




























Dealing with massive volumes of data in Databricks, but feeling held back by sluggish processing power? The need for faster data crunching is crucial if you want to perform any meaningful analysis these days. Traditional Databricks clusters just can't seem to keep up with the demands of modern data workloads, leading to frustratingly long query execution times and suboptimal query performance. But fear not; this is exactly where Databricks Photon comes into play—introduced in 2021, it's a high-performance, native, vectorized query engine written entirely in C++ that is created with the primary goal of accelerating SQL and DataFrame workloads, giving you a serious query performance boost right out of the gate.
In this article, we will dive deep into Databricks Photon, exploring its features, advantages, architecture, use cases, and providing a step-by-step guide on how to enable/disable Databricks Photon. Also, we will compare the query performance between Photon-enabled and non-enabled clusters.
What is Databricks Photon?
Databricks Photon is a high-performance, vectorized query engine—developed by Databricks to significantly accelerate the execution of SQL and DataFrame workloads. This native query engine—written entirely in C++—seamlessly integrates with the existing Databricks Runtime (DBR) and Apache Spark. The result? Substantial query performance improvements without requiring any kind of modifications to existing workloads.
Databricks Photon is designed to be fully compatible with Apache Spark APIs—meaning you don’t have to entirely rewrite your existing codebase to leverage from its benefits. On top of that, it is fully ANSI-compliant—ensuring broad compatibility with standard SQL syntax and functionality. Since its launch, Databricks Photon has evolved significantly; previously, it was only focused on optimizing SQL workloads, but now—it supports a broader range of ingestion sources, languages (e.g. Python, Scala, Java, and R), workloads (e.g. data engineering, analytics, and data science), data formats, APIs, and methods—making it a versatile solution for accelerating various types of data processing and analytics workloads.
Databricks Photon has many features and capabilities that make it a powerful and efficient query engine, such as:
- Accelerated Query Performance: Databricks Photon delivers substantial performance improvements for SQL and DataFrame workloads, enabling faster data processing and analysis. This translates into reduced query execution times and lower overall costs.
- Seamless Integration: Databricks Photon is designed to be fully compatible with Apache Spark APIs, ensuring that existing workloads can benefit from its performance enhancements without requiring any code changes or modifications.
- Efficient Data Ingestion: Databricks Photon accelerates data ingestion processes, such as data loads for Delta Lake and Parquet tables, by leveraging its vectorized I/O capabilities. This results in faster data ingestion and lower overall runtime for data engineering jobs.
- Faster Data Writes: Databricks Photon supports faster Delta and Parquet writing using UPDATE, DELETE, MERGE INTO, INSERT, and CREATE TABLE AS SELECT, including wide tables that contain thousands of columns
- Optimized Joins & Aggregations: Databricks Photon replaces sort-merge joins with more efficient hash-joins and optimizes aggregation operations, leading to improved performance for complex queries involving joins and aggregations.
- Robust Scan Performance: Databricks Photon delivers robust scan performance, even for tables with numerous columns and small files, ensuring efficient data access and processing.
- Broad range of support: Databricks Photon supports a wide range of data types, operators, and expressions, making it suitable for a variety of use cases and workloads.
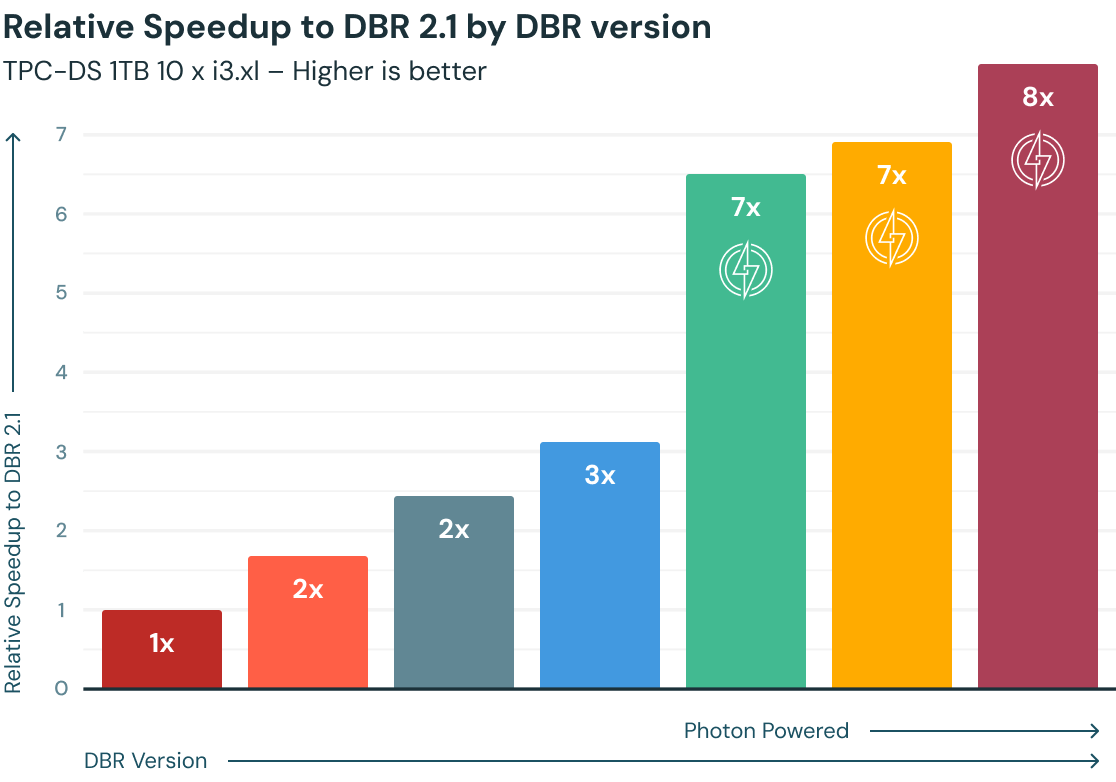
Databricks Photon offers several advantages over the traditional approach of using Databricks Runtime (DBR) alone. These advantages are:
- Up to +8x speedups: Databricks Photon accelerates your queries by using modern hardware and vectorized processing to process data faster and more efficiently. You can also benefit from the disk cache and predictive I/O features that improve the performance of repeated and sequential queries.
