




























Apache Spark has revolutionized big data processing, providing fast, near real-time, horizontally scalable, and distributed computing capabilities. It's no wonder that Spark has become the preferred choice for enterprises seeking high-speed, efficient solutions for processing big datasets in parallel. What genuinely distinguishes Spark is its tight connection with Scala—the language it was originally built with. This relationship isn’t accidental. Scala's seamless compatibility with Spark provides considerable benefits, including efficient code execution, extensive functional programming support, and strong type safety—all of which improve performance and reliability.
In this article, we'll cover everything you need to know about Apache Spark with Scala, why they are a powerful combination for data processing, and provide a step-by-step hands-on tutorial to get you started with using Scala APIs with Spark for data analysis.
What is Apache Spark?
Apache Spark is an open source, distributed computing system designed for fast and general-purpose data processing at scale. Spark was developed in 2009 at UC Berkeley's AMPLab and later became an Apache Software Foundation project in 2013. It was created to address the limitations of the Hadoop MapReduce, particularly in terms of performance for iterative algorithms and interactive data analysis.

Here are some key features of Apache Spark:
1) In-memory computing — Apache Spark can cache data in memory across operations, significantly speeding up iterative algorithms and interactive queries compared to disk-based systems.
2) Distributed processing — Apache Spark can distribute data and computations across clusters of computers, allowing it to process massive datasets efficiently.
3) Fault tolerance — Apache Spark's core abstraction, Resilient Distributed Datasets (RDDs), allows it to automatically recover from node failures.
4) Lazy evaluation — Apache Spark uses lazy evaluation in its functional programming model, which allows for optimized execution plans.
5) Unified engine — Apache Spark provides a consistent platform for various data processing tasks, including batch processing, interactive queries, streaming, machine learning, and graph processing.
6) Rich ecosystem — Apache Spark comes with higher-level libraries for SQL (Spark SQL), machine learning (MLlib), graph processing (GraphX), and stream processing (Structured Streaming).
7) Polyglot nature — Apache Spark is primarily written in Scala, but it also offers APIs in Java, Python, and R, making it accessible to a wide range of developers and engineers.
TL;DR: Apache Spark isn't just a computational engine—it's a framework that makes distributed computing easier and big data processing more efficient.
Save up to 50% on your Databricks spend in a few minutes!


Why Spark?
Now that we understand what Spark is, let's explore why it has become such a crucial tool in the big data landscape.
One reason Spark is widely used is that it's fast, scalable, and easy to use. It's different from Hadoop MapReduce because it processes data in-memory, which reduces processing time. This makes it a versatile tool that can handle various workloads on the same engine - from machine learning to graph processing. Whether you're working with a huge amount of data for real-time analytics or running big batch jobs, Spark can handle it efficiently.
Apache Spark has a wide range of use cases across various industries and applications.
- E-commerce: Real-time product recommendations, customer segmentation, and inventory optimization.
- Finance: Fraud detection, risk assessment, and algorithmic trading.
- Healthcare: Patient data analysis, disease prediction, and drug discovery.
- IoT and Telematics: Real-time sensor data analysis, predictive maintenance.
- Social Media: Network analysis, sentiment analysis, and trend prediction.
- Log Analysis: Real-time monitoring and anomaly detection in system logs.
Apache Spark's power and adaptability make it a top tool for organizations facing big data challenges. It's great for handling batch jobs, interactive queries, and building ML models. Plus, it can process real-time data streams. What's more, Spark offers one platform to take care of all these tasks.
Fundamentals of Apache Spark by Philipp Brunenberg
Spark and Scala—A Symbiotic Relationship
Scala's a natural fit with Spark since it was built using the same language. Scala, which stands for "Scalable Language", is a statically typed programming language that combines object-oriented and functional programming paradigms. The close integration between Scala and Spark has led to a symbiotic relationship, with Scala being the primary language for developing Spark applications.
Features and Benefits of Using Spark with Scala
Let's dive into why Scala is Spark's native language and the benefits this brings:
1) Performance — Scala compiles to Java bytecode and runs on the Java Virtual Machine (JVM), which provides excellent performance and optimization capabilities. Scala's type system allows for catching many errors at compile-time rather than runtime, which is crucial in distributed systems where runtime errors can be costly and difficult to debug.
2) Expressiveness — Scala's syntax is concise yet powerful, allowing developers to express complex operations in a readable manner. This is particularly useful for defining data transformations and analyses in Spark.
3) Functional Programming — Scala's strong support for functional programming aligns well with Spark's design, which heavily utilizes immutable data structures and higher-order functions. Scala's functional programming features enable concise and expressive code.
4) Type Safety — Scala's strong static typing helps catch errors at compile-time, reducing runtime errors in distributed environments where debugging can be challenging.
val data: RDD[Int] = sc.parallelize(1 to 10)
val result: RDD[String] = data.map(_.toString)5) Performance Optimizations — Scala's compiler can perform various optimizations, and its close alignment with Spark's internals allows for efficient code execution. For example, Scala's case classes work seamlessly with Spark's serialization system.
6) Access to Latest Spark Features — As Spark is primarily developed in Scala, new features are often available in the Scala API first, before being ported to other language APIs.
7) Seamless Integration with Java Libraries — Scala's interoperability with Java means you can easily use Java libraries in your Spark applications when needed.
Scala APIs vs PySpark, SparkR, and Java APIs
PySpark is popular due to Python's ease of use and extensive machine-learning libraries. That said, Scala offers better performance optimizations and type safety. Similarly, SparkR is useful for data scientists familiar with R, but it lacks the functional programming power and deep integration that Scala provides. Java APIs are also available but tend to be more verbose compared to Scala’s concise syntax.
TL;DR:
PySpark (Python API):
➤ Pros: Easier for Python developers, great for data science workflows, integrates well with Python's scientific computing ecosystem (NumPy, Pandas, etc.).
➤ Cons: Generally slower than Scala due to serialization overhead, may lag behind in features.
SparkR (R API):
➤ Pros: Familiar for R users, good for statistical computing and plotting.
➤ Cons: Limited functionality compared to Scala API, performance overhead.
Java API:
➤ Pros: Familiar for Java developers, good performance.
➤ Cons: More verbose than Scala, lacks some of Scala's functional programming features.
