





























We're drowning in a sea of data. Seriously, it's like trying to drink from a firehose. To make sense of this overwhelming flood, we need to process it efficiently and intelligently. Choosing the right data processing framework is key, as it helps in generating insights, improving efficiency, enabling real-time analysis, and scaling operations. Apache Spark and Apache Flink are two popular options that can handle huge datasets. But, they differ in terms of how they're built, how they process data, and what they're best for.
In this article, we will provide an in-depth comparison between Apache Spark vs Flink, diving into their architectures, data processing models, performance benchmarks, fault tolerance mechanisms, APIs, optimization techniques, community support, use cases, and their respective pros and cons.
Table of Contents
What is Apache Flink?
Apache Flink is an open source stream processing framework that excels in both stream and batch processing capabilities, making it ideal for high-throughput and low-latency data processing. It is particularly well-suited for applications requiring real-time analytics and complex event processing. Flink's architecture is built on a true streaming model, meaning it can process data as it arrives, rather than waiting for a complete dataset to be available.

Here are some key features of Apache Flink:
1) True Streaming Architecture — Apache Flink processes data in real-time, allowing for immediate insights and actions. It supports event-time processing, enabling it to handle out-of-order events effectively.
2) Stateful Stream Processing — Apache Flink maintains state across events, allowing for complex event processing and enabling applications to track information over time. It provides exactly-once processing guarantees, ensuring that data is neither lost nor duplicated in the event of failures.
3) Unified Batch and Stream Processing — Apache Flink treats batch processing as a special case of stream processing, allowing users to leverage the same APIs and concepts for both types of workloads.
4) Advanced Windowing Capabilities — Apache Flink supports various windowing strategies, including event-time, processing-time, and session windows, making it suitable for complex event pattern detection.
5) Custom Memory Management — Apache Flink implements its own memory management system, which reduces garbage collection overhead and improves performance.
6) Rich Ecosystem — Apache Flink includes libraries for machine learning (FlinkML), complex event processing (FlinkCEP), and graph processing (Gelly), providing a comprehensive toolset for developers.
Apache Spark vs Flink
Save up to 50% on your Databricks spend in a few minutes!


What is Apache Spark?
Apache Spark is also an open source big data processing framework that provides fast and general-purpose cluster computing. Originally designed for batch processing, Spark has evolved to support a wide range of data processing tasks, including streaming, machine learning, and graph processing.

Here are some key features of Apache Spark:
1) 100x Speed — Apache Spark can process data up to 100 times faster in memory and 10 times faster on disk compared to traditional disk-based systems like Apache Hadoop.
2) In-Memory Computing — Apache Spark's in-memory processing capabilities allow it to cache intermediate data, significantly speeding up processing times compared to traditional disk-based systems.
3) Fault Tolerance via Resilient Distributed Datasets in Spark (RDDs) — RDDs are the fundamental data structure in Apache Spark, enabling fault-tolerant processing through lineage tracking. This allows Spark to recover lost data by recomputing it from the original sources.
4) Rich API Support — Apache Spark provides APIs in multiple languages, like Java, Scala, Python, and R.
5) Comprehensive Libraries — Apache Spark includes a suite of libraries for various tasks, such as MLlib for machine learning, GraphX for graph processing, and Spark Streaming for processing real-time data.
7) Highly Scalable — Apache Spark can easily scale horizontally by adding more nodes to a cluster, enabling it to handle large volumes of data efficiently.
… and more!!
Apache Spark vs Flink
What Is the Difference Between Apache Flink and Apache Spark?
Apache Spark and Apache Flink are similar in many ways when it comes to handling data, but they have some big differences too. So, let's dive in and see how they compare against each other. We'll take a close look at their architecture, how they process data, performance, fault tolerance, APIs, optimization techniques, ecosystem support, and what kinds of jobs they're best for.