- Lower Total Cost of Ownership (TCO): Databricks Photon reduces the cost of running queries on your data lake by using fewer resources and optimizing the performance of your queries. You can also use spot instances or enable autoscaling to further reduce the cost.
- No code changes required: Databricks Photon is compatible with Apache Spark APIs, so you can use it with your existing code and tools without any modifications. You can also switch between Photon and DBR easily by changing a cluster configuration setting.
- No vendor lock-in: Databricks Photon is based on open standards and formats, such as SQL, Delta, and Parquet. You can use Photon with any data lake storage, such as AWS S3, Azure Data Lake Storage, or Google Cloud Storage. On top of that, you can also migrate your data and queries to other platforms if needed.
How Databricks Photon works?
At its very core, Databricks Photon is a vectorized query engine that has been carefully engineered from the ground up in C++ to harness the full potential of modern hardware. One of the key innovations in Photon is its vectorized execution engine. Instead of processing data row by row, Photon processes data in batches, allowing it to take advantage of CPU vectorization and parallelism. This approach results in significantly faster query execution times, with up to ~12x better price/performance compared to traditional execution engines, all while seamlessly operating on existing data lakes.
But Photon is not just about raw speed; it has been designed to seamlessly integrate with your existing Spark workloads and avoid vendor lock-in. Photon is 100% compatible with DataFrame and Spark APIs, which allows you to take full advantage of its performance benefits without having to rewrite your code or undergo complex migrations. Simply turn it on, and Photon will transparently coordinate work and resources, accelerating portions of your SQL and Spark queries without any user intervention or tuning required.
At the heart of Databricks Photon's performance lie three powerful components: the query optimizer, the caching layer, and the native vectorized execution engine itself.
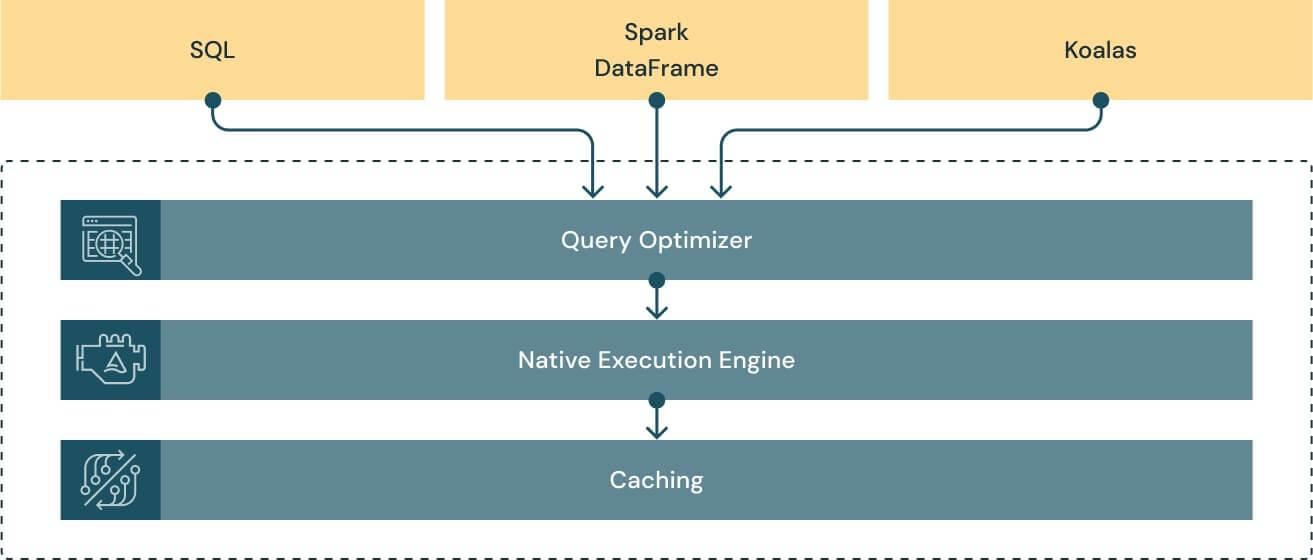
- Query Optimizer: Databricks Photon extends the functionality already present in Spark 3.0 (cost-based optimizer, adaptive query execution, and dynamic runtime filters), delivering up to ~18x increased performance for star schema workloads.
- Caching Layer: Databricks Photon Engine's caching layer intelligently selects and transcodes input data into a CPU-efficient format, taking advantage of the blazing-fast speeds of NVMe SSDs. This results in up to ~5x faster scan performance across virtually all workloads.
- Native Vectorized Execution Engine: The crown jewel of Databricks Photon Engine is its native execution engine, rewritten from the ground up in C++ to maximize performance on modern cloud hardware. This fully Spark API-compatible engine brings significant performance improvements to all workload types while maintaining compatibility with open Spark APIs.
To understand how Databricks Photon works, let's follow the lifecycle of a typical query:
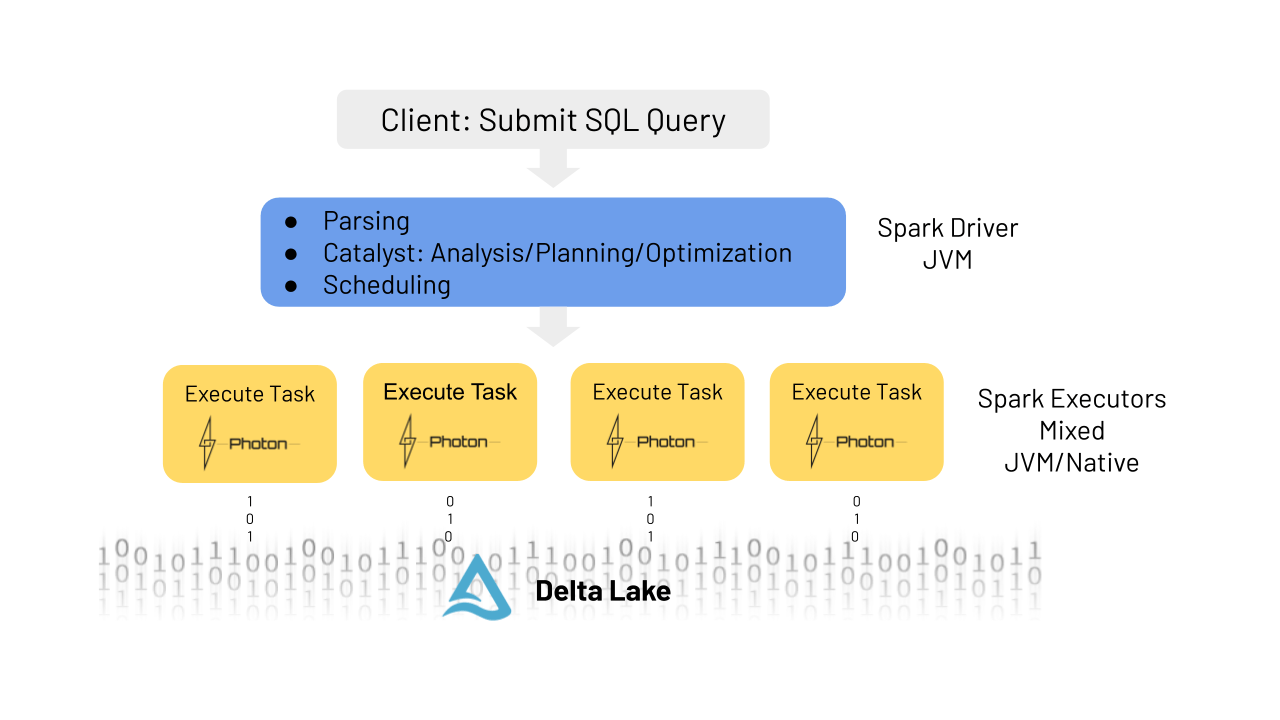
- Query Submission: When a user submits a query or command to the Spark driver, it is parsed and analyzed by the Catalyst optimizer, just as it would be in a non-Photon environment.