Here's a quick comparison of how a word count program might look in Spark Scala APIs and PySpark (Spark Python) APIs:
1) Scala:
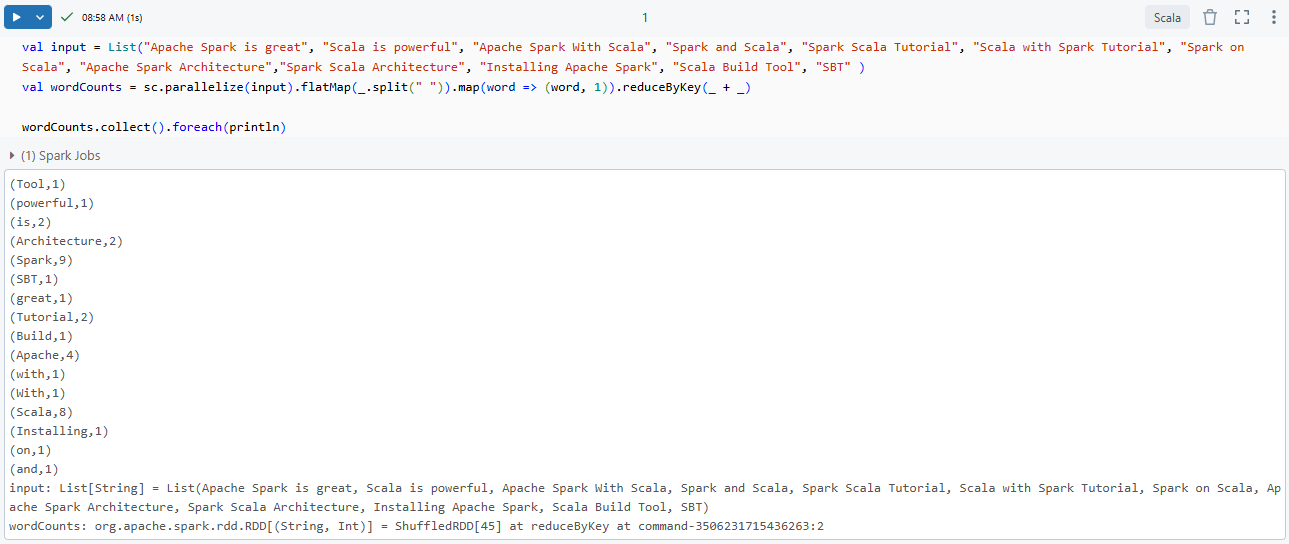
val input = List("Apache Spark is great", "Scala is powerful", "Apache Spark With Scala", "Spark and Scala", "Spark Scala Tutorial", "Scala with Spark Tutorial", "Spark on Scala", "Apache Spark Architecture","Spark Scala Architecture", "Installing Apache Spark", "Scala Build Tool", "SBT" )
val wordCounts = sc.parallelize(input).flatMap(_.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
wordCounts.collect().foreach(println)Comparison between Scala APIs vs PySpark - Apache Spark with Scala
2) PySpark:
input = ["Apache Spark is great", "Scala is powerful", "Apache Spark With Scala", "Spark and Scala", "Spark Scala Tutorial", "Scala with Spark Tutorial", "Spark on Scala", "Apache Spark Architecture","Spark Scala Architecture", "Installing Apache Spark", "Scala Build Tool", "SBT"]
word_counts = sc.parallelize(input).flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
print(word_counts.collect())
As you can see, the Scala version is concise and expressive, leveraging Scala's functional programming features to create readable and efficient code.
Apache Spark with Scala: Architecture Overview
To effectively use Apache Spark with Scala, it's crucial to understand Spark's architecture and how Scala interacts with its various components. Spark's architecture is designed for distributed computing, allowing it to process large amounts of data across a cluster of machines efficiently.
Apache Spark operates on a master-worker architecture, which consists of a driver program that manages the execution of tasks across a cluster of worker nodes.
Apache Spark architecture relies on two main abstractions:
The driver program is the entry point of a Spark application. It's responsible for:
- Creating a SparkContext (or SparkSession in newer versions)
- Defining the operations to be performed on data
- Submitting jobs to the cluster manager
- Coordinating the execution of tasks on executors
The cluster manager is responsible for resource allocation across the cluster. Spark can use several cluster managers:
- Standalone: Spark's built-in cluster manager
- Apache Mesos
- Hadoop YARN
- Kubernetes
3) Executors
Executors are worker nodes in the Spark cluster. They:
- Run tasks assigned by the driver program
- Store data in memory or on disk
- Return results to the driver
Execution Flow of a Spark Application
➥ App Submission
When a Spark application is submitted, the driver program is launched, which communicates with the cluster manager to request resources.
➥ Job Creation and DAG Formation
The driver translates user code into jobs, breaking them into stages, each further divided into tasks. A Directed Acyclic Graph (DAG) is created to represent the task and stage dependencies.
➥ Stage Division and Task Scheduling
The DAG scheduler breaks down the DAG into stages, and the task scheduler assigns tasks to executors based on resource availability and data locality.
➥ Task Execution on Worker Nodes
Executors process tasks on worker nodes, execute the computation and return results to the driver, which aggregates and presents the final output to the user.
How does Scala Interact with Spark?
Scala's interaction with Apache Spark is highly efficient due to its close integration with the Spark framework. Since Spark is primarily written in Scala, running applications in Scala provides direct access to Spark's APIs and leverages the Java Virtual Machine (JVM), resulting in efficient execution and eliminating the need for language translation during runtime.
Direct Compatibility with JVM
Scala runs on the Java Virtual Machine (JVM), just like Spark, which means Scala code does not require additional conversions or inter-process communication. This direct compatibility ensures that Spark applications written in Scala are executed with minimal overhead, leveraging Spark's native capabilities for performance optimization. Because both Spark and Scala are JVM-based, the processing is generally faster and more efficient than with non-JVM languages like Python or R, which require additional steps for execution (such as serialization/deserialization through PySpark).
Direct API Access
Spark's core APIs are designed with Scala in mind, offering several benefits:
- Native Access: Scala developers can directly interact with Spark's internals without additional abstraction layers, allowing for fine-grained control and optimization.
- Type Safety: Scala's strong type system helps catch errors at compile-time, enhancing code reliability and reducing runtime errors.
- Functional Programming Support: Spark's API design aligns well with Scala's functional programming paradigm, enabling concise and expressive code.
Type-Safe Data Manipulation
Scala interacts with Spark's structured data APIs through Datasets and DataFrames:
- Datasets: Provide strongly typed, compile-time safe data manipulation. In Scala, Datasets offer type inference and static analysis, catching potential errors at compile-time rather than runtime. They are particularly useful when working with domain-specific objects.
- DataFrames: Technically, a DataFrame in Spark is an alias for Dataset[Row], where Row is a generic, untyped JVM object. This unification simplifies the API while retaining performance benefits.
Functional Programming Paradigm
Scala's functional programming features align well with Spark's distributed computing model:
- Higher-order functions: Operations like
map,filter, andreduceare efficiently parallelized across Spark's distributed environment.
val numbers = spark.sparkContext.parallelize(1 to 1000000)
val sumOfSquares = numbers.map(x => x * x).reduce(_ + _)- Immutability: Scala's emphasis on immutable data structures complements Spark's fault-tolerant, distributed processing paradigm.
- Pattern matching: Enables concise and expressive data transformations on complex nested structures.
def processData(data: Any): String = data match {
case s: String => s"String: $s"
case i: Int if i > 0 => s"Positive Int: $i"
case _ => "Unknown type"
}Advanced Performance Optimizations
Since Spark is designed with Scala in mind, using Scala allows developers to tap into Spark's internal optimizations, such as Catalyst (query optimization) and Tungsten (memory and CPU efficiency).
Custom Serialization
Scala objects can be efficiently serialized for distribution across Spark clusters using Kryo serialization, which is often faster and more compact than Java's default serialization. To enable Kryo serialization:
val conf = new SparkConf().setAppName("MyApp")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
spark = SparkSession.builder().config(conf).getOrCreate()REPL Integration
Scala's Read-Eval-Print Loop (REPL) integrates seamlessly with Spark through the Spark Scala Shell, allowing for interactive data exploration and rapid prototyping of Spark jobs.