1). Apache Spark vs Flink — Architecture Showdown
Apache Flink Architecture:
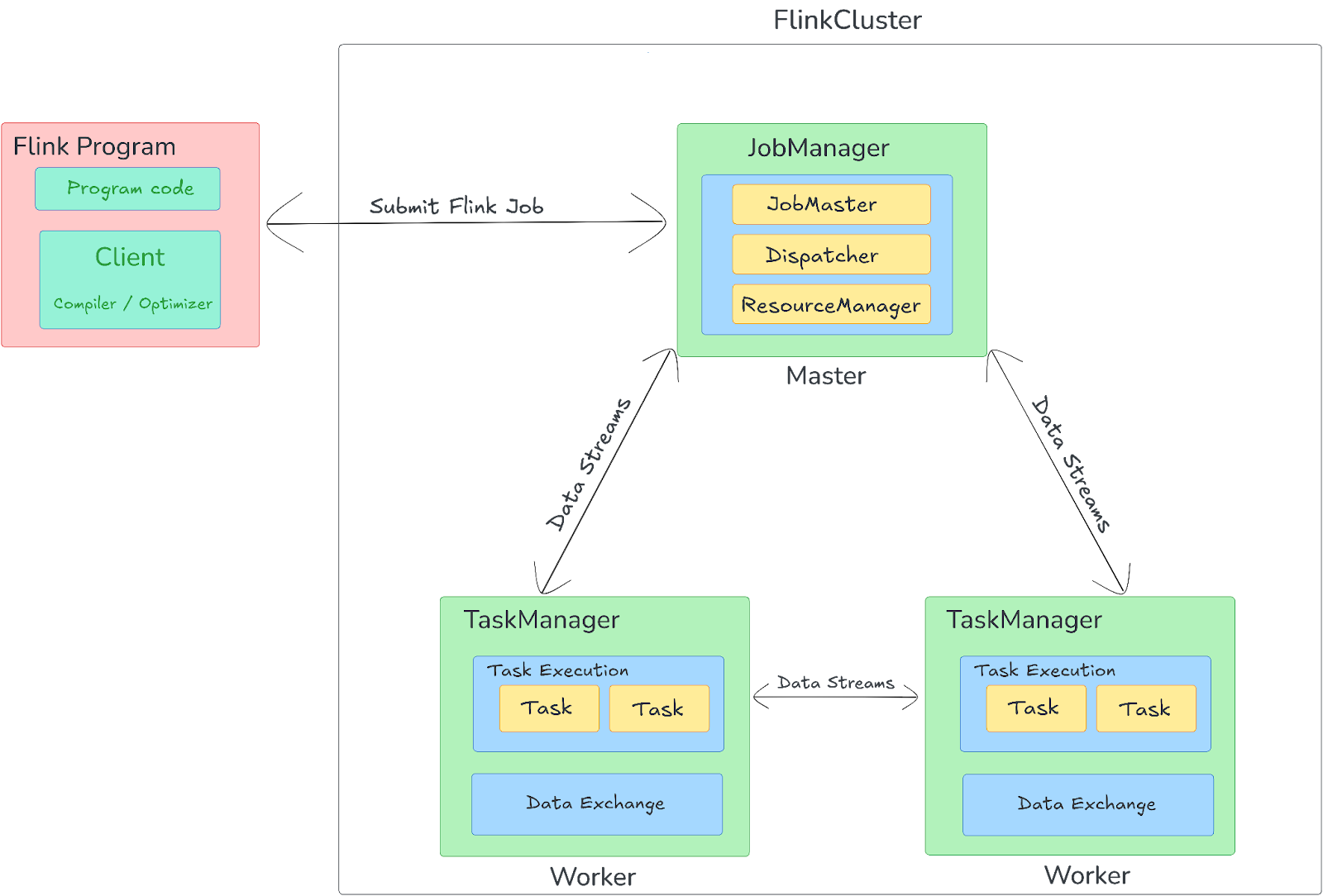
Apache Flink is designed around a master-worker architecture that efficiently handles data processing tasks in a distributed environment. The key components of Flink's architecture include the Client, JobManager, and TaskManagers.
1) Client
Client is responsible for submitting Flink jobs. It first compiles user code and constructs a JobGraph—a logical representation of the computation. The Client then submits this graph to the JobManager. There are two operational modes for the Client:
- Attached Mode: Remains connected to receive progress updates.
- Detached Mode: Disconnects after job submission.
2) JobManager
JobManager coordinates and controls job execution in the Flink cluster. It manages various responsibilities such as task scheduling, checkpointing, failure recovery, and overall resource management. The JobManager is composed of multiple subcomponents:
- ResourceManager: Allocates and manages resources (like CPU and memory) in the cluster by assigning Task Slots (units of work allocation) to the tasks.
- Dispatcher: Provides a REST API for job submission and launches a JobMaster for each job.
- JobMaster: Each job is assigned a dedicated JobMaster, which manages the execution of the JobGraph and makes sure that tasks are correctly distributed and executed on the TaskManagers. The JobMaster handles the scheduling, fault tolerance, and state management for its associated job.
