





























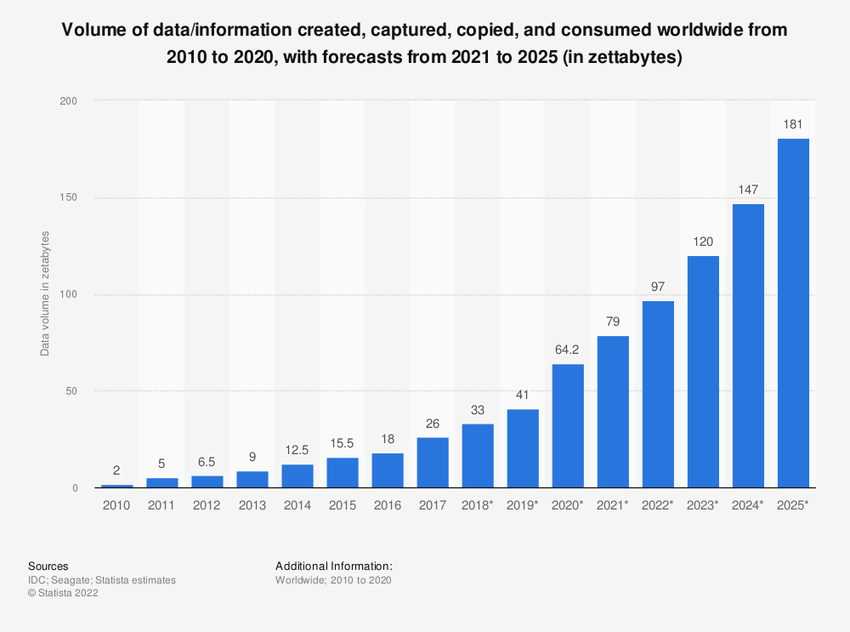
You've probably noticed it: data isn't just growing, it's exploding. According to Statista, the global datasphere (total amount of data created, captured, copied, and consumed worldwide) is forecast to hit 181 zettabytes by the end of 2025 and is expected to grow to more than 394 zettabytes by 2028. How big is that? To put it in perspective, a single zettabyte equals the storage capacity of roughly 50 million high-capacity 20 Terabyte hard drives! That's a mind-boggling amount of information.
But just having all this data isn't enough; you need to process it to get real value out of it. Traditionally, we've relied on Relational Database Management Systems (RDBMS) like PostgreSQL or MySQL. These are workhorses, fantastic for recording transactions accurately and reliably. They store data in rows, which is efficient for fetching or updating a specific record. But, ask these traditional row-oriented databases to perform real-time analytics and they often start to struggle. This is exactly the problem ClickHouse was built to solve. ClickHouse is an open source, columnar database management system specifically designed for high-speed OLAP (Online Analytical Processing). Instead of storing data row by row, it stores it column by column, which drastically speeds up analytical queries that typically only need data from a few columns. The payoff for tackling this analytical challenge can be significant; a survey highlighted by PR Newswire found that 80% of businesses reported revenue increases thanks to implementing real-time data analytics. ClickHouse usually does much better than traditional databases when complex analytical work needs to be done. To figure out how ClickHouse is so fast, you need to know how it is built.
In this article, we will take a deep dive into the ClickHouse Architecture, exploring its origins, what it is, its characteristics, and how organizations use it for data storage and processing, among other things. We will then break down the fundamental components of the ClickHouse Architecture, examine how it handles data storage with its MergeTree engine, see how the query engine processes queries, discuss its benefits and weaknesses, and compare the ClickHouse Architecture to other database types you may be familiar with.
What is ClickHouse?
First, where did ClickHouse come from? It started around 2008-2009 at Yandex, basically Russia's version of Google. An engineer named Alexey Milovidov was working on Yandex.Metrica (Yandex's web analytics platform), which is similar to Google Analytics. They needed a way to quickly generate reports from massive amounts of raw data, without pre-aggregating everything. They looked around, but couldn't find a database that fit their needs—something that could handle huge datasets, scale well, and work with SQL.
So, Alexey Milovidov decided to build one himself. It started as a small experimental project. Over the next few years, it evolved, got the name ClickHouse (short for "Clickstream Data Warehouse"), added SQL support, and some key features like the MergeTree storage engine, which became central to the ClickHouse Architecture. By 2011-2012, it was up and running in production for Yandex.Metrica.

After proving itself internally at Yandex, they decided to open source it in June 2016 under the Apache 2 license. That's when things really took off worldwide. Companies like Uber, eBay, and Cloudflare started using it, thanks to its significant speed advantages derived from the efficient ClickHouse Architecture.
Fast forward to 2021, ClickHouse, Inc. was formed as an independent company (headquartered in the San Francisco Bay Area) to focus on the development of the open-source project and offer commercial cloud services (ClickHouse Cloud).
Here is the timeline of ClickHouse:
- 2009 — Start of development
- 2012 — Production launch (Yandex.Metrica)
- 2016 — Open Source release
- 2017 — First integration engine (Kafka)
- 2018 — Mutations introduced
- 2019 — New execution framework
- 2020 — Improved introspection tools
- 2021 — ClickHouse Cloud launched; Async inserts, Projections introduced
- 2022 — Column statistics; CPU and I/O scheduling
- (Ongoing) — Continuous feature development (JOIN improvements, etc.)
So, What Is ClickHouse?
Alright, let's get to the core definition. ClickHouse is an open source distributed, columnar database management system (DBMS) built for speed on analytical OLAP (Online Analytical Processing) queries. It lets you analyze petabytes of data quickly by storing and processing data in columns, a fundamental aspect of the ClickHouse Architecture. The system runs SQL queries on raw data directly while taking advantage of modern hardware, which means you get results in real-time even when working with huge volumes of data.
Let's unpack that a bit:
1) Open Source
ClickHouse is fully open source (under the Apache 2.0 license).
2) Column-Oriented (or Columnar)
This is fundamental to the ClickHouse Architecture. Unlike traditional row-oriented databases (MySQL, PostgreSQL) that store all values for a row together, ClickHouse stores all values belonging to a single column together.
Why it matters for OLAP (Online Analytical Processing): Analytical queries often aggregate or filter data based on a few columns out of potentially hundreds. ClickHouse only needs to read the data files for those specific columns, drastically reducing disk I/O compared to reading entire rows.
