





























Data pipelines are crucial for moving data from source systems into data warehouses and lakes. But as data volumes explode exponentially, building and managing efficient data pipelines becomes highly complex. Databricks Delta Live Tables are specifically built to simplify this issue and helps in development by allowing you to build reliable, maintainable, and testable data pipelines in Databricks. You can define the transformations to perform on your data, and Delta Live Tables manage task orchestration, cluster management, monitoring, data quality, error handling, and everything in between.
In this article, we will provide an in-depth overview of Databricks Delta Live Tables and walk through examples of how to create Delta Live Tables using SQL. We will also discuss the limitations and challenges of this approach.
What Are the Hurdles of Building Data Pipelines the Traditional Way?
In the past, companies had to build their data pipelines entirely from the ground up. This involved writing custom code and using orchestration tools like Apache Airflow and Apache Spark to manage the flow of data. Developing these pipelines from scratch was a complex and time-consuming process, and it was easy for errors to creep in along the way. Maintaining and updating these custom-built pipelines also required significant effort and resources. Even a tiny bug could bring the entire pipeline crashing down.
There were several major challenges that made traditional data pipeline development such a nightmare:
- Troubleshooting nightmare. Debugging issues in these complex, custom-coded pipelines was extremely difficult. It was hard to trace where the data came from and pinpoint the root cause of problems.
- Optimization was a manual headache. Data teams had to manually optimize pipeline performance, add caching, partitioning, and other optimizations.
- The code was overly complex. Building reliable, scalable pipelines required writing a lot of complex orchestration code beyond just the core data transformation logic.
- Reliability was a constant issue. Custom pipelines were prone to race conditions, duplicates, data loss or corruption, and more. Guaranteeing fault tolerance and exactly-once processing added even more complexity.
- Lineage and Traceability were lacking. Most custom pipelines were tailored to specific use cases and not easily reusable. New pipelines often had to be built from scratch, making it difficult to ensure clear data lineage and traceability.
- Maintenance was high. Any changes to schemas or business logic necessitated reworking across all pipelines, burdening engineers.
- Collaboration was limited. Traditional pipelines made it hard for SQL users, data engineers, data scientists, and others to collaborate effectively on building pipeline logic.
- Scaling was challenging. Running pipelines at scale required configuring and maintaining scalable compute infrastructure, diverting engineer time.
- Batch and streaming coordination was complex. Handling both batch and streaming data ingestion and processing within a single framework added further complexity.
- Securing pipelines was an added burden. Building secure, governed data pipelines involved additional cross-cutting code for access controls, auditing, lineage tracking, etc.
The traditional approach made it incredibly complex to develop, optimize, monitor, and maintain efficient production-ready data pipelines as needs evolved over time. A better solution was desperately needed, which is where Databricks Delta Live Tables come in.
What is a Databricks Delta Live Table?
Databricks Delta Live Tables is a declarative ETL framework for building reliable, maintainable, and testable data processing pipelines. It allows you to define the transformations to perform on your data using either SQL or Python queries, and manage task orchestration, cluster management, monitoring, data quality, and error handling without having to define a series of separate Spark tasks. Instead, you define streaming tables and materialized views that the system should create and keep up-to-date.
You can create three types of datasets using Delta Live Tables:
- Streaming tables: Streaming tables process each record exactly once, assuming an append-only source. They are ideal for incrementally processing new data.
- Materialized views(MV): Materialized views process records as needed to return accurate results for the current data state. They are used for data sources with updates, deletions, or aggregations, as well as for change data capture (CDC) processing where the target table needs to reflect the full current state.
- Views: Views are intermediate queries that should not be exposed to end users or systems. They are useful for enforcing data quality constraints or transforming and enriching datasets that drive multiple declarative queries.
Here's a quick overview of how Databricks Delta Live Tables work:
- Define Tables using SQL/Python: You define Delta Live Tables using standard DDL SQL syntax or the Table API in Python. These table definitions specify the data schema and associated transformations.
- Express Transformations: Directly define ETL logic for pipelines using ANSI SQL or Python queries on the defined tables.
- Handle Lineage & Dependencies: Databricks Delta Live Tables automatically track dependencies between tables and schedule execution based on these table lineages.
- Continuous/Scheduled Execution: Pipelines can run continuously as data arrives (for streaming sources) or be scheduled to run at intervals, with new data incrementally processed.
- Auto-Optimize Performance: Databricks Delta Live Tables automatically optimize queries, perform auto-compaction, manage partitions, and scale clusters to ensure optimal performance.
- Unified Batch & Streaming: Databricks Delta Live Tables process both streaming and batch data using the same table definitions and underlying processing engine (Apache Spark Structured Streaming).
- Handle Reliability & Scaling: The service takes care of pipeline scaling, reliability, fault tolerance, and ensures exactly-once processing without requiring manual configuration.
- Secure by Default: You can implement fine-grained access controls on tables through integration with Unity Catalog, with credential management, encryption, and other security aspects handled by the service, ensuring a secure default configuration.
Using Databricks Delta Live Tables eliminates the necessity to create an orchestration framework and infrastructure from the ground up. Instead, you solely define your data transformation logic, leaving Databricks Delta Live Tables to manage the intricate processes of operationalizing and operating the pipelines.
Benefits of Building/Running ETL/ELT Pipelines with Databricks Delta Live Tables
Using Databricks Delta Live Tables for ETL/ELT pipelines offers several benefits, they are:
1) Data Ingestion
Databricks Delta Live Table provides efficient data ingestion from various data sources like cloud storage, message buses, external systems using features like AutoLoader and streaming tables. You can also use Change data capture (CDC) capability in Databricks Delta Live Table to update tables based on changes in source data.
2) Data Transformation
Intelligent and cost-effective data transformations using just a few lines of code. Databricks Delta Live Table determines the most efficient way to build and execute streaming or batch data pipelines for optimal price/performance. You can quickly set up a flexible and streamlined medallion architecture with streaming tables and materialized views, and make sure your data is good and useful with expectations. You can also update your data whenever you want, or let it update automatically, depending on how fresh you need your data to be.
3) Pipeline Management
Very simple pipeline setup and maintenance. Databricks Delta Live Table automates operational complexity like task orchestration, CI/CD, autoscaling infrastructure, monitoring via metrics and error handling. This allows engineers to focus on data quality.

4) Stream Processing
Databricks Delta Live Table provides next-gen stream processing using Spark Structured Streaming as the core technology. It provides unified batch and stream processing with subsecond latency and high performance.
5) Data Storage and Governance
Databricks Delta Live Table provides unified data governance and storage leveraging Delta Lake and Unity Catalog. Raw data is optimized with Delta Lake for both streaming and batch workflows. Unity Catalog provides integrated governance, discovery, access and sharing of data and AI assets across clouds.
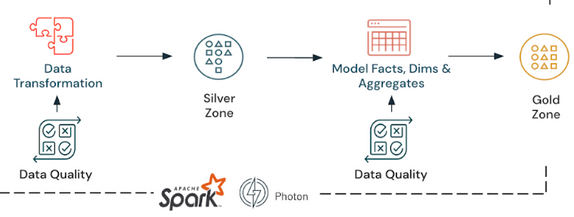
As we have already mentioned, Delta Live Tables is often used in conjunction with the Medallion Lakehouse Architecture. The Medallion Lakehouse Architecture is a series of data layers that denote the quality of data stored in the Lakehouse. It consists of bronze (raw), silver (validated), and gold (enriched) layers. The architecture guarantees atomicity, consistency, isolation, and durability as data passes through multiple layers of validations and transformations before being stored in a layout optimized for efficient analytics.
Syntax to Create Databricks Delta Live Table in SQL
To create a Delta Live Table in SQL, you need to use the CREATE OR REFRESH statement with either the STREAMING TABLE or LIVE TABLE keyword, depending on whether you want to process streaming or batch data (materialized view). You also need to specify the table name, optionally define columns and their types, partitioning scheme, location, comment, properties, and the query expression that defines the table.
To create a Delta Live Table in SQL, you can use the following syntax:
CREATE OR REFRESH [TEMPORARY] { STREAMING TABLE | LIVE TABLE } table_name
(...
...
...
...)
PARTITIONED BY (<col_name>)
COMMENT "Some comment"
AS SELECT * FROM ...Syntax and Modules Required to Run Databricks Delta Live Table in Python
To create a Databricks Delta Live Table in Python, you need to use the @dlt.table decorator function to define a query that performs either a static (batch) or a streaming read against a data source. You can also specify the table name, comment, properties, path, partition columns, schema, and expectations using the function parameters and additional decorators.
To create a Delta Live Table in Python, you can use the following syntax:
import dlt
@dlt.table(
name="table_name",
comment="table_comment",
table_properties={"key1": "value1", "key2": "value2"},
path="storage_location_path",
partition_cols=["partition_column1", "partition_column2"],
schema="schema_definition",
temporary=False
)
@dlt.expect("expectation_name1", "expectation_expr1", on_error="fail_update")
@dlt.expect("expectation_name2", "expectation_expr2", on_error="drop_row")
def table_function():
return dlt.read_stream("data_source").select("column1", "column2", ...)Note: Databricks Delta Live Tables are not designed for interactive execution in notebook cells. They are intended for use in pipelines, which are the main unit used to configure and run data processing workflows with Delta Live Tables.
