





























What if your queries were always accessible for you to explore? Wouldn't it be great if you could skip the time-consuming process of rerunning complex queries and, instead, dive straight into the analysis process? This is where Databricks Materialized Views come in. They cache previously computed query results, thus ensuring that users never have to wait for repeated computations. Materialized Views in Databricks SQL are controlled using the Databricks Unity Catalog and are intended to hold pre-computed results based on the most recent data from source tables.
In this article, we will go over all you need to know about Materialized Views, Materialized Views in Databricks SQL, their benefits, real-world applications, and step-by-step instructions for creating and managing Materialized Views in Databricks.
What Is a Materialized View?
A Materialized View is a type of database object that is useful when you need to run the same query repeatedly. To give you a basic example, think of an MV as a pre-cooked meal. Instead of making the same dish from scratch every time you're hungry, you can prepare it ahead of time, refrigerate it, and then simply heat it when you're ready to eat.
So, how does this work? When you create a Materialized View, you write a query telling the database whatever data/query you want to pre-compute. The DB then executes it, computes its results, and stores ‘em in a physical table. It means the next time you need that data/query, the DB can simply look up the pre-computed results in the table rather than rerunning the query from scratch.
The benefit of Materialized View is that it can greatly speed up data retrieval, particularly for complex queries that take a long time to execute.
Note: Materialized Views come with trade-offs. They take up space in your and may become obsolete if the underlying data changes. To make sure that Materialized Views are up to date, they must be refreshed on a regular basis.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Databricks Views vs Materialized Views: Key Differences
There are several significant distinctions between Views and Materialized Views in Databricks, even though both have the same function of providing a virtual representation of data.
The following table shows how Databricks Materialized Views and standard Views differ:
| Standard Databricks Views | Databricks Materialized View |
| Standard Databricks Views are the virtual representation of data | Databricks Materialized Views store pre-computed results in a physical table-like structure |
| Query performance of standard Databricks Views depends on the underlying tables | Databricks Materialized Views have faster query performance due to pre-computed results |
| Standard Databricks Views always reflect the latest data in the underlying tables | Databricks Materialized Views reflect data at the time of the last refresh |
| Refresh of standard Databricks Views is not applicable (always reflects the latest data) | Databricks Materialized Views can be refreshed manually or on a schedule |
| Standard Databricks Views do not require additional resources | Databricks Materialized Views consume storage space for storing pre-computed results |
| Standard Databricks Views are simple to create and maintain | Databricks Materialized Views are more complex to create and manage due to refresh requirements |
As you can see in the table above, the main advantage of Databricks Materialized Views is their capacity to store pre-computed results, which leads to quicker query performance. But this performance advantage comes at the cost of increased storage requirements and the need for periodic refreshes to keep data fresh.
What Are Materialized Views in Databricks SQL?
Materialized Views in Databricks SQL(aka DBSQL) are managed via the Unity Catalog and are intended to store pre-computed results based on the most recent data from source tables. These Databricks Materialized Views use a different approach than standard implementations in that they retain the data state at the time of their last refresh, rather than updating results each time they are queried.
Let's say you work for a financial institution, and your team is responsible for generating daily reports on investment portfolio performance. These reports involve intricate calculations and aggregations of various data sources, such as stock prices, trading activity, and market trends.
Running these queries on raw data can be time-consuming, especially during peak hours when system resources are in high demand. Databricks Materialized Views offer a solution by allowing you to pre-compute the results of these complex queries during off-peak hours when system resources are more available.
Once the Databricks Materialized View is created, your team can immediately access the pre-calculated results, significantly reducing query execution time and improving overall performance.
To create a Materialized View in Databricks SQL, you can use the CREATE Materialized View statement, followed by the SQL query that defines the View. Here's an example:
CREATE Materialized View user_orders
AS
SELECT
users.name,
sum(orders.amount) AS total_amt,
orders.order_date
FROM orders
LEFT JOIN users ON orders.user_id = users.user_id
GROUP BY
name,
order_date;As seen in this example, we initially created a Databricks Materialized View called user_orders that combines the orders and user tables, calculates the total order amount for each user and order date, and stores the pre-computed results.
Business Use Cases and Technical Benefits of Databricks Materialized Views
Databricks Materialized Views store query results as actual tables. Materialized Views considerably increase the efficiency of subsequent queries that use the same data by processing and storing the query results in advance. This is because the table does not need to recalculate the results each time a query is conducted; instead, it retrieves the pre-computed data directly from the Databricks Materialized View, resulting in faster access and more efficient processing.
