





























Databricks was first founded in 2013 by the brilliant minds behind Apache Spark. Fast forward, and it's now a household name in data analytics. The founders—Ali Ghodsi, Andy Konwinski, Ion Stoica, Matei Zaharia, Patrick Wendell, Reynold Xin, and Arsalan Tavakoli-Shiraji—had a simple, yet powerful idea: make big data easy to handle. They took Apache Spark's potential and ran with it, building a platform that could tackle everything from data engineering to machine learning on a massive scale.
According to DB-Engines, Databricks is one of the most fastest-growing unified data analytics platforms. As you can see in the graph below, Databricks now ranks 15th with an overall score of 84.46 (as of August 2024).
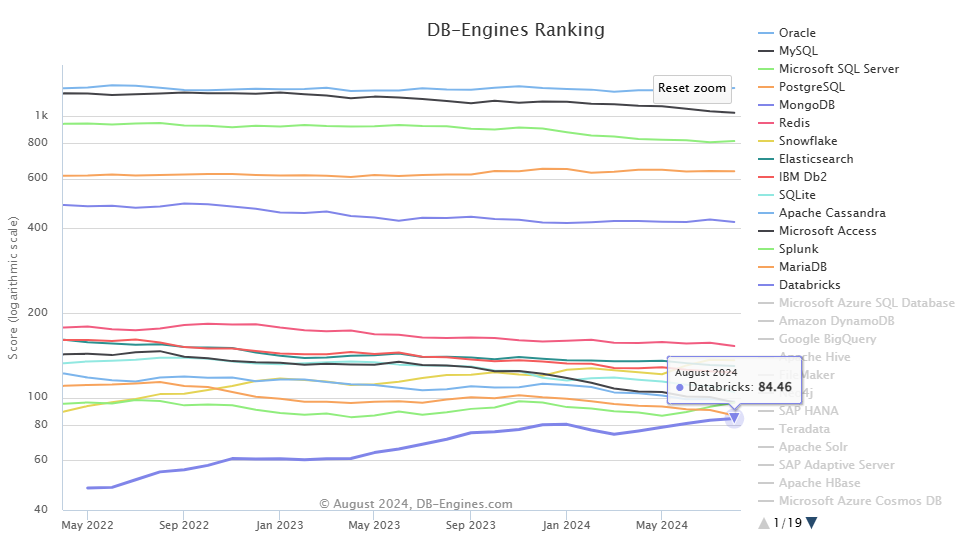
Here's how DB-Engine evaluates the ranking score: It analyzes Google Trends, checks technical experts' opinions, counts job postings, and tracks mentions on professional as well as social networks. It then crunches the numbers to create a fair, comparable popularity score.
Databricks' impressive technical accomplishments and rapid growth haven't flown under the radar. They even earned a spot as a Leader in the 2024 Gartner® Magic Quadrant™ for Data Science and Machine Learning Platforms. But here's the thing: the competition is super fierce. There are a bunch of other powerful players fighting to be the best. In this article, we're about to dig in and explore 13 Databricks competitors that could potentially go head-to-head with Databricks.
Save up to 50% on your Databricks spend in a few minutes!


Table of Contents
Top 13 Best Databricks Competitors—Which Will You Choose?
1) Snowflake
Snowflake is a top Databricks competitor—they're neck and neck when it comes to features and capabilities. So what is Snowflake? It's a cloud-based data warehouse platform that lets you store, process, and explore massive amounts of data. What sets it apart is its unique architecture, which gives businesses and organizations the scalability and flexibility they need to manage and analyze their data effectively.

Snowflake stands out with its architecture that keeps storage and compute separate. You can scale up or down without affecting the other. This helps you get the best performance while saving massive on cost.
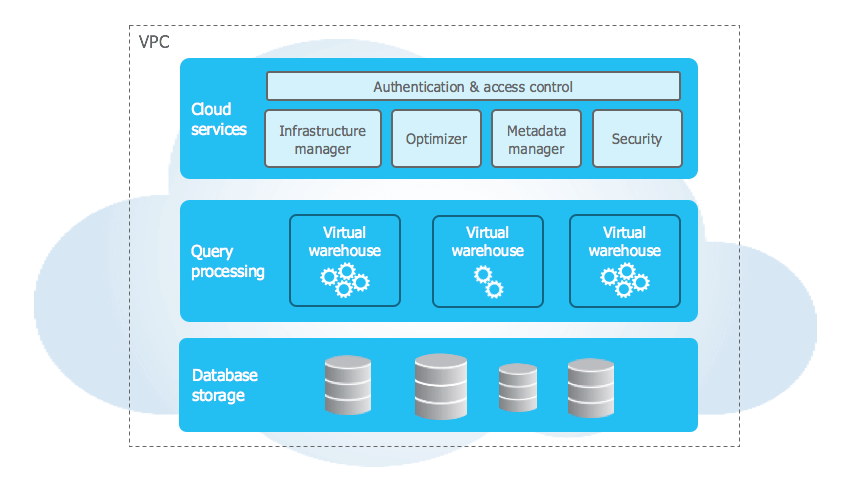
Snowflake is built for heavy analytics workloads. It uses columnar storage, clustering, caching, and optimizations to provide excellent performance on concurrent queries over structured as well as semi-structured data workloads.
Databricks Competitors - Databricks Alternatives
Pros and Cons of Snowflake
Pros of Snowflake:
- Easy to use with a user-friendly interface
- Cloud-native architecture providing instant elasticity and separation of storage and compute
- Excellent price-performance for analytics workloads
- Unique recovery features like zero-copy cloning and time travel
- Simplicity, scalability, and automatic performance optimization
- Perfect for organizations needing easy data management
- Strong support for data sharing and collaboration
Cons of Snowflake:
- Performance might drop on semi-structured data workloads compared to structured data
- Requires third-party integrations for advanced data engineering and data science capabilities compared to Databricks
- Technically more difficult to expand into AI/ML and data pipeline space
Databricks vs Snowflake—Which One Should You Opt For?
Here's how Databricks vs Snowflake compare. It really comes down to what you need. Both Databricks vs Snowflake are top cloud data platforms. Databricks started by focusing on data engineering and data science. It uses Apache Spark for big data processing workloads, MLflow for machine learning, and Delta Lake for a unified data lakehouse. Snowflake, on the other hand, set out to create a centralized cloud data warehouse for storing and accessing massive amounts of data.
Databricks excels in real-time data processing, advanced analytics, and machine learning workloads. It offers high processing capacity through Apache Spark and configurable clusters. But, it requires more technical expertise for effective configuration and optimization.
In contrast, Snowflake is perfect for teams that want easy data management and simplicity. It's also great at optimizing performance on its own. Plus, it works well with lots of data tools and is super easy to use.
🔮 TL;DR:, if you're stuck deciding between Databricks vs Snowflake? It all depends on what you and your organization need. If you're all about advanced analytics, AI/ML, and real-time data processing, Databricks is probably the way to go. On the other hand, if you want something easy to use, simple, and with automatic performance tweaks for analytics, Snowflake might be the better fit.
For a detailed comparison, please refer to the article on Databricks vs Snowflake.
Save up to 30% on your Snowflake spend in a few minutes!


2) Google BigQuery
Google BigQuery is another major Databricks competitor. It's a fully managed, serverless data warehouse that lets you run SQL queries on massive datasets without worrying about infrastructure. It was first launched in 2010, it's part of the Google Cloud Platform and excels at handling massive volumes of data efficiently. It's perfect for BI apps and ad-hoc queries, helping you analyze loads of data fast and cost-effectively.