Who Should Use Databricks Delta Live Table?
Databricks Delta Live Tables are suitable for data engineers, data scientists, and data analysts who want to build and maintain reliable data processing pipelines. They are particularly useful for those who need to handle large amounts of data, manage complex data transformations, and ensure high data quality.
Save up to 50% on your Databricks spend in a few minutes!


Step-By-Step Guide to Create Databricks Delta Live Table Using SQL
Now that we understand what Databricks Delta Live Tables are, let's jump into an example to see how we can define a modern ETL data pipeline using SQL.
In this example, we will use the sample code provided by Databricks to ingest Wikipedia clickstream data and create Bronze, Silver, and Gold tables following the Medallion Lakehouse architecture.
Prerequisites
Before you begin, make sure that you have the following:
- Access to a Databricks workspace with the Delta Live Tables feature enabled.
- Familiarity with SQL and the Databricks Lakehouse Platform.
Step 1—Create a Bronze (Raw) Databricks Delta Live Table
The first step is to create a Bronze Delta Live Table to ingest raw data from the source. This table will contain the unprocessed data in its original format.
CREATE LIVE TABLE wiki_clickstream_raw
COMMENT "The raw wikipedia clickstream dataset, ingested from /databricks-datasets."
TBLPROPERTIES ("quality" = "bronze")
AS SELECT * FROM json.`/databricks-datasets/wikipedia-datasets/data-001/clickstream/raw-uncompressed-json/2015_2_clickstream.json`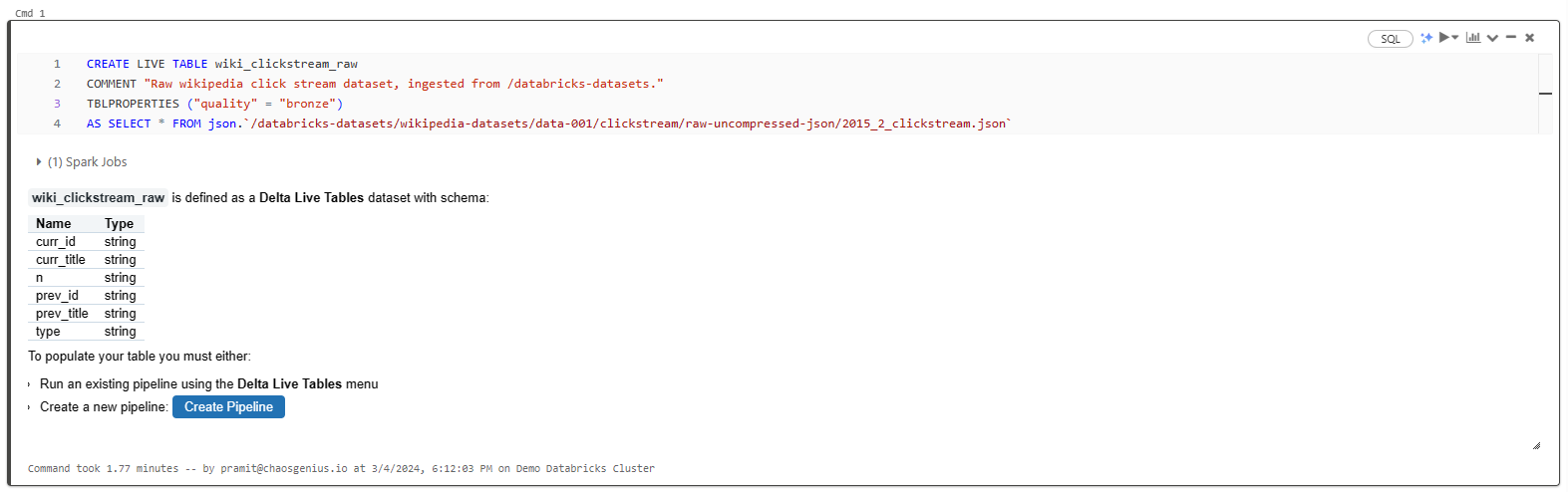
Here's what each part of the statement does:
- CREATE LIVE TABLE: Defines a new Delta Live Table.
- COMMENT: Provides a description of the table.
- TBLPROPERTIES: Allows setting metadata properties; in this case, we label the table as "bronze" quality.
- AS SELECT: Pulls data from the specified JSON dataset location.
As you can see, this creates a Bronze table containing the raw, unprocessed data ingested directly from the source files.
Note: If you want to ingest data from a streaming source (e.g., Auto Loader or an internal dataset), you can create a STREAMING table instead.
Step 3—Create a Silver (Validated) Databricks Delta Live Table
Next, we'll create a Silver Delta Live Table that cleans, transforms, and validates the raw data from the Bronze table.
CREATE LIVE TABLE wiki_clickstream_clean (
CONSTRAINT valid_current_page EXPECT (current_page_id IS NOT NULL AND current_page_title IS NOT NULL),
CONSTRAINT valid_count EXPECT (click_count > 0) ON VIOLATION FAIL UPDATE
)
COMMENT "Wikipedia clickstream dataset with cleaned data types, column names, and quality expectations"
TBLPROPERTIES ("quality" = "silver")
AS SELECT
CAST(curr_id AS INT) AS current_page_id,
curr_title AS current_page_title,
CAST(n AS INT) AS click_count,
CAST(prev_id AS INT) AS previous_page_id,
prev_title AS previous_page_title
FROM live.wiki_clickstream_raw;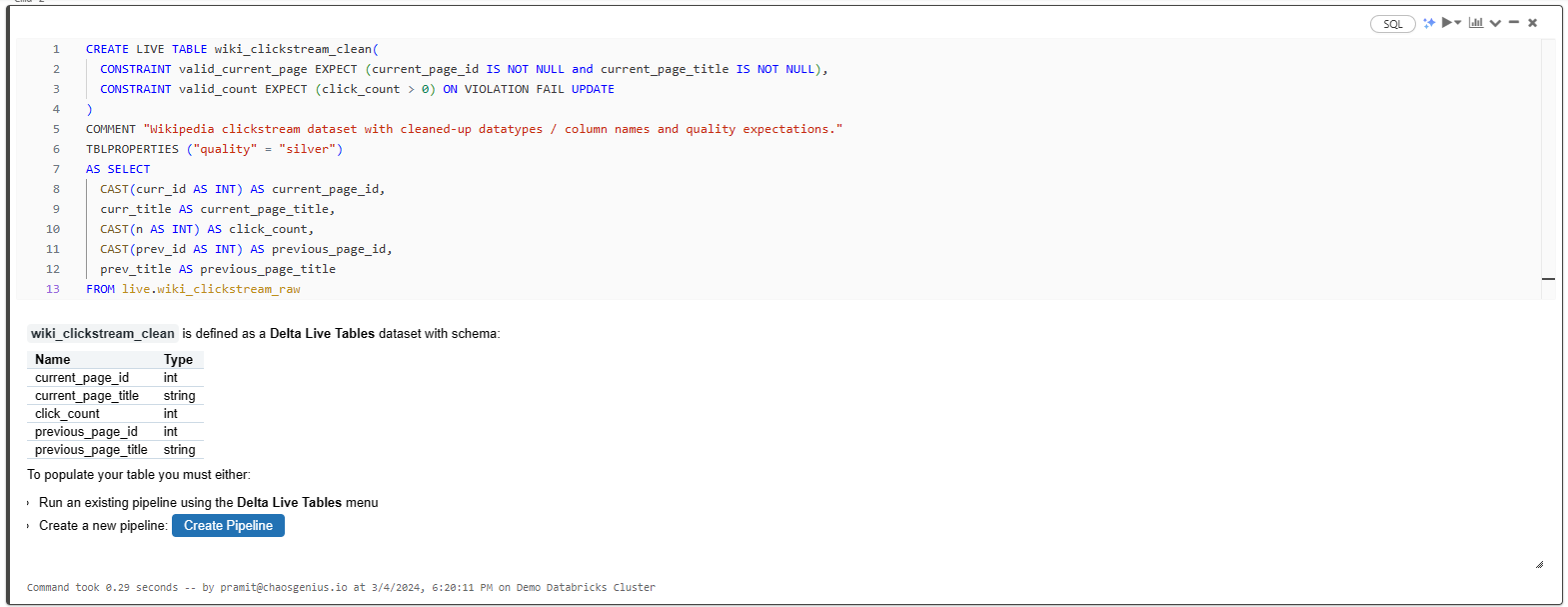
In this statement:
- CONSTRAINT: Defines table constraints to validate data quality.
- CAST: Cleans up data types.
- TBLPROPERTIES to label this as "silver" quality data.
- Column aliases: Renames columns for better readability.
