),
StructField("Age", IntegerType(), True)
])
# Create DataFrame from list of tuples
data = [(1, "Elon Musk", 55), (2, "Jeff Bezos", 45), (3, "Mark Zuckerberg", 30)]
df = spark.createDataFrame(data, schema=schema)
# Show the DataFrame
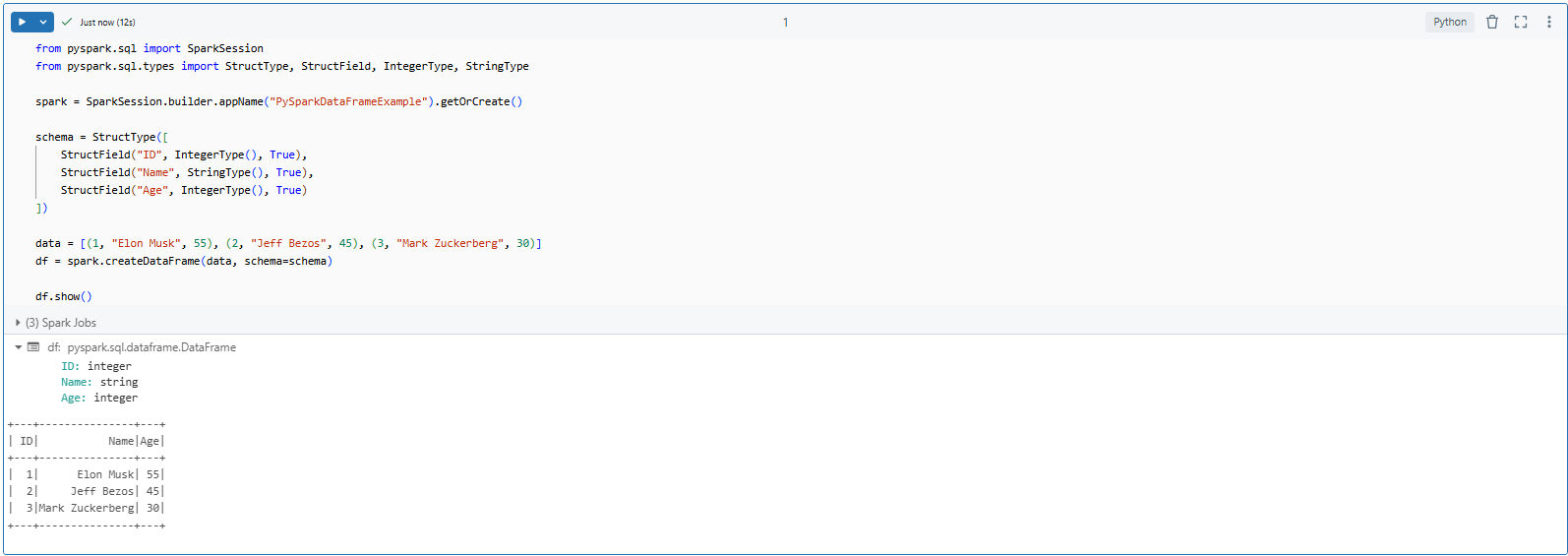
df.show()Here is what the output should look like.
Core Operations on PySpark DataFrames
Once you have a DataFrame, you can manipulate it using built-in PySpark functions. Some common operations include:
Selecting specific columns:
df.select("Name", "Age").show()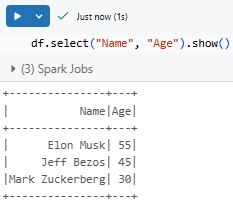
Filtering rows based on conditions:
df.filter(df.Age > 30).show()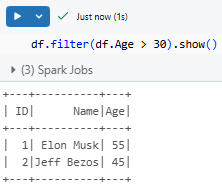
Adding new columns (w/ transformations):
from pyspark.sql.functions import col
df = df.withColumn("Age_30_Years_Later", col("Age") + 30)
df.show()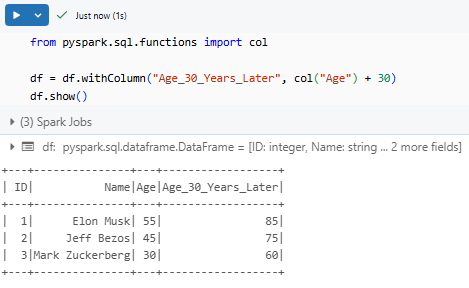
Grouping and aggregating data:
df.groupBy("Age").count().show()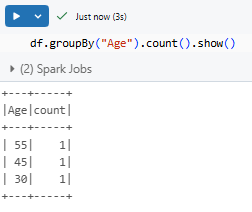
Sorting:
df.orderBy("Age", ascending=False).show()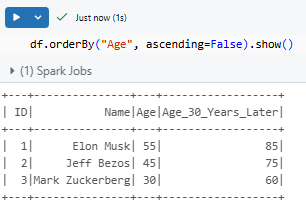
Removing duplicates:
df.dropDuplicates(["Name"]).show()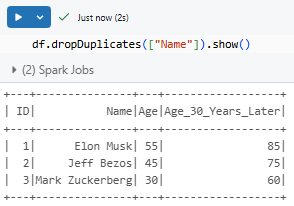
Converting PySpark to Pandas DataFrame (for local analysis):
pdf = df.toPandas()Caching:
Keep data in memory for faster access if you're going to use it multiple times.
df.cache()
These operations let you efficiently manipulate large datasets without loading everything into memory. Since PySpark executes operations lazily, transformations don’t run immediately—they're only triggered when an action like .show() or .collect() is called.
PySpark DataFrames provide a scalable way to work with big data.
Now, in the next section, we’ll explore how to extract unique values in column in PySpark, a common task in data cleansing and analysis.
