




























Storing and managing data efficiently is crucial for big data processing and analytics. If you are working with large volumes of data on a platform like Databricks, having a robust, high-performance storage solution is essential. Databricks File System (DBFS) is designed specifically for this purpose. DBFS is a distributed file system integrated natively into a Databricks workspace and available on Databricks clusters. It acts as an abstraction layer on top of highly scalable object storage services, such as Amazon S3, Azure Blob Storage, Azure Data Lake Storage Gen2, or Google Cloud Storage.
In this article, we will delve deep into Databricks DBFS, exploring its key features, benefits, and common use cases. Also, we will provide a step-by-step guide for uploading, querying, and downloading files from DBFS. Finally, we'll wrap up by comparing DBFS with HDFS (Hadoop Distributed File System).
What is Databricks File System (DBFS)?
Databricks File System (DBFS) is a distributed file system that comes pre-configured with every Databricks workspace and is available on all Spark clusters. It enables storing and accessing data from notebooks and jobs, acting as the storage layer for Databricks.
Some key capabilities and use cases of Databricks DBFS are:
- Databricks DBFS provides a unified interface for accessing files stored in cloud object storage like S3, ADLS, and GCS.
- It offers high performance for workloads like ETL, machine learning, and ad-hoc analytics. Reads and writes are optimized for fast data access.
- It can handle various data formats like Parquet, Avro, JSON, TXT, ORC, CSV, and much more.
- DBFS supports various standard APIs, which means that you can use DBFS to interact with data using different languages, frameworks, and tools
- DBFS allows you to reliably share data, datasets, and models across different clusters. Access controls are in place for secure data sharing.
TL;DR: Databricks DBFS acts as a high-performance and reliable distributed file system tailored for Databricks. Its unified interface and optimization for cloud object storage makes it easy to leverage for various analytics use cases.
Now that we understand what Databricks DBFS is and its benefits, let's dive into understanding what the DBFS root is before we walk through the steps to upload and download files using DBFS.
What is the DBFS root?
DBFS root is the default file system location provisioned for a Databricks workspace when the workspace is created. It resides in the cloud storage account associated with the Databricks workspace.
Some users may refer to the DBFS root simply as "DBFS" or "the DBFS." However, DBFS is the distributed file system used by Databricks, while the DBFS root is a specific location in cloud object storage accessed through DBFS. DBFS has many uses beyond the DBFS root.
The DBFS root contains several default directories used for various actions in the Databricks workspace:
- /FileStore: The default location for data and libraries uploaded through the Databricks UI. Generated plots are also stored here.
- /databricks-datasets: Contains open source datasets provided by Databricks. These are used in tutorials and demos.
- /databricks-results: Stores result files downloaded from queries.
- /databricks/init: Contains legacy global init scripts. These should not be used anymore.
- /user/hive/warehouse: Where Databricks stores managed Hive tables defined in the Hive metastore by default.
Check out this documentation to learn more about DBFS root.
Which File Formats Does Databricks DBFS Support?
Databricks DBFS supports a wide variety of data file formats that are commonly used for big data analytics. Some of the major file formats supported by DBFS are:
- Parquet: Binary and columnar format that provides the best compression and performance on DBFS. Optimized for analytical queries.
- Avro: Binary and row-oriented format that provides language-neutral serialization. Supports schema evolution.
- JSON: Lightweight, text-based, and semi-structured data format that describes data using key-value pairs. Ideal for NoSQL data
- ORC: Similar to Parquet, offers good compression and performance. Particularly suited for Hive-based workloads.
- CSV: Text-based and simple format that represents tabular data using comma-separated values.
On top of that, DBFS also supports binary file formats like images, audio, PDFs, TXT etc. XML, SequenceFiles, and RCFiles can also be stored and processed.
Parquet is particularly optimized for performance on DBFS and Databricks, given its columnar nature. But DBFS offers flexibility to use both row and columnar formats based on specific use cases.
What are the Benefits of Using Databricks DBFS(Databricks File System)?