- FROM live.wiki_clickstream_raw: Reads data from the Bronze table as input.
The Silver table now contains cleaned, validated, and transformed data ready for further processing.
Step 4—Create Gold (Enriched) Databricks Delta Live Tables
Finally, let's create some aggregated Gold Delta Live Tables for analysis. So let's create two separate Gold tables tailored for distinct analytical purposes. These tables will involve filtering, aggregating, and joining data using standard SQL operations, with the data sourced from the Silver live.wiki_clickstream_clean table.
Gold Table 1: Top Spark Referrers
CREATE LIVE TABLE top_spark_referrers
COMMENT "A table of the most common pages linking to the Apache Spark page"
TBLPROPERTIES ("quality" = "gold")
AS SELECT
previous_page_title AS referrer,
click_count
FROM live.wiki_clickstream_clean
WHERE current_page_title = 'Apache_Spark'
ORDER BY click_count DESC
LIMIT 10;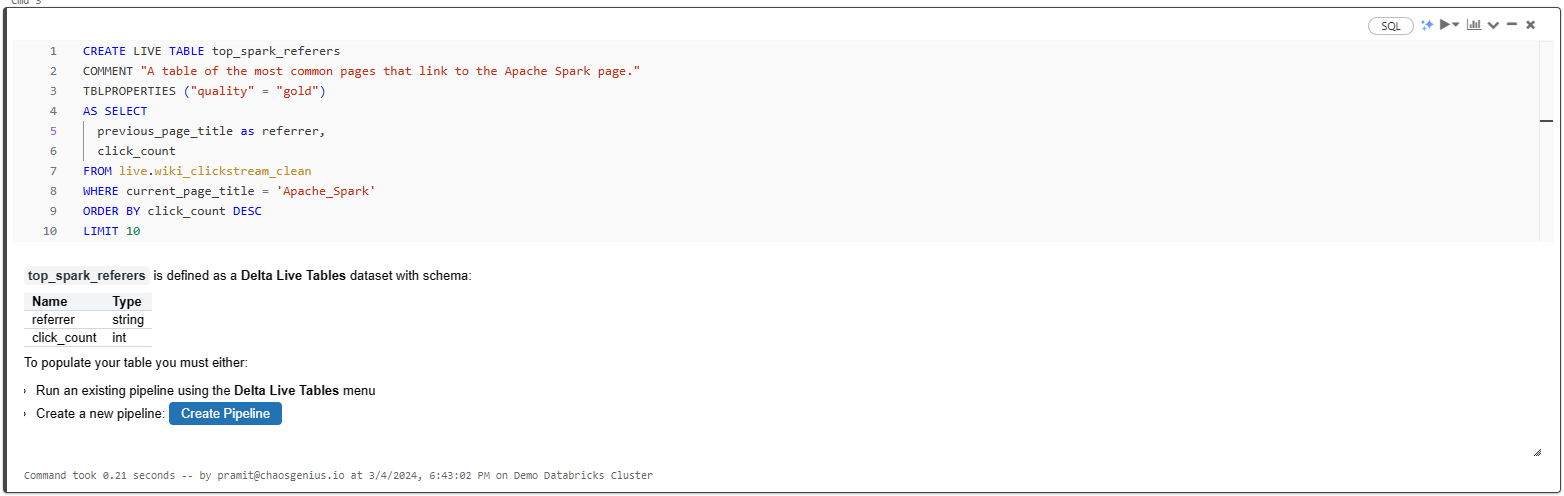
Here, we used:
- TBLPROPERTIES to label this as "gold" quality data.
- AS SELECT to populate the table by selecting data from "live.wiki_clickstream_clean." Columns selected include previous_page_title renamed as "referrer" and click_count.
- WHERE to filter data for the Apache Spark page.
- ORDER BY to arrange results in descending order based on click count.
- LIMIT 10 to restrict the output to the top 10 referrers linking to the Apache Spark page.
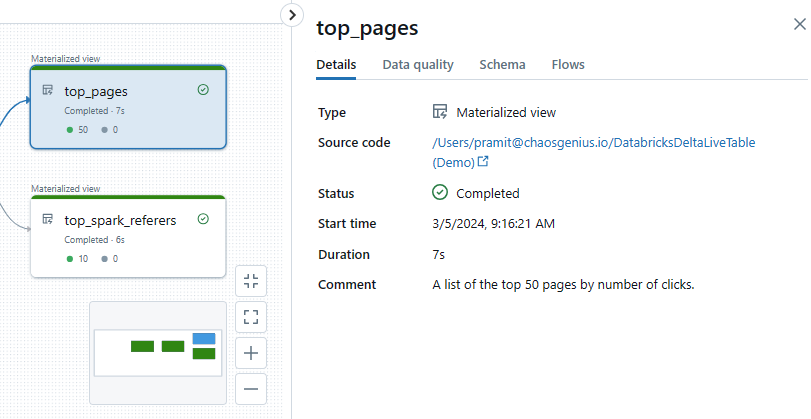
Gold Table 2: Top Pages
CREATE LIVE TABLE top_pages
COMMENT "A list of the top 50 pages by the number of clicks"
TBLPROPERTIES ("quality" = "gold")
AS SELECT
current_page_title,
SUM(click_count) AS total_clicks
FROM live.wiki_clickstream_clean
GROUP BY current_page_title
ORDER BY total_clicks DESC
LIMIT 50;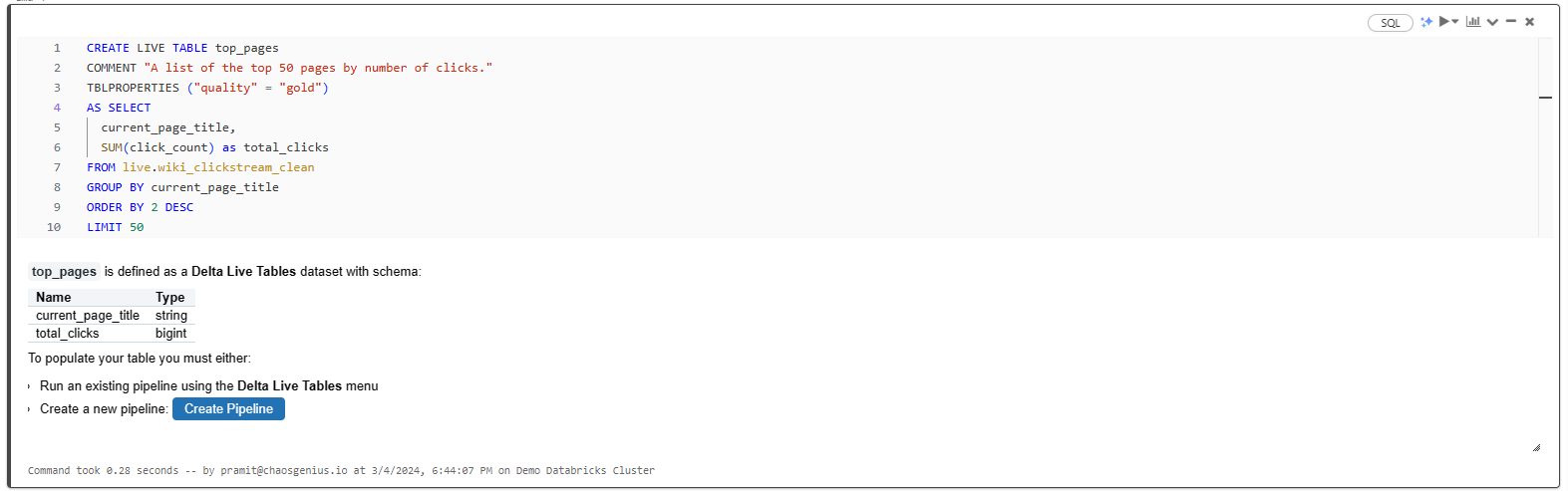
This Gold table lists the top 50 pages by the total number of clicks, ordered by the highest number of clicks.
As you can see, these Gold tables provide the cleaned, aggregated, analysis-ready data for powering dashboards, reports, and applications.
Step 5—Execute the Delta Live Tables in a Pipeline (optional)
So far, we have defined a series of Delta Live Tables for our pipeline using SQL DDL.
The Delta Live Tables need to execute within an orchestrated pipeline to run the table queries and populate data.
For instance, if you try to populate data directly in one of the tables in a notebook, it will fail with: "Delta Live Tables cannot be executed interactively. Please execute them in a Delta Live Tables pipeline."
So we need to create a Delta Live Tables pipeline to orchestrate executing these tables, which we'll cover next.
Step-by-step Guide to Create Databricks Delta Live Table Pipeline
Now, in this section, we'll walk through how to create a Delta Live Tables pipeline in the Databricks UI to execute the Delta Live Tables we defined earlier using SQL.
Prerequisites
Before you begin, make sure that you have the following:
- Access to a Databricks workspace with Databricks Runtime 7.3 LTS or later.
- Necessary permissions to create and manage Delta Live Tables pipelines
- Familiarity with SQL/Python and the Databricks Lakehouse Platform.