Step-By-Step Practical Guide to Find Unique Values in Column in PySpark
If you are working with large datasets in PySpark, it is common to need a list of distinct values from a specific column. You might be analyzing customer segments, filtering unique product categories, or validating dataset integrity. PySpark provides efficient ways to extract unique values, and this step-by-step guide walks you through the process. We will explore 4 different examples:
- Example 1—Find Unique Values in Column Using PySpark distinct()
- Example 2—Find Unique Values in Column Using PySpark dropDuplicates() for Selective Column Uniqueness
- Example 3—Find Unique Values in Column Using PySpark groupBy()
- Example 4—Find Unique Values in Column Using SQL Queries in PySpark
Prerequisites
Now, before jumping into the steps, make sure you have:
- You need access to a Databricks account. Or, you can use Apache Spark locally. Here are the installation guides for Apache Spark on various operating systems:
- Basic knowledge of Python, SQL, and Apache Spark.
- Familiarity with PySpark DataFrame operations.
🔮 PySpark Example 1—Find Unique Values in Column Using PySpark distinct()
PySpark distinct() function removes duplicate values from a column, returning only the unique entries. Let’s break this down into practical steps.
Step 1—Login to Databricks
If you're using Databricks, sign in to your account. If you're running locally, launch a Jupyter Notebook with PySpark installed or use PySpark in a terminal. For the purpose of this article, we will use Databricks. If you are not familiar with Databricks, you can skip the first three steps and resume from step four onwards.
Step 2—Configure Databricks Compute Cluster
Before you can execute any code, you must have an active Databricks compute cluster. To set this up, navigate to the "Compute" section on the left sidebar. If you don't have a cluster or require a new one, select "Create Compute". For local environments, make sure your Spark session is running.
Next, configure the cluster settings to suit your requirements.
If the cluster is not already running, start it.
Step 3—Open Databricks Notebook (or your preferred PySpark interface)
In Databricks, go to the Databricks Workspace, create a new Databricks Notebook, and attach it to your cluster. For local use, initiate a Python script with Spark configured.
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType
spark = SparkSession.builder.appName("PySparkUniqueValuesInColumn").getOrCreate()Step 4—Create a Sample DataFrame and Populate with Sample Data
Let's create a simple PySpark DataFrame to work with, including some duplicate values.
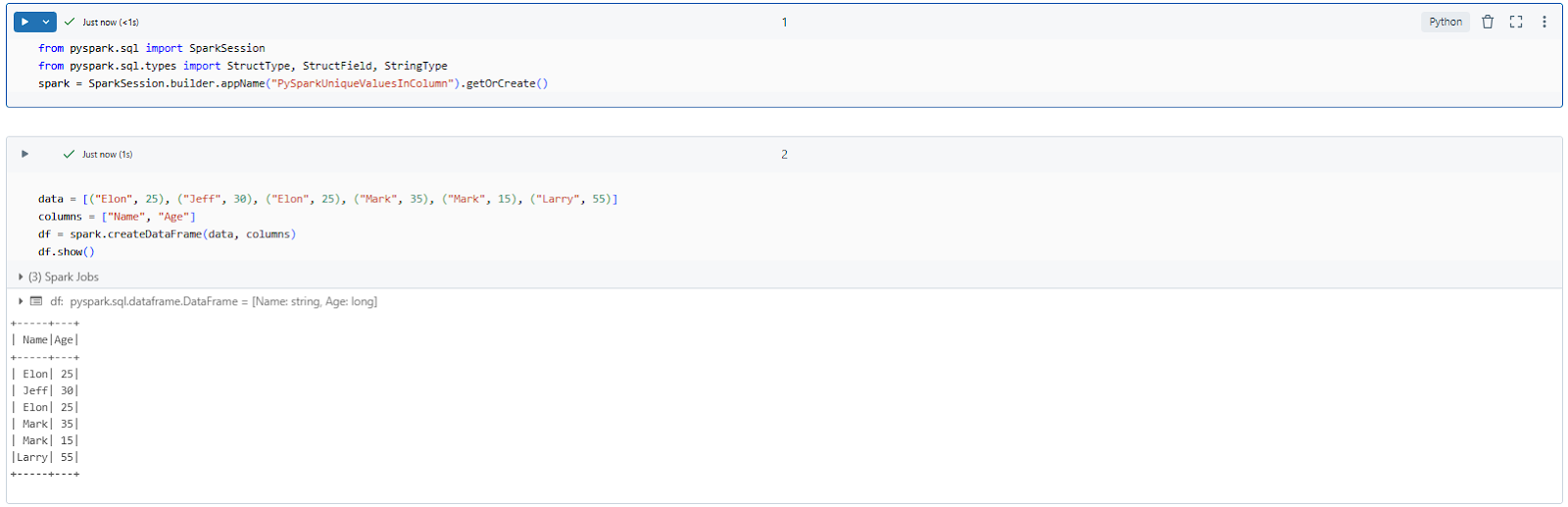
data = [("Elon", 25), ("Jeff", 30), ("Elon", 25), ("Mark", 35), ("Mark", 15), ("Larry", 55)]
columns = ["Name", "Age"]
df = spark.createDataFrame(data, columns)
df.show()Here is what the output should look like.
Step 5—Extract Unique Values Using PySpark distinct()
Now to find unique names, apply PySpark distinct() to remove duplicates.
pyspark_unique_values_in_column = df.select("Name").distinct()
pyspark_unique_values_in_column.show()This gives us:
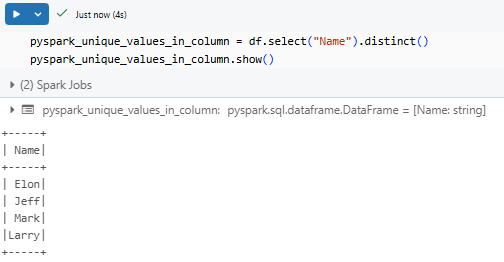
As you can see, this gives you a PySpark DataFrame containing only unique values.