Databricks Materialized Views are an effective solution for improving query performance and streamlining data processing procedures. They provide various important benefits, such as:
1) Query Performance Optimization with Materialized Views
Databricks Materialized Views increase query performance by pre-computing and storing the results of difficult queries or frequently performed computations, lowering query latency and increasing overall system responsiveness.
2) Simplified Data Access for Analytics Teams
Databricks Materialized Views simplify data access by abstracting difficult queries and offering a user-friendly representation of the data in pre-aggregated or denormalized formats, hence improving the overall user experience.
3) Incremental Data Processing and Refresh Strategies
In some cases, Databricks Materialized Views can incrementally compute updates from base tables, eliminating the need to recompute the entire View and improving efficiency.
4) Cost Reduction Through Efficient Data Processing
Databricks Materialized Views can help reduce the computational impact on your data processing workflows, potentially resulting in cost savings, particularly when working with large datasets.
5) Data Transformation and ETL Pipeline Optimization
Databricks Materialized Views offer smooth data transformations by letting you clean, enhance, and denormalize base tables, hence simplifying data preparation.
6) Historical Data Analysis and Time-Point Snapshots
Databricks Materialized Views are especially useful for historical analysis, allowing you to execute analysis on data snapshots from precise moments in time.
7) Accelerating Business Intelligence Dashboards
End users' queries are substantially faster since MVs precompute data, eliminating the need to re-process the data by querying the underlying tables directly.
8) Streamlining ETL Workflows with Declarative Transformations
Databricks Materialized Views can help streamline Extract, Transform, and Load (ETL) procedures. They offer a straightforward and declarative method for managing data transformations, compliance checks, corrections, aggregations, and change data capture (CDC).
Streaming Tables vs Databricks Materialized Views—Which One Is the Ideal Choice?
Streaming Tables and Databricks Materialized Views are two important Databricks features that help improve data processing and analysis workflows. However, knowing the differences between these two aspects is critical for making an informed decision about which one best meets your personal needs. Before we dive into their differences, let's first understand what Streaming Tables are in Databricks.
What Are Streaming Tables?
A Databricks Streaming Table is a Delta table with added capabilities for streaming or incremental data processing. It is designed to handle and process continuous streams of data in real-time or near-real time. These tables are particularly useful in situations where data is constantly generated and needs to be analyzed as it arrives, such as log files or real-time event streams.
Streaming Tables enable you to process a growing dataset by addressing each row only once. They are suitable for the majority of ingestion workloads, as most datasets continuously increase. Streaming Tables are best suited for pipelines requiring frequent data updates and minimal latency. Streaming Tables can also be beneficial for enormous scale transformations since they allow results to be calculated progressively as new data arrives, keeping results up to date without having to recompute all source data for each update. Streaming Tables are intended for use with append-only data sources.
To create a Databricks Streaming Table, you can use the CREATE Streaming Table statement. Here's the syntax for creating it:
Create or refresh a Streaming Table using the following format:
{ CREATE OR REFRESH Streaming Table | CREATE Streaming Table [ IF NOT EXISTS ] }
table_name
[ table_specification ]
[ table_clauses ]
[ AS query ]- Table_specification
( [ column_identifier column_type [ NOT NULL ]
[ COMMENT column_comment ] [ column_constraint ]
] [, ...]
[ CONSTRAINT expectation_name EXPECT (expectation_expr)
[ ON VIOLATION { FAIL UPDATE | DROP ROW } ] ] [, ...]
[ , table_constraint ] [...] )- Table_clauses
{ PARTITIONED BY (col [, ...]) |
COMMENT table_comment |
TBLPROPERTIES clause |
SCHEDULE [ REFRESH ] CRON cron_string [ AT TIME ZONE timezone_id ] } [...]Some major advantages of using Databricks Streaming Tables are:
1) Real-time Data Processing
Databricks Streaming Tables support real-time or near-real-time data processing, allowing you to derive insights and make decisions based on the most recent data.
2) Highly Scalabale
Databricks Streaming Tables are highly scalable, able to handle massive amounts of data and enable high-throughput data streams.
3) Built on Apache Spark’s Fault-Tolerant Design
Databricks Streaming Tables are built on Apache Spark's fault-tolerant design, enabling reliable data processing even in the case of node failures or system disturbances.
4) Integration with Batch Processing
Databricks Streaming Tables can be readily integrated into batch processing workflows, allowing for a more unified approach to data processing and analysis.
What Is the Difference Between Materialized Views and Streaming Tables in Databricks?