Databricks DBFS is a distributed file system that offers several benefits over other storage options:
- It provides a unified interface to access data from various cloud storage systems (S3, ADLS, GCS) without using different APIs.
- It is optimized specifically for Spark workloads, providing high performance for reads and writes from Spark jobs, notebooks, and other analytics processes.
- It simplifies interacting with cloud object storage using file/directory semantics.
- It can auto-scale to handle increasing data volumes without storage bottlenecks.
- It eases persisting files to cloud storage instead of interfacing directly from clusters.
- It allows storing initialization scripts, JARs, libraries, etc. to share across clusters.
- It supports multiple data formats (Parquet, JSON, CSV, etc.) as per the use case.
- It enables storing checkpoint files for model training with OSS deep learning libraries.
- It integrates with central access controls in Databricks for secure data access across users and clusters.
Now that we have covered the overall basics of what Databricks DBFS is, let's move on to the next section where we will show you how to upload files in Databricks using Databricks DBFS step by step.
Step-By-Step Guide to Uploading a File in Databricks Using Databricks DBFS
Now, in this section, we will show you how to upload a file in Databricks using DBFS and how to create and query tables from the uploaded file. We will use a CSV file as an example, but you can choose any other file format supported by DBFS.
Uploading data files into DBFS is straightforward. Here is a step-by-step guide:
Step 1—Enabling DBFS
First, we need to enable the Databricks DBFS file browser from the workspace settings in Databricks. This allows uploading files into DBFS from the UI.
To do so, follow these steps:
- Navigate to your Databricks workspace and click on the Admin Settings icon in the top right corner.
- Click on the Workspace settings tab.
- Scroll down to the Advanced section.
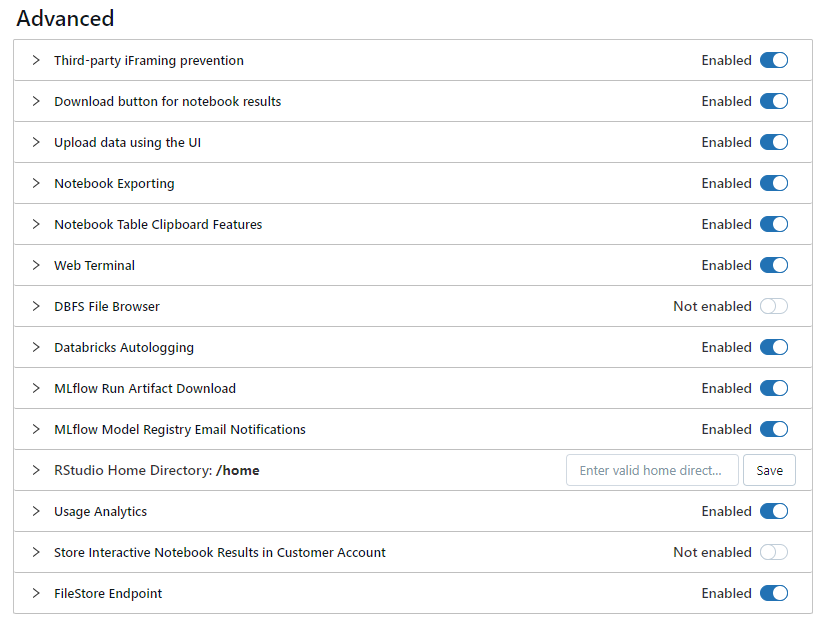
- Check the box next to Enable DBFS File Browser and then refresh the page for this change to take effect.

You should see a new tab called “DBFS” in the Catalog section, located next to Database tables.
