




























Data platforms have usually been run in a centralized way, with one team in charge of everything to do with data—storing it, making it available, ensuring its good quality, governing it, and making it discoverable. This setup kept data producers (apps) and data providers (data platforms) separate. It allowed them to develop on their own. But it also caused big issues: bottlenecks, delays, and disconnections between data producers and users. That's where Data Mesh comes in—a fresh new solution to these long-standing issues. It was first introduced by Zhamak Dehghani in 2019. Data Mesh is different because it's decentralized, meaning teams in charge of specific areas take care of their own data like it's their own product. They're accountable for its quality, availability, and governance. This approach brings data closer to its source. It sets up shared governance. It provides a self-serve infrastructure for producers and users to get what they need quickly.
In this article, we will cover everything you need to know about Data Mesh, the core principles of Data Mesh, and discuss how it resolves the challenges that traditional data architectures have struggled to overcome.
What Is Data Mesh?
Data mesh is a decentralized sociotechnical approach to sharing, accessing, and managing analytical data in complex, large-scale environments—within or across organizations. Data Mesh Architecture emphasizes:
- Domain Driven data ownership (Domain Ownership)
- Treating data as a product
- Self-serve data platforms
- Federated data governance
Zhamak Dehghani introduced Data Mesh to overcome the limitations of traditional data architectures, which often struggle to scale and adapt to the complex needs of modern businesses.
So, why do we need Data Mesh? Traditional data management approaches often use centralized management, leading to bottlenecks and slow responses to changing requirements. These systems often create data silos and face challenges with data quality and data governance. Data Mesh solves these problems by allowing domain teams to manage their own data independently.
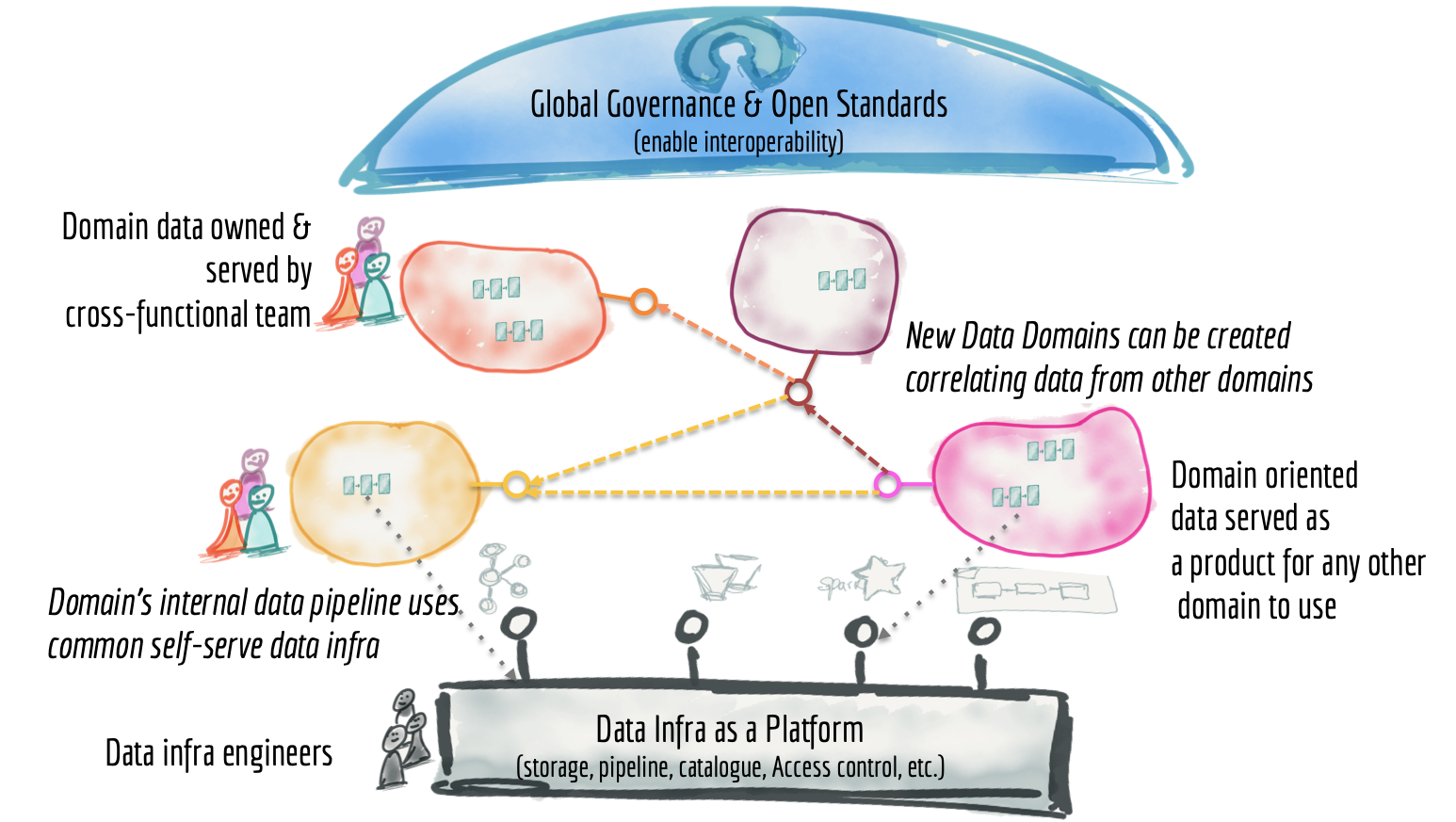
