




























AWS EMR and Databricks are the leading solutions for processing massive amounts of data in the cloud. They both offer powerful tools for handling massive amounts of data, but they go about it in totally different ways. AWS EMR is a cloud-based service from AWS that makes it easier to process large datasets using frameworks like Apache Hadoop, Apache Spark, and others. It lets users run data processing tasks across clusters of AWS EC2 instances, handling all the setup and fine-tuning automatically. On the other hand, Databricks is a unified analytics platform built around Apache Spark. It integrates data lakes and warehouses into a single "lakehouse" architecture, making it easy to manage both structured and unstructured data and simplify your data processing pipeline. Databricks also supports collaborative data science and machine learning workflows. It works seamlessly across AWS, Azure, and GCP. If you're deciding between AWS EMR and Databricks, knowing the differences between them can help you pick the right one for your particular data workload.
In this article, we’ll cover the differences between AWS EMR vs Databricks in detail, examining each platform’s architecture, data processing capabilities, deployment options, ecosystem integrations, security, and pricing models.
Table of Contents
What is Databricks?
Databricks, founded in 2013 by Apache Spark creators, aimed to simplify data workflows using the cloud infrastructure. The platform is designed to scale Spark applications and make it easier for data engineers, scientists, and analysts to collaborate. Since its launch, Databricks has evolved into a robust analytics platform, now supporting AI, machine learning, and big data. On top of that, it has expanded across cloud providers like AWS, Azure, and Google Cloud.

In a nutshell, Databricks is a cloud-based unified analytics platform built around Apache Spark. It merges big data processing and collaborative features, letting data teams handle and process data as it happens. Databricks works with major cloud services, giving users the flexibility to manage data from different sources. Its Delta Lake component is key to keeping data reliable and running smoothly.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Features of Databricks
Databricks offers a bunch of features and tools:
1) Apache Spark Foundation — Databricks is built around Apache Spark, offering a high-performance engine for processing large data sets.
2) Data Lakehouse Architecture — Databricks' Lakehouse architecture combines the capabilities of data lakes and data warehouses—providing structured data governance alongside cost-effective storage.
3) Delta Lake — Databricks also has Delta Lake, which is like a supercharged data lake with ACID transactions, making sure your data is reliable and consistent.
4) Unified Workspace — Databricks offers a collaborative workspace for data engineering, machine learning, and analytics tasks.
5) Multi-Cloud Availability — Databricks is available on AWS, Azure, and Google Cloud, which gives users deployment flexibility.
6) Collaborative Notebooks — Databricks has interactive notebooks for code, docs, and visualizations. They also support multiple languages, including Python, R, Scala, and SQL with built-in version control.
7) Delta Live Tables (DLT) — DLT is a recent addition to Databricks for declarative data pipelines, providing reliable ETL processes with automated management of data flows and dependencies.
8) Machine Learning (ML) Integration — Databricks supports the full ML lifecycle with native integration of MLflow, an open source platform for experiment tracking, model management, and deployment. The platform includes tools for feature engineering, model tuning, and MLOps, making it easy to operationalize machine learning models.
10) Real-Time Data Processing — Databricks enables real-time analytics through Spark Streaming, supporting low-latency processing for time-sensitive applications like IoT and financial transactions.
11) Scalability and Flexibility — Databricks can automatically scale compute resources. It adjusts them based on workload demands, to meet varying data processing needs.
12) Data Processing and ETL — Databricks has tools for ETL. They help users manage data workflows efficiently.
13) Data Visualization and BI Integration — Databricks integrates with popular BI tools like Tableau, Power BI. Users can create interactive dashboards and share insights directly from Databricks, which improves collaborative decision-making.
14) Security and Compliance — Databricks offers robust security features including role-based access control (RBAC), encryption at rest and in transit, and auditing capabilities. Unity Catalog, Databricks’ centralized governance tool, allows users to manage access and data lineage for all data and AI assets in one place.
15) Lakehouse Federation and Open Data Connectivity — Databricks has expanded connectivity through Lakehouse Federation, enabling users to query and govern data across external systems like Redshift, Snowflake, and BigQuery.
18) Generative AI Support — Databricks recently integrated generative AI tools to simplify the development and deployment of AI models. Features such as vector search, model serving, and support for popular large language models (LLMs) make Databricks an attractive option for advanced AI applications.
… and a whole lot more features!!
What is Databricks Used For? Databricks is used across sectors for a variety of data-related tasks, which includes:
🔮 Big Data Processing: Databricks can handle large datasets for analytics and reporting.
🔮 Machine Learning: Databricks supports the whole ML lifecycle, including feature engineering, model training, and deployment.
🔮 Data Engineering: Databricks provides tools for building and managing data pipelines, whether for batch processing or real-time streaming.
🔮 Collaborative Data Science: Databricks helps teams to work together on data projects seamlessly.
Databricks is a great choice if you want to simplify data pipelines and analytics in a collaborative environment that spans multiple cloud providers. It's especially useful for organizations trying to bring their data and AI processes together on one platform.
Databricks the Data + AI Company - AWS EMR vs Databricks
What is AWS EMR?
AWS EMR, launched by Amazon in 2009, was initially designed to make it easier to process large datasets using Hadoop clusters. Over time, it evolved to support Apache Spark and other popular data processing frameworks, meeting a broad set of data processing needs on AWS infrastructure. EMR enables users to run complex analytics, perform ETL operations, and carry out large-scale data processing on distributed clusters without managing the underlying hardware.

In a nutshell, AWS EMR is a managed cluster platform on Amazon Web Services that simplifies running big data frameworks such as Apache Hadoop, Apache Spark, HBase, Presto, and more. It handles data processing and analytical tasks by distributing them across a fleet of EC2 instances, automating cluster management, and reducing setup time. EMR integrates deeply with other AWS services, creating a robust ecosystem for data engineering and analytics.
Features of AWS EMR
AWS Elastic MapReduce (EMR) is a scalable and flexible service for processing and analyzing large data sets on the AWS cloud. Here’s a breakdown of its key features:
1) Elastic Scalability — AWS EMR dynamically scales clusters based on workload demands, integrating with EC2 for virtual servers and EKS for containerized applications. You can scale clusters up or down depending on resource needs, optimizing cost and performance.
2) Parallel Clusters — If your input data is stored in Amazon S3 you can have multiple clusters accessing the same data simultaneously.
3) Data Access Control — With AWS Identity and Access Management (IAM), EMR provides detailed access control to resources. Administrators can define policies for who can create, modify, or delete clusters and control access to data, supporting security compliance requirements.
4) Multi-Framework Support — EMR supports various data processing frameworks to handle a range of workloads, including:
- Apache Spark: Fast, in-memory data processing.
- Apache Hadoop: Traditional MapReduce-based processing.
- Apache Hive: SQL-like querying for data warehousing.
- Apache HBase: NoSQL database for real-time applications.
- Apache Flink: Stream and batch processing.
- Presto: SQL engine for large-scale data.

5) Data Storage Integration — AWS EMR offers two main storage solutions:
- HDFS: For temporary storage within the EMR cluster.
- EMRFS: Extends HDFS capabilities to Amazon S3, allowing scalable, persistent storage without relying solely on the cluster.