3) TaskManagers
TaskManagers are the worker nodes in the Flink cluster, responsible for executing tasks assigned by the JobManager. Each TaskManager contains multiple Task Slots, which are the execution units where tasks run. These slots provide resource isolation, and the number of slots in a TaskManager defines how many parallel tasks it can handle. TaskManagers facilitate the execution of distributed tasks, handle intermediate data shuffling, and manage the local task state.
Apache Spark Architecture:
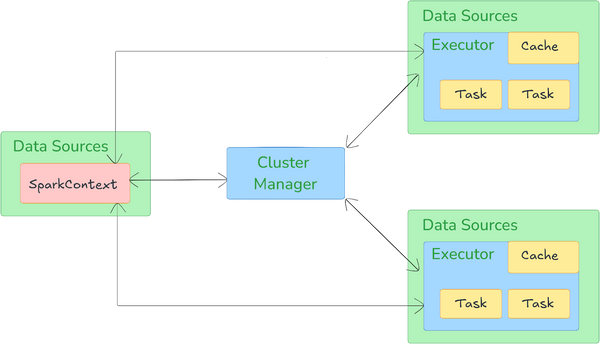
Apache Spark architecture also operates on a master-worker model and is built around several key components and abstractions that enable high-speed data processing, fault tolerance, and real-time analytics.
Apache Spark architecture relies on two main abstractions:
Key Components of Apache Spark Architecture:
Driver is the master node of a Spark application, orchestrating the execution of a Spark program. It converts user code into a Directed Acyclic Graph (Spark DAG) of stages and tasks, which are then distributed across the cluster. It manages the execution of tasks by negotiating resources with the Cluster Manager and schedules tasks to be run by the Executors.
2) Executors
Executors are distributed agents that run on worker nodes in the cluster. They are responsible for executing tasks assigned by the Driver. Each Executor performs data processing tasks and stores the computation results in memory (for fast access) or on disk. Executors are also responsible for interacting with the underlying storage systems and reporting back the results to the Driver.
Cluster Manager is an external service that manages the resources for Apache Spark cluster. It allocates resources like CPU and memory to Spark applications and assigns them to the Executors.
Apache Spark can work with various cluster managers, which include Apache Hadoop YARN, Apache Mesos, Kubernetes, or its standalone cluster manager. The choice of cluster manager depends on the specific requirements and environment of the Spark application.
Check out this article on how Apache Spark works to learn more in-depth about Apache Spark architecture.
2). Apache Spark vs Flink — Data Processing Models
Apache Spark vs Flink are two prominent frameworks for big data processing, each with distinct data processing models tailored to different use cases. Here's a brief overview of the data processing models used by each framework:
Apache Spark's Data Processing Model
Apache Spark's data processing model is based on the Resilient Distributed Dataset (RDD) concept. RDDs are immutable, partitioned collections of data that can be split across multiple nodes in a cluster.
Apache Spark's data processing model involves the following key components:
1) Resilient Distributed Dataset (RDDs)
RDDs are the fundamental data structure in Spark. They are created by loading data from various sources, such as HDFS, HBase, or Cassandra.
2) Transformations
Transformations are operations that create a new dataset from an existing one. They are lazy operations, meaning they do not compute their results immediately but instead build a lineage of transformations. This lineage is used to optimize data processing, reducing data shuffling across the network. Common transformations include map(), filter(), and reduceByKey().
3) Actions
Actions trigger the execution of the transformations defined on RDDs. When an action such as collect(), count(), or saveAsTextFile() is invoked, Spark computes the result by executing the transformations in the lineage.
4) DAG (Directed Acyclic Graph) Scheduler
Spark's DAG scheduler is responsible for scheduling the execution of transformations and actions. It constructs a DAG of tasks that need to be executed and schedules them across the cluster.
5) Executor
Executors are the processes that run on each node in the cluster, executing the tasks assigned by the DAG scheduler.
Apache Spark's data processing model is designed for batch processing, but it also supports real-time processing through its micro-batch model.
Apache Flink's Data Processing Model
Apache Flink's data processing model is based on streams and transformations. A stream represents a flow of data records, which can be unbounded (continuous) or bounded (finite). Transformations in Flink take one or more streams as input and produce one or more output streams.
Apache Flink programs consist of streams and transformations, which can be arranged as a directed, acyclic data flow graph, allowing an application to branch and merge dataflows. Flink executes these dataflow programs in a data-parallel and pipelined manner.