Databricks Competitors - Databricks Alternatives
Here’s BigQuery’s architecture in a nutshell. It’s built on a few key components that make it serverless and scalable:
First up, BigQuery has the Dremel Execution Engine, which is the brain behind fast SQL query processing. It achieves this by spreading the workload across multiple servers.
Next, there’s the Colossus Storage System. This is where Google BigQuery stores and retrieves data, ensuring it’s always available and secure.
3) Borg
Then there’s Borg, Google’s cluster management system. It ensures resources are used efficiently across the infrastructure.
And don’t forget the Jupiter Network—BigQuery’s high-speed network that delivers data quickly.
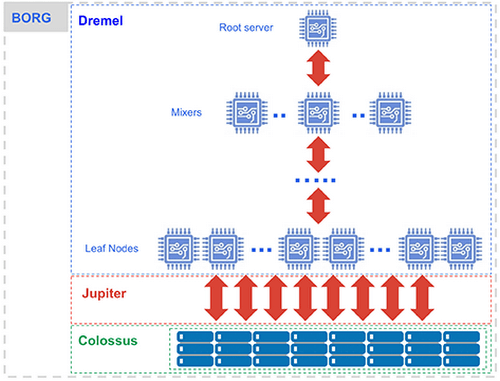
The beauty of Google BigQuery’s architecture is that it’s decoupled, meaning storage and compute resources operate separately, allowing users to scale storage and processing independently, cutting cost and improving performance.
For further details, take a look at this article on Google BigQuery Architecture.
Pros and Cons of Google BigQuery
Pros of Google BigQuery:
- Users don't have to deal with infrastructure, so you can focus on analyzing data instead of maintaining it
- BigQuery can handle massive amounts of data and automatically adjusts resources when needed
- Offers on-demand pricing based on data scanned, which can be economical for variable workloads
- Users can easily build and run machine learning models right in the data warehouse using SQL, thanks to BigQuery ML
- BigQuery works super smoothly with other Google Cloud services, making data analytics and processing a whole lot easier
Cons of Google BigQuery:
- Users have limited control over the underlying computing power, which can cause performance issues for some workloads
- Exporting data can be a real hassle due to some restrictions, making integration tasks more complicated
- Users might get hit with extra costs when moving data for scheduled queries and other tasks
Databricks vs BigQuery—Which One Should You Opt For?
So, if you're trying to decide between Databricks vs BigQuery? First, let's look at what they're good at and when to use them.
Databricks is perfect for heavy stuff like data engineering, ML, and real-time analytics. It handles structured and unstructured data and is great for anyone needing advanced analytics and data science capabilities. Plus, it's got a Lakehouse architecture that combines the best of data lakes and data warehouses.
BigQuery, on the other hand, is great when it comes to ad-hoc queries and business intelligence. It's perfect for anyone who needs to crunch massive volumes of data without having to worry about managing infrastructure. And most importantly, if you're already using Google Cloud services, BigQuery is a no-brainer.
🔮 So, which one should you opt for—Databricks vs BigQuery? If you're focused on data science, data engineering, machine learning, and real-time analytics, choose Databricks. If you want easy, large-scale data analysis—especially if you're already in the Google ecosystem—go with BigQuery.
3) Amazon Redshift
Amazon Redshift is a fully managed, petabyte-scale data warehousing service offered by Amazon Web Services (AWS). It is designed to handle complex analytical workloads efficiently by leveraging columnar storage and massively parallel processing (MPP) architecture.
Databricks Competitors - Databricks Alternatives - Databricks vs Redshift
Amazon Redshift's architecture is based on a cluster of nodes, which are responsible for data storage and processing. The architecture can be summarized in the following components:
- Leader Node: The leader node is responsible for coordinating the compute nodes and handling external communication. It parses and develops execution plans for database operations and distributes them to the compute nodes.
- Compute Nodes: These nodes execute the database operations and store the data. They get their instructions from the leader node and perform the required operations. Amazon Redshift provides two categories of nodes:
- Dense compute nodes: Optimized for heavy workloads with SSD storage.
- Dense storage nodes: Ideal for large datasets with HDD storage.
- Redshift Managed Storage (RMS): RMS is a separate storage tier that stores data in a scalable manner using Amazon S3 storage. It automatically uses super-fast SD-based local storage as a tier-1 cache and scales storage automatically to Amazon S3 when needed.
- Node Slices: Node slices are subdivisions within a compute node, each with its own allocation of memory and disk space. The leader node distributes data and queries across slices, enabling parallel processing. Queries are executed in parallel by the slices, with data partitioned across them to optimize performance.
- Internal Network: Amazon Redshift uses a private, high-speed network between the leader node and compute nodes.
- Databases: A cluster may contain one or more databases that store user data. The leader node coordinates queries and communicates with the compute nodes to retrieve data.
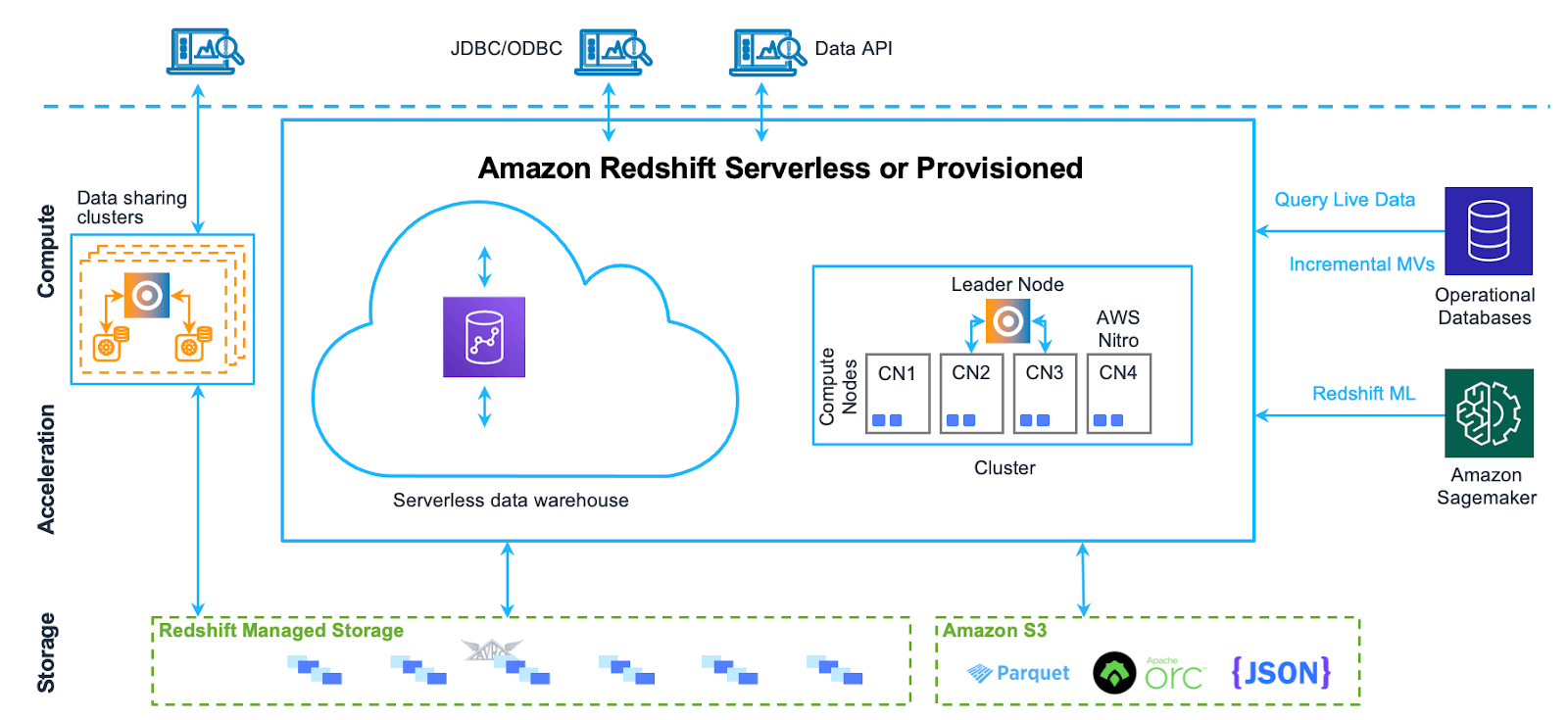
For further details, take a look at this article on Amazon Redshift Architecture.