- Query Optimization: During the optimization phase, the Catalyst optimizer performs its standard analysis, planning, and optimization tasks. However, when Photon is enabled, the runtime engine makes an additional pass over the physical plan to determine which parts of the query can be executed using Photon.
- Plan Modification: If necessary, minor modifications may be made to the query plan to optimize it for Photon execution. For example, sort-merge joins might be replaced with more efficient hash-joins.
- Hybrid Execution: Since Photon does not yet support all features available in Apache Spark, a single query can be executed partially in Photon and partially in the traditional Spark engine. This hybrid execution model is completely transparent to the user.
- Task Distribution: The optimized query plan is then broken down into atomic units of distributed execution called tasks, which are assigned to worker nodes for parallel processing.
Now, at the task level, Databricks Photon takes over the execution of supported operations:
- JVM Integration: On the worker nodes, the Photon library is loaded into the Java Virtual Machine (JVM), allowing Spark and Photon to communicate via the Java Native Interface (JNI).
- Off-Heap Memory Management: Both Spark and Photon are configured to use off-heap memory, and they coordinate memory management under memory pressure, ensuring efficient resource utilization.
- Data Processing: Photon processes the assigned tasks by operating on specific partitions of the data, leveraging its vectorized processing capabilities and optimized algorithms to deliver superior performance.
- Result Aggregation: Once the tasks are completed, the results are aggregated and returned to the Spark driver for further processing or presentation to the user.
What is the use of photon in Databricks?
Databricks Photon can be applied to a wide range of use cases and workloads, which enables users and organizations to accelerate their data processing and analysis efforts. Here are some of the key use cases and applications of Databricks Photon:
1) Large-scale Data Transformations
Databricks Photon excels at accelerating large-scale data transformations, such as ETL (Extract, Transform, Load) processes, data ingestion, and data preparation tasks. Its optimized processing capabilities ensure faster data ingestion and transformation, enabling organizations to keep up with the ever-increasing volume of data.
2) ML Workloads
Databricks Photon can significantly improve the performance of Machine Learning workloads by accelerating the data processing and feature engineering steps involved in model training and inference, which can lead to faster model development and deployment cycles.
3) Real-time Data Processing and Analysis
Databricks Photon's support for stateless streaming workloads, such as processing data from Kafka or Kinesis streams, allows for real-time data processing and analysis.
4) Interactive Analytics and Reporting
With the help of its fast query execution capabilities, Databricks Photon can significantly enhance the performance of interactive analytics and reporting tasks. Users can explore and analyze data more efficiently, enabling faster decision-making and deeper insights.
5) Data Privacy and Compliance
Databricks Photon's ability to query petabyte-scale datasets efficiently makes it suitable for data privacy and compliance tasks, such as identifying and deleting records that violate data protection regulations. By using Databricks Photon and Delta Lake's time travel capabilities, users can efficiently manage sensitive data without duplicating it.
7) IoT Applications
The accelerated time-series analysis capabilities of Databricks Photon make it well-suited for IoT applications, where large volumes of sensor data need to be processed and analyzed in real-time or near real-time.
8) Data Warehousing
Databricks Photon's performance enhancements and compatibility with SQL make it an attractive choice for users seeking to build high-performance solutions on the Databricks Platform.
These are just a few examples of the many use cases and applications where Databricks Photon can provide significant performance improvements and enable users, businesses or organizations to unlock the full potential of their data.
Limitations of Databricks Photon
Databricks Photon offers numerous advantages and performance improvements, but it's important to note that not everything is perfect—there are some limitations. Here are some of the current limitations of Databricks Photon:
1) Structured Streaming limitations
Databricks Photon currently supports stateless streaming with Delta, Parquet, CSV, and JSON formats. But, it has limited support for stateful streaming operations. Stateless Kafka and Kinesis streaming is supported when writing to a Delta or Parquet sink, but more advanced streaming use cases may not benefit from Photon's performance enhancements.
2) No UDFs or RDD APIs
Databricks Photon does not support user-defined functions (UDF) or the Resilient Distributed Dataset (RDD) APIs provided by Apache Spark. Workloads that rely heavily on UDF or RDD operations may not experience significant performance improvements with Databricks Photon.
3) Limited impact on very fast queries
Databricks Photon is designed to optimize and accelerate queries that process significant amounts of data (> 100GB). For queries that execute in under a few seconds(< 2s), Photon may not provide noticeable performance improvements, as the overhead of leveraging Photon can outweigh the potential benefits for such short-running queries.
List of supported operators, expressions, and data types by Databricks Photon.
Databricks Photon supports a broad range of data types, operators, and expressions, enabling it to handle a variety of workloads and use cases. Here's an overview of the supported elements:
1) Operators:
- Scan, Filter, Project
- Hash Aggregate/Join/Shuffle
- Nested-Loop Join
- Null-Aware Anti Join
- Union, Expand, ScalarSubquery
- Delta/Parquet Write Sink
- Sort
- Window Function
2) Expressions:
- Comparison / Logic
- Arithmetic / Math (most)
- Conditional (IF, CASE, etc.)