Here's a very simple example of how you can use Scala to interact with Spark:
1) Creating a SparkSession
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("Spark with Scala App").getOrCreate()Creating a SparkSession - Apache Spark With Scala
2) Creating an RDD
val rdd = spark.sparkContext.parallelize(List(1, 2, 3, 4, 5))Creating an RDD - Apache Spark With Scala
3) Using map and reduce to process the RDD
val result = rdd.map(x => x * 2).reduce((x, y) => x + y)Using map and reduce to process the RDD
4) Printing the result
println(result)Printing the result - Apache Spark With Scala
5) Creating a DataFrame
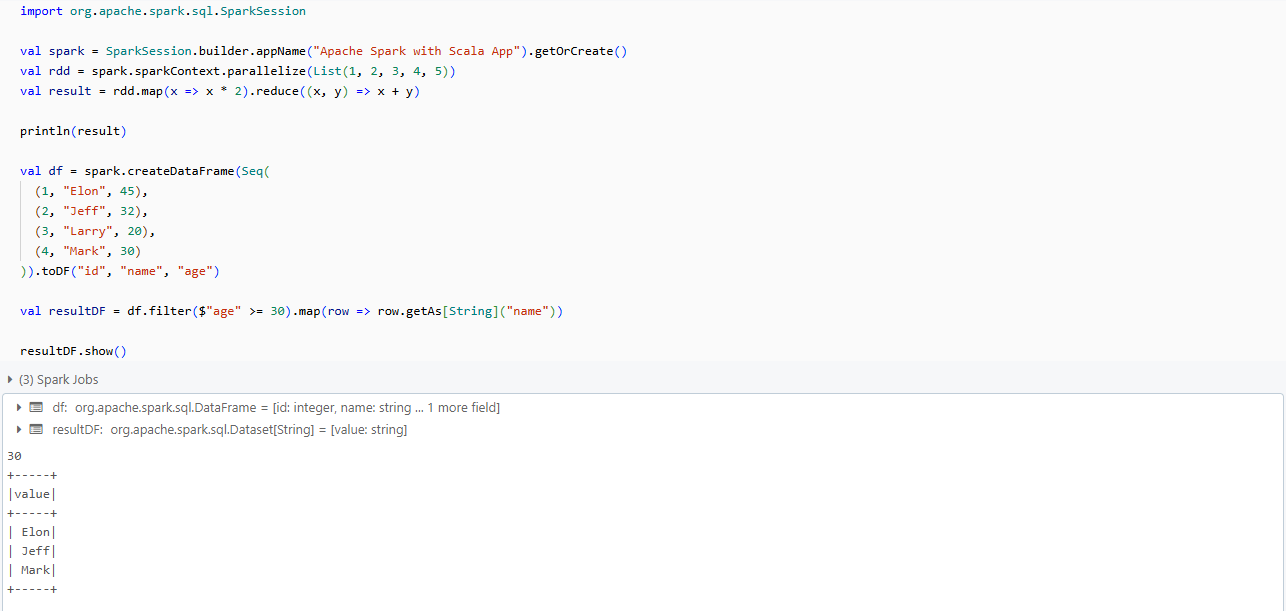
val df = spark.createDataFrame(Seq(
(1, "Elon", 45),
(2, "Jeff", 32),
(3, "Larry", 20),
(4, "Mark", 30)
)).toDF("id", "name", "age")Creating a DataFrame - Apache Spark With Scala
6) Using filter and map to process the DataFrame
val resultDF = df.filter($"age" >= 30).map(row => row.getAs[String]("name"))Using filter and map to process the DataFrame - Apache Spark With Scala
7) Printing the final result
resultDF.show()Printing the final result - Apache Spark With Scala
This easy and seamless interaction allows Scala developers to leverage Spark's full potential, making it the most efficient language for Spark-based applications.
Step-by-Step Guide to Installing Apache Spark with Scala (Windows, Mac, Linux)
Now that we understand Spark's architecture and its relationship with Scala, let's set up a Spark environment with Scala. We'll cover installation steps for Windows, macOS, and Linux.
Prerequisites
Before we start, make sure you have the following installed:
- Java Development Kit (JDK) 8 or 11 (Spark 3.x is compatible with both).
- A text editor or IDE (VScode or IntelliJ IDEA with the Scala plugin is recommended for Scala development).
1) Installing Apache Spark with Scala on Windows
Step 1—Install Java Development Kit (JDK)
First, download the JDK from the Oracle website or use OpenJDK.
Run the installer and follow the prompts to complete the installation.
Now, set the JAVA_HOME environment variable:
- Right-click on “My Computer “This PC” > Properties > Advanced system settings > Environment Variables
- Add a new system variable JAVA_HOME and set it to your JDK installation path (e.g., C:\Program Files\Java\jdk….)
To verify the installation, open Command Prompt and type:
java --versionStep 2—Install Scala
Next, download Scala from the official Scala website, or use scoop or choco (Windows package managers) to install it.
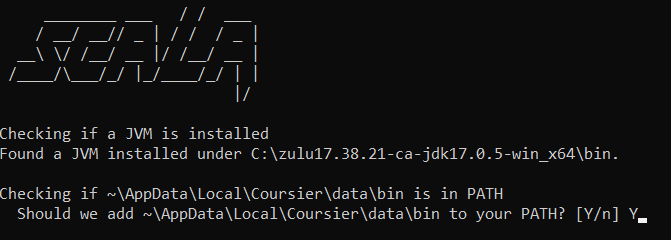
Run the installer, and type “Y” to add it to the PATH. And, to verify the installation, open the command prompt, and type:
scala -version
Step 3—Install Apache Spark
Go to the Apache Spark download page and select a pre-built version for Hadoop. Download the .tgz file.
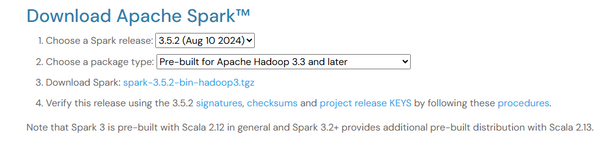
Create a directory for Spark, e.g., C:\spark, and extract the downloaded Spark file into this directory. Verify the extraction and check that the bin folder contains the Spark binaries.
Step 4—Install winutils
Download winutils.exe from the Winutils repository corresponding to your Hadoop version (e.g., Hadoop 3). Then, create a folder named “C:\winutils\bin” and place winutils.exe inside it.
Set environment variables:
- SPARK_HOME: Set it to the path of your extracted Spark folder, e.g., C:\spark\spark-3.x.x-bin-hadoop3.x.
- HADOOP_HOME: Set it to C:\winutils.
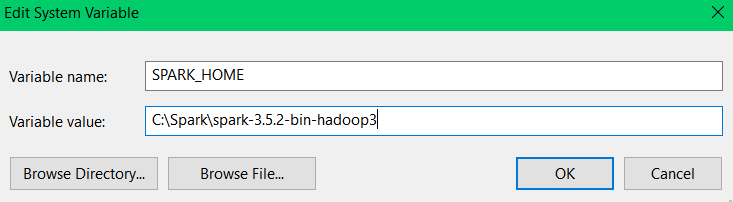
Next, add HADOOP_HOME by creating another variable named HADOOP_HOME, and set its value to C:\winutils.
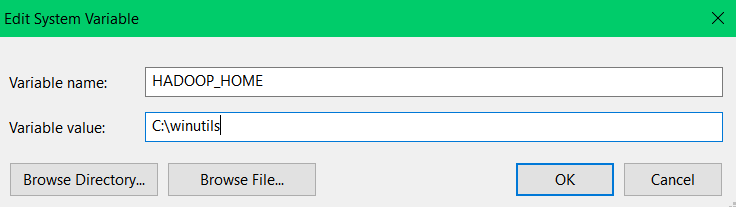
Once these variables are set, update the system's Path variable by editing it and adding the following entries:
%SPARK_HOME%\bin
%HADOOP_HOME%\binStep 5—Verify Spark with Scala Installation
To verify Spark with Scala installation, head over to your Command Prompt and type:
spark-shellThis command will start the Scala REPL with Spark. You should see the Spark logo and a Scala prompt.
