
Data Warehouse vs Data Lake vs Data Lakehouse: Technical Guide (2025)

Think about it—a huge part of your life is now recorded in tiny digital breadcrumbs. That selfie you snapped? It's data. Your fitness app tracking your steps? Same thing—data. And those YouTube recommendations that seem to know what you're in the mood for? Yep, all data too.
Today, data is the foundation of modern business and society. People often compare it to new “oil” or “electricity,” and for good reason—its value is immense. The catch is that data only holds value if it's well-organized. If it's not, poorly managed data can quickly become a burden rather than a valuable resource.
Data collection is a significant part of modern life, affecting everything from business deals to our personal habits. Almost everything we do is being tracked, stored, and analyzed. It's actually pretty insane when you stop to think about it. Your smartphone's probably got a better idea of your daily routine than your best friends do.
Let’s break down a typical day. You wake up and check your phone, right? Then you scroll through social media, order coffee or breakfast from an app, track your steps, and maybe even make a big purchase online. Each of these actions generates digital signals—data points that businesses eagerly collect to gain insights into consumer preferences and behaviors.
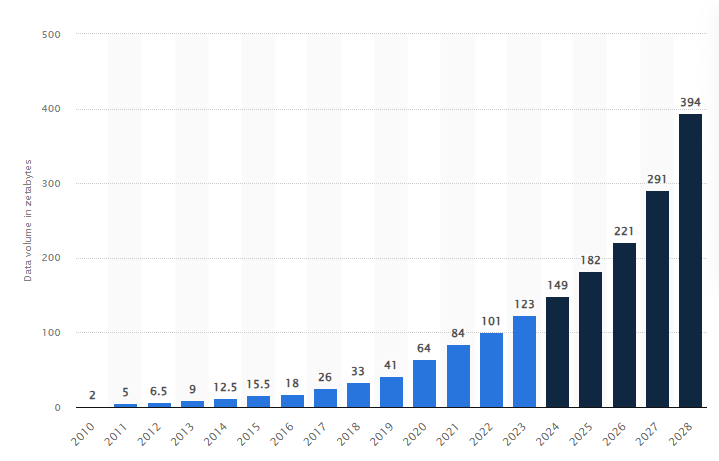
That’s wild, right? The scale of our data generation is off the charts. According to Statista, by 2028, global data creation is projected to reach approximately 394 zettabytes annually. To visualize this volume: if all the gigabytes of data produced were converted into grains of sand, you'd be able to blanket multiple continents.
However, it’s not just about having a lot of data; it’s about what we do with it. Choosing the right data storage solution is crucial. We have several options: traditional Data Warehouses, Data Lakes, and the newer Data Lakehouses. Each serves a specific purpose and has its own pros and cons. Knowing how these systems work is key to picking the right one for your organization's expanding data needs.
In this article, we’ll break down the differences between Data Warehouse vs Data Lake vs Data Lakehouse—what sets them apart, how they work, and their pros and cons. By the end, you'll know which approach is best for you.
What Is a Data Warehouse?
Data Warehouse (DW or DWH) is a centralized repository designed to store, manage, and analyze large volumes of data collected from various sources. It pulls data from various sources like transactional systems, relational databases, and other sources, optimizing it for querying and analytics. This setup prevents operational systems from slowing down due to heavy analysis. As a result, users can access data quickly—all at the same time if they need to.
The concept of data warehousing emerged in the late 1980s, primarily through the work of IBM researchers Bill Inmon and Ralph Kimball, who introduced the "business datawarehouse" model. This model aimed to streamline the flow of data from operational systems to decision-support environments, addressing issues like data redundancy and high costs associated with managing multiple decision-support systems independently.
Bill Inmon, often referred to as the "father of data warehousing" further developed the concept by defining a data warehouse as a subject-oriented, non-volatile, integrated, time-variant collection of data that supports management decision-making. His contributions included writing foundational texts on the subject and establishing early frameworks for data warehousing architecture.
Initially, these warehouses were costly and on-premises. However, with advances in cloud computing and ETL (Extract, Transform, Load) processes, they have become scalable, affordable, and well-integrated solutions.
The main purpose of a data warehouse is to give you a complete picture of your organization's data, making it easier to analyze and make informed decisions. It enables users to:
- Gather data from different places.
- Look at past data and trends.
- Make sure data is consistent and good quality.
- Support business intelligence tools for dashboards and advanced analytics.
Traditional data warehouses had a tough time dealing with unstructured or semi-structured and were pricey to maintain, which limited how much they could grow. These issues led to the creation of newer solutions like Data Lakehouses—a mix of Data Lakes and Warehouses that take the best of both worlds. Platforms like Databricks and Snowflake are leading the charge, offering scalable and versatile environments that support machine learning, real-time analytics, and integration with modern cloud ecosystems.
This shift has also allowed organizations to tackle the rising complexity of data, leveraging unified architectures to streamline workflows and optimize analytics across structured, semi-structured, and unstructured datasets.