Optional—Convert Unique Values to a List
If you need the unique values as a list instead of a PySpark DataFrame, use PySpark collect() function in combination with list comprehension.
pyspark_unique_values_in_column_to_list = [row.Name for row in pyspark_unique_values_in_column.collect()]
print(pyspark_unique_values_in_column_to_list)This gives us:

Step 6—Find and Sort Unique Values in Column
If you want unique values in sorted order, chain PySpark orderBy().
sorted_names = pyspark_unique_values_in_column.orderBy("Name")
sorted_names.show()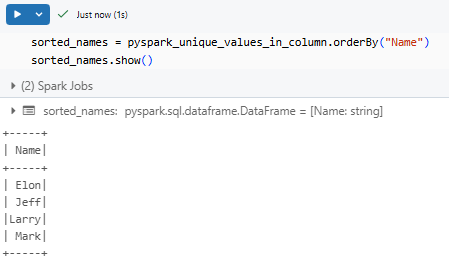
As you can see, this sorts the unique values in ascending order.
You can use PySpark orderBy("Name", ascending=False) for descending order.
sorted_names = pyspark_unique_values_in_column.orderBy("Name", ascending=False)
sorted_names.show()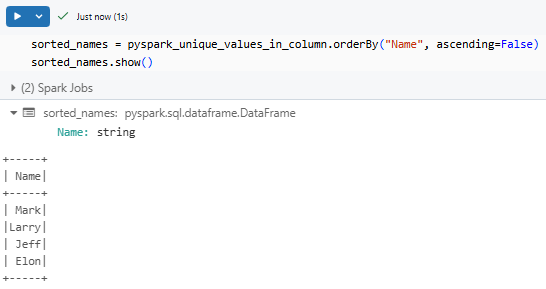
Step 7—Performance Optimization Technique for Large Datasets
If you have thousands or even millions of rows or columns, performance may drop. Still, a few simple tweaks can greatly speed up your operations.
1) Cache the PySpark DataFrame—If you need to use the unique values multiple times, caching prevents recomputation.
pyspark_unique_values_in_column.cache()2) Use PySpark count() function to get the number of unique values without displaying them all:
unique_count = pyspark_unique_values_in_column.count()
print(f"PySpark Unique Values in Column: {unique_count}")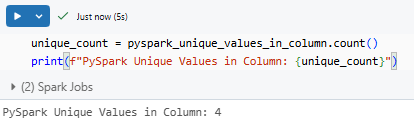
As you can see, it's just not practical to display thousands of values. So this helps prevent that from happening.
Take note, when working with big datasets, these optimizations can really pay off in terms of performance. You're not just checking for uniqueness—you're doing it in a way that keeps processing time and resource use under control.
PySpark distinct() function is a simple way to get unique values in column, but for large datasets, it's better to temporarily store the data, count it, and then gather the results to avoid slowdowns. In the next section, we'll explore how to extract unique values in column using PySpark dropDuplicates() function, so let's dive right in!
🔮 PySpark Example 2—Find Unique Values in Column Using PySpark dropDuplicates() for Selective Column Uniqueness
Just like in the previous example with PySpark distinct(), PySpark has another method to get unique values from a column: the PySpark dropDuplicates() function. So, what's the difference between this and PySpark distinct()? Well, distinct() looks at the entire PySpark DataFrame and removes rows where every single column value matches. PySpark dropDuplicates() is more flexible—it lets you choose which columns to consider when deciding what's unique. This particular method is super useful when you want to filter out duplicates based on just a few columns, without touching the rest of the data.
Let’s break it down.
Step 1 to Step 3—Setup Your PySpark Environment
These steps remain the same as in the PySpark distinct() example:
- Step 1—Login to Databricks or start a PySpark session in your preferred environment.
- Step 2—Make sure your Databricks Compute cluster or local PySpark setup is running.
- Step 3—Open a Databricks Notebook or a Python script with PySpark initialized.
If you've already done this, move on to the next step.
Step 4—Create a Sample PySpark DataFrame
Let’s create a dataset with duplicate values across different columns.
First, we need to import the required libraries from PySpark. We also import various types from pyspark.sql.types to define the schema of our PySpark DataFrame.
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerTypeNext, we initialize a Spark session, which is the entry point to using PySpark.
spark = SparkSession.builder.appName("PySparkUniqueValuesInColumnExample").getOrCreate()Then, we define the schema for our PySpark DataFrame. The schema specifies the structure of the data, including the column names and their data types.
schema = StructType([
StructField("Category", StringType(), True),
StructField("Product", StringType(), True),
StructField("Price", IntegerType(), True)
])After that, we create a PySpark DataFrame with some duplicate data for demonstration purposes:
data = [
("Electronics", "Laptop", 2000),
("Electronics", "Laptop", 2000),
("Electronics", "Smartphone", 350),
("Furniture", "Chair", 50),
("Furniture", "Table", 300),
("Furniture", "Chair", 50),
("Electronics", "Laptop", 2000),
("Furniture", "Chair", 50),
("Electronics", "Smartphone", 350),
("Electronics", "Laptop", 2000),
("Furniture", "Chair", 50),
("Electronics", "Smartphone", 350),
("Electronics", "Laptop", 2000),
("Furniture", "Table", 300),