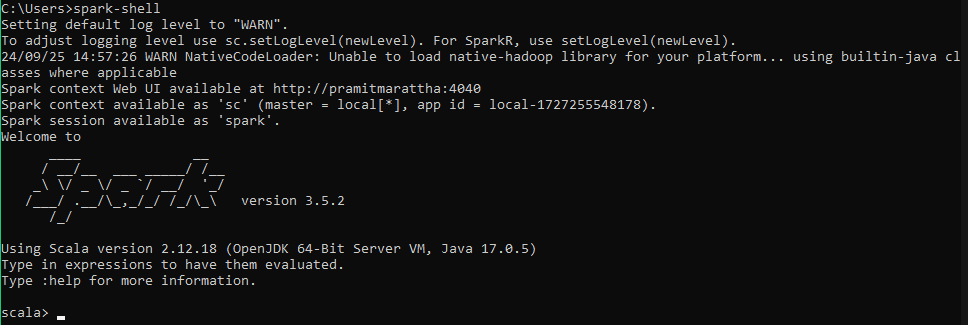
Test a basic Spark operation:
val data = spark.range(1, 100)
data.filter(_ % 2 == 0).count()Testing a basic Apache Spark with Scala operation - Installing Apache Spark on Windows
2) Installing Apache Spark with Scala on Mac
Step 1—Install Homebrew (if not already installed)
Open your terminal and run the following command to install Homebrew:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"Step 2—Install Java Development Kit (JDK)
Install OpenJDK using Homebrew:
brew install openjdkFollow the instructions in the terminal to add Java to your PATH.
After installation, verify that Java is installed correctly by checking the version:
java -versionStep 3—Install Scala
Install Scala using Homebrew:
brew install scalaVerify the installation:
scala -version
Step 4—Install Apache Spark
Install Spark using Homebrew:
brew install apache-sparkStep 5—Set Environment Variables
Open your shell configuration file (e.g., ~/.zshrc or ~/.bash_profile):
open -e ~/.bash_profileAdd the following configuration to the file:
export SPARK_HOME=/usr/local/Cellar/apache-spark/3.x.x/libexec
export PATH=$PATH:$SPARK_HOME/binReplace 3.x.x with your installed Spark version.
Save the file and reload the environment:
source ~/.bash_profileStep 6—Verify Apache Spark with Scala Installation
Open a new Terminal window and run:
spark-shell This will start the Scala REPL with Spark.
Installing Apache Spark with Scala on Linux (Ubuntu, Debian, CentOS)

Step 1—Install Java (OpenJDK via the package manager)
Open a terminal and update the package manager and install Java runtime environment:
sudo apt update
sudo apt install default-jreVerify Java installation:
java -versionStep 2—Install Scala
Install Scala using the package manager:
sudo apt install scalaVerify the installation:
scala -versionStep 3—Install Apache Spark
Download Spark:
wget https://downloads.apache.org/spark/spark-3.x.x/spark-3.x.x-bin-hadoop3.tgzReplace 3.x.x with the latest version number.
Extract the Spark archive:
tar xvf spark-3.x.x-bin-hadoop3.tgz
sudo mv spark-3.x.x-bin-hadoop3 /opt/sparkStep 5—Set Environment Variables
Open your shell configuration file (e.g., ~/.bashrc). Add the following lines:
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/binSave the file and reload it:
source ~/.bashrcStep 6—Verify Apache Spark with Scala Installation
To verify Spark with Scala installation, open a new Terminal window and run the following command:
spark-shell This will start the Scala REPL with Spark.
Getting Started on Apache Spark with Scala
Now that we have Spark and Scala installed, let's dive into some basic operations to get you started with Spark programming in Scala.
Step 1—Create a SparkSession
SparkSession is the entry point for programming Spark with the Dataset and DataFrame API. Here's how to create one:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder()
.appName("Getting Started")
.master("local[*]")
.getOrCreate()Step 2—Basic RDD operations
RDDs (Resilient Distributed Datasets) are the fundamental data structure of Spark. Let's perform some basic operations:
1) Creating an RDD (Resilient Distributed Datasets)
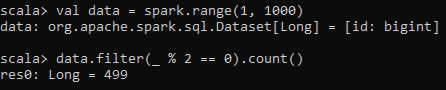
val data = sc.parallelize(1 to 1000)2) Transformation — Filtering all even numbers
val evenNumbers = data.filter(_ % 2 == 0)3) Action — Counting the elements
println(s"Number of even numbers: ${evenNumbers.count()}")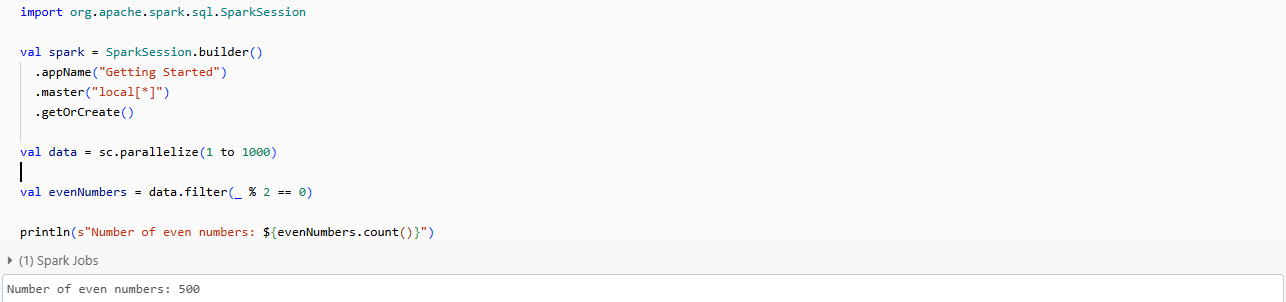
4) Transformation — Squaring each number
val squared = evenNumbers.map(x => x * x)5) Action — Collecting the results
val result = squared.take(10)
println(s"First 10 squared even numbers: ${result.mkString(", ")}")
Step 3—Introduction to DataFrames and Datasets
DataFrames and Datasets are distributed collections of data organized into named columns. They provide a domain-specific language for structured data manipulation:
First, let's create a DataFrame from a range.
val df = spark.range(1, 1000).toDF("number")Then, let's perform operations using DataFrame API.