Data Mesh Architecture Overview
Unlike traditional architectures, where a central team controls everything, Data Mesh Architecture distributes data responsibilities across different domains within the organization. This setup encourages agility and scalability, aligning data strategies more closely with business goals. Each domain-specific team owns and manages their data, enabling more customized solutions that are closer to where the data is generated. This shift avoids the headaches of centralized data management, leading to a data system that's more agile and less prone to breakdowns.
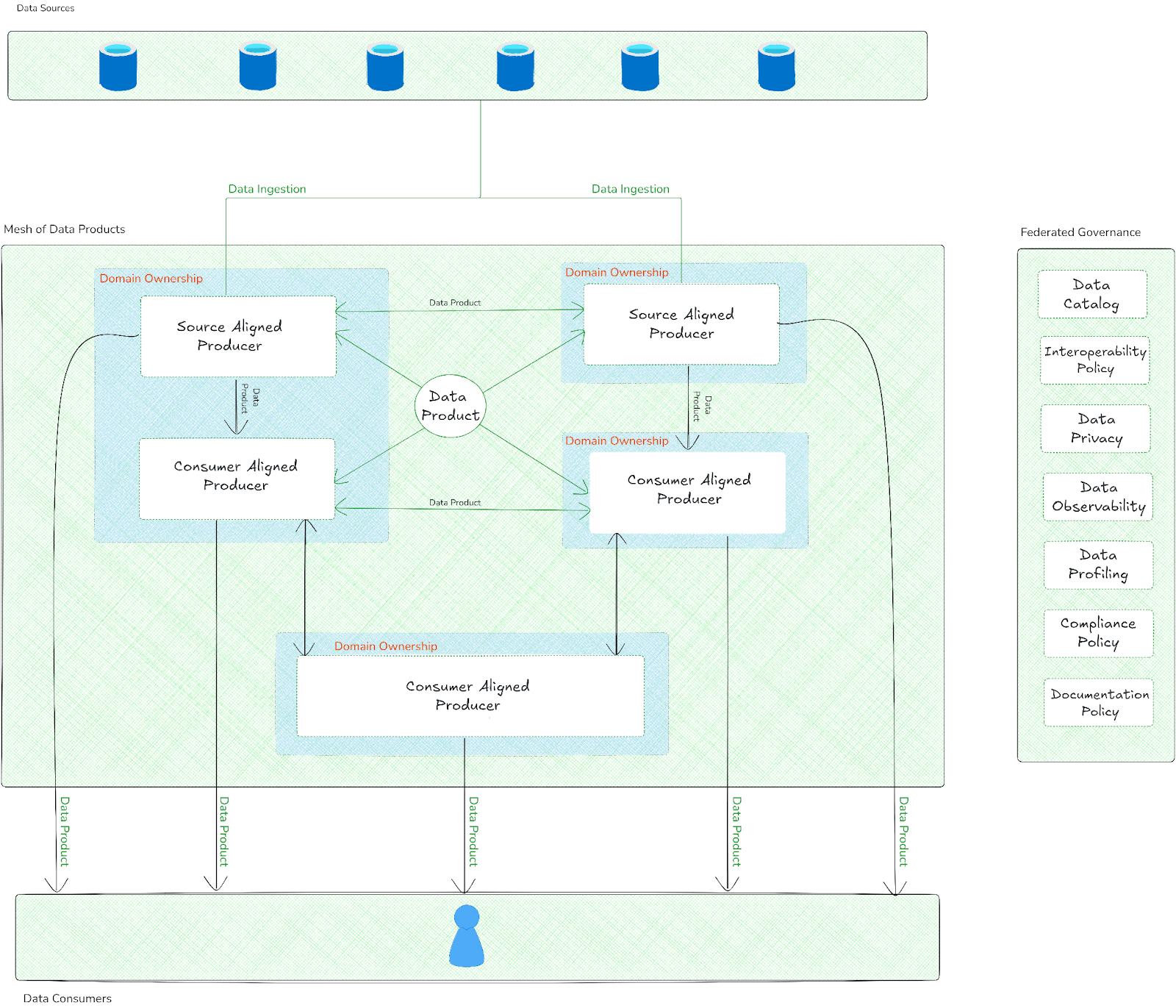
For more in-depth information, check out this video to learn more about Data Mesh Architecture.
Save up to 30% on your Snowflake spend in a few minutes!


Core Principles of Data Mesh Architecture—The 4 Key Pillars
Data Mesh Architecture is defined by four key principles that guide its implementation:
- Domain Driven data ownership (Domain Ownership)
- Data as a Product
- Self-Serve Data Platform
- Federated Computational Governance

1) Principle 1—Distributed Domain Driven Architecture
In Data Mesh Architecture, data ownership is decentralized, with individual teams or domains responsible for their data products. Each domain team handles the entire lifecycle of their data—from ingestion and processing to delivery. This autonomy allows teams to innovate and adapt more quickly, improving scalability and reducing bottlenecks that typically occur with centralized governance. Also, this principle aligns with the concept of Domain Driven design, where teams focus on their specific business domains.
2) Principle 2—Data as a Product
Data is treated as a product, meaning that each dataset is managed with the same care and discipline as a commercial product. This involves maintaining high standards for data quality, usability, and reliability. Domain teams are expected to provide well-defined data products with clear interfaces, versioning, and documentation, ensuring that data consumers can easily understand and integrate the data into their workflows.