("Furniture", "Chair", 50),
("Electronics", "Laptop", 2000),
("Furniture", "Chair", 50),
("Furniture", "Table", 300)
]
df = spark.createDataFrame(data, schema=schema)Finally, we display the initial PySpark DataFrame to see how it looks:
df.show()Here is the complete code put together:
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
spark = SparkSession.builder.appName("PySparkUniqueValuesInColumnExample").getOrCreate()
schema = StructType([
StructField("Category", StringType(), True),
StructField("Product", StringType(), True),
StructField("Price", IntegerType(), True)
])
data = [
("Electronics", "Laptop", 2000),
("Electronics", "Laptop", 2000),
("Electronics", "Smartphone", 350),
("Furniture", "Chair", 50),
("Furniture", "Table", 300),
("Furniture", "Chair", 50),
("Electronics", "Laptop", 2000),
("Furniture", "Chair", 50),
("Electronics", "Smartphone", 350),
("Electronics", "Laptop", 2000),
("Furniture", "Chair", 50),
("Electronics", "Smartphone", 350),
("Electronics", "Laptop", 2000),
("Furniture", "Table", 300),
("Furniture", "Chair", 50),
("Electronics", "Laptop", 2000),
("Furniture", "Chair", 50),
("Furniture", "Table", 300)
]
df = spark.createDataFrame(data, schema=schema)
df.show()This gives us:
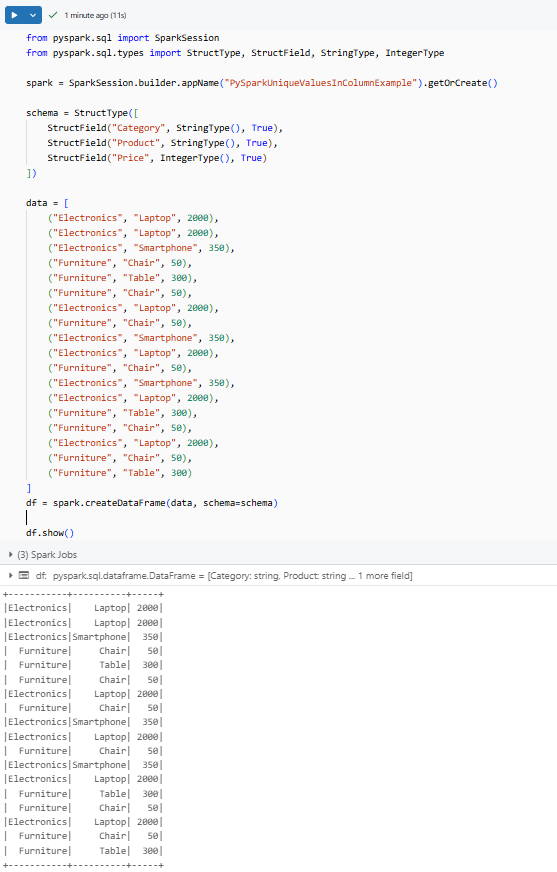
Step 5—Get Unique Values Based on a Single Column
Let’s say you want to extract unique Category values while ignoring duplicates within the Product and Price columns. The PySpark dropDuplicates(["Category"]) method achieves this:
pyspark_unique_values_in_column_df = df.dropDuplicates(["Category"])
pyspark_unique_values_in_column_df.show()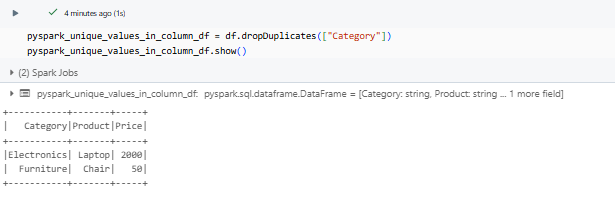
Notice that PySpark dropDuplicates(["Category"]) keeps only the first occurrence of each unique category while retaining the rest of the row’s data from that occurrence. The remaining duplicate categories are removed.
Step 6—Get Unique Values Based on Multiple Columns
But hold on, if you want to get unique values based on more than one column, you can pass multiple column names to PySpark dropDuplicates(). For example, to remove duplicates based on both Category and Product but allow price variations:
unique_category_product_df = df.dropDuplicates(["Category", "Product"])
unique_category_product_df.show()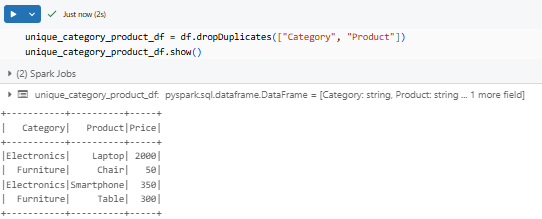
Now, duplicate Category-Product combinations are removed, but different products within the same category remain.
Step 7—Sorting Unique Values
To make the results more readable, you can apply sorting with PySpark orderBy(). Here’s how to get unique categories sorted alphabetically:
sorted_unique_categories_df = unique_categories_df.orderBy("Category")
sorted_unique_categories_df.show()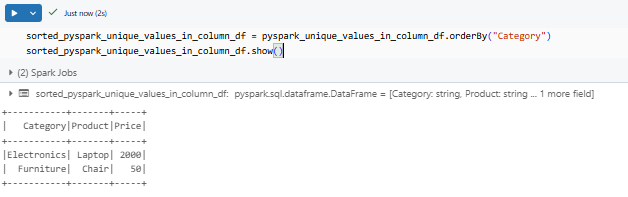
If sorting by multiple columns, specify them inside PySpark orderBy():
sorted_df = unique_category_product_df.orderBy("Category", "Product")
sorted_df.show()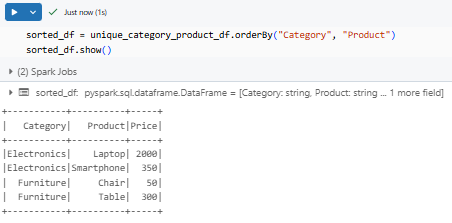
Sorting makes analysis and debugging easier when working with large datasets.
Step 8—Count Unique Values in Column
If you just need the count of unique values without displaying them all, use PySpark count() after PySpark dropDuplicates().
For a single column:
unique_category_count = df.dropDuplicates(["Category"]).count()
print(f"Number of unique categories: {unique_category_count}")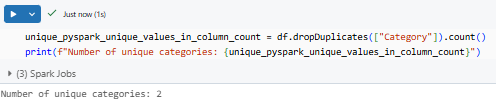
For multiple columns:
unique_category_product_count = df.dropDuplicates(["Category", "Product"]).count()
print(f"Number of unique Category-Product pairs: {unique_category_product_count}")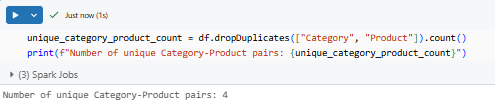
This prevents unnecessary memory usage when the full PySpark DataFrame isn’t required.
Optional—Convert Unique Values to a List
Sometimes, you may need the unique values in a Python list rather than a DataFrame. Use PySpark collect() to achieve this:
unique_category_list = [row["Category"] for row in pyspark_unique_values_in_column_df.collect()]
print(unique_category_list)Output:

If working with multiple columns:
unique_category_product_list = [(row["Category"], row["Product"]) for row in unique_category_product_df.collect()]
print(unique_category_product_list)Here is what your output should look like:

PySpark dropDuplicates() is more flexible than PySpark distinct() because it lets you control which columns define uniqueness. Whether working with single or multiple columns, this method is a simple way to filter out redundant data while keeping necessary context intact. When dealing with massive datasets, always consider caching (cache()) or persisting (persist()) to optimize performance, especially when performing multiple operations on the same DataFrame.