Databricks Materialized Views and Streaming Tables are both excellent Databricks capabilities, but they serve different purposes and have distinct properties. Here's a table that compares both:
| Databricks Materialized Views | Databricks Streaming Tables |
| Databricks Materialized Views improve query performance by pre-computing and caching results | Streaming Tables process continuous streams of data in real-time or near real-time |
| Databricks Materialized Views can incrementally compute updates from base tables | Streaming Tables are particularly useful in situations where data is constantly generated and needs to be analyzed as it arrives (e.g., logs, sensors, event streams) |
| Databricks Materialized Views reflect data at the time of the last refresh | Streaming Tables processes data as it arrives, providing the most recent data |
| Databricks Materialized Views can be refreshed manually or on a scheduled basis | Streaming Tables continuously process incoming data streams |
| Databricks Materialized Views scale horizontally by making several copies | Streaming Tables is scalable through the addition of more workers to the streaming cluster |
| Databricks Materialized Views is very inexpensive and focused on query optimization | Streaming Tables may be more expensive because of the resources needed for streaming processing |
| Databricks Materialized Views are useful for complex query optimization, historical analysis, data transformations | Streaming Tables can be used for real-time data processing, event monitoring, and IoT applications |
Which One Should You Pick—Databricks Materialized View or Streaming Table?
To figure out whether Databricks Materialized Views or Streaming Tables work better for you, it really comes down to your unique needs and what you plan to use them for.
If your primary goal is to enhance query performance on static or slowly changing data, increase data processing efficiency for batch workloads, or enable safe data exchange, Databricks Materialized Views may be the best option.
Streaming Tables, on the other hand, are better suited for processing and analyzing continuous streams of data in real-time or near real-time.
Here's a brief overview to help you make a wise choice:
- Data Volume and Velocity: If you're dealing with vast amounts of data or fast-moving data streams, Streaming Tables may be better suited to the task.
- Query Frequency: If you execute frequent queries on static data, Databricks Materialized Views can dramatically increase performance by caching the results.
- Budget: Streaming Tables might be more expensive to maintain due to the resources required for constant data processing, but Databricks Materialized Views are typically less expensive for maximizing query speed on static data.
- Real-time Requirements: If real-time or near-real-time data processing is critical to your use case, Streaming Tables should be your first choice.
Finally, the choice between Databricks Materialized Views and Databricks Streaming Tables should be made based on a thorough understanding of your individual data processing and analysis needs, as well as the characteristics and trade-offs of each approach.
Technical Limitations and Restrictions of Databricks Streaming Tables
Databricks Streaming Tables have several limitations that you should be aware of when working with it:
1) Ownership and Access Control Limitations
Only the table owner can refresh a Streaming Table to get the most recent data. This can complicate communication and access management in a team setting.
2) Unsupported SQL Commands and Operations
Traditional ALTER TABLE commands are not available for Streaming Tables. Users must use the ALTER Streaming Table statement to change the table's definition or properties.
3) Time Travel Limitations
Unlike Delta tables, Streaming Tables do not support historical data queries using time travel.
4) Schema Evolution Restrictions
The table schema cannot be modified using DML operations like INSERT INTO and MERGE. This means that users cannot dynamically alter the schema based on new data.
5) Unsupported Commands
Several commands that are commonly used with regular tables are not supported for Streaming Tables, such as:
- CREATE TABLE ... CLONE <streaming_table>
- COPY INTO
- ANALYZE TABLE
- RESTORE
- TRUNCATE
- GENERATE MANIFEST
- [CREATE OR] REPLACE TABLE
6) Delta Sharing
Databricks Delta Sharing, a feature that allows sharing data between Databricks workspaces or other compute platforms, does not work with Streaming Tables.
7) Table Operations
Certain operations, such as renaming the table or changing the owner, are not supported by Databricks Streaming Tables.
8) Table Constraints
Common table constraints like PRIMARY KEY and FOREIGN KEY are not supported for Streaming Tables, which can limit data integrity checks and enforce relationships between tables.
9) Column Type Restrictions
Generated columns, identity columns, and default columns are not supported in Streaming Tables.
These limitations emphasize the necessity of understanding Databricks Streaming Tables' specific capabilities and constraints when creating and executing data pipelines to ensure that they suit the needs of your data processing operations.
Databricks Materialized Views: Limitations and Workarounds
Although Databricks Materialized Views provide tremendous capabilities for boosting query performance and streamlining data processing workflows, it is critical to understand their limitations to ensure successful adoption and management. Here are some important limits to be aware of while working with Materialized Views in Databricks:
1) Warehouse Compatibility Requirements
Materialized Views in Databricks SQL can only be created and refreshed in Pro Databricks SQL warehouses and Serverless Databricks SQL warehouses. They are not compatible with other warehouse types.