Database vs Data Warehouse
Now that you understand what a data warehouse is, you might still be confused about the difference between Database vs Data Warehouse, as they may seem similar. To clear up this confusion, let's dive into the detailed differences between a Database vs Data Warehouse.
| Features | Database | Data Warehouse |
| Purpose/Use Case | Optimized for Online Transaction Processing (OLTP), supporting transactional operations like data entry and updates | Designed for Online Analytical Processing (OLAP), supporting complex analytics and reporting |
| Usage | Handles real-time data access and operational tasks such as CRUD operations (Create, Read, Update, Delete) | Focuses on strategic insights through historical data analysis and business intelligence |
| Data Structure | Uses a normalized schema to minimize redundancy and ensure efficient transactional operations | Uses denormalized schemas (e.g., star or snowflake) to optimize read-intensive queries |
| Data Type | Stores current, detailed, and frequently updated data essential for daily operations | Stores aggregated, historical, and current data from various sources for long-term analysis |
| Data Integration | Integrates application-specific data, often requiring custom integration for each source | Combines and unifies data from multiple disparate sources for holistic analysis |
| Query Complexity | Supports simple queries with low latency for real-time operations | Handles complex, multi-dimensional queries that analyze trends and patterns over time |
| Data Freshness | Maintains real-time or near-real-time data for operational purposes | Typically updated in scheduled batches, providing periodic snapshots of data |
| Storage Volume | Manages smaller, application-specific datasets | Handles large volumes of historical and aggregated data across different domains |
| Performance Focus | Prioritizes fast read-write operations with low latency to support concurrent transactions | Optimized for read performance, using indexing, partitioning, and distributed architectures |
| Data Transformations | Minimal transformations, with raw data processed directly for real-time use | Extensive transformations (ETL: Extract, Transform, Load) prepare data for analysis |
| Applications | Banking, e-commerce, telecommunications, and HR systems for operational data management | Business intelligence, trend analysis, sales forecasting, and customer behavior analysis |
| Data Source | Relies on specific operational systems or isolated applications | Integrates data from relational databases, APIs, and third-party systems for analytics |
Data Warehouse Features
Data warehouses are designed to handle large-scale data aggregation, storage, and analysis. Here are some of the key features of a data warehouse:
1) Centralized Repository — Data warehouse pulls together data from various sources, like transactional systems and relational databases. This creates a single view that makes analysis and reporting much easier.
2) Subject-Oriented — Data is grouped by specific business areas, like sales, finance, or customer data. This structure is ideal for analytics and reporting—it's not centered on individual transactions.
3) Integrated Data — The integration process standardizes data formats and resolves inconsistencies across sources. This ensures reliable and consistent analytics.
4) Time-Variant — Historical data is stored with timestamps, enabling trend analysis and comparisons over time. This is essential for tracking performance and understanding patterns.
5) Non-Volatile — Once data is loaded into a data warehouse, it is not altered. This immutability supports repeatable and reliable reporting.
6) Optimized for Queries — Unlike transactional databases, a data warehouse is optimized for complex queries and analytics. It supports Online Analytical Processing (OLAP) for multi-dimensional data analysis.
7) ETL Process — Data warehouses rely on ETL (Extract, Transform, Load) to gather data, clean and transform it into a consistent format, and store it efficiently for analysis.
8) Support for BI Tools — Data warehouses integrate with Business Intelligence (BI) tools, allowing users to create dashboards, reports, and visualizations for informed decision-making.
9) Highly Scalable — Modern Cloud data warehouses offer scalability, making it easy to handle growing data volumes and users. They also support efficient resource usage, ensuring cost-effectiveness.
10) Data Quality Management — Data warehouses guarantee good data quality by incorporating data cleansing and validation processes. Accurate and consistent data is critical for reliable insights.
Architecture Overview of Data Warehouse
Data warehouse architecture is typically organized into tiers (single-tier, two-tier, and three-tier architectures), each of them serves different purposes depending on your operational and analytical needs. Here’s a detailed breakdown:
1) Single-Tier Architecture
Single-tier architecture centralizes data storage and processing in one layer. It’s simple and often used for batch and real-time processing. In this setup, data is transformed into a usable format before reaching analytics tools. This process reduces the risk of bad data but limits flexibility. Single-tier systems are rarely used for complex real-time analytics because they lack scalability and separation of concerns.
2) Two-Tier Architecture
Two-tier architecture divides business processes and analytics into separate layers. This separation improves data management and analysis. Data moves from source systems through an ETL (extract, transform, load) process into the Warehouse. You can manage metadata to track data consistency, updates, and retention. This model also supports features like real-time reporting and data profiling. While it’s more capable than single-tier setups, two-tier architectures may struggle with high data volumes or complex integrations.
3) Three-Tier Architecture
Three-tier architecture is a widely-used and well-defined framework for data warehouses. It consists of three distinct layers (Bottom Tier, Middle Tier, Top Tier)—each serving specific roles in data management, processing, and user interaction:
➥ Bottom Tier — The bottom tier layer serves as the physical storage of the data warehouse, often implemented using relational databases. Data from various sources—like transactional systems, flat files, or external sources—is cleansed, transformed, and loaded (ETL/ELT processes) into this layer. The data stored here is highly structured and optimized for querying and analysis.
➥ Middle Tier — The middle tier acts as the application layer that processes the data and provides a logical abstraction for querying. It includes the Online Analytical Processing (OLAP) server, which can operate in two primary modes:
- MOLAP (Multidimensional OLAP) — Uses pre-aggregated data cubes for faster analysis.