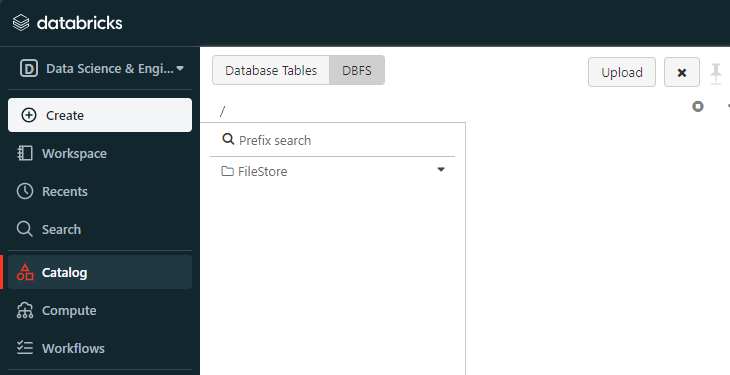
Step 2—Uploading Files to Databricks DBFS
Next, navigate to the DBFS tab in your Databricks workspace. Click on the "Upload" button and select the CSV or other file you want to upload from your local system.
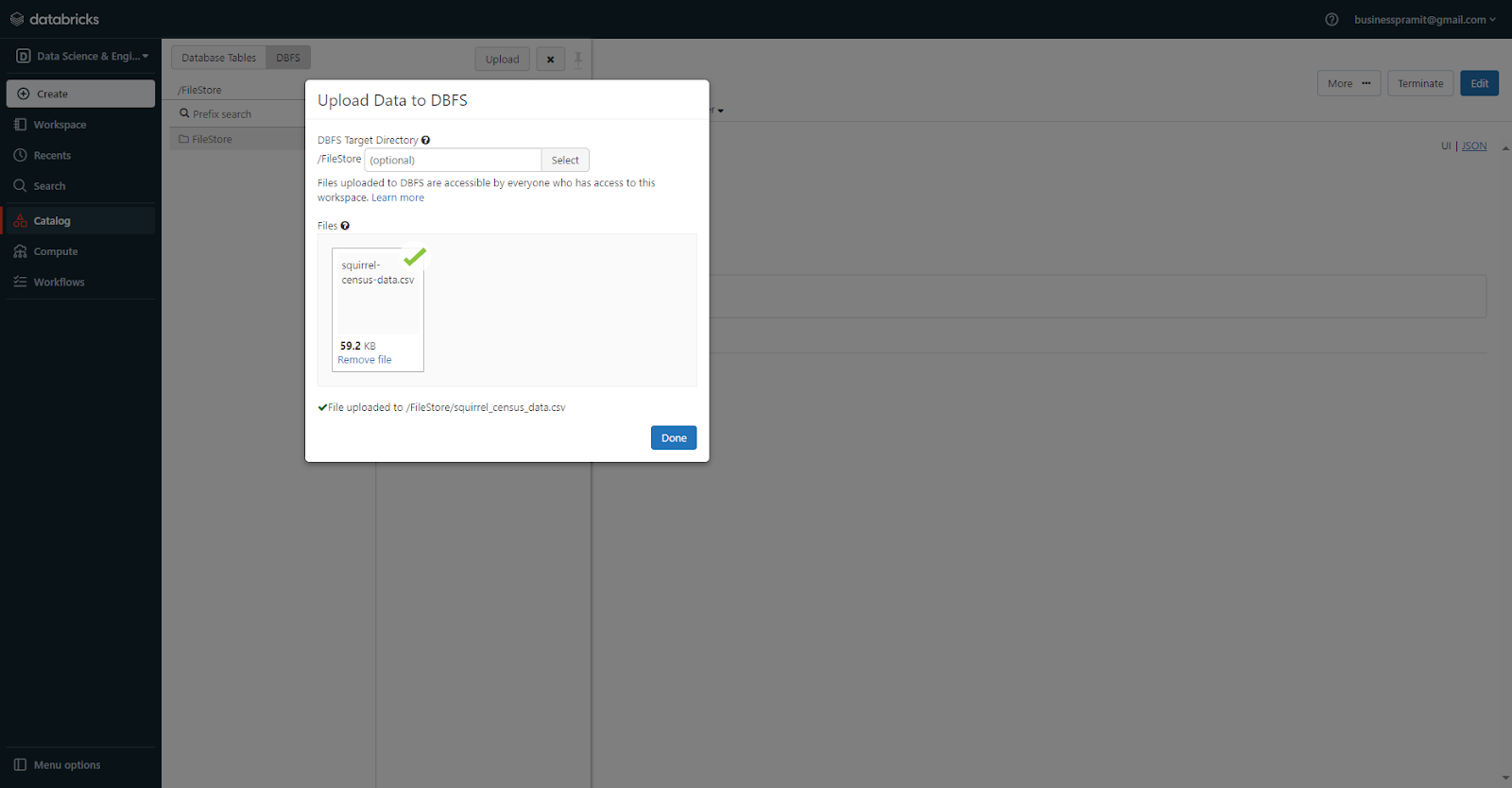
The file will get uploaded into the "/FileStore" folder in DBFS by default. You can create custom folders as well within DBFS using the UI.