2) Workspace Restriction
Databricks Materialized Views can only be refreshed within the workspace in which they have been created, limiting cross-workspace cooperation.
3) Query Restrictions
Databricks SQL Materialized Views can only be accessed by Databricks SQL warehouses, Delta Live Tables, and shared clusters with Databricks Runtime 11.3 or higher. They can also be accessed from Dedicated access mode compute (formerly single user access mode) on Databricks Runtime 15.4 and above if the workspace is enabled for serverless compute; owners can use Dedicated access mode compute on Databricks Runtime 14.3 and above.
4) Base Table Requirement
The base tables used for Materialized Views must be registered in Unity Catalog as managed or external Delta tables.
5) Ownership
The owner of a Databricks SQL Materialized View can be changed by a metastore admin and a workspace admin via Catalog Explorer.
6) Unsupported Features
Databricks Materialized Views do not support identity columns or surrogate keys.
7) Row Filters and Column Masks
Materialized Views in Databricks SQL do not directly support the use of row filters or column masks in their definition.
8) NULL Aggregation
When a SUM aggregate is applied to a NULL-able column in a Databricks Materialized View, if all values in that column become NULL, the aggregate result is zero rather than NULL.
9) Column Aliases
While column references do not require aliases, non-column reference expressions must have them. For example:
- Allowed:
SELECT student_id, SUM(score) AS total_score FROM students GROUP BY student_id;- Not Allowed:
SELECT student_id, SUM(score) FROM students GROUP BY student_id;10) Limitations of OPTIMIZE and VACUUM commands
Databricks Materialized Views do not allow ad hoc OPTIMIZE and VACUUM commands. Maintenance occurs automatically.
11) No Change Data Feed (CDF)
You cannot read a change data feed from a Materialized View.
12) No Time Travel
Time travel queries are not supported on Databricks Materialized Views.
13) Underlying Data Visibility
Databricks Materialized Views' underlying files might contain data from upstream tables (including possible personally identifiable information) that does not appear in the Materialized View schema. This data is automatically added to support incremental refreshing. To avoid exposing this data to untrusted consumers, Databricks recommends not sharing the underlying storage.
How to Create and Manage Databricks Materialized Views: Step-by-Step Tutorial
Now that we've covered the basics of Databricks Materialized Views, including their benefits and limits, let's have a look at how to create and manage ‘em.
Prerequisite
Before we begin, please check that you meet the following prerequisites:
1) Active Databricks Account: To follow along with this guide, you must have an active Databricks account. If you don't already have one, you may sign up for a free trial.
2) Access to a Databricks Workspace: You must have access to a Databricks workspace from which you may create and maintain Databricks Materialized Views.
3) Serverless-Enabled Region: Your Databricks workspace must be in a region that supports serverless computing.
4) Necessary Permissions: To create and manage Materialized Views, you'll need the following permissions:
- SELECT privilege on the base tables referenced by the Materialized View
- USE CATALOG and USE SCHEMA privileges on the catalog and schema containing the source tables for the Materialized View
- USE CATALOG and USE SCHEMA privileges on the target catalog and schema for the Materialized View
- CREATE TABLE and CREATE Materialized View privileges on the schema containing the Materialized View
5) Unity Catalog-Enabled Databricks SQL Warehouse: Materialized Views in Databricks SQL require a Unity Catalog-enabled Databricks SQL warehouse.
Step 1—Logging Into Databricks and Navigating the Interface
Start by logging into your Databricks workspace using your account credentials. Once you're in, you'll have access to the Databricks workspace UI, which provides a comprehensive environment for working with MVs and other data processing and analysis tasks.
Step 2—Create a New Cluster/Databricks SQL Warehouse or Select Existing
In the Databricks workspace, you can either create a new Databricks compute cluster or Databricks SQL Warehouse or use an existing one to run your Databricks Materialized View queries; in this step-by-step guide, we will create Materialized Views in Databricks SQL.
To start a new Databricks cluster or Databricks SQL warehouse, go to the "Compute" section.
If you want to create a new All-purpose compute cluster, click on the "Create Compute" button.

Follow the instructions to customize your cluster settings, including the cluster type, worker node requirements, and any other libraries or configurations needed for your individual use case.