Traditional Row-Oriented Database:
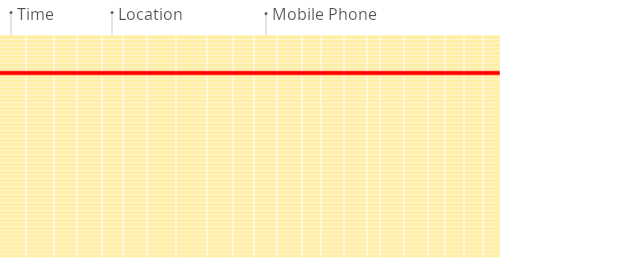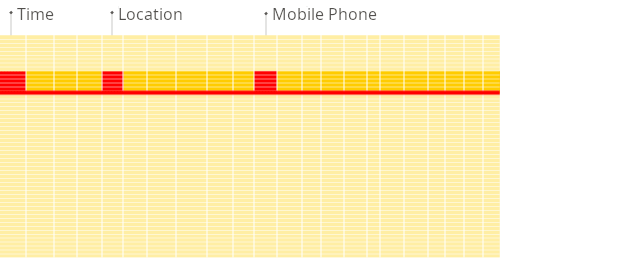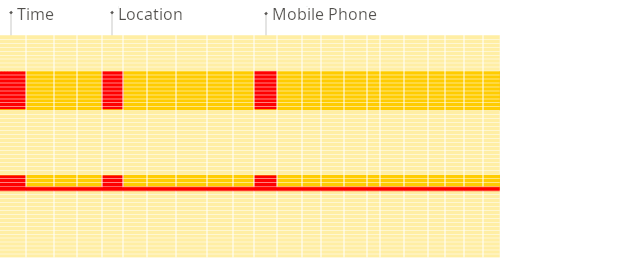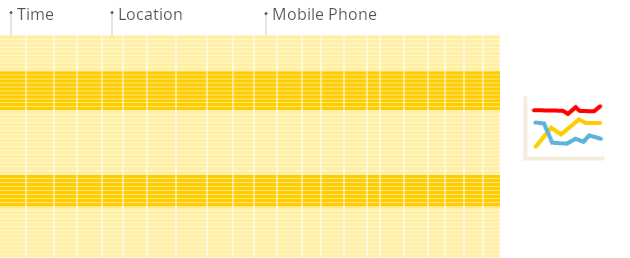
ClickHouse Columnar Database—ClickHouse Architecture
3) DBMS (Database Management System)
ClickHouse is a full-fledged system for creating and managing databases, tables, users, permissions, and executing queries. It's not just a storage library.
4) Optimized for OLAP (Online Analytical Processing)
The ClickHouse Architecture is designed to execute complex analytical queries (aggregations like SUM, AVG, COUNT, GROUP BY, window functions) across massive datasets (billions or trillions of rows) and return results with low latency (often sub-second to seconds).
5) Real-Time Analytics
The ClickHouse Architecture is engineered to ingest high volumes of data rapidly and make it available for querying almost immediately.
6) Distributed
The ClickHouse Architecture is natively designed to scale horizontally across multiple servers (nodes) in a cluster for both storage capacity and query processing power.
ClickHouse is NOT designed for OLTP (Online Transaction Processing). It's generally inefficient for frequent, single-row inserts, updates, or deletes, or queries requiring strict transactional consistency across multiple operations.
Core ClickHouse Architecture Principles: Why ClickHouse is Fast
ClickHouse's speed stems from a combination of deliberate choices within the ClickHouse Architecture and low-level optimizations:
Principle 1: Column-Oriented Storage Architecture
As mentioned above, this core element of the ClickHouse Architecture means less data read from disk for typical analytical queries. It also allows for much better data compression because data within a column is often similar.
Principle 2: Data Compression Techniques
ClickHouse Architecture leverages highly effective general-purpose codecs (like LZ4 - the default, ZSTD) and specialized codecs tailored for specific data types (like Gorilla for floats, Delta coding for timestamps/monotonic sequences, T64 for 64-bit integers). Compression can even be chained (Delta + LZ4). This saves storage space and reduces the amount of data transferred from disk/network, often speeding up queries.
Principle 3: Vectorized Query Execution
Instead of processing data row-by-row, one value at a time, ClickHouse processes data in chunks or "vectors" (batches of column values). Because of this, function call overhead is minimized and modern CPU capabilities (like SIMD aka Single Instruction, Multiple Data instructions) are better utilized, significantly speeding up calculations.
Principle 4: Distributed Query Processing and Parallelization
In ClickHouse, queries are automatically parallelized across multiple CPU cores and even multiple servers in a cluster. It tries to use all available hardware resources to get your answer faster.
Principle 5: Sparse Primary Index and Data Skipping
ClickHouse uses a sparse primary index associated with its MergeTree tables. It doesn't index every row. Instead, it stores index "marks" for every Nth row (a "granule," typically 8192 rows). Since data within a storage part is sorted by the primary key, this sparse index allows ClickHouse to quickly identify and load only the relevant granules from disk for queries filtering on the primary key, skipping large irrelevant blocks. Skipping indices (like min-max, set, bloom filters) provide similar capabilities for non-primary key columns.
Principle 6: Hardware Optimization and C++ Implementation
ClickHouse is written in C++ and designed to utilize CPU resources (cache, SIMD), memory bandwidth, and I/O efficiently. It avoids JVM overhead and aims for bare-metal performance.
Principle 7: SQL with Analytical Extensions
ClickHouse provides a familiar SQL interface but extends it with powerful features for analytics, including rich support for arrays, nested data structures, approximate query processing functions, window functions, and integration capabilities.
Principle 8: Scalability - Vertical and Horizontal
ClickHouse scales vertically by utilizing more resources on a single node and horizontally by distributing data and queries across multiple nodes (sharding).
Principle 9: Fault Tolerance and Replication Architecture
ClickHouse supports asynchronous multi-master replication for its ReplicatedMergeTree tables, typically coordinated by ClickHouse Keeper (a C++ implementation of the Raft consensus algorithm). This allows multiple copies (replicas) of data shards for high availability and read scaling.
What is ClickHouse used for?
First up, let's look at what are the key features enabled by the ClickHouse Architecture.
ClickHouse Features: Technical Capabilities
Feature 1: Columnar Storage Implementation
As we have already covered above, ClickHouse stores data by column, instead of storing data row by row like traditional databases. Why does this matter? When you run analytical queries (like calculating an average or sum over a specific column), the system only needs to read the data for that column, not slice through unrelated data in rows. Due to this, I/O is drastically reduced and things are sped up.
Feature 2: Vectorized Query Execution Engine
ClickHouse processes data in batches, or "vectors," rather than single values at a time. Due to this, it leverages CPU cache better and uses SIMD (Single Instruction, Multiple Data) CPU instructions more effectively. Basically, it tells the CPU to perform the same operation on multiple data points simultaneously.
