





























Databricks SQL—a serverless data warehouse solution built on lakehouse architecture, enabling users to streamline data management and analytics workloads. It leverages the scalability and flexibility of cloud platforms like Azure, AWS, and GCP behind the scenes. You can forget about manually configuring clusters and resources as you would when configuring all-purpose compute clusters or job compute clusters. Instead, focus on querying data without worrying about the underlying infrastructure. Databricks SQL helps you effortlessly run SQL queries, create interactive visualizations, and build intuitive dashboards to unlock the full potential of your data.
In this article, we will cover everything you need to know about what Databricks SQL has to offer, including an in-depth exploration of its features, capabilities, and best practices. We'll also provide a detailed, step-by-step tutorial on creating your own Databricks SQL warehous, and much more!
What Is Databricks SQL?
Databricks SQL (aka DBSQL) is a serverless data warehouse solution engineered on top of the robust Databricks Lakehouse architecture. It enables users to efficiently run all your business intelligence (BI) and extract, transform, and load (ETL) workloads at scale, with industry-leading performance and cost-efficiency. Databricks SQL seamlessly combines the benefits of data lakes and traditional data warehouses—offering the adaptability, cost-effectiveness, and scalability of data lakes, along with the governance, reliability, and security features of conventional data warehouses.
One of the standout features of Databricks SQL is its serverless nature, which relieves users of the burden of provisioning, managing, or scaling compute resources. Instead, Databricks SQL uses intelligent automation to scale up or down based on the workload, providing optimal performance while ensuring costs remain low.
Here's what makes Databricks SQL stand out:
- Serverless Architecture: Databricks SQL eliminates the need for provisioning, managing, or scaling compute resources, using intelligent automation to scale up or down based on workload demands.
- Lakehouse architecture: Databricks SQL combines the flexibility of data lakes with the structure of data warehouses, allowing users to store all their data in one place without duplication or movement.
- Unified governance: DBSQL provides a single, unified governance model across all data teams.
- Open formats and APIs: Databricks SQL uses open formats and APIs, so you can easily integrate it with your favorite tools and systems. No more vendor lock-in!
- Up to 12x better price/performance: Databricks SQL is designed to provide the best possible performance at the lowest possible cost.
- Rich ecosystem: Databricks SQL integrates seamlessly with popular tools like Fivetran, dbt, Power BI, Tableau, and Looker, allowing users to ingest, transform, and query all their data in one place.
- Break down silos: Databricks SQL empowers every analyst to access the latest data faster and easily move from BI to Machine Learning (ML) workflows. Get more insights, faster, and make better decisions.
- AI-powered performance: Databricks SQL uses next-generation vectorized query engine Photon, with thousands of optimizations for best-in-class performance.
- Centrally store and govern all your data: Databricks SQL allows you to establish one single copy of all your data using open format Delta Lake, and perform in-place analytics and ETL/ELT on your lakehouse.
Databricks SQL Pricing
When it comes to pricing, Databricks SQL offers several pricing options that are both adaptable and budget-friendly. Pricing depends on the type of Databricks SQL warehouse you choose and the cloud provider (AWS, Azure, or Google Cloud) that you prefer. The cost is based on the Databricks Unit (DBU), a unit of measurement that represents a combination of compute and storage resources. For SQL Compute DBU rates, the usage pricing begins at:
| Plan Type | Base Rate Per DBU (USD) |
| SQL Classic | $0.22 |
| SQL Pro | $0.55 |
| SQL Serverless | $0.70 |
Note: These rates are illustrative and can vary by region, cloud provider, and specific Databricks edition. SQL Serverless DBU rates typically include the underlying cloud instance costs.
Save up to 50% on your Databricks spend in a few minutes!


How Does Databricks SQL Enable Users to Work With Large Datasets?
Databricks SQL is an integral part of the Databricks Lakehouse platform. To understand how it works, we'll first explore the architecture of Databricks Lakehouse Platform.
The Lakehouse Platform combines the best features of data warehouses and data lakes, enabling teams to extract valuable insights from raw data quickly. Its key strength lies in handling batch processing and data streaming, making it versatile for various use cases. Plus, it facilitates the transition from descriptive to predictive analytics, empowering data teams to uncover deeper insights with ease.
The platform offers the reliability of traditional data warehouses, such as ACID transactions and robust data governance (via Delta Lake and Unity Catalog), while retaining the adaptability and cost-effectiveness of data lakes. As a result, data teams can benefit from both the trustworthiness of data warehouses and the flexibility of data lakes.
Databricks SQL is built upon this robust foundation, specifically designed to manage complex SQL workloads efficiently. It leverages Apache Spark, a distributed computing framework that enables parallel processing of data across multiple nodes. This parallelism ensures fast execution of even the most complex queries, regardless of dataset size.
Using Databricks SQL, you can work with standard SQL to query and analyze large amounts of data efficiently. The underlying architecture of the Lakehouse Platform provides scalable and cost-effective storage solutions, ensuring seamless data management and analysis.