🔮 PySpark Example 3—Find Unique Values in Column Using PySpark groupBy()
Now, in this section, we will dive into how to extract unique values from a column using the PySpark groupBy(). This technique aggregates data by a column (or columns), letting you count occurrences for each unique value. It works well when you want to see how often each unique value appears.
Let’s walk through each of the steps.
Step 1 to Step 3—Setup Your PySpark Environment
As with earlier PySpark examples, start by setting up your PySpark session. Login to Databricks or run a local PySpark session. Open your Databricks Notebook (attach it to your Databricks compute cluster) or use your preferred code editor/IDE.
Step 4—Create a Sample PySpark DataFrame
Let’s now create a PySpark DataFrame with duplicate values to practice the PySpark groupBy() approach.
First, we need to import the necessary libraries from PySpark. pyspark.sql provides the core functionality for working with DataFrames, and pyspark.sql.types allows us to define the schema of our data.
from pyspark.sql import SparkSession
from pyspark.sql.types import StuctType, StructField, StringType, IntegerTypeNext, we initialize a SparkSession. This is the entry point for any Spark application and is essential for creating and manipulating DataFrames. The appName helps in identifying your application in the Spark UI. getOrCreate() checks that if a SparkSession already exists, it will be reused; otherwise, a new one will be created.
spark = SparkSession.builder.appName("PySparkUniqueValuesInColumnExample3").getOrCreate()Now, we define the schema for our PySpark DataFrame. A schema is crucial as it specifies the structure of the data, including column names and their corresponding data types. This helps Spark optimize data processing and guarantees data consistency. We're using StructType to define the overall structure and StructField to define each individual field (column).
schema = StructType([
StructField("StudentName", StringType(), True),
StructField("Course", StringType(), True),
StructField("Grade", IntegerType(), True)
])Here, we have three fields: StudentName (String type), Course (String type), and Grade (Integer type). The True argument in StructField indicates that these fields are nullable (can have null values).
Now that we have defined the schema, lets actually create our PySpark DataFrame. We'll use sample data that includes duplicate entries to demonstrate the PySpark groupBy() operation later on.
data = [
("Elon Musk", "Math", 85),
("Jeff Bezos", "Science", 92),
("Elon Musk", "Math", 85),
("Bernard Arnault", "History", 78),
("Bill Gates", "Science", 92),
("Elon Musk", "Science", 90),
("Warren Buffett", "Math", 88),
("Bernard Arnault", "History", 78),
("Elon Musk", "Math", 85),
("Jeff Bezos", "Science", 92),
("Warren Buffett", "Math", 88),
("Mark Zuckerberg", "English", 95),
("Mark Zuckerberg", "English", 95),
("Mark Zuckerberg", "English", 95)
]
df = spark.createDataFrame(data, schema=schema)The spark.createDataFrame() method creates the DataFrame from the provided data and applies the defined schema.
Let's take a look at our DataFrame to confirm its structure as expected:
df.show()df.show() displays the first 20 rows of the DataFrame. This is useful for inspecting the data and verifying that it has been loaded correctly.
Here is the complete code put together:
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
spark = SparkSession.builder.appName("PySparkUniqueValuesInColumnExample3").getOrCreate()
schema = StructType([
StructField("StudentName", StringType(), True),
StructField("Course", StringType(), True),
StructField("Grade", IntegerType(), True)
])
data = [
("Elon Musk", "Math", 85),
("Jeff Bezos", "Science", 92),
("Elon Musk", "Math", 85),
("Bernard Arnault", "History", 78),
("Bill Gates", "Science", 92),
("Elon Musk", "Science", 90),
("Warren Buffett", "Math", 88),
("Bernard Arnault", "History", 78),
("Elon Musk", "Math", 85),
("Jeff Bezos", "Science", 92),
("Warren Buffett", "Math", 88),
("Mark Zuckerberg", "English", 95),
("Mark Zuckerberg", "English", 95),
("Mark Zuckerberg", "English", 95)
]
df = spark.createDataFrame(data, schema=schema)
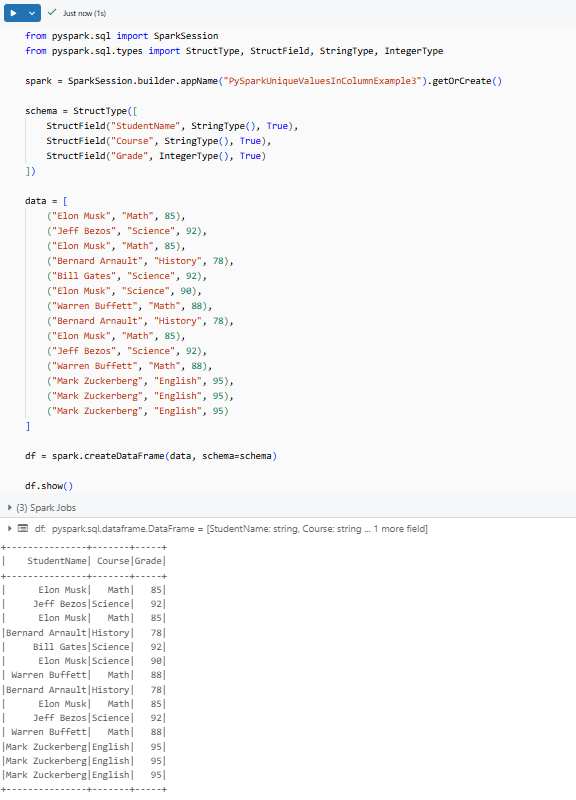
df.show()
This prints out:
Step 5—Find Unique Values in Column Using PySpark groupBy()
Now, to retrieve unique values from the “StudentName” column, group the PySpark DataFrame by that column and count the occurrences:
pyspark_unique_values_in_column_example_df = df.groupBy("StudentName").count()
pyspark_unique_values_in_column_example_df.show()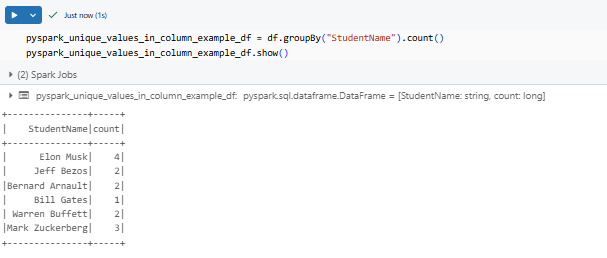
As you can see, this command groups the rows by StudentName and counts how many times each one appears.