val evenDF = df.filter($"number" % 2 === 0)
evenDF.show(5)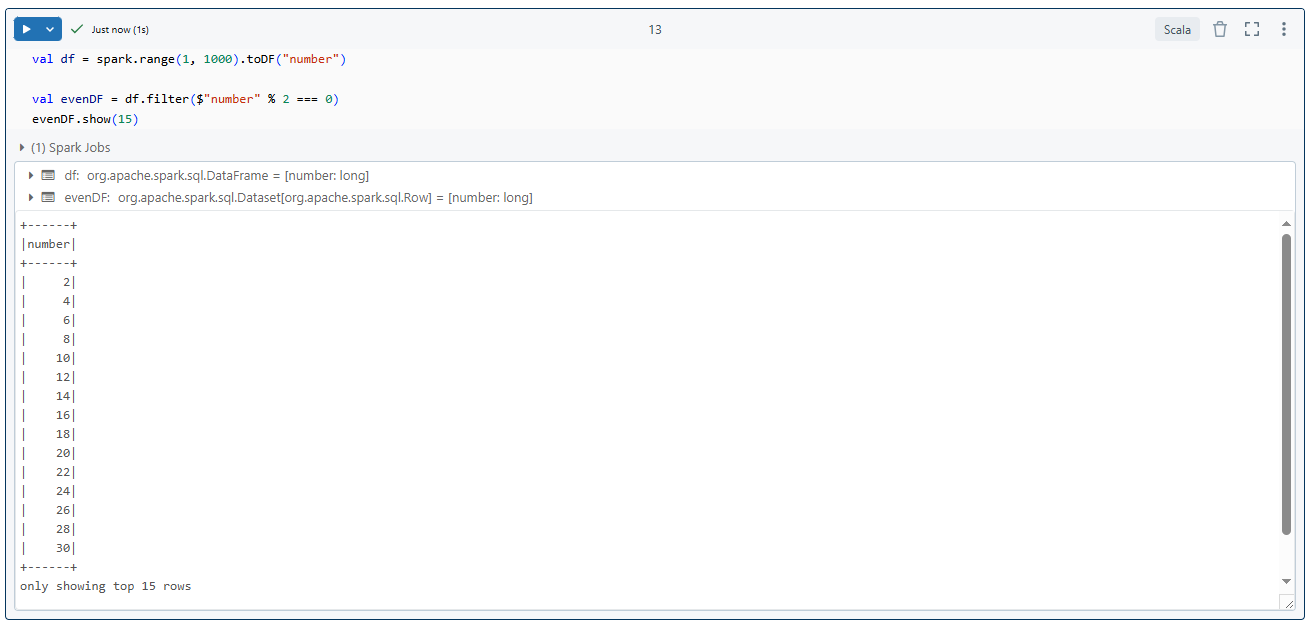
Now, here is how you could create a Dataset on Spark with Scala.
case class Person(name: String, age: Int)
val peopleDS = Seq(Person("Elon", 25), Person("Mark", 30), Person("Jeff", 20), Person("Larry", 40), Person("David", 50), Person("George", 30)).toDS()
peopleDS.show()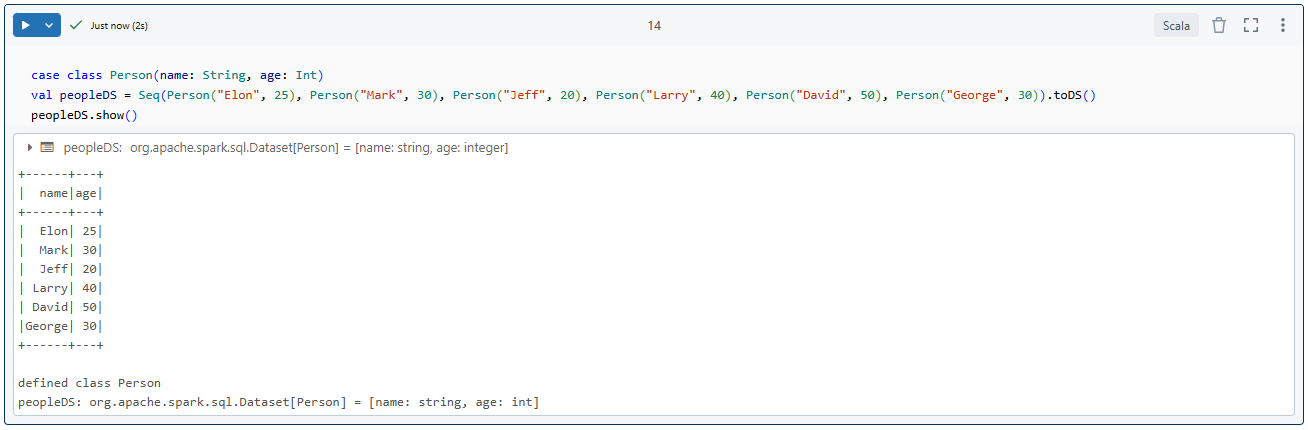
Step 4—Spark SQL basics
Spark SQL allows you to write SQL queries against your DataFrames:
1) Registering the DataFrame as a SQL temporary view
df.createOrReplaceTempView("numbers")2) Run a SQL query
val sqlDF = spark.sql("SELECT * FROM numbers WHERE number % 2 = 0 LIMIT 5")
sqlDF.show()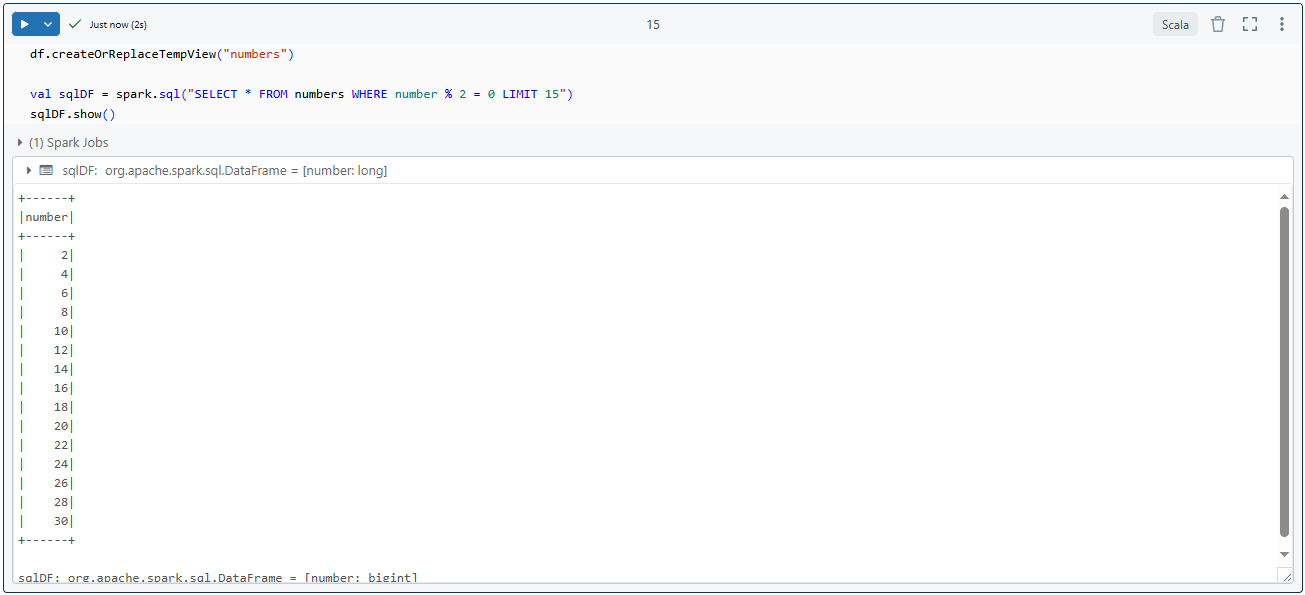
Step 5—Reading and writing data (various formats: CSV, JSON, Parquet)
Spark can read and write data in various formats. Let's look at CSV, JSON, and Parquet:
// Read CSV
val csvDF = spark.read
.option("header", "true")
.csv("path/to/your/file.csv")
// Read JSON
val jsonDF = spark.read.json("path/to/your/file.json")
// Read Parquet
val parquetDF = spark.read.parquet("path/to/your/file.parquet")
// Write DataFrame to Parquet
evenDF.write.parquet("path/to/output/directory")This concludes our initial exploration of Spark with Scala. Now, in the next section, we'll dive into more detailed and more hands-on examples of data analysis using these concepts.
