




























Logging is a fundamental practice in software development and data engineering. It is a fundamental aspect of building reliable and maintainable systems. Logging is especially helpful for debugging, keeping an eye on things, and keeping track of what's happened. In modern data platforms like Databricks, logging becomes even more critical due to the distributed nature and complexity of data processing tasks. Databricks, with its integrated notebook environment, offers unique considerations for implementing effective logging strategies.
In this article, we'll go over the top 10 best practices for logging in Databricks Notebooks, making sure you have a solid strategy to monitoring and troubleshooting your workflow. We'll start with the fundamentals of logging, explain its benefits, and then go on to specific techniques and practices designed for the Databricks environment.
What Is Logging?
Logging is the systematic recording of events that occur during software execution. Think of it as maintaining a detailed record of your application's behavior, capturing everything from routine operations to unexpected errors. Logs typically include:
- Program/Application events and actions
- Errors and exceptions
- Performance metrics
- Resource utilization data
- User interactions and system state changes
Benefits of Logging
Effective logging offers several advantages:
1) Debugging
Logs help trace issues by providing detailed information about what went wrong, where it occurred, and the surrounding context.
2) Monitoring
Logs keep you in the loop about how your application behaves over time. You can see if it's performing well under load or if there's a pattern in the errors.
3) Audit Trails
Logs track who did what and when. This is key for security if you need to check who accessed which data or made changes.
4) Performance Analysis
Logging the time certain operations take helps you pinpoint bottlenecks in your code or system.
5) Compliance
Logs can establish compliance in regulated industries by indicating when data was accessed or modified.
6)User Behavior Analysis
Logs offer insights into user interactions, informing design improvements and feature development.
Save up to 50% on your Databricks spend in a few minutes!


Logging in Databricks Notebooks
Databricks Notebook is extremely useful for data engineering, machine learning, and analytics workflows. Their unique environment presents specific logging considerations:
➥ Interactive Execution Environment — Code is executed interactively, often requiring real-time logging.
➥ Distributed Computing Architecture — Operations may span multiple nodes, necessitating centralized logging.
➥ Multi-user collaboration capabilities — Multiple users can work simultaneously, making user-specific logging important.
➥ Integration with Apache Spark — Tight coupling with Spark requires capturing both notebook and Spark job logs.
Why Notebook-Specific Logging Matters
Unlike traditional scripts, Databricks Notebooks' interactive and collaborative nature demands tailored logging approaches:
➥ Session-Specific Context: Since Databricks Notebooks are interactive, logs help you correlate actions with outcomes within the same session. This context is invaluable when you're debugging or monitoring long-running processes.
➥ Integration with Python: You can use Python's built-in logging module directly in your notebooks. This means you don't need to learn new tools; you use what you already know.
➥ Centralized Storage: You can direct logs to Databricks DBFS or cloud storage, making it easier to analyze logs across different notebooks or clusters.
➥ Flexibility: Whether you're logging for a single cell or an entire workflow, Databricks Notebook environment lets you adapt your logging practices to your project's needs.
Tools for Logging in Databricks Notebooks
You can implement logging in Databricks Notebooks using:
- Python’s logging module: A flexible, built-in library for creating and managing log messages.
- Log4j: A Java-based logging framework that integrates with Spark, suitable for logging within Spark jobs.
- External logging services: Tools like Azure Log Analytics or third-party tools like Splunk can be integrated for centralized log management, enhancing monitoring and analysis capabilities.
Adding logging into your Databricks Notebooks can make a big difference. Not only are you getting ready for when things go wrong, but you're also building a system that helps you keep improving your data processes. Think about it: the logs you create now might just help you fix problems later.
Now let's explore the top 10 Databricks logging best practices in Databricks Notebooks.
10 Best Practices for Logging in Databricks Notebooks
Logging in to Databricks Notebooks is a must if you want to keep an eye on your data workflows and fix any issues that come up. Here are 10 best practices to take your logging strategy to the next level:
- Implement Logging with Python’s logging Module
- Configure Logging Levels Appropriately
- Use Structured Logging with JSON
- Write Meaningful Log Messages
- Add Timestamps and Maintain a Consistent Format (ISO-8601)
- Periodically Test Logging Configuration
- Store Logs in a Centralized Location (e.g., DBFS or a Storage Account)
- Implement Error Handling with try-except Blocks and Log Exceptions
- Integrate Databricks with a Log Analytics Tool
- Enable Databricks Audit Logs
1️⃣ Databricks Logging Best Practice #1—Implement Logging with Python’s logging Module
Let's start with the first best practice for logging in Databricks Notebooks: using Python's built-in logging module. This approach is the simplest and most effective way to start logging in Databricks Notebooks. It allows for structured and customizable logging.