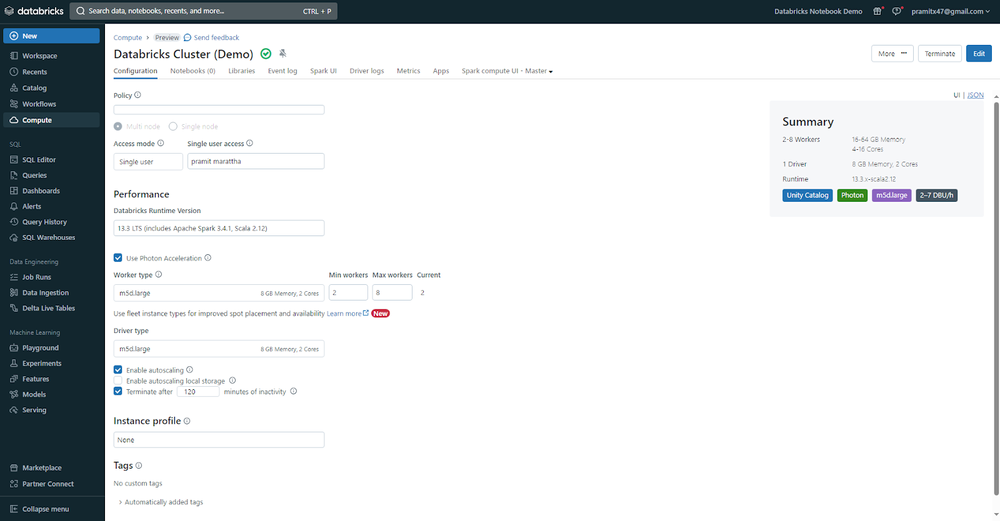
To create a new Databricks SQL warehouse, navigate to the "SQL Warehouse" tab and then click the "Create SQL Warehouse" button.

You can now customize settings to meet your specific needs. Adjust cluster size to strike a balance between query speed and cost, enable auto-stop to save money during idle periods, configure scaling parameters for concurrent users and queries, and choose a warehouse type that meets your performance and availability needs.
Alternatively, if you already have a compute cluster or Databricks SQL warehouse that fulfills your needs, you can start it and be done.
Step 3—Open a New Databricks Notebook or Databricks SQL Editor
Once you've set up and started a cluster or Databricks SQL Warehouse, open a new Databricks notebook or Databricks SQL Editor (if Databricks SQL Warehouse is running). Notebooks are interactive coding environments in which you can write and execute SQL, Python, R, and Scala queries, whereas Databricks SQL editors just allow you to write SQL queries.
To create a new notebook, click the "+New" button in the upper left sidebar, then select "Notebook" from the dropdown menu, and then choose SQL language. Once you've created a notebook, attach the Databricks SQL warehouse and you're done.
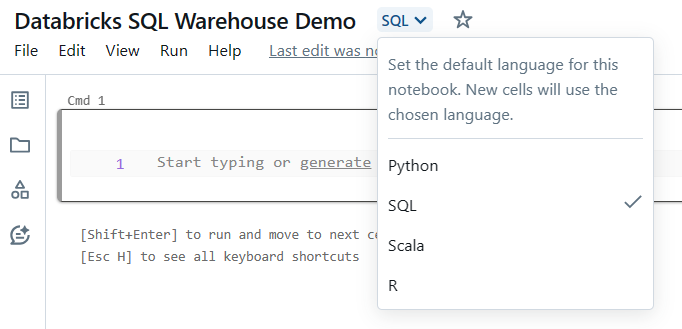
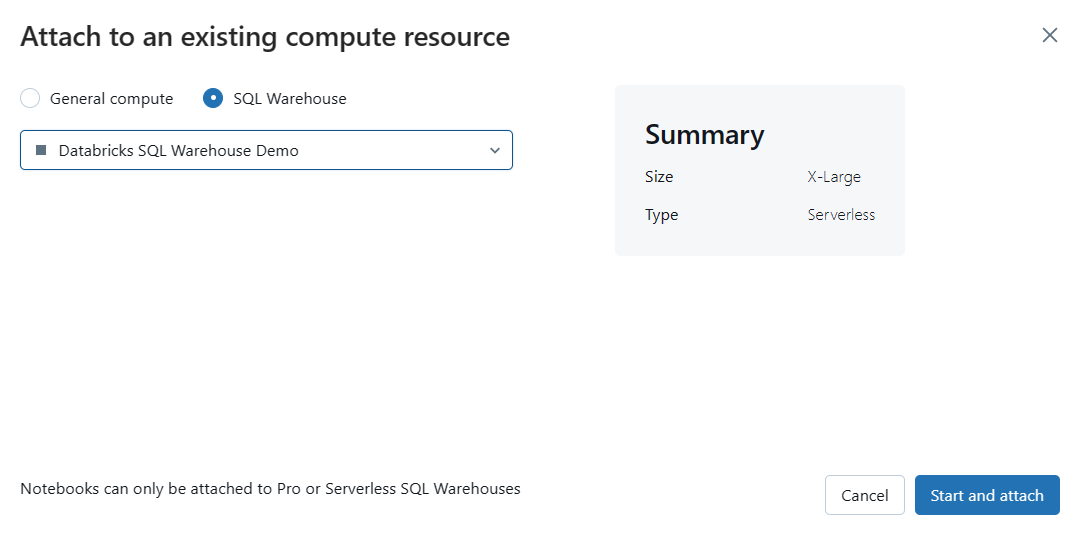
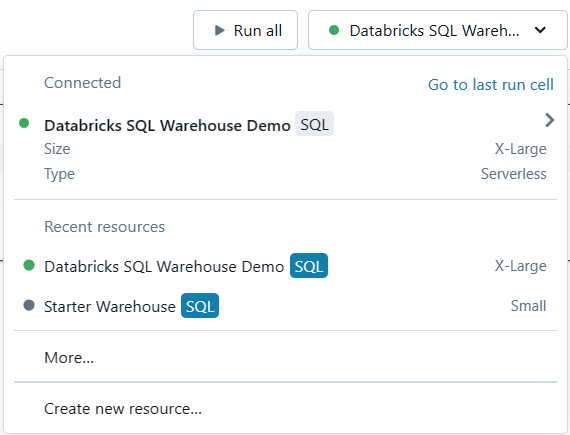
Now, to create Databricks SQL Editor, click "SQL Editor" on the left sidebar menu, then attach the SQL warehouse, and you're done.
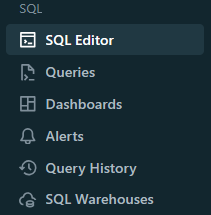
Step 4—Create Databricks Materialized View
Make sure your data is loaded and prepared before creating a Databricks Materialized View. You can cleanse it, transform it, and perform other necessary preprocessing steps to make sure that your data is in the correct format and structure.
Let's start by creating a demo user_details and orders table and inserting some dummy data into it.
CREATE TABLE user_details (
user_id INT,
name VARCHAR(50)
);
CREATE TABLE orders (
order_id INT,
user_id INT,
amount DECIMAL(10, 2),
order_date DATE