Hands-on Example: Step-by-Step Data Analysis Using Spark with Scala
Now that we've covered the basics, let's work through a practical example of data analysis using Spark with Scala. We'll analyze a dataset of e-commerce transactions to derive some insights.
Step 1—Set Up Your Environment
First, make sure you have Spark with Scala installed as per the instructions in the previous section. Open your terminal and launch the spark-shell:
spark-shellThis command will start an interactive Scala shell with Spark context (sc) and Spark session (spark) pre-configured for immediate use.
Step 2—Create a New Scala Project
In spark-shell, you already have a SparkSession instance (spark) automatically created for you. If you’re working in a different environment, you can initiate a Spark session using the following code:
val spark = SparkSession.builder
.appName("Spark with Scala Example")
.master("local[*]")
.getOrCreate()The master("local[*]") setting tells Spark to run locally using all available CPU cores.
To load the scala file or want to execute the block of code in spark shell you can load the entire file and execute it to do so, you can type in the following command:
:load <your-file-name>.scalaStep 3—Load Data into Spark
Next, let’s load some sample data. This random dataset represents sales data for an imaginary retail store.
val data = Seq(
("Elon Musk", 52, "Technology", 2200),
("Jeff Bezos", 59, "E-commerce", 2000),
("Bernard Arnault", 74, "Luxury Goods", 1800),
("Bill Gates", 68, "Philanthropy", 1500),
("Warren Buffett", 93, "Investments", 1300),
("Larry Ellison", 79, "Software", 1600),
("Larry Page", 50, "Technology", 1400),
("Sergey Brin", 49, "Technology", 1400),
("Mark Zuckerberg", 39, "Social Media", 1000),
("Steve Ballmer", 67, "Technology", 900),
("Carlos Slim", 83, "Telecommunications", 1100),
("Mukesh Ambani", 66, "Energy", 1200),
("Francoise Bettencourt Meyers", 70, "Cosmetics", 800),
("Amancio Ortega", 87, "Fashion", 950),
("Gautam Adani", 61, "Energy", 1300)
)
val columns = Seq("Name", "Age", "Category", "Amount")
import spark.implicits._
val df = data.toDF(columns: _*)
df.show()Here, we create a sequence of tuples, where each tuple represents a customer’s data: Name, Age, Category (department they bought from), and Amount (total money spent). The toDF method converts this hardcoded data into a DataFrame with defined column names.
When you run df.show(), Spark prints the following output:
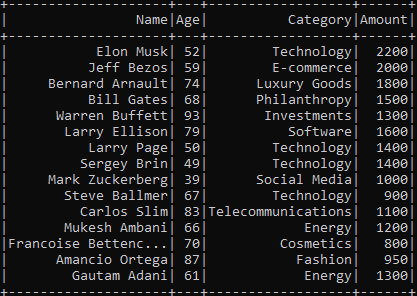
Step 4—Data Exploration and Cleaning
Before performing any analysis, it’s good practice to explore and clean the data. Let’s start by filtering any rows where the Amount spent is below a certain threshold (For e.g., 1000):
val filteredDF = df.filter($"Amount" >= 1000)
filteredDF.show()As you can see this code filters out customers who spent less than 1000.
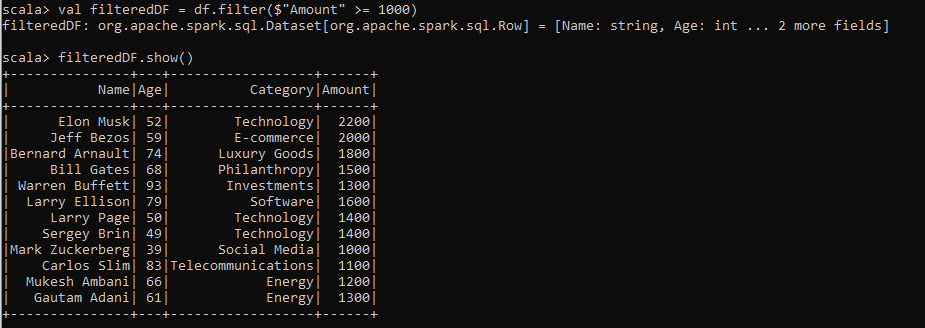
Step 5—Prepare and Transform Data
Next, let's transform the dataset. We'll add a new column called DiscountedAmount, which applies a 10% discount for amounts greater than 1100.
val transformedDF = filteredDF.withColumn("DiscountedAmount",
when($"Amount" > 1100, $"Amount" * 0.9).otherwise($"Amount"))
transformedDF.show()As you can see, this creates a new column with discounted values where applicable:
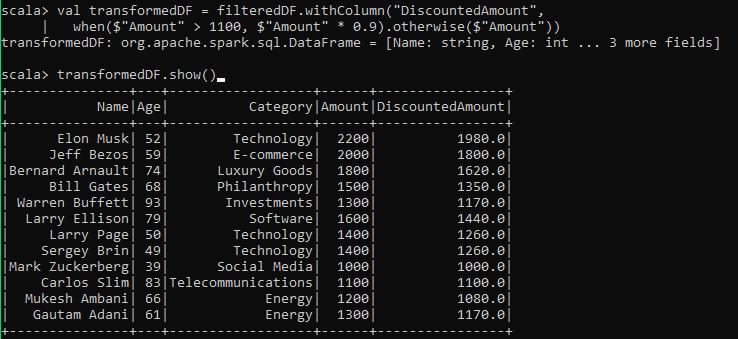
Step 6—Perform Grouped Analysis
Let’s group the data by Category and calculate the average amount spent per category:
val avgAmountDF = transformedDF.groupBy("Category").agg(avg("Amount").as("AvgAmount"))
avgAmountDF.show()The output would look like this:
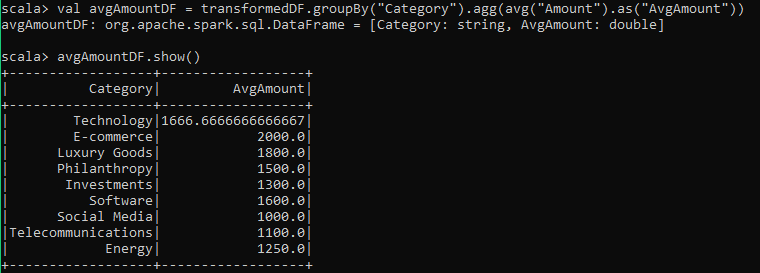
This provides insight into the spending behavior across different categories.
Step 7—Perform Analysis with Spark SQL
You can also register the DataFrame as a temporary view and use SQL to query the data. This is especially useful for more complex queries.