Step-by-Step Guide to Set Up Databricks Logging in Databricks Notebooks
Prerequisite:
- Access to a Databricks Workspace
- Basic knowledge of Databricks DBFS
- Necessary permissions for DBFS
- Configured Databricks Compute Cluster
- Basic to intermediate Python skills
Step 1—Log in to Databricks Account
Log in to your Databricks account using your credentials. If you’ve already set up your account, this step is straightforward.
Step 2—Navigate to Databricks Workspace
Once logged in, click on "Workspace" from the left sidebar to access your Databricks notebooks, clusters, and data.
Step 3—Configure Databricks Compute Cluster
Before running any code, you need an active Databricks compute cluster. To do this, navigate to the Compute section on the left sidebar.
If you don’t have a cluster or need a new one, click Create Compute.
Then, configure the cluster settings, such as the Databricks runtime version and worker count. Finally, start the cluster if it isn’t already running.
Step 4—Open a New Databricks Notebook
In your workspace, click the "+ New" button and select "Notebook".
Then, choose Python as the language and name your Databricks Notebook, for example, "Databricks Logging in Notebooks".
Step 5—Attach Databricks Notebook to Cluster
At the top of the Databricks Notebook, select the cluster you configured in Step 3 to attach it.
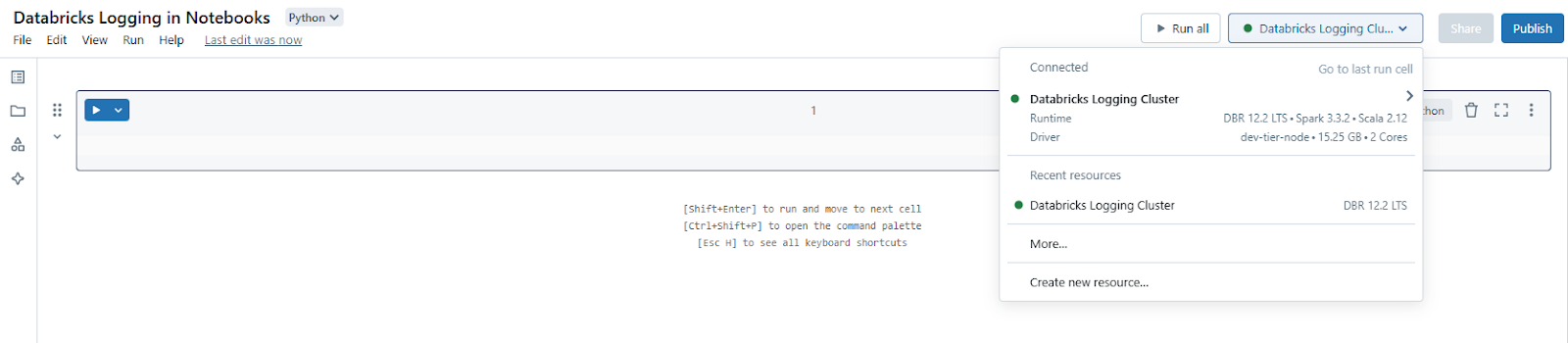
Step 6—Import the Python Logging Module in Notebooks
Now, start by importing the logging module in your Databricks Notebook:
import loggingStep 7—Configure the Databricks Logger
Set up a logger with a specific name and define its logging level. The logging level determines the severity of messages that the logger will handle. For comprehensive logging, you might choose DEBUG; for general operational messages, INFO is appropriate. We will delve deeper into this section in the next best practice section.
logger = logging.getLogger('databricks_logger')
logger.setLevel(logging.INFO)
Step 8—Create and Configure a Stream Handler
To display log messages directly in the Databricks Notebook output, add a StreamHandler. This handler sends log messages to the console.
stream_handler = logging.StreamHandler()
stream_handler.setLevel(logging.INFO)
Step 9—Test the Logging Configuration
Establish a consistent format for your log messages to include timestamps, logger names, log levels, and the actual message.
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
stream_handler.setFormatter(formatter)Step 10—Attach the Handler to the Logger
With the handler configured, attach it to your logger.
logger.addHandler(stream_handler)Step 11—Implement Logging in Your Code
You can now use the logger to record messages at various severity levels throughout your Databricks Notebook.
logger.debug("Debug message: Useful for troubleshooting.")
logger.info("Info message: General information.")
logger.warning("Warning message: Indicates potential issues.")
logger.error("Error message: An error occurred.")
logger.critical("Critical message: Severe issues requiring immediate attention.")
