





























Machine learning (ML) is driving innovation across industries by offering powerful tools to enhance efficiency and reduce costs. However, building and deploying reliable ML models is challenging and requires a significant amount of skill and time. Everyone (from small startups to large enterprises) is trying to build and train ML models to gain competitive insights and efficiencies, which has led to a massive surge in demand for reliable and effective ML models. This is where automation through AutoML plays a key role. Automating parts of the machine learning workflow not only enhances user-friendliness and accessibility but also significantly reduces the time and expertise required for model development. AutoML tools, especially those that are low-code/no-code, are gaining popularity because they simplify the process, allowing users with varying levels of technical expertise to create powerful ML models without needing to be experts. Databricks AutoML, launched at the 2021 Data + AI Summit, is a standout solution integrated within the Databricks platform. It automates the entire ML lifecycle (from data preparation => feature engineering => model training => hyperparameter tuning) and generates customizable source code, accelerating the time-to-value for ML projects.
In this article, we will cover everything you need to know about Databricks AutoML—diving into its features, inner workings, and practical applications. On top of that, we'll examine how it addresses common challenges faced by existing AutoML solutions, and and provide you with step-by-step guide for training and deploying models through both the user interface and the Python API.
Let’s dive right into it!
What is AutoML?
AutoML, short for Automated Machine Learning, aims to democratize machine learning by automating key stages of the ML pipeline—data preprocessing, feature engineering, model selection, hyperparameter tuning, and model evaluation. AutoML handles these steps to enable data scientists and engineers to concentrate on interpreting results rather than on the intricacies of model development and tuning.
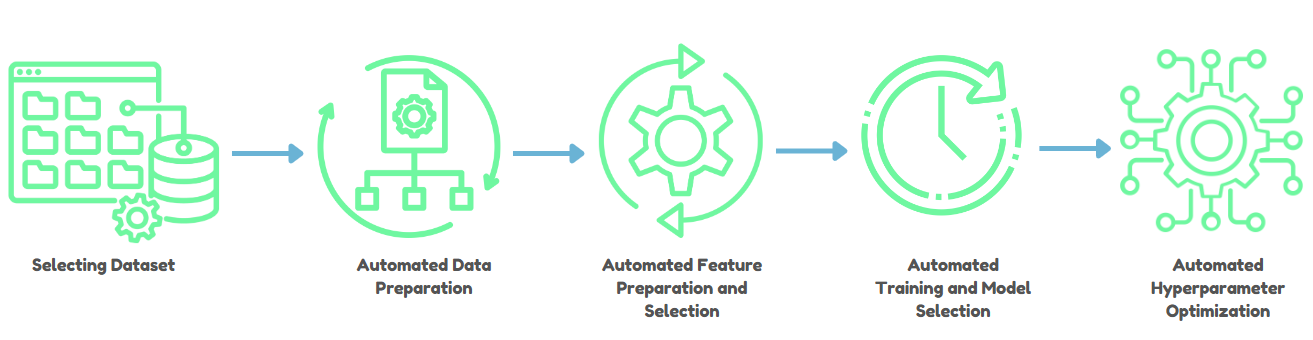
1) Data Preparation and Ingestion
AutoML starts with preprocessing data, which includes tasks like handling missing values, normalizing data, and detecting data types—whether they're numbers, categories, or text. This step is crucial because it sets the stage for accurate model training.
2) Automated Feature Engineering and Selection
One of the most time-consuming aspects of ML is creating and selecting features that improve model performance. AutoML automates feature engineering by identifying and generating features that are most predictive, thus speeding up the process while maintaining interpretability—especially important in highly regulated industries.
3) Automated Model Selection and Training
AutoML automates the selection of the best machine learning algorithm for a given task. It iterates over various algorithms and hyperparameters, using optimization techniques like Bayesian optimization to efficiently find the best model configurations, saving you from the usual trial and error.
4) Automated Hyperparameter Optimization
Fine-tuning and tweaking hyperparameters can boost your model's performance but it's often a tedious job. AutoML automates this by exploring and optimizing hyperparameters through techniques such as grid search, random search, and more sophisticated methods like Bayesian optimization.
5) Evaluation and Validation
AutoML rigorously tests models using cross-validation and other metrics to make sure they're robust. It also checks for issues like data leakage and misconfiguration, helping to make sure the model is reliable before it gets deployed.
6) ML Model Deployment and Monitoring
After training and validating a model, AutoML makes ML model deployment easy, allowing it to be smoothly integrated into production systems with minimal coding. Plus, many AutoML tools offer monitoring features to track how the model performs over time and to facilitate retraining as needed.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Benefits of AutoML
AutoML provides a number of advantages that can improve the productivity and usability of machine learning. Let's dive in.
First and foremost, AutoML can significantly minimize the time and effort necessary to develop and deploy machine learning models. Data engineers and data scientists can devote more time to the strategic parts of ML model development and deployment by automating tedious chores.
Second, AutoML makes machine learning more accessible to a larger number of people and organizations. Even if you don't have a deep understanding of machine learning methods and techniques, AutoML can help you utilize advanced ML capabilities to improve business outcomes.
Key Points Addressed by AutoML
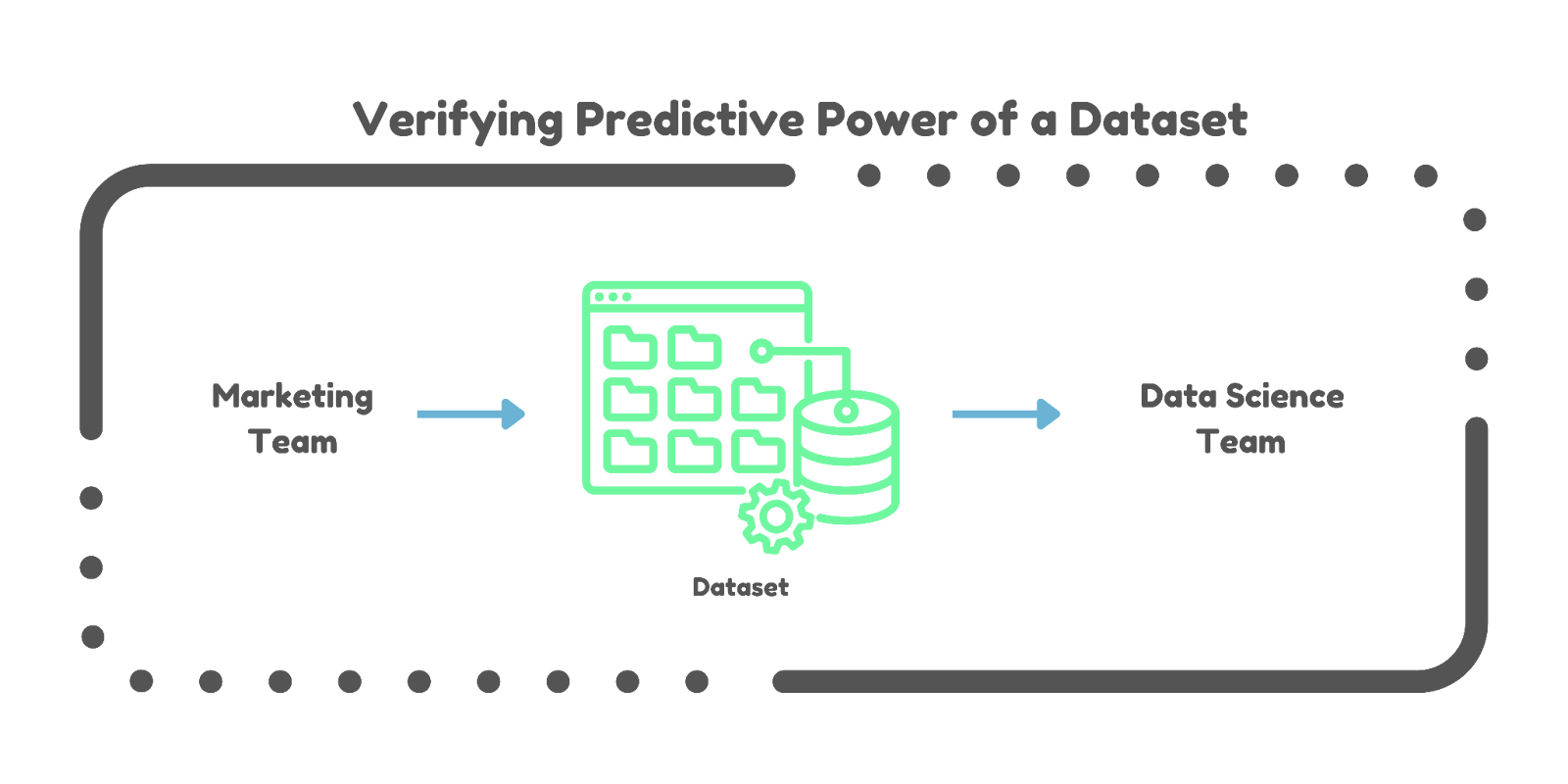
Verifying Predictive Power. Data scientists and engineers often spend days/weeks/months determining if a dataset has the predictive power required for a specific task. AutoML accelerates this process, providing quicker insights into the viability of a dataset.