6) Real-Time Data Processing — AWS EMR supports near real-time processing, especially useful for applications that need instant insights—like fraud detection and user analytics. It can be used with tools like Apache Kafka and Apache Flink for efficient stream processing.
7) AWS Service Integrations — EMR integrates with several AWS services, enabling comprehensive data workflows:
- Amazon S3 for storage.
- Amazon CloudWatch for monitoring and alarms.
- AWS Glue for ETL and data cataloging.
8) Cluster Resource Management — AWS EMR uses YARN (Yet Another Resource Negotiator) to manage resources within clusters. YARN allocates resources dynamically, helping optimize performance across multiple applications.
9) Data Security Features — AWS EMR prioritizes security with several built-in features:
- IAM integration for access control.
- Encryption for data at rest and in transit.
- VPC isolation to secure network traffic.
10) Interactive Environments — For exploratory and collaborative work, EMR provides, EMR Notebooks and EMR Studio.
11) Business Intelligence Tools — AWS EMR integrates with popular business intelligence (BI) tools such as Tableau, MicroStrategy, and Datameer.
… and a whole lot more features!!
What is AWS EMR Used For? AWS EMR serves various functions for data processing and analytics:
🔮 ETL and Data Processing: Ideal for extracting, transforming, and loading data, as well as large-scale data transformations across distributed clusters.
🔮 Data Analytics: Facilitates analytics for real-time insights from large datasets using data processing engines like Apache Hadoop, Apache Spark, HBase, Presto and more.
🔮 Machine Learning: Supports machine learning frameworks like TensorFlow and Spark MLlib for training and deploying models at scale.
AWS EMR is a great option for companies that are already invested in AWS and for those that need a flexible and scalable way to manage large datasets. Since it works seamlessly with other AWS services, it's a great solution for businesses that rely on the AWS ecosystem for storing, securing, and processing their data.
An Introduction to AWS EMR - AWS EMR vs Databricks
AWS EMR vs Databricks—High-Level Feature Comparison
Need a fast comparison of AWS EMR vs Databricks? Here's a high-level look at their key features.
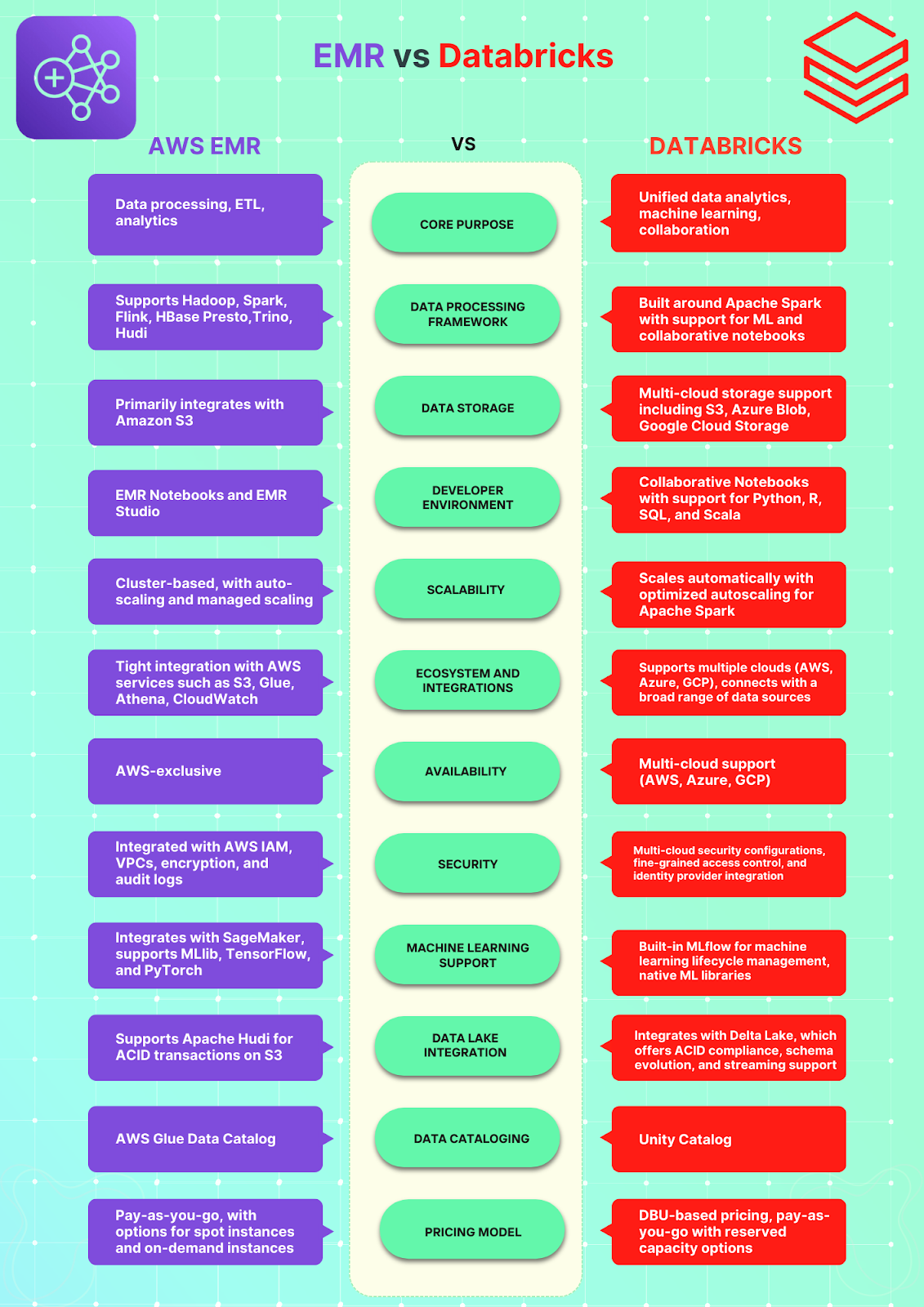
What Is the Difference Between EMR and Databricks?
We've covered what AWS EMR and Databricks are. Now, let's explore their differences in nine areas: architecture, data processing engines, multi-cloud capabilities, ecosystem integration, machine learning, scalability, security, developer experience, and pricing models. Let's dive in!
1). AWS EMR vs Databricks—Core Architecture Breakdown
Databricks Architecture Overview
Databricks architecture integrates tightly with major cloud providers—AWS, Azure, and Google Cloud—supporting scalable data processing. It’s structured with two main layers: the control plane and the compute plane, each with distinct roles.
a) Control Plane
Control Plane is fully managed by Databricks and hosts backend services that support operational tasks for the platform like:
- User Authentication and access control, including Single Sign-On (SSO) and Role-Based Access Control (RBAC), especially in Premium and higher plans.
- Job Scheduling and orchestration of Databricks jobs.
- Cluster Management and monitoring, enabling the creation, management, and termination of clusters across different cloud infrastructures.
- Web Application Interface, providing user access to the Databricks environment.
All tasks in the control plane are isolated from customer data, ensuring data security and compliance standards. Networking for control-plane components is securely handled by Databricks within the cloud region assigned to your account.
b) Compute Plane
Compute plane is where data processing happens, with two types depending on user needs:
- Serverless Compute Plane: Resources in this mode are fully managed by Databricks, offering automatic scaling and simplicity without needing users to manage clusters. Suitable for users prioritizing ease of use over control.