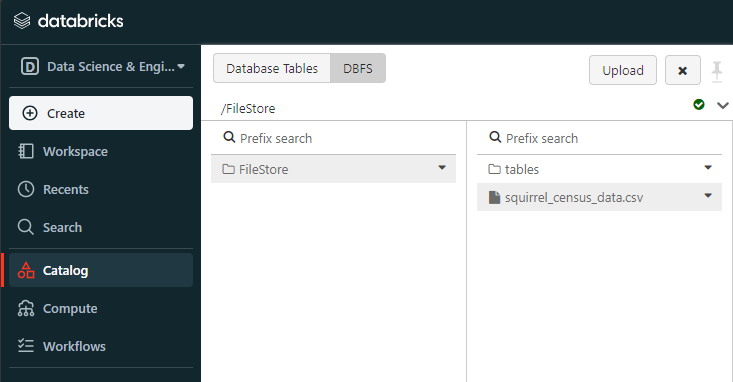
Step 3—Creating Tables from Uploaded Files
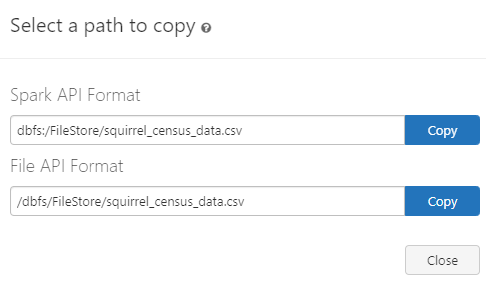
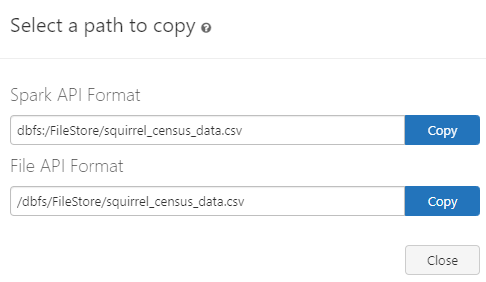
Once a file is uploaded, you can directly create a table or DataFrame in Databricks from it. To do so, head over to your Notebook and then create a DataFrame from the CSV file that you just loaded. To obtain the path of the CSV file you just loaded, all you have to do is double-click on the CSV file. You will get two options: one is Spark API Format, and the other one is File API Format. Copy the Spark API format and proceed to the next step.