Pros and Cons of Amazon RedShift
Pros of Amazon RedShift:
- High-performance query processing for large datasets
- Scalable data warehousing capabilities
- Relatively easy setup and management with automated provisioning
- Pay-as-you-go pricing model with no upfront costs
- Structured and centralized data for efficient data queries
Cons of Amazon RedShift:
- Limited SQL dialect compared to Databricks
- Data locked in proprietary disk format
- Vendor lock-in with AWS services
- Slow performance for some queries, especially with Redshift Spectrum
Databricks vs Redshift—Which One Should You Opt For?
Databricks vs Redshift are two popular data warehousing solutions, but they're pretty different.
Databricks is like an all-in-one data platform that can do a lot of stuff, like data engineering, analytics, and machine learning. It's powered by Apache Spark and supports multiple programming languages like Python, Scala, R, and SQL.
On the other hand, Amazon Redshift is perfect for SQL-based analytics and business intelligence applications. It's a great tool if you require a robust and scalable data warehouse, mainly for structured data analytics. And, since it integrates well with other AWS services, it's a no-brainer for those already in the AWS ecosystem.
🔮 Which one to choose: Databricks vs Redshift? The answer depends on the specific needs of you and your organization. If you're focused on advanced analytics, machine learning, and real-time data processing, Databricks is a great choice. However, if you require a powerful data warehouse for large-scale SQL-based analytics and business intelligence applications and are already invested in the AWS ecosystem, Amazon Redshift is the way to go.
4) Azure Synapse Analytics
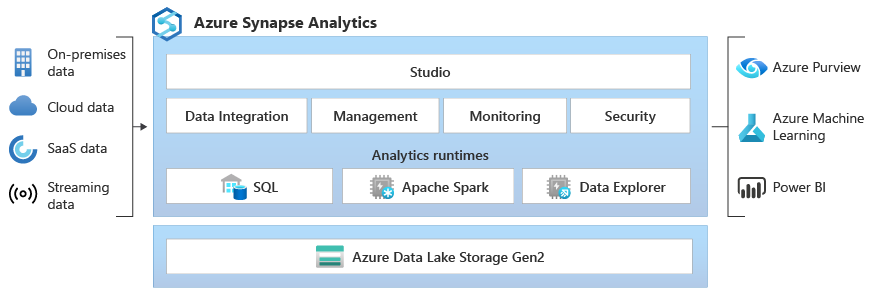
Azure Synapse Analytics is a limitless analytics service offered by Microsoft Azure that integrates big data and data warehousing capabilities into a unified platform. It enables organizations to analyze vast amounts of data through both serverless and provisioned resource models, effectively catering to various analytical workloads.
Synapse is designed to streamline the process of ingesting, preparing, managing, and serving data for business intelligence (BI) and machine learning (ML) applications.
Databricks Competitors - Databricks Alternatives - Azure Synapse vs Databricks
Azure Synapse uses a distributed query system for T-SQL that enables data warehousing and data virtualization scenarios. It offers both serverless and dedicated resource models. And it utilizes Azure Data Lake Storage Gen2 for scalable data storage. The service deeply integrates Apache Spark for big data processing, data preparation, data engineering, ETL, and machine learning.
Azure Synapse contains the same Data Integration engine as Azure Data Factory, allowing you to create rich at-scale ETL pipelines. The Synapse Studio provides a single workspace for data prep, data management, data exploration, enterprise data warehousing, big data, and AI tasks.
Pros and Cons of Azure Synapse Analytics
Pros of Azure Synapse Analytics:
- Unified platform for SQL, Spark, and data engineering
- Serverless and dedicated resource models
- Seamless integration with Azure Data Factory for ETL
- Unified experience with Synapse Studio
- Tight integration with other Azure services like Power BI and Azure Machine Learning
Cons of Azure Synapse Analytics:
- Vendor lock-in with Azure
- Potentially higher costs compared to some alternatives
- Performance can vary depending on the configuration and workload
- Complexity of managing a unified platform
- Users may face a steep learning curve due to the variety of tools and technologies integrated within Synapse.
Azure Synapse vs Databricks—Which One Should You Opt For?
So, you're trying to decide between Azure Synapse vs Databricks, two heavy-hitting analytics platforms. What's the difference?
Databricks is built on Apache Spark and makes it easy to run Spark workloads. It's amazing for data engineering, machine learning, and real-time analytics. If you need top-notch analytics and can handle both structured and unstructured data, Databricks is a great fit.
Azure Synapse Analytics, on the other hand, is a full-service analytics tool that combines SQL, Spark, data integration, and data exploration. It's perfect for SQL-based analytics, BI applications, and scenarios where you need to integrate with other Azure services. Plus, it's super familiar for SQL users and BI pros since it offers a full T-SQL experience.
🔮 Which one should you opt for—Azure Synapse vs Databricks? Consider your existing skills, data landscape, and required features. If you're focused on Spark and data science, Databricks might be the way to go. But if you need a comprehensive analytics solution that integrates data warehousing with big data—especially if your team is proficient in T-SQL and traditional BI tools, and you need to integrate with other Azure services—Azure Synapse is the better bet.
5) Apache Spark
Apache Spark is an open source, distributed computing system designed for fast processing of large-scale data, well-suited for big data workloads, and can handle both batch and real-time analytics. Spark is known for its speed, ease of use, and versatility, making it a popular choice among data engineers and data scientists.
Databricks Competitors - Databricks Alternatives
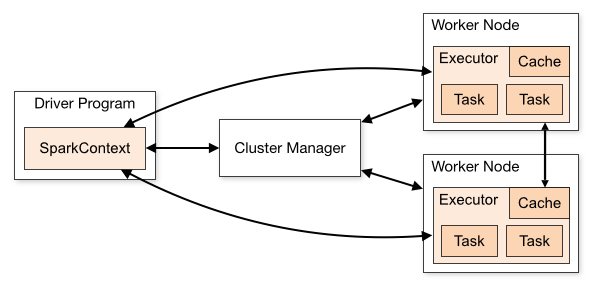
Apache Spark uses a master-slave architecture, which consists of:
First, you have the Driver Program. This is the brain of the operation. It's in charge of making sure tasks get done, and it turns your program into smaller tasks that can be handled by the system.
Next, there's the Cluster Manager. This component is in charge of resources across the cluster. It decides how to divvy up resources between the driver and executor nodes.
Lastly, you have Executor Nodes. These are the worker bees that actually do the tasks the driver assigns. Each executor runs in its own JVM and is responsible for executing the tasks and storing data for the application.
The core abstraction in Spark is the Resilient Distributed Dataset (RDD), which allows data to be distributed across the cluster while providing fault tolerance. Spark also supports Directed Acyclic Graphs (DAG) for representing the execution plan of jobs, which optimizes the execution process.
Key Features of Apache Spark:
- Apache Spark processes data in-memory, which significantly speeds up data processing compared to traditional disk-based processing systems.