Key Benefits of Databricks SQL
Databricks SQL offers a wide range of benefits that make it a compelling choice for organizations looking to unlock the full potential of their data. Here are some of the key advantages of using Databricks SQL:
1) Serverless and Cost-Effective
Databricks SQL is a serverless offering, which means you don't need to manage, configure, or scale cloud infrastructure. This approach eliminates overhead costs and complexity, resulting in better cost-efficiency compared to traditional cloud data warehouses.
2) Unified Data Governance
Databricks SQL allows you to establish a single copy of all your data using open standards like Delta Lake, avoiding data lock-in. This unified repository enables in-place analytics and ETL/ELT on your lakehouse, eliminating the need for data duplication and movement across different platforms. Databricks Unity Catalog further simplifies data management by enabling easy data discovery, fine-grained governance, data lineage tracking, and standard SQL support across cloud platforms.
3) Diverse Tool Integrations
Databricks SQL seamlessly integrates with popular tools and services like Fivetran (for data ingestion), dbt (for data transformation), Power BI, Tableau, and Looker (for business intelligence and visualization). This allows data teams to work with their preferred tools without moving data out of the lakehouse.
4) Streamlined Analytics
Databricks SQL makes it easy to get the latest data fast, so you can move quickly from business intelligence to machine learning. No more silos - just a unified platform for all your analytics needs.
5) Streamlined Data Ingestion and Transformation
With Databricks SQL, ingesting and transforming data is a breeze. You can easily bring in data from cloud storage, enterprise applications, and more, and transform it in-place using built-in ETL capabilities or your favorite tools.
6) AI-Powered Performance Optimization
Databricks SQL uses the next-generation vectorized query engine Photon and is packed with several optimizations to provide you with the best performance like:
- Predictive I/O uses neural networks to intelligently prefetch data and enable faster writes through merge-on-read techniques, eliminating the need for manual indexing.
- Automatic Data Layout dynamically optimizes file sizes based on query patterns.
- Liquid Clustering intelligently adjusts the data layout as new data arrives to avoid over- or under-partitioning issues.
- Results Caching system improves query performance by intelligently managing cached results across local and remote caches.
- Predictive Optimization seamlessly optimizes file sizes and clustering by automatically running commands like OPTIMIZE, VACUUM, ANALYZE, and CLUSTERING on your behalf.
7) Open Standards and APIs
Databricks SQL promotes open standards and APIs, avoiding vendor lock-in. It supports open formats like Delta Lake, enabling in-place analytics and ETL/ELT on the lakehouse without data movements and copies across disjointed systems.
What are the Key Features and Tools Provided by Databricks SQL?
Databricks SQL offers a comprehensive suite of features and tools designed to streamline data analytics workflows and empower users with powerful insights. Here are some of the key features and tools provided by Databricks SQL:
1) SQL Editor
The Databricks SQL Editor is an interactive interface designed to facilitate the process of writing, executing, and managing SQL queries. It enables users to explore their data, create visualizations, and collaborate with team members by sharing queries. Databricks also introduced a new chart system in January 2025 with improved performance and enhanced color schemes.
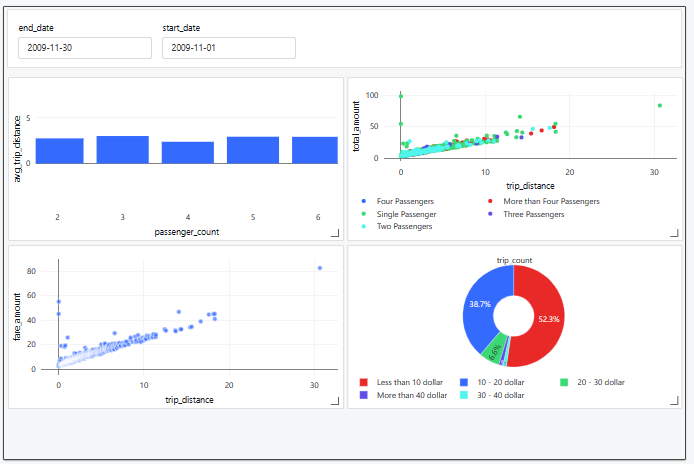
2) Dashboards
Databricks SQL enables users to create dynamic and interactive dashboards for data visualization and storytelling. These dashboards can be populated with visualizations generated from SQL queries, allowing users to present their findings in a clear and compelling manner. Dashboards can be shared across teams, facilitating collaboration and data-driven decision-making.
3) Alerts
Using Databricks SQL, users can set up alerts to monitor their data and receive notifications when specific conditions are met. These alerts can be based on thresholds, data anomalies, or any other predefined criteria. This feature enables active monitoring and timely response to critical events or changes in the data.
4) Query History
Databricks SQL maintains a comprehensive query history that provides valuable insights into query performance, execution times, and resource utilization. This feature allows users to identify and optimize slow-running queries, troubleshoot issues, and monitor the overall health of their analytics workloads.
Note: Query history data has a 30-day retention period, after which it's auto-deleted.