Feature 3: Advanced Data Compression
ClickHouse uses excellent data compression. Since data in columns tends to be similar (like lots of the same URLs or event types), it compresses really well. Due to this, it saves storage space and often speeds up queries, as less data needs to travel from disk to memory.
Feature 4: SQL Support with Extended Syntax
You can easily interact with ClickHouse using SQL, which is familiar territory for many. Its dialect is powerful and includes extensions for array handling and analytical functions. It's not exactly standard SQL everywhere, so you might need to adjust some habits, but it's close and quite capable.
Feature 5: Distributed Processing Architecture
ClickHouse is built to scale horizontally. It supports sharding and replication, allowing you to distribute your data across multiple nodes. When you run a query, each node processes its partition of the data in parallel, and the results are merged seamlessly. This offers both high throughput and fault tolerance.
Feature 6: Real-Time Data Ingestion and Low-Latency Analytics
ClickHouse is optimized for continuously inserting high-volume data. It processes incoming data in batches and uses asynchronous background merges, which gives you near real-time query responses even with billions of rows.
Feature 7: Materialized Views for Pre-Aggregation
These aren't your typical SQL views. ClickHouse materialized views can store pre-aggregated data. As new data flows into a source table, the materialized view automatically aggregates it. Queries hitting the view are then super fast because the hard work is already done incrementally.
Feature 8: Fault Tolerance and Replication System
ClickHouse uses an asynchronous multi-master replication approach coordinated by ZooKeeper to make sure that your data is available even if one or more nodes fail. Due to this, you can write to any node and have the data distributed across replicas automatically. (Note: Modern ClickHouse often uses ClickHouse Keeper instead of ZooKeeper)
Feature 9: Pluggable Storage Engines
While the default MergeTree family of engines is usually the star for OLAP (Online Analytical Processing) tasks, ClickHouse supports other engines for different needs, like integrating with Kafka or handling smaller lookup tables.
and many more…
Alright, those are some core technical abilities. Now, where do people actually use this thing?
ClickHouse Use Cases: When to Use This Database
Clickhouse's speed with analytical queries and its ability to handle huge amounts of data in real-time, characteristics derived from the ClickHouse Architecture, make it well-suited for a few key areas.
Use Case 1: Real-Time Analytics Dashboards
ClickHouse excels in scenarios where you need immediate insights from massive data streams. You can use it to build dashboards for monitoring website traffic, user behavior, or network metrics with sub-second query response times.
Use Case 2: Business Intelligence (BI) Applications
ClickHouse can directly power Business Intelligence dashboards and ad-hoc analytical queries.
Use Case 3: Log Analysis and Management
Centralizing and analyzing application logs, server logs, or security logs becomes much easier when you can ingest them quickly and run complex search and aggregation queries without waiting forever.
Use Case 4: Security Information and Event Management (SIEM)
Similar to log analysis, SIEM systems need to process and correlate vast amounts of security-related events in near real-time to detect threats. The ingestion speed and analytical query performance fit well here.
Use Case 5: AdTech and Marketing Analytics
Analyzing impressions, clicks, conversions, and user journeys generates enormous datasets. ClickHouse helps analyze ad performance, calculate A/B test results quickly, and understand market dynamics in near real-time.
Use Case 6: Time-Series Data Analysis
Applications that involve sensor data, financial market streams, or IoT telemetry can benefit from ClickHouse. Its design is optimized for handling large numbers of time-stamped records, letting you analyze trends and patterns over time efficiently.
Use Case 7: Financial Data Analysis and Market Data
Processing market data, tick data, or transaction logs where performance on time-series aggregations is key.
Use Case 8: Product Analytics and User Behavior Tracking
If you need to track how users interact with your product, ClickHouse offers the performance needed to store and analyze detailed clickstream or event data.
Use Case 9: Machine Learning Data Preprocessing
While not its primary function, ClickHouse can be used as a data store for ML workloads. Its speed is useful for feature stores, preprocessing data, running vector searches, or powering analytics needed for model training, especially at petabyte scale. Some use it for observability in LLM applications.
And many more…
When NOT to Use ClickHouse?
It's good to remember ClickHouse is specialized. It's an analytical database (OLAP), not a transactional one (OLTP (Online Transaction Processing)) like PostgreSQL or MySQL.
- It's generally not great for frequent updates or deletes of single rows. Its storage format is optimized for bulk reads and writes.
- It doesn't typically enforce ACID (Atomicity, Consistency, Isolation, Durability) guarantees the way traditional relational databases do for transactions.
- Its sparse index is not optimized for fetching single rows by key quickly. Use cases requiring many fast point lookups are better served by other databases.
- Joins can be more limited or less performant than in row-based databases, although this has improved over time.
Often, ClickHouse is used alongside a traditional OLTP (Online Transaction Processing) database. Transactional data is captured in the RDBMS, then streamed or batch-loaded into ClickHouse for analytical processing.