- Apache Spark supports multiple programming languages, including Java, Scala, Python, and R, making it accessible to a wide range of developers.
- Apache Spark provides a unified framework for various data processing tasks, like batch processing, stream processing, machine learning, and graph processing.
- RDDs are designed to be resilient, meaning that if a node fails, Apache Spark can recompute lost data using lineage information.
- Apache Spark includes libraries for SQL queries (Spark SQL), machine learning (MLlib), graph processing (GraphX), and stream processing (Spark Streaming).
🔮 Databricks Uses Spark Under the Hood
Databricks is built on top of Apache Spark and leverages its capabilities to provide a unified analytics platform. It adds features to Spark. They include collaborative notebooks, integrated workflows, and better performance for big data workloads. Databricks uses Spark under the hood. This lets users harness its power. But, it simplifies managing a Spark cluster. It helps data teams do data engineering, data science, and machine learning tasks more efficiently.
6) Amazon EMR (Elastic MapReduce)
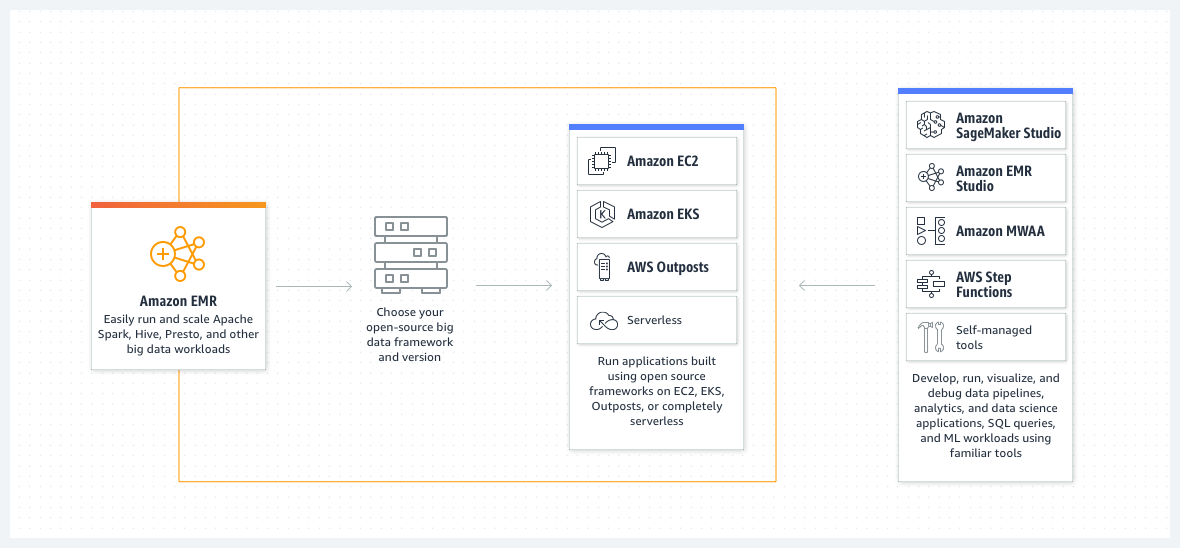
Amazon EMR (Elastic MapReduce) is a managed cluster platform that simplifies running big data frameworks, such as Apache Spark, Apache Hadoop, Apache Hive, Apache HBase, Apache Flink, and Presto. It allows users to quickly and cost-effectively process vast amounts of data by automating time-consuming tasks like provisioning capacity and tuning clusters. EMR integrates seamlessly with other AWS services, making it a popular choice for businesses already using the AWS ecosystem.
Databricks Competitors - Databricks Alternatives - Databricks vs EMR
Amazon EMR architecture consists of several layers:
This layer manages the different file systems used within the EMR cluster. The main storage options include:
- Hadoop Distributed File System (HDFS): A distributed file system that stores data across multiple instances, ensuring redundancy and fault tolerance. Data in HDFS is ephemeral, meaning it is lost when the cluster is terminated.
- EMR File System (EMRFS): This extends Hadoop's capabilities by allowing direct access to data stored in Amazon S3 as if it were in HDFS. Typically, input and output data are stored in S3, while intermediate results are kept in HDFS.
- Local File System: Each EC2 instance in the cluster has a local disk, which retains data only while the instance is running.
This layer is responsible for executing data processing tasks. Amazon EMR supports several frameworks, which includes:
- Apache Hadoop MapReduce: A programming model for processing large data sets.
- Apache Spark: A fast, in-memory data processing engine that supports batch and stream processing.
3) Cluster Resource Management Layer
This layer oversees resource allocation and job scheduling. Amazon EMR uses YARN (Yet Another Resource Negotiator) to manage resources across various data processing frameworks. YARN guarantees that resources are efficiently distributed and that jobs are scheduled without interruption, even when using Spot Instances.
Key Features of Amazon EMR
- Amazon EMR supports a wide range of open source tools beyond just Apache Spark, including Apache Spark, Apache Hadoop, Apache Hive, Apache HBase, Apache Flink, and Presto.
- Amazon EMR integrates with other AWS services like Amazon EC2, S3, and more.
- Amazon EMR can easily scale up or down based on the workload, making it suitable for processing large datasets.
- Amazon EMR offers a pay-as-you-go pricing model, making it economical for organizations with variable workloads.
- Amazon EMR is a fully managed service, reducing the overhead of setting up and maintaining the underlying infrastructure.
Databricks vs EMR—Which One Should You Opt For?
When you're choosing between Databricks vs EMR, think about what each does best.
Databricks helps data engineers and scientists work together. It leverages Apache Spark's power. It's got an easy-to-use interface with cool features like interactive notebooks for digging into data, making it perfect for machine learning and advanced analytics.
Amazon EMR is a more flexible big data processing platform that goes beyond Spark. It's great for anyone who wants to pick their own processing tools and are already invested in the AWS ecosystem.
🔮 Therefore, if you're all about Spark-based analytics and teaming up on data science projects, Databricks might be the way to go. But if you need a platform that can handle multiple big data processing frameworks and plays nice with other AWS services, Amazon EMR could be a better fit for you.
7) Google Cloud Dataproc
Google Cloud Dataproc is a fully managed cloud service designed to run Apache Hadoop and Apache Spark clusters. It allows organizations to leverage open source data processing tools for batch processing, querying, streaming, and machine learning, all while simplifying the management of these resources. Dataproc automates cluster creation and management, enabling users to focus on their data processing tasks rather than the underlying infrastructure.
Databricks Competitors - Databricks Alternatives - Dataproc vs Databricks
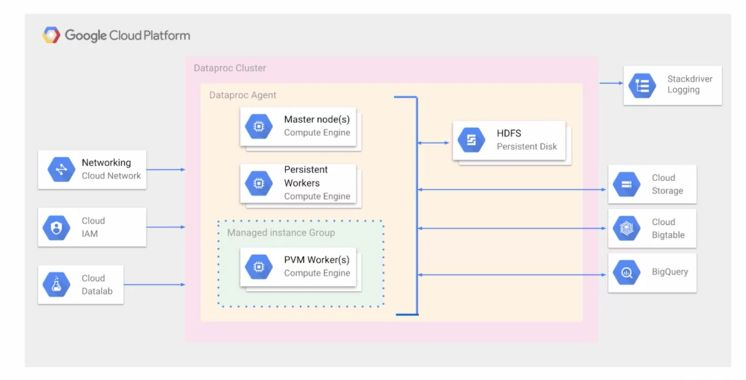
Google Cloud Dataproc's architecture consists of several key components:
1) Clusters
Google Cloud Dataproc operates on clusters, which are groups of virtual machines (VMs) that run Hadoop or Spark jobs. Users can create, manage, and delete clusters as needed. Clusters can be configured with various machine types and sizes to suit different workloads.