Step 12—Avoid Duplicate Log Entries
To prevent duplicate log entries, especially when re-running cells, ensure that handlers are not added multiple times. Check if the logger already has handlers before adding new ones:
if not logger.hasHandlers():
logger.addHandler(stream_handler)Step 13—Optional: Log to a File
If you prefer to save logs to a file for persistent storage, you can add a FileHandler. However, direct logging to Databricks DBFS (Databricks File System) can be problematic due to write permission issues. A common workaround is to log to a local file and then move it to DBFS after the notebook execution completes.
file_handler = logging.FileHandler('/tmp/databricks_log.log')
file_handler.setLevel(logging.INFO)
file_handler.setFormatter(formatter)
if not logger.hasHandlers():
logger.addHandler(file_handler)After your Databricks Notebook runs, you can move the log file to Databricks DBFS:
dbutils.fs.mv('file:/tmp/databricks_log.log', 'dbfs:/FileStore/logs/databricks_log.log'
Key points to bear in mind:
🔮 Logging directly to DBFS from a FileHandler can be tricky because of file permissions. A workaround is to use a temporary DBFS path and then move it to a more permanent spot.
🔮 Make sure you have permission to write to the /dbfs/tmp/ path or wherever you'll be writing temporary logs.
🔮 Remember, after each notebook run, you'll need to manually or programmatically move logs if you want them stored long-term in DBFS.
Step 14—Integrate Logging into Your Code
Use the logger throughout your Databricks Notebook to track the progress and status of operations:
try:
logger.info("Starting a data processing task...")
# <Example task>
result = 1 / 0 # Intentional error
except Exception as e:
logger.error(f"An error occurred: {e}")
finally:
logger.info("Task complete.")
Step 15—Test the Databricks Logging Setup
Run the Databricks Notebook to check if logs appear in the console or wherever you've set up external logging.
2️⃣ Databricks Logging Best Practice #2—Configure Logging Levels Appropriately
Logging levels, as discussed in the best practice above, help you filter out unnecessary information by controlling what appears in your logs. In Python’s logging module, you can configure these levels to determine which messages are logged based on their severity. Now, here's how to put logging levels to good use in Databricks Notebooks to streamline your logging output.
1) Debug Level
Use the DEBUG level during development to capture detailed information about the application's behavior. It provides insights into the flow and state of your code. It's like having a magnifying glass on your code's every move.
logger.debug('Detailed debug information')2) Info Level
The INFO level is ideal for logging general operational messages that describe the normal flow of your application. Use it to track key events or milestones.
logger.info('Application started')3) Warning Level
Log at the WARNING level when something might cause problems in the future or if there's an issue that doesn’t immediately impact functionality. It acts as an early alert system.
logger.warning('Resource usage is high')4) Error Level
Use the ERROR level when an issue occurs that prevents a specific operation but doesn’t stop the entire application. These logs highlight problems requiring attention.
logger.error('Failed to open file')5) Critical Level
The CRITICAL level is reserved for severe issues that may cause the program/application to crash or indicate a significant failure. These logs demand immediate action.
logger.critical('Out of memory, application stopping')Set the Appropriate Logging Level Based on the Deployment Stage:
🔮 DEBUG for Development:
During development, set the logging level to DEBUG to capture detailed insights about your application. This helps identify issues and refine your code effectively. logger.setLevel(logging.DEBUG)
🔮 WARNING / ERROR for Production:
In production, focus on potential issues or errors to avoid excessive logging. Set the level to WARNING or ERROR to make sure the logs remain concise and relevant. logger.setLevel(logging.WARNING) # or ERROR
To keep your logs from getting out of hand, customize your logging levels for each deployment stage. Don't try to log everything—focus on capturing the info that'll help you maintain or debug your program quickly.
3️⃣ Databricks Logging Best Practice #3—Use Structured Logging with JSON
Structured logging in JSON format simplifies parsing and analysis, making it especially useful when working with Databricks Notebooks. Here’s how to set up structured logging in JSON format for better log management and integration.
Why JSON for Logging?
JSON logs can be easily integrated with analytics tools and are machine-readable, which is beneficial for logging in Databricks where you might want to pull log data for further processing or visualization.
Implementing JSON Logging:
Below is an example to output logs in JSON format:
import logging
import json
import os
class JSONFormatter(logging.Formatter):
def format(self, record):
log_record = {
'timestamp': self.formatTime(record, self.datefmt),
'level': record.levelname,
'message': record.getMessage()
}
return json.dumps(log_record)
# Create a logger object
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO) # Set your logging level
# Create a file handler
log_file_path = '/tmp/json____log.txt'
handler = logging.FileHandler(log_file_path)
# Set the formatter for the handler
formatter = JSONFormatter(datefmt='%Y-%m-%d %H:%M:%S')
handler.setFormatter(formatter)
# Add the handler to the logger
logger.addHandler(handler)
# Debug statement to check if the file is created
if os.path.exists(log_file_path):
print(f"Log file created at: {log_file_path}")
else:
print(f"Failed to create log file at: {log_file_path}")
# Log messages
logger.info('Test log message')
logger.error('Error message')
# Debug to check the content of the log file
with open(log_file_path, 'r') as file:
log_content = file.read()
print(f"Log file content:\n{log_content}")
What Happens in the Code
1) JSON Formatter:
- A custom JSONFormatter class converts log records into JSON format.