Step 1—Navigating to Databricks Workflows Section
First, head over to your Databricks workspace, click on the Workflows in the left sidebar.
Step 2—Selecting Databricks Delta Live Table Tab
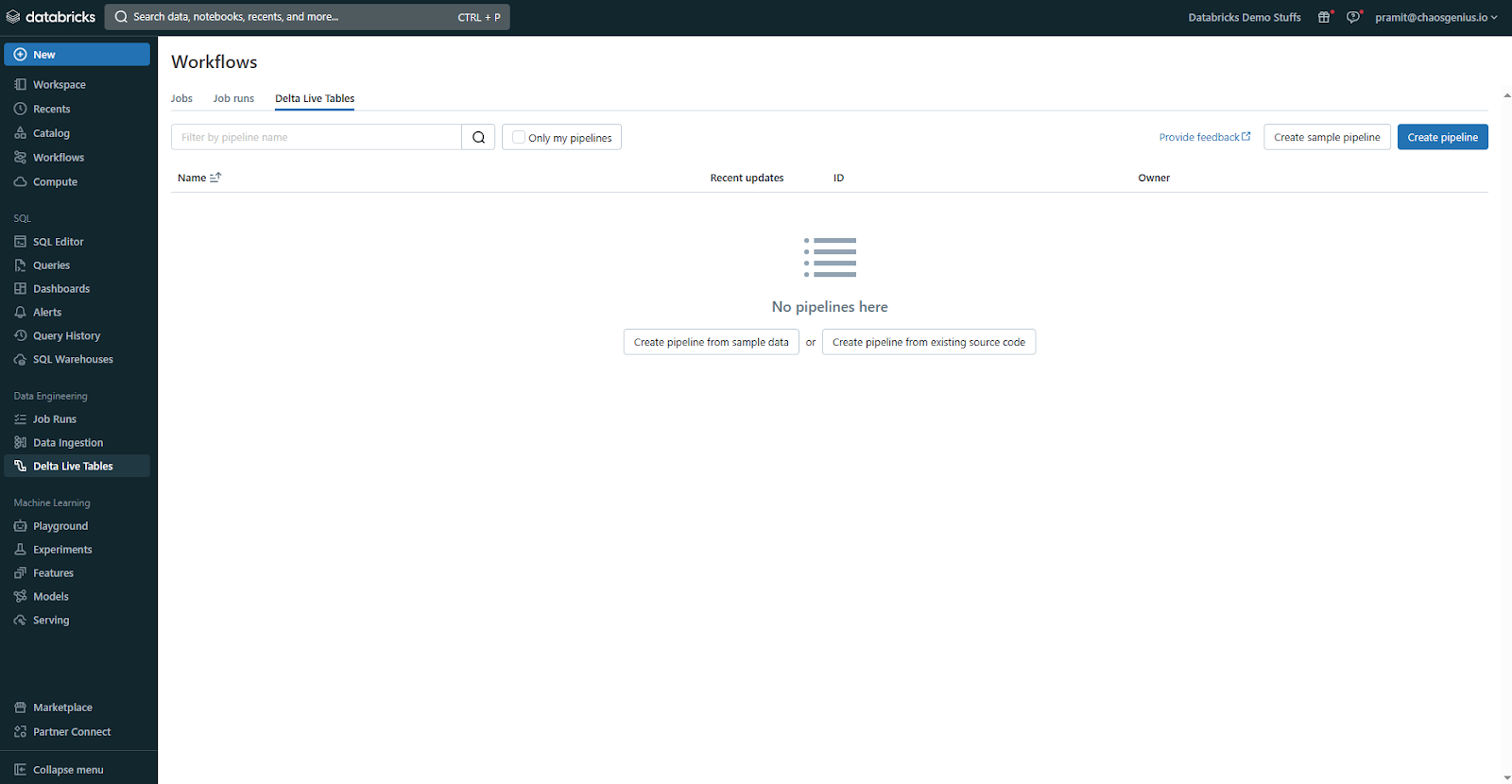
Next, you need to select the Databricks Delta Live Table tab on the top of the Workflows section. This tab shows you all the existing Databricks Delta Live table pipelines in your workspace. You can also create a new pipeline from here.
Step 3—Creating a Pipeline
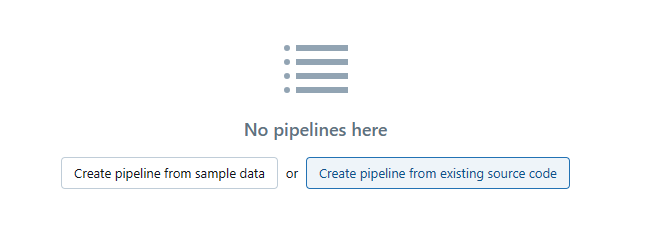
Click the "Create Pipeline" button and select "Create pipeline from existing source code" to create a pipeline based on your existing notebooks, SQL files, or Python files containing Delta Live Tables code.
Step 4—Creating Pipeline From Existing Source Code
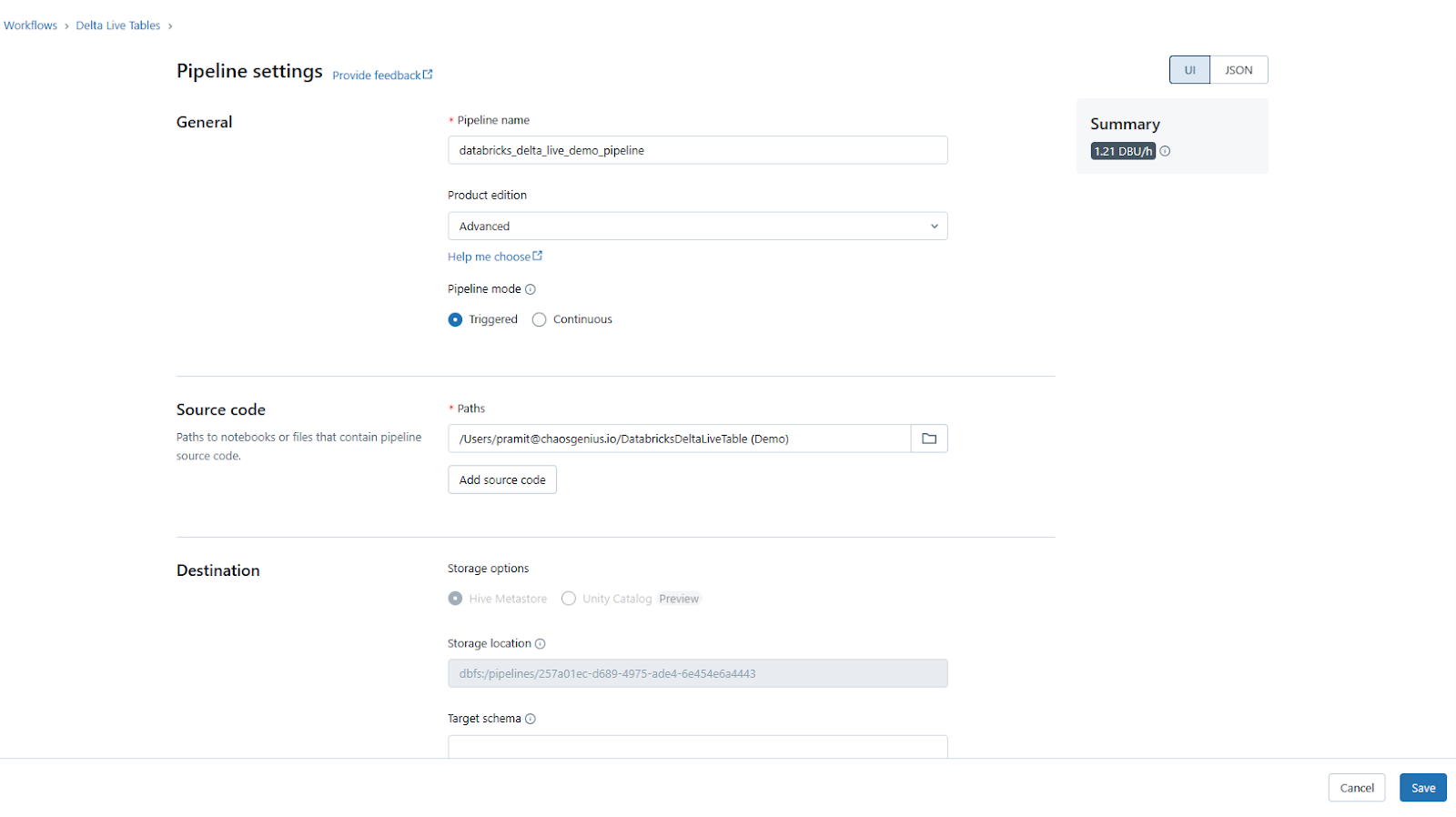
To create a pipeline from an existing source code, you need to select “Create pipeline from existing source code”. After you select it, you need to provide some basic information about your pipeline, such as:
- Pipeline Name: Enter a descriptive and unique name for your pipeline (e.g., "databricks_delta_live_demo_pipeline").