Now, let's create a DataFrame from the CSV file using the following code:
df = spark.read.format("csv").option("header", "true").load("dbfs:/FileStore/squirrel_census_data.csv")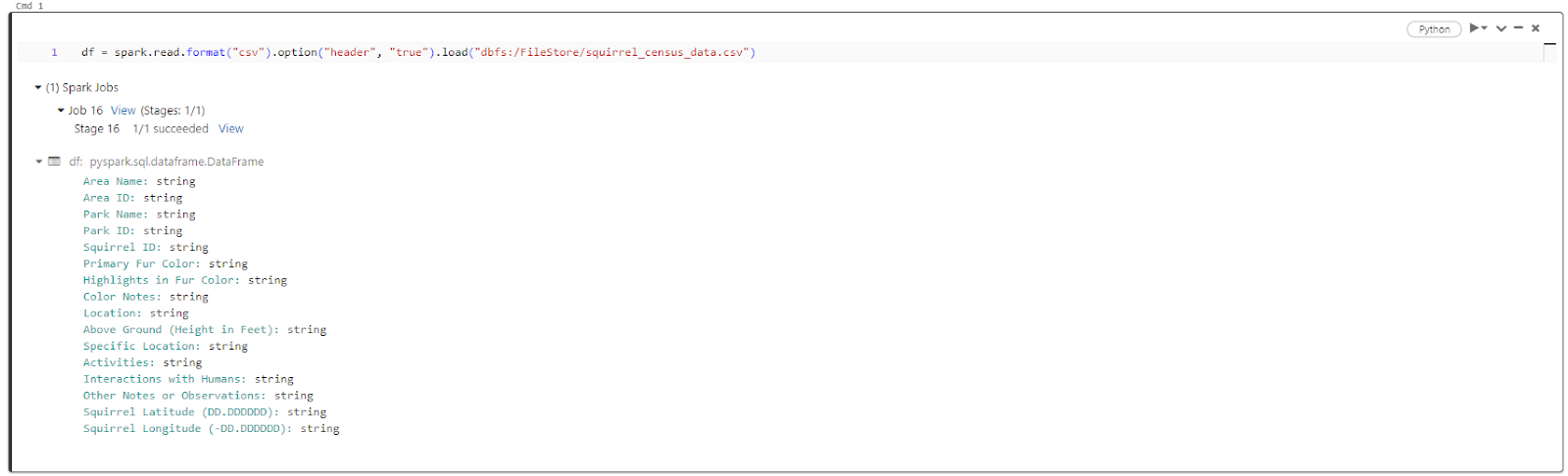
As you can see, this code reads the CSV file and loads its contents into the DataFrame named df. The option “header” is set to “true” to indicate that the first row of the CSV file contains column headers.
Next, let's create a temporary view from the DataFrame. Execute the code below:
df.createOrReplaceTempView("squirrel_census_data")
This code creates a temporary view named squirrel_census_data from the DataFrame."
Step 4—Querying/Accessing the Table
Finally, after you have created a table or view from the uploaded file, you can query and access the table using SQL or DataFrame APIs. To do so, follow these steps: navigate to the notebook where you created the table, add a new cell, and then proceed to write your query or code to access the table using SQL or DataFrame APIs. For instance, you can use the following code to display the first 20 rows of the table:
1) Displaying the first 20 rows of the table—using SQL
%sql
SELECT * FROM squirrel_census_data LIMIT 20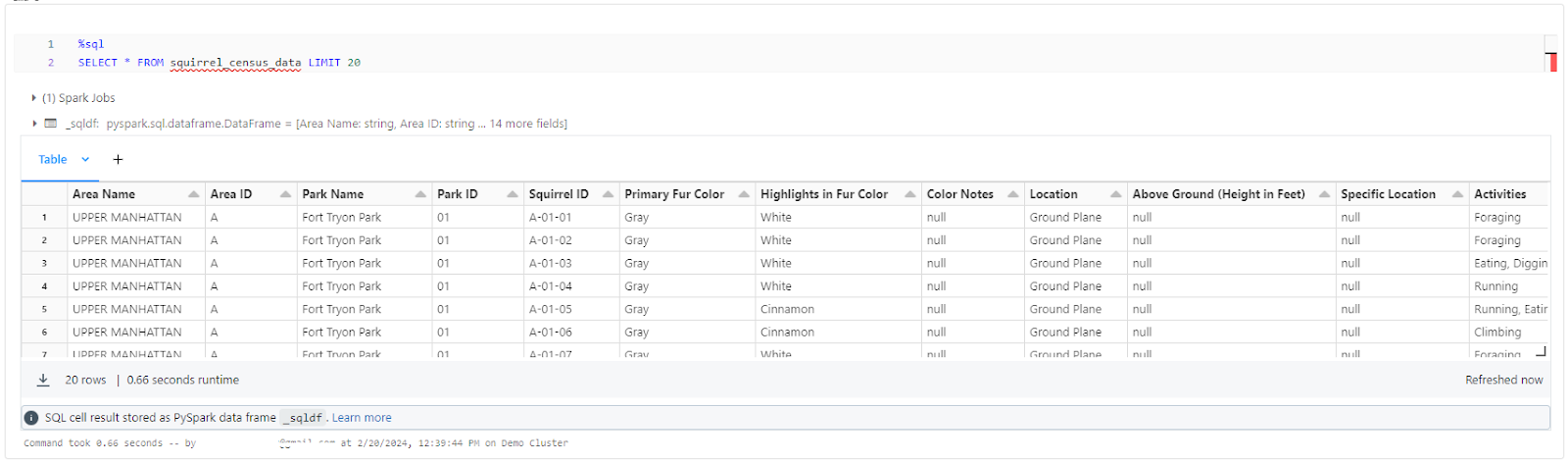
2) Displaying the first 10 rows of the table—using DataFrame API
display(df.limit(10))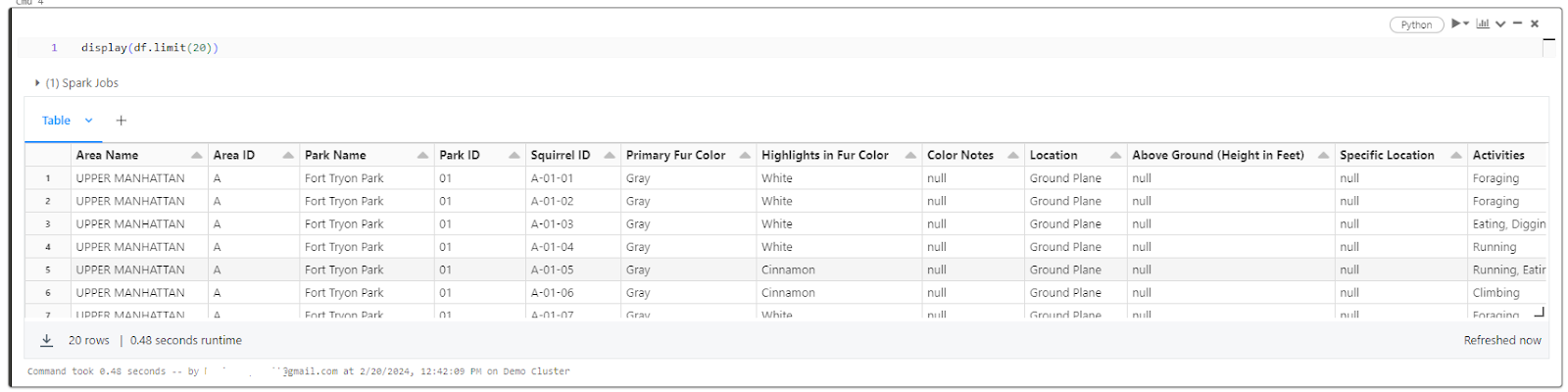
This demonstrates a simple workflow to ingest data into DBFS and make it available for analytics.
Now, let's proceed to the next section, where we'll guide you on downloading a file from Databricks DBFS.
Step-By-Step Guide to Downloading Files From Databricks DBFS
Databricks does not allow direct downloading of files from DBFS via the UI. But you need to use a web URL to access the file and download it. In this section, you will learn how to download a file from DBFS using a web URL, and what are the steps involved. Here is a step-by-step guide to do so:
Step 1—Get Databricks Instance URL
The very first step to download a file from DBFS is to get the Databricks instance URL, which is the base URL of your Databricks workspace, plus the o parameter with the tenant ID. The tenant ID is a unique identifier for your Databricks account, and it is required for authentication. To get the Databricks instance URL, follow these steps:
Navigate to your Databricks workspace and copy the URL from the browser address bar. The URL should look something like this: ”https://<region>.cloud.databricks.com/?o=<tenant-id>” or “https://community.cloud.databricks.com/?o=<tenant-id>” if you are using the community edition.

Note down the base URL and the o parameter with the tenant ID. The base URL is the part before the question mark, and the o parameter is the part after the question mark.