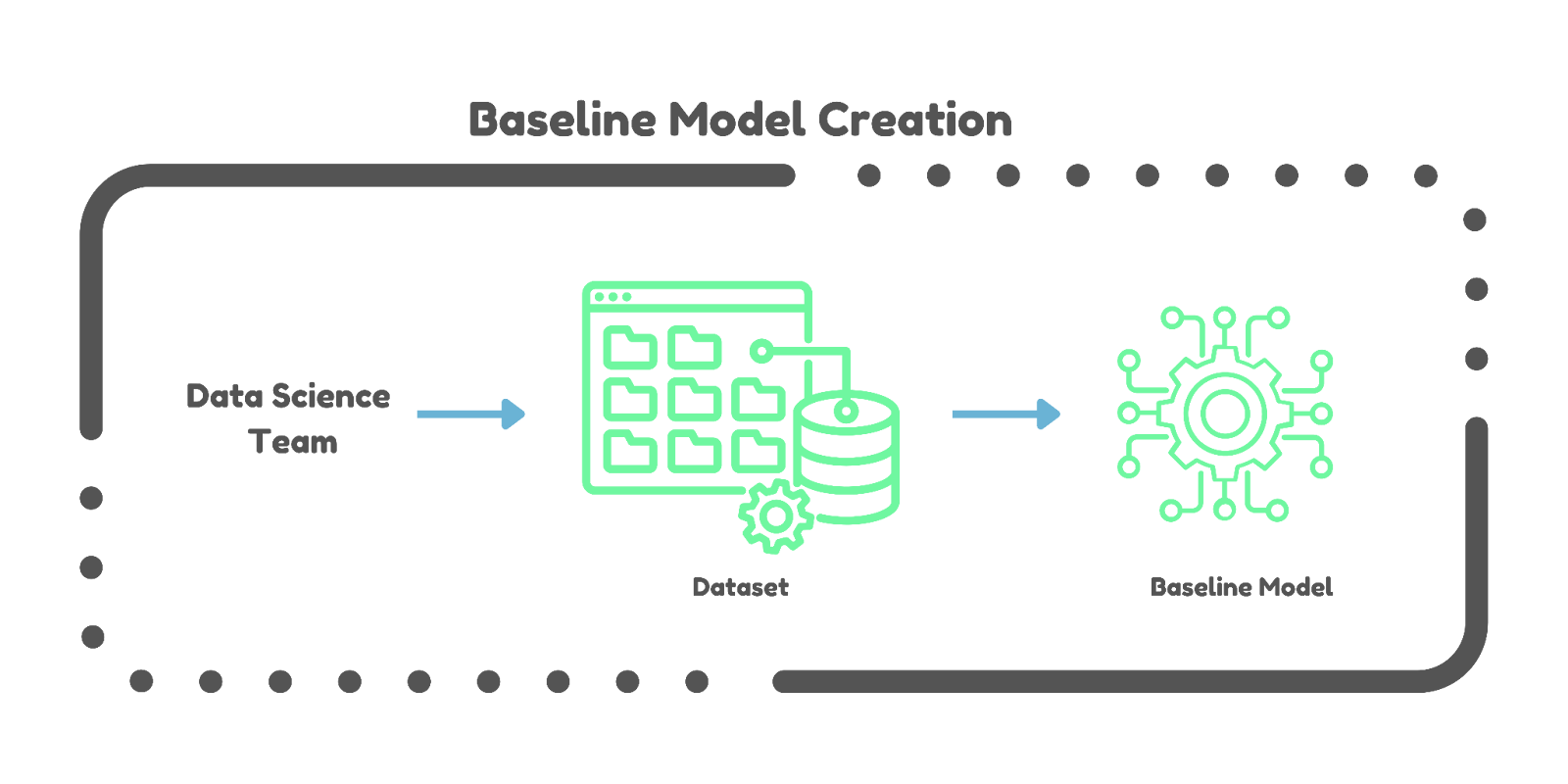
Baseline Model Creation. Establishing a baseline model can take weeks or even months. AutoML streamlines this by automatically generating baseline models, guiding project direction more efficiently.
Challenges with Existing AutoML Solutions
Automated Machine Learning (AutoML) has made machine learning more accessible by automating many of the tedious steps involved in building models. But, it's not without its flaws. Many current AutoML solutions suffer from two significant issues: the "Opaque-Box" problem and the "Production Cliff".
1) The Opaque-Box Problem
The "Opaque-Box" problem refers to the lack of transparency in how AutoML models are created and optimized. Here are some of the key issues:
Regulatory Compliance. In industries like healthcare and finance, regulations often require that companies explain how their models make decisions. If the process is hidden, it’s hard to meet these requirements.
Trust and Interpretability. When users can't see inside the model, it becomes difficult to trust the results. Understanding how a model works is crucial for making right decisions and improving the model further.
2) The Production Cliff
The "Production Cliff" problem happens when the best model from an AutoML tool isn’t ready for production use right away. Here's why:
Need for Customization. Auto-generated models often need tweaks to fit specific business needs or to integrate smoothly with existing systems. This can require significant additional effort from data scientists.
Reverse Engineering. Data scientists may need to spend a lot of time figuring out how the auto-generated model works so they can modify and optimize it for their specific use case.
Okay, so how does Databricks AutoML solve these problems? Databricks AutoML addresses these challenges by providing a "glass-box" solution that offers transparency into training machine learning models process while also facilitating a seamless transition from development to production deployment.
Now let's dive in deep and understand what Databricks AutoML actually is.
What is Databricks AutoML?
Databricks AutoML is a tool designed to simplify and accelerate the process of building and deploying machine learning models all within the Databricks platform. It automates essential tasks such as preprocessing, feature engineering, tuning, and training machine learning models, allowing data teams to focus on higher-level decisions and insights.
What Is the Feature Importance of Databricks AutoML?
The following are some significant features of Databricks AutoML:
1) Data Cleaning and Preprocessing
Databricks AutoML handles missing value imputation, feature normalization, and categorical encoding automatically, so datasets are ready for training machine learning models without requiring considerable manual involvement.
2) Semantic Type Detection
Databricks AutoML detects and assigns semantic types to columns, which helps in applying appropriate preprocessing procedures based on the data type.