- Classic Compute Plane: In this setup, resources run within the user’s own cloud account, providing more control and isolation. Each workspace operates within a dedicated Virtual Private Cloud (VPC) or Virtual Network (VNet), depending on the cloud provider, and this option allows compliance with specific organizational security requirements.
c) Workspace Storage
Databricks associates each workspace with cloud-native storage—AWS S3, Azure Blob Storage, or Google Cloud Storage—depending on the deployment. This storage is utilized for operational data, including notebooks, job run details, and logs. The Databricks File System (DBFS) provides an abstraction layer across these storage services, making data accessible via a unified interface. DBFS supports various data formats (e.g., CSV, JSON, Parquet) and is compatible with Spark APIs, which simplifies data management across different cloud environments.
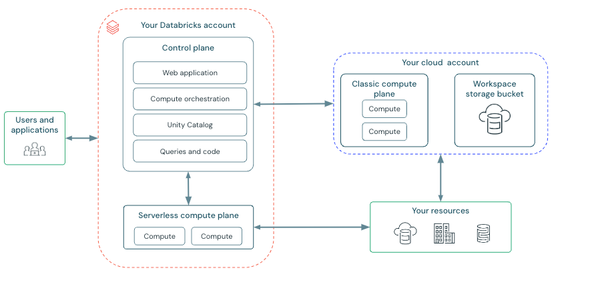
Check out this article to learn more in-depth about Databricks architecture.
AWS EMR Architecture Overview
AWS Elastic MapReduce (EMR) supports scalable data processing using Apache Hadoop and Apache Spark, structured around key architectural layers that facilitate storage, resource management, data processing, and application interaction. Here’s a breakdown of these core layers.
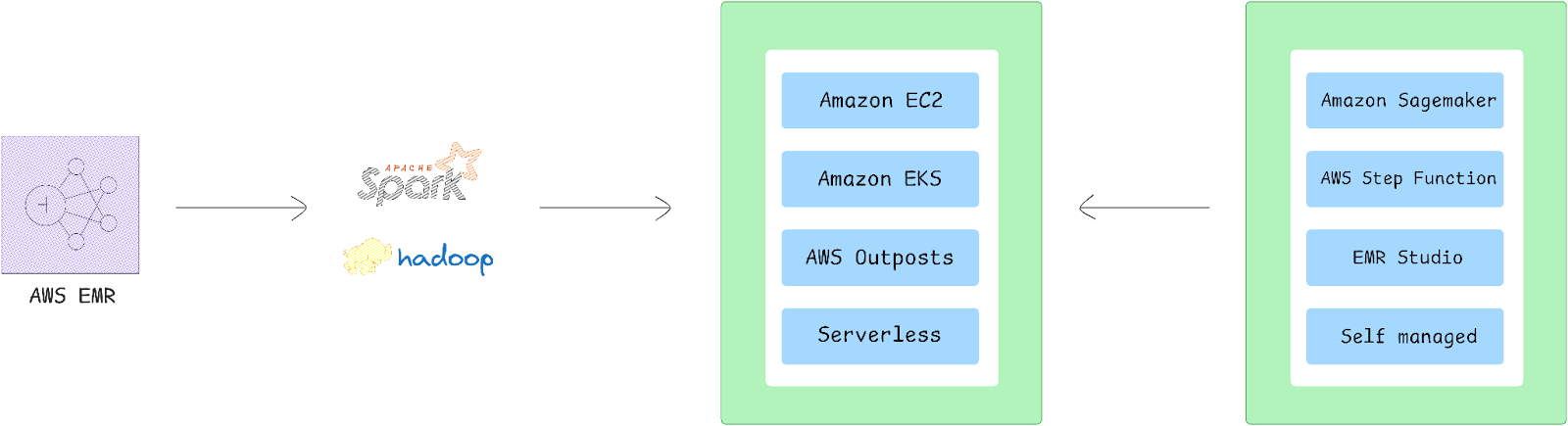
➥ Cluster Architecture
AWS EMR clusters consist of EC2 instances, categorized into three types of nodes:
- Primary Node — Responsible for overall cluster management, including task scheduling, job coordination, and health monitoring. Each cluster has exactly one primary node.
- Core Nodes — Handle HDFS storage and execute processing tasks. Core nodes are critical for fault-tolerant storage in multi-node clusters.
- Task Nodes — Execute processing workloads but do not contribute to storage. Task nodes are often used in transient Spot Instances for cost optimization.
Storage Layer
The storage layer is critical for managing data input, output, and intermediate results during processing. It supports multiple file systems:
Hadoop Distributed File System (HDFS) — HDFS is suited for ephemeral storage, distributing data across instances and replicating it to improve fault tolerance. Primarily, it’s used for intermediate data caching during job execution. Data here isn’t persistent, disappearing after the cluster’s lifecycle ends.
EMR File System (EMRFS) — EMRFS extends Hadoop's flexibility by allowing seamless integration with Amazon S3, which acts as a persistent storage solution. Unlike HDFS, data in Amazon S3 persists even after the cluster ends, providing long-term storage. EMRFS is especially valuable for input, output, and data archiving, allowing EMR to scale with Amazon S3’s vast storage capabilities.
Local File System (LFS) — EMR nodes use the instance store (local disk) for temporary data, which can be useful for short-lived computations. Data stored here, however, is also ephemeral—lost when the EC2 instance stops or terminates. EC2 instances with Amazon Elastic Block Store (EBS) volumes can offer additional, potentially persistent storage.
➥ Resource Management Layer
This layer manages the resources of the EMR cluster. It utilizes YARN (Yet Another Resource Negotiator), which was introduced in Hadoop 2.0, to allocate resources dynamically among various applications running on the cluster. Key functions include:
- Resource Allocation: YARN manages CPU, memory, and network bandwidth across the cluster to optimize performance.
- Job Scheduling: It schedules jobs based on resource availability, ensuring efficient execution of tasks.
YARN operates by placing an agent on each node that communicates with the EMR service to maintain cluster health and manage job execution.
➥ Data Processing Frameworks
AWS EMR supports a variety of data processing frameworks, enabling different workloads on a single cluster:
Hadoop MapReduce — Hadoop MapReduce offers a distributed computing model for processing large datasets. It provides a simplified model where users define Map and Reduce functions, while the framework handles task distribution. MapReduce’s integration with tools like Apache Hive enables users to run SQL-like queries, abstracting complex code into accessible interfaces.
Apache Spark — Apache Spark is an in-memory cluster-computing framework that enables fast processing of big data workloads. It supports complex execution plans through directed acyclic graphs (DAGs) and provides modules like SparkSQL for interactive querying. Spark’s compatibility with EMRFS allows direct access to Amazon S3 data, optimizing it for both batch and interactive workflows.
Additional Frameworks — Other options, like Apache HBase for NoSQL data storage and Presto for low-latency SQL queries, are also available on EMR, depending on the workload requirements.
➥ Applications and Programs
AWS EMR’s applications and programs layer provides tools and programming interfaces that enhance data processing capabilities and support development flexibility.
Applications Supported by EMR — EMR clusters support various applications such as Apache Hive for SQL-based querying, Pig for data transformation, and Spark Streaming for real-time data processing. Each application is optimized to handle specific types of workloads, whether batch or streaming and can run concurrently on the same cluster.
Programming Languages and Interfaces — You can interact with EMR applications using a variety of languages and interfaces. Spark, for example, supports Java, Scala, Python, and R, while MapReduce relies on Java. Job management can be handled via the EMR console, AWS CLI, or SDKs, providing flexibility in how you execute and monitor processing tasks.
