





























Processing data at scale is no longer a luxury—it’s a necessity. Organizations today face the challenge of managing and analyzing massive volumes of data, and they need powerful, efficient tools to meet these demands. That's where Amazon Elastic MapReduce(EMR) comes in. EMR is a flexible cloud platform that's really good at handling big data and analytics. It started out as a way to make Hadoop easier to use on the cloud, but it currently supports a number of data processing frameworks, like Apache Spark, Apache Flink, Apache HBase, and Presto. Of these, Apache Spark is especially useful for fast and flexible data processing. Spark's in-memory computing means it can handle both batch and real-time workloads, making it a perfect choice than traditional systems like Hadoop MapReduce. Running Apache Spark on EMR provides several significant advantages over on-premise deployments or platforms such as Databricks. For one thing, it integrates smoothly with plethora of AWS services, which makes it easier for organizations to scale and reduces operational complexity.
In this article, we provide an in-depth overview of AWS EMR and its integration with Apache Spark, covering its architecture, step-by-step configuration for setting up Spark on EMR, optimization techniques for performance tuning, and common use cases to help you leverage Apache Spark on EMR effectively.
What is AWS EMR?
AWS Elastic MapReduce (EMR) is Amazon's fully managed big data platform that's all about processing and analyzing huge datasets. It makes setting up and running clusters of computing resources a lot easier, and lets you do distributed data processing on a large scale. AWS EMR was first designed to make Hadoop easier to use in the cloud, but now it supports a bunch of other data processing frameworks too, like Apache Spark, Apache Flink, Apache HBase, and Presto.
AWS EMR (Elastic MapReduce) is versatile and supports a wide range of use cases, including:
3) Real-Time Analytics and Stream Processing
6) Data Warehousing and Log Analysis
For more, see What Is AWS EMR Used For.
Save up to 50% on your Databricks spend in a few minutes!


Features of AWS EMR
AWS EMR offers a comprehensive suite of features. Here are some key features of AWS EMR:
1) Elastic Scalability
- Dynamic Scaling: AWS EMR can scale clusters dynamically using Amazon EC2 instances or Kubernetes-based containers via Amazon EKS.
- Auto Scaling and Spot Instances: Auto Scaling adjusts cluster size based on pre-configured metrics, while Spot Instances allow cost-effective resource utilization by leveraging unused EC2 capacity.
- Serverless Model: EMR Serverless eliminates the need to manage clusters, automatically provisioning and scaling resources as needed.
2) Data Access Control and Security
AWS EMR integrates with AWS IAM for fine-grained data access control, allowing precise user permissions on clusters, jobs, and AWS S3 data. EMR also supports encryption at rest and in transit. At rest, it uses S3-managed or KMS-managed keys; in transit, TLS encrypts data movement. Additionally, users can deploy EMR clusters within a Virtual Private Cloud (VPC) for network isolation, enhancing security for sensitive data.
3) Broad Support for Data Processing Frameworks
AWS EMR supports numerous open source data processing engines:
- Apache Spark: For in-memory processing and stream processing
- Apache Hadoop: For distributed storage (HDFS) and processing (MapReduce)
- Apache Hive: For SQL-like queries on large datasets
- Apache HBase: For NoSQL workloads
- Apache Flink: For stream processing
- Presto: For interactive querying
4) Flexible Data Store Integration
AWS EMR natively supports data storage options like:
- Amazon S3 (EMRFS): For scalable, cost-effective object storage.
- HDFS: For distributed storage within the cluster.
- Amazon DynamoDB: For fast, NoSQL database storage and integration.
EMRFS provides S3-specific features like consistent data views, which help with data consistency checks, ensuring reliable access across storage locations.
5) Integration with AWS Services
AWS EMR integrates seamlessly with:
- Amazon S3: For scalable, cost-effective data storage.
- Amazon CloudWatch: For monitoring metrics, logs, and alerting.
- AWS Glue: Streamlines ETL workflows and schema management.
- Athena and QuickSight: Enable querying and visualization of processed datasets.
- Step Functions: Facilitates orchestration of data workflows.
6) Real-Time Data Processing
- Stream Processing: EMR supports tools like Kafka and Flink for real-time analytics.
- Batch Workloads: Hadoop and Spark enable efficient handling of large-scale batch jobs.
7) Cluster Resource Management with YARN
AWS EMR uses YARN (Yet Another Resource Negotiator) to handle resource allocation across applications within the cluster. YARN’s dynamic resource management optimizes performance by adjusting allocations based on the workload, ensuring efficient use of computing resources.
8) Robust Data Security
In addition to IAM integration, AWS EMR offers extensive security configurations:
- Encryption in transit and at rest.
- Compliance with standards like HIPAA, PCI DSS, and SOC 2.
- Provides secure internal and external communication within clusters.
- VPC deployment for additional network control.
- CloudTrail logs provide visibility into user activity and cluster operations.
9) Interactive Development Environments
AWS EMR Notebooks (Jupyter-based) and EMR Studio provide interactive, collaborative environments for data exploration, visualization, and code execution on EMR clusters.
10) Extended Release Support
AWS EMR now offers 24-month support for major versions, ensuring stability, regular patches, and updates to prevent disruptions
AWS EMR Architecture Overview
The architecture of AWS EMR is built around many essential layers, allowing users to manage a wide range of large-scale data processing tasks such as batch processing, real-time analytics, and machine learning.
Cluster Composition in AWS EMR
Clusters in AWS EMR are groups of Amazon EC2 (Elastic Compute Cloud) instances called nodes, organized into roles to facilitate distributed data processing:
- Primary Node — Manages cluster operations, including job distribution and monitoring. The cluster always has one primary node responsible for overseeing task scheduling and data distribution.