Flink provides two core APIs: the DataStream API for bounded or unbounded streams of data and the DataSet API for bounded data sets. It also offers a Table API, which is a SQL-like expression language for relational stream and batch processing that can be easily embedded in Flink's DataStream and DataSet APIs.
Flink's runtime system enables the execution of both batch and stream processing programs. It supports event-time processing, allowing applications to handle out-of-order events and late arrivals, and provides state management capabilities for maintaining application state across the processing of multiple events.
🔮 So, which one should you opt for—Apache Spark vs Flink? If you need to process data in real-time with low latency, Apache Flink is the way to go. It does true streaming and is super fast. But if you're dealing with batch processing or micro-batch stream processing, Apache Spark is a great pick. It's fast and easy to use.
3). Apache Spark vs Flink — Performance and Scalability
Performance Benchmarks:
Both Apache Flink and Apache Spark are known for their high performance, but they excel in different areas.
1) Execution Speed
- Apache Flink is primarily designed for real-time stream processing, achieving low-latency and high-throughput performance. This makes Flink particularly effective in scenarios requiring immediate data processing, often outperforming Spark in stateful computations and complex event processing.
- Apache Spark, originally developed for batch processing, has adopted a micro-batching approach for streaming data. This can result in higher latencies compared to Flink's true stream processing model. But Spark has made significant advancements in its streaming capabilities, especially with the introduction of Structured Streaming(spark streaming), which enhances its ability to handle continuous data streams.
2) Task Performance
In benchmarks comparing specific tasks, Apache Flink tends to outperform Apache Spark in real-time processing applications due to its efficient handling of stateful computations and backpressure management. For batch processing tasks, Apache Spark can be competitive, particularly with its in-memory computing capabilities that accelerate data processing. But Apache Flink's architecture allows it to maintain performance even under high load conditions, making it the preferred choice for applications that require consistent low-latency processing.
Scalability:
Apache Spark and Apache Flink, both of them are designed to scale horizontally across distributed environments. They can dynamically allocate and deallocate resources based on workload requirements, allowing them to efficiently handle large-scale data processing tasks.
1) Apache Spark
Apache Spark operates on a bulk synchronous processing model, processing data in parallel across partitions. While this allows Spark to scale out by adding more nodes, it requires all tasks in a stage to complete before proceeding to the next stage. This can lead to bottlenecks in scenarios with complex data dependencies or when scaling down, as it may need to redistribute data among fewer nodes.
2) Apache Flink
Apache Flink uses a dataflow model that allows for more flexible scaling. It can adjust to varying workloads dynamically without requiring all tasks to complete simultaneously. This flexibility, combined with its efficient backpressure management, enables Flink to maintain consistent performance even as the system scales up or down.
4). Apache Spark vs Flink — Fault Tolerance
Apache Spark vs Flink both provide robust fault tolerance mechanisms designed to ensure system resilience and continuity in data processing.But they implement these mechanisms in distinct ways that reflect their respective design philosophies and use cases.
Apache Spark's Fault Tolerance Mechanisms
1) Resilient Distributed Datasets (RDDs)
RDDs are Spark's core abstraction, inherently designed for fault tolerance. They are immutable, partitioned collections of data that can be recomputed in case of node failure by tracing the lineage of transformations from the original data source. This recomputation is possible due to the deterministic nature of RDDs.
2) Lineage
Apache Spark maintains a lineage graph, recording all transformations applied to RDDs, which allows for efficient fault recovery by simply re-executing the necessary transformations, rather than requiring frequent state persistence, which can introduce additional overhead.
3) Checkpointing
Although Spark can rely on lineage for fault recovery, checkpointing offers a more efficient method for recovering from failures in long-running applications. By persisting RDDs to a reliable storage system (like HDFS), Spark reduces the overhead associated with recomputation. This is especially useful in streaming applications, where lineage chains can become lengthy.
4) Driver and Executor Fault Tolerance
In case of a driver failure, Spark can restart the driver and recreate the SparkContext, the entry point to Spark's APIs. Similarly, if an executor—responsible for running tasks—fails, Spark's cluster manager can reassign tasks to other available executors, ensuring continuity in processing.
Apache Flink's Fault Tolerance Mechanisms
1) Checkpointing
Apache Flink’s fault tolerance is heavily based on its distributed snapshot mechanism, where the state of all operators in the dataflow is periodically captured and stored in a reliable storage system. These snapshots, or checkpoints, allow Flink to resume processing from the last known good state with minimal disruption.