➥ Modes of Deployment
EMR on EC2 (Cluster Mode):
- The most common deployment, where EMR clusters run on Amazon EC2 instances.
- Clusters can have three node types: primary (for cluster management), core (for storage and processing), and task (processing-only) nodes.
- Suitable for workloads requiring high elasticity and direct control over the cluster configuration.
EMR on AWS Outposts:
- Extends EMR to on-premises environments using AWS Outposts.
- Provides the same EMR capabilities while maintaining data residency and reducing latency for on-premises datasets.
EMR Serverless:
- Eliminates the need to manage infrastructure by automatically provisioning and scaling resources.
- Perfect for intermittent or unpredictable workloads where maintaining a cluster isn't cost-effective.
EMR on Amazon EKS (Kubernetes Integration):
- Allows EMR applications to run on Amazon Elastic Kubernetes Service (EKS).
- Leverages Kubernetes’ orchestration to integrate EMR with existing containerized workloads.
2). AWS EMR vs Databricks—Data Processing Engines
Traditional data warehousing systems weren’t built to handle the scale and variety of today’s data. Apache Spark addresses these limitations, bringing faster, more flexible processing than Hadoop's MapReduce. Unlike MapReduce, which processes data in stages and uses disk storage heavily, Spark uses in-memory processing—making it significantly faster and ideal for large-scale, real-time, and iterative data tasks.
Databricks Engine
Databricks was developed around Apache Spark, though it remains compatible with Hadoop ecosystems like Hive, YARN, and Mesos. This design makes Databricks highly versatile and a preferred platform for managing Spark-based workloads. Its primary advantage lies in a simplified, integrated experience that streamlines Spark development and management, allowing for data processing and analytics without the need for extensive configuration.
AWS EMR Engine
Amazon EMR (Elastic MapReduce) started with MapReduce as its core. Now, it supports multiple engines, including Spark, so you can run tools like Presto, Hudi, and Hadoop on managed clusters. EMR also offers pre-configured clusters, providing a convenient setup for distributed processing engines and enabling users to get started quickly without extensive manual configuration.
🔮 Databricks seamlessly integrates with Apache Spark, offering a robust, Spark-native environment, while EMR is compatible with multiple engines, including but not limited to Spark, enabling flexibility for diverse workflows.
3). AWS EMR vs Databricks—Hybrid and Multi-Cloud Deployment Capabilities
Databricks Deployment Options
Databricks offers significant flexibility by allowing deployment across multiple cloud platforms. It is integrated with:
Databricks' multi-cloud flexibility is advantageous for organizations seeking interoperability with other cloud services.
Databricks also supports serverless compute, enabling on-demand resource allocation without the need to manage infrastructure directly. This flexibility benefits multi-cloud deployments, as organizations can switch between providers or use services from multiple clouds as needed.
AWS EMR Deployment Constraints
In contrast, AWS EMR is exclusive to the AWS environment, optimized for the AWS ecosystem. EMR doesn’t natively support cross-cloud deployment, limiting its use to organizations committed to AWS as their primary cloud provider. However, it has increasingly integrated with other deployment models to expand its flexibility. Originally relying solely on EC2 instances for compute, EMR now supports multiple deployment methods:
- EMR on EKS (Elastic Kubernetes Service) enables users to run containerized Spark and Hadoop workloads on Kubernetes.
- EMR on Outposts allows users to extend AWS infrastructure to on-premises data centers, providing hybrid cloud solutions where compute and storage are seamlessly integrated with the cloud.
- EMR Serverless option takes advantage of AWS's serverless offerings, allowing users to execute workloads without provisioning or managing any infrastructure.
🔮 Databricks provides more extensive support across multiple cloud platforms, whereas AWS EMR is better suited for deployments within the AWS ecosystem. Compared to EMR, Databricks offers more flexibility when working across different cloud platforms. If you're looking for a truly multi-cloud or hybrid setup, Databricks is the better choice. On the other hand, if you're already heavily invested in AWS, EMR is a great option.
4). AWS EMR vs Databricks—Ecosystem and Integration
When comparing AWS EMR and Databricks, ecosystem and integration capabilities are essential factors. Each platform offers distinct strengths in compatibility and interoperability, particularly within their native ecosystems.
Databricks Ecosystem
Databricks is built on top of Apache Spark, which means it seamlessly integrates with the open source Spark ecosystem. Databricks provides extensive connectivity options to a wide range of data sources—both SQL and NoSQL databases, cloud storage options (like AWS S3 and Azure Blob Storage), and streaming sources like Kafka. This flexibility enables teams to bring in data from multiple sources, a useful feature for complex analytics or machine learning models. Also, Databricks is available across AWS, Azure, and Google Cloud, so organizations working in multi-cloud environments benefit from Databricks’ cross-platform availability and unified interface. Another advantage of Databricks is its collaborative workspace, with support for team-based notebooks that allow data scientists and engineers to work together in real-time, ideal for machine learning projects.
AWS EMR Ecosystem
On the other hand, AWS EMR is deeply integrated within the AWS ecosystem, making it a natural choice for organizations that are already heavily invested in AWS services. EMR can connect natively to AWS tools such as AWS S3 for data storage, Redshift for data warehousing, and RDS for relational databases, which makes it easier to set up a full data pipeline within the AWS ecosystem. EMR also offers strong security and monitoring options through AWS’s Identity and Access Management (IAM) and CloudWatch services. These features provide granular access control and comprehensive monitoring capabilities, which are particularly valuable in regulated industries. For cost-conscious users, EMR also supports Amazon EC2 Spot Instances, allowing companies to leverage unused EC2 capacity at reduced rates—a significant advantage for batch processing and other flexible workloads. AWS EMR is also compatible with a wider range of open source frameworks beyond Spark, including Hadoop, Presto, and HBase, providing additional flexibility if you need multiple data frameworks in your workflows.
🔮 Databricks is a better choice if you prioritize open-source tool compatibility, multi-cloud availability, and team collaboration features—especially for machine learning and analytics tasks. On the other hand, AWS EMR shines when your work is closely tied to AWS services, and you want easy integration, affordable computing options, and top-notch security within the AWS ecosystem.
5). AWS EMR vs Databricks—Machine Learning and Analytics
In the context of machine learning and analytics, AWS EMR and Databricks offer distinctive approaches suited to different enterprise needs and workflows.
Databricks ML Features
- Built-in ML Support: Databricks is designed to streamline the machine learning (ML) lifecycle. It includes built-in ML frameworks like MLflow and Spark MLlib, which support end-to-end development and deployment without extensive configuration. Its collaborative environment allows data scientists to work together in real-time with shared notebooks, accelerating the ML experimentation and training phases.
- AutoML: Databricks supports automated machine learning (AutoML) tools, which can automatically generate models based on input data. This feature helps data scientists iterate rapidly and validate models before scaling.
- GPU Support: For high-performance ML tasks, Databricks provides robust GPU integration, making it easier to process complex, large-scale ML tasks.
- Visualization & Analytics: Databricks’ interface integrates visualization tools directly into the notebook environment, allowing for intuitive data exploration and streamlined analytics, especially for teams working in collaborative settings
AWS EMR ML Integration
AWS EMR, in contrast, emphasizes flexibility and integration with the broader AWS ecosystem.