- String (common operations)
- Casts
- Aggregates (most common ones)
- Date/Timestamp operations
3) Data types:
- Byte/Short/Int/Long
- Boolean
- String/Binary
- Decimal
- Float/Double
- Date/Timestamp
- Struct
- Array
- Map
For a more up-to-date list of supported operators, expressions, and data types, please refer to the official Databricks documentation.
Now, to get the list of all available functions supported by Databricks Photon, you can use the following Scala code. Make sure that you are on the latest runtimes to take advantage of the most recent functions.
%scala
import com.databricks.photon.PhotonSupport
display(PhotonSupport.supportedExpressions(spark))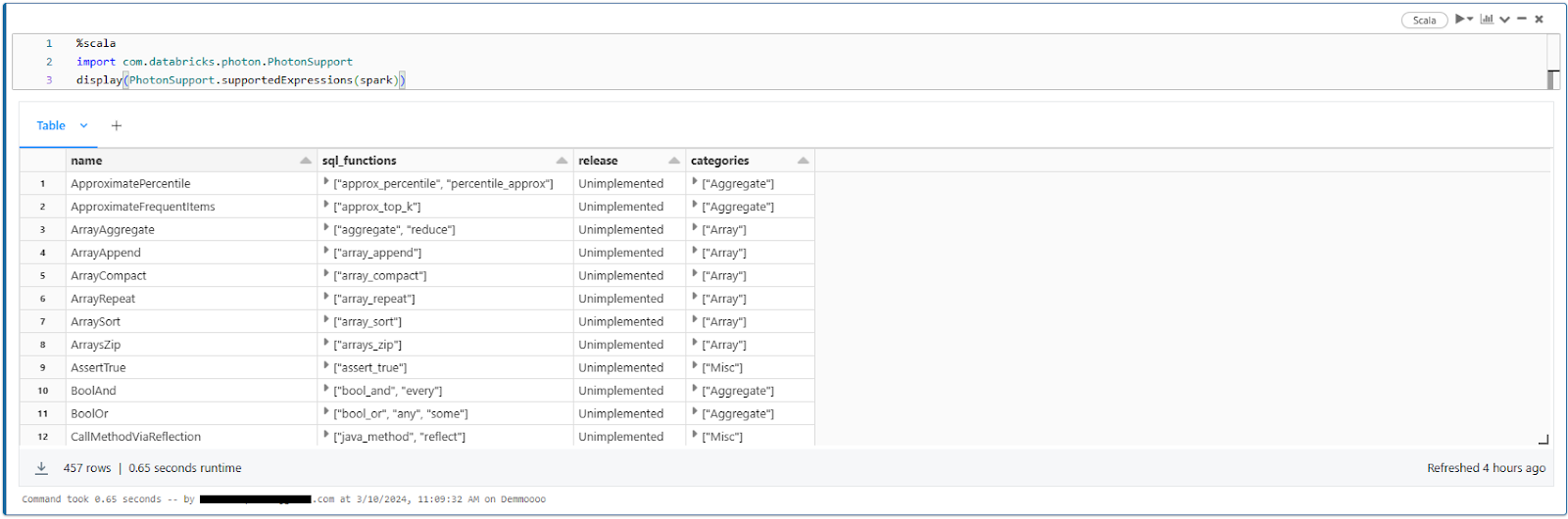
Step-by-step Guide to Enable Databricks Photon
Enabling Databricks Photon is a straightforward process that can be accomplished through the Databricks cluster provisioning interface. Here's a step-by-step guide to help you get started:
Step 1—Access Cluster Management
Log in to your Databricks workspace, click on the +New button, and then proceed to select Clusters.
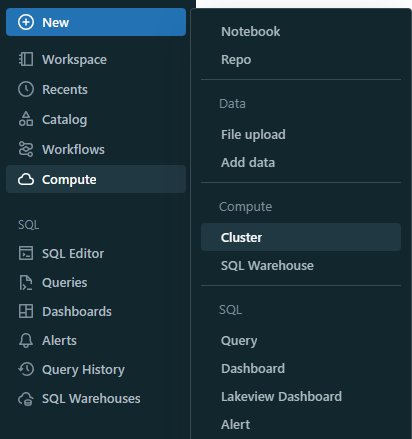
Step 2—Create a New Cluster (or Edit an Existing One)
Click on the "Create Compute" button (or select an existing cluster and click "Edit" if you want to modify an existing cluster).

Step 3—Cluster Configuration
In the cluster configuration window, scroll down to the "Photon Acceleration" section.
Make sure that you are using Databricks Runtime 9.1 LTS or a later version, as Photon is enabled by default on these versions.
Step 4—Enable or Disable Databricks Photon
By default, the "Use Photon Acceleration" checkbox should be selected, indicating that Databricks Photon is enabled for the cluster. If you want to disable Photon, uncheck the box.
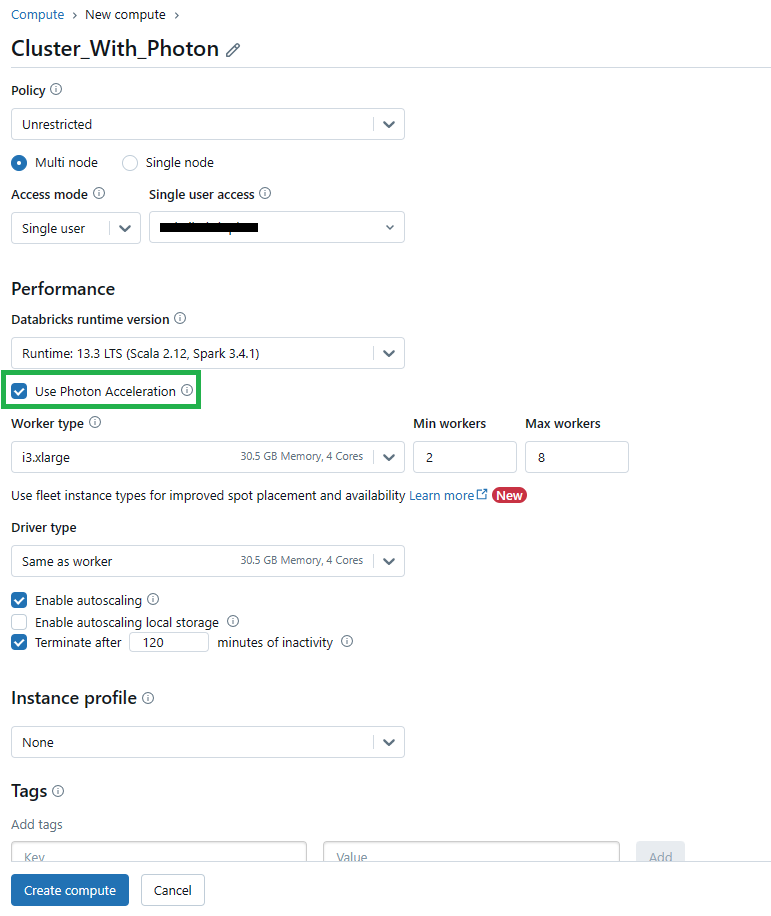
Step 5—Specify Instance Types (Optional)
Databricks Photon supports a range of instance types on both the driver and worker nodes. If desired, you can specify the instance types you want to use for your Photon-enabled cluster.