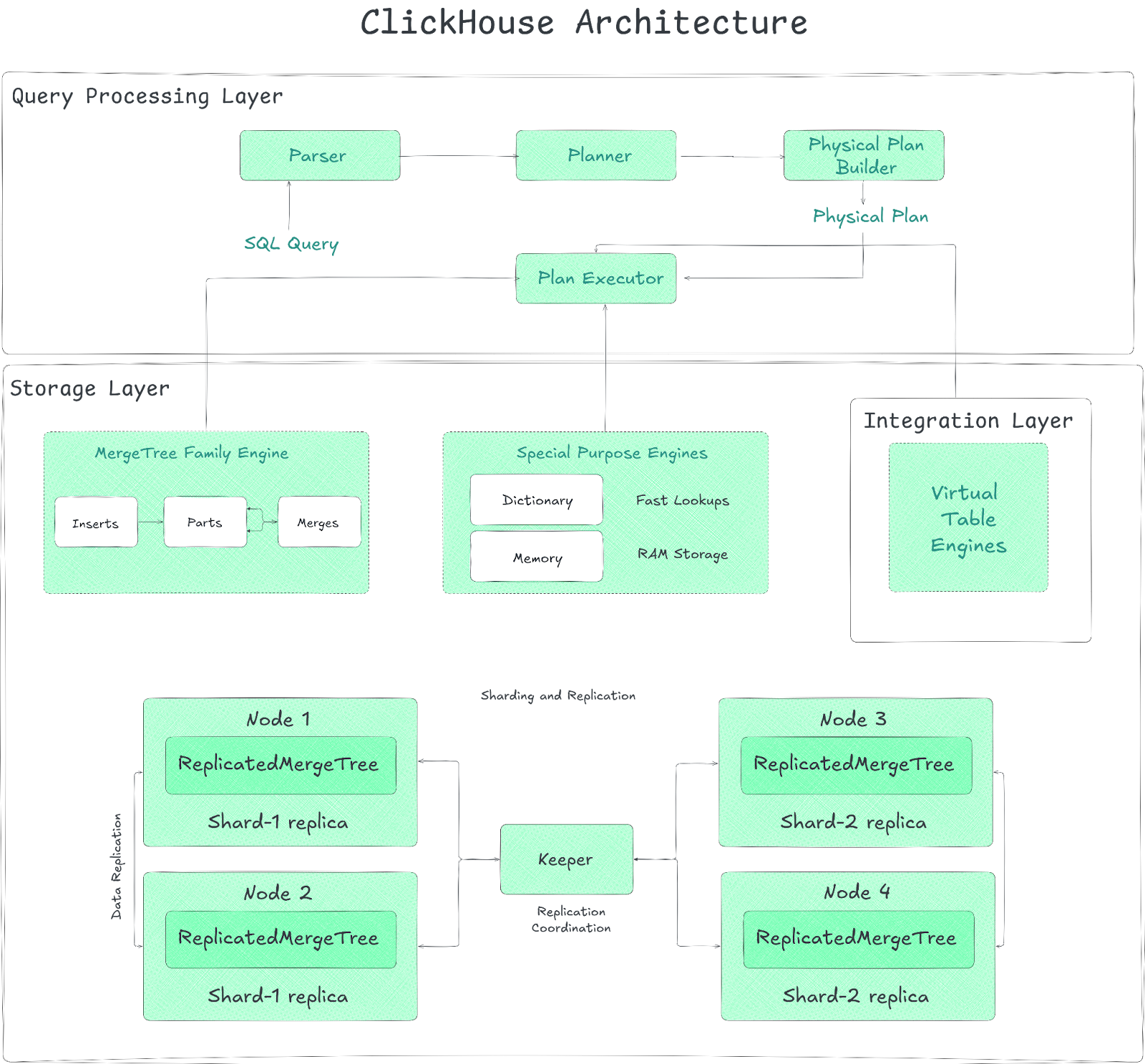
ClickHouse Architecture—Three-Layer Breakdown
Alright, let's get into the nuts and bolts. The ClickHouse architecture splits broadly into three layers:
- Query Processing Layer — The brain of the operation.
- Storage Layer — Where and how data resides.
- Integration Layer — Connecting to the outside world.
Each layer within the ClickHouse Architecture plays a distinct role in the query lifecycle—from ingestion and storage to processing and integration with external systems.
1) ClickHouse Architecture Layer 1—Query Processing Layer
ClickHouse’s query processing layer is where the magic happens within the ClickHouse Architecture. It’s the engine that takes your SQL queries, optimizes them, and executes them with blazing speed.
Query processing layer of the ClickHouse Architecture is designed to handle massive datasets and high ingestion rates. Let’s dive into how it works and what makes it so efficient.
First things first, how are queries processed in the ClickHouse Architecture? When you send a query to ClickHouse, it doesn't just jump straight to execution. Instead, it goes through a series of steps designed to optimize performance:
➥ Parsing — The SQL query text is parsed into an Abstract Syntax Tree (AST).
➥ Optimization (Logical & Physical) — The AST is transformed into a logical query plan, which is then optimized (filter pushdown, constant folding, predicate reordering). This logical plan is further converted into a physical execution plan, considering table engine specifics (utilizing sorted primary keys to avoid sorting steps).
➥ Execution Plan & Scheduling — An execution plan is created, which outlines the pipeline of operators. ClickHouse unfolds this plan into parallel execution lanes based on available cores and data distribution.
➥ Execution — Finally, the query is executed. ClickHouse uses the vectorized engine across multiple threads and potentially multiple nodes, leveraging SIMD instructions where possible.
Core Components & Techniques Making It Fast:
Vectorized Execution Model
First off, ClickHouse doesn't usually handle data row-by-row, which is slow. Instead, it employs a vectorized execution model. This means operators (the building blocks of a query plan, like filters or aggregations) work on batches (vectors) of column values at a time. Processing data in chunks like this dramatically reduces overhead and improves CPU cache usage. You see similar ideas in systems like Snowflake or DuckDB.
To squeeze out even more speed, ClickHouse uses opportunistic code compilation. For computationally intensive parts of a query (complex expressions, aggregations, sorting), it can use LLVM to compile optimized, native machine code specifically for that task, right when it's needed. This compiled code is then cached and potentially reused by later queries.
Parallelization at Multiple Levels
Parallelism is deeply integrated into the ClickHouse Architecture:
➥ Data Elements (SIMD) — Down at the individual CPU core level, ClickHouse uses SIMD (Single Instruction, Multiple Data) instructions. Think of these as special CPU commands that can perform the same operation (like adding numbers or checking a condition) on multiple data points simultaneously within a single clock cycle. It can use compiler auto-vectorization or hand-tuned intrinsics and picks the best available on your CPU at runtime.
➥ Data Chunks (Multi-Core) — On a single server (node), ClickHouse processes different chunks of data across multiple CPU cores. It breaks the query plan into independent execution lanes. Each lane works on a different range of the data. Operators within these lanes process data chunks (those vectors we talked about). To keep things balanced, especially after filtering steps where one core might end up with more work than another, it uses exchange operators like Repartition to shuffle data between lanes dynamically. Operators themselves act like little state machines, requesting chunks, processing them, and making results available. The system tries to keep work for the same lane on the same core to help CPU caches stay "hot".
➥ Table Shards (Multi-Node) — If your table is massive and you've sharded it across multiple ClickHouse servers in a cluster, the query processing layer orchestrates work across these nodes. The node that receives your query (the initiator) optimizes the plan to push as much work as possible (like scanning, filtering, and maybe even partial aggregation) out to the nodes holding the data shards. These worker nodes process their local shard data and send back intermediate results (or sometimes raw data, depending on the query) to the initiator node, which then performs the final merge.
Advanced Optimizations in Query Processing Within the Clickhouse Architecture
ClickHouse uses several optimizations to make query processing faster:
➥ Query Optimization — Optimizations occur at multiple stages:
- AST Level — Techniques like constant folding (e.g: turning 1+2 into 3) are applied early.
- Logical Plan Level — Filter pushdown moves filtering conditions closer to the data source, reducing data volume early. Common subexpressions are eliminated. Disjunctions might be converted to IN lists.