- SageMaker Integration: While EMR itself doesn’t focus on ML, it integrates tightly with SageMaker, AWS’s dedicated ML service. SageMaker provides a comprehensive suite of ML tools, including training, tuning, and deployment options that work in tandem with EMR’s data-processing capabilities. This setup is particularly advantageous if your ML workflow already leverages the AWS ecosystem.
- Spark MLlib & Custom Libraries: EMR supports Spark MLlib for scalable ML model training and allows users to integrate additional libraries or frameworks (like TensorFlow, MXNet, or Scikit-learn). This flexibility lets teams bring in custom ML tools while still relying on Spark for distributed data processing.
- Data Lake and Analytics Integrations: EMR can easily connect with AWS analytics services, like Glue and Redshift, and data storage through S3. This capability simplifies large-scale data processing for analytical tasks, making it effective for batch processing, ETL workflows, and BI operations.
🔮 Databricks is probably the better choice if your focus is on a streamlined machine-learning process with strong collaborative features. But if you need an environment that works seamlessly with AWS services for big data projects, AWS EMR might be a better fit. Ultimately, your choice should match your project's needs and your team's skills. Both platforms have their own strengths that can support different workflows, depending on what you and your organization need, and what you already have set up.
6). AWS EMR vs Databricks—Scalability and Performance
Now, let's compare scalability and performance between AWS EMR and Databricks. There are key distinctions in how each platform handles autoscaling, resource optimization, and cost-effective scaling options.
AWS EMR Autoscaling Mechanisms
AWS EMR uses a cluster-based scaling model that lets you expand or shrink your cluster capacity based on workload demands. It has two main options for automatic scaling: instance fleet-based autoscaling, which adjusts the number and type of EC2 instances based on job requirements, and managed scaling, which lets AWS optimize cluster size based on key performance metrics, like CPU and memory usage. EMR is particularly efficient for big data processing workloads that benefit from consistent, stable clusters.
Databricks Autoscaling Mechanisms
Databricks, being deeply optimized for Apache Spark, supports a more flexible autoscaling option specifically designed for Spark jobs. Unlike EMR, which scales at the instance level, Databricks can scale at the workload level, adjusting resources in line with Spark stages, which can boost performance for variable, on-demand workloads. Its horizontal and vertical scaling options allow quick adaptation to peak loads, and its serverless offerings make it particularly well-suited for unpredictable, dynamic workloads.
AWS EMR Performance Optimization Technique
AWS EMR provides various instance types and supports Spot Instances, allowing you to save on costs by using spare EC2 capacity. However, spot instances can be terminated if EC2 capacity is needed elsewhere, so EMR includes mechanisms to handle the interruptions, making it a fit for cost-conscious, fault-tolerant workloads. Managed scaling further optimizes costs by dynamically adjusting the cluster size without manual intervention.
Databricks Performance Optimization Technique
Databricks optimizes resource usage with its DBU-based pricing model, where you pay per second based on the Databricks Unit (DBU) usage tied to workload performance. Since this pricing model directly correlates with performance, it gives you more control over cost optimization as you scale. Also, Databricks' optimized Spark execution reduces job run times, which can translate into lower DBU costs for intensive Spark jobs, especially when using on-demand or serverless compute.
| Feature | AWS EMR | Databricks |
| Autoscaling | Cluster-based; instance fleet and managed scaling options | Workload-optimized for Spark; serverless options on AWS, Azure |
| Spot Instances | Available for cost savings | Only Available in Databricks on AWS |
| Core Use Case Fit | Cost-effective for stable, steady workloads | Optimized for dynamic, Spark-heavy workflows |
7). AWS EMR vs Databricks—Security and Governance
Here's a comparison of the security and governance features between AWS EMR and Databricks to help you understand how each handles data protection, access control, and compliance.
AWS EMR Security and Governance
AWS EMR integrates tightly with other AWS services to provide a robust security framework:
- Identity and Access Management (IAM): AWS EMR integrates with IAM, allowing you to control access through fine-grained permissions, role-based access, and custom policies. You can enforce specific permissions for users and applications working with EMR resources.
- Data Encryption at Rest: Supports server-side encryption (SSE) with either S3-managed keys or AWS Key Management Service (KMS) keys. Local storage volumes and EBS volumes can also be encrypted with options like LUKS or NVMe encryption, depending on instance type.
- Data Encryption in Transit: EMR supports TLS encryption for data in transit across Amazon S3, Hadoop Distributed File System (HDFS), and other cluster communications.
- Network Isolation: By deploying EMR clusters within a Virtual Private Cloud (VPC), you can isolate your cluster from other resources. AWS security groups further control network traffic within and outside the VPC, ensuring restricted access.
- Auditing: AWS CloudTrail records actions taken on EMR resources, helping with auditing and compliance by logging events and generating reports.
- Apache Ranger Support: For fine-grained access control, EMR supports Apache Ranger, which enables you to manage permissions across the Hadoop ecosystem effectively.
- Compliance: AWS EMR is compliant with several industry standards, including HIPAA, PCI DSS, and SOC, providing a secure platform that meets stringent compliance needs
Databricks Security and Governance
Databricks also offers a comprehensive set of security features tailored for cloud environments:
- Identity and Access Management: Databricks integrates with cloud-specific identity providers (such as Azure AD, AWS IAM, and Google IAM) to centralize authentication. Single sign-on (SSO) support and multi-factor authentication (MFA) enhance security for identity management.
- Access Control:
- Role-Based Access Control (RBAC): Admins can set granular permissions for users and groups, including access to notebooks, databases, and clusters.
- Fine-Grained Access Control: Databricks Unity Catalog provides column- and row-level security, allowing access control at a finer level across tables and data assets, especially helpful for sensitive data.
- Data Encryption:
- Encryption at Rest and in Transit: Databricks uses encryption to protect data both at rest and in transit. For data at rest, encryption is applied at the storage layer using mechanisms like AWS KMS (Key Management Service), Azure Key Vault, or GCP CMEK depending on the cloud provider. For data in transit, all communications are encrypted using TLS (Transport Layer Security) to ensure secure data transfer between components.
- Secret Management: Databricks includes a robust secret management system that allows secure storage and access to sensitive information like database credentials and API keys. It provides a "Secrets" utility to reference credentials securely in notebooks and workflows without exposing them in plaintext. Users can manage secrets via Databricks CLI, the Secrets API, or the web interface. Access control can be applied to secret scopes, and secret redaction is employed to limit visibility in notebooks.
- Network Security: Configurations like IP access lists and secure VPC deployments enable you to restrict access based on network location. Also, you can enforce restrictions on data movement to prevent data exfiltration.
- Auditing: Databricks offers comprehensive auditing tools that track user activities, resource access, and potential anomalies.