- Each log entry includes a timestamp, severity level, and message.
2) Logger Configuration:
- A logger object is created and set to INFO level.
- A file handler is added to save logs to a file (
/tmp/json____log.txt).
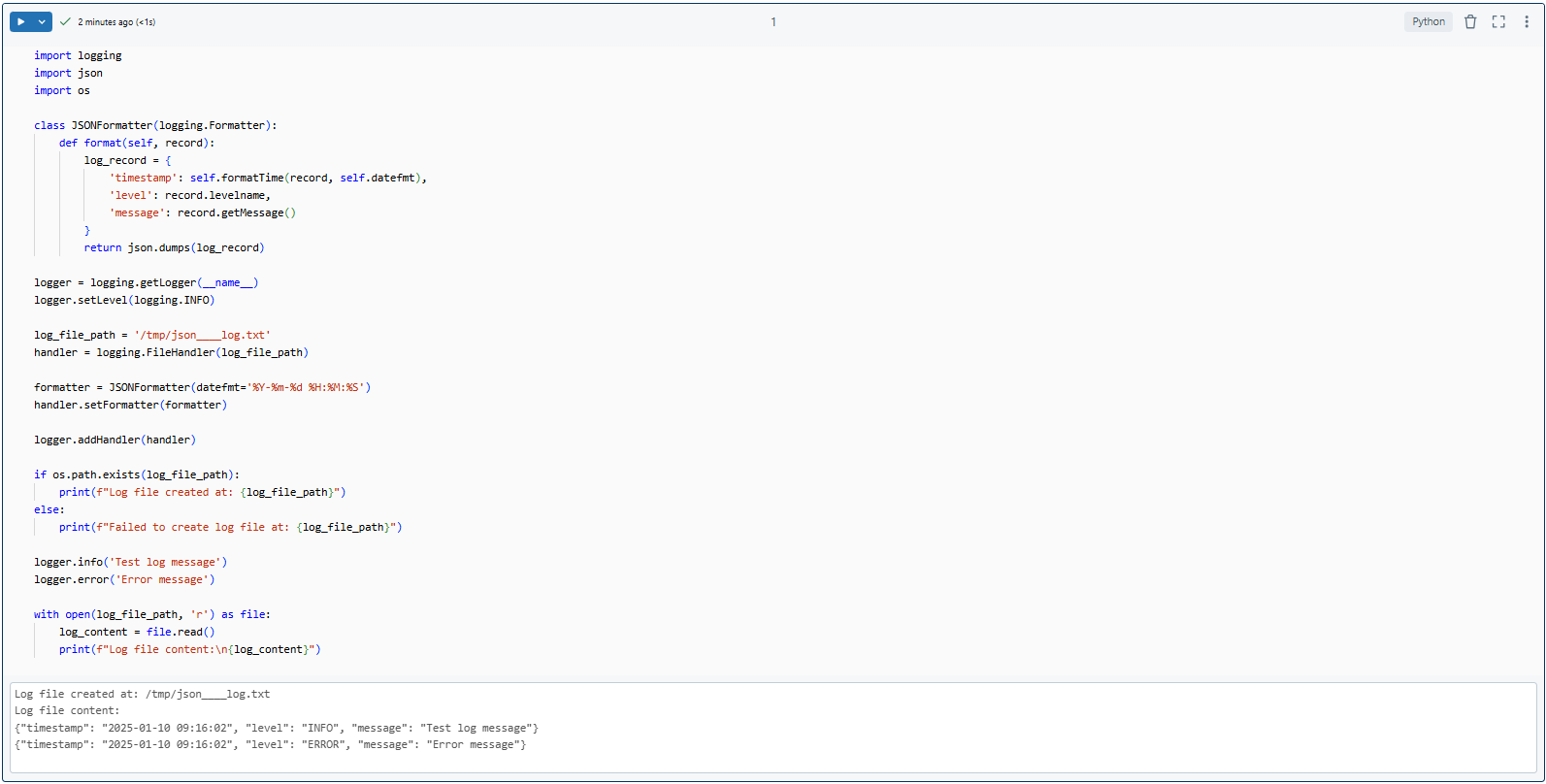
After you run this code, your log file (json____log.txt) will contain entries like:
{"timestamp": "2025-01-10 09:16:02", "level": "INFO", "message": "Test log message"}
{"timestamp": "2025-01-10 09:16:02", "level": "ERROR", "message": "Error message"}Here is what your output should look like:
Benefits of JSON Logging:
🔮 Makes it easier to search, filter, and analyze logs programmatically.
🔮 Simplifies integration with external tools or Databricks' own visualization features.