3) Algorithm Variety
Databricks AutoML leverages a range of algorithms from popular ML libraries such as scikit-learn, XGBoost, LightGBM, Prophet, and Auto-ARIMA. This allows it to address various ML tasks, including classification, regression, and time series forecasting.
4) Parallelized Training
Databricks AutoML distributes hyperparameter tuning trials across multiple nodes, speeding up the training machine learning model process significantly.
5) Customizable Notebooks
Databricks AutoML generates editable Python notebooks for each trial run, enabling data scientists and engineers to inspect and modify the underlying code to better fit specific project needs.
6) Integration with MLflow
Databricks AutoML integrates with MLflow for tracking metrics and parameters throughout multiple trial runs. This integration makes it easier to compare model performance while also streamlining the model registry and ML model deployment processes.
7) Transparency and Explainability
Databricks AutoML provides detailed notebooks that document each step of the model training process, including SHAP plots for model interpretability, guaranteeing transparency and ease of audit.
8) Configurable Evaluation Metrics
Users can specify evaluation metrics to rank and select the best-performing models. This flexibility guarantees that models are optimized based on criteria that matter most to the specific use case.
9) Enterprise Reliability
Databricks AutoML is designed on a strong and scalable architecture that provides enterprise-level reliability. It uses Databricks' distributed computing capabilities to efficiently handle massive datasets and sophisticated computations.
10) Handling Imbalanced Datasets
For classification problems, Databricks AutoML automatically balances training datasets by adjusting class weights and downsampling major classes, thereby improving model performance on imbalanced datasets.
11) UI and API Access
Users can initiate Databricks AutoML experiments via a graphical user interface (GUI) or programmatically through the Python API. This dual approach serves both non-technical users and those who prefer scripting and automation.
12) Low-Code/No-Code Interface
Databricks AutoML offers a user-friendly interface that requires minimal coding. This low-code/no-code approach allows users with varying levels of technical expertise to easily configure and run ML experiments, democratizing access to machine learning.
13) Efficient Resource Utilization
Databricks AutoML predicts memory requirements and dynamically samples big datasets to fit available computational resources, allowing for effective cluster capacity utilization without manual configuration.
14) Collaboration and Compliance
Databricks AutoML helps teams collaborate by providing full logs and documentation for each experiment. It assures compliance with industry norms and laws by keeping an audit record of all ML operations.
Inner Workings of Databricks AutoML—How Does AutoML Work?
Databricks AutoML streamlines the machine learning process by automating critical activities such as the ability to evaluate and train ML models. This "glass box" method enables transparency and extensive insights into each process, allowing users to understand and alter the resulting models.
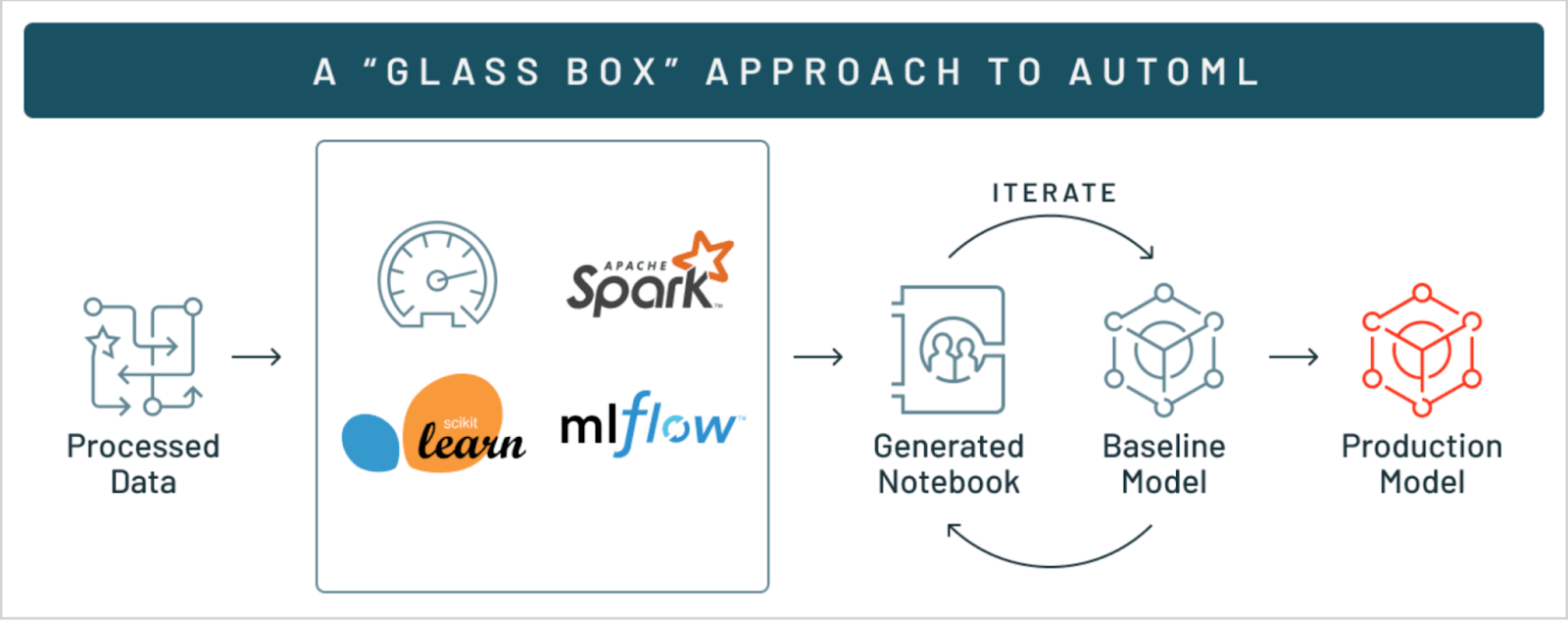
Here's a detailed look into how AutoML works in Databricks:
Phase One—Data Preparation
Data preparation is the first step in the AutoML pipeline. This stage includes numerous critical tasks:
Missing Value Imputation. Databricks AutoML uses statistical or machine learning models to identify and fill in missing data points.
Data Type Detection and Semantic Type Annotation. Databricks AutoML finds and assigns suitable data and semantic types to columns, guaranteeing that data is handled accurately during model training.
Imbalanced Data Handling. For classification problems, Databricks AutoML finds and corrects dataset imbalances by downsampling the majority class and applying class weights to balance the training dataset.
Phase Two—Data Splitting
Databricks AutoML supports two primary methods for splitting data into training, validation, and test sets:
- Random Split: By default, the dataset is split into 60% training, 20% validation, and 20% test sets. For classification tasks, a stratified random split is used to maintain the class distribution across splits.
- Chronological Split: For time series data, the dataset can be split based on a time column, ensuring that the training, validation, and test sets follow the chronological order.
Phase Three—Train ML Model and Hyperparameter Tuning
AutoML iteratively trains and tunes multiple models using algorithms from popular packages such as scikit-learn, XGBoost, LightGBM, Prophet, and ARIMA. Here’s how the process unfolds:
Model Selection. Databricks AutoML identifies relevant algorithms based on the problem type (classification, regression, or forecasting).
Hyperparameter Tuning. Databricks AutoML distributes hyperparameter tuning trials across worker nodes in a cluster. Each trial explores different hyperparameter configurations to identify the best optimal settings.
Sampling large datasets. If the dataset is too huge to fit in the memory of a single worker node, Databricks AutoML will sample it. The sample fraction can be changed according to the memory available on the worker nodes and the Spark configurations.