To guarantee optimal usability, domain data products should have the following essential qualities:
📚 Discoverable
- Data products should be easily findable through a centralized data catalog. This catalog guarantees that datasets are easily searchable and accessible across the organization.
🔗 Addressable
- Each data product must have a unique identifier or API endpoint for programmatic access.
- Addresses should comply with centrally defined naming conventions to ensure consistency.
✅ Trustworthy
- Data products must establish and adhere to clear service-level objectives (SLOs) that define data accuracy and timeliness.
- SLOs reflect data accuracy, freshness, and completeness
📝 Self-describing
- Data products should include comprehensive metadata description that explains their syntax, semantics, and intended use.
- Descriptions should adhere to organizational standards for naming conventions and documentation to maintain clarity.
🔄 Interoperable
- Data products should be designed for seamless integration with other data assets and systems within the organization.
- Interoperability ensures that data can be easily combined and analyzed across different domains.
🔒 Secure
- Data products must implement robust security measures to protect sensitive information.
- Access control and encryption should be enforced to comply with organizational and regulatory requirements.
Treating data as a product encourages domain teams to focus on usability and value for data consumers, rather than just data collection and storage. It also promotes the creation of reusable data assets that can serve multiple use cases across the organization.
3) Principle 3—Self-Serve Data Platform
A self-serve data platform is a crucial component of a successful data mesh architecture. It provides domain teams with the necessary tools and infrastructure to create, manage, and consume data products without getting bogged down in the complexities of data management. Here are the key characteristics of a self-serve data platform:
- Abstraction of Complexity: The platform should hide the underlying technical complexity, allowing teams to focus on their data products rather than the infrastructure.