2) Savepoints
Savepoints are manually triggered checkpoints that capture the state of Apache Flink application at a specific point in time. They are primarily used for planned restarts, upgrades, or migrations, ensuring that the application can continue seamlessly from the exact point it was paused.
3) Barrier Alignment
Apache Flink introduces the concept of barriers to make sure consistency across distributed operators. Barriers flow with the data stream, ensuring that all operators align on the same checkpoint, preserving the exact state at a particular point in processing.
4) Asynchronous Snapshots
Apache Flink’s ability to take asynchronous snapshots allows it to capture the state without stopping the data flow, thus maintaining high throughput and low latency. This is critical for real-time processing applications where even minor pauses can be detrimental.
5) Task Failure Handling
Apache Flink provides a task failure handling mechanism that allows the system to recover from task failures. If a task fails, Flink can restart the task and re-execute it.
🔮 So, which one has the best fault tolerance mechanism—Apache Spark vs Flink? Both of them provide robust fault tolerance mechanisms to make sure that the system can recover from failures and continue processing data without significant interruptions.
🔮 Apache Spark's checkpointing mechanism is more granular than Flink's. Spark checkpoints are typically taken at the RDD level, while Flink checkpoints are taken at the operator level.
🔮 Apache Spark's lineage graph is used to recompute lost data, while Flink uses a more explicit checkpointing mechanism to recover the application state.
🔮 Apache Spark provides a more comprehensive driver fault tolerance mechanism than Flink.
5). Apache Spark vs Flink — APIs and Language Support
Apache Spark:
Apache Spark provides a unified API for batch and real-time data processing. The primary APIs for Spark are:
1) RDD (Resilient Distributed Dataset) API
The core API for Spark, which represents a collection of data that can be split across multiple nodes in the cluster.
Introduced in Spark 1.3, the DataFrame API provides a higher-level abstraction for working with structured data. DataFrames are similar to tables in a relational database and provide a more convenient API for data manipulation.
3) Dataset API
Dataset API, available from Spark 1.6, offers a type-safe, object-oriented interface for working with structured data. It unifies the advantages of RDDs and DataFrames, providing compile-time type safety while optimizing the execution.
Apache Spark supports multiple programming languages:
Apache Flink
Apache Flink provides a comprehensive set of APIs for building real-time data processing applications. The primary APIs for Apache Flink are:
1) DataStream API (real-time processing)
It is the core API for processing unbounded and bounded data streams. It allows for complex event processing, windowing, and stateful computations.
2) DataSet API (batch processing)
It is designed for batch processing and provides operations for bounded data sets, including transformations and aggregations.
3) Table API (structured data)
A declarative API that allows users to define data processing logic using SQL-like syntax. It can be used for both batch and stream processing.
Apache Flink supports multiple programming languages:
Apache Flink's support for Python is less mature compared to Spark, which may limit its appeal to Python-centric data science teams.
🔮 TL;DR: Both Apache Spark and Apache Flink provide powerful APIs for data processing, with Spark offering more language support and a larger ecosystem, while Apache Flink excels in real-time stream processing and state management.
6). Apache Spark vs Flink — Optimization Techniques
Apache Spark Optimization:
1) Catalyst Optimizer
Apache Spark utilizes the Catalyst optimizer, which applies a series of transformations to the logical query plan to produce an optimized physical plan. It includes:
- Predicate Pushdown: Filters are pushed down to the data source level to minimize the amount of data read.
- Constant Folding: Constant expressions are evaluated at compile time, reducing runtime computation.
- Projection Pruning: Only the required columns are read, which decreases I/O operations.
- Join Optimization: The optimizer selects the most efficient join strategy (e.g., broadcast join or sort-merge join) based on dataset sizes.
2) Tungsten Execution Engine
Tungsten is an execution engine that optimizes memory usage and CPU efficiency:
- Whole-Stage Code Generation: Generates optimized bytecode for query execution, reducing the overhead of virtual function calls.
- Off-Heap Memory Management: Uses off-heap memory for data storage, which reduces garbage collection overhead and improves performance.
3) Data Locality
Apache Spark attempts to schedule tasks on nodes where the data resides (data locality), minimizing data transfer across the network.
4) Caching:
Apache Spark supports caching of intermediate results in memory, significantly speeding up iterative algorithms and interactive queries. Users can select from various storage levels (e.g., MEMORY_ONLY, MEMORY_AND_DISK) based on their requirements.