5) SQL Warehouses
At the core of Databricks SQL lies SQL warehouses, which are compute resources dedicated to executing SQL queries. Databricks SQL offers three types of SQL warehouses: Serverless, Pro, and Classic, each tailored to meet specific performance and pricing requirements. We'll explore these warehouse types in more detail later in this article.
On top of these core features, Databricks SQL integrates seamlessly with a wide range of popular tools and technologies, enabling users to leverage their existing skill sets and workflows. Some notable integrations are:
- dbt Integration: Databricks SQL supports integration with dbt (Data Build Tool), a popular open-source tool for data transformation and modeling. This integration allows data engineers and analysts to leverage dbt's powerful transformation capabilities within the Databricks SQL environment, streamlining the data pipeline process.

- Fivetran Integration: Fivetran is a widely-used data integration platform, and its integration with Databricks SQL simplifies the process of ingesting data from various sources, including databases, SaaS applications, and cloud storage services. This integration ensures that users have access to the most up-to-date and comprehensive data for their analytics workloads.
- Business Intelligence (BI) Tool Integrations: Databricks SQL seamlessly integrates with popular business intelligence tools like Power BI and Tableau. This integration helps analysts leverage their preferred BI tools to discover new insights based on the data stored and processed within the Databricks Lakehouse.
Databricks SQL Warehouses and Their Types
A Databricks SQL warehouse is a computing resource that allows you to execute SQL commands on SQL data objects. It is part of the computational resources that DBSQL utilizes. The SQL warehouse is designed to handle SQL queries and data manipulation tasks efficiently. It is built on the lakehouse architecture, which enables it to scale up and down as needed to accommodate varying workloads.
Databricks SQL offers three types of SQL warehouses: Serverless, Pro, and Classic.

Each warehouse type is available to address specific performance needs and budgets, allowing you to find the perfect fit for your unique requirements.
1) Serverless Databricks SQL Warehouses
Serverless Databricks SQL warehouses are the most advanced and feature-rich option offered by Databricks SQL. These warehouses are built on Databricks' fully managed serverless architecture, which means they can rapidly scale up or down based on your workload demands, ensuring optimal performance and cost-effectiveness. Serverless warehouses support all advanced performance features of Databricks SQL, including Photon (a native vectorized query engine), Predictive IO (for speeding up selective scan operations), Intelligent Workload Management (IWM), Predictive Query Execution (PQE), and Photon Vectorized Shuffle.
Serverless SQL warehouses have rapid startup times (typically 2-6 seconds) and can quickly scale up or down as per the workload, providing consistent performance with optimized costs and resources. These warehouses are well-suited for workloads like ETL, business intelligence, and exploratory analysis, where query demand may vary greatly over time.
2) Pro Databricks SQL Warehouses
Pro Databricks SQL warehouses support Photon and Predictive I/O but do not include Intelligent Workload Management (IWM) out-of-the-box in the same way Serverless does. Unlike serverless warehouses, the compute layer for Pro SQL warehouses exists in your cloud provider's account, rather than being fully managed by Databricks. As a result, Pro SQL warehouses are less responsive to rapidly changing query demands and cannot autoscale as quickly as serverless warehouses.
Pro SQL warehouses typically take around 4 minutes to start up and scale up or down with less responsiveness compared to serverless warehouses. These warehouses are useful when serverless SQL warehouses are not available in a particular region, or when you need to connect to databases in your network (cloud or on-premises) for federation or hybrid architectures.
3) Classic Databricks SQL Warehouses
Classic Databricks SQL warehouses are the entry-level option, supporting only the Photon engine. They do not support Predictive I/O, Intelligent Workload Management, or other advanced features found in Pro or Serverless warehouses. Like Pro SQL warehouses, the compute layer for Classic SQL warehouses exists in your cloud provider's account.
Classic SQL warehouses provide basic performance and are suitable for running interactive queries for data exploration with entry-level performance and Databricks SQL features. They lack the advanced performance features and rapid scaling capabilities of serverless and Pro SQL warehouses.
Classic SQL warehouses also take several minutes to start up (typically around 4+ minutes) and scale up or down with less responsiveness than serverless warehouses. These warehouses are suitable for running interactive queries for data exploration with entry-level performance and basic Databricks SQL features.
Step-By-Step Guide to Create Databricks SQL Warehouse
Creating a Databricks SQL warehouse is a straightforward process that can be accomplished through the Databricks web UI or programmatically. In this section, we'll walk through the step-by-step process of creating a SQL warehouse using the web UI.
Prerequisite:
- To create an SQL warehouse, you must be a workspace admin or a user with unrestricted cluster creation permissions.
- Make sure that serverless SQL warehouses are enabled in your region/workspace
Step 1—Navigate to SQL Warehouses
Click on the "SQL Warehouses" option in the sidebar of your Databricks workspace. This will take you to the SQL Warehouses management page.
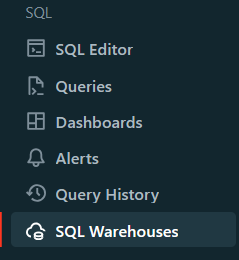
Step 2—Initiate Warehouse Creation
On the SQL Warehouses page, you'll find a "Create SQL Warehouse" button. Click on it to initiate the process of creating a new SQL warehouse.