- Standardized Tools and Interfaces: The platform should provide a consistent set of tools and interfaces that enable domain teams to work with data efficiently and effectively.
- Automated Data Pipeline Creation and Management: The platform should automate the creation and management of data pipelines, reducing the manual effort involved and freeing up teams to focus on more strategic tasks.
- Infrastructure as Code: The platform should enable teams to define their data infrastructure using code, promoting consistency, reproducibility, and version control, which allows for easy deployment, testing, and rollback of changes to the data infrastructure.
- Data Observability: The platform should provide built-in monitoring and logging capabilities to track data quality, lineage, and usage.
- Scalable Compute and Storage: The platform should be able to handle varying data volumes and processing requirements, ensuring that domain teams can scale their data products as needed without worrying about the underlying infrastructure.
This principle is key to letting domain teams do their thing without needing to be experts in everything data infrastructure.
4) Principle 4—Federated Data Governance
While domain teams own and manage their data products, a federated model of data governance guarantees consistency and compliance across the organization. A central data governance team sets standards for data quality, data security, and data compliance.
These policies are then implemented computationally by the data platform through automation. For instance, sensitive data can be automatically classified and secured based on predefined rules.
Federated computational governance enables data governance at scale without introducing bureaucratic delays for domain teams. It ensures that data products meet necessary standards while enabling teams to innovate and add value.
Why Data Mesh?
Now that we've explored the core principles, let's dive into why organizations are adopting Data Mesh Architecture and what challenges they might face in adoption.
Challenges with Traditional Data Architectures
So, before we dive into the big advantages of Data Mesh Architecture let's not forget the challenges with Traditional Architecture:
╰➤ Complexity in Setup
Implementing a distributed system like Data Mesh Architecture is inherently more complex than a centralized architecture. Organizations need to invest in tools and practices to manage this complexity.
╰➤ Standardization vs Autonomy
Balancing domain autonomy with organization-wide standards can be tricky. Too much standardization may stifle innovation, while too little can lead to interoperability issues.
╰➤ Skill Issue
Domain teams need to develop new skills in data management and product thinking. This requires investment in training and potentially new hires.
╰➤ Cultural Shift
Data Mesh Architecture represents a significant shift in how organizations think about and manage data. This cultural change can be challenging and requires strong leadership support.
╰➤ Hard to keep up with Consistency
With multiple domains producing data products, ensuring consistency in data definitions, quality, and presentation across the mesh can be extremely challenging.
We will discuss this further in the Disadvantages of Data Mesh Architecture section below.
What Are the Benefits of a Data Mesh?
1) Improved Data Quality and Trust
When you put data ownership in the hands of people who really know what they're doing, you get better data products. These domain teams have a vested interest in making sure their data is accurate, up-to-date, and useful.
Here are some key aspects that contribute to improved data quality:
- Well-defined data schemas and metadata
- Comprehensive documentation
- Clearly defined data ownership
- Continuous monitoring and improvement of data quality metrics
2) Enhanced Scalability and Flexibility
The distributed, domain oriented nature of a Data Mesh Architecture allows organizations to scale their data architecture more effectively as data sources and use cases grow. Each domain can scale independently based on its specific needs, avoiding the bottlenecks often seen in centralized systems.
This flexibility also enables faster adaptation to changing business requirements, as domain teams can innovate and iterate on their data products without being constrained by a central data team's backlog.
3) Increased Agility and Time-to-Value
Data Mesh allows domain teams to control and manage their data products, resulting in a faster time-to-value for new data efforts. Domain teams may need to quickly design and deliver data products adapted to their individual requirements, eliminating the delays associated with centralized data management techniques.
4) Better Alignment with Organizational Structure
Data Mesh Architecture aligns data ownership with the natural structure of most organizations, reducing friction and improving collaboration.
5) Improved Data Discovery and Access
Data Mesh treats data as a product and by implementing standardized discovery mechanisms, it makes it easier for users across the organization to find and access the data they need.
6) Enhanced Data Security and Compliance
Federated data governance allows for more nuanced and effective implementation of data security and compliance policies, tailored to the specific needs of each domain and data product.
What Are the Disadvantages of Data Mesh?