- ROLAP (Relational OLAP) — Works directly with relational data for greater flexibility.
This layer arranges the raw data into a format suitable for analysis by applying business rules, aggregations, and indexes. It essentially bridges the raw storage and the user-facing tools by providing an optimized interface for data retrieval and computation.
➥ Top Tier: The top tier is the front-end layer where users interact with the data through reporting tools, dashboards, and analytical applications. This layer provides interfaces for querying and visualizing data, enabling users to derive insights. Tools at this level often include: Reporting Tools, Data Mining Tools and Visualization Tools.
Components of Data Warehouse
Data warehouse architecture typically consists of several core components:
➥ Source Systems — These are the databases and applications that generate raw data. They can include CRM systems, ERP software, and transactional DBs.
➥ Data Staging Area — This temporary storage area prepares data for loading into the Warehouse. It handles initial processing, including data cleansing and transformation.
➥ ETL Layer (Extract, Transform, Load) — This crucial layer extracts data from source systems, transforms it into a suitable format, and loads it into the Data warehouse. It ensures that the data is accurate and relevant.
➥ Central Database — This is the central repository where integrated data is stored. It allows for efficient querying and analysis.
➥ Metadata Repository — This component stores information about the data warehouse structure, including details about the data warehouse's structure, content, and usage.
➥ BI Tools — BI tools allow users to interact with the data warehouse. They help in reporting, visualization, and advanced analytics.
➥ Data Governance Layer — This layer encompasses policies and tools that checks data quality, security, and compliance throughout its lifecycle.
➥ Security and Access Control — This component manages user authentication, authorization, and encryption to protect sensitive information.
Types of Data Warehouses
1) Enterprise Data Warehouse (EDW)
Enterprise Data Warehouse (EDW) is a centralized repository that integrates data from multiple sources, supporting enterprise-wide data analysis and reporting. It is ideal for large organizations requiring comprehensive, integrated insights across departments. EDWs enable complex queries and uphold data governance and quality but can be costly and require significant planning and maintenance.
2) Operational Data Store (ODS)
Operational Data Store (ODS) is focused on current, operational data rather than historical data. It provides real-time access to transactional data, making it ideal for daily reporting and operational decision-making. An ODS complements an EDW by offering up-to-date information that supports short-term business needs. It refreshes frequently to ensure that users have access to the latest data.
3) Data Mart
Data mart is a smaller, more focused version of a data warehouse. It targets specific business units or departments, such as sales or marketing. Data marts allow teams to access relevant data without navigating through the entire EDW. They provide quick insights tailored to departmental needs, improving efficiency in data retrieval and analysis.
4) Cloud Data Warehouse
Cloud-based Data Warehouses are hosted on cloud platforms like AWS Redshift, Google BigQuery, or Snowflake. They offer scalability, flexibility, and reduced infrastructure costs, making them suitable for businesses seeking to manage fluctuating workloads or avoid heavy upfront investments in hardware.
5) Big Data Warehouse
Big Data Warehouse is designed to handle vast amounts of unstructured or semi-structured data. Big Data Warehouses utilize non-relational databases and can process diverse data formats efficiently. They support advanced analytics and machine learning applications, making them suitable for organizations dealing with large datasets from various sources.
Pros and Cons of Data Warehouse
Now that you have a good understanding of what a data warehouse is, let's dive into the data warehouse advantages and its disadvantages.
Data Warehouse Advantages
- Consolidates data from multiple sources into a single, unified view.
- Easily handles complex queries and advanced analytics.
- Removes duplicates and inconsistencies, improving overall data quality.
- Allows for historical data analysis and long-term trend forecasting.
- Separates analytical processing from operational systems, ensuring high query performance without disrupting day-to-day operations.
- Modern Warehouses, especially cloud-based ones, can scale to accommodate growing data volumes.
Data Warehouse Disadvantages
- Setting up and maintenance of a data warehouse requires significant investment in hardware, software, and skilled personnel.
- Designing and implementing a data warehouse is a time-consuming process, requiring expertise in ETL (Extract, Transform, Load) processes, schema design, and analytics optimization.
- Traditional Warehouses often rely on batch processing, leading to delays in data availability for real-time analytics.
- Data warehouses are optimized for structured data and struggle with unstructured datasets like text, videos, or social media content. For such needs, Data Lakes may be more suitable.
- Combining data from diverse sources with different formats can be complex, potentially leading to integration bottlenecks and delayed access to unified datasets.
- Storing large volumes of sensitive data makes warehouses a potential target for breaches. Maintaining robust security protocols and compliance adds another layer of complexity and cost.
What Is a Data Lake?
Data Lake is a centralized storage system designed to keep raw, unprocessed data in its original form. On the flip side, data warehouses, which organize and prepare data for specific use cases, data lakes can handle all types of data—structured, semi-structured, and unstructured. Because of this flexibility, data lakes are perfect for advanced analytics, machine learning, and exploratory data tasks.
Data lakes emerged as a solution to handle the growing volumes of big data. Back in the early 2000s, traditional data warehouses were hitting a wall. They were pricey, had trouble scaling, and were inflexible. But then Hadoop-based systems came along, offering a way to store huge datasets affordably and efficiently. Today, cloud platforms such as Amazon S3, Azure Data Lake Storage, and Google Cloud Storage have made data lakes more scalable, accessible, and efficient.