Step 6—Complete Cluster Creation/Editing
Once you've made the necessary configurations, click the "Create Cluster" button (or "Edit Cluster" if you're modifying an existing cluster) to apply the changes.
Performance Comparison Between Photon vs non-Photon Clusters
To illustrate the performance advantages of Databricks Photon, let's compare the execution times of a sample query on a Photon-enabled cluster and a non-Photon cluster. We'll follow a step-by-step approach to demonstrate the performance difference clearly.
Step 1—Setup and Data Preparation
For this comparison, we'll use a publicly available dataset, the NYC Taxi trip dataset. This dataset contains around ~83-84 million rows of taxi trip data, providing a sufficiently large dataset to test and benchmark the performance effectively.
First, let's create a database and a new table, then load the dataset into the table:
CREATE DATABASE IF NOT EXISTS databricks_photon_demo_db;
CREATE TABLE databricks_photon_demo_db.taxi_dataset
AS SELECT * FROM delta.`/databricks-datasets/nyctaxi/tables/nyctaxi_yellow/`;Databricks Photon Example

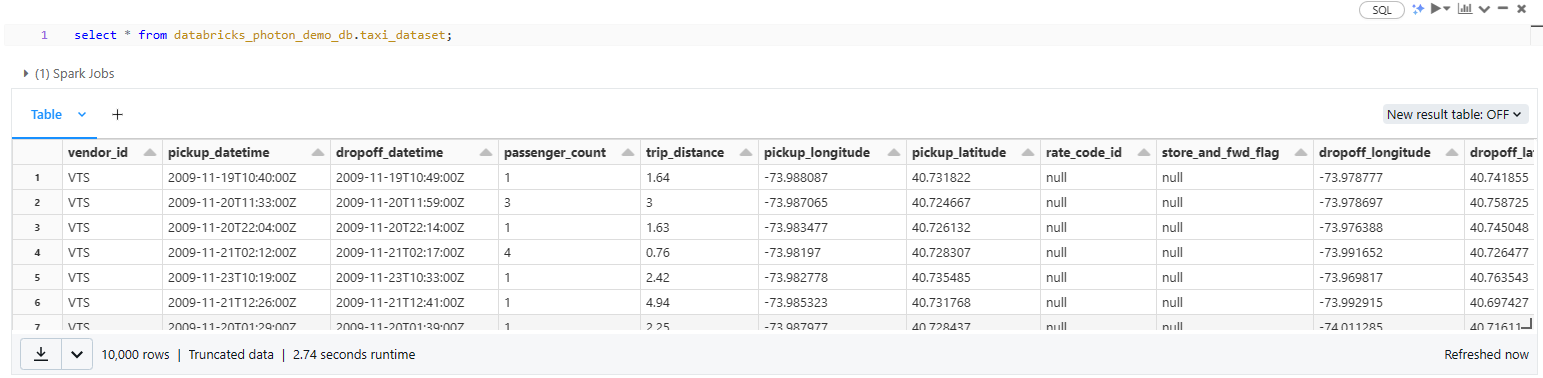
To verify that the data is loaded correctly, we can select all the table data:
select * from databricks_photon_demo_db.taxi_dataset;Databricks Photon Example
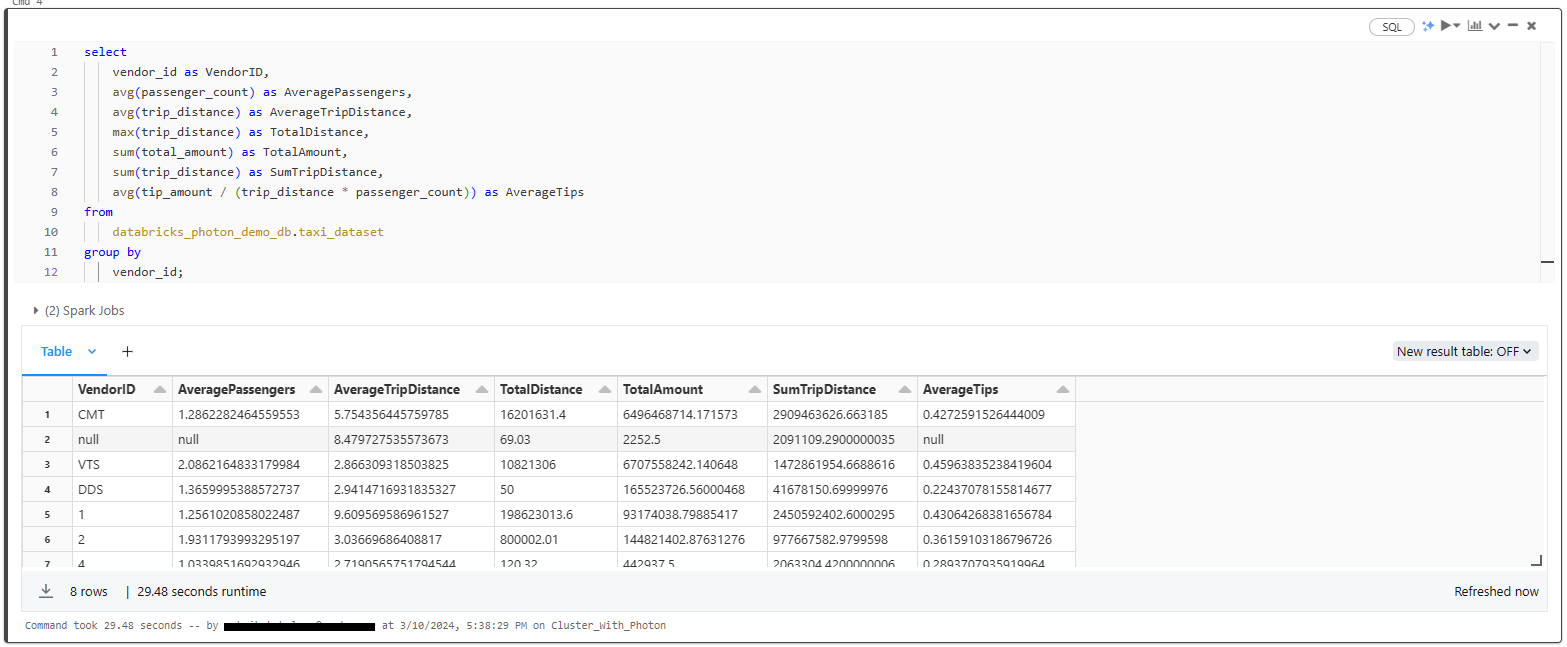