Step 3—Name the Databricks SQL Warehouse
You'll be prompted to provide a name for your new SQL warehouse. Choose a descriptive and meaningful name that will help you identify the warehouse easily.
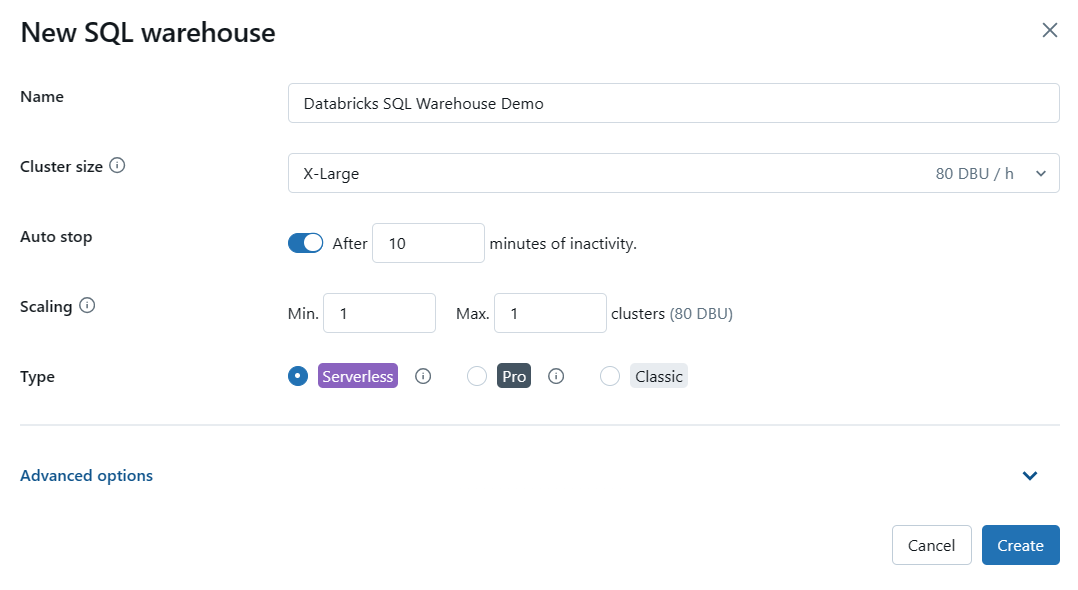
Step 4—Configure Databricks SQL Warehouse Settings (Optional)
This step is optional, but you can configure various settings for your SQL warehouse based on your requirements. Some of the settings you can modify include:
- Cluster Size: This represents the size of the driver node and the number of worker nodes. Larger sizes might make your queries run faster, but they also increase costs.
- Auto Stop: This determines whether the warehouse will automatically stop if it remains idle for a specified number of minutes, helping you save costs.
- Scaling: This sets the minimum and maximum number of clusters that will be used for queries. More clusters can handle more concurrent users.
- Type: This specifies the type of Databricks SQL warehouse (serverless, pro, or classic) based on your performance needs and availability.
Step 5—Configure Advanced Options (Optional)
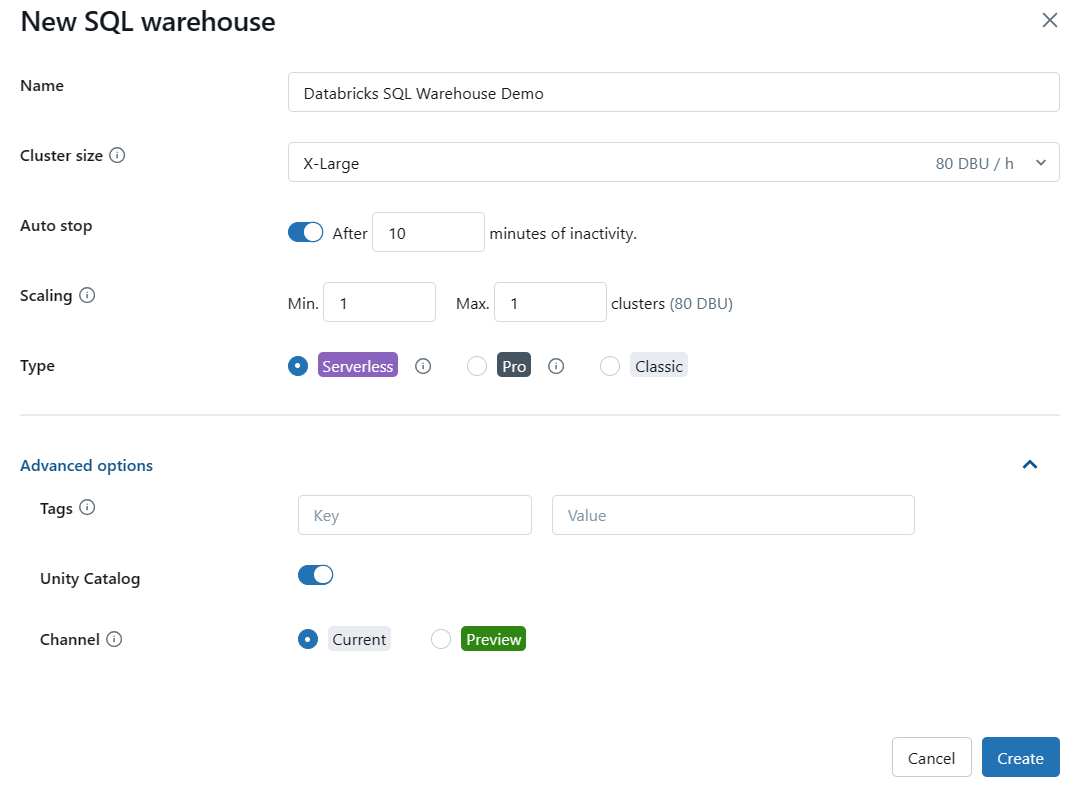
Expand the "Advanced Options" section to configure additional settings for your SQL warehouse, if needed. Some of the advanced options include:
- Tags: Allows you to assign key-value pairs for monitoring and cost-tracking purposes.