Phase Four—Model Evaluation and Selection
Databricks AutoML evaluates models using performance metrics suitable for the specific task. For instance, it uses accuracy, precision, recall, and F1-score for classification; RMSE (Root Mean Square Error), MAE (Mean Absolute Error), and R^2(R squared) for regression; and SMAPE (Symmetric Mean Absolute Percentage Error) for forecasting. The models are ranked based on these metrics, and the best-performing model is selected for further use.
Phase Five—Model Explainability
Databricks AutoML supports Shapley values (SHAP) for model explainability. SHAP values help in understanding the contribution of each feature to the model's predictions. This feature is particularly useful for interpreting complex models.
Phase Six—Integration with Databricks Ecosystem
Databricks AutoML interacts easily with the Databricks environment, providing various benefits, that include:
Automatically generated notebooks. Databricks AutoML creates notebooks for each trial, which include the source code used for data preparation, model training, and evaluation. These notebooks can be reviewed, reproduced, and modified easily.
Feature Store Integration. With Databricks Runtime 11.3 LTS ML and above, Databricks AutoML can leverage existing feature tables in the Feature Store to enhance the input dataset.
Scalability. Databricks AutoML is designed to scale across large datasets and clusters, leveraging the distributed computing capabilities of Databricks.
Phase Seven—ML Model Deployment
Once the best model is selected based on the evaluation metrics, it can be registered with the MLflow Model Registry and deployed as a REST endpoint using MLflow Model Serving, streamlining the transition from experimentation to production
Algorithms Used by Databricks AutoML
Databricks AutoML utilizes a variety of algorithms from several prominent machine learning libraries to support different types of machine learning tasks such as classification, regression, and forecasting. Here are the primary algorithms and libraries used:
Classification Models:
Regression Models:
Forecasting Models:
- Prophet (for time-series forecasting)
- Auto-ARIMA (Available in Databricks Runtime 10.3 ML and above, for time-series forecasting with regularly spaced time intervals)
What Are the Feature Types That Databricks AutoML Support?
Databricks AutoML supports a variety of data feature types:
- Numeric (ByteType, ShortType, IntegerType, LongType, FloatType, DoubleType)
- Boolean
- String (categorical or English text)
- Timestamps (TimestampType, DateType)
- ArrayType[Numeric] (Databricks Runtime 10.4 LTS ML and above)
- DecimalType (Databricks Runtime 11.3 LTS ML and above)
Now that we have a comprehensive understanding of AutoML and Databricks AutoML, let's dive into the step-by-step guide for training machine learning models and deploying ‘em using Databricks AutoML, via UI and programmatically using Python API. Let's get started.
Step-By-Step Guide to Train and Deploy ML Models With Databricks AutoML—Using UI
Before diving into the step-by-step guide, make sure you meet the following prerequisites:
- Databricks Runtime: 9.1 ML or above (for GA, 10.4 LTS ML or above).
- Time Series Forecasting: Requires Databricks Runtime 10.0 ML or above.
- AutoML Dependencies: Databricks Runtime 9.1 LTS ML and above requires the databricks-automl-runtime package, available on PyPI.
- Library Management: Do not install additional libraries beyond those preinstalled. Modifying existing library versions can cause run failures.
- Cluster Compatibility: Databricks AutoML is incompatible with shared access mode clusters. For Unity Catalog usage, the cluster access mode must be Single User, and you must be the single designated user.
To train and deploy machine learning models using the Databricks AutoML UI, follow these steps for a seamless and efficient process.
Step 1—Access the Databricks AutoML UI
To begin training a machine learning model using Databricks AutoML, first open the AutoML user interface. In the Databricks sidebar, click "New" and then "AutoML Experiment".
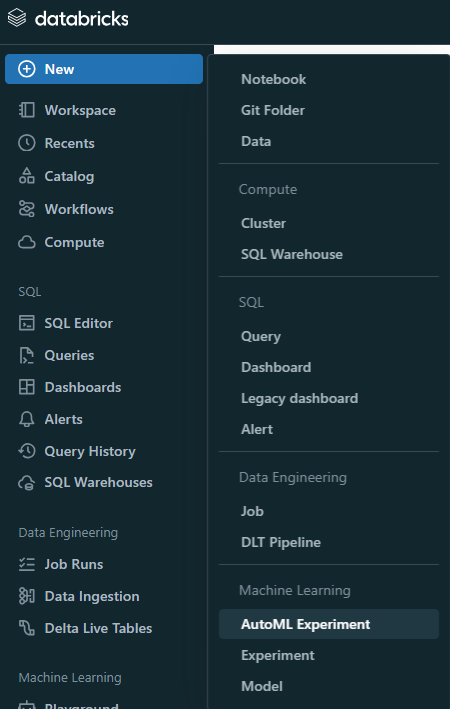
Also, you can create a new AutoML experiment from the Experiments page, which serves as a centralized hub for organizing all of your experiments.
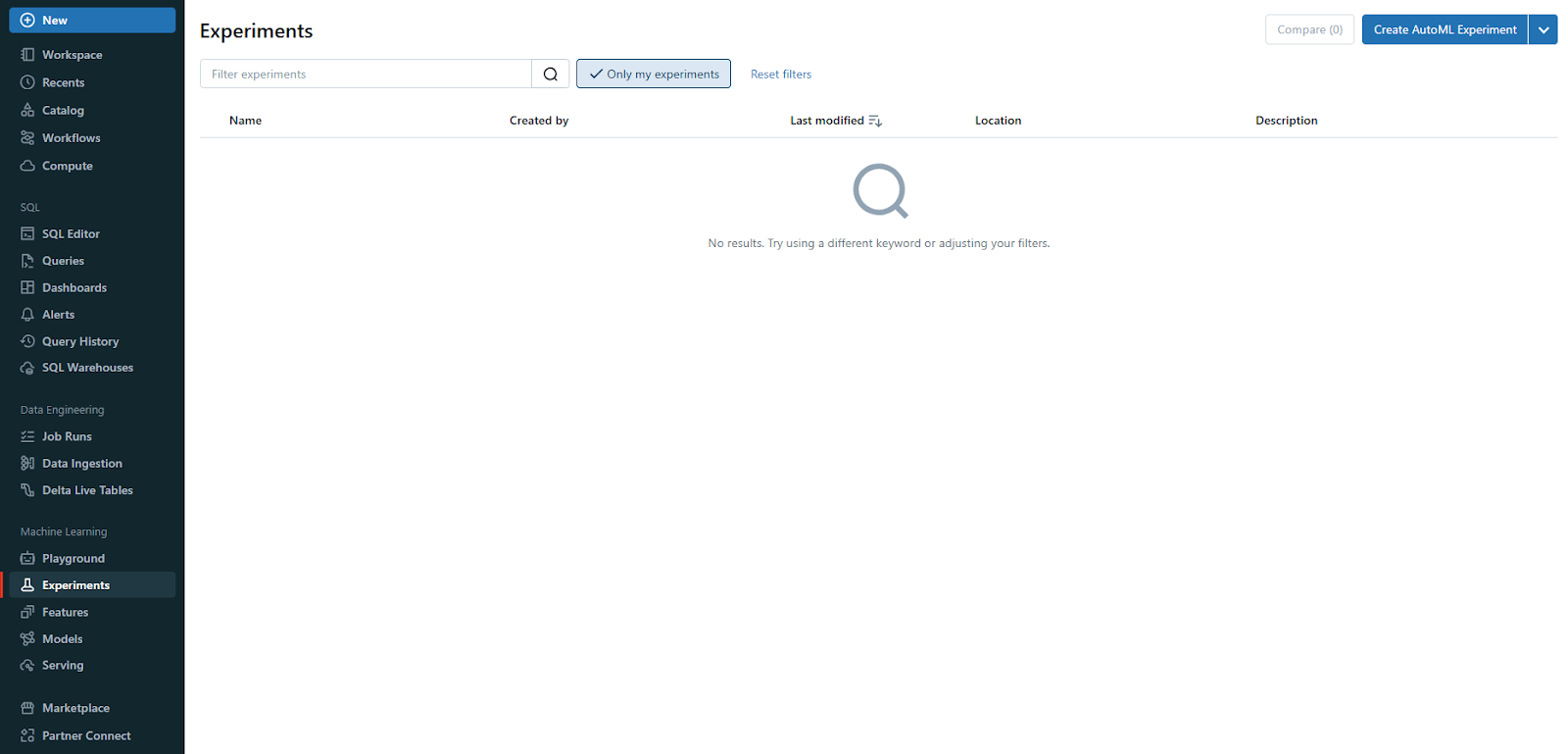
Step 2—Configure the Databricks AutoML Experiment
On the Configure Databricks AutoML experiment page, you'll need to specify key details for your experiment.