Despite its benefits, Data Mesh Architecture also introduces several challenges that organizations need to be aware of:
1) High Costs
Transitioning to a Data Mesh Architecture can be expensive, requiring investment in new tools and training.
2) Complexity in Setup and Management
Setting up a Data Mesh is complicated. It requires a deep understanding of both technical and organizational aspects. Moving from a centralized to a decentralized data model involves major changes in governance, infrastructure, and team roles. You need to plan carefully to avoid disruptions during this transition.
3) Customization and Lack of Standardization
Data Mesh Architectures are often customized for each organization, which can lead to inconsistencies across different teams. This lack of standardization can affect data quality, data security, and data governance. Organizations should create clear guidelines and tools to promote standard practices, which requires coordination among teams.
4) Resource Allocation Challenges
Decentralizing data ownership means that domain teams are responsible for managing their data products. Smaller teams or those with limited data expertise may struggle with this responsibility, which can diminish the benefits of a Data Mesh. It’s crucial to make sure that all teams have enough resources, training, and support for successful implementation.
5) Data Governance Complexity
Implementing a governance model that balances central oversight with team autonomy can be tough. Organizations need to balance local team autonomy with centralized oversight, which can create confusion about data responsibilities. Investing in training and governance tools is essential for effective management across teams.
6) Data Silos and Fragmentation
Although Data Mesh Architecture aims to reduce data silos, its decentralized approach can create new silos if not handled properly. Fragmentation may occur if teams don’t collaborate well or if data products aren’t designed to work together. Ensuring that data products are integrated and accessible across the organization is vital.
7) Interoperability Issues
For Data Mesh Architecture to work well, data from different teams must be able to work together. Organizations may need help to ensure that data products from various domains are compatible, which can limit insights from cross-domain data.
8) Inconsistent Data Quality
With decentralized data management, maintaining consistent data quality can be a challenge. Different teams might use different standards, leading to data silos and inconsistencies. This can complicate data integration and analysis.
9) Initial Investment and Time Cost
Transitioning to a Data Mesh Architecture requires a significant initial investment in time, resources, and technology.
10) Integration Complexity
Integrating a Data Mesh with existing data systems can be complex, especially for organizations moving from centralized models. This may require major adjustments to data pipelines, governance frameworks, and access controls. Careful planning is crucial to minimize disruptions during integration.
11) Skill Gaps
As teams take on more responsibility for their data, they may need additional training. Organizations might find it challenging to provide the necessary training, which can lead to a decline in data quality and usability.
12) Monitoring and Observability
In a decentralized setup, monitoring data products becomes more challenging since they are spread across various teams. You need to implement strong observability tools to make sure that data products work as intended and that issues are quickly identified and resolved.
How to Design a Data Mesh—Step-by-Step Approach
To implement a Data Mesh Architecture effectively, you must follow a structured approach that encompasses several key principles and practices. Below is a detailed explanation based on the outlined steps for designing a Data Mesh.
#1 Understand the 4 Pillars of Data Mesh Architecture
The main ideas behind a Data Mesh Architecture are:
- Each business area (domain) manages its own data
- Data is treated like a product
- Teams can independently create and manage data products
- Governance policies are shared across domains
#2 Identify Domains
Identify the critical business domains within the organization that require dedicated data management. Domains should be defined based on business functions, products, or services, allowing teams to focus on their specific areas of expertise.
#3 Define Data as a Product
Each domain should treat its data as a product, which includes defining data quality standards, usability, and documentation. Establishing data contracts that specify the expectations for data quality and availability will help maintain high standards across the organization.
#4 Establish a Self-Serve Data Platform
Develop a self-serve data platform that provides the necessary tools and infrastructure for domain teams to manage their data. Key capabilities to include are:
- Data encryption to guarantee data security.
- Data product schema for consistency.
- Governance and access control mechanisms.
- Data product discovery tools for easy access to datasets.
- Monitoring and logging for performance tracking.
- Caching to improve data retrieval speeds.
#5 Implement Federated Computational Governance Policies
Create a governance framework that balances centralized oversight with domain-specific autonomy. Establish policies for:
- Reporting standards
- Compliance requirements
- Access controls for data product owners
#6 Execute Pilot Projects
Start with pilot projects in selected domains to test the Data Mesh implementation. These pilot projects should focus on specific use cases that can demonstrate the benefits of the Data Mesh approach. Gather feedback and learnings from these projects to refine the implementation strategy before scaling up.