- Unity Catalog: Enables or disables the use of Databricks' Unity Catalog for data governance.
- Channel: Allows you to test new functionality by using the "Preview" channel before it becomes the standard.
Step 6—Create the Databricks SQL Warehouse
After configuring the desired settings, click on the "Create" button to create your new Databricks SQL warehouse.
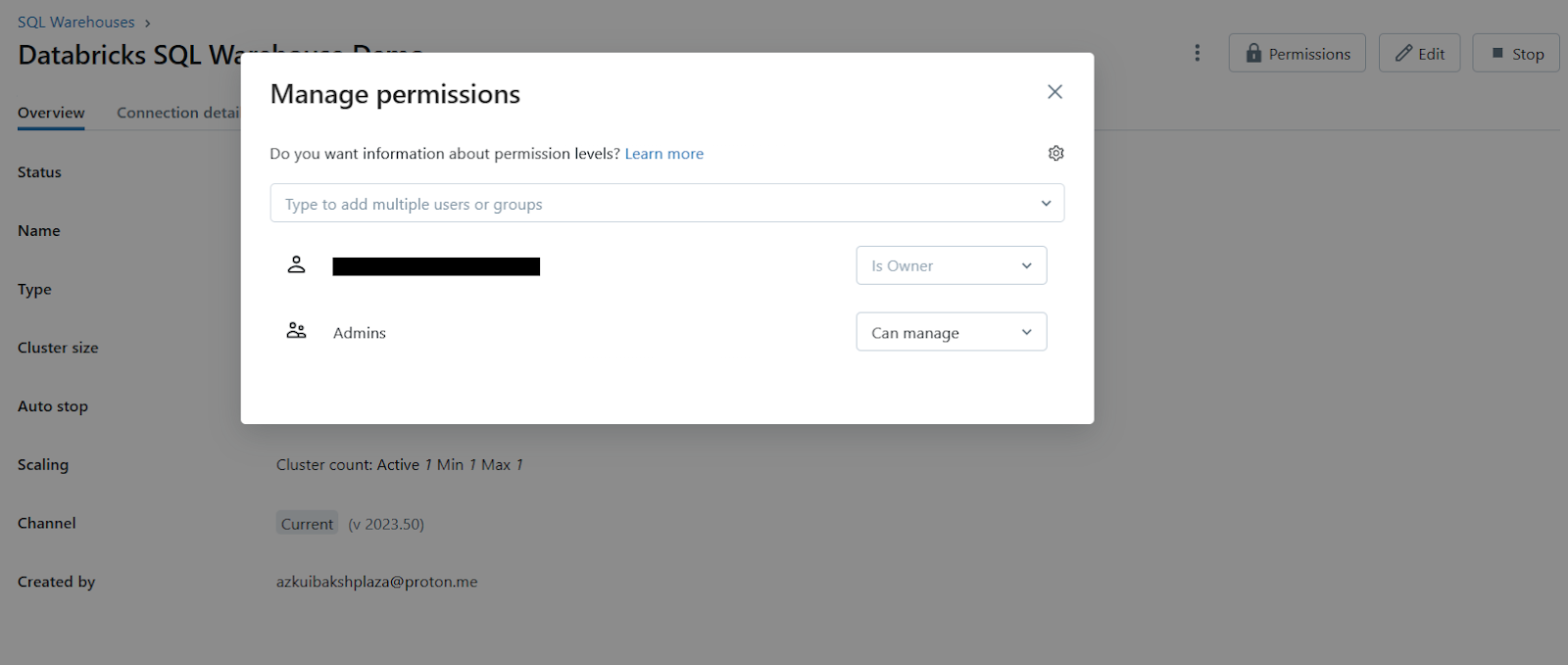
Step 7—Configure Access Permissions (Optional)
Once the SQL warehouse is created, you can optionally configure access permissions for it. Click on the kebab menu next to the warehouse (or if you see the permission button with a lock icon), and select "Permissions". Here, you can add or edit permissions for users or groups to access and manage the SQL warehouse.