- Source Code destination: Specify the location of your notebooks, SQL files, or Python files containing the Delta Live Tables code. You can provide a local file path or a cloud storage location. Note that you can modify these paths later if needed.

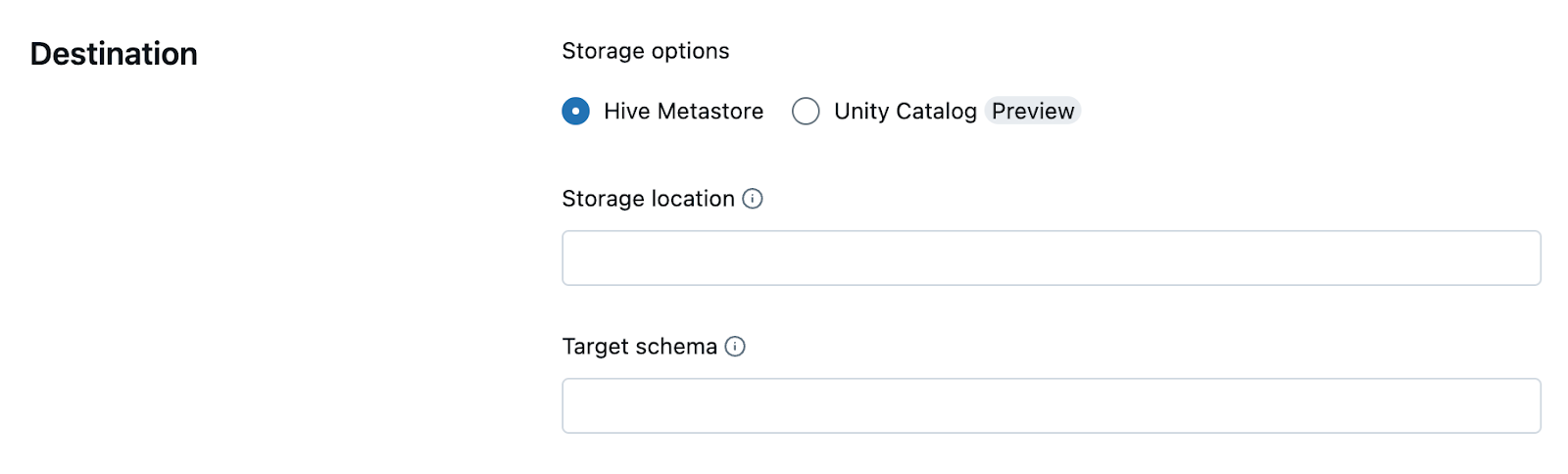
- Destination(Optional): Provide a path on DBFS or cloud storage where the pipeline's output tables and metadata will be stored. If left blank, Databricks will automatically select a default DBFS location.
Scroll down to the "Compute" section to configure additional pipeline settings:
- Cluster Policy: Define limits on the attributes available during cluster creation. You can use a predefined policy, create a custom one, or leave it as "None".

- Cluster Mode: Choose the cluster scaling mode - Enhanced Autoscaling (recommended), Legacy Autoscaling, or Fixed Size cluster.
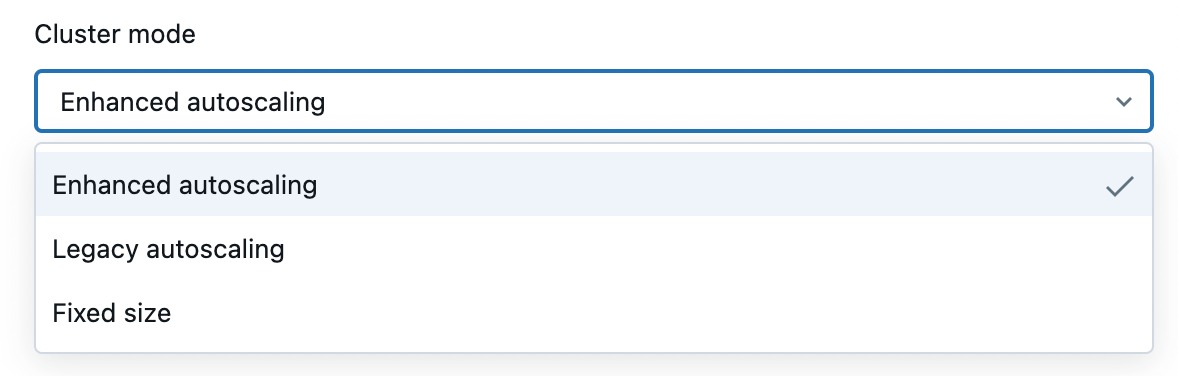
- Photon acceleration: Photon accelerates modern Apache Spark workloads, reducing your total cost per workload. You can check to enable it.

- Cluster Tags(Optional): Add tags to be associated with the pipeline's compute clusters.
- Notifications: Configure email notifications for pipeline success, failure, or fatal failures.
- Advanced Options: Specify any additional configuration overrides or fine-tune pipeline settings.
Once configured, click "Create Pipeline" to initialize the pipeline based on your source code.
Step 5—Walkthrough of Delta Live Table Interface
Once you create your pipeline, you will be taken to the Delta Live Table interface. This is where you can edit, test, deploy, and monitor your pipeline. The interface consists of two main sections: Development Environment and Production Environment.
1) Development Environment (Left Pane): The left section where you can edit and test your pipeline code.
2) Production Environment (Right Pane): The right section where you can deploy and monitor your pipeline.
Additionally, Databricks Delta Live Tables interface provides the following:
- Pipeline Details: Overview of the pipeline with ID, source code location, author, etc.
- Table Graph: Visual graph illustrating the lineage and dependencies between Delta Live Tables in your pipeline.
- Live Updating: The pipeline status, runs, and logs update in real-time as the pipeline executes.
- Settings: Configure pipeline deployment settings like permissions, schedules, notifications, clusters, etc.
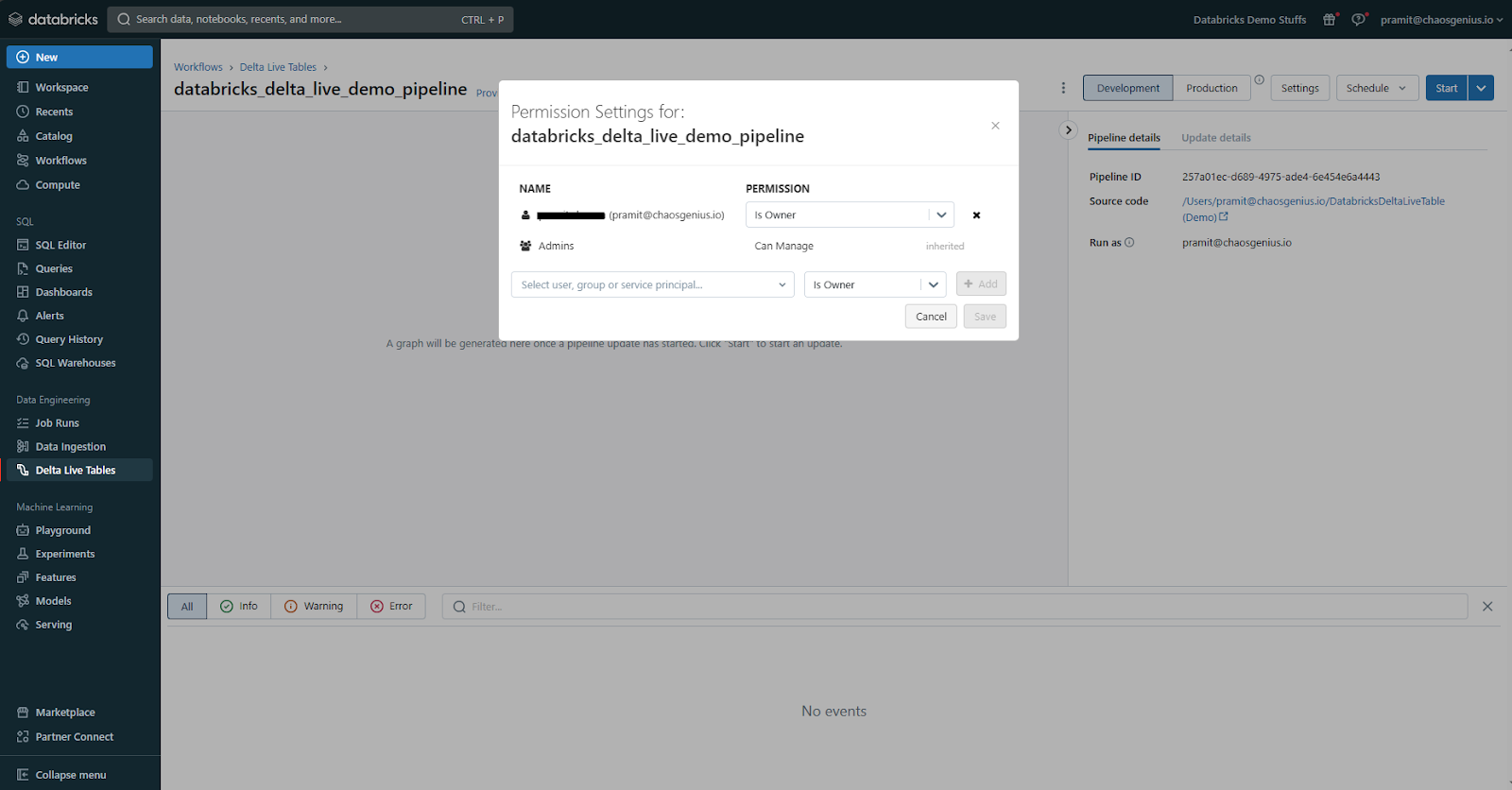
Step 6—Configuring Pipeline Permission
Before executing, we need to configure permissions for the pipeline. To do this, navigate to the Permissions option, which you can find by clicking on the kebab menu. From there, specify which users/groups can view, edit, and run the pipeline. Access can be enabled or restricted as needed.