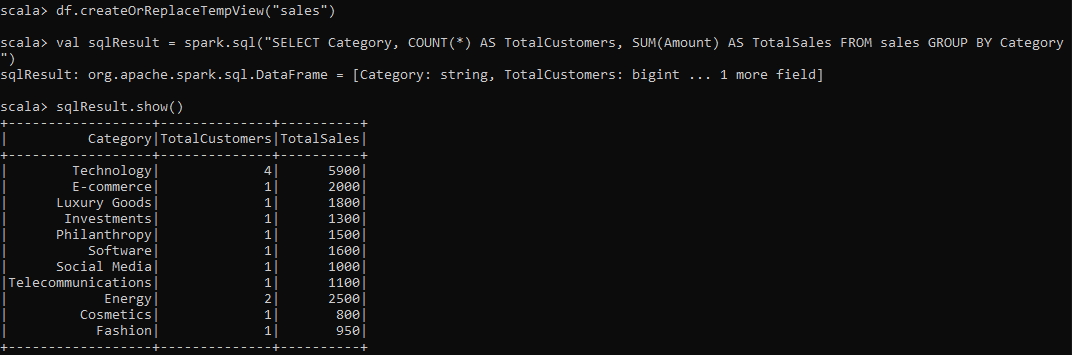
df.createOrReplaceTempView("sales")
val sqlResult = spark.sql("SELECT Category, COUNT(*) AS TotalCustomers, SUM(Amount) AS TotalSales FROM sales GROUP BY Category")
sqlResult.show()This SQL query counts the total number of customers and sums the total sales per category:
Step 8—Save Processed Data (Parquet, CSV, JSON)
Finally, you can save the processed DataFrame in multiple formats. For example, let’s save the final DataFrame in Parquet format:
transformedDF.write.parquet("path/to/output/output_parquet")Bonus: Configuring a Spark Project with sbt (Scala Build Tool)
Scala Build Tool (sbt) is the de facto build tool for Scala projects. It's particularly useful for managing dependencies and building Spark applications. Let's walk through the process of setting up a Spark project with sbt.
What is sbt (Scala Build Tool)?
sbt (Scala Build Tool) is a powerful and fully open source build tool for Scala and Java projects. It allows developers to manage project dependencies, compile code, run tests, and package applications efficiently. sbt uses a simple configuration file (build.sbt) to define project settings and dependencies.
sbt is similar in concept to tools like Maven and Gradle. However, sbt is specifically optimized for Scala's requirements, making it the default tool for Scala developers. Its key features include:
- sbt (Scala Build Tool) simplifies managing dependencies, including external libraries like Spark, Hadoop, and more.
- sbt (Scala Build Tool) continuously compiles and tests your code as you make changes, making development more efficient.
- sbt (Scala Build Tool) allows easy packaging of your application into JAR files, which you can deploy in different environments (e.g., local, cluster).
- sbt (Scala Build Tool) integrates smoothly with most major IDEs, like VScode, IntelliJ IDEA, and more, enhancing the development experience.
Prerequisites:
Before we start setting up the project, make sure that you have the following installed on your system:
- Java (version 1.8 JDK or higher): Spark relies on the JVM, so Java must be installed.
- Scala (version 2.12.x): Spark 3.x is compatible with Scala 2.12.x. Make sure you’re using the correct version.
- sbt (latest stable version): sbt manages your project dependencies and builds your code.
- Apache Spark: The version of Spark should be compatible with your Scala version. Spark 3.x works best with Scala 2.12.x.
- IDE (optional but recommended): VScode or IntelliJ IDEA with the Scala plugin is highly recommended for faster and smooth development.
Optionally, you can use Docker for a consistent development environment, especially if you need to switch between different versions of Spark, Scala, or Java.
Step 1—Install sbt
First, start by installing sbt. Use the following commands based on your operating system:
For macOS:
sdk install sbtbrew install sbt
For Windows:
Download the installer files:
> choco install sbt> scoop install sbtFor Linux:
Linux (deb):
echo "deb https://repo.scala-sbt.org/scalasbt/debian all main" | sudo tee /etc/apt/sources.list.d/sbt.list
curl -sL "https://keyserver.ubuntu.com/pks/lookup?op=get&search=0x2EE0EA64E40A89B84B2DF73499E82A75642AC823" | sudo apt-key add
sudo apt-get update
sudo apt-get install sbtLinux (rpm):
curl https://bintray.com/sbt/rpm/rpm | sudo tee /etc/yum.repos.d/bintray-sbt-rpm.repo
sudo yum install sbtVerify the installations by running the following commands in your terminal:
java -version
scala -version
sbt -version
Step 2—Setting Up the Project Structure
Now, let’s start by creating the basic structure for the Spark project. Open a terminal and create a new directory for the project:
mkdir SparkWithScalaProject
cd SparkWithScalaProjectInside this directory, you will need to create a typical sbt project structure:
mkdir -p src/main/scala
mkdir -p src/test/scalaThis creates a standard Scala project structure with separate directories for main and test code.
Step 3—Create the build.sbt File
In the root of the ‘SparkWithScalaProject’ directory, create a file named build.sbt and add the following content:
name := "SparkWithScalaProject"
organization := "com.example"
version := "0.1"
scalaVersion := "2.12.18"
val sparkVersion = "3.5.1"
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % sparkVersion,
"org.apache.spark" %% "spark-sql" % sparkVersion
)
// Configure sbt to fork a new JVM for running Spark jobs
fork := true
// Add additional settings if needed
javaOptions ++= Seq("-Xms512M", "-Xmx2048M", "-XX:+CMSClassUnloadingEnabled")
// If you want to run Spark in local mode by default
run / runLocal := trueThis build.sbt file sets up your project with Spark dependencies and configures sbt to fork a new JVM when running Spark jobs, which is important for proper classpath isolation.
Step 4—Create build.properties File
Create a build.properties file inside a new project folder to specify the sbt version:
mkdir project
echo 'sbt.version=1.10.2' > project/build.propertiesStep 5—Write Your First Scala Code
Create a simple Scala file named SparkWithScalaMain.scala in src/main/scala/com/example with the following content:
object SparkWithScalaMain extends App {
println("Spark with Scala!")
}Step 6—Compile and Run the Project Locally
Start the sbt console:
sbtIn the sbt console, compile your project:
compileRun your main object:
run
Exit the sbt console with:
exitStep 7—Add Data for Processing
Now, we will create sales data to analyze sales data for a store. Create a CSV file named sales_data.csv inside a new folder called data in your project directory:
mkdir dataAdd the following content to sales_data.csv:
TransactionID,Product,Quantity,Price,Date
1,Smartphone,2,699.99,2024-01-01
2,Washing Machine,1,499.99,2024-01-02
3,Laptop,1,999.99,2024-01-03
4,Tablet,3,299.99,2024-01-04
5,Headphones,5,99.99,2024-01-05
6,Smartwatch,2,249.99,2024-01-06
7,Refrigerator,1,899.99,2024-01-07
8,Television,2,1099.99,2024-01-08
9,Vacuum Cleaner,3,149.99,2024-01-09
10,Microwave,2,199.99,2024-01-10
11,Blender,4,59.99,2024-01-11
12,Air Conditioner,1,799.99,2024-01-12
13,Camera,1,549.99,2024-01-13
14,Speaker,3,199.99,2024-01-14
15,Smartphone,1,699.99,2024-01-15
16,Washing Machine,1,499.99,2024-01-16
17,Television,1,1099.99,2024-01-17
18,Laptop,1,1999.99,2024-01-18
19,Microwave,2,199.99,2024-01-19
20,Blender,3,59.99,2024-01-20
21,Camera,2,549.99,2024-01-21
22,Smartwatch,1,249.99,2024-01-22
23,Headphones,4,99.99,2024-01-23
24,Air Conditioner,1,799.99,2024-01-24
25,Vacuum Cleaner,2,149.99,2024-01-25
26,Smartphone,1,699.99,2024-01-26
27,Laptop,1,999.99,2024-01-27Step 8—Update build.sbt for Spark Dependencies
Make sure your build.sbt includes Spark dependencies if not already done:
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.5.0"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "3.5.0"Step 9—Implement Your Spark Job Logic
Create a package object by adding a file named package.scala in src/main/scala/com/example/sparktutorial with functions to create a Spark session and parse command-line arguments.