Data lake's main goal is to help you make smarter data-driven decisions. It does this by giving you access to all sorts of data you can analyze. Data lakes do this in three key ways:
- They collect and store data from many sources without changing it.
- They allow for advanced analysis, like predictive modeling and machine learning.
- They support projects that need to adapt quickly to new data types or analysis methods.
Data lakes have their perks, but they also come with challenges such as governance, data quality, and security. If not managed properly, they can end up as "data swamps", where data is either hard to get to or can't be used.
Data Lake Features
Data lake is a storage system designed to handle vast amounts of structured, unstructured, and semi-structured data in its raw form. Here are its key features:
➥ Raw Data Storage — Retains data in its original state, enabling support for diverse analytical and operational needs without prior transformation.
➥ Highly Scalabale — Data lakes can scale to accommodate immense data volumes, up to exabytes due to distributed architectures.
➥ Schema-on-Read — Data lakes allow schema-on-read meaning you don't need to define a schema upfront—data can be stored as-is and processed later based on use cases.
➥ Real-Time Data Processing — Data lakes can integrate with tools like Apache Kafka for real-time data ingestion and analysis, supporting use cases like fraud detection, predictive analytics, and more.
➥ Advanced Analytics — Data lake supports machine learning, predictive modeling, and big data analytics. Users can run queries using open source or commercial tools without needing to move the data.
➥ Unified Repository — Data lakes consolidate data from various sources into one location, reducing silos and enabling holistic analysis.
➥ Flexible Data Ingestion — Supports a wide variety of sources, including IoT sensors, social media feeds, XML files, and multimedia. Uses modern ETL/ELT techniques, with ELT often preferred for large, unstructured datasets.
➥ Metadata and Cataloging — Metadata tagging and cataloging make stored data searchable and easier to manage, reducing the risk of creating a "data swamp" where data becomes unusable.
➥ Support for AI and Machine Learning — Data lakes support AI and machine learning use cases by providing a centralized repository for large datasets. This enables batch processing, data refinement, and analysis for advanced analytics and modeling.
Architecture Overview of Data Lake
To understand the architecture of a data lake, you need to know its key components and what they do. It's made up of several layers that work together in the data lifecycle. Here's what you need to know about them:
1) Data Ingestion Layer
Data Ingestion Layer is where the data enters the lake. You can ingest data from multiple sources such as databases, IoT devices, social media, and applications. The ingestion can happen in real-time or in batches, depending on your needs. This layer supports various ingestion methods, including:
- Batch Processing — Collecting and loading data at scheduled intervals.
- Streaming — Continuously ingesting data as it becomes available.
2) Storage Layer
Storage layer holds the ingested data in its raw format. It accommodates different types of data:
- Structured Data — Data organized in a predefined manner (e.g., relational databases).
- Semi-Structured Data — Data that does not fit neatly into tables (e.g., JSON, XML).
- Unstructured Data — Raw data without a predefined structure (e.g., images, videos).
Data lakes typically use distributed storage systems like Hadoop Distributed File System (HDFS), Amazon S3, or Azure Blob Storage for scalability and durability.
3) Processing Layer
Once the data is stored, it often needs processing to make it useful for analysis. This layer handles various tasks such as:
- Data Transformation — Converting raw data into a more analyzable format.
- Data Cleaning — Removing inaccuracies and inconsistencies.
You can perform processing using frameworks like Apache Spark or Apache Flink, which support both batch and stream processing.
4) Data Management Layer
This layer focuses on organizing and governing the data within the lake. Key functions include:
- Metadata Management — Keeping track of the data's origin, structure, and changes over time.
- Data Governance — Ensuring that the data is accurate, secure, and compliant with regulations.
Tools such as AWS Glue or Apache Atlas are commonly used for managing metadata and tracking lineage.
5) Consumption Layer (Analytics and Visualization Layer)
The consumption layer is where users access and analyze the processed data. This includes:
- Business Intelligence (BI) Tools — Applications like Tableau or Power BI that help visualize and analyze data.
- Machine Learning Models — Utilizing the stored data for predictive analytics.
Users interact with this layer to generate reports and insights based on their analytical needs.
Pros and Cons of Data Lake
Data Lake Advantages
- Data lakes can store virtually any type of data, including structured data (like databases), semi-structured data (like JSON files), and unstructured data (like images and videos).
- Data lakes support advanced analytics, including real-time processing and machine learning workflows.
- Compared to traditional data warehouses, data lakes are often cheaper to implement and maintain since they leverage inexpensive object storage.
- All information stored within a Data Lake is available at any given time in its native format.
Data Lake Disadvantages
- Raw data in a lake can become a "data swamp" if not properly managed, resulting in unorganized, redundant, or inappropriate for data analysis.
- Data lake can only be used effectively if qualified individuals and a robust infrastructure are available.
- Querying raw data in a lake can be slower than querying a well-optimized data warehouse. For real-time analytics or high-speed queries, additional tools and configurations might be necessary.
- Storing data in a data lake can raise security concerns, especially if the data includes sensitive information. Ensuring the security of data in a Data Lake requires additional measures, such as encryption and access controls.