Step 7—Scheduling Pipeline
Next to the Settings tab in the Delta Live Tables interface, you will find an option to Schedule your pipeline job, where you can configure an automated schedule to trigger your pipeline runs.
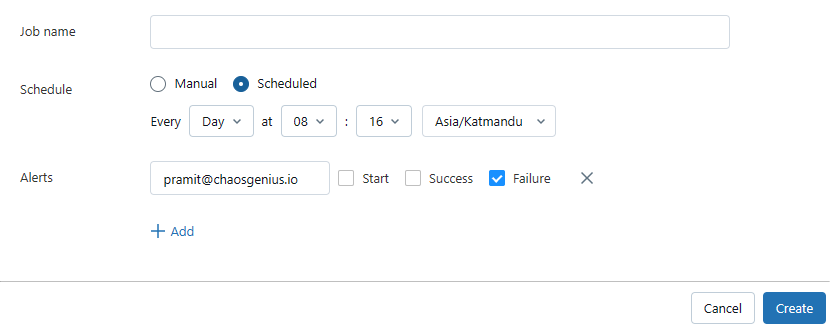
The scheduling mode can be selected as Manual or Scheduled based on your requirements. For scheduled pipelines, you can define a Cron-based schedule expression to specify the frequency, such as running daily, hourly, or adhering to custom calendars. Additional scheduling options allow you to set specific start and end times for the pipeline window, introduce delays if needed, and define dependencies on other pipelines or events. This automated scheduling capability enables you to operationalize your Databricks Delta Live Tables pipelines for continuous data processing and analytics without any kind of manual interventions.
Step 8—Configuring Pipeline Settings
If you want to change any of the pipeline settings before you deploy it, you can do so by clicking on the Settings button in the top right corner of the Delta Live Table interface.
This will open a new settings page where you can modify the following settings:
- Pipeline Name: Modify the pipeline name if needed.

- Product Edition: Select the Databricks edition for your pipeline (Core, Pro, or Advanced). Higher tiers offer additional features like enhanced data quality, lineage tracking, and more.
- Pipeline Mode: Choose between "Triggered" or "Continuous" mode. The "Triggered" mode runs the pipeline only when there is new data available in the source, while the "Continuous" mode runs the pipeline continuously, regardless of data availability.

- Source: Modify the data source for your pipeline if needed.

- Destination: You cannot edit or modify the storage location's destination; the only editable aspect is the target schema. Here, you can specify the target database if you intend to publish your table to the metastore.
- Compute: Configure cluster settings like cluster policy, cluster mode, worker configuration, Photon acceleration, instance profile, and cluster tags.
- Notification: You can also modify the notification settings that you want to use for your pipeline. You can either enable or disable the email notifications for your pipeline, which can be configured for pipeline success, failure, or fatal failures.
After making any changes, click "Save" to apply the new settings.
Step 9—Starting Pipeline
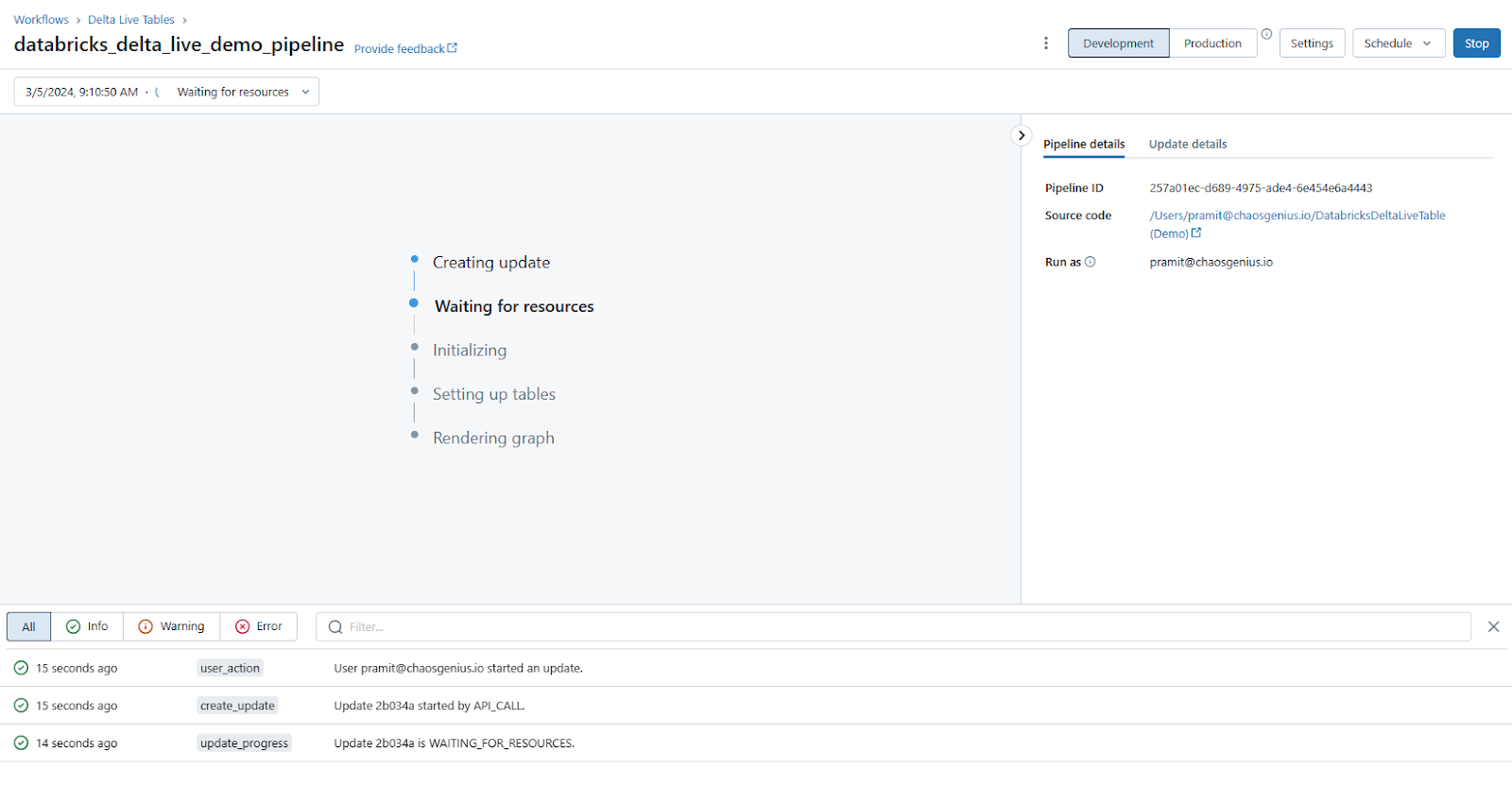
Once configured, click the "Start" button in the top toolbar. This will trigger a run of the Delta Live Tables pipeline.
You can monitor progress in the Runs sidebar and inspect logs.