First, in the Compute field, select a cluster running Databricks Runtime ML.
Next, select your dataset by browsing and choosing the appropriate data table.
Then, define the ML problem type—Classification, Regression, or Forecasting—based on your analysis needs.
Select the target column, which Databricks AutoML should use for training by including or excluding them as needed. This functionality is only available for classification and regression problems.
Choose an evaluation metric to score the experiment runs, and set any stopping conditions to control the duration and scope of the experiment. This configuration ensures that your AutoML process is tailored to your specific requirements.
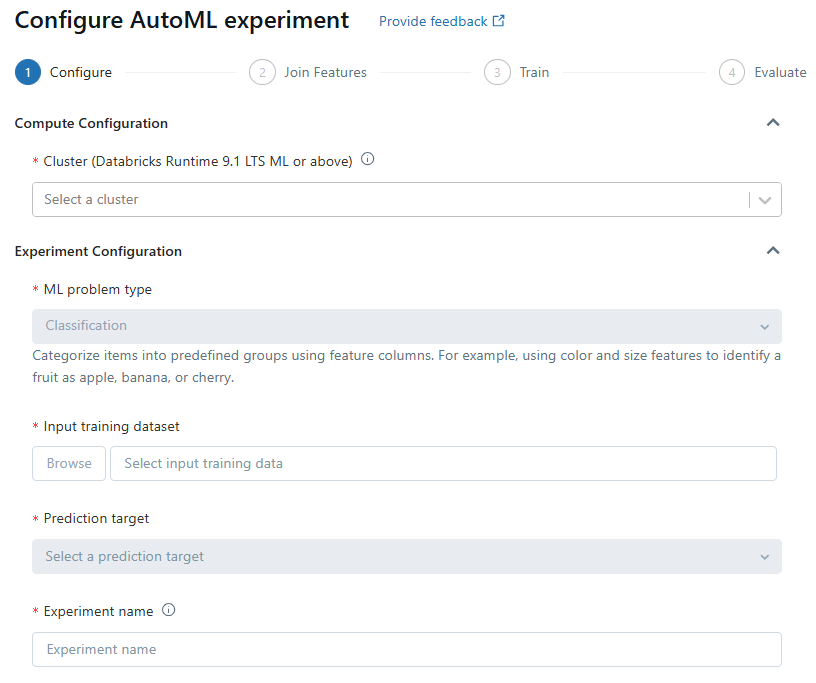
Step 3—Setting Up Classification or Regression Problems
For classification or regression problems, start by selecting a cluster running Databricks Runtime ML in the Compute field. Choose the problem type from the drop-down menu—Regression if predicting a continuous numeric value or Classification if categorizing observations into discrete classes.
Next, browse and select your dataset.
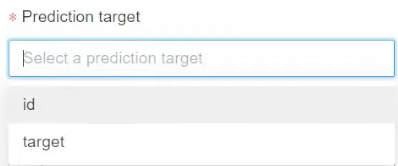
In the Prediction target field, pick the column you want the model to predict.
You can also customize the columns included in the training, select imputation methods for missing values, and leverage existing feature tables from the Feature Store to enhance your dataset.
Optionally, rename the experiment for better organization.

Step 4—Setting Up Forecasting Problems
To set up a forecasting problem, make sure that you select a cluster running Databricks Runtime 10.0 ML or above. Choose Forecasting from the ML problem type menu, then browse and select your dataset.

In the Prediction target field, choose the column to predict, just like you did above. Select the appropriate time column, which should be of type timestamp or date. For multi-series forecasting, identify the individual time series using the Time series identifiers field.
Specify the forecast horizon and frequency to define the number of periods into the future for which predictions are needed.
If you are using Auto-ARIMA, make sure your time series has a regular frequency.
Optionally, save the prediction results to a specified database (Databricks Runtime 11.3 LTS ML and above).
Again, you can rename the experiment and add any additional configurations as needed.
Step 5—Using Existing Feature Tables
In Databricks Runtime 11.3 LTS ML and above, you can enhance your input training dataset by incorporating feature tables from the Databricks Feature Store. To do this, click "Join features (optional)" on the Configure AutoML experiment page.
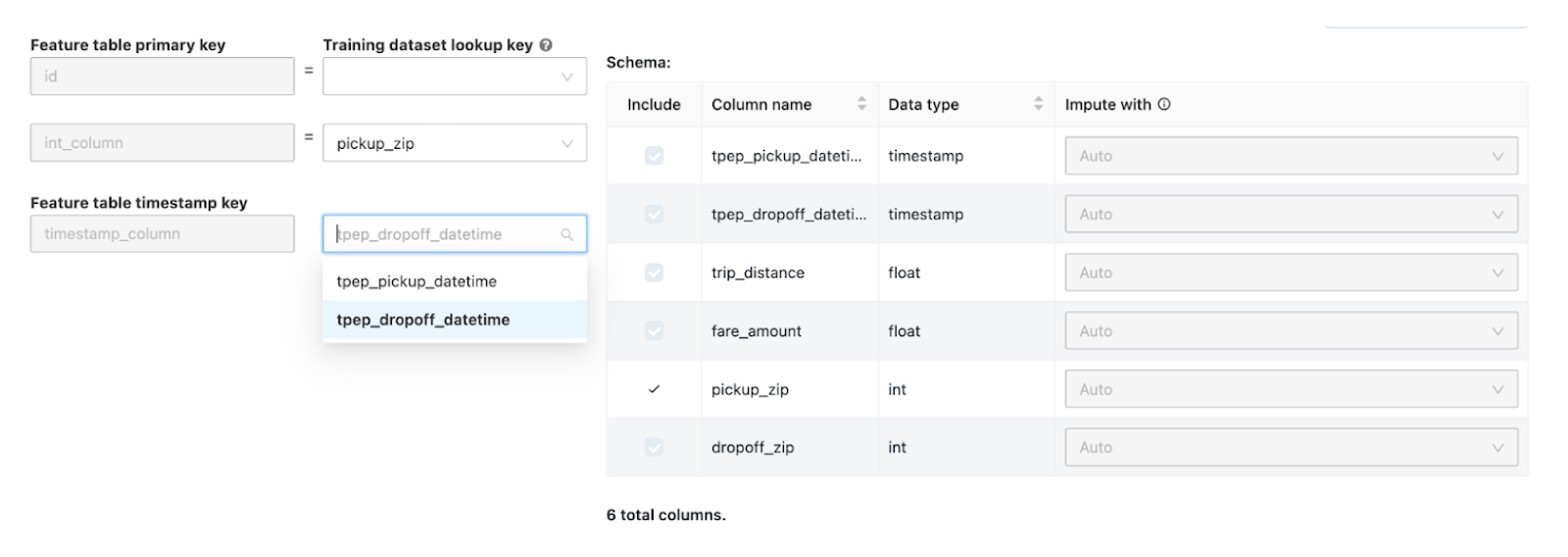
Select a feature table and the corresponding lookup keys that match your training dataset. For time series feature tables, make sure the timestamp lookup key aligns with your dataset.