- Integrating with BI tools can be problematic if your data lake lacks proper structure and governance.
- Organizations often need to invest in upskilling their teams to handle data lake technologies, which can be a significant barrier for smaller companies
Data Warehouse vs Data Lake
You've got an understanding of data lakes, but the difference between data warehouse vs Data Lake might still be a bit unclear. Don't worry, they can be tough to tell apart at first. To clarify, let's compare the two.
| Feature | Data Lake | Data Warehouse |
| Data Type | Raw, structured, semi-structured, and unstructured data (e.g., logs, videos, images) | Structured and some semi-structured data (e.g., tabular formats) |
| Purpose | Central repository for all data types, supporting raw and processed data for advanced analytics | Optimized for analytics and business intelligence, focusing on structured data |
| Data Processing | Uses ELT (Extract, Load, Transform) to process data after storage as needed | Relies on ETL (Extract, Transform, Load) processes to preprocess data before storage |
| Schema | Schema-on-read—data can be stored in its raw format and structured later | Schema-on-write—data must be structured before storage |
| Query Performance | Suited for exploratory and batch processing using tools like Hadoop and Spark | Optimized for fast queries on preprocessed data using SQL-based tools |
| Accessibility | Highly accessible; easy to update and modify data. | More complex to change; requires significant effort to update. |
| Scalability | Highly scalable; can store vast amounts of data economically. | Scalable but often more expensive and complex to manage. |
| Access Control | Less structured control, requiring robust metadata management to avoid disorganization | Strong access control mechanisms with defined user roles |
| Real-Time Data | Supports real-time data ingestion for streaming use cases | Rarely supports real-time ingestion due to preprocessing requirements |
| Security | Generally less secure due to the volume and variety of data stored. | More secure; includes encryption and access controls for sensitive data. |
🔮 Data Lakes and Data Warehouses are meant for different things. A Data Lake is perfect for storing raw data in its original form, without setting up a specific structure, making it flexible and cost-effective for massive amounts of information. You can load all kinds of data from different sources, which is ideal for machine learning and big data analytics.
A Data Warehouse is different—it focuses on structured data that's been cleaned and organized for fast access and reporting. It uses a predefined schema to keep the data consistent and reliable.
What Is a Data Lakehouse?
Data Lakehouse is a data management system that combines the scalability and flexibility of a data lake with the structured data processing and analytics capabilities of a data warehouse. It enables you to store and process structured, semi-structured, and unstructured data in a single platform, supporting analytics use cases like business intelligence and machine learning.
The concept of the data lakehouse emerged around 2017, which was first picked up and promoted by Snowflake, with significant advancements occurring in 2020 when Databricks popularized it. Before this, data warehouses, which emerged in the 1980s, were great for structured data but lacked flexibility. Data lakes, introduced in the 2000s, brought cost-effective storage for diverse data types but often fell short on data governance and analytics performance. However, both systems had limitations: Data lakes often struggled with performance and quality, while Data Warehouses lacked flexibility for unstructured data. This is where Data Lakehouse comes in which fixing these problems by providing a unified system, merging the power of both data lake and data warehouse.
How Does a Data Lakehouse Work?
Data Lakehouse stores raw and processed data in open formats like Parquet or ORC, with a transactional layer (Delta Lake) to manage updates, schema enforcement, and reliability. This lets you analyze raw data directly or refine it into structured formats for BI tools—all in one place.
Why Did the Data Lakehouse Model Emerge?
Traditional architectures had clear weaknesses:
- Data Lakes — Offered cheap storage but struggled with performance, governance, and quality.
- Data Warehouses — Provided structured analytics but were expensive and rigid with unstructured data.
Data Lakehouse approach reduces duplication, lowers costs, and supports diverse analytics. It also simplifies infrastructure by replacing multiple systems with one.
When Should You Use a Data Lakehouse?
Data lakehouse makes sense if you’re managing large datasets and need a system that:
- Handles diverse data types (structured, semi-structured, and unstructured).
- Supports both batch processing and real-time analytics.
- Offers top-of-the-chart governance and data reliability for sensitive workloads.
- Works well with advanced analytics and machine learning.
🔮 TL;DR: Data Lakehouse provides a streamlined approach to managing and analyzing large volumes of diverse data. It combines the best features of both Data Lakes and Data Warehouses, making it an appealing choice for organizations looking to enhance their analytics capabilities while controlling costs.
Data Lakehouse Features
Data lakehouse combines the features of a data lake and a data warehouse into a single platform. Here are its key features:
➥ Unified Storage and Access — Store all types of data (structured, unstructured and semi-structured) in affordable, cloud-based object storage, enabling direct access without duplicating data across systems.
➥ ACID Transactions — Many data lakehouses implement ACID (Atomicity, Consistency, Isolation, Durability) transactions, which make sures that all operations on the data are reliable and maintain integrity even in distributed environments. You can perform multiple read and write operations simultaneously without compromising the quality of your data.
➥ Open Formats and Interoperability — Data lakehouses support open file formats like Apache Parquet or ORC (Optimized Row Columnar), which enhances interoperability with various tools and programming languages such as SQL, Python, and R.