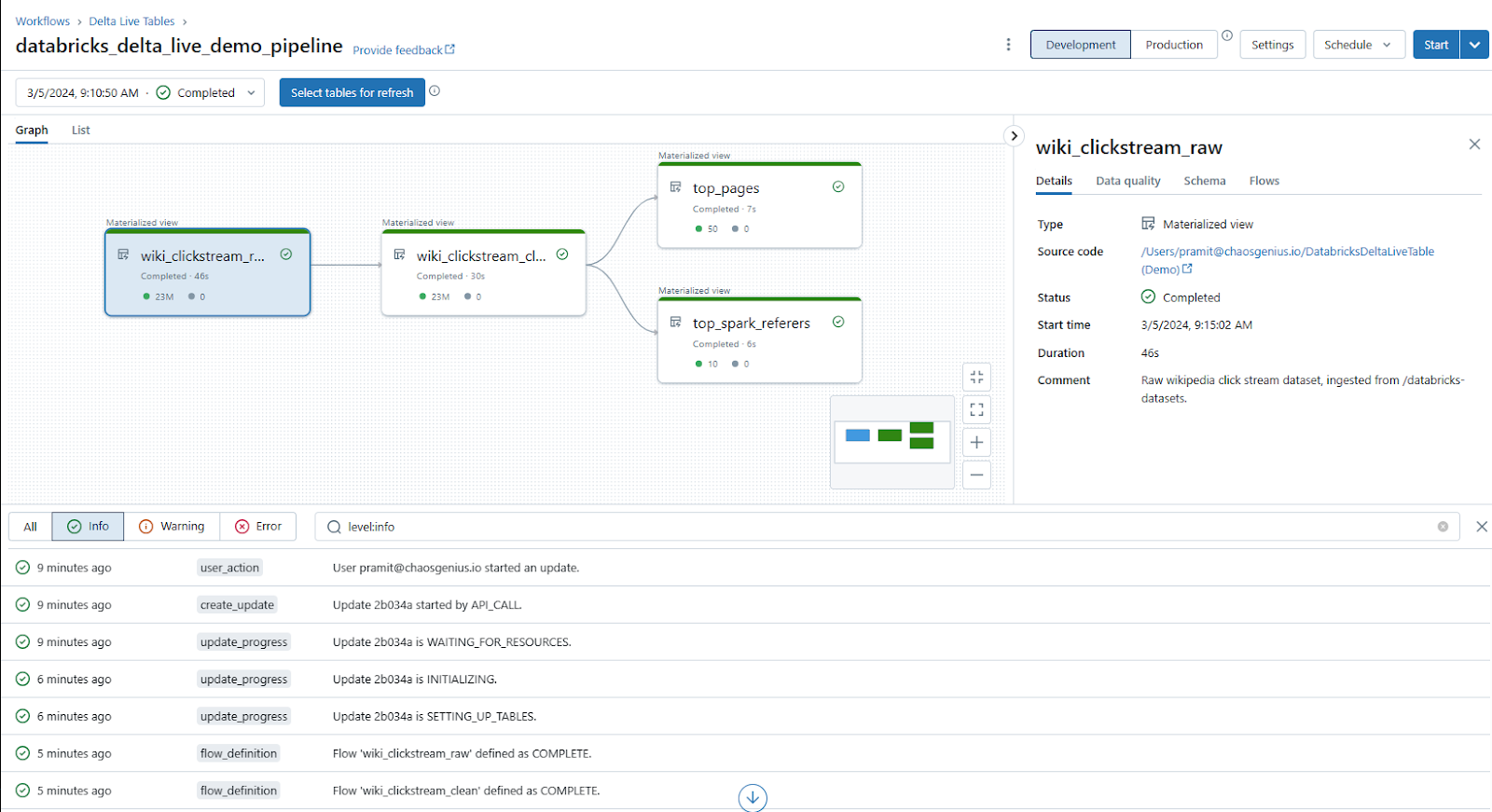
As you can see, The "Graph" section in the Delta Live Tables interface provides a visual representation of your pipeline through an interactive graph. This graph depicts the lineage and relationships between the various Delta Live Tables defined in your pipeline code.
- Each node in the graph represents a Delta Live Table, and the connections between nodes show how data flows from one table to another.
- Clicking on a node displays detailed information about that table, including its code definition, schema, data quality checks, and metrics such as record counts and data quality violations over time.
- The graph helps you understand the entire data journey, from the source data ingestion to the final output tables, and how the data is transformed at each step.
In the example pipeline, the graph shows the following tables:
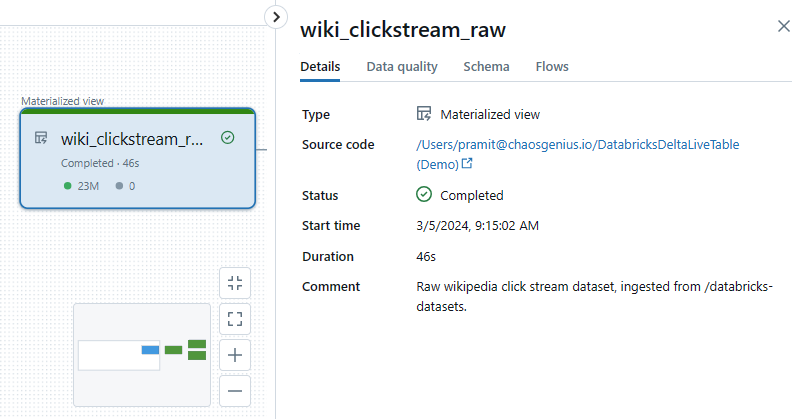
- The wiki_clickstream_raw table, which is the Bronze table ingesting the raw clickstream data containing around 23 million records.
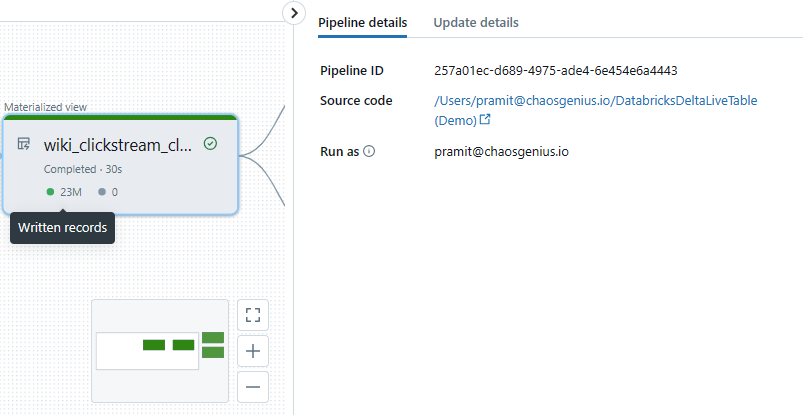
- The wiki_clickstream_clean table, which is the Silver table that cleans and transforms the raw Bronze data by applying type casting, column aliasing, and quality constraints. It maintains the same 23 million record count as the Bronze table.
Two Gold tables:
- The top_pages table, which contains the top 50 pages ordered by total click count.
- The top_spark_referers table, which lists the top 10 referrer pages.
If you have configured your pipeline to run in "Continuous" mode, and you insert a new record into the Bronze table (e.g., wiki_clickstream_raw), the pipeline will automatically trigger a new run after a few seconds. The new record you added will flow through each stage of the pipeline, undergoing the defined transformations and quality checks, until it is filtered and refined into the synchronized Gold tables (top_pages and top_spark_referers). But, if you have configured your pipeline to run in "Triggered" mode, you will need to manually trigger a new run of the pipeline after adding a new record to the Bronze table.
Databricks Delta Live Table visually lays out your entire Delta Live Tables pipeline in an interactive graph. At a glance, you can follow the whole data journey from source all the way through each transformation to the final output tables. Each step of the process is represented as a node, so you understand instantly how the data is flowing and changing at each stage. It's especially helpful to see metrics like record volumes right there, too. That way, you know how much data is being processed. But numbers only tell you so much, clicking on any node gives you even more context. Databricks pulls up all sorts of useful details for that specific table like the code used to define it, data quality checks over time, full schema info, and where each field originated from.
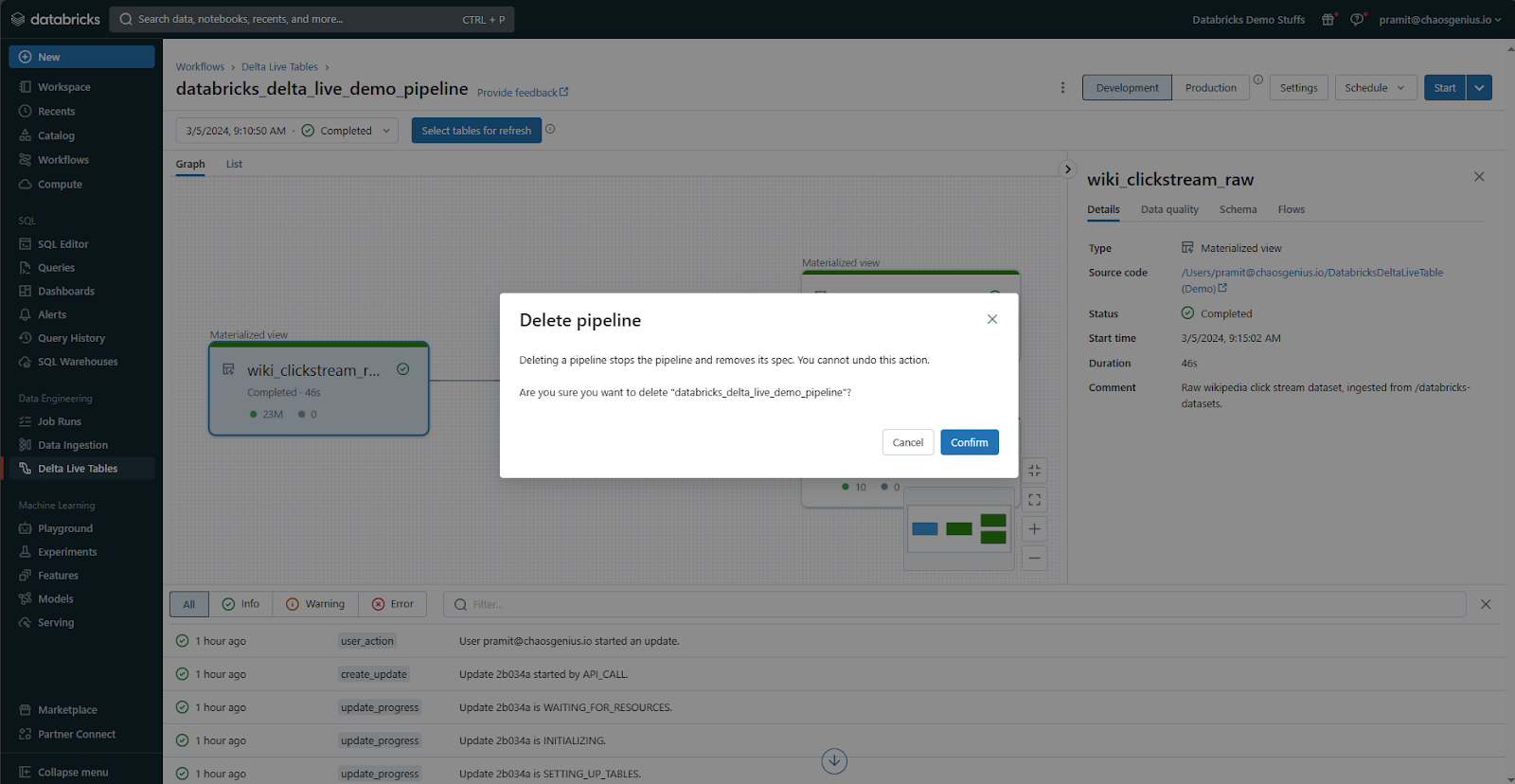
Step 10—Deleting Pipeline
When you no longer need a pipeline, you can delete it within the Delta Live Tables UI.