package com.example
import org.apache.spark.sql.SparkSession
package object sparktutorial {
def createSparkSession(appName: String): SparkSession = {
SparkSession.builder()
.appName(appName)
.master("local[*]")
.config("spark.sql.caseSensitive", value = true)
.config("spark.sql.session.timeZone", value = "UTC")
.getOrCreate()
}
def parseArgs(args: Array[String]): (String) = {
require(args.length == 1,"Expecting input path as argument")
val inputPath = args(0)
println(s"Input path: $inputPath")
inputPath
}
}Then create an analysis file named SalesAnalysis.scala in the same package with the following code to analyze the sales data:
package com.example.sparktutorial
import org.apache.spark.sql.{DataFrame,SparkSession}
import org.apache.spark.sql.functions._
object Analysis {
def analyzeSalesData(spark: SparkSession,inputPath: String): DataFrame = {
// Read sales data from CSV file into DataFrame
val salesDF = spark.read.option("header","true").csv(inputPath)
// Calculate total sales per product and add it as a new column 'TotalSales'
val resultDF = salesDF.withColumn("TotalSales",col("Quantity").cast("int") * col("Price").cast("double"))
.groupBy("Product")
.agg(sum("TotalSales").alias("TotalSales"))
.orderBy(desc("TotalSales"))
resultDF.show() // Display result in console
// Return result DataFrame for further processing if needed
resultDF
}
}
Step 10—Update Main Object to Call Analysis Logic
Update your SparkWithScalaMain.scala to include logic to call the analysis function:
package com.example.sparktutorial
import org.apache.spark.sql.SparkSession
object SparkWithScalaMain extends App {
// Create Spark session
val spark = createSparkSession("Spark Sales Analysis")
// Specify input path for sales data CSV file
val inputPath = args(0) // Pass input path as command line argument
// Call analysis function
Analysis.analyzeSalesData(spark,inputPath)
// Stop the Spark session
spark.stop()
}Step 11—Compile and Run Your Spark Job Locally
Compile and run the project using sbt, passing the input path of the CSV file:
sbt "run data/sales_data.csv"
This command will read from sales_data.csv, perform the analysis defined in SalesAnalysis.scala, and display results in the console.
Step 12—Configure Logging
Create a log4j2.properties file in src/main/resources to manage logging output:
status = error
name = PropertiesConfig
appender.console.type = Console
appender.console.name = ConsoleAppender
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{HH:mm:ss.SSS} [%t] %-5level %msg%n
rootLogger.level = INFO
rootLogger.appenderRefs = console
rootLogger.appenderRef.console.ref = ConsoleAppender Step 13—Package Your Application as a JAR
Use the following SBT command to package your project into a JAR file:
sbt packageThis will generate a JAR file in the target/scala-2.13/ directory (depending on your Scala version). However, this JAR will not include any dependencies.
Step 14—Packaging using sbt-assembly to Create a Fat JAR
To package your project along with its dependencies into a single standalone JAR (often referred to as a fat JAR), you'll need the sbt-assembly plugin.
Add the sbt-assembly plugin to your project by creating a project/plugins.sbt file with the following content:
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "1.1.0")Next, configure sbt-assembly in your build.sbt file:
assemblyOption in assembly := (assemblyOption in assembly).value.copy(includeScala = false)
mainClass in assembly := Some("com.example.sparktutorial.SparkWithScalaMain")Finally, run the following command to generate a fat JAR:
sbt assembly
This will produce a JAR file with all dependencies bundled, which you can run or distribute as needed.
Step 15—Submit Your JAR to Spark Cluster
Use the following command to submit your JAR file to your Spark cluster (replace <master-url> with your actual master URL):
spark-submit \
--class com.example.sparktutorial.SparkWithScalaMain \
--master <master-url> \
target/scala-2.12/sparkexample-assembly-0.1.jar \
data/sales_data.csv
Replace <master-url> with your Spark cluster's master URL (e.g., yarn for YARN cluster, spark://host:port for standalone cluster). And, make sure sparkexample-assembly-0.1.jar matches the exact artifact name generated by sbt-assembly.
Follow these steps and you'll be all set to create, develop, and run Spark projects in Scala using sbt.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Further Reading
To continue your journey with Apache Spark and Scala, here are some valuable resources:
Official Documentation:
Books:
- "Learning Spark: Lightning-Fast Data Analytics" by Jules S. Damji et al.
- "Spark: The Definitive Guide" by Bill Chambers and Matei Zaharia
- "Programming in Scala" by Martin Odersky, Lex Spoon, and Bill Venners
Online Courses:
- Coursera: "Big Data Analysis with Scala and Spark"
- edX: "Introduction to Apache Spark" by UC Berkeley
Community Resources:
Articles and Tutorials:
Comparison Articles:
Conclusion
Apache Spark with Scala offers a powerful toolset for big data processing and analysis. Throughout this guide, we've explored the symbiotic relationship between Spark and Scala, delved into Spark's architecture, and walked through the process of setting up a Spark environment and building Spark applications using Scala.
In this article, we've covered:
- Fundamentals of Apache Spark and its ecosystem
- Why has Spark become a go-to solution for big data processing?
- Benefits of using Scala with Spark
- How to set up a Spark environment on different operating systems?
- Basic and advanced Spark operations using Scala
- A hands-on example of data analysis using Spark with Scala
- How to configure and manage Spark projects using sbt
… and so much more!
FAQs
What is Apache Spark?
Apache Spark is an open source, distributed computing system designed for fast and general-purpose data processing at scale, developed to overcome the limitations of Hadoop MapReduce.
How does Apache Spark achieve fault tolerance?
Spark uses Resilient Distributed Datasets (RDDs), which allow automatic recovery from node failures by maintaining lineage information.
What is lazy evaluation in Spark?
Lazy evaluation means that Spark does not execute operations until an action is called, allowing it to optimize execution plans and reduce unnecessary computations.
What role does the driver program play in a Spark application?
The driver program creates a SparkContext, defines operations on data, submits jobs to the cluster manager, and coordinates task execution on executors.
How do executors function within a Spark cluster?
Executors are worker nodes that run tasks assigned by the driver program and store data either in memory or on disk while returning results to the driver.
What is Scala with Spark?
Scala is the native language for Spark, offering deep integration, type safety, and performance optimizations.
How do I run Scala in Spark?
You can run Scala in Spark using the spark-shell for interactive mode or by creating a full project with sbt for production-level code.
How do you verify your installation of Spark with Scala?
You can verify your installation by running spark-shell in your command line, which should display the Spark logo and a Scala prompt.
What is the difference between using Scala APIs and PySpark?
Scala APIs offer better performance optimizations and type safety compared to PySpark, which is easier for Python developers but may lag in features and speed due to serialization overhead.
Can you use Scala 3 with Spark?
Scala 3 support is gradually improving, but Spark primarily supports Scala 2.12 and 2.13. Make sure to check the compatibility with your Spark version before upgrading.
Can I use Scala in PySpark?
While PySpark primarily uses Python, Scala can still be utilized when Spark jobs are deployed to a cluster, enabling mixed-language pipelines.
What are some alternatives to using Scala with Apache Spark?
Alternatives include PySpark (Python API), which is user-friendly but slower, and Java APIs which are more verbose compared to Scala’s concise syntax.
Is Scala better than Python for Spark?
Scala provides better performance and type safety compared to PySpark. However, Python has a richer ecosystem of data science libraries, making it more popular in some scenarios.