- Physical Plan Level — The planner leverages table engine specifics. For MergeTree tables, if the query's ORDER BY clause matches a prefix of the table's primary key, sorting steps can be entirely removed from the plan. Similarly, if grouping keys match the primary key prefix, a more memory-efficient sort aggregation can be used instead of hash aggregation.
➥ Query Compilation — For frequently executed computation patterns within queries (like complex expressions, aggregation functions, or multi-key sorts), ClickHouse uses LLVM to compile optimized machine code at runtime. This fuses multiple operations, reduces virtual function calls, improves register/cache usage, and leverages the fastest available CPU instructions. Compiled code is cached for reuse.
➥ Data Pruning and Skipping — To avoid reading unnecessary data:
- Primary Key Index — ClickHouse uses the sparse primary key index to quickly identify granules (blocks of 8192 rows) that might contain relevant data for WHERE clauses matching the key prefix. It uses efficient range scanning and ternary logic during index analysis. It can also optimize functions on key columns by analyzing function monotonicity or calculating preimages.
- Skipping Indices — Lightweight data structures (min-max, set, bloom filters) built over granules allow skipping data based on conditions on non-primary-key columns.
- Statistics-Based Filtering — Filters are evaluated sequentially, often ordered by estimated selectivity (based on heuristics or collected column statistics) to discard the maximum number of rows with the cheapest predicates first.
➥ Hash Table Optimizations — Hash tables are fundamental for GROUP BY aggregations and hash joins. ClickHouse selects from over 30 specialized hash table implementations based on key data types (numeric, string, fixed-size, tuples), estimated cardinality, and other factors. Optimizations include:
- Two-level layouts for huge key sets.
- Specialized string hash tables.
- Direct lookup tables (no hashing) for very small cardinalities.
- Embedded hashes for faster collision checks with complex types.
- Pre-sizing based on runtime statistics.
- Efficient memory allocation (slab allocators).
- Fast clearing using version counters.
- CPU prefetching (
__builtin_prefetch) during lookups.
➥ Join Execution — ClickHouse supports standard SQL join types (INNER, LEFT/RIGHT/FULL OUTER, CROSS, AS OF) and multiple algorithms:
- Hash Join — The most common type, featuring a highly optimized parallel implementation where both build and probe phases are parallelized across multiple threads using partitioned hash tables to minimize synchronization.
- Sort-Merge Join — Used when inputs are sorted on join keys.
- Index Join — Applicable for joins against tables with fast key-value lookup capabilities (like Dictionary tables).
Handling Simultaneous Queries in the ClickHouse Architecture
ClickHouse is designed to handle multiple queries simultaneously without performance degradation. It does this by:
➥ Concurrency Control — ClickHouse dynamically adjusts the number of threads a query can use based on overall system load and configured limits.
➥ Memory Usage Limits — ClickHouse tracks memory allocations at the server, user, and query levels. If a query tries to use too much memory for (say) aggregation or sorting, it can gracefully spill data to disk and use external algorithms instead of just crashing.
➥ I/O Scheduling — ClickHouse allows you to restrict local and remote disk accesses for workload classes based on maximum bandwidth, in-flight requests, and policy.
2) ClickHouse Architecture Layer 2—Data Storage Layer
ClickHouse's storage layer is the unsung hero behind its blazing-fast performance and a critical part of the ClickHouse Architecture. It's designed to handle massive datasets with high ingestion rates, all while keeping queries snappy. Let's dive into the details of how this layer of the ClickHouse Architecture stores and manages data, focusing on the MergeTree family of table engines, which are the workhorses of this system.
The ClickHouse Storage Layer, a fundamental piece of the ClickHouse Architecture, is built around the concept of Table Engines. You choose a table engine when you create a table, and that engine determines:
- How and where data is physically stored.
- Which queries are supported and how they perform.
- Whether data is replicated.
- How data indexing works.
These engines fall into roughly three families within the ClickHouse Architecture:
1) The MergeTree* Family Engine
The MergeTree* family is the main engine family within Clickhouse Architecture and what it's famous for. If you're storing serious amounts of data for analytics, you're likely using one of these. The design of the MergeTree engine is central to the performance characteristics of the ClickHouse Architecture.
The MergeTree Family Engine is inspired by Log-Structured Merge Trees (LSM Trees), but don't mistake it for a direct copy. Data you insert gets written as immutable "parts"—essentially, batches of rows sorted according to the table's primary key. In the background, ClickHouse continuously merges these smaller parts into larger ones. This keeps the number of parts manageable and optimizes data for reads.
How Data Sits on Disk:
➥ Columnar — Data for each column is stored in separate files within a part's directory. This is great for analytical queries that often only need a few columns.
➥ Granules — Within a column file, data is logically chunked into "granules." A granule is the smallest indivisible unit ClickHouse processes during scans (typically 8192 rows).
➥ Blocks — For actual disk I/O, ClickHouse reads and writes compressed "blocks" (defaulting around 1 MB). A block might contain several granules depending on the data type and compression.
➥ Compression — Blocks are compressed (LZ4 is the default, but you can choose others like ZSTD, or even chain codecs, maybe delta coding followed by LZ4). This saves space and often speeds up queries because less data needs to travel from disk.
➥ Sparse Primary Key Index — This is key! For each part, ClickHouse keeps a small index file in memory. This index doesn't point to every row, but rather to the primary key values at the start of every granule. Since the data within a part is sorted by this primary key, ClickHouse can use this sparse index to quickly figure out which granules might contain the data you need, skipping over huge chunks of irrelevant data.
Getting Data In — Inserts
You can insert data synchronously, where each INSERT potentially creates a new small part (which is why batching inserts is recommended). Or, you can use asynchronous inserts. ClickHouse buffers incoming rows and writes a new part only when the buffer hits a certain size or timeout, which is a whole lot better for scenarios with lots of small, frequent inserts, as it reduces merge overhead.
Finding Data Faster (Pruning)
Besides the primary key index, ClickHouse uses other tricks to avoid reading unnecessary data:
➥ Projections — Projections are pre-computed, alternative versions of your table, sorted differently or containing only a subset of columns/rows, potentially aggregated. If a query filters or aggregates on columns that match a projection's definition, ClickHouse might use the smaller, faster projection instead of the main table. They are populated lazily by default when new data arrives.
➥ Skipping Indices — These are lightweight metadata structures stored for blocks of granules (not every granule). You can define them in arbitrary expressions. Types include:
- minmax — Stores min/max values for the expression in that block. Great for range queries on somewhat sorted data.