🔮 Provides consistent and structured log output.
TL:DR; If you adopt this best practice, it'll be a lot easier to go through your logs and connect them to other tools or use them for more analysis.
4️⃣ Databricks Logging Best Practice #4—Write Meaningful Log Messages
Clear and meaningful log messages make debugging and monitoring in Databricks Notebooks significantly easier. Here’s an example of how to craft log messages that provide valuable context:
import logging
# Set up logger
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
# Create a console handler
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
# Add handler to logger
logger.addHandler(console_handler)
def process_data(data):
try:
result = data * 2 # Example
logger.info(f'Data processed. Input: {data}, Output: {result}')
except Exception as e:
logger.error(f'Failed to process data. Input: {data}, Error: {e}')
process_data(10)
So what's happening here:
1) Informational Logging: When the data is processed successfully, the try block logs an informational message. This message includes the input and output, helping you trace the flow of data.
Example log:
Data processed successfully. Input: 10, Output: 20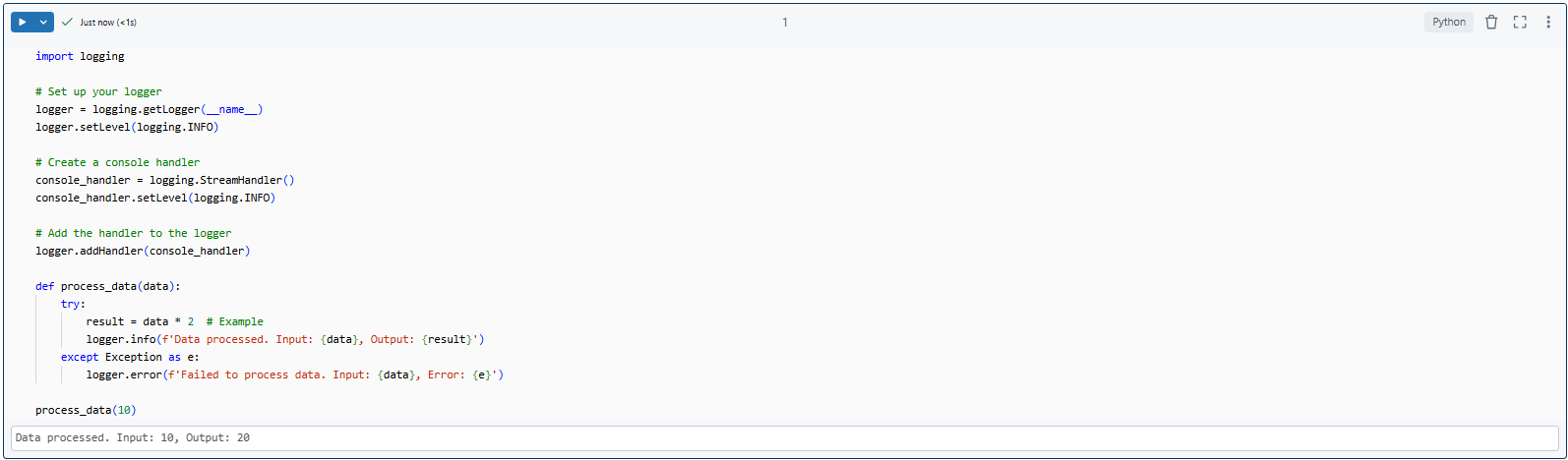
2) Error Logging: If something goes wrong, the except block logs the error, including the input data that caused it and what the error is. That info is super helpful for figuring out what went wrong.
Example log:
Error processing data. Input: 10, Error: division by zero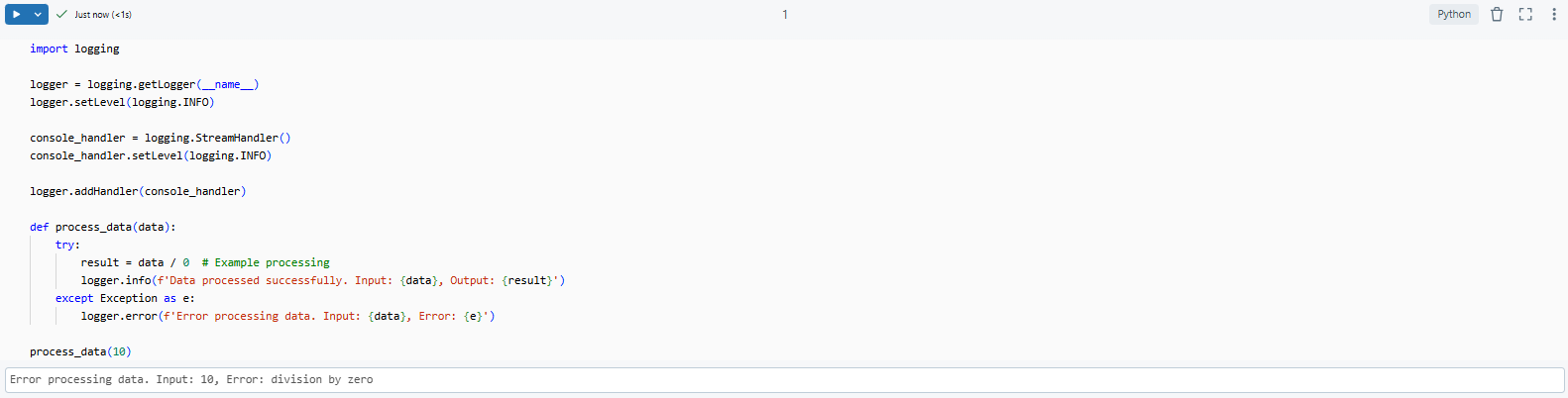
Guidelines for Writing Meaningful Log Messages:
When writing log messages, try to cover the basics:
🔮 What actually happened: Clearly describe the action or event (e.g. “Data processed successfully”).