➥ Metadata Layer — A key differentiator of lakehouses is a robust metadata layer that combines schema enforcement with the flexibility of lakes. This facilitates governance, data lineage, and easy integration with BI tools, enabling a balance between data exploration and compliance.
➥ Performance Optimization — Data Lakehouses provide near-warehouse query performance on raw or semi-structured data by utilizing indexing, in-memory caching, and vectorized query execution.
➥ Schema-on-Read and Schema-on-Write — Data Lakehouse provides the flexibility of schema-on-read and schema-on-write. For instance:
- Data ingested directly into raw storage uses schema-on-read, retaining the flexibility to process and structure data later.
- Data processed and stored in optimized formats for high-performance querying uses schema-on-write, which adds structure for analytics and reporting.
➥ Scalability and Flexibility — Handle vast amounts of data with a design that supports growth without significant hardware upgrades. Many platforms offer pay-as-you-go models for cost efficiency.
➥ Advanced Analytics Support — Data Lakehouses support machine learning and AI workloads directly on data without the need for complex ETL pipelines. Built-in compatibility with frameworks like Apache Spark enables real-time and batch processing.
➥ Improved Data Governance — Data governance is more robust in a data lakehouse compared to traditional systems. The centralized nature of the architecture allows for better control over access permissions and compliance measures. You can enforce security protocols more effectively across all datasets.
➥ Governance and Security — Provide unified governance models for consistent data access controls, lineage tracking, and compliance with privacy regulations.
➥ Multi-Cloud and Hybrid Support — Modern Data Lakehouses are compatible with on-premises, hybrid, and multi-cloud environments, allowing you to leverage existing infrastructure while maintaining flexibility for future migrations.
Architecture Overview of Data Lakehouse
Data lakehouse architecture combines the strengths of data lakes and data warehouses. Data Lakehouse consists of several layers that work together to facilitate data ingestion, storage, processing, and consumption. Now lets understand these layers is essential for leveraging the full potential of a data lakehouse.
1) Ingestion Layer
Ingestion layer is where data enters the lakehouse. It collects data from various sources, including:
You can use tools like Apache Kafka for streaming data or Amazon DMS for migrating data from traditional databases. This layer ensures that all types of data—structured and unstructured—are captured in their raw format.
2) Storage Layer
Storage layer is where the ingested data is stored. It typically uses low-cost object storage solutions like Amazon S3 or Azure Blob Storage. The key features of this layer are:
- Decoupled Storage and Compute, allowing you to scale storage independently from processing power.
- Data is stored in open file formats like Parquet or ORC, which are optimized for analytics.
3) Metadata Layer
Metadata layer manages all the information about the stored data. It includes:
- Data Lineage — Tracks where the data comes from and how it has been transformed.
- Schema Management — Make sure that incoming data adheres to predefined structures, maintaining consistency.
This layer also supports ACID transactions, which ensure that operations on the database are processed reliably.
4) API Layer
APIs play a crucial role in enabling access to the stored data. They allow analytics tools and applications to query the lakehouse directly. With well-defined APIs, you can:
- Retrieve datasets as needed.
- Execute complex queries without needing to move the data around.
This flexibility supports various analytics tools, making it easier for teams to work with the data they need.
5) Consumption Layer
Consumption layer is where users interact with the data. It includes business intelligence (BI) tools, machine learning platforms, and reporting systems. This layer allows:
- Real-Time Analytics — Users can analyze streaming data as it arrives.
- Batch Processing — Historical datasets can be processed in bulk for deeper insights.
Medallion Architecture
Many implementations of the Data Lakehouse architecture adopt a medallion architecture approach, which organizes data into three distinct layers:
🥉 Bronze Layer — Raw, unprocessed data.
🥈Silver Layer — Cleaned and transformed data ready for analysis.
🥇 Gold Layer — Highly curated datasets optimized for specific business needs.
For Data governance, it is extremely critical in a lakehouse architecture. It involves implementing policies for:
- Data Quality — Ensuring that only accurate and relevant data enters your system.
- Access Control — Managing who can view or manipulate certain datasets.
Tools like Unity Catalog help maintain a unified governance model across different datasets, ensuring compliance with regulations and internal standards.
Pros and Cons of Data Lakehouse
Pros of a Data Lakehouse
- Data lakehouses can handle both structured and unstructured data. This flexibility allows you to ingest various data types without needing to conform to strict schemas upfront.
- Data lakehouses can scale horizontally, accommodating massive amounts of data. This feature is crucial as your organization grows and data needs expand.
- Data lakehouses provide performance enhancements typical of data warehouses, such as optimized query execution and indexing.
- Data and resources get consolidated in one place with data lakehouses, making it easier to implement, test, and deliver governance and security controls.
- Data lakehouse support robust data governance frameworks. This capability helps maintain data quality and consistency across various datasets, which is essential for accurate analytics.
- Data lakehouse can can be really cost effective because it lower overall costs by consolidating storage solutions. Instead of maintaining multiple systems, you have one platform that handles various workloads efficiently.
Cons of Data Lakehouse
- Setting up a data lakehouse can be more complicated than traditional systems.
- Data lakehouse is a relatively new technology, the ecosystem around data lakehouses is still developing. You might face a learning curve and encounter immature tooling that can hinder adoption.