5) Adaptive Query Execution (AQE):
AQE was introduced in Spark 3.0, AQE dynamically adjusts query plans based on runtime statistics, allowing for optimizations such as changing join strategies and optimizing partition sizes according to actual data characteristics.
6) Partitioning and Bucketing:
Apache Spark supports partitioning and bucketing of data to optimize query performance. Proper partitioning can reduce the amount of data shuffled across the network during operations like joins and aggregations.
Apache Flink Optimization:
1) Cost-Based Optimization (CBO)
Apache Flink utilizes a cost-based optimizer that estimates the cost of different execution plans based on statistics about the data, allowing Flink to choose the most efficient plan for executing queries.
2) Streaming and Batch Processing
Apache Flink is designed for both stream and batch processing. It optimizes for low-latency processing in streaming applications while also applying batch optimizations when processing bounded datasets.
3) State Management
Apache Flink offers advanced state management for streaming applications, utilizing snapshots and incremental checkpoints to maintain state consistency and optimize recovery times.
4) Event Time Processing
Apache Flink supports event time processing, allowing it to handle out-of-order events efficiently.
5) Operator Fusion
Apache Flink can fuse multiple operators into a single task to reduce the overhead of task scheduling and improve data locality.
6) Backpressure Handling
Apache Flink has a built-in backpressure mechanism that dynamically adjusts the data flow between operators based on their processing rates, which guarantees system stability under varying loads.
7) Dynamic Scaling
Apache Flink supports dynamic scaling of resources, allowing it to adjust the number of task slots according to workload demands.
8) Data Serialization
Apache Flink utilizes efficient serialization frameworks to minimize the overhead of data transfer between nodes, enhancing performance.
🔮 So, who is the winner—Apache Spark vs Flink? Welp, the choice between Apache Spark and Apache Flink largely depends on the specific use case. Spark focuses heavily on optimizing batch processing with its Catalyst optimizer and Tungsten execution engine, while Apache Flink emphasizes real-time stream processing with its cost-based optimization and advanced state management capabilities, making it ideal for applications requiring low-latency data handling.
7). Apache Spark vs Flink — Ecosystem and Community Support
Apache Spark Ecosystem and Community Support
Apache Spark has a vast and mature ecosystem, with a large community of contributors, users, and vendors.
Apache Spark community is one of the largest and most active in the big data space, with over 2100+ contributors and more than 42000+ commits on GitHub. The community is supported by the Apache Software Foundation (ASF), which provides a governance structure, infrastructure, and resources.
Apache Spark also has a wide range of extensions and libraries that provide additional functionality, such as:
- Spark SQL & DataFrames: a SQL interface for Spark
- Spark Streaming: a module for real-time data processing
- MLlib: a machine learning library
- GraphX: a graph processing library
- SparkR: an R interface for Spark
Popular libraries with PySpark integrations
On top of that, Apache Spark also provides ranges of connectors:
- spark-redshift
- spark-sql-connector
- azure-cosmos-spark
- azure-event-hubs-spark
- azure-kusto-spark
- mongo-spark
- couchbase-spark-connector
- spark-cassandra-connector
- elasticsearch-hadoop
- neo4j-spark-connector
- starrocks-connector-for-apache-spark
- tispark
Supported Open table formats
Infrastructure projects
- Kyuubi
- REST Job Server for Apache Spark
- Apache Mesos
- Alluxio (née Tachyon)
- FiloDB
- Zeppelin
- K8S Operator for Apache Spark
- IBM Spectrum Conductor
- MLflow
- Apache DataFu
New libraries and connectors are continuously added, so for the latest updates, refer to the official Apache Spark documentation
Many vendors, including Databricks, Cloudera, and IBM, offer commercial support, training, and services for Apache Spark.
Apache Flink Ecosystem and Community Support
Apache Flink also has a growing ecosystem and community.
Apache Flink community is smaller compared to Spark, but still active and growing, with over 1200+ contributors and more than 35000+ commits on GitHub.
Apache Flink also has a range of extensions and libraries:
- Flink Table API: a SQL-like API for Flink
- Flink ML: a machine learning library
- Flink Stateful Functions: a library for building stateful applications
- Flink Kafka Connector: a connector for Apache Kafka
DataStream Connectors
Flink also provides range of connectors:
- Apache Cassandra
- Amazon DynamoDB
- Amazon Kinesis Data Streams
- Amazon Kinesis Data Firehose
- DataGen
- Elasticsearch
- Opensearch
- FileSystem
- RabbitMQ
- Google PubSub
- Hybrid Source
- Apache Pulsar
- JDBC
- MongoDB
Also streaming connectors for Flink are being released through Apache Bahir:
Table & SQL Connectors
Flink’s Table API & SQL programs can be connected to other external systems for reading and writing both batch and streaming tables. Flink natively support various connectors. Here is the list all available connectors.