The count lets you see the frequency of each unique category.
Step 6—Find Unique Values in Multiple Columns
If you want to extract unique combinations from multiple columns—for example, both “StudentName” and “Course”—apply PySpark groupBy() on both:
pyspark_unique_values_in_multiple_column_df = df.groupBy("StudentName", "Course").count()
pyspark_unique_values_in_multiple_column_df.show()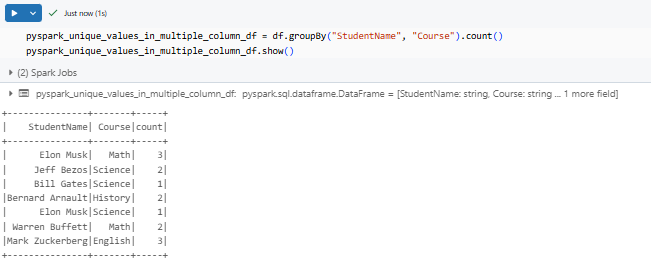
This groups rows where both columns match and gives you counts.
Step 7—Sorting Unique Values
Sorting the results helps you review the data more easily. Chain the PySpark orderBy() method to sort by a column. For example, to sort unique StudentName alphabetically:
sorted_pyspark_unique_values_in_column_df = df.groupBy("StudentName").count().orderBy("StudentName")
sorted_pyspark_unique_values_in_column_df.show()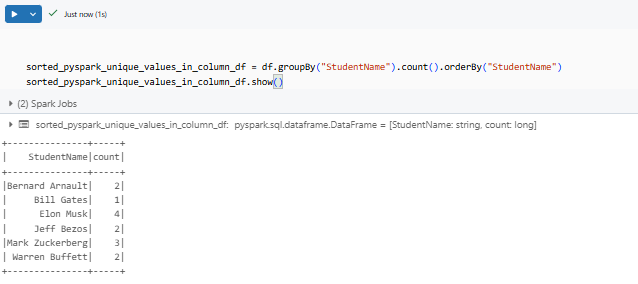
Likewise, if sorting multiple columns, list them inside PySpark orderBy():
sorted_pyspark_unique_values_in_multiple_column_df = df.groupBy("StudentName", "Course").count().orderBy("StudentName", "Course")
sorted_pyspark_unique_values_in_multiple_column_df.show()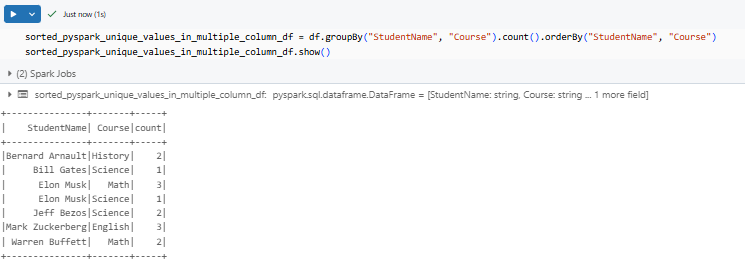
Here you can see that it displays the grouped data in an ordered fashion, making patterns and trends easier to spot.
Optional—Extract Unique Values to a List
At times, you might want to work with the unique values as a Python list rather than a PySpark DataFrame. Use the PySpark collect() method to gather the data:
unique_list = [row["StudentName"] for row in pyspark_unique_values_in_column_example_df.collect()]
print(unique_list)
For multiple columns:
unique_multiple_col_list = [(row["StudentName"], row["Course"]) for row in pyspark_unique_values_in_multiple_column_df.collect()]
print(unique_multiple_col_list)
You can see that this converts the PySpark DataFrame rows into a list, which you can then manipulate in pure Python.
Step 9—Performance Optimization Technique for Large Datasets
PySpark groupBy() operation may require significant computation on large datasets. To reduce processing time:
Cache the DataFrame:
Before grouping, cache your DataFrame so Spark holds the data in memory.
df.cache()Monitor and adjust partitions:
You might also use methods like PySpark repartition() if your dataset isn’t evenly distributed.
Caching helps when you plan to reuse the grouped results multiple times, cutting down on recomputation. Adjusting partitions can further improve performance by balancing the load across your cluster.
So by using PySpark groupBy() with count() offers a flexible way to extract unique values from your DataFrame, while also providing frequency information. This particular method serves you well for both single and multiple columns, especially when you want to inspect how many times each value occurs. Also, remember to apply performance optimizations like caching when working with large datasets to keep your computations fast and responsive.
🔮 PySpark Example 4—Find Unique Values in Column Using SQL Queries in PySpark
Finally, in this section, we'll look at a simple way to pull unique values from a PySpark DataFrame column using SQL queries. Here in this example you'll learn how to create a DataFrame, turn it into a temporary SQL table, and run queries to get, sort, and count unique values.
Step 1 to Step 3—Setup Your PySpark Environment
Start by launching your PySpark session. If you use Databricks, log in, create or attach to a Databricks compute cluster, and open a new Databricks notebook. Otherwise, launch your PySpark session locally. These initial steps are the same as in previous examples.
Step 4—Create a Sample DataFrame
Create a PySpark DataFrame with sample data to work with. Let's stick with the same example we used earlier (step 4 in example 3).