);Inserting dummy data into the user_details and orders table
INSERT INTO user_details (user_id, name)
VALUES
(1, 'Elon Musk'),
(2, 'Jeff Bezos'),
(3, 'Mark Zuck');
INSERT INTO orders (order_id, user_id, amount, order_date)
VALUES
(101, 1, 1212.00, '2024-04-01'),
(102, 2, 1515.00, '2024-04-02'),
(103, 1, 1111.50, '2024-04-03'),
(104, 3, 100.00, '2024-04-03'),
(105, 1, 120.00, '2024-04-04');Once your data is ready, You can start creating your Databricks Materialized View. In your Databricks notebook, specify and create your Materialized View with the CREATE Materialized View statement.
Here's an example of creating a Materialized View named user_orders that joins the orders and user_details tables, calculates the total order amount for each user and order date, and stores the pre-computed results:
CREATE Materialized View user_orders
AS
SELECT
user_details.name,
sum(orders.amount) AS total_amt,
orders.order_date
FROM orders
LEFT JOIN users ON orders.user_id = user_details.user_id
GROUP BY
name,
order_date;
When you execute this statement, Databricks will generate the Materialized View and load the initial data.
Note: CREATE Materialized View operation is synchronous, which means it will block until the Materialized View is constructed and the initial data load is completed.
Step 5—Refresh Databricks Materialized Views
As changes occur in your underlying data sources, you'll need to refresh your Materialized Views to make sure they reflect the latest data. To do so, Databricks SQL uses Delta Live Tables to handle the refresh process for Materialized Views.
When you need to update a Materialized View, just use the "REFRESH MATERIALIZED VIEW" statement, and the underlying Delta Live Tables pipeline will handle the rest.
For example, to refresh a Materialized View named "user_orders", you would execute the following command:
REFRESH Materialized View user_orders;Using this simple statement, you can keep your Materialized View in sync with the base table, thus guaranteeing you have the most up-to-date data for analysis.
Databricks SQL provides two methods for refreshing Materialized Views: incremental refresh and full refresh.