- Filesystem
- Elasticsearch
- Opensearch
- Apache Kafka
- Amazon DynamoDB
- Amazon Kinesis Data Streams
- Amazon Kinesis Data Firehose
- JDBC
- Apache HBase
- Apache Hive
- MongoDB
🔮 So, who is the winner—Apache Spark vs Flink? Apache Spark is the clear winner in this one because it is more mature, widely adopted, and has a larger community and more extensive ecosystem.
8). Apache Spark vs Flink — Use Cases
When to Use Apache Spark
Apache Spark is a versatile framework suitable for various data processing scenarios, particularly perfect in the following use cases:
1) Batch Processing of Large Datasets
Apache Spark is highly optimized for processing large, bounded datasets in batch mode. It is ideal for retrospective analysis, data warehousing, and ETL (Extract, Transform, Load) pipelines due to its efficient in-memory processing capabilities.
2) Micro-Batch Streaming Analytics
Apache Spark Streaming is not as low-latency as Flink, but it is still effective for processing data streams in micro-batches. It is suitable for applications like log analysis, monitoring, and scenarios where slight delays are acceptable.
3) Machine Learning and Advanced Analytics
Apache Spark's MLlib library supports a broad range of machine learning algorithms, making it a popular choice for building predictive models and conducting advanced analytics. Its ability to handle large datasets efficiently enhances its appeal in data science applications.
4) Interactive Queries and Data Exploration
Apache Spark's interactive shell and support for SQL queries allow for rapid data exploration and ad-hoc analysis, making it useful for data science and BI applications.
5) Ease of Use and Familiarity
Apache Spark's high-level APIs and support for multiple programming languages (Scala, Java, Python, R) make it accessible to a wide range of developers, especially those familiar with Python and SQL.
6) Easy Integration with the Hadoop Ecosystem
Apache Spark integrates well with the Hadoop ecosystem, allowing it to process data from various sources like HDFS, HBase, and Cassandra, making it a good fit for existing Hadoop-based infrastructures.
When to Use Apache Flink
Apache Flink, on the other hand, is primarily focused on real-time data processing and excels in the following use cases:
1) Real-Time Stream Processing
Apache Flink is designed for low-latency processing of continuous data streams. It can process data as it arrives, enabling real-time analytics, fraud detection, and monitoring applications.
2) Event-Time Processing and Late Data Handling
Apache Flink's advanced windowing capabilities allow it to handle out-of-order events and late-arriving data, making it suitable for applications that require precise time semantics, such as financial transactions and event-driven systems.
3) Stateful Stream Processing
Apache Flink provides efficient state management, allowing you to maintain and update state in real time, which is crucial for applications like user activity tracking, session management, and complex event processing.
4) Batch Processing
Apache Flink was initially designed for streaming, but it also supports batch processing, making it a good choice for applications that require both real-time and batch processing.
🔮 Choose Apache Flink for real-time, low-latency stream processing, complex event processing, and scenarios where event time handling is critical.
🔮 Choose Apache Spark for batch processing, machine learning, interactive data analysis, and scenarios where the workload can tolerate higher latency.
Apache Spark vs Flink — Pros & Cons
Apache Spark Pros and Cons
Pros:
- Apache Spark is renowned for its speed, often processing data up to 100 times faster than traditional MapReduce frameworks. This is primarily due to its in-memory computation capabilities, which reduce the need for disk I/O operations.
- Apache Spark has a large and established community, offering a wide range of libraries and tools for diverse use cases, from data processing to machine learning.
- Apache Spark supports multiple programming languages, including Scala, Java, Python, and R.
- Apache Spark can handle various workloads—batch processing, streaming, machine learning, and graph processing—within a single framework.
- Apache Spark comes with robust libraries like Spark SQL for querying, MLlib for machine learning, GraphX for graph processing, and Spark Streaming for near-real-time data processing.
- Apache Spark’s architecture includes resilient distributed datasets (RDDs) that provide fault tolerance through lineage graphs, allowing it to recover lost data by recomputing it from the original source.
Cons:
- Apache Spark’s reliance on in-memory processing can lead to high memory consumption, potentially requiring expensive hardware with large memory capacities.