Repeat these steps if you need to add more feature tables, which can significantly improve the model’s performance by providing additional contextual information.
Step 6—Advanced Configurations
The Advanced Configuration section allows you to fine-tune several parameters. Choose the primary evaluation metric for scoring runs and exclude specific training frameworks if necessary (Databricks Runtime 10.4 LTS ML and above). Adjust the stopping conditions based on time or trial count. For classification and regression experiments, enable early stopping to halt training if the validation metric ceases to improve. You can also split data for training, validation, and testing in chronological order by selecting a time column (applies to Databricks Runtime 10.4 LTS ML and above).
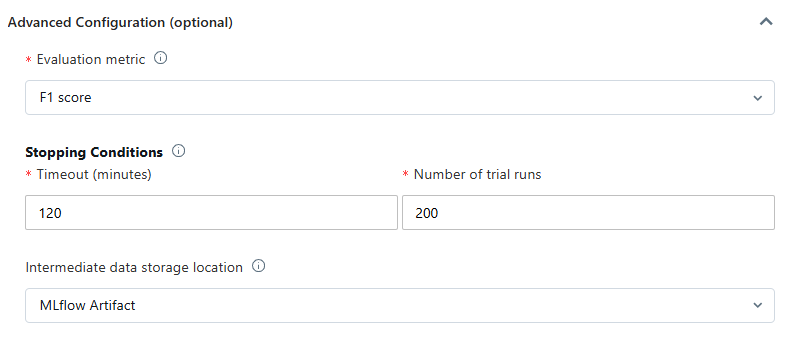
It’s recommended not to populate the Data directory field to maintain secure dataset storage as an MLflow artifact.
Step 7—Run the Experiment and Monitor Results
After configuring your experiment, click "Start AutoML" to begin the training process. The Databricks AutoML training page will display, allowing you to stop the experiment, open the data exploration notebook, and monitor the runs.
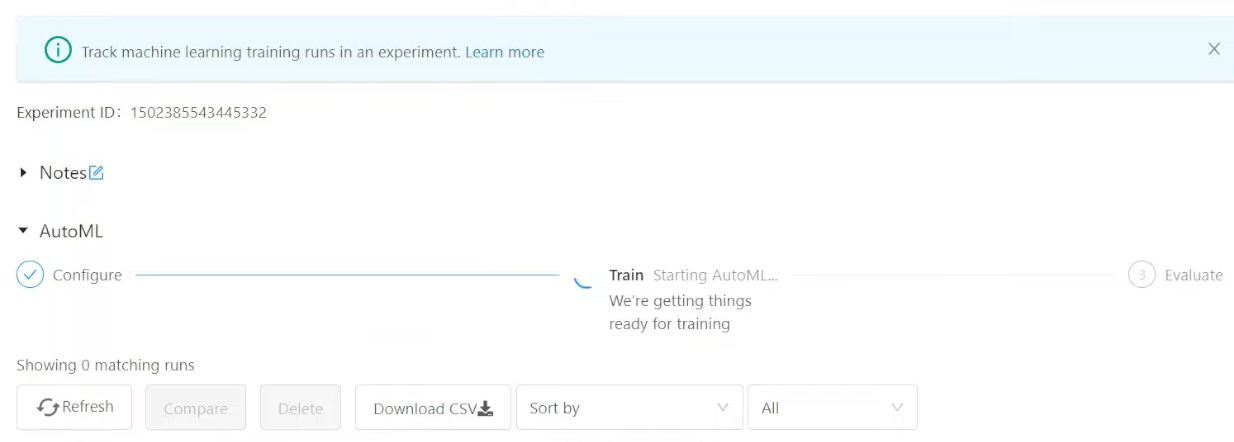
Databricks AutoML provides warnings for potential dataset issues, such as unsupported column types or high cardinality columns, which you can review in the Warnings tab.
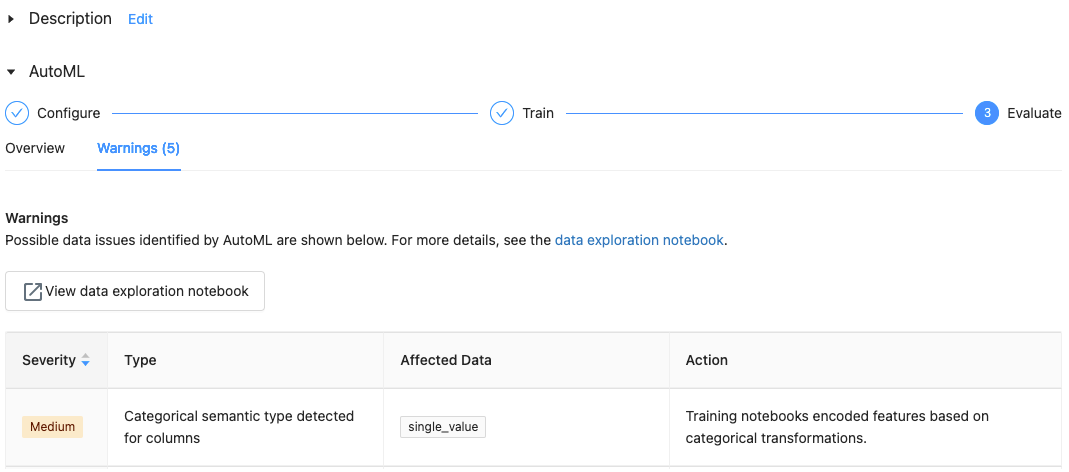
If you monitor your runs closely it helps in identifying and resolving any issues promptly.
Step 8—Post-experiment Actions
Once the experiment is completed, you have several options for post-processing. You can register and deploy the best model using MLflow, allowing you to manage and track your model's life cycle. To review and edit the notebook that created the best model, select “View notebook for best model”. If you want to delve into the data exploration phase, select “View data exploration notebook”.
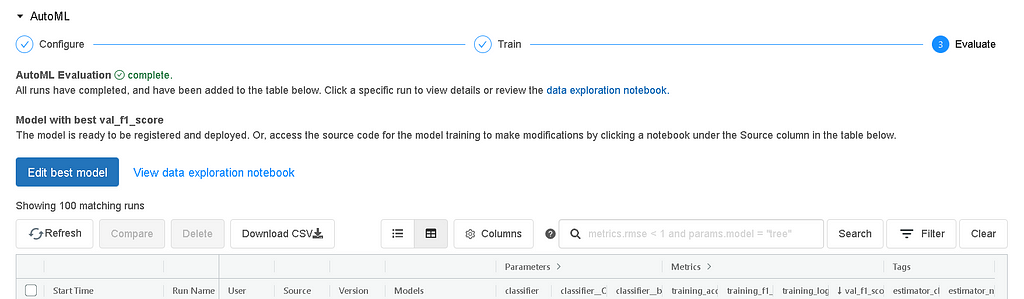
On top of that, you can also search, filter, and sort the runs in the runs table to analyze the experiment results comprehensively.
Step 9—Review and Edit Notebooks
As you know, Databricks AutoML automatically generates notebooks for each trial run. You can view, edit, and download these notebooks to review the source code and further customize your models. This feature is particularly useful for understanding the model's behavior and making necessary adjustments based on the experiment's results. Notebooks are stored in the MLflow run's Artifacts section and can be imported into the workspace if needed.
Step 10—Manage Experiment Results
To revisit your experiments, go to the Experiments page where all results are listed. The outputs, including data exploration and training notebooks, are stored in a databricks_automl folder within your home directory. This centralized storage ensures easy access to your experiment results and facilitates further analysis or model enhancements.