Step 8—Manage the Databricks SQL Warehouse
If your newly created Databricks SQL warehouse is not automatically started, click on the start icon next to it to start the warehouse.
That's it! You've successfully created a Databricks SQL warehouse in Databricks.
Remember, Databricks recommends using serverless Databricks SQL warehouses whenever available, as they provide the best performance and cost-effectiveness for most workloads.
How to Use a Databricks Notebook With a Databricks SQL Warehouse?
Databricks SQL not only provides a powerful environment for running SQL queries and managing data warehouses but also integrates seamlessly with Databricks Notebooks. By attaching a notebook to a Databricks SQL warehouse, you can leverage the flexibility of notebooks while taking advantage of the computational resources provided by the SQL warehouse.
Prerequisite:
- Access to the Databricks workspace: You must have access to the Databricks workspace where you want to use the notebook and SQL warehouse.
- Access to a Databricks SQL warehouse: You must have access permissions to the specific SQL warehouse that you want to attach the notebook to. The document mentions that you need access to both the workspace and the SQL warehouse.
- Databricks SQL warehouse type: The SQL warehouse you want to use must be either a Pro or Serverless type.
- Available SQL warehouse: There must be at least one SQL warehouse (Pro or Serverless) available and running in your workspace for you to be able to attach the notebook to it.
Step 1—Open a Notebook
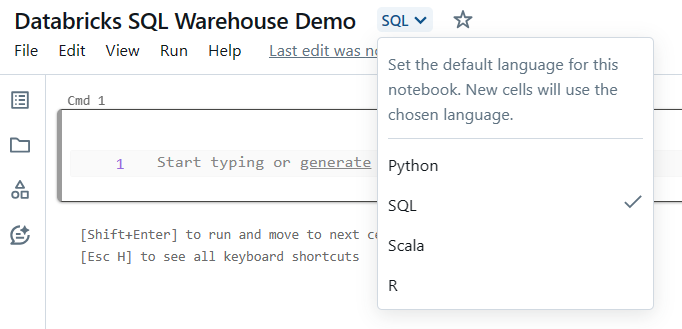
Launch a new notebook or open an existing one in your Databricks workspace. You can create a new notebook by clicking on the "Notebook" icon in the sidebar and then selecting the appropriate language (SQL).
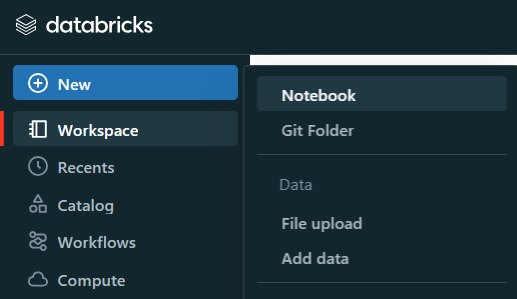
Step 2—Attach the Notebook to a SQL Warehouse
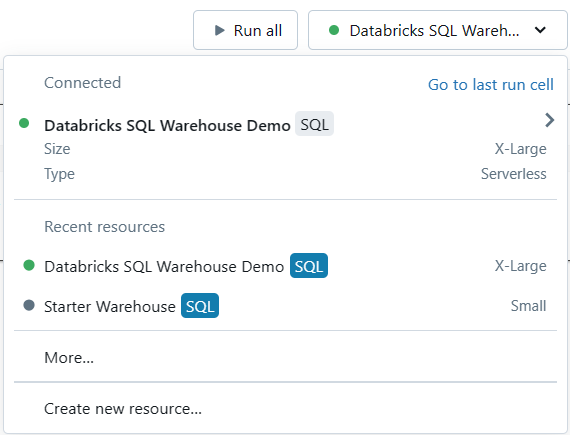
In the notebook toolbar, you'll find a compute selector (typically a dropdown or a button with the current compute resource displayed). Click on this selector to reveal a list of available compute resources.
Note: SQL warehouses are marked with a special icon (e.g., a SQL symbol) in this list.