- Achieving optimal performance in Spark often requires careful tuning of various parameters, such as memory allocation, executor configurations, and parallelism, which can be complex.
- Apache Spark's basic API is easy to use, but its advanced features, such as RDDs (Resilient Distributed Datasets) and DataFrames, require a deeper understanding of the underlying architecture.
- Apache Spark Streaming provides near-real-time processing capabilities; it operates on a micro-batch model rather than true real-time processing.
- Apache Spark can face backward compatibility issues, complicating upgrades and integration with existing systems.
Apache Flink Pros and Cons
Pros:
- Apache Flink is designed for true stream processing, allowing it to handle data in real-time with low latency. Unlike Spark's micro-batching approach, Flink processes events as they arrive.
- Apache Flink excels in event-time processing, handling late-arriving data and out-of-order events more effectively than Spark, which is crucial for real-time analytics applications that require precise time-based operations.
- Apache Flink provides robust state management and fault tolerance through its distributed, consistent checkpointing mechanism, which is highly efficient for long-running streaming jobs.
- Apache Flink can be deployed in various environments, including cloud, on-premises, and hybrid setups, offering flexibility to adapt to different infrastructure needs.
- Apache Flink offers a rich set of APIs for batch and stream processing.
Cons:
- Apache Flink can be complex to set up and manage, particularly for teams not familiar with stream processing paradigms and concepts.
- Flink's ecosystem, while growing, is not as extensive or mature as Apache Spark’s. This can limit the availability of third-party tools, libraries, and community support.
- In scenarios where batch processing is more efficient, Spark may outperform Flink due to Spark's optimizations for batch workloads. Flink is primarily optimized for streaming but can handle batch processing, though with potentially less efficiency.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Conclusion
And that's a wrap! So, which one should you choose between Apache Spark and Flink? Welp, it all comes down to your data processing needs. If you need real-time analytics or complex event processing, Apache Flink is your best bet. On the other hand, Apache Spark is perfect for batch processing and machine learning. Both have their pros and cons, so it's essential to understand these differences before making a call.
In this article, we have covered:
- What is Apache Flink?
- What is Apache Spark?
- Difference between Apache Flink and Apache Spark
- Apache Spark vs Flink — Architecture Showdown
- Apache Spark vs Flink — Data Processing Models
- Apache Spark vs Flink — Performance and Scalability
- Apache Spark vs Flink — APIs and Language Support
- Apache Spark vs Flink — Optimization Techniques
- Apache Spark vs Flink — Ecosystem and Community Support
- Apache Spark vs Flink — Use Cases
- Apache Spark vs. Apache Flink — Pros and Cons
… and much more!
FAQs
What is Apache Spark used for?
Apache Spark is used for batch processing, interactive queries, real-time analytics, machine learning, and graph processing. Its versatility enables it to handle a variety of data processing tasks across different domains, such as finance, healthcare, and eCommerce.
Who created Apache Spark?
Apache Spark was created by the AMPLab at the University of California, Berkeley, and was later donated to the Apache Software Foundation.
What is Apache Flink used for?
Apache Flink is used for real-time analytics, event-driven applications, and stateful computations. It excels in handling unbounded and bounded data streams with low latency and high throughput.
What is Apache Flink vs Kafka?
Apache Flink and Kafka are complementary technologies. Kafka is a messaging system designed for high-throughput and provides low-latency, fault-tolerant, and scalable data processing. Flink can integrate with Kafka to process the data streams it provides, offering advanced analytics and processing capabilities.
What is Flink best used for?
Flink is best used for real-time analytics, event-driven applications, and stateful computations where low latency and high throughput are critical.
Is Flink better than Kafka?
Flink and Kafka serve different purposes. Kafka is a messaging system, while Flink is a processing engine. Flink can process data from Kafka, but it is not a replacement for Kafka.
Is Flink better than Spark?
Flink is better than Spark for real-time analytics and stateful computations due to its true streaming capabilities and low latency. However, Spark excels in batch processing and has a more mature ecosystem.
Is Apache Flink still relevant?
Yes, Apache Flink is still highly relevant, especially in scenarios requiring real-time analytics and low-latency processing. Its advanced features and capabilities make it a preferred choice for many organizations.
Is Apache Flink an ETL tool?
Apache Flink is not primarily an ETL (Extract, Transform, Load) tool but can be used for ETL tasks. Its main focus is on real-time analytics and stateful computations, making it more versatile than traditional ETL tools.