Now, let's write a query that performs various aggregations, calculations, and grouping operations, which will stress-test and benchmark the performance we want to measure:
SELECT
vendor_id AS VendorID,
AVG(passenger_count) AS AveragePassengers,
AVG(trip_distance) AS AverageTripDistance,
MAX(trip_distance) AS TotalDistance,
SUM(total_amount) AS TotalAmount,
SUM(trip_distance) AS SumTripDistance,
AVG(tip_amount / (trip_distance * passenger_count)) AS AverageTips
FROM
databricks_photon_demo_db.taxi_dataset
GROUP BY
vendor_id;Databricks Photon Example
We'll create two separate clusters with the same cluster configuration: one with Photon enabled and another without Photon enabled. For this example, we'll use Databricks Runtime 13.3 LTS (includes Apache Spark 3.4.1, Scala 2.12) and i3.xLarge instance types for both clusters.
Step 2—Run the Query on the Non-Photon Cluster
First, we'll execute the sample query on the non-Photon enabled cluster. This will serve as our baseline for performance comparison.
Before running the query, ensure that Photon is disabled for the cluster. You can check this on the cluster configuration page, where the "Use Photon Acceleration" checkbox should be unchecked.
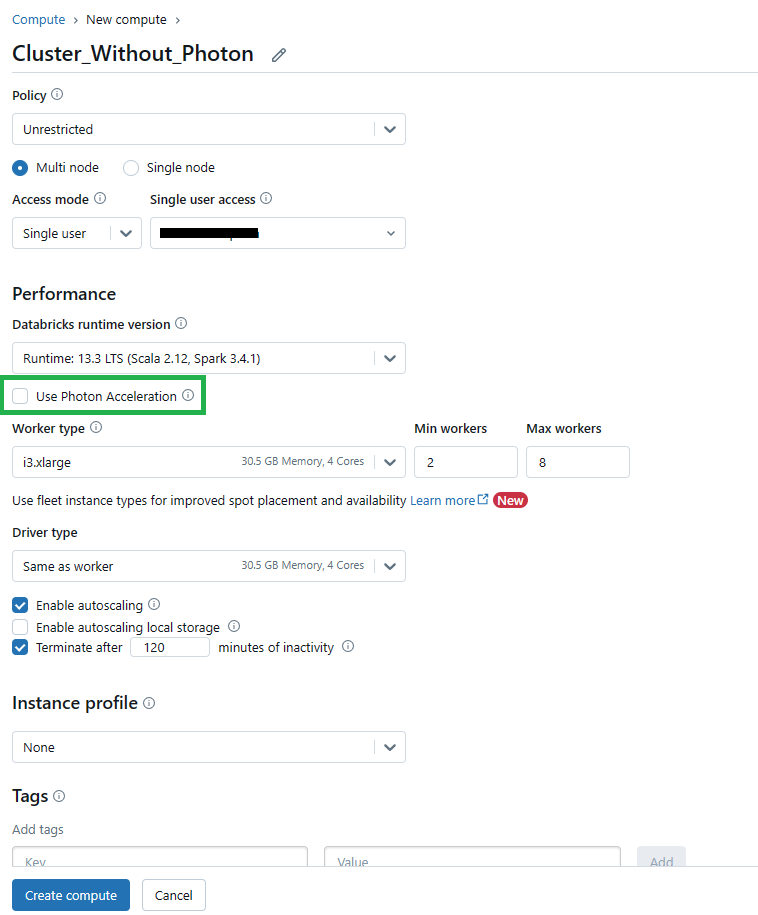
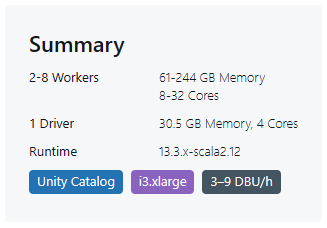
Note that the DBU (Databricks Unit) consumption for non-Photon clusters (Databricks Runtime 13.3 LTS and i3.xLarge instance types) is typically lower, around 3-9 DBUs per hour .