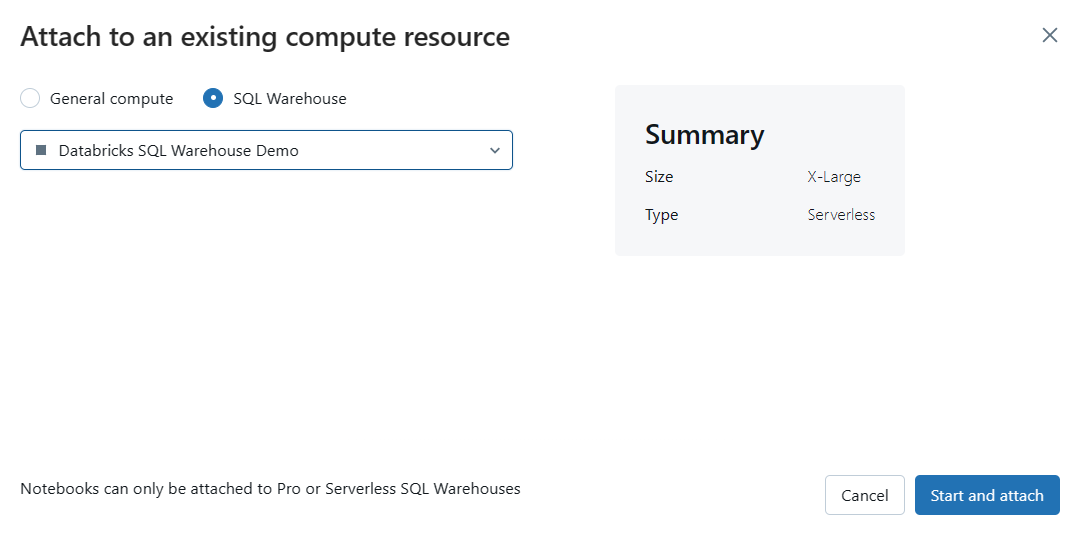
If you don't see the SQL warehouse you want to use, select "More..." from the dropdown menu. A dialog will appear, showing all the available compute resources for the notebook. In this dialog, select "SQL Warehouse", choose the specific warehouse you want to attach, and click "Start and Attach".
Step 3—Run SQL and Markdown Cells
Once your notebook is attached to a SQL warehouse, you can run SQL and Markdown cells within the notebook.
To run a cell, simply place your cursor within the cell and click the "Run Cell" button (typically a triangle play icon) in the notebook toolbar, or use the appropriate keyboard shortcut (e.g., Shift + Enter).
Step 4—View Query History and Profiles
SQL cells executed on a SQL warehouse will appear in the warehouse's query history. If you want to view the query profile for a specific query you ran, look for the elapsed time displayed at the bottom of the cell output. Clicking on this elapsed time will show you the query profile.
OR
Head over to the Query History navigation located in the Sidebar menu and select "Query History" to view the entire query history and profiles.
Step 5—Use Widgets (Optional)
If you need to use widgets in a notebook connected to a SQL warehouse, it's important to understand the differences in syntax compared to using them with a compute cluster. Specifically, you should use the :param syntax to reference widget values instead of the $param syntax.
For example, if you have a widget named demo_age_widget, use the following code:
SELECT * FROM students WHERE age < :demo_age_widgetTo reference objects like tables, views, schemas, and columns, use the IDENTIFIER keyword. Let's say you have a widget named schema_name and table_name, you would use:
SELECT * FROM IDENTIFIER(:schema_name).IDENTIFIER(:table_name)Step 6—Detach or Switch Warehouses (Optional)
If you need to detach the notebook from the current SQL warehouse or switch to a different warehouse, simply follow Step 2 again and select the appropriate action (detach or attach to a different warehouse).
Limitations of Databricks SQL Warehouse
Although there are many advantages to using a notebook with a SQL warehouse, there are also some limitations and things to keep in mind:
1) Execution Context Timeout
When attached to a SQL warehouse, notebook execution contexts have an idle timeout of 8 hours. If the notebook remains idle for more than 8 hours, the execution context will be terminated.
2) Maximum Result Size
The maximum size for returned query results in a notebook attached to an SQL warehouse is 10,000 rows or 2MB, whichever is smaller. If your query returns a larger result set, you may need to consider alternative approaches, such as exporting the data or using data visualization tools.
3) Language Support
When a notebook is attached to a SQL warehouse, you can only run SQL and Markdown cells. Attempting to run cells in other languages, such as Python or R, will result in an error.
4) Query History and Profiling
SQL cells executed on a SQL warehouse will appear in the warehouse's query history, accessible through the Databricks SQL interface. Plus, you can view how long each query took right in the notebook cell output, allowing you to click and view the query profile.
If you follow these steps and keep the limitations in mind, you can harness the combined power of Databricks Notebooks and SQL warehouses to enhance your data management and analysis capabilities.
Best Practices for Databricks SQL
To get the most out of Databricks SQL, it's essential to follow industry best practices. These guidelines can improve performance, cost-efficiency, and data governance.
1) Leverage Disk Caching and Dynamic File Pruning for Better Performance
- Disk Caching: Speed up repeated reads of Parquet data files by caching them on disk volumes attached to compute clusters. This reduces the need to read from slower storage systems, making queries run faster.
- Dynamic File Pruning: Databricks SQL can automatically detect and skip irrelevant directories, so less data needs to be scanned, making query execution quicker.
2) Utilize Table Cloning and the Cost-Based Optimizer:
- Table Cloning: Create deep or shallow clones of datasets to work on isolated copies while keeping the original data intact.
- Cost-Based Optimizer: Provide table information to this optimizer to improve query performance by enabling more efficient query planning.
3) Always Use the Latest Databricks Runtime
Always use the latest Databricks Runtime version, which includes Apache Spark and other components. Updates bring performance improvements, bug fixes, and new features, so you can get the most out of Databricks SQL.
4) Optimize Query Execution with Databricks Workflows
Databricks Workflows let you orchestrate and schedule complex data pipelines, including SQL scripts and notebooks. Optimize execution order and parallelize tasks for improved performance and efficiency.