Step 2—Create Request to Databricks DBFS File URL
Now, to download a file from DBFS, you need to create a request to the DBFS file URL, which consists of the Databricks instance URL plus the file path. The file path represents the location of the file in DBFS and should start with /dbfs/FileStore/. To create a request to the DBFS file URL, follow these steps:
1) Find/Select File Path
Find the file path of the file that you want to download from DBFS. You can use the DBFS tab in your workspace or the DBFS APIs or commands to locate the file. For example, if the file is in:
/FileStore/squirrel_census_data.csvthen the file path is:
/dbfs/FileStore/squirrel_census_data.csv.Or,
Refer back to the previous section of the article and go to step 3, where we have shown you how to select the file path.
2) Replacing dbfs/FileStore/ with /files
Replace /dbfs/FileStore/ in the file path with /files/. This is because the /FileStore folder is a special folder that allows you to access files using web URLs, and the /files/ prefix is required for the web URL. For example, if the file path is:
/dbfs/FileStore/squirrel_census_data.csvthen the new file path is:
/files/squirrel_census_data.csv3) Append Databricks Base URL Before File Path
Append the Databricks base URL before the file path, and the o parameter after the file path. This will create the DBFS file URL, which is the complete web address of the file.
For example, if the base URL is:
https://community.cloud.databricks.com/The file path is /files/squirrel_census_data.csv, and the o parameter is o=1234567890123456.
Step 3—Access Databricks DBFS File URL
Finally, to download a file from DBFS is to access the DBFS file URL by pasting it to the browser and downloading the file. To access the DBFS file URL, follow these steps:
Paste the DBFS file URL to the browser address bar and press enter.
https://community.cloud.databricks.com/files/squirrel_census_data.csv?o=1234567890123456
You should see a prompt to download the file or open it with a compatible application. Now, choose the option to download the file and save it to your desired location.
That’s it! You have successfully downloaded a file from DBFS using a web URL. You can use the same method to download any other file from DBFS, as long as you have the Databricks instance URL and the file path.
What Are the Main Differences Between HDFS and Databricks DBFS?
HDFS and DBFS are both distributed file systems, but they have different architectures and storage backends. Here is the main difference between HDFS and Databricks DBFS:
|
Databricks DBFS (Databricks File System) |
HDFS (Hadoop Distributed File System) |
|
DBFS stores data in objects on cloud storage that are independent of the Databricks cluster, meaning that DBFS can scale and access data more easily and efficiently than HDFS, and also avoid data loss when the cluster is terminated |
HDFS stores data in blocks on local servers that are part of a Hadoop cluster. No separation of storage and compute. |
|
Databricks DBFS uses a serverless architecture, where cloud object storage (like S3, ADLS, or GCS), acts as the backend storage, and DBFS provides a unified and high-performance interface to access the data |
HDFS uses a master-slave architecture, where a NameNode manages the metadata and coordinates the access to the data, and multiple DataNodes store the data blocks across a cluster of nodes |
|
Databricks DBFS has unlimited scalability, as the cloud object storage can scale up or down as needed, and the Databricks clusters can be provisioned/terminated on demand |
HDFS has limited scalability, as the NameNode is a single point of failure and a bottleneck for the system, and adding more nodes to the cluster requires manual configuration |
|
Databricks DBFS has high performance for both sequential and random access, as well as updates, as it uses Databricks Delta to optimize the data access and modification |
HDFS has high performance for sequential reads and writes, as it stores data in large blocks and uses data locality to minimize network overhead. But HDFS has low performance for random access and updates, as it does not support transactions, indexing, or caching |
|
Databricks DBFS is compatible with various cloud platforms and services. Note that it cannot be used independently outside of Databricks. |
HDFS is compatible with Hadoop and its ecosystem, such as MapReduce, Hive, and Spark. |
|
Databricks DBFS has strong security features, such as encryption, authentication, and authorization, using SSL, IAM, and RBAC. |
HDFS has basic security features, such as authentication and authorization, using Kerberos and ACLs. |
|
Databricks DBFS is optimized for mixed workloads including ETL/batch jobs, interactive queries, data science workflows, etc on the Databricks platform. |
Its main intended workloads are batch jobs, analytics, etc. Not optimized for ad-hoc access and interactive use cases. |
|
Databricks DBFS provides APIs and direct access from Spark jobs/notebooks without needing to move data on/off the cluster. |
HDFS is primarily intended for storage, with the data needing to be moved on/off the cluster for processing rather than accessing directly from jobs/applications. |
Conclusion
And that's a wrap! Databricks DBFS provides a unified, high-performance, and scalable file system purposely built to supercharge analytics workflows on Databricks. From loading massive volumes of data, to efficiently processing files using Spark, to collaboratively sharing datasets across your teams—DBFS acts as the optimized system that powers end-to-end data journeys on the platform.