🔮 What data was involved: Include key inputs and outputs to provide context.
🔮 Where it went down: While optional, specifying the function or module can help in complex systems.
5️⃣ Databricks Logging Best Practice #5—Add Timestamps and Maintain a Consistent Format (ISO-8601)
Adding timestamps to logs in Databricks Notebooks is essential for tracking event sequences. Use the ISO-8601 format for consistency across logs.
Why Use ISO-8601 Timestamps?
➥ Standardized Format: ISO-8601 (%Y-%m-%dT%H:%M:%S) provides a universally recognized timestamp format (like 2025-01-10T09:29:38).
➥ Chronological Sorting: It lets you sort and analyze your logs in order, so you can see what happened when.
➥ Tool Integration: ISO-8601 works seamlessly with monitoring and analytics tools that need a standard timestamp format.
Here is an example of adding ISO-8601 timestamps to Logs:
import logging
# Set up the logger with ISO-8601 timestamp format
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s', datefmt='%Y-%m-%dT%H:%M:%S')
handler = logging.StreamHandler()
handler.setFormatter(formatter)
logger.addHandler(handler)
# Log an example message
logger.info('Test message with a timestamp')
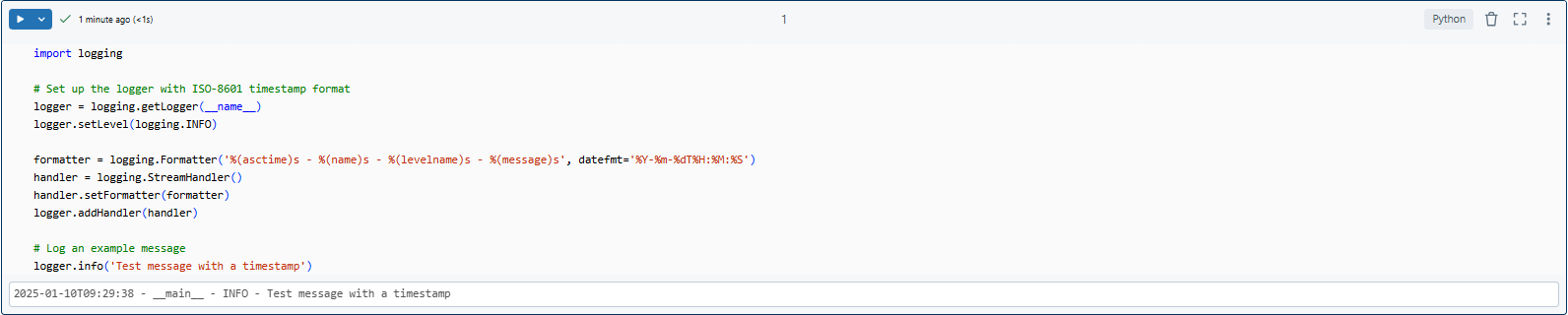
Here you can see that ISO-8601 format (%Y-%m-%dT%H:%M:%S), looks like 2025-01-10T09:29:38.
This standardized format is beneficial when sorting logs by time to view the sequence of events. It also helps in integrating logs with monitoring or analytics tools that require timestamps in this format.
Most logging frameworks include timestamps by default. However, make sure they follow the ISO-8601 format to maintain consistency across systems and tools.
6️⃣ Databricks Logging Best Practice #6—Periodically Test Logging Configuration
Don't take a "set it and forget it" approach to logging in Databricks Notebooks—that can backfire. Instead, test your logging setup often to catch potential issues. This way, you can ensure your logs stay reliable.
Why Test Your Logging Configuration?
1) Catch Configuration Drifts
Over time, updates to Databricks or changes in your environment can alter how logs are recorded or stored. Regular testing helps identify and fix these issues before they become bigger problems.