- Compliance: Databricks also meets several industry compliance standards such as SOC 2, HIPAA, and PCI DSS, ensuring secure operations across regulated industries.
| Feature | AWS EMR | Databricks |
| Identity Management | Integrates with AWS IAM for access control via roles and policies, enabling granular permissions | Integrates with cloud-specific identity providers (e.g., Azure AD, AWS IAM); supports SSO and MFA for enhanced security |
| Access Control | Managed through IAM policies; permissions can be applied to users, roles, and resources | Role-Based Access Control (RBAC) and Unity Catalog provide fine-grained access control at column and row levels for sensitive data |
| Data Encryption |
|
|
| Network Isolation | Deploys clusters within a VPC; security groups manage inbound and outbound traffic | Configurable network protections like IP access lists and secure VPC deployment; options to limit data movement and prevent exfiltration |
| Auditing | Uses AWS CloudTrail for logging and auditing actions taken on EMR resources. | Detailed audit logging, including user activities and access logs; designed to detect anomalies, with tools for compliance monitoring. |
| Compliance | Complies with HIPAA, PCI DSS, SOC, and other industry standards | Complies with SOC 2, HIPAA, PCI DSS, and similar standards; Unity Catalog enhances governance for sensitive data handling |
🔮 AWS EMR vs Databricks both offers robust security features, but their approaches vary: AWS EMR’s strengths lie in network isolation and deep integration with other AWS security tools, while Databricks emphasizes role-based access and fine-grained data governance through Unity Catalog, making it more adaptable for large-scale, multi-cloud environments.
8). AWS EMR vs Databricks—Developer Experience
Collaboration Tools in Databricks
Databricks provides a unique notebook-style environment, called Databricks Notebooks, which supports Python, SQL, R, and Scala—enabling developers to work across multiple languages in one platform. Databricks Notebooks also have interactive widgets, extensive libraries, and data visualization options to support data exploration and analysis.
Databricks is designed for team collaboration with real-time editing, version control, and commenting, making it particularly well-suited for data science and analytics teams working on shared projects.
Development Environment in AWS EMR
AWS EMR provides two primary options for interacting with services running on its clusters:
1) EMR Notebooks: EMR Notebooks are tightly integrated with EMR clusters and AWS services like S3. These notebooks are suitable for data analysis, scripting, and prototyping directly within the AWS environment. EMR Notebooks are well-suited for ad-hoc analysis and rapid prototyping, especially if you're working primarily within the AWS infrastructure. But, they lack some of the specialized optimizations and features present in Databricks Notebooks.
2) EMR Studio: EMR Studio is a more comprehensive IDE, offering a more sophisticated interface tailored to Spark and big data workloads on EMR. This web-based IDE provides built-in Spark monitoring tools, interactive debugging, and notebook-based development, much like Databricks. EMR Studio supports Python, R, and Scala, with direct integration into AWS services, making it particularly useful for complex data science and engineering workflows. Here are some key features of EMR Studio:
- User Authentication: EMR Studio integrates with AWS Identity and Access Management (IAM), allowing secure access using corporate credentials.
- Collaboration Tools: Users can collaborate in real-time, share notebooks, and integrate with version control systems like GitHub or BitBucket.
- Job Scheduling: You can schedule workflows using orchestration tools such as Apache Airflow or AWS Managed Workflows for Apache Airflow.
- Data Exploration: The SQL Explorer feature allows users to browse data catalogs, run queries, and download results before diving into coding.
🔮 Databricks offers a unified notebook experience optimized for collaboration and fast visualization, while AWS EMR offers flexibility with both Jupyter-based EMR Notebooks and a full-featured IDE in EMR Studio. Databricks is the go-to choice for teams wanting an all-in-one notebook that supports multiple languages, while AWS EMR is a hit with developers who want options—either a straightforward notebook interface or a powerful development environment tied to the AWS ecosystem.
9). AWS EMR vs Databricks—Billing and Pricing Models
When comparing pricing for AWS EMR vs Databricks, the two platforms have distinct cost structures that correspond to their features and intended use cases. Here's a breakdown of their key pricing strategies and how they may affect overall costs based on unique workload requirements.
Detailed Pricing Breakdown for AWS EMR
AWS Elastic MapReduce (EMR) pricing varies by deployment type, resources used, and additional AWS services. Here's a breakdown of the primary pricing models for different AWS EMR configurations:
➥ AWS EMR on AWS EC2 (AWS Elastic Compute Cloud)
Using AWS EMR on EC2 incurs costs for the EMR service itself, the EC2 instances, and any Amazon Elastic Block Store (EBS) volumes. Here’s what you need to know:
- AWS EMR Costs: Based on cluster resources.
- AWS EC2 Options:
- On-Demand
- Reserved Instances (one- or three-year commitments)
- Savings Plans
- Spot Instances (up to 90% discount)
- Storage Charges: Additional costs for EBS volumes attached to EMR clusters.
Note: The cost varies by instance type (like Accelerated Computing, Compute optimized, GPU instance, General purpose, Memory optimized, Storage optimized) and region.
Example Cost Calculation (US-East-1 region)
For example an AWS EMR deployment with one master and two core nodes (c4.2xlarge instances) in the US-East-1 region, On-Demand pricing would apply as follows:
| Node Type | Resource | Rate | Monthly Cost |
| Master Node | EMR | $0.105/hour | $76.65 |
| EC2 | $0.398/hour | $290.54 | |
| Core Nodes (x2) | EMR | $0.105/hour | $153.30 |
| EC2 | $0.398/hour | $581.08 | |
| Total | $1,101.57 |
➥ AWS EMR on AWS EKS (Elastic Kubernetes Service)
Running AWS EMR on EKS involves charges for both EMR and EKS resources, and compute can be handled by either EC2 or AWS Fargate.
- AWS EC2 with EKS (Elastic Kubernetes Service): Charges apply for EC2 instances and EBS volumes used by worker nodes. Pricing is per usage, with detailed rates on the EC2 pricing page.
- AWS Fargate with EKS (Elastic Kubernetes Service): Charges are based on the vCPU and memory allocated from container image download start to EKS pod termination, rounded to the nearest second with a one-minute minimum.
For AWS EMR on EKS, costs are calculated based on requested vCPU and memory resources for the task or pod from image download to pod termination. Rates are specific to the AWS region in use.
For Example, (US East - Ohio):
- vCPU per hour: $0.01012
- Memory per GB per hour: $0.00111125
Lets say for running an EMR-Spark application on EKS with 100 vCPUs and 300 GB memory for 30 minutes:
| Resource | Quantity | Rate | Cost |
| vCPU | 100 | $0.01012/hour | $0.506 |
| Memory | 300 GB | $0.00111125/hour | $0.167 |
| Total | $0.673 |
Note: Additional EKS cluster fees may apply, and compute resources on EKS are separately charged if using AWS Fargate.
➥ AWS EMR on AWS Outposts
Pricing for AWS EMR (AWS Elastic MapReduce) on AWS Outposts aligns with standard EMR pricing. AWS Outposts extends AWS infrastructure to on-premises data centers, delivering consistent EMR functionality. For more in-depth AWS Outposts-specific charges, see AWS Outposts pricing page.
➥ AWS EMR Serverless
AWS EMR (AWS Elastic MapReduce) Serverless is a fully managed option, where you only pay for the vCPU, memory, and storage resources used by your applications.
AWS EMR Serverless automatically manages scaling, so costs are based on actual usage from application start to finish, billed per second with a one-minute minimum.
- Worker Resource Configuration: Flexible configurations allow you to define the number of vCPUs, memory (up to 120 GB), and storage per worker (up to 2 TB).
- Compute and Memory Rates: Rates depend on aggregate resource usage across all workers in an application.
- Storage Options: Standard ephemeral storage or shuffle-optimized storage for heavy data movement needs.
Rates Example (US East - Ohio):
- vCPU per hour: $0.052624
- Memory per GB per hour: $0.0057785
- Standard storage per GB per hour: $0.000111
Note: Additional AWS services such as Amazon S3 or Amazon CloudWatch may add to the cost, depending on the workload’s requirements.