1) Incremental Refresh
An incremental refresh updates the Databricks Materialized View by computing only the changes that have occurred in the base tables since the last refresh. This approach can be more efficient, especially when dealing with large datasets or frequent data changes.
Here's an example of creating a Materialized View with an incremental refresh schedule:
CREATE Materialized View user_orders_materialized_view
AS SELECT * FROM orders;
SCHEDULE REFRESH user_orders_materialized_view
ON INTERVAL '5' HOUR
WITH OPTIONS (INCREMENTAL REFRESH = TRUE);In this example, the INCREMENTAL REFRESH option is set to TRUE, instructing Databricks to perform an incremental refresh of the user_orders_materialized_view Materialized View every hour.
2) Full Refresh
A full refresh rebuilds the Databricks Materialized View entirely from the underlying data sources. While this approach may be more computationally expensive, it ensures that the Materialized View accurately reflects the current state of the data.
Here's an example of creating a Databricks Materialized View with a full refresh schedule:
CREATE Materialized View user_orders_materialized_view
AS SELECT * FROM orders;
SCHEDULE REFRESH user_orders_materialized_view
ON INTERVAL '5' DAY
WITH OPTIONS (INCREMENTAL REFRESH = FALSE);In this example, the INCREMENTAL REFRESH option is set to FALSE, which means that Databricks will perform a full refresh of the user_orders_materialized_view Materialized View every day.
Step 6—Refresh Databricks Materialized Views on a Schedule
Databricks SQL gives you the option to schedule automated refreshes for your Materialized Views in addition to manual refreshes. This makes sure that your Databricks Materialized Views stay up-to-date with the latest data changes without requiring manual intervention.
A refresh schedule can be configured using the ALTER MATERIALIZED VIEW command, followed by ADD, ALTER, or DROP SCHEDULE followed by a CRON expression to define the refresh schedule.
Here is an example of creating Databricks Materialized View with a refresh schedule:
ALTER Materialized View user_orders_materialized_view
ADD SCHEDULE CRON '0 0 0 * * ? *' AT TIME ZONE '.........;Changing/Updating the schedule to run every 20 minutes for a Databricks Materialized View
ALTER Materialized View user_orders_materialized_view
ALTER SCHEDULE CRON '0 0/20 * * * ? *';Dropping the schedule for a Databricks Materialized View
ALTER Materialized View user_orders_materialized_view
DROP SCHEDULE;Step 7—Control Access to Databricks Materialized View
Databricks Materialized Views support robust access control mechanisms, allowing you to grant or revoke privileges to specific users or groups. This ensures that sensitive data remains protected while enabling controlled access to the pre-computed results stored in the Materialized View.
1) Granting Privileges
To grant access to a Materialized View, use the GRANT statement. Here's an example:
ALTER Materialized View user_orders_materialized_view
GRANT SELECT TO user1;
GRANT REFRESH TO user2;In this example, we grant the SELECT privilege on the user_orders_materialized_view Materialized View to user1, allowing them to query the view. We also grant the REFRESH privilege to user2, which allows them to refresh the Databricks Materialized View.
2) Revoking Privileges
To revoke access from a Materialized View, use the REVOKE statement:
ALTER Materialized View user_orders_materialized_view
REVOKE SELECT TO user1;This statement revokes the SELECT privilege on the user_orders_materialized_view Materialized View from user1.
Note: Even if a user loses SELECT privileges on the base tables referenced by a Materialized View, or if the base table is dropped, the user can still query the Materialized View. They will, however, be unable to refresh the Materialized View, which will eventually become stale.
Step 8—Deleting/Dropping Databricks Materialized Views
If you no longer require a Materialized View, you can delete it using the DROP Materialized View statement. However, keep in mind that you must be the owner of the Materialized View to drop it.
Here's how you drop a Databricks Materialized View:
DROP Materialized View user_orders;Once you execute this command, the user_orders Databricks Materialized View will be permanently removed from your Databricks environment.
If you follow these step-by-step guides, you'll be able to create, refresh, modify, manage access, and delete Databricks Materialized Views effectively, enabling you to optimize your data processing and analysis workflows while ensuring data security and efficient resource utilization.
Save up to 50% on your Databricks spend in a few minutes!


Conclusion
And that's it! Databricks Materialized Views are an absolutely fantastic feature that allows you to enhance query performance, automate data processing workflows, and extract useful insights from your data with remarkable efficiency. It does all of that by pre-computing and storing the results of complex queries. These powerful objects avoid the need for repeated expensive computations, resulting in much shorter query execution times and computational overhead.