2) Verify Log Retention
Are your logs being stored for the expected duration? This is particularly important for meeting compliance requirements or reviewing historical data.
3) Evaluate Log Quality
Are your logs providing actionable insights? Regular checks help ensure your log messages are clear, relevant, and valuable for debugging or monitoring.
4) Confirm Log Accessibility
Can you access your logs easily from storage locations like DBFS, Azure Blob Storage, or Amazon S3? Periodic testing guarantees your logs are accessible when needed.
Here’s a quick checklist for periodic testing:
Testing your logging setup often helps keep everything running smoothly, accurately, and easily accessible. Catching problems early on saves you from surprises down the line. This also means you can keep your logs in great shape for when you need to monitor, debug, or meet regulatory requirements.
7️⃣ Databricks Logging Best Practice #7—Store Logs in a Centralized Location Like DBFS or Storage Account
Centralizing your logs is a top best practice when working with Databricks Notebooks. It's simple: keep all your logs in one spot. Consider using Databricks File System (DBFS) or a cloud storage.
So why is this such a big deal? Here are a few reasons:
➥ First thing first centralizing logs means you can find and review all your logs from a single location, streamlining the debugging and analysis process when things go wrong.
➥ Storing logs in one place makes it easier to implement retention policies. You can easily manage which logs to keep and which to delete based on your compliance or operational needs.
➥ And let's not forget security. When all your logs are in one place, it's way easier to keep an eye on who can access them.
We've already gone over using DBFS for log storage, so let's do a quick recap of the benefits. Since DBFS is built right into the Databricks platform, it's a no-brainer choice.
import logging
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
handler = logging.FileHandler('/dbfs/FileStore/my_log.txt')
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler.setFormatter(formatter)
logger.addHandler(handler)
logger.info('Logging to DBFS')This code writes logs to a file located in /dbfs/FileStore/, which you can access via the Databricks UI or programmatically.
If you prefer using external storage services like Azure Blob Storage, AWS S3, or Google Cloud Storage (GCS), you can set up your logger in a similar way. Just use the appropriate path for your chosen storage service.
8️⃣ Databricks Logging Best Practice #8—Implement Error Handling with Try-Except Blocks and Log Exceptions
In Databricks Notebooks, proper error handling and logging are essential for smooth operation and debugging. Using try-except blocks effectively helps you catch and log exceptions, making it easier to identify issues and resolve them quickly. Here's how you can do it:
Here is an example of error handling and logging:
import logging
# Set up your logger
logger = logging.getLogger(__name__)
logger.setLevel(logging.ERROR)
# Configure handler to write to a file in DBFS
handler = logging.FileHandler('/dbfs/FileStore/logs/error_log.txt')
formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
handler.setFormatter(formatter)
logger.addHandler(handler)
def divide_numbers(a, b):
try:
result = a / b
return result
except ZeroDivisionError:
# Log and handle the specific error
logger.error('Attempted to divide by zero')
return "Error: Division by zero"
except Exception as e:
# Catch any other exceptions
logger.error(f'An unexpected error occurred: {e}')
Raise
Try Block {
- Attempts to execute code that might raise an exception. In this case, it tries to divide two numbers. If the denominator is zero, a ZeroDivisionError is raised.
}
Except Blocks {
- ZeroDivisionError: Specifically handles division by zero, logs the error, and returns a custom error message.
- General Exception: Catches any other unexpected errors, logs them, and re-raises the exception for further handling if necessary.
}
Handling Exceptions During Function Execution
You can test the error handling like this:
try:
result = divide_numbers(10, 0)
print(f"Result: {result}")
except Exception as e:
# Handle the exception
print(f"Operation failed: {e}")
try:
result = divide_numbers(200, 100)
print(f"Result: {result}")
except Exception as e:
print(f"Operation failed: {e}")
9️⃣ Databricks Logging Best Practice #9—Integrate Databricks With Log Analytics Tools
To improve your monitoring and log analysis, it's a good practice to integrate Databricks with log analytics tools. These tools can help you gain deeper insights, visualize metrics, and monitor logs more effectively. Here are some of the top tools you can use with Databricks:
1) Azure Log Analytics
If you're already using the Azure ecosystem, Azure Log Analytics. It integrates smoothly with Databricks and other Azure services, making it easier to query logs with Kusto Query Language (KQL). This allows you to dive deep into your logs and extract valuable insights, such as performance metrics, error rates, and more.

2) Datadog
Datadog is known for its comprehensive monitoring capabilities and can ingest logs from Databricks to provide real-time observability across your applications. This includes metrics, traces, and logs in one place.

3) Splunk
Splunk offers powerful log analysis capabilities with its search-processing language. You can configure Databricks to send logs to Splunk for centralized log management and analysis.