- set — Stores unique values (up to a limit). Good for IN or = queries on columns with low cardinality locally ("clumped" values).
- bloom_filter — Probabilistic check for existence. Useful for equality checks on high-cardinality columns or text search, with a small chance of false positives (reading data you don't need) but no false negatives.
Transforming Data During Merges
The background merge process isn't just about combining parts; it can also transform data:
➥ ReplacingMergeTree — Keeps only the latest version of rows with the same primary key, effectively handling updates or deduplication during merges.
➥ AggregatingMergeTree — Collapses rows with the same primary key by combining aggregate function states (like intermediate results for sum(), avg(), uniq()). This is often used with Materialized Views to pre-aggregate data incrementally.
➥ TTL (Time-To-Live) Merges — Automatically delete or move old data (e.g: to slower storage like S3) based on time expressions during merges. You can also trigger recompression or aggregation based on age.
Handling Updates and Deletes
OLAP (Online Analytical Processing) systems aren't typically designed for frequent updates/deletes, but sometimes you need them:
➥ Mutations (ALTER TABLE ... UPDATE/DELETE) — These rewrite the affected parts entirely. They are heavyweight operations, especially deletes, as they rewrite all columns in the affected parts. They are also non-atomic, meaning concurrent reads might see data before or after the mutation during the process.
➥ Lightweight Deletes (DELETE ... WHERE) — A faster alternative. This just updates an internal bitmap column to mark rows as deleted. SELECT queries automatically filter these out. The rows are physically removed later during normal background merges. It's faster to execute the ALTER but can make subsequent SELECT queries slightly slower.
Keeping Data Safe and Scaled (Replication)
You typically use ReplicatedMergeTree variants (ReplicatedAggregatingMergeTree). Replication works on a multi-master model coordinated via ClickHouse Keeper (a C++ Raft consensus implementation, think Zookeeper but built-in). Each replica processes inserts and merges locally but coordinates through Keeper to ensure all replicas eventually converge to the same state by fetching missing parts or replaying operations logged in Keeper. It aims for eventual consistency.
ACID Properties
ClickHouse provides snapshot isolation for queries (you see data consistent as of the query start time, thanks to immutable parts). But note that, it's generally not fully ACID compliant like transactional databases. For performance, it doesn't typically fsync every write by default, meaning a power loss could potentially lose very recent data that wasn't flushed by the OS.
2) Special-Purpose Table Engines
Special-Purpose table engines serve specific niches, often complementing MergeTree tables:
➥ Dictionary — Technically related to the Integration Layer but defined like a table. These are typically in-memory key-value structures loaded from various sources (including other ClickHouse tables, files, or external databases). They provide very fast lookups, great for enriching fact tables with dimension attributes during queries (like joins).
➥ Memory — A simple engine that holds data purely in RAM. Useful for temporary tables, but data is lost on restart.
(Others exist for specific tasks like logging (Log engine family), buffering (Buffer engine), etc.)
3) Virtual Table Engines
Virtual Table Engines don't store data themselves but act as connectors to external systems. They blur the line between the Storage and Integration layers because you define them like tables, but they interact with outside data. Examples include engines (Table Functions or specific engines) to query:
- Relational databases (MySQL, PostgreSQL) - (MySQL engine, PostgreSQL engine)
- Object storage (S3, GCS, Azure Blob Storage) - (S3 engine)
- Message queues (Kafka) - (Kafka engine)
- Data Lake table formats (Hudi, Iceberg, Delta Lake) - (DeltaLake engine, Hudi engine, Iceberg engine)
- Files (CSV, Parquet, JSON, etc.) - (File engine)
Sharding and Replication Layer (Built on Table Engines)
While not a separate engine type, how ClickHouse distributes data heavily relies on the Storage Layer concepts:
➥ Sharding — You can split a large logical table across multiple ClickHouse nodes (shards). Each shard holds a portion of the data, usually in a local ReplicatedMergeTree table. Queries are then processed in parallel across shards using the Distributed table engine, which acts as a proxy, forwarding queries to shards and aggregating results. This lets you scale beyond a single server's capacity.
➥ Replication — As mentioned under MergeTree, using Replicated engines guarantees that each shard's data is copied across multiple nodes for fault tolerance. ClickHouse Keeper manages this coordination.
So, the ClickHouse Storage Layer is quite sophisticated. Its use of different table engines, particularly the highly optimized MergeTree family with its specific on-disk format, sparse indexing, and merge strategies, is fundamental to how ClickHouse achieves its high performance for analytical workloads and massive data volumes. You essentially choose the right tool (engine) for the job when you define your tables.
3) ClickHouse Architecture Layer 3—Connectivity and Integration Layer
ClickHouse isn’t just a high-performance OLAP (Online Analytical Processing) database; it’s a system designed to integrate seamlessly with your existing data ecosystem. The integration layer in ClickHouse architecture offers flexibility and compatibility that sets it apart in the analytics space.
The integration layer in ClickHouse serves as the bridge between the database and external systems, which enables seamless data exchange and compatibility with diverse data ecosystems.
How ClickHouse Handles Data Integration
ClickHouse adopts a pull-based approach for integrating external data. Instead of having to rely on external components to push data into the system, ClickHouse connects directly to remote data sources and retrieves the necessary data.
External Connectivity in ClickHouse Architecture
ClickHouse supports over 50 integration table functions and engines, allowing it to connect with a wide range of external systems. These include:
- Relational databases (MySQL, PostgreSQL, SQLite) - via engines like MySQL, PostgreSQL, or ODBC / JDBC table functions.
- Object storage (AWS S3, Google Cloud Storage (GCS), Azure Blob Storage) - often via the S3 table engine or S3 table function.
- Streaming systems (Kafka) - via the Kafka engine.
- NoSQL/Other systems (Hive, MongoDB, Redis) - via engines/functions like Hive, MongoDB, Redis.
- Data Lakes (interacting with formats like Iceberg, Hudi, Delta Lake ) - via engines like Iceberg, Hudi, DeltaLake.
- Standard protocols like ODBC - via the ODBC table function.
Data Formats Supported by ClickHouse Architecture
ClickHouse doesn't just connect to systems; it understands formats. Beyond its own native format, it can read and write a ton of others. This includes essentials like:
Compatibility Interfaces in ClickHouse Architecture
To enhance interoperability with existing tools and applications, ClickHouse provides MySQL- and PostgreSQL-compatible wire-protocol interfaces. These interfaces allow applications that already support MySQL or PostgreSQL to interact with ClickHouse without requiring native connectors.