For example, for a job running on EMR Serverless with 25-75 workers (each 4 vCPU, 30 GB memory), costs are calculated as follows:
| Resource | Configuration | Cost |
| vCPU | (100 x $0.052624 x 0.5) + (200 x $0.052624 x 0.25) | $5.26 |
| Memory | (750 x $0.0057785 x 0.5) + (1500 x $0.0057785 x 0.25) | $4.33 |
| Total | $9.59 |
➥ AWS EMR WAL
For applications requiring Apache HBase, AWS EMR provides a Write Ahead Log (WAL) service, which ensures data durability and rapid recovery in case of cluster or availability issues. Charges apply for storage (WALHours), read (ReadRequestGiB), and write (WriteRequestGiB) operations.
- WAL Storage (WALHours): Charges per hour per HBase region, with retention for 30 days if data isn't flushed to Amazon S3 or removed by the user.
- Read and Write Operations: Each write or read request through Apache HBase is billed based on data size.
Example Rates (US East - Ohio):
- WALHours: $0.0018/hour
- ReadRequestGiB, WriteRequestGiB: $0.0883 per GiB
For example, using EMR WAL with Apache HBase to log 3.55 million write and 1 million read requests over a month in the US-East-1 region:
| Request Type | Quantity | Rate | Cost |
| Write | 3.55 GiB | $0.0883/GiB | $0.30 |
| Read | 1 GiB | $0.0883/GiB | $0.08 |
| WAL Storage | 10 tables x 2 regions x 720 hours | $0.0018/hour | $25.92 |
| Total | $26.52 |
Detailed Pricing Breakdown for Databricks
Databricks uses a flexible, pay-as-you-go pricing model based on Databricks Units (DBUs) — a measure of processing power over time. This approach allows you to control costs without large upfront commitments.
Core Pricing Components
Databricks Units (DBUs)
A DBU measures the processing capability consumed across various tasks like ETL, machine learning, and SQL queries. How DBUs are used depends on a few factors:
- Data Volume: More data processed means higher DBU usage.
- Data Complexity: Complex operations consume more DBUs.
- Data Velocity: Faster streaming workloads increase DBU usage.
DBU Rates
Rates for DBUs vary depending on:
- Cloud Provider: AWS, Azure, or GCP
- Region
- Databricks Edition: Standard, Premium, or Enterprise
- Instance and Compute Types
- Committed Use Contracts
Pricing for Key Databricks Products
Below are the DBU rates for different products, covering tasks like job scheduling, Delta Live Tables, SQL, Data Science, and Model Serving.
| Product | DBU Rates (Starting At) |
| Jobs | Classic/Photon Clusters: $0.15/DBU |
| Serverless (Preview): $0.37/DBU (discounted from $0.74) | |
| Delta Live Tables (DLT) | DLT Core: $0.20/DBU |
| DLT Pro: $0.25/DBU | |
| DLT Advanced: $0.36/DBU | |
| Databricks SQL | SQL Classic: $0.22/DBU |
| SQL Pro: $0.55/DBU | |
| SQL Serverless: $0.70/DBU (includes instance cost) | |
| Data Science & ML | Classic All-Purpose/Photon Clusters: $0.40/DBU |
| Serverless (Preview): $0.75/DBU (includes compute cost) | |
| Model Serving | Model & Feature Serving: $0.07/DBU (includes instance cost) |
| GPU Model Serving: $0.07/DBU (includes instance cost) |
This table should give you a clear view of how Databricks charges for different products. Remember, prices may vary with region, edition, and contract specifics.
Here is the full Databricks Pricing Breakdown:
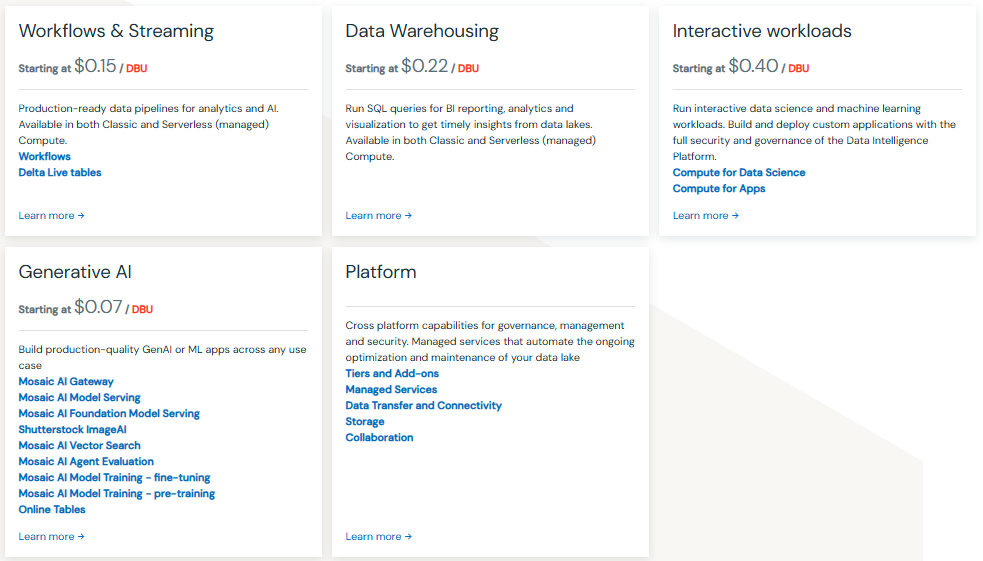
For more in-depth Databricks pricing breakdown, refer to:
Note: Pricing for each product varies based on the chosen cloud provider, region, Databricks edition, and compute type.
Check out this article to learn more in-depth about Databricks pricing.
AWS EMR vs Databricks—Pros & Cons
Now that we've completed our extensive comparison of these two platforms, let's highlight the essential pros and cons of each:
AWS EMR Pros and Cons
Here are the main AWS EMR pros and cons:
➥ AWS EMR Pros:
- AWS EMR connects seamlessly with Amazon services like S3, IAM, CloudWatch, and Glue, making data movement and orchestration across AWS much easier for large data processing tasks.
- AWS EMR supports popular data frameworks such as Apache Hadoop, Apache Spark, HBase, Presto and more, allowing you to tailor resources to various data processing needs, from ETL jobs to interactive queries
- AWS EMR’s auto-scaling capabilities help control costs by adapting to workload demand.
- AWS EMR offers encryption both at rest and in transit, as well as integration with AWS Identity and Access Management (IAM) and Virtual Private Cloud (VPC) for network isolation.
- EMR provides features like EMR Studio developers can build, test, and debug applications in an integrated environment that supports Python, R, and Scala, making it accessible for data science and engineering.
- The “pay-as-you-go” model of EMR makes it a perfect choice for temporary or fluctuating workloads. Combined with spot instances, it’s more affordable for short-term data processing.
➥ AWS EMR Cons:
- AWS EMR’s tight integration with AWS services can create vendor lock-in, making it less flexible for users looking to maintain a multi-cloud strategy.
- AWS EMR requires familiarity with AWS services and understanding of big data frameworks, leading to a steeper learning curve, especially for new users or those transitioning from a different cloud platform.
- AWS EMR is a fully managed service, so users are responsible for configuring clusters and tuning resources by themselves, which can become challenging for large-scale or highly variable workloads.