4) Grafana
While Grafana is primarily a visualization tool, it can be paired with data sources like Loki for log storage. When integrated with Databricks, Grafana provides rich, detailed visualizations of your log metrics, helping you quickly identify performance bottlenecks or other issues.

Each tool has its own advantages, so select the one that's best for your log analysis needs and fits with your existing tech stack.
🔟 Databricks Logging Best Practice #10—Enable Databricks Audit Logs
Enabling Databricks Audit Logs is a crucial practice for tracking user activity and system changes within your workspace. These logs provide a detailed record of who did what, when, and often why—essential for security, compliance, and troubleshooting.
What Audit Logs Do:
➥ Audit Logs include details like who logged in, what data they accessed, or changes made to configurations.
➥ Audit Logs record actions like cluster creation, deletion, or modifications, giving insight into the operational history of your Databricks environment.
➥ Audit logs help organizations meet regulatory obligations for data management and user actions by keeping a complete record of operations.
Need more detailed steps on enabling and managing audit logs in Databricks? Check out the official Databricks documentation for more info.
Setting up and using audit logs does more than just keep a record—it helps you prep for audits, boost your security, and make your Databricks environment more open and accountable.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Conclusion
And that’s a wrap! Logging in to Databricks is crucial. It gives you a clear view of your data workflows, which helps you spot problems before they cause trouble and keep your system intact. Logging in to Databricks Notebooks isn't just about recording what's happening—it's about creating a set of tools that make it easier to debug, monitor, and meet compliance standards.
In this article, we covered 10 best practices for logging in Databricks Notebooks:
- Databricks Logging Best Practice #1—Implement Databricks Logging in Databricks Notebook With Python's Logging Module
- Databricks Logging Best Practice #2—Configure Logging Levels Appropriately
- Databricks Logging Best Practice #3—Databricks Logging Using a Structured Format
- Databricks Logging Best Practice #4—Write Meaningful Log Messages
- Databricks Logging Best Practice #5—Add Timestamps and Maintain Consistent Format
- Databricks Logging Best Practice #6—Periodically Test Logging Configuration
- Databricks Logging Best Practice #7—Store Logs in a Centralized Location Like DBFS or Storage Account
- Databricks Logging Best Practice #8—Implement Error Handling with Try-Except Blocks and Log Exceptions
- Databricks Logging Best Practice #9—Integrate Databricks With Log Analytics Tools
- Databricks Logging Best Practice #10—Enable Databricks Audit Logs
… and so much more!
FAQs
What are the primary benefits of logging in Databricks?
Logging in Databricks supports debugging, monitoring, and creating audit trails, thereby enhancing observability and accountability.
What formats are recommended for structured logging?
JSON is highly recommended for structured logging because it's easily parseable and compatible with many analytics tools.
How do I configure different logging levels in Python?
Configure logging levels using logger.setLevel(logging.<LEVEL>) where <LEVEL> can be DEBUG, INFO, WARNING, ERROR, or CRITICAL.
Can I automate the testing of my logging configuration?
Yes, you can automate log testing using scripts that log messages at different levels and check if they are correctly formatted and stored.
How do I get cluster logs in Databricks?
Cluster logs are accessible through the cluster details page in the Databricks UI. For long-term storage or analysis, you can configure logs to be sent to external storage solutions like Azure Blob Storage, AWS S3, or Databricks File System (DBFS).
What should I include in meaningful log messages?
Include timestamps, the context of the operation, severity level, and a clear description of the event or error.
How do I set up logging to write to DBFS in Databricks?
Use logging.FileHandler('/dbfs/path/to/logfile.txt') to write logs to Databricks File System. Make sure you have the necessary permissions.
What's the difference between notebook logs and cluster logs in Databricks?
Notebook logs are specific to the code execution within notebooks, while cluster logs include broader system and runtime information for the entire cluster.
Can I log from Spark operations in Databricks?
Yes, you can log from Spark operations using the same Python logging framework, but make sure to understand the distributed nature of Spark where logs might be scattered across executors.
How do I integrate Databricks logs with Azure Log Analytics?
Configure diagnostic settings in your Databricks workspace to send logs to an Azure Log Analytics workspace for centralized log analysis.
Is it possible to customize log retention in Databricks?
Databricks manages some logs internally, but for custom retention, you'll need to handle storage and lifecycle policies on your cloud storage solutions.
What should I do if my logs are not appearing in DBFS?
Check your file permissions, ensure the path is correct, and confirm the cluster has write access to the DBFS location you specified.
Can I use Databricks audit logs for compliance reporting?
Yes, audit logs in Databricks can be used for compliance reporting as they provide a record of user activities and system changes.
How do I handle sensitive information in logs?
Implement log masking or sanitization to remove or obscure sensitive data before logging, or use structured logging to exclude sensitive fields from log outputs.