5) Implement Data Governance and Access Control
Databricks SQL integrates with Unity Catalog, providing centralized access control, auditing, lineage, and data discovery across Databricks workspaces. Effective access control and data governance guarantee data security, compliance, and productive teamwork.
6) Integrate with External Data Tools
Databricks SQL seamlessly integrates with popular data ingestion, transformation, and visualization tools like Fivetran, dbt, Power BI, and Tableau. Leveraging these integrations can streamline your data analytics workflows, improve collaboration, and provide a consistent user experience across different tools.
7) Monitor and Fine-Tune Query Performance
Databricks SQL provides query history and profiling capabilities to help identify and optimize slow queries. Regularly monitoring and addressing bottlenecks ensures optimal system performance and resource utilization.
If you implement these best practices, you'll maximize the efficiency and governance of your Databricks SQL environment.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Conclusion
And that’s a wrap! We've seen how Databricks SQL makes data management and analytics effortless. No more worrying about managing resources or clusters, just focus on your data queries and let Databricks handle the rest. Making awesome visualizations and dashboards is a piece of cake, too. Thanks to the power of cloud platforms like Azure, AWS, and GCP, Databricks SQL has got your back when it comes to making data-driven decisions. Give it a try!
In this article, we have covered:
- What Is Databricks SQL?
- How Does Databricks SQL Enable Users to Work With Large Datasets?
- Key Benefits of Databricks SQL
- What are the Key Features and Tools Provided by Databricks SQL?
- Databricks SQL Warehouses and Their Types
- Step-By-Step Guide to Create Databricks SQL Warehouse
- How to Use a Databricks Notebook With a Databricks SQL Warehouse?
- Best Practices for Databricks SQL
… and so much more!
FAQs
What is Databricks SQL?
Databricks SQL is a serverless data warehouse solution built on the lakehouse architecture, enabling efficient BI and ETL workloads with industry-leading performance and cost-efficiency.
What makes Databricks SQL stand out?
Key differentiators include serverless architecture, lakehouse architecture, unified governance, open formats/APIs, better price/performance, rich ecosystem integrations, unified analytics/ML workflows, and AI-powered performance optimizations like Predictive I/O, Automatic Data Layout, Liquid Clustering, and Predictive Optimization.
How does Databricks SQL handle large datasets?
Databricks SQL leverages Apache Spark's distributed computing, Massively Parallel Processing (MPP), Predictive I/O, Dynamic File Pruning, and Disk Caching for efficient parallel processing of large datasets across multiple nodes.
What are the key benefits of Databricks SQL?
Benefits include better price/performance, built-in governance, diverse tool integrations, unified data access, streamlined data ingestion/transformation, AI-driven performance optimization, and support for open standards.
What are the key features and tools provided by Databricks SQL?
Key features include SQL Editor, Dashboards, Alerts, Query History, and SQL Warehouses (Serverless, Pro, Classic). It integrates with tools like dbt, Fivetran, Power BI, Looker, and Tableau.
What are the different Databricks SQL warehouse types?
Serverless (most advanced, supports all perf features), Pro (supports Photon and Predictive IO), Classic (supports only Photon engine).
How do you use a Notebook with a Databricks SQL warehouse?
Attach a Notebook to a Pro or Serverless SQL warehouse from the compute selector, enabling SQL and Markdown cells leveraging the warehouse's compute resources.
What is theDatabricks Photon engine?
Photon is Databricks SQL's next-gen vectorized query engine with thousands of optimizations for best performance across tools, query types, and real-world applications.
How does Predictive I/O help?
It uses machine learning to intelligently prefetch data, minimizing disk I/O and improving query performance.
How does Databricks SQL promote data governance and security?
Databricks SQL integrates with Unity Catalog for centralized access control, auditing, lineage, and data discovery. It supports open formats like Delta Lake for in-place analytics and ETL/ELT on the lakehouse.
What popular tools integrate with Databricks SQL?
Fivetran (data ingestion), dbt (data transformation), Power BI, Tableau, Looker (BI/visualization).
What are limitations of using a Notebook with a Databricks SQL warehouse?
When using Notebook with Databricks SQL, you may encounter the following limitations:
- Execution contexts have an idle timeout of 8 hours.
- The maximum result size is limited to 10,000 rows or 2MB, whichever is smaller.
- You can only run SQL and Markdown cells; other languages are not supported.
- Query history and profiling are separate from the notebook, which may affect your workflow.
What's the difference between Serverless, Pro, and Classic Databricks SQL warehouses?
- Serverless: Fully managed, most advanced, includes all performance features (Photon, Predictive I/O, IWM, PQE, Photon Vectorized Shuffle), rapid startup (2-6 seconds).
- Pro: Supports Photon and Predictive I/O, but compute resources are in the customer's cloud account, leading to slower startup (~4 minutes) and less dynamic scaling compared to Serverless.
- Classic: Entry-level, supports only the Photon engine, compute resources are in the customer's cloud account, resulting in slower startup (~4+ minutes) and basic features.