Step 11—Register and Deploy
Finally, now that you have successfully trained and evaluated your model, it's time to register and deploy it using the AutoML UI. Follow these steps:
Select the link in the Models column for the model you want to register—when a run completes, the best model based on the primary metric appears in the top row. Click the register model button to register it in the Model Registry.

Now, select "Create a new model", enter the model name, and click "Register".
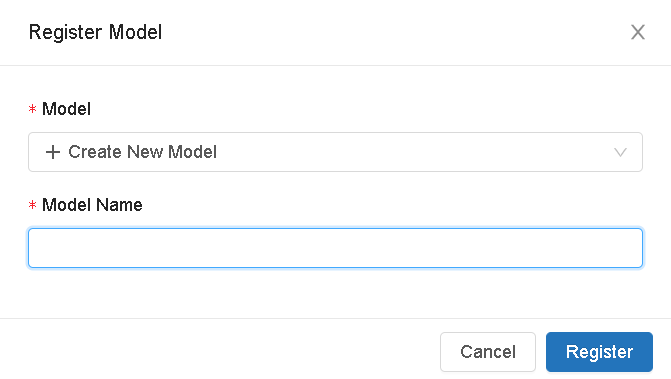
Now that we have registered our model in the Model Registry, click the popup icon located at the top right corner of the artifacts section to open the Model Registry user interface.
Or
Select the Models icon in the sidebar to navigate to the Model Registry, then choose the name of your model in the model table.
From the registered model page, you can serve the model using Model Serving.
And there you go—if you follow these detailed steps, you can easily use Databricks AutoML to train, evaluate, and deploy machine learning models, taking full advantage of the platform’s powerful capabilities to streamline your machine learning workflows.
Let's move on to the next step, where we will train an ML model with Databricks AutoML—programmatically via the Python API.
Step-By-Step Guide to Train ML Models With Databricks AutoML—Programmatically
Training machine learning models programmatically using Databricks AutoML is an efficient way to leverage automated model selection and tuning. In this step-by-step guide we will walk you through the process from setup to ML model development and deployment.
Before diving into the step-by-step guide, make sure you meet the following prerequisites:
- Databricks Workspace: Access to a Databricks workspace with Databricks Runtime for Machine Learning.
- Databricks Runtime: 9.1 ML or above (for GA, 10.4 LTS ML or above).
- Databricks Cluster: A cluster running Databricks Runtime ML.
- Time Series Forecasting: Requires Databricks Runtime 10.0 ML or above.
- AutoML Dependencies: Databricks Runtime 9.1 LTS ML and above requires the databricks-automl-runtime package, available on PyPI.
- Library Management: Do not install additional libraries beyond those preinstalled. Modifying existing library versions can cause run failures.
- Cluster Compatibility: Databricks AutoML is incompatible with shared access mode clusters. For Unity Catalog usage, the cluster access mode must be Single User, and you must be the single designated user.
Step 1—Set Up Your Environment
First, create a notebook, attach it to a cluster running Databricks Runtime ML, and write the code mentioned below.
import databricks.automl
import pandas as pd
from pyspark.sql import SparkSession
# Initialize Spark session
spark = SparkSession.builder.appName("Databricks AutoML Example").getOrCreate()Train ML Models via Databricks AutoML API—Programmatically Databricks AutoML Example
Step 2—Load Your Data
Identify which table you want to use from your existing data source or upload a data file to DBFS and create a table.
# Load dataset into a Pandas DataFrame
data = {
'age': [25, 32, 47, 51, 62],
'income': [40000, 50000, 60000, 70000, 80000],
'education': ['Bachelors', 'Masters', 'PhD', 'Masters', 'Bachelors'],
'income_bracket': ['<=50K', '>50K', '>50K', '>50K', '>50K']
}
df = pd.DataFrame(data)
# Convert Pandas DataFrame to Spark DataFrame
spark_df = spark.createDataFrame(df)
spark_df.createOrReplaceTempView("income_data")Train ML Models via Databricks AutoML API—Programmatically Databricks AutoML Example
Step 3—Start Databricks AutoML Run
Pass the table name to the appropriate API specification: classification, regression, or forecasting.
1) Classification Example
from databricks import automl
# Databricks AutoML classification run
summary = automl.classify(
dataset="income_data",
target_col="income_bracket",
timeout_minutes=30
)Train ML Models via Databricks AutoML API—Programmatically Databricks AutoML Example
2) Regression Example
from databricks import automl
# Databricks AutoML regression run
summary =automl.regress(
dataset="income_data",
target_col="income_bracket",
timeout_minutes=30
)Train ML Models via Databricks AutoML API—Programmatically Databricks AutoML Example
3) Forecasting Example
For forecasting, make sure your dataset contains a time column.
from databricks import automl
# Databricks AutoML forecasting run
summary = automl.forecast(
dataset="income_data",
target_col="income_bracket",
time_col="---",
horizon=30,
frequency="d",
primary_metric="mdape"
)Train ML Models via Databricks AutoML API—Programmatically Databricks AutoML Example
- horizon=30 to specify that AutoML should forecast 30 days into the future.
- frequency="d" to specify that a forecast should be provided for each day.
- primary_metric="mdape" to specify the metric to optimize for during training.
Step 4—Monitor Databricks AutoML Run
When the Databricks AutoML run begins, an MLflow experiment URL appears in the console. Use this URL to monitor the progress of the run.
# Output summary to understand the trials and best model
print("MLflow experiment URL:", summary.experiment.url)Train ML Models via Databricks AutoML API—Programmatically Databricks AutoML Example
Step 5—Explore Results
Once the Databricks AutoML run is complete, you can explore the results. View the auto-generated trial notebook and the data exploration notebook.
# Display info about Databricks AutoML output
help(summary)Train ML Models via Databricks AutoML API—Programmatically Databricks AutoML Example
Step 6—Use the Best Model for Inference
You can use the model trained by Databricks AutoML to make predictions on new data.
Using Pandas DataFrame
import mlflow
# Prepare test dataset
test_data = {
'age': [29, 41],
'income': [45000, 52000],
'education': ['Bachelors', 'Masters']
}
test_df = pd.DataFrame(test_data)
spark_test_df = spark.createDataFrame(test_df)
# Load the best model
model_uri = summary.best_trial.model_path
model = mlflow.pyfunc.load_model(model_uri)
# Run inference using the best model
predictions = model.predict(test_df)
print(predictions)
Train ML Models via Databricks AutoML API—Programmatically Databricks AutoML Example
Step 7—Evaluate Model Performance
Use the final model to make predictions on the holdout test set to estimate how the model would perform in a production setting.
import sklearn.metrics as metrics
# Prepare true labels and predicted labels
y_true = ['<=50K', '>50K']
y_pred = predictions
# Print confusion matrix
conf_matrix = metrics.confusion_matrix(y_true, y_pred)
print(conf_matrix)
# Plot confusion matrix
metrics.plot_confusion_matrix(model, test_df.drop(columns=['income_bracket']), test_df['income_bracket'])Train ML Models via Databricks AutoML API—Programmatically Databricks AutoML Example
That's it! Training machine learning models with Databricks AutoML using the Python API simplifies the entire process—from loading data and initiating an AutoML run to monitoring, evaluating, and deploying the best model. This step-by-step guide offers a concise yet thorough walkthrough, helping you automate your machine learning workflow effortlessly.
Remember, in this example, we used a hardcoded, very simple dataset. Databricks AutoML can handle much larger and more complex datasets, making it a powerful tool for any data scientist or engineer looking to optimize their machine learning workflows.