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
spark = SparkSession.builder.appName("PySparkUniqueValuesInColumnExample4").getOrCreate()
schema = StructType([
StructField("StudentName", StringType(), True),
StructField("Course", StringType(), True),
StructField("Grade", IntegerType(), True)
])
data = [
("Elon Musk", "Math", 85),
("Jeff Bezos", "Science", 92),
("Elon Musk", "Math", 85),
("Bernard Arnault", "History", 78),
("Bill Gates", "Science", 92),
("Elon Musk", "Science", 90),
("Warren Buffett", "Math", 88),
("Bernard Arnault", "History", 78),
("Elon Musk", "Math", 85),
("Jeff Bezos", "Science", 92),
("Warren Buffett", "Math", 88),
("Mark Zuckerberg", "English", 95),
("Mark Zuckerberg", "English", 95),
("Mark Zuckerberg", "English", 95)
]
df = spark.createDataFrame(data, schema=schema)
df.show()Output:
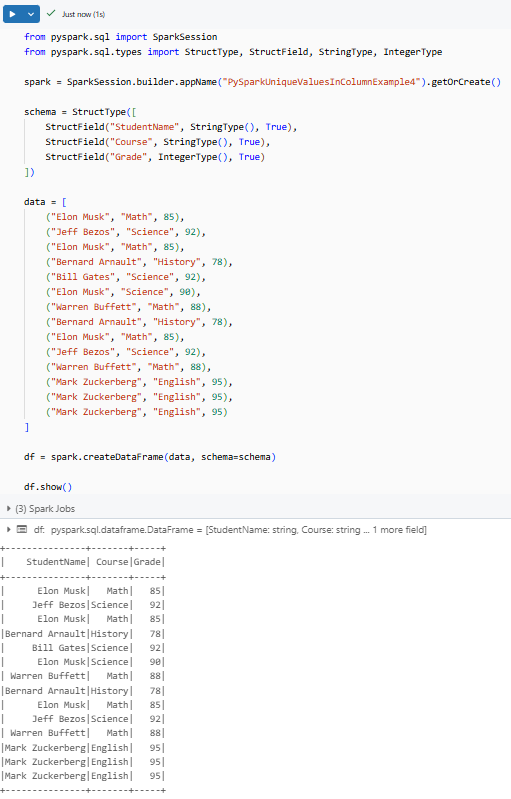
This prints a table with duplicate rows that you’ll filter using SQL.
Step 5—Register the DataFrame as a SQL Table
To run SQL queries, register your PySpark DataFrame as a temporary table. You can do this with:
df.createOrReplaceTempView("students_table")Now, you can use SQL syntax to query your data.
Step 6—Find Unique Values in Column Using SQL
Run a SQL query to extract distinct values from a column. For example, to get unique StudentName, use SQL SELECT DISTINCT Statement:
pyspark_unique_values_in_column_example = spark.sql("SELECT DISTINCT StudentName FROM students_table")
pyspark_unique_values_in_column_example.show()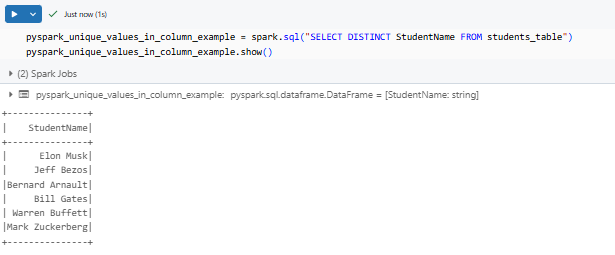
This query returns only one row per unique category.
Step 7—Find and Sort Unique Values in Column
If you need the unique values sorted, modify your SQL query with an ORDER BY clause. For example, to sort unique StudentName alphabetically:
sorted_pyspark_unique_values_in_column_example = spark.sql("SELECT DISTINCT StudentName FROM students_table ORDER BY StudentName")
sorted_pyspark_unique_values_in_column_example.show()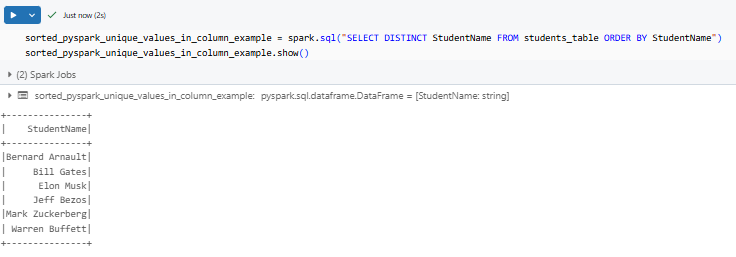
This sorts the results in ascending order by default.
If you want descending order, add DESC after the column name.
sorted_pyspark_unique_values_in_column_example = spark.sql("SELECT DISTINCT StudentName FROM students_table ORDER BY StudentName DESC")
sorted_pyspark_unique_values_in_column_example.show()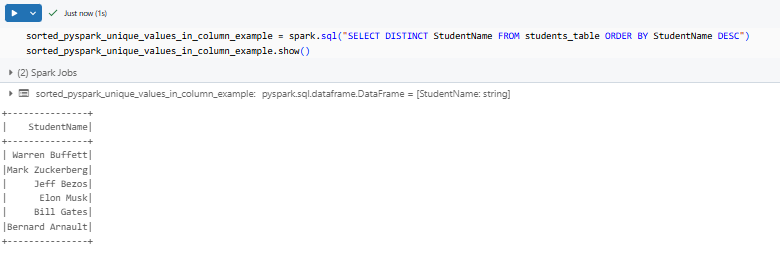
Step 8—Find and Count Unique Values in Column
To count how many unique values exist, you can combine SQL functions. For instance, to count unique StudentName:
unique_count = spark.sql("SELECT COUNT(DISTINCT StudentName) AS unique_count FROM students_table")
unique_count.show()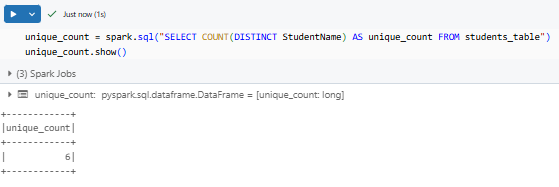
This returns a single row with the count of unique StudentName.