- Customizing and configuring EMR clusters to optimize performance for specific workloads requires in-depth expertise, especially for complex environments that span multiple frameworks (e.g., Spark and Hadoop).
- EMR lacks native ACID transaction support, unlike platforms like Databricks Delta Lake, requiring additional setup or third-party tools for robust data lake functionality.
Databricks pros and cons:
Here are the main Databricks pros and cons:
➥ Databricks Pros:
- Databricks combines data engineering, data science, and machine learning into a single collaborative platform, making it well-suited for teams working on end-to-end data projects.
- Databricks, which is optimized exclusively for Apache Spark, provides comprehensive tuning and automatic cluster management, resulting in great processing and analytics performance.
- Databricks’ Delta Lake provides features for reliable data lake management, such as ACID transactions, schema enforcement, and support for both batch and streaming data—this greatly enhances data reliability.
- Databricks offers enterprise-grade security features, including access controls, encryption, and auditing trails.
- Databricks Notebooks allow for real-time collaboration, making it easier for data engineers, data scientists, and analysts to co-develop and share code.
- Databricks operates on AWS, Azure, and Google Cloud, allowing for cross-cloud deployments and mitigating vendor lock-in concerns.
- Databricks provides extensive documentation and support from an active community.
➥ Databricks Cons:
- Databricks' DBU-based pricing can add up, especially for high-concurrency or resource-intensive tasks, impacting cost-efficiency for long-term, large-scale workloads.
- Databricks is tightly integrated with Spark, which, while ideal for Spark-centric workloads, may not be as beneficial for organizations needing a broader range of engines or tools (like Hadoop or Presto).
- New users unfamiliar with distributed processing may face a steep learning curve, especially those transitioning from traditional SQL-only or Hadoop environments
- Databricks’ managed nature means that users don’t have full control over underlying infrastructure, which may be a limitation for specific enterprise requirements around custom hardware or configurations.
- While Databricks is a comprehensive analytics platform, some users may still require additional third-party tools or libraries for specific data processing, data visualization needs, which can introduce complexity into workflows.
Further Reading
- Databricks documentation
- Amazon EMR Documentation
- Databricks vs Snowflake
- Databricks Pricing 101
- Databricks Delta Lake 101
- Databricks Competitors
- Amazon Elastic MapReduce Developer Guide
- What Is AWS EMR? Here's Everything You Need To Know
Save up to 50% on your Databricks spend in a few minutes!


Conclusion
And that’s a wrap! AWS EMR vs Databricks both of em’ are powerful platforms for big data processing and analytics, but they cater to different needs. AWS EMR fits seamlessly within the AWS ecosystem and is ideal for those already using AWS who require flexible, on-demand processing power. It supports multiple data processing engines and allows detailed control, offering maximum flexibility. However, this flexibility comes with a learning curve and requires manual management for optimal performance.
Databricks, on the other hand, is a unified data platform designed to enhance collaboration and productivity for teams working with Apache Spark and machine learning. With Delta Lake, Databricks supports reliable data lakes, ensuring data quality and consistency for long-term projects. Its collaborative features, built-in machine learning capabilities, and multi-cloud support—including AWS, Azure, and GCP—make it an attractive choice for scaling data workloads. However, its pricing and reliance on Apache Spark might be potential drawbacks.
So, choosing between AWS EMR vs Databricks ultimately depends on your specific needs. What does your infrastructure look like, and do you need customizability? How flexible do you need to be with data processing? Are collaboration tools for your team a priority? And finally, what’s your budget?
In this article, we have covered:
- What Databricks is
- What AWS EMR is
- AWS EMR vs Databricks—High-Level Feature Comparison
- What Is the Difference Between EMR and Databricks?
- AWS EMR vs Databricks—Core Architecture Breakdown
- AWS EMR vs Databricks—Data Processing Engines
- AWS EMR vs Databricks—Hybrid and Multi-Cloud Deployment Capabilities
- AWS EMR vs Databricks—Ecosystem and Integration
- AWS EMR vs Databricks—Machine Learning and Analytics
- AWS EMR vs Databricks—Scalability and Performance
- AWS EMR vs Databricks—Security and Governance
- AWS EMR vs Databricks—Developer Experience
- AWS EMR vs Databricks—Billing and Pricing Models
- AWS EMR Pros and Cons
- Databricks Pros and Cons
FAQs
What is AWS EMR?
Amazon EMR (Elastic MapReduce) is a cloud-based big data platform that enables users to process large volumes of data across scalable EC2 clusters using frameworks such as Apache Hadoop, Spark, Presto, and Hive. Integrated within AWS, EMR is used primarily for data transformation, analytics, and machine learning applications, particularly for users already invested in the AWS ecosystem.
What is Databricks used for?
Databricks is primarily used for data engineering, machine learning, and analytics. It provides a unified platform that integrates data processing, collaborative notebooks, and machine learning workflows, enabling teams to work together effectively on large datasets.
What is AWS EMR used for?
AWS EMR is used for processing large-scale data sets, running batch jobs, and performing data analysis. It supports various frameworks like Hadoop and Spark, making it suitable for ETL (Extract, Transform, Load) operations, data warehousing, and real-time analytics.
How do Databricks and Amazon EMR handle scaling?
Both platforms offer auto-scaling capabilities; however, Databricks provides a more seamless experience with its serverless architecture, automatically adjusting resources based on workload demands.
Which platform offers better performance for Spark applications?
Databricks is often considered faster for Spark applications due to its optimized runtime and additional features like caching and query optimization.
What is the difference between EMR and Databricks?
AWS EMR vs Databricks have some key differences—mainly in their architecture, ecosystem integrations, and target users. EMR is closely tied to AWS and supports a wide range of data processing engines which can handle all sorts of data processing tasks. On the other hand, Databricks is geared towards teams that do data science and need collaborative tools for analytics and machine learning. It uses Apache Spark and Delta Lake to build advanced data lakes, making it a great fit for those teams.
Is there a difference in the learning curve between the two?
Databricks generally has a gentler learning curve due to its user-friendly interface and integrated tools, whereas Amazon EMR may require more familiarity with AWS services.
What data storage options do EMR and Databricks provide?
Amazon EMR primarily uses Amazon S3 for storage, while Databricks can connect to any object storage across supported cloud platforms.
Who are Databricks' biggest competitors?
Databricks' main competitors include:
- Snowflake
- Amazon Redshift
- Google BigQuery
- AWS EMR
- Microsoft Fabric
- Microsoft Azure Synapse
What is equivalent to Databricks in AWS?
The closest equivalent to Databricks in AWS is AWS EMR.
Can we run Databricks on AWS?
Yes, Databricks can be run on AWS. It provides a managed service that integrates with AWS resources, allowing users to leverage the benefits of both platforms.
Can we perform ETL in Databricks?
Yes, Databricks supports ETL operations. Its capabilities allow users to extract data from various sources, transform it using Spark's powerful processing capabilities, and load it into data warehouses or lakes efficiently.
Is AWS EMR a good choice for ETL processes?
Yes, AWS EMR is commonly used for ETL (Extract, Transform, Load) processes, as it supports scalable processing with Hadoop, Spark, and more. Its integration with AWS services like S3, Redshift, and Glue also facilitates data ingestion, transformation, and loading workflows, particularly within the AWS ecosystem.