A Google Cloud Dataproc cluster consists of:
- Master Node: The master node manages the cluster, handling resource allocation, job scheduling, and overall management of the cluster. It runs services like the ResourceManager (in YARN) or Master (in Spark) and is responsible for coordinating distributed processing tasks.
- Worker Nodes: These nodes execute the actual data processing tasks. Depending on the workload, a cluster can be scaled horizontally by adding or removing worker nodes. Dataproc supports using preemptible VMs to reduce costs for transient workloads.
2) Storage
Google Cloud Dataproc utilizes Google Cloud Storage (GCS) for data storage, which decouples the storage from the compute cluster. This means data can persist independently of the compute cluster's life cycle, allowing clusters to be created and destroyed without data loss. GCS provides a highly durable and scalable storage solution.
3) Job Submission and Management
Users interact with Google Cloud Dataproc through Google Cloud Console, gcloud CLI, or REST APIs. Jobs can be submitted using various engines like Apache Spark, Apache Hadoop, Apache Hive, or Apache Pig. Dataproc manages the lifecycle of these jobs, from submission to completion, including monitoring and logging through integrated tools like Stackdriver (it's now part of Google Cloud's Operations suite).
4) Initialization Actions
During cluster creation, initialization actions can be used to install and configure custom software, setting up the environment before jobs are executed.
5) Integration with Google Cloud Services
Google Cloud Dataproc integrates seamlessly with other Google Cloud services, such as BigQuery for interactive analytics, Bigtable for low-latency data access, and Pub/Sub for real-time data ingestion. These integrations enable comprehensive data processing pipelines.
For more details, see Google Cloud Dataproc documentation.
Key Features of Google Cloud Dataproc:
- Google Cloud Dataproc is a fully managed service. It reduces the work of setting up and maintaining the underlying infrastructure.
- Google Cloud Dataproc can easily scale up or down based on the workload.
- Google Cloud Dataproc offers a pay-as-you-go pricing model.
- Rapid cluster creation, scaling, and shutdown within 90 seconds.
- Google Cloud Dataproc seamlessly integrates with Google Cloud services. These include BigQuery, Cloud Storage, Cloud Bigtable, Cloud Logging, and Cloud Monitoring.
- Simplified cluster management without administrative overhead.
- Users can customize the software stack, configure clusters, and submit jobs. They can do this using the Google Cloud Console, API, or command-line interface.
Dataproc vs Databricks—Which One Should You Opt For?
Google Cloud Dataproc vs Databricks—they're both powerful, but they're built to handle different jobs.
If you're already using or familiar with the Google Cloud ecosystem, Google Cloud Dataproc is a great choice. It lets you use your existing infrastructure for big data processing, which can help you save massive costs. It's perfect for batch processing and SQL analytics workloads.
Databricks, on the other hand, is all about data engineering, machine learning, and real-time analytics. It's great for anyone who needs to work with all kinds of data and wants advanced analytics capabilities.
🔮 So, Which one to choose? Welp! It all depends on what you need.
If your focus is on leveraging Google Cloud's ecosystem and running Apache Spark and Hadoop workloads in a cost-effective and managed environment, Dataproc may be the better choice.
But if you need advanced analytics, machine learning, and real-time data processing, and you want a platform that can handle all kinds of data, Databricks could be the better choice.
8) IBM Cloud Pak for Data
IBM Cloud Pak for Data is a fully integrated data and AI platform designed to modernize the processes of collecting, organizing, and analyzing data while seamlessly integrating artificial intelligence (AI) capabilities.
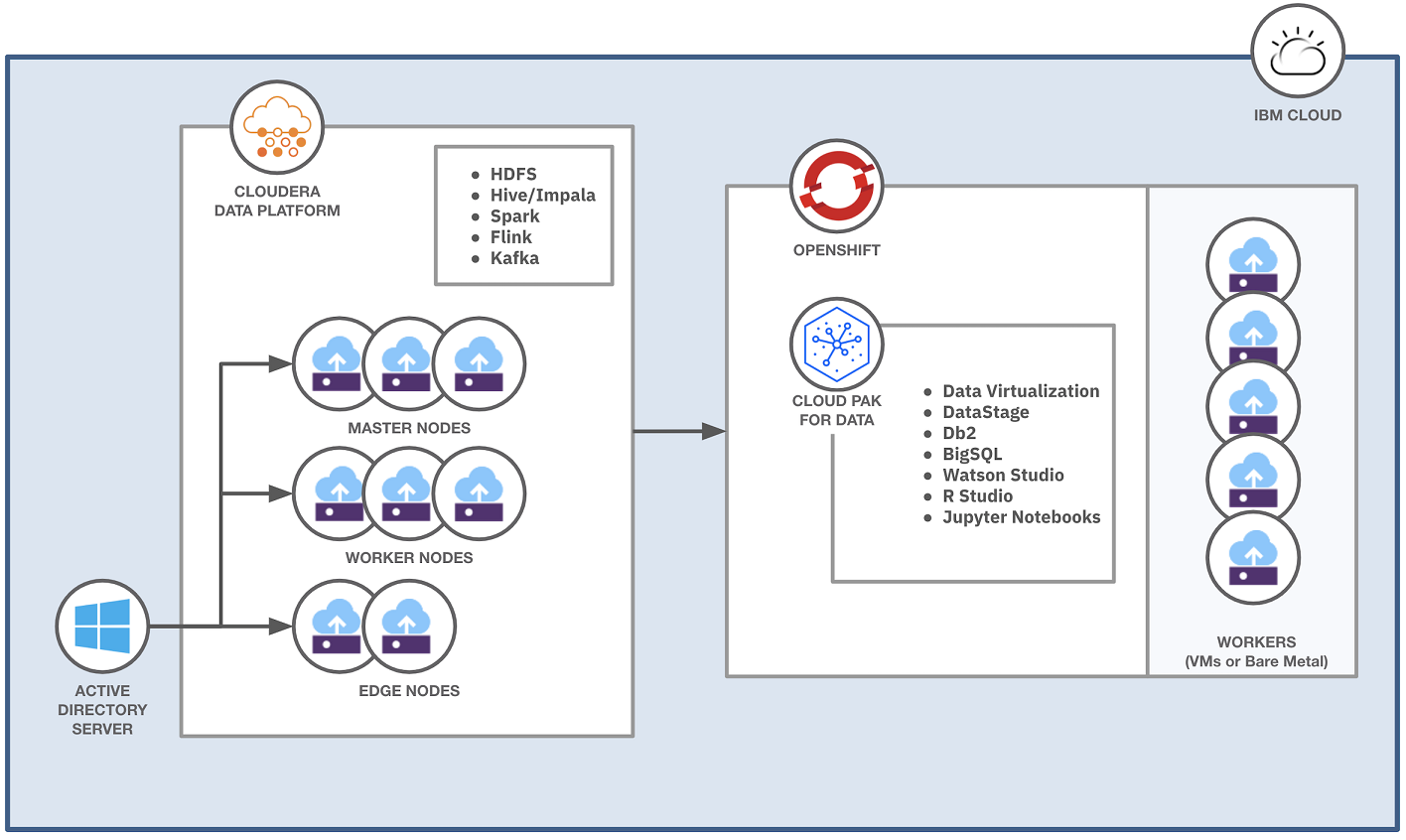
Based on Red Hat® OpenShift® Container Platform, IBM Cloud Pak for Data integrates IBM Watson® AI technology with IBM Hybrid Data Management Platform, enabling organizations to manage their data operations effectively. The platform also encompasses DataOps, governance, and business analytics technologies, providing a cohesive framework that supports the entire data lifecycle.