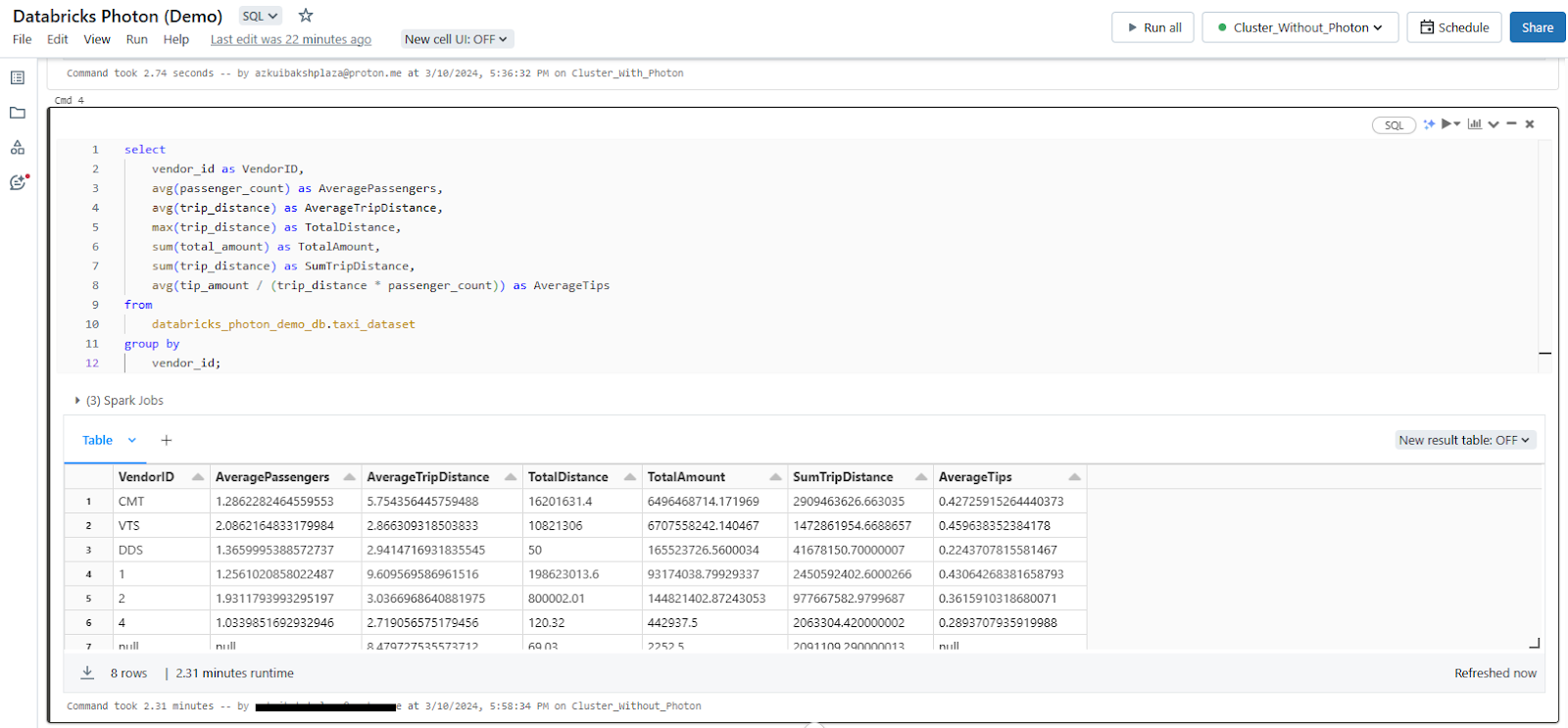
Attach the "Non-Photon" cluster to the Databricks Notebook and execute the query. Note the execution time and any other relevant performance metrics for the non-Photon run.
Step 3—Run the Same Query on the Photon-enabled Cluster
Next, we'll execute the same query on the Photon-enabled cluster, keeping all other parameters and configurations identical to the non-Photon cluster.
Before running the query, ensure that Photon is enabled for the cluster. You can check this on the cluster configuration page, where the "Use Photon Acceleration" checkbox should be selected.
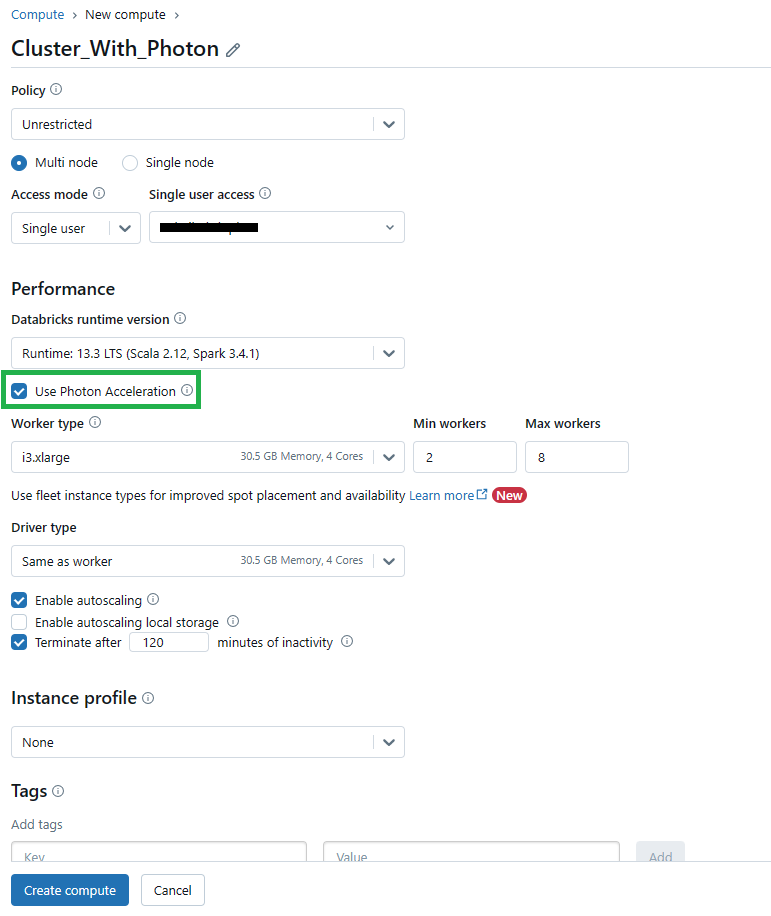
Note that the DBU consumption for Photon-enabled clusters(Databricks Runtime 13.3 LTS and i3.xLarge instance types) is typically higher, around 6-18 DBUs per hour. This higher consumption is justified by the significant performance improvements provided by Databricks Photon, especially for larger workloads.
Attach the "Photon-enabled" cluster and execute the same query.
Step 4—Compare the Results
After running the same query on both the non-Photon and Photon-enabled clusters, let's compare the execution times and any other relevant performance metrics.
Example results:
Photon Enabled: [29.48 seconds]
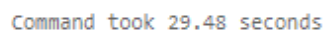
Non-Photon Enabled: [138.6 seconds]

As you can see, the non-Photon run took 138.6 seconds (approximately 2.31 minutes), while the Photon-enabled run completed in only 29.48 seconds, resulting in an impressive approximately 4.7x speedup. This showcases the impactful efficiency gained through Photon's optimized query execution capabilities.
Note: Actual performance improvements may vary depending on the complexity of the query, the size of the dataset, and other factors specific to your workload and environment. But, this example demonstrates the potential performance gains that Photon can provide for SQL and DataFrame workloads, enabling users to process and analyze their data more efficiently and cost-effectively.
What is the difference between DBR and Databricks photon?