- Data lakehouse can save costs in the long run, the upfront investment in hardware, software, and expertise may be higher than that required for traditional solutions.
- The monolithic design of Data lakehouse might limit specific functionalities that specialized systems (like dedicated data warehouses) offer.
Data Lake vs Data Lakehouse
Let's get started on a detailed comparison of data lake vs data lakehouse.
Data Lake vs Data Lakehouse
| Feature | Data Lake | Data Lakehouse |
| Data Storage | Stores raw, unprocessed data in various formats (e.g., JSON, CSV, Parquet) | Combines raw data storage with table structures, enabling schema enforcement and ACID transactions |
| Data Organization | Organized hierarchically in folders/subfolders | Organized into tables with schemas for structured access |
| Data Processing | Requires significant ETL (Extract, Transform, Load) work for analytics | Supports in-platform processing with distributed engines like Apache Spark |
| Query Performance | Slower for analytics due to raw data format and lack of indexing | Optimized for analytics with features like indexing, caching, and query optimization |
| Governance and Quality | Lacks strict governance; prone to data inconsistency ("data swamp") | Enforces governance, with support for data validation and schema evolution |
| Transaction Support | Minimal or absent | ACID compliance ensures reliable concurrent transactions and data consistency |
| Cost Efficiency | Cheaper for storage but high costs for compute during processing | Balances costs with optimized compute for analytics, offering more predictable expenses |
| Use Cases | Ideal for exploratory analysis and staging unstructured data | Suitable for advanced analytics, real-time insights, and machine learning pipelines |
| Scalability | Scales well but may face performance bottlenecks as data grows | Scales horizontally with better performance management through advanced query engines |
| Integration | Works as a landing zone; often used with data warehouses for analytics | Provides a unified platform combining features of data lakes and warehouses |
🔮 Data Lake stores raw, unprocessed data in various formats. They are great for exploratory analysis but often need a lot of ETL work to prep the data, and it can struggle with inconsistent governance and slow query performance. On the other hand, a Data Lakehouse combines the best of both worlds—the scalability and flexibility of a data lake, and the structured governance, ACID compliance, and query optimization of a data warehouse, making it perfect for advanced analytics, real-time insights, and machine learning, all while keeping storage and compute costs in check.
Data Lakehouse vs Data Warehouse
Here is a table highlighting the technical differences between data lakehouse vs data warehouse.
Data Lakehouse vs Data Warehouse
| Feature | Data Warehouse | Data Lakehouse |
| Data Structure | Optimized for structured data with predefined schemas (schema-on-write) | Supports both structured and unstructured data with flexible schema management (schema-on-read and schema-on-write) |
| Storage Architecture | Relational databases with rigid schema enforcement | Unified architecture that integrates data lake storage with data warehouse processing capabilities |
| Data Processing | Schema-on-write: Data must be cleaned and organized before storage | Combines schema-on-read (for flexibility) and schema-on-write (for optimization), allowing for real-time analytics |
| Use Cases | Business intelligence, reporting, and historical analysis | Mixed workloads: Business intelligence, advanced analytics, machine learning, and real-time processing |
| Scalability | Limited scalability due to resource-intensive architecture | Highly scalable, leveraging cloud-native technologies and object storage for large volumes of data |
| Cost | Higher costs due to compute-heavy processing and rigid infrastructure | Cost-efficient by minimizing data duplication and utilizing low-cost storage solutions |
| Governance & Security | Mature tools for data governance and compliance, but often rigid | Evolving governance features with built-in security measures like encryption and fine-grained access controls |
| Query Performance | Optimized for fast SQL queries on structured data with high performance | Flexible querying capabilities supporting SQL and NoSQL with improved real-time query performance |
| Industries | Finance, healthcare, retail, and others requiring precise data management | Applicable across various industries needing diverse analytics and flexible data management strategies |
| Technologies | Examples include Snowflake, Amazon Redshift, and Google BigQuery | Pioneered by Databricks Lakehouse; also includes technologies like Apache Iceberg and Cloudera's platform |
🔮 Data warehouse focuses on structured, high-performance analytics for standardized use cases. A data lakehouse blends the flexibility of data lakes with the rigor of warehouses, making it more versatile for modern data needs like machine learning and real-time analytics. Each has strengths depending on your organization's specific requirements for scalability, data complexity, and cost management.
What Is the Difference Between Data Warehouse, Data Lake and Data Lakehouse?
Finally, we’ve reached the end of the article. Now that you have a clear understanding of data warehouse vs data lake vs data lakehouse, let’s wrap up with a TL;DR—a comparison table that highlights their key differences. Let’s dive in!