Databricks AutoML—Pros and Cons
Here is list of advantages and disadvantages of Databricks AutoML:
What Are the Advantages of AutoML?
Databricks AutoML offers several advantages that streamline the machine learning workflow:
1) Automated Tuning and Training Machine learning model
Databricks AutoML simplifies the process of training and tuning machine learning models. It automatically handles data preparation, model training, hyperparameter tuning, and evaluation, significantly reducing the time and effort required to build high-quality models.
2) Support for Multiple Algorithms and Libraries
It leverages a variety of machine learning libraries such as Scikit-Learn, XGBoost, LightGBM, Prophet, and ARIMA, allowing users to select the best algorithms for their specific needs. This flexibility assures robust model performance across different types of tasks, which includes classification, regression, and forecasting.
2) Integrated MLflow Tracking
The integration with MLflow allows for seamless tracking of experiment metrics and parameters, making it easier to compare model performance and manage the lifecycle of machine learning models.
3) Customizable Notebooks
For each trial run, Databricks AutoML automatically generates a detailed Python notebook that includes all the code used for data preparation, model training, and evaluation. These notebooks are fully editable.
4) Glass-Box Approach
The "glass-box" approach of Databricks AutoML provides transparency into the model building process. Users can see and modify each and every step of the pipeline, assuring they understand how the models are built and can meet any compliance or audit requirements.
5) Scalability and Efficiency
Databricks AutoML is designed to handle large datasets efficiently by automatically estimating memory requirements and distributing workloads across cluster nodes.
Databricks AutoML also supports sampling large datasets to fit within memory constraints while maintaining performance.
6) Handling Imbalanced Datasets
It offers robust support for imbalanced datasets by employing techniques like downsampling the majority class and adding class weights to ensure balanced training.
7) User-Friendly Interface and Databricks AutoML API Access
The intuitive UI and API make it accessible for both beginners and experienced users to set up and run machine learning experiments quickly. Users can easily configure their experiments, monitor progress, and view results directly all within Databricks platform.
What Are the Disadvantages of AutoML?
Databricks AutoML offers several advantages, but it also comes with some disadvantages that users should consider:
1) Limited Customization
While Databricks AutoML automates many aspects of the machine learning process, it may not provide the level of customization some experienced data scientists and engineers need. Advanced users might find it limiting compared to manually fine-tuning models and hyperparameters.
2) Resource Intensive
Running Databricks AutoML can be resource-intensive, particularly for large datasets. Databricks AutoML automatically estimates memory requirements and may need to sample datasets to fit within memory constraints. This can lead to increased computational costs and may require powerful hardware to run efficiently.
3) Sampling Issues
Databricks AutoML might sample large datasets to manage memory usage, which can sometimes lead to less accurate models if the sampling isn't representative of the entire dataset. This is a crucial consideration for projects requiring high precision.
4) Imbalanced Data Handling
While Databricks AutoML provides some support for handling imbalanced datasets by adjusting class weights, it does not balance the test and validation datasets. This could lead to misleading performance metrics if not carefully managed.
5) Semantic Type Detection Limitations
Databricks AutoML attempts to detect semantic types for columns but might miss some cases or misclassify columns. This can affect the model's performance, especially if the data requires specific preprocessing steps that AutoML doesn't handle well.
7) Dependency on Databricks Runtime Versions
The functionality and performance of Databricks AutoML can vary significantly with different versions of Databricks Runtime. Users need to ensure they are running compatible and up-to-date versions to leverage the full capabilities of Databricks AutoML.
8) Limited Support for Feature Types
Databricks AutoML does not support all feature types, such as images. This limitation means it might not be suitable for projects involving these types of data.
Save up to 50% on your Databricks spend in a few minutes!


Conclusion
And that's a wrap! Databricks AutoML is an extremely powerful tool that helps streamline the entire machine learning workflow—from data preparation and feature engineering to model training and tuning—without having to leave the Databricks platform itself. Automating these complex processes, Databricks AutoML not only democratizes access to machine learning for users with diverse technical backgrounds but also accelerates the development of reliable and effective models.
In this article, we have covered:
- What is AutoML?
- Challenges with existing AutoML solutions
- What is Databricks AutoML?
- What is the feature importance of Databricks AutoML?
- Inner workings of Databricks AutoML—how does AutoML work?
- Algorithms used by Databricks AutoML
- What are the feature types that Databricks AutoML support?
- Step-by-step guide to train and deploy ML models with Databricks AutoML—using UI
- Step-by-step guide to train ML models with Databricks AutoML—programmatically
- What are the advantages of Databricks AutoML?
- What are the disadvantages of Databricks AutoML?
… and so much more!
FAQs
What is Databricks AutoML?
Databricks AutoML is a tool that automates key stages of the machine learning pipeline like data preprocessing, feature engineering, model selection, hyperparameter tuning, and model evaluation within the Databricks platform.
What are the benefits of using Databricks AutoML?
It minimizes time and effort for model development, makes ML accessible to non-experts, provides transparency into the model-building process, offers scalability and efficient resource utilization, and supports imbalanced datasets.
What machine learning tasks does Databricks AutoML support?
Databricks AutoML supports classification, regression, and time series forecasting tasks.
What popular machine learning libraries does Databricks AutoML use?
It uses algorithms from libraries like scikit-learn, XGBoost, LightGBM, Prophet, and Auto-ARIMA.
How does Databricks AutoML handle data preparation?
It performs tasks like missing value imputation, data type detection, semantic type annotation, and handling imbalanced datasets for classification problems.
How does Databricks AutoML split the data?
By default, it uses a 60% training, 20% validation, and 20% test split. For time series, it supports chronological splitting based on a time column.
How does Databricks AutoML perform model training and tuning?
It iteratively trains multiple models using different algorithms and hyperparameter configurations in a distributed manner across worker nodes.
What evaluation metrics does Databricks AutoML use?
It uses appropriate metrics like accuracy, F1-score for classification, RMSE for regression, and SMAPE for forecasting to evaluate models.
How does Databricks AutoML ensure model interpretability?
It supports Shapley values (SHAP) to understand each feature's contribution to model predictions.
How does Databricks AutoML integrate with the Databricks ecosystem?
It automatically generates notebooks, integrates with the Databricks Feature Store, leverages Databricks' distributed computing, and integrates with MLflow.
How can you deploy models trained with Databricks AutoML?
The best model can be registered with the MLflow Model Registry and deployed as a REST endpoint using MLflow Model Serving.
How does Databricks AutoML handle large datasets?
It predicts memory requirements and can dynamically sample large datasets to fit available computational resources.
What are the primary advantages of Databricks AutoML?
Advantages include automated model training, support for multiple algorithms, MLflow integration, customizable notebooks, transparency, scalability, handling imbalanced data, and user-friendly UI/API access.
What are the disadvantages of Databricks AutoML?
Disadvantages include limited customization, resource-intensive operations, potential sampling issues, limitations in imbalanced data handling, semantic type detection issues, dependency on Databricks Runtime versions, and limited feature type support.
How can you access Databricks AutoML?
You can access it through the Databricks UI by creating a new AutoML Experiment or programmatically via the Python API.
What are the prerequisites for using Databricks AutoML?
Prerequisites include access to a Databricks workspace with the appropriate Databricks Runtime version, a cluster running Databricks Runtime ML, and meeting compatibility requirements.
Can you incorporate existing feature tables with Databricks AutoML?
Yes, in Databricks Runtime 11.3 LTS ML and above, you can join existing feature tables from the Databricks Feature Store with your training dataset.
How can you review and edit the code generated by Databricks AutoML?
Databricks AutoML generates editable Python notebooks for each trial run, which you can view, modify, and download to further customize the models.