Databricks Competitors - Databricks Alternatives
IBM Cloud Pak for Data is a modular platform designed to run integrated data and AI services on a cloud-native architecture. It operates on a multi-node Red Hat OpenShift cluster, leveraging Kubernetes for container management. The architecture of IBM Cloud Pak for Data is built around the following key components:
1) Cloud-Native Design
IBM Cloud Pak for Data integrates multiple data and AI services to streamline IT operations, reduce costs, and enhance scalability. It supports modern DevOps practices while allowing efficient resource management.
2) OpenShift Integration
The platform runs on Red Hat OpenShift, which can be deployed on-premises, in a private cloud, or on any public cloud supporting OpenShift. OpenShift’s Kubernetes cluster is utilized for container orchestration.
3) Cluster Architecture
Deployed on a multi-node cluster, with a typical production setup including at least three control plane nodes and three or more worker nodes.
4) Modular Platform
IBM Cloud Pak for Data platform is modular, consisting of a lightweight control plane that provides essential interfaces and a services catalog. The control plane is installed per project (namespace), enabling interaction with deployed services.
5) Common Core Services
These are shared services that provide essential features like data source connections, job management, and project management. They are installed once per project and utilized by any service requiring them.
6) Integrated Data and AI Services
IBM Cloud Pak for Data offers a diverse catalog of services, including AI, analytics, data governance, and more. Users can select and install services based on their needs, ensuring that sufficient resources are allocated for expected workloads.
Pros and Cons of IBM Cloud Pak for Data
Pros of IBM Cloud Pak for Data:
- Integrates data across multiple clouds, offering robust AI analytics for faster insights
- Highly flexible, with strong security features suitable for various deployment options
- Supports AI-driven insights, which can accelerate data exploration and analysis
- Streamlines digital shifts, enhancing operational efficiency through automation
Cons of IBM Cloud Pak for Data:
- Steep learning curve due to the platform’s extensive features
- High setup and maintenance costs, particularly for customized deployments
- Customer support can be slow and less effective
IBM Cloud Pak for Data vs Databricks—Which One Should You Opt For?
If you're trying to decide between IBM Cloud Pak for Data vs Databricks. Here is what you need to know.
IBM Cloud Pak for Data is very good at handling data governance, AI integration, and managing data from start to finish in hybrid cloud environments. If you're a big enterprise that needs serious AI power and strict data governance, especially in industries with lots of rules/regulations, this is the way to go.
Databricks, on the other hand, is best when it comes to processing massive amounts of data, doing analytics in real-time, and machine learning. It uses Apache Spark to handle scalable data processing like a pro. If your thing is advanced analytics and real-time data pipelines, Databricks is your best bet.
🔮 So, do you need help with overall data management and governance in a hybrid cloud setup? IBM Cloud Pak for Data is your right choice. Or do you need real-time analytics, scalability, and machine learning? Then Databricks is the way to go.
9) Dremio
Dremio is an innovative data platform that simplifies data access and analytics by providing a unified interface for querying data across various sources. It is often referred to as an "open lakehouse" due to its ability to combine the capabilities of data lakes and data warehouses. Dremio allows users to perform self-service analytics on data stored in cloud object storage and other systems without needing to Extract, Load and Transform the data into a separate warehouse.

Key Features of Dremio:
- Dremio connects to multiple data sources seamlessly.
- Dremio utilizes Data Reflections and Apache Arrow for optimized query performance.
- Dremio supports community-driven standards such as Apache Parquet, Apache Iceberg, and Apache Arrow so there is no proprietary format or lock-in.
- Dremio offers a user-friendly data catalog for efficient data discovery and self-service.
- Dremio integrates with Apache Ranger for fine-grained access control and secure data access.
- Dremio supports flexible deployment on-premises or in the cloud, with options for elastic scaling using Kubernetes.
- Dremio allows for optimized resource allocation across various workloads and users, enhancing performance and efficiency.
- Dremio has native connectors for various data sources, including AWS S3, Azure Data Lake, and relational databases.
Pros and Cons of Dremio
Pros of Dremio:
- Dremio is praised for its user-friendly interface, making it accessible even to non-technical users.
- Dremio's ability to perform high-speed queries directly on data lakes is a significant advantage, reducing latency and improving data accessibility.
- Dremio can dramatically cut infrastructure and operational costs by eliminating the requirement for ETL operations and querying data in place.
Cons of Dremio:
- Despite its user-friendly interface, some users find Dremio challenging to master due to the depth of its features.
- Dremio has limitations in handling certain data types, which might require workarounds or additional tools.
- Dremio can be resource-intensive when working with huge datasets, necessitating significant compute power to maintain performance.
Dremio vs Databricks—Which One Should You Opt For?
Dremio vs Databricks. Both of em’ are top players in the data lakehouse game, but they're suited for different things.
What do you need? Databricks excels for teams focused on both data engineering and data science, with robust capabilities in machine learning and real-time processing. Conversely, Dremio simplifies data access for analytics teams, making it ideal for business intelligence (BI) and reporting.
Speed? Both platforms offer impressive speed, but Databricks provides greater flexibility, handling everything from AI to machine learning. Dremio shines in optimizing SQL queries on data lakes, making it a strong choice for enterprises that prioritize rapid data analytics.
Growing pains? Databricks is well-suited for scaling across clouds, essential for complex, multi-cloud environments. Dremio also scales effectively, particularly when querying data in place without the need to move it.
Cost? Dremio's cost efficiency is due to its ability to minimize ETL processes and directly query data lakes, which can result in significant savings. Databricks may be more expensive, especially if utilizing its full range of Data Engineering and AI features.
🔮 So, which one to choose? It depends on what you and your organization need. If you want a platform that can handle machine learning and data science, Databricks is the way to go. But if you need fast, self-service analytics on cloud data lakes with minimal data movement, Dremio might be the better fit.
10) Talend Data Fabric
Talend Data Fabric is a powerful platform designed to streamline data integration, management, and sharing across an enterprise. It offers a comprehensive suite of tools and capabilities to address various data challenges, from data quality and governance to API development and application integration.
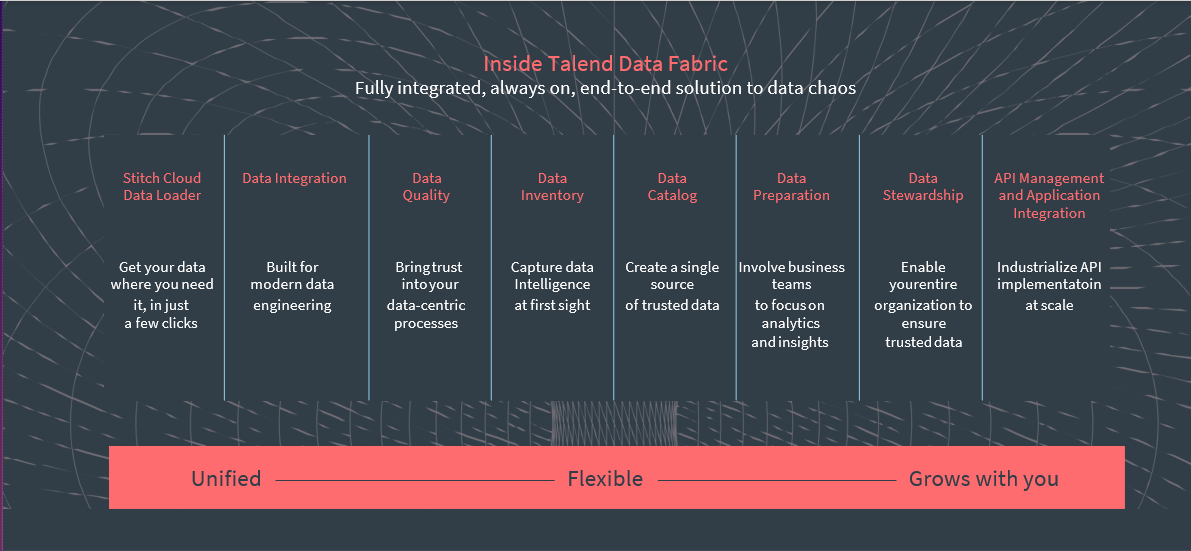
Key Features of Talend Data Fabric:
- Talend Data Fabric unifies and transforms data from various sources, supports specialized connectors for large-scale data movement, and handles batch and real-time processing with Apache Spark.