- Core Nodes — Execute tasks and handle storage within the Hadoop Distributed File System (HDFS) or other file systems. They are essential for multi-node clusters.
- Task Nodes — Task-only nodes that handle processing without storing data. These nodes are often used in transient Spot Instances to optimize costs.
Storage Layer
AWS EMR supports multiple storage options based on data persistence and access requirements:
- HDFS: Used for distributed storage across cluster nodes, ideal for temporary data during processing tasks.
- EMR File System (EMRFS): Integrates Amazon S3 as a Hadoop-compatible file system, making S3 a highly scalable and persistent storage solution for both input/output data.
- Local Storage: Uses instance-attached storage, offering temporary, high-speed access during processing. This data, however, is deleted when an instance shuts down.
Data Processing Layer
At this layer, AWS EMR offers pre-configured, open source frameworks for parallel data processing:
AWS EMR integrates these frameworks with AWS data services (like S3, DynamoDB), enabling flexible and scalable analysis across diverse use cases.
Resource Management
AWS EMR leverages Apache YARN (Yet Another Resource Negotiator) for resource management. YARN facilitates resource allocation and job scheduling across nodes, with dynamic adjustments to manage instance terminations and Spot Instance volatility.
Applications and Programs Layer
Beyond core frameworks, AWS EMR allows custom configurations with additional applications like Apache HBase for NoSQL, and Apache Flink for real-time stream processing.
AWS EMR's architecture is designed to be flexible and modular, optimizing big data workloads on the AWS cloud with high scalability and efficient resource usage.
For more in-depth details, see AWS EMR architecture.
What is Apache Spark?
Apache Spark is a powerful open source engine optimized for large-scale data processing. Developed to improve the performance of Hadoop’s MapReduce, Spark executes tasks in memory, leading to significantly faster computation times. Spark supports various programming languages, including Python, Java, Scala, and R, making it accessible to data scientists, engineers, and developers alike.
Features of Apache Spark
1) In-Memory Computing
Apache Spark stores intermediate data in memory, making it way faster than traditional disk-based systems.
2) Unified Analytics
Apache Spark gives you one platform that covers batch processing, real-time streaming, machine learning, and interactive queries, cutting down the need for multiple tools.
3) Support for Multiple Languages
Apache Spark supports a bunch of programming languages—like Java, Scala, Python, and R.
4) Built-in Libraries
Apache Spark includes a wide range of built-in libraries that meet various data processing needs.
These libraries are deeply embedded in the Spark ecosystem, guaranteeing that they work together smoothly and efficiently.
5) Fault Tolerance
Apache Spark's secret to withstanding failures lies in its Resilient Distributed Datasets—or RDDs for short. RDDs are basically immutable collections of objects that can be distributed across a cluster. If a partition of an RDD is lost due to node failure, Spark can automatically recompute it using the lineage information stored for each RDD, guaranteeing that the system remains robust even in the face of hardware failures.
6) Lazy Evaluation
Apache Spark doesn't execute your commands immediately. What it does instead is create a plan, then waits until it absolutely needs to compute something.
7) Advanced DAG Execution Engine
Underneath it all, Spark relies on a Directed Acyclic Graph (DAG) to map out your data processing workflow. This helps it streamline complicated steps and operations.
Why Apache Spark for Data Processing?
Spark’s core strength lies in its ability to handle large datasets with speed and efficiency. Whether used for traditional ETL processes, real-time streaming, or building machine learning models, Spark’s architecture makes it highly efficient in distributed computing environments.
Check out this video if you want to learn more about Apache Spark in depth.
Apache Spark Architecture Overview
Spark's architecture is designed to efficiently handle big data processing in a distributed and fault-tolerant manner. It follows a layered structure that includes three core components: the driver, executors, and a cluster manager, each coordinating tasks to optimize processing.
Driver
Driver is responsible for coordinating the execution of tasks. It runs on a master node and creates a SparkContext object to manage Spark’s internal environment, including data management and scheduling. The driver submits tasks to the cluster and keeps track of their status, resource allocation, and results.
Executors
Executors are distributed across the cluster, performing actual data processing for tasks assigned by the driver. Each executor is responsible for:
- Running Tasks: Executors execute tasks in parallel, using the cluster's distributed resources.
- Caching/Storing Data: Leveraging in-memory storage for efficient retrieval and data locality.
- Sending Results: After processing, executors send results back to the driver.
Cluster Manager
Cluster manager allocates resources to the driver and executors, controlling access to the physical machines that run Spark processes. It facilitates communication between the driver and the worker nodes to keep tasks synchronized and manage resource distribution effectively. Spark supports several cluster managers:
- Standalone — Spark’s built-in cluster manager.
- YARN — The resource management layer for Hadoop.
- Apache Mesos — A general-purpose cluster manager.
- Kubernetes— For deploying Spark in containerized environments.
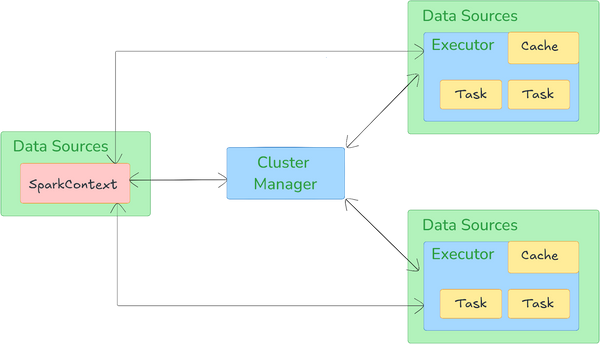
The execution flow of an Apache Spark application begins when a user submits an application, which launches the driver process. The driver, responsible for overseeing the application, communicates with the cluster manager to allocate the necessary resources and then transforms the user’s code into a series of jobs. Each job is further subdivided into stages, determined by Spark's Directed