#7 Choose the Right Technologies
Select technologies that support the decentralized architecture of a Data Mesh. Consider:
- Decentralized data repositories
- Cloud platforms to reduce costs
- Integration with existing systems
#8 Analyze Existing Data
Catalog data assets, identify relevant domains, and establish data harmonization rules.
#9 Focus on Data Quality
Implement data quality checks and standardize data formats.
#10 Prioritize Analytics
Emphasize real-time data processing and empower users to conduct their own analyses.
#11 Monitor & Iterate
Once implemented, continuously track performance, use feedback to make improvements, and gradually scale the Data Mesh.
Building a Data Mesh requires a shift in mindset and culture. If you follow these steps carefully, you can create a more flexible, user-centric approach to data management.
Technology Stack for Data Mesh
Implementing a Data Mesh requires a diverse set of technologies tailored to support its decentralized architecture and principles. Here’s a list of essential components and tools that can be part of a Data Mesh technology stack:
1) Data Storage and Processing
- Cloud Solutions: AWS, Azure, Google Cloud
- Data Warehousing: Snowflake, Databricks
- Data Lakes: Apache Hadoop, Amazon S3
2) Data Integration and Workflow
- ETL/ELT Tools: Apache NiFi, Talend, Fivetran
- Streaming Solutions: Apache Kafka
3) API Management
4) Data Quality and Governance
- Data Catalogs: Alation, Collibra
- Monitoring Tools: Prometheus, Grafana
- Observability Tools: Chaos Genius
5) Analytics and Visualization
Further Reading
- How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh
- Data Mesh (Wikki)
- What is a Data Mesh? (Microsoft)
- What is a Data Mesh — and How Not to Mesh it Up
- What is a Data Mesh? (AWS)
- Data Mesh Architecture: Data Mesh From an Engineering Perspective
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Conclusion
Data Mesh marks a dramatic shift in how enterprises view data architecture. Data Mesh helps organizations extend their data capabilities, drive agility, and create high-quality, relevant data products by decentralizing data ownership, supporting a product mindset, and fostering a culture of collaboration. As the data landscape evolves, implementing Data Mesh concepts could be a critical step toward long-term success and competition.
In this article, we have covered:
- What Is Data Mesh?
- Core Principles of Data Mesh Architecture—The 4 Key Pillars
- Principle 1—Distributed Domain Driven Architecture
- Principle 2—Data as a Product
- Principle 3—Self-Serve Data Platform
- Principle 4—Federated Data Governance
- Why use Data Mesh?
- What Are the Benefits of a Data Mesh?
- What Are the Disadvantages of Data Mesh?
- Technology Stack for Data Mesh
…and so much more
FAQs
What is the Data Mesh Architecture?
Data Mesh is a decentralized data architecture approach that emphasizes domain oriented ownership, data as a product, self-serve platforms, and federated computational governance.
Who introduced the Data Mesh?
Zhamak Dehghani introduced Data Mesh in 2019.
What problem does Data Mesh aim to solve?
Data Mesh addresses the limitations of centralized data architectures, such as bottlenecks, slow adaptability, and misalignment with business domains.
What are the 4 pillars of Data Mesh?
Domain Driven decentralized data ownership, data as a product, self-serve data platform, and federated computational governance.
What are the benefits of Data Mesh?
Improved data quality, enhanced scalability, increased agility, better organizational alignment, and improved data discovery.
What challenges might organizations face when implementing Data Mesh?
Complexity in setup, balancing standardization with autonomy, skill development needs, and cultural shifts.
Is Data Mesh suitable for all organizations?
Not necessarily. It's most beneficial for large organizations with complex data needs and multiple domains.
Can Data Mesh coexist with existing data architectures?
Yes, but integration can be complex and usually requires careful planning and gradual implementation.
How does Data Mesh impact data security and compliance?
It allows for more subtle, domain-specific implementation of security and compliance policies.
What's the first step in implementing Data Mesh?
Understanding the core principles and identifying key business domains within the organization.