Data Warehouse vs Data Lake vs Data Lakehouse
| Data Warehouse | Data Lake | Data Lakehouse |
| Structured data is stored using a schema-on-write approach. Data must conform to a predefined schema before being loaded. | Uses a schema-on-read approach. Data is stored in its raw format and structured when accessed. | Supports both schema-on-read and schema-on-write, balancing flexibility and structure. |
| Optimized for SQL-based analytics and business intelligence. Excellent for structured reporting and trend analysis. | Suitable for storing and processing structured, semi-structured, and unstructured data, often used in big data analytics, data science, and machine learning workflows. | Combines features of data warehouses and data lakes, supporting mixed workloads, including SQL-based analytics, machine learning, and real-time processing. |
| Uses high-performance, proprietary storage solutions, which are expensive. | Uses cost-efficient cloud object storage for scalability and flexibility. | Balances cost-efficiency with advanced features like indexing and caching for performance. |
| Offers strong governance, security, and compliance features. | Limited governance and security tools; requires additional effort for management. | Provides governance capabilities inherited from data warehouses while supporting data lake flexibility. |
| Supports ACID transactions, allowing updates and deletes. | Limited update capabilities; data is typically appended or recreated. | Efficiently supports updates and deletes using ACID-compliant formats like Delta Lake. |
| Best for structured reporting and historical trend analysis. | Ideal for raw data storage, exploratory analysis, and batch processing. | Supports mixed workloads, including BI, exploratory analytics, and real-time data applications. |
| Performance is high for well-defined queries, but scalability comes at a cost. | Highly scalable but not optimized for complex queries, especially with unstructured data. | Scales effectively while providing query performance near that of data warehouses for structured data. |
| Typically used in finance, retail, and healthcare industries for traditional analytics. | Ideal for tech and media industries, handling streaming data and exploratory analytics. | Used across industries requiring unified data platforms for BI and advanced analytics (e.g., predictive modeling). |
That concludes the article on Data Warehouse vs Data Lake vs Data Lakehouse. By now, you should have a thorough and proper understanding of each of these storage systems.
Conclusion
And that’s a wrap! Now that you have a thorough understanding of Data Warehouse vs Data Lake vs Data Lakehouse, it’s clear that each serves distinct purposes and aligns with specific needs:
- Data Warehouses excel at handling structured data for business intelligence, offering fast and reliable SQL-based analytics.
- Data Lakes shine when flexibility is key, enabling the storage of vast, diverse datasets for big data projects, AI, and machine learning.
- Data Lakehouses bridge the gap between the two, combining the governance and performance of warehouses with the scalability and versatility of lakes.
It all boils down to your specific needs. For real-time insights from structured datasets, a data warehouse is the way to go. But if you're looking to store raw, diverse data for AI or exploratory analytics, a data lake is your top choice. If you want a unified solution for hybrid workloads? The emerging data lakehouse architecture could be the answer.
In the end, the best choice between data warehouse vs data lake vs data lakehouse is the one that matches your technical needs, budget, and long-term vision. Given how much data is driving our world, knowing your options helps you make wiser, more scalable decisions.
In this article, we have covered:
- What is a Data Warehouse?
- Database vs Data Warehouse — Key differences
- Features of a Data Warehouse
- Overview of Data Warehouse architecture
- Types of Data Warehouses
- Pros and cons of Data Warehouse
- Data Warehouse Advantages
- Data Warehouse Disadvantages
- What is a Data Lake?
- Features of a Data Lake
- Overview of Data Lake architecture
- Pros and cons of a Data Lake
- Data Lake Advantages
- Data Lake Disadvantages
- Data warehouse vs. Data Lake — Key differences
- What is a Data Lakehouse?
- Why did the Data Lakehouse model emerge?
- Features of a Data Lakehouse
- Overview of Data Lakehouse architecture
- Pros and cons of a Data Lakehouse
- Advantages of a Data Lakehouse
- Disadvantages of a Data Lakehouse
- Data lake vs Data Lakehouse — Key differences
- Data lakehouse vs Data Warehouse — Key differences
- What is the difference between a Data Warehouse, Data Lake, and Data Lakehouse? (Data Warehouse vs Data Lake vs Data Lakehouse)
… and much more!
FAQs
What do you mean by a Data Warehouse?
A data warehouse is a centralized system that stores structured data optimized for fast querying and analysis, primarily used for reporting and business intelligence.
What is a Data Warehouse vs a Data Lake?
A data warehouse stores structured, processed data ready for analysis, while a data lake stores raw, unprocessed data in various formats, including structured, semi-structured, and unstructured.
What is the short form of Data Warehouse?
The common abbreviation for Data Warehouse is DWH or DW.
Why is it called a Data Warehouse?
It's called a Data Warehouse because it acts as a storage hub for large volumes of data, structured and organized like a physical Warehouse.
What is OLAP and OLTP?
OLAP (Online Analytical Processing) supports complex queries and data analysis, while OLTP (Online Transaction Processing) handles real-time transactional operations.
What do you mean by a Data Lake?
Data lake is a storage system that holds raw, unprocessed data in its native format, including structured, semi-structured, and unstructured data.
What is a Data Lake vs. a database?
Data lake stores raw, diverse data for flexible analysis, while a database is optimized for managing structured, transactional data in real time.
What is a Data Lakehouse vs a Data Warehouse?
Data lakehouse combines the flexibility of data lakes with the structured data management and query efficiency of data warehouses.
When should you use a Data Lakehouse?
Use a data lakehouse when you need a unified platform to manage both structured and unstructured data while enabling analytics and machine learning.
What does "lakehouse" mean?
A lakehouse refers to a hybrid architecture that integrates features of data lakes and data warehouses for versatile data management.
What are the advantages of a Data Lakehouse?
Data lakehouse supports diverse data formats, enables advanced analytics, reduces data duplication, and integrates machine learning workflows.