Step 9—Find Unique Values in Multiple Columns
If you need to extract unique combinations of multiple columns, modify your query to select distinct values on more than one column. For example, to get unique pairs of StudentName and Course:
unique_student_course = spark.sql("SELECT DISTINCT StudentName, Course FROM students_table")
unique_student_course.show()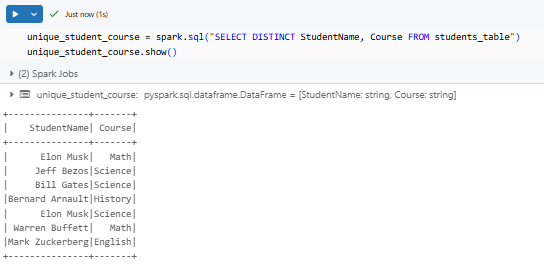
This query returns unique rows based on both columns.
Optional—Extract Unique Values as a Python List
Sometimes you want to work with the unique values in a Python list instead of a DataFrame. To do that, use the PySpark collect() method:
unique_students_list = [row["StudentName"] for row in pyspark_unique_values_in_column_example.collect()]
print(unique_students_list)
For multiple columns, use a list of tuples:
unique_student_course_list = [(row["StudentName"], row["Course"]) for row in unique_student_course.collect()]
print(unique_student_course_list)
You can see that this converts your SQL query results into a Python list, letting you use the values in your own Python code.
So if you're more familiar with SQL syntax, using it in PySpark is a no-brainer. Just register your DataFrame as a temporary table and you can run standard SQL queries—SELECT DISTINCT, ORDER BY, COUNT (DISTINCT, and so on. This method integrates perfectly with PySpark and other SQL operations.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Conclusion
And that's a wrap on our guide to extracting unique values using PySpark. You've seen how PySpark lets you pull distinct entries from your DataFrame using methods like PySpark distinct(), dropDuplicates(), groupBy(), and even SQL queries. This approach helps you work with your data quickly and reliably, whether you need a simple list or a detailed count of each unique entry. The techniques discussed allow you to work efficiently with large datasets and keep your data clean for further analysis.
In this article, we have covered:
- What is PySpark?
- Overview of PySpark architecture
- What is a PySpark DataFrame?
- Step-by-Step Practical Guide to Find Unique Values in Column in PySpark
… and so much more!
FAQs
What is a DataFrame in PySpark?
PySpark DataFrame is a distributed collection of data organized into named columns, much like a table in a relational database. It builds on RDDs to offer a more user-friendly API that supports SQL queries, complex aggregations, and various transformations on large datasets.
How do I create DataFrames in PySpark?
You can create a DataFrame using methods such as spark.createDataFrame() with a list of tuples or by loading data from external sources like CSV, JSON, or Parquet files. PySpark can also convert RDDs into DataFrames, allowing you to apply schema definitions either manually or through schema inference.
How do I find unique values in column in PySpark?
To extract unique values from a column, use df.select("column_name").distinct(). This returns a new DataFrame with duplicate entries removed. For further processing, you can convert the result into a Python list using PySpark collect().
What does distinct() do in PySpark?
PySpark distinct() returns a new DataFrame that contains only the unique rows of the original DataFrame. When applied to a single column, it extracts unique values by eliminating duplicate entries.
How to get unique values in a DataFrame column?
You can retrieve unique values by selecting the column and then applying the distinct() function, like so:
unique_df = df.select("column_name").distinct()
unique_df.show()If you prefer a Python list, convert the result using PySpark collect() and a list comprehension.
How do I count rows in PySpark?
Use the df.count() method to get the total number of rows in your DataFrame. This simple action triggers the execution of your DataFrame transformations and returns an integer.
How do I count distinct values in PySpark?
You can count the unique values in column by chaining distinct() with count() as in:
unique_count = df.select("column_name").distinct().count()Or, the PySpark countDistinct() function can perform a similar operation.
How do I remove duplicates in PySpark?
To remove duplicate rows entirely, use distinct(). If you want to remove duplicates based on a specific column or subset of columns, use dropDuplicates(["col1", "col2"]), which retains the first occurrence of each unique value combination.
How do I optimize performance when finding unique values in PySpark?
For large datasets, you can speed up operations by caching your DataFrame using df.cache() before applying transformations. Also, avoid using PySpark collect() on massive datasets since it transfers data to the driver node and might cause memory issues.
How do I handle performance considerations when using groupBy()?
PySpark groupBy() operations can be heavy on large datasets. To improve performance, cache your DataFrame, reduce the number of columns involved in the grouping, or adjust the number of partitions using methods like repartition() to balance the load across your cluster.
Can I use groupBy() on multiple columns?
Yes, you can pass multiple column names to PySpark groupBy(). This groups the data by unique combinations of the specified columns, allowing you to perform aggregations like counting the occurrences of each combination.
Can I use SQL queries to find unique values?
Yes. Register your DataFrame as a temporary SQL view using createOrReplaceTempView() and run SQL queries such as:
spark.sql("SELECT DISTINCT column_name FROM your_table").show()What is the role of PySpark collect()?
PySpark collect() method retrieves all the elements of a DataFrame or RDD to the driver node as a list. It is useful for small result sets when you need to perform further Python-based processing, but be careful when using it on large datasets.
What is the difference between dropDuplicates() and distinct()?
PySpark distinct() removes duplicate rows across all columns in the DataFrame, whereas dropDuplicates() lets you specify one or more columns for deduplication.
For example, df.dropDuplicates(["column_name"]) removes rows that have duplicate values in the specified column while retaining the rest of the data from the first occurrence.
What is countDistinct() in PySpark?
countDistinct() is an aggregate function that returns the count of distinct values in a column. It is useful when you want a quick summary of unique entries without fetching the entire list.
How can I convert unique DataFrame values to a Python list?
After obtaining unique values with distinct(), convert them to a list using:
unique_list = [row["column_name"] for row in df.select("column_name").distinct().collect()]It gives you a flat list of unique values for further processing.
How does caching help in PySpark?
Caching stores the DataFrame in memory across your Spark cluster, which speeds up repeated operations on the same dataset. It is useful when you perform multiple transformations or actions on data used to extract unique values.