- Talend Data Fabric guarantees accurate, compliant data with tools for data profiling and reusable transformation recipes to fix common data quality issues.
- Talend offers a single platform that integrates data management, quality, governance, and cataloging, making it easier for users to oversee their data.
- Talend Data Fabric enables data team collaboration and self-service data preparation tools.
- Talend Data Fabric facilitates API creation and application-to-application integration for secure data sharing.
- Talend Data Fabric supports cloud, hybrid, and on-premises deployment models for adaptability.
- Talend facilitates the creation of data pipelines with a drag-and-drop interface, reducing the need for manual coding.
Pros and Cons of Talend Data Fabric
Pros of Talend Data Fabric:
- Easy to use, even for those without a technical background
- Scalable to accommodate the needs of different organizations
- Supports a wide range of data sources and integrations
- Offers a robust platform with a user-friendly interface
- Reliable for managing large datasets
- Integrates well with both on-premises and cloud systems
- Has an active community for support and resources
Cons of Talend Data Fabric:
- Some advanced features may require programming knowledge
- Users have noted that error management could be improved
- Scheduling features are seen as limited compared to competitors
- Some users have reported stability issues in large-scale environments
- Certain features may require additional paid extensions
Databricks vs Talend—Which One Should You Opt For?
Are you trying to choose between Databricks vs Talend Data Fabric? Here's the thing: they're meant for different tasks, even though they share some similarities.
Databricks is renowned when it comes to handling massive volumes of data and machine learning. It's super fast at analyzing data in real-time and is great for team projects, making it the top choice for companies that focus on big data and AI/ML work.
Talend Data Fabric, on the other hand, is awesome at integrating data and keeping it in check. It's perfect for places where data quality and compliance are super important. Talend has a bunch of tools that help with ETL, data quality, and making sure data is consistent across complex systems.
🔮 TL;DR: If you and your organization needs to crunch massive data, especially with big data, and you want a platform that can handle machine learning and real-time data processing, Databricks is probably your best bet. But, if you're more focused on integrating data, keeping it high-quality, and making sure it's secure across multiple environments, Talend Data Fabric is the way to go. And, if you need both, you can even integrate both of them.
11) Clickhouse
ClickHouse is a high-performance, open source, column-oriented database management system (DBMS) designed for online analytical processing (OLAP). It was initially developed by Yandex, and has since gained popularity for its ability to handle large amounts of data and provide real-time analytical insights using SQL queries.
ClickHouse is particularly well-suited for scenarios that involve processing large volumes of data, such as web analytics, advertising technology, and financial data analysis.
Key Features of Clickhouse:
- ClickHouse stores data in a column-oriented format, which is highly efficient for analytical queries that typically access only a subset of columns in a table.
- ClickHouse enables real-time analytics by processing data as it arrives, without the need for complex ETL pipelines.
- ClickHouse is designed to scale horizontally, allowing users to add more servers to handle increasing data volumes and query loads. ClickHouse also supports replication and sharding for improved fault tolerance and load balancing.
- ClickHouse provides a SQL-like query language that is familiar to many developers and analysts, making it easy to integrate with existing tools and workflows.
- ClickHouse employs advanced compression algorithms to reduce storage requirements and improve query performance.
Pros and Cons of Clickhouse
Pros of Clickhouse:
- Extremely fast performance for analytical queries
- Efficient storage and compression of large datasets
- Scalable architecture that can handle growing data volumes
- Real-time analytics capabilities for immediate insights
- SQL compatibility for easy integration with existing tools
Cons of Clickhouse:
- Limited support for complex transactions and updates
- Relatively new technology compared to traditional databases, with a smaller ecosystem and community
- May require more resources (CPU, memory) for certain workloads compared to other databases
Clickhouse vs Databricks—Which One Should You Opt For?
You're trying to decide between Clickhouse vs Databricks? To make a smart choice, you need to know what you need and the type of workloads you need to handle. Let's compare them side by side. Here is a table difference between ClickHouse vs Databricks.
| Feature | ClickHouse | Databricks |
| Primary Focus | High-performance, real-time OLAP analytics | Unified data analytics and machine learning |
| Data Storage | Column-oriented storage for efficient analytics | Support for various storage formats, including Delta Lake |
| Scalability | Horizontal scalability through sharding and replication | Scalability through Spark and cloud infrastructure |
| Query Language | SQL-like query language | Supports SQL, Python, R, Scala, and more |
| AL and Machine Learning | Limited built-in ML capabilities | Advanced ML capabilities with MLflow |
| Cloud Support | Supports deployment on various cloud platforms | Cloud-native, optimized for cloud deployments |
🔮 If your primary focus is on high-performance, real-time analytical queries over large datasets, ClickHouse could be a suitable choice. Its column-oriented storage, efficient compression, and scalable architecture make it ideal for web analytics, advertising technology, and financial data analysis use cases. On the other hand, if your organization requires a unified platform for data engineering, data science, and machine learning, Databricks may be a better fit.
12) Cloudera
Cloudera is a leading provider of big data and analytics solutions, offering a comprehensive platform designed to manage and analyze vast amounts of data. The Cloudera Data Platform (CDP) integrates various data management capabilities, which includes data warehousing, machine learning, and data engineering, all while making sure robust security and governance is in place. Established from the merger of Cloudera and Hortonworks, the platform is tailored for enterprises looking to leverage data for actionable insights across various industries.
Databricks Competitors - Databricks Alternatives - Databricks vs Cloudera
Key Features of Cloudera:
- Cloudera provides a unified platform that integrates data engineering, data warehousing, machine learning, and analytics, streamlining workflows and reducing data silos.
- Cloudera includes enterprise-grade security features, such as data encryption, access controls, and comprehensive audit capabilities, ensuring compliance with regulatory standards.
- Cloudera is designed to scale horizontally, allowing organizations to expand their data infrastructure as needed without significant disruptions.
- Cloudera Data Platform (CDP) can be deployed on various cloud environments (AWS, Azure, Google Cloud) as well as on-premises, providing flexibility in data management strategies.
- Cloudera offers tools for machine learning and predictive analytics, enabling organizations to derive insights from their data and make data-driven decisions.
- Cloudera platform supports various Apache projects, including Apache Hadoop, Apache Spark, and Apache Kafka, allowing users to leverage existing tools and frameworks.
Pros and Cons of Cloudera
Pros of Cloudera:
- Comprehensive platform that covers a wide range of data needs from engineering to analytics
- Strong focus on security and governance, making it suitable for regulated industries
- Multi-cloud deployment options providing flexibility and scalability
- Robust community support due to its integration with the Apache ecosystem
Cons of Cloudera:
- Complexity in setup and management may require specialized knowledge and resources
- Higher operational costs compared to some competitors, especially for smaller organizations
- Users have reported challenges in finding skilled personnel familiar with Cloudera solutions
Databricks vs Cloudera—Which One Should You Opt For?