Click on the kebab menu and then select Delete to delete the pipeline. This will remove the pipeline definition and associated configuration settings.
Any Delta Tables populated by the pipeline will need to be manually deleted separately if required.
That’s it! This covers the end-to-end steps to create, run, monitor, and manage Delta Live Tables pipelines within Databricks. You can now leverage these pipelines to quickly build reliable data products.
Limitations and Challenges of Databricks Delta Live Tables
Compared to traditional ETL, Delta Live Tables offer a significantly easier method for building and executing data pipelines; however, there are a few drawbacks to be aware of:
1) Unidirectional Table Dependencies
Delta Live Tables only allow defining data dependencies in one direction between tables. Cyclical dependencies are not supported.
2) Schema Changes Require Full Reprocessing
While recent versions of Delta Live Tables support certain types of schema evolution, such as adding or dropping columns, and changing data types, more complex changes like renaming or reordering columns still require a full reprocessing of the data.
3) Tables Must Use Delta Format
All tables created and managed by Delta Live Tables are stored as Delta tables. Non-Delta sources need to be converted to Delta Lake format during ingestion.
4) Table Names within a Pipeline
A Delta Live Table with a given name can only be defined once within a single DLT pipeline definition.
5) Limited to 100 Concurrent Writes
The default workspace edition limits concurrent writes to 100 tables at a time to avoid resource overload. This limitation can be increased or removed in higher editions.
6) Constraints Cannot Span Multiple Rows
Table constraints are row-limited and cannot enforce complex relationships across multiple rows.
7) Limited Data Validation
While simple validation is possible via constraints, complex validation logic may still need to be custom-coded.
8) Requires Incremental Data Feeds
Databricks Delta Live Tables can handle full table scans, but it is generally recommended to use incremental data feeds (CDC or change data capture) for better performance.
9) Logic Limited to SQL and Python
Delta Live Tables currently supports defining pipeline logic using SQL, and Python. Other languages are not supported yet.
10) Tight Databricks Integration
The solution is optimized for Databricks and does not easily port outside it currently.
11) Scaling Limitations
Extremely high data volumes may require custom optimizations not provided out of the box.
12) Advanced Performance Tuning
DLT offers significant auto-optimization for extremely high-volume or highly complex workloads, but some custom Spark optimizations or fine-tuning of cluster configurations might still be required beyond DLT's automatic capabilities.
Delta Live Tables greatly simplify pipeline development, but have some constraints compared to custom coding. The abstractions save time but reduce flexibility in certain cases. Consider whether the time savings outweigh the potential limitations for your specific needs.
What Is the Difference Between Delta Table and Databricks Delta Live Table?
Here is a quick difference between Delta Table and Databricks Delta Live Table:
| Databricks Delta Table | Databricks Delta Live Table |
| Delta Table is a data format for efficient data operations and optimized for data lakes. | Databricks Delta Live Table is a declarative framework for building reliable, maintainable, and testable data processing pipelines. It manages data transformation based on defined queries for each processing step. |
| Suitable for data storage and efficient data operations | Designed for building and managing data pipelines, enforcing data quality, and handling complex data processing tasks |
| Delta lake is optimized for data lakes, with efficient data operations, support for ACID transactions, scalable metadata handling, and data versioning | Designed for efficient data processing, with auto-compaction and auto-optimization features improving query performance and reducing costs by removing old versions of tables |
| Manually have to load data | Runs on automated schedule |
| Data must be loaded in batches | Incrementally ingests and processes streaming data |
| Can be queried but not for streaming processing | Fully manages streaming execution pipelines declaratively |
Pros and Cons:
| Databricks Delta Table | Databricks Delta Live Table |
|
Pros:
|
Pros:
|
Cons:
|
Cons:
|
TL;DR: Delta Table and Delta Live Table are different concepts in Databricks, with Delta Table being a data format for efficient data operations and Delta Live Table being a declarative framework for building and managing data pipelines.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Conclusion
And that’s a wrap! Databricks Delta Live Tables simplifies building and managing complex data pipelines. You can define your ETL logic using Python or SQL without dealing with complicated custom code for infrastructure and orchestration. Delta Live Tables handle all the details like scheduling, dependencies, lineage, reliability, scaling, security, and more. That means you can concentrate on the actual data transformations and let Delta Live Tables handle the rest.
In this article, we have covered:
- What Are the Hurdles of Building Data Pipelines the Traditional Way?
- What is a Databricks Delta live table?
- What Is the Difference Between Delta Table and Databricks Delta Live Table??
- Step-by-step Guide to Create Databricks Delta Live Table using SQL
- Step-by-step Guide to Create Databricks Delta Live Table Pipeline
- Limitations and Challenges of Databricks Delta Live Tables
... and so much more!
FAQs
What is a Databricks Delta Live Table?
Databricks Delta Live Table is a declarative framework for building reliable, maintainable, and testable data processing pipelines using SQL or Python queries.
What are the three types of datasets that can be created using Databricks Delta Live Tables?
Streaming tables, Materialized views, and Views.
How does Delta Live Tables simplify data pipeline development?
It allows defining transformations using SQL/Python, automatically handling orchestration, scaling, monitoring, data quality, and error handling.
What is the difference between Delta Table and Delta Live Table?
Delta Table is a data format, while Delta Live Table is a framework for building and managing data pipelines.
Can you create a Databricks Delta Live Table using SQL?
Yes, using the CREATE OR REFRESH statement with STREAMING TABLE or LIVE TABLE keywords.
Can you create a Databricks Delta Live Table using Python?
Yes, using the @dlt.table decorator function.
Who should use Databricks Delta Live Tables?
Data engineers, data scientists, and data analysts who need to build and maintain reliable data processing pipelines.
Can Databricks Delta Live Tables handle both batch and streaming data?
Yes, it supports unified batch and stream processing.
How does Databricks Delta Live Tables handle data quality and reliability?
It allows defining expectations and constraints, handles records that fail expectations, and ensures exactly-once processing.
What is the Medallion Lakehouse Architecture, and how does it relate to Delta Live Tables?
It is a series of data layers (bronze, silver, gold) denoting data quality. Delta Live Tables are often used to implement this architecture.
How does Databricks Delta Live Tables handle pipeline orchestration and scaling?
It automatically manages task orchestration, cluster management, autoscaling, monitoring, and error handling.
Can you monitor and manage Databricks Delta Live Tables pipelines?
Yes, through the Delta Live Tables UI, which provides visual graphs, real-time monitoring, and pipeline management capabilities.
Can Databricks Delta Live Tables handle complex schema changes?
DLT supports schema evolution for additive changes and in CDC flows, but disruptive changes like renaming or reordering columns may require code updates and potentially a full refresh.
Are there any limitations on enforcing complex data validation rules across multiple rows in Databricks Delta Live Tables?
Yes, DLT expectations are primarily row-limited and cannot easily enforce complex multi-row relationships or aggregate conditions.
Is Databricks Delta Live Tables tightly integrated with Databricks?
Yes, it is optimized for Databricks and does not easily port outside it currently.
Can Databricks Delta Live Tables handle extremely high data volumes without custom optimizations?
No, extremely high data volumes may require custom optimizations not provided out of the box.