In short, the Integration Layer in ClickHouse architecture is what makes ClickHouse a perfect choice. It provides the functions, engines, format support, and compatibility interfaces needed to pull data from, push data to, and interact with a wide variety of external systems directly from within the database.
What Are the Drawbacks of ClickHouse? (ClickHouse Limitations)
No database architecture is perfect. The specialized nature of the ClickHouse Architecture for OLAP (Online Analytical Processing) leads to trade-offs:
Limitation 1: Inefficient Updates and Deletes (Mutations)
ClickHouse wasn't originally built for frequent data modification. Operations like UPDATE and DELETE are handled differently than in traditional databases (like PostgreSQL or MySQL). They are called "mutations" and run as asynchronous background processes.
Limitation 2: Limited JOIN Performance
ClickHouse does support JOIN operations, but its performance can be less efficient compared to traditional relational databases, especially for complex joins involving multiple tables.
Limitation 3: Poor Point Lookup Performance (Key-Value Access)
ClickHouse uses a sparse primary index; this index doesn't point to every single row but rather to blocks (granules) of rows. Though, it is great for scanning large ranges of data quickly (typical for analytics) but makes retrieving a single row by its key (point lookup) inefficient. ClickHouse might need to read and process more data than necessary for these lookups. Therefore, using ClickHouse as a primary key-value store is not recommended.
Limitation 4: Lack of Full ACID Transactions
ClickHouse does not offer full-fledged ACID transactions like traditional OLTP (Online Transaction Processing) databases. Transactional guarantees are typically limited, often applying only within a single block of inserted data into one table, which makes complex operations requiring atomicity across multiple steps or tables difficult to implement reliably.
Limitation 5: Non-Standard SQL Dialect
ClickHouse uses a dialect of SQL that has differences from standard ANSI SQL. It may lack certain features found in other SQL databases.
Limitation 6: Concurrency Limitations (Historical)
ClickHouse was initially designed for scenarios with relatively fewer concurrent queries compared to high-throughput transactional systems.
Limitation 7: Single-Row Insert Performance
ClickHouse excels at inserting data in large batches (thousands of rows at a time). But, inserting data row-by-row or in very small batches frequently can lead to massive issues. Each insert creates a new "part" on disk, and too many parts can overwhelm the background merge process, leading to errors like "Too many parts". Using asynchronous inserts or buffer tables can mitigate this but adds complexity.
Limitation 8: Hardware Resource Requirements
ClickHouse can run on standard hardware, but performance significantly benefits from ample RAM, especially for caching. Running ClickHouse effectively on systems with low RAM (under 16GB) requires careful tuning of settings and limits performance.
Limitation 9: OLAP-Only Focus (Not OLTP)
ClickHouse is explicitly designed for Online Analytical Processing (OLAP). Its strengths lie in read-heavy workloads, scanning large volumes of data across a limited number of columns, and performing aggregations quickly. It is generally unsuitable for Online Transaction Processing (OLTP) workloads that involve frequent single-row inserts, updates, deletes, point lookups, and strict transactional consistency. It's also not designed for storing BLOBs or large document data.
ClickHouse vs Traditional Databases: Comparative Analysis
How does ClickHouse stack up against other database types you might be familiar with?
Here is a table summarizing the technical differences between ClickHouse and traditional databases (like MySQL, PostgreSQL):
| ClickHouse VS Traditional DBs |
ClickHouse | Traditional Databases (Row-Based RDBMS) |
| Main Use Case | Online Analytical Processing (OLAP) | Online Transaction Processing (OLTP) |
| Data Storage Model | Columnar - Stores values for each column together (Core of ClickHouse Architecture). | Row-based - Stores all values for a single record together |
| Data Compression | Very high compression ratios due to columnar storage and specialized codecs (LZ4, ZSTD). | Offers compression (like TOAST in PostgreSQL, zlib in MySQL), but generally less effective than columnar |
| Indexing | Sparse Primary Index (Unique to ClickHouse Architecture) | B-trees (or similar) indexing individual rows |
| Updates/Deletes | Handled as batch "mutations". Less efficient for frequent, row-level changes. Optimized for bulk inserts. | Designed for efficient, real-time, row-level updates and deletes |
| Joins | Supported, but can be less performant/flexible | Highly optimized join engines |
| ACID Compliance | Not fully ACID compliant (Trade-off in ClickHouse Architecture) | Typically fully ACID compliant |
| Query Execution | Vectorized Execution - Processes data in batches using CPU SIMD instructions for speed. | Often row-by-row processing or different optimization techniques |
| Scalability | Designed for horizontal scalability (sharding and replication). Scales well for massive data and queries. | Scales vertically (more power) or via more complex horizontal methods (read replicas, manual sharding) |
| Architecture Focus | Optimized for reading a few columns across many rows quickly. | Optimized for reading/writing entire rows quickly |
| Engine Flexibility | Specialized table engines (MergeTree central to ClickHouse Architecture) | May offer different storage engines, often one primary |
| Materialized Views | Often efficient/automatic updates | Typically require manual refreshing |
Is ClickHouse faster than Snowflake? (ClickHouse vs Snowflake)
ClickHouse vs Snowflake is considered closer competitors because they both target OLAP (Online Analytical Processing) workloads.