In this article, we have covered:
- What is a Materialized View?
- What is the difference between View and Databricks Materialized View?
- What are Materialized Views in Databricks SQL?
- Use cases and purpose of Databricks Materialized Views
- Streaming Tables vs. Databricks Materialized Views—which one is the ideal choice?
- What are Streaming Tables?
- What is the difference between Materialized View and Streaming Table in databricks?
- Limitations of databricks Streaming Table
- Limitations of Materialized View in databricks
- Step-by-step guide to create databricks Materialized Views
… and so much more!
Frequently Asked Questions (FAQs)
What is a Materialized View?
A Materialized View is a database object that stores pre-computed results of a query, allowing for faster data retrieval by avoiding repeated expensive computations.
How do Materialized Views differ from standard Views in Databricks?
Databricks Materialized Views store pre-computed results in a physical table-like structure, leading to faster query performance, while standard Views are virtual representations of data that reflect the latest data in underlying tables.
What are Materialized Views in Databricks SQL (DBSQL)?
Materialized Views in DBSQL are managed via the Unity Catalog and are intended to store pre-computed results based on the most recent data from source tables at the time of their last refresh.
What are the benefits of using Databricks Materialized Views?
Benefits of using Databricks Materialized Views are enhanced query performance, better data access, incremental computations, lower data processing costs, data transformation capabilities, historical analysis support, faster BI dashboards, and streamlined ETL workflows.
What is the difference between Databricks Materialized Views and Streaming Tables?
Materialized Views improve query performance on static data, while Streaming Tables process continuous streams of data in real-time or near real-time.
How do you create a Materialized View in Databricks SQL?
Use the CREATE Materialized View statement followed by the SQL query that defines the View.
How do you refresh a Materialized View in Databricks SQL?
Use the REFRESH Materialized View statement to update the pre-computed results based on changes in the underlying data sources.
What are the two methods for refreshing Materialized Views in Databricks SQL?
The two methods are incremental refresh (updates the View by computing only changes since the last refresh) and full refresh (rebuilds the View entirely from the underlying data sources).
How do you schedule automated refreshes for Materialized Views in Databricks SQL?
Use the ALTER Materialized View statement with ADD, ALTER, or DROP SCHEDULE, followed by a CRON expression to define the refresh schedule.
How do you grant or revoke access to a Materialized View in Databricks SQL?
Use the GRANT and REVOKE statements followed by the privilege (e.g., SELECT or REFRESH) and the target user or group.
How do you delete a Materialized View in Databricks SQL?
Use the DROP Materialized View statement, but you must be the owner of the Materialized View to drop it.
What Are the Types of Views in Databricks?
There are two main types of views in Databricks:
- Non-Materialized Views (Databricks Views): Virtual tables based on the result-set of a SELECT statement. Types include Temporary Views and Global Temporary Views.
- Materialized Views: Pre-computed and stored in memory or on disk, offering faster query performance
What Is the Difference Between Temporary View and Global Temporary View in Databricks?
Temporary Views and Global Temporary Views are both session-scoped, but they differ in their visibility:
- Temporary View: Only visible within the specific Spark job or notebook that created it.
- Global Temporary View: Visible to all jobs and tasks that run within the same SparkSession, allowing multiple concurrent jobs/tasks to access the same view.
Can Materialized Views in Databricks SQL be accessed from any Databricks cluster?
No, Materialized Views can only be accessed by Databricks SQL warehouses, Delta Live Tables, shared clusters with Databricks Runtime 11.3 or higher, and Dedicated access mode compute on Databricks Runtime 15.4+ (or 14.3+ for owners) with serverless enabled.
Can Databricks Materialized Views in Databricks SQL use row filters or column masks?
No, Materialized Views in Databricks SQL do not support the use of row filters or column masks.
How do Databricks handle NULL values in Materialized View aggregations?
If all values in a NULL-able column become NULL when a SUM aggregate is applied, the aggregate result will be zero instead of NULL.
Can the owner of a Databricks Materialized View be changed in Databricks SQL?
Yes, the owner of a Databricks Materialized View can be altered by a metastore admin and a workspace admin via Catalog Explorer.
Can Databricks Materialized Views in Databricks SQL be shared across workspaces?
No, Databricks Materialized Views can only be refreshed within the workspace in which they were created.
Can Databricks Materialized Views in Databricks SQL use identity columns or surrogate keys?
No, Databricks Materialized Views in Databricks SQL do not support identity columns or surrogate keys.