Both Databricks Runtime (DBR) and Databricks Photon are integral components of the Databricks, they serve different purposes and have distinct characteristics. Here's a comparison of the two:
| Databricks Photon | Databricks Runtime (DBR) |
| Databricks Photon is a vectorized query engine that runs SQL workloads and DataFrame API calls faster, reducing the total cost per workload | Databricks Runtime is the compute engine that powers the Databricks platform, providing the underlying infrastructure for running data processing workloads |
| Databricks Photon offers enhanced optimizations for SQL workloads, including faster aggregations, joins, and data processing | Databricks Runtime has limited optimizations compared to Photon |
| Databricks Photon is compatible with Apache Spark APIs, supporting SQL operations on Delta and Parquet tables | Databricks Runtime is compatible with Apache Spark APIs |
| Databricks Photon supports different instance types on driver and worker nodes with varying DBU consumption rates compared to non-Photon runtimes | Databricks Runtime offers various compute resources like All-Purpose, Job, Instance Pools, Serverless SQL warehouses, and Classic SQL warehouses |
| Databricks Photon is enabled by default on clusters running Databricks Runtime 9.1 LTS and above but can be manually enabled or disabled | Databricks Runtime is the default component in Databricks workspace |
| Databricks Photon significantly boosts performance for large jobs, especially in aggregations and joins, with a slight increase in compute cost | Databricks Runtime has standard performance impact for queries under two seconds |
Conclusion
And that's a wrap! Databricks Photon is a robust solution powerful enough to completely revolutionize data processing and analytics workloads on Databricks. Leveraging a vectorized architecture and seamless integration with Apache Spark, Databricks Photon delivers unparalleled performance improvements for SQL and DataFrame workloads, enabling users to extract insights from their data faster and more cost-effectively.
In this article, we have covered:
- What is Databricks Photon?
- How Databricks Photon works?
- What is the use of photon in Databricks?
- Limitations of Databricks Photon
- Step-by-step Guide to Enable Databricks Photon
- Performance Comparison Between Photon Runtime vs non-Photon runtime
- Difference between DBR and Databricks photon?
FAQs
What is Databricks Photon?
Databricks Photon is a high-performance, vectorized query engine developed by Databricks to significantly accelerate the execution of SQL and DataFrame workloads.
How does Databricks Photon work?
Photon is a vectorized engine that processes data in batches, taking advantage of CPU vectorization and parallelism. It integrates with the existing Databricks Runtime (DBR) and Apache Spark, and transparently accelerates supported operations.
What are the advantages of using Databricks Photon?
Advantages include up to 10x speedups, lower total cost of ownership (TCO), no code changes required, and no vendor lock-in.
What are some limitations of Databricks Photons?
Limitations include limited structured streaming support, lack of UDF and RDD API support, and limited impact on very fast queries (< 2 seconds).
How do I enable Databricks Photon?
Photons can be enabled or disabled through the "Use Photon Acceleration" checkbox in the cluster configuration settings.
What are the key components of the Databricks Photon architecture?
The key components are the Query Optimizer, Caching Layer, and Native Vectorized Execution Engine.
How does Databricks Photon handle unsupported operations?
Databricks Photon uses a hybrid execution model, where unsupported operations are executed by the traditional Spark engine.
What types of workloads can benefit from Databricks Photon?
Databricks Photon can benefit large-scale data transformations, ML workloads, real-time data processing, interactive analytics, data privacy and compliance, IoT applications, and data warehousing.
How does Databricks Photon compare to the traditional Databricks Runtime (DBR)?
Databricks Photon is specifically optimized for high-performance SQL and DataFrame workloads, while DBR is a general-purpose execution engine for Apache Spark workloads.
What data formats are optimized for Databricks Photon?
Databricks Photon is optimized for Delta Lake and Parquet data formats.
Does Databricks Photon support user-defined functions (UDFs)?
No, Databricks Photon currently does not support UDFs.
What is the impact of Databricks Photon on cluster resource consumption?
Databricks Photon-enabled clusters typically consume more resources (DBUs) than non-Photon clusters, but the performance gains often justify the increased consumption.
Can Databricks Photon be used with spot instances or autoscaling?
Yes, Databricks Photon can be used with spot instances or autoscaling to further reduce costs.
Does Databricks Photon support all Apache Spark APIs?
No, Databricks Photon only supports SQL and equivalent DataFrame operations, not the full range of Apache Spark APIs.
What is the difference between Databricks Photon and Apache Spark's cost-based optimizer?
Databricks Photon extends the functionality of Spark's cost-based optimizer, delivering up to 18x increased performance for star schema workloads.
How does Databricks Photon handle memory management?
Databricks Photon and Spark coordinate off-heap memory management under memory pressure, ensuring efficient resource utilization.
Can Databricks Photon be used with any data lake storage?
Yes, Databricks Photon can be used with any data lake storage, such as AWS S3, Azure Data Lake Storage, or Google Cloud Storage.
What are the supported instance types for Databricks Photon?
Databricks Photon supports a range of instance types on both the driver and worker nodes, which can be specified during cluster configuration.
Is Databricks Photon compatible with open standards and formats?
Yes, Databricks Photon is based on open standards and formats, such as SQL, Delta, and Parquet, avoiding vendor lock-in.
Do I need to make any code changes to use Databricks Photon?
No, one of the key advantages of Photon is that it seamlessly integrates with existing Apache Spark APIs.
Can I use Databricks Photon with other data formats besides Delta Lake and Parquet?
While Photon is optimized for Delta Lake and Parquet data formats, it can also work with other formats like CSV and JSON.
How do I enable Databricks Photon on my clusters?
Databricks Photon is enabled by default on Databricks Runtime 9.1 LTS and later versions. You can also manually enable or disable Photon through the cluster provisioning interface in your workspace.
Will enabling Databricks Photon affect the cost of my workloads?
Yes, Databricks Photon may consume compute resources at a different rate than the traditional Databricks Runtime. It's essential to monitor your workload performance and costs to determine the optimal configuration for your use case.
Can I use Databricks Photon for both batch and streaming workloads?
Databricks Photon supports stateless streaming workloads with Delta, Parquet, CSV, and JSON formats. But, its support for stateful streaming operations is currently limited.
Does Databricks Photon support all data types and operators available in Apache Spark?
Databricks Photon supports a broad range of data types, operators, and expressions, but it may not cover the entire set of features available in Apache Spark.