| ClickHouse VS Snowflake |
ClickHouse | Snowflake |
| Architecture | ClickHouse Architecture: ➤ Open source, columnar database. ➤ Three layered architecture: Query Processing Layer, Storage Layer, Integration Layer ➤ Available as an on‑premise solution or through managed cloud services (ClickHouse Cloud). |
➤ Cloud‑native data warehouse with a multi‑tenant design. ➤ Separates storage and compute using virtual warehouses. |
| Storage & Compute | ➤ Data is stored in columns using MergeTree engines and other variants. ➤ OSS deployments manage resources manually; Cloud services use object storage with local caching. |
➤ Data is stored in micro‑partitions in object storage. ➤ Automatically decouples storage and compute so you scale them independently. |
| Scalability & Concurrency | ➤ Achieves horizontal scaling via distributed clusters. ➤ Managed cloud editions can support high concurrent query execution (up to 1000 queries per node). |
➤ Provides multi‑cluster virtual warehouses to scale compute independently. ➤ Supports high concurrency with workload isolation in a managed environment. |
| Query Performance | ➤ Optimized for low‑latency Online Analytical Processing queries. ➤ Offers materialized views and secondary (skip) indexes (e.g. bloom filters) for fast aggregations. |
➤ Uses automated query optimization, caching, and clustering. ➤ Performance is solid for complex analytics but generally lags for sub‑second real‑time queries. |
| Data Compression | ➤ Achieves high compression with columnar storage and custom codecs. ➤ Compression ratios often surpass those in Snowflake. |
➤ Compresses data via micro‑partitioning. ➤ Clustering can improve compression but may add compute overhead. |
| Data Ingestion & Load | ➤ High ingestion throughput with support for various file formats. ➤ OSS deployments require manual tuning; Cloud services offer managed pipelines. |
➤ Supports bulk‑loading via external stages with native Parquet support. ➤ Optimal with files sized near 150 MiB for best performance. |
| Ecosystem & Integrations | ➤ Supported by a large open‑source community. ➤ Offers many file formats and custom integrations; however, manual tuning is common. |
➤ Rich native ecosystem with built‑in connectors to Business Intelligence and ML tools. ➤ Managed service reduces operational overhead. |
| Management & Maintenance | ➤ OSS requires manual installation, tuning, and updates. ➤ ClickHouse Cloud offloads maintenance; advanced configuration can demand a steeper learning curve. |
➤ Fully managed service that automates maintenance, updates, and backups. ➤ Provides a web‑based interface with automated monitoring. |
| Use Cases | Suited for real‑time analytics, time‑series and event data, and low‑latency OLAP queries. | Fits large‑scale data warehousing, structured and semi‑structured analytics, and integrated enterprise workflows. |
| Data Governance & Security | Offers role‑based access control and basic encryption; deployments may require custom approaches for advanced compliance. | Provides built‑in encryption (in‑transit and at‑rest), fine‑grained access controls, and enterprise compliance features. |
Conclusion
And that's a wrap! ClickHouse is a really powerful open-source columnar database built for super-fast performance in OLAP (Online Analytical Processing) and real-time analytics. ClickHouse architecture is all about columnar storage, vectorized execution, efficient indexing, and multi-level parallelism. Due to this, it can handle huge datasets way faster than traditional row-based systems when it comes to analytical tasks. While the ClickHouse Architecture has its limitations, especially concerning transactional workloads and frequent updates/deletes, its strengths make it a top choice for a range of use cases. To get the most out of ClickHouse, you need to understand the core ClickHouse architecture, particularly the MergeTree engine family and how queries are processed within its distinct layers.
In this article, we have covered:
- What is ClickHouse?
- What is ClickHouse used for?
- ClickHouse Architecture Breakdown
- ClickHouse Architecture Layer 1—Query Processing Layer
- ClickHouse Architecture Layer 2—Data Storage Layer
- ClickHouse Architecture Layer 3—Connectivity and Integration Layer
- What Are the Drawbacks of ClickHouse (Limitations of ClickHouse Architecture)?
- ClickHouse vs Traditional Databases
- ClickHouse vs Snowflake
… and more!
FAQs
What is ClickHouse used for?
Real-time analytics dashboards, log analysis, SIEM, Business Intelligence acceleration, AdTech, time-series analysis, product analytics, and observability platforms. Essentially, fast analysis on large datasets, often append-only.
What makes ClickHouse so fast for analytical queries?
➥ Columnar Storage — Reads only necessary columns, minimizing I/O.
➥ Vectorized Execution — Processes data in batches using CPU SIMD instructions efficiently.
➥ Data Compression — Reduces data size using effective general and specialized codecs.
➥ Sparse Primary Index & Skipping Indices — Avoids scanning irrelevant data blocks.
➥ Parallel Processing — Utilizes multiple CPU cores and servers.
➥ Hardware Optimization — Written in C++ to leverage hardware effectively.
What is the minimum RAM for ClickHouse?
While it can technically run with less, practical minimums for reasonable performance are often cited in the 8GB-16GB range, but this depends heavily on dataset size, query complexity, and concurrency. Production deployments typically use much more RAM (32GB, 64GB, 128GB+ per node) for caching data, indexes, and intermediate query results.
Is ClickHouse SQL or NoSQL?
ClickHouse is a SQL database. It uses a dialect of SQL for querying and data definition. It is not a NoSQL database, although it integrates with some NoSQL systems.
What is the benefit of ClickHouse?
Its primary benefit is extreme speed for OLAP queries on large datasets, enabling real-time analytics. Other benefits include high data compression, horizontal scalability, open-source nature, fault tolerance (via replication), and cost-effectiveness (especially the OSS version).
Is ClickHouse an OLAP?
Yes, ClickHouse is fundamentally designed and optimized as an OLAP (Online Analytical Processing) database system.
Is ClickHouse better than MySQL?
They are designed for different purposes. ClickHouse is vastly better/faster for OLAP (Online Analytical Processing) analytics. MySQL (with engines like InnoDB) is generally better for Online Transaction Processing transactions involving frequent small reads, writes, updates, deletes, and strict ACID compliance. They are often used together.
What is the MergeTree engine?
It's the primary family of storage engines in ClickHouse, optimized for OLAP (Online Analytical Processing). Key features include columnar storage, data sorting by primary key, storing data in immutable 'parts', background merging of parts, sparse primary indexing, support for replication, and variants for deduplication (ReplacingMergeTree) or pre-aggregation (AggregatingMergeTree).
Can ClickHouse update or delete data?
Yes, but it's handled differently and is generally less efficient than in OLTP systems.
- ALTER TABLE ... UPDATE/DELETE (Mutations) — Asynchronous, potentially heavy operations that rewrite data parts.
- DELETE FROM ... WHERE (Lightweight Deletes) — Faster operation that marks rows deleted; physical deletion happens later during merges.
How does ClickHouse integrate with other external systems?
Through its Integration Layer:
- Table Functions/Engines — Connect directly to databases (SQL/NoSQL), object storage (S3), message queues (Kafka), HDFS, etc.
- Data Format Support — Reads/writes many formats (CSV, JSON, Parquet, ORC, etc.).
- Compatibility Interfaces — Acts like MySQL or PostgreSQL for compatible tools.
- Dictionaries — Can load key-value data from various sources for fast enrichment.
- Client Drivers/APIs — Native TCP, HTTP, language-specific drivers (Python, Java, Go), JDBC/ODBC.
Is ClickHouse ACID compliant?
No, not fully in the traditional RDBMS sense. It provides Snapshot Isolation for reads and Atomicity for single INSERT blocks. It lacks multi-statement transaction guarantees. Default durability settings prioritize performance over immediate fsync guarantees after writes.
How does ClickHouse handle data replication?
It uses asynchronous multi-master replication, typically via the ReplicatedMergeTree engine family. Replicas coordinate through ClickHouse Keeper (using the Raft protocol) to log operations (inserts, merges) and ensure all replicas eventually converge to the same state by fetching missing parts or replaying operations.