In this article, we have covered:
- What is Databricks File System (DBFS)?
- Which file formats does Databricks DBFS support?
- What are the Benefits of Using Databricks DBFS?
- Step-By-Step Guide to Upload/Download a File in Databricks Using Databricks DBFS
..and so much more!
FAQs
What is Databricks File System (DBFS)?
DBFS is a distributed file system integrated natively into Databricks workspaces. It provides a centralized system for storing and accessing data on Databricks clusters.
What does Databricks DBFS provide abstraction on?
DBFS provides an abstraction layer on top of highly scalable object storage services like Amazon S3, Azure Blob Storage, Google Cloud Storage etc.
Does Databricks DBFS support POSIX, REST and Hadoop APIs?
Yes, DBFS supports various standard APIs like POSIX, REST, and Hadoop-compatible APIs allowing interaction with data using different languages, frameworks, and tools.
Can Databricks DBFS scale to large data volumes?
Yes, as DBFS uses scalable cloud object storage in the backend, it can auto-scale to handle increasing data volumes without performance bottlenecks.
What are the major file formats supported by Databricks DBFS?
Major file formats supported are Parquet, Avro, JSON, ORC, and CSV as well as binary formats like images, audio, etc.
Which file format provides the best compression and performance on DBFS?
Parquet provides the best compression and performance on DBFS as it is optimized for analytic queries.
Can Databricks DBFS files be shared securely across users?
Yes, Databricks DBFS provides access controls for the secure sharing of files, datasets, and models across users and clusters.
How does Databricks DBFS improve data loading performance?
Databricks DBFS optimizes reads and writes for high performance during data loading from Spark jobs, notebooks, and other analytics processes.
How do I enable the Databricks DBFS file browser in the workspace?
You can enable the DBFS File Browser option under Advanced settings in the Admin section of the Workspace settings.
What are the main differences between DBFS and HDFS?
DBFS uses scalable cloud storage, and HDFS uses local servers. DBFS has better performance for random access while HDFS for sequential.
Can Databricks DBFS scale unlimitedly due to the cloud backend?
Yes, as DBFS uses elastic cloud object storage in the backend, it can scale up or down storage capacity unlimitedly on demand.
Are Databricks DBFS files encrypted for security?
Yes, Databricks DBFS provides security features like encryption of files at rest as well as authentication and authorization using IAM.
Can Databricks DBFS handle batch, interactive, and ML workflows?
Yes, Databricks DBFS is optimized to handle mixed workloads including ETL/batch, interactive queries, data science, etc on the Databricks platform.
Can Databricks DBFS files be accessed directly from Spark jobs?
Yes, Databricks DBFS allows direct access to files from Spark jobs and notebooks without needing to move data on/off clusters.
Is Databricks DBFS specific to Databricks or can it be used independently?
Databricks DBFS is designed specifically for and integrated within Databricks. It cannot be used independently outside of Databricks.
Is there a limit on the number or size of files that can be stored in Databricks DBFS?
No, as Databricks DBFS leverages scalable cloud storage in the backend, there are no inherent limits to the number or size of files that can be stored.
Can files be directly queried from Databricks DBFS-like tables?
While files in DBFS can be registered as tables to query, they themselves are not queryable like tables and require converting to a DataFrame/table format first.
Does Databricks DBFS support the archival of data to cold storage?
No, Databricks DBFS is designed for active data access and analytics. For archival to cold storage, files need to be externally moved out of the DBFS storage class.
Can multiple files be combined into a single file in Databricks DBFS?
No, it does not support operations to combine multiple source files into a single target file natively.