Here is a table difference between Databricks vs Cloudera.
| Feature | Cloudera | Databricks |
| Primary Focus | Unified data management and analytics | Collaborative data analytics and machine learning |
| Deployment Flexibility | Multi-cloud and on-premises options | Cloud-native, optimized for big data processing |
| Data Processing | Supports batch and real-time processing | Primarily focused on real-time data processing with Apache Spark |
| Machine Learning | Integrated ML capabilities | Advanced ML capabilities with built-in tools like MLflow |
| User Interface | More complex, requiring technical expertise | User-friendly notebooks for collaborative work |
| Cost Structure | Can be cost-prohibitive for smaller teams | Pay-as-you-go model can be more economical for variable workloads |
🔮 If you need a top data management solution with strong security and governance, consider Cloudera. It's a good fit for industries with strict rules/regulations. It's an all-in-one platform that's perfect for big companies wanting to bring all their data functions under one roof.
If you're into analytics and machine learning, use Databricks. It can process huge datasets in real-time. Its easy-to-use interface and smooth integration with Apache Spark make it a dream for data teams wanting to innovate quickly and efficiently.
13) Yellowbrick Data
Yellowbrick Data is a data warehouse platform designed for modern analytics workloads. It was first founded in 2014 by Neil Carson, Jim Dawson, and Mark Brinicombe, which offers a hybrid cloud architecture that allows customers to run analytics on-premises, in the cloud, or in a hybrid environment.
Databricks Competitors - Databricks Alternatives - Databricks vs Yellowbrick Data
Key Features of Yellowbrick Data:
- Yellowbrick leverages MPP architecture to handle large datasets and complex queries efficiently.
- It delivers fast query performance, enabling real-time analytics.
- Yellowbrick can scale horizontally to accommodate growing data volumes and increasing workloads.
- Yellowbrick is designed to be deployed on public cloud platforms like AWS, Azure, and GCP.
- It can also be deployed on-premises for organizations with specific infrastructure requirements.
- Yellowbrick supports ANSI SQL and ACID reliability by using a PostgreSQL-based front-end, supporting any database driver or external connector.
- Yellowbrick Data Warehouse includes a purpose-built execution engine with a primary column store, built-in compression, and erasure encoding for reliability.
- Yellowbrick also has a fully cloud-native version of its data warehouse, based on Kubernetes and available across all public clouds.
- Yellowbrick integrates with various data sources and tools, enabling seamless data pipelines.
Pros and Cons of Yellowbrick Data
Pros of Yellowbrick Data:
- Hybrid cloud architecture provides flexibility
- High performance for analytics workloads
- Scalable to handle changing workloads
- SQL compatibility for easy migration
- Easy to use interface and tools
Cons of Yellowbrick Data:
- May be more expensive than some cloud-based alternatives
- Limited ecosystem compared to larger platforms like Databricks
- On-premises deployment may require more IT resources to manage
Databricks vs Yellowbrick Data—Which One Should You Opt For?
So, you're trying to decide between Databricks vs Yellowbrick Data for your data warehousing and analytics needs. Both are solid choices, but they've got some key differences.
First off, where do you want to run your stuff? Databricks is mostly a cloud-based deal, while Yellowbrick lets you run on-premises, in the cloud, or a mix of both.
Speed is important too. Both platforms are built for high-performance analytics, but Yellowbrick might have an edge in some cases thanks to its specialized hardware and MPP architecture.
Ease of use. Both platforms try to be user-friendly, but Yellowbrick's simple interface and intuitive tools might make it a bit easier to get started.
🔮 Go with Databricks if your organization needs a one-stop shop for machine learning and AI. It's got advanced ML libraries, AutoML, and great collaboration tools that work across cloud environments - perfect for big projects.
If you need super-fast analytics, especially for on-premises or hybrid environments, Yellowbrick Data is the way to go. It's perfect for organizations dealing with massive datasets that need lightning-fast query responses. Plus, you can deploy it however you want without sacrificing performance.
That's it! As you can tell, there are loads of Databricks competitors out there that are super powerful. We picked out 13 of them that could go toe-to-toe with Databricks.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Further Reading
- Databricks vs Snowflake: 5 Key Features Compared
- Snowflake vs Redshift Comparison - 10 Key Differences
- Snowflake vs BigQuery Comparison: 7 Critical Factors
- 22 Best DataOps Tools for Data Management and Observability
- What is Amazon Redshift?
- Azure Synapse Analytics
- What Is Apache Spark?
- What is Amazon EMR (Amazon Elastic MapReduce)?
- Run Spark and Hadoop faster with Dataproc
- IBM Cloud Pak for Data
- What is Talend ? — An Introduction to Talend ETL Tool
- Discover Cloudera Data Platform
- Yellowbrick Data Explained in Under 2 Minutes
Conclusion
And that’s a wrap! Databricks has established itself as a leader in the data analytics and processing space. They offer a strong platform for data engineering, machine learning, and analytics. But as the market grows, other competitors are stepping up with unique features that might be a better fit for some businesses. To make smart decisions, you need to know what Databricks and its competitors bring to the table—and what they don't. This way, you can supercharge your data strategy and hit your targets.
FAQs
What is Databricks used for?
Databricks is used for data engineering, machine learning, and analytics, providing a unified platform for managing big data.
What is Databricks and why is it used?
Databricks was founded in 2013 by the creators of Apache Spark. They had the idea to make big data easier to handle by building a platform that could tackle data engineering, data science, and machine learning at scale.
How does Databricks compare to Snowflake?
Databricks is better for complex analytics and machine learning, while Snowflake excels in data warehousing and business intelligence.
What are the key features of Google BigQuery?
Google BigQuery offers a serverless architecture, automatic scaling, and strong integration with Google Cloud services.
Is Amazon Redshift suitable for small businesses?
Amazon Redshift can be complex to set up, making it more suitable for larger enterprises with predictable workloads.
What is the main advantage of using Apache Spark?
Apache Spark provides fast in-memory data processing capabilities. Perfect for large-scale data analytics.
How does Amazon EMR differ from Databricks?
Amazon EMR is a more flexible big data processing platform that supports a wide range of open source tools beyond just Apache Spark, while Databricks is focused on providing a unified platform for Spark-based analytics and machine learning.
What are the key features of Google Cloud Dataproc?
Google Cloud Dataproc is a fully managed service that simplifies running Apache Hadoop and Apache Spark clusters, with features like rapid cluster creation, seamless integration with other Google Cloud services, and a pay-as-you-go pricing model.
How does Talend Data Fabric differ from Databricks in terms of use cases?
Talend Data Fabric excels at data integration, data quality, and data governance, while Databricks is more focused on large-scale data processing, advanced analytics, and machine learning.
How does Cloudera's deployment flexibility compare to Databricks?
Cloudera offers multi-cloud and on-premises deployment options, while Databricks is primarily cloud-native and optimized for cloud environments.
Are Databricks and Redshift the same?
Amazon Redshift is best for large-scale data warehousing and easy integration with other AWS services, while Databricks is a unified platform for data engineering, data science, and machine learning, with a stronger focus on real-time analytics and Apache Spark.
What are the key advantages of Dremio's "open lakehouse" architecture compared to Databricks' Lakehouse approach?
Dremio's ability to query data directly from cloud object storage without the need for ETL can provide cost savings and faster time-to-insight compared to Databricks' Lakehouse, which still requires some data movement.
What does Yellowbrick data do?
Yellowbrick Data is a data warehouse platform designed for modern analytics workloads. It offers a hybrid cloud architecture that allows customers to run analytics on-premises, in the cloud, or in a hybrid environment.
















{kind=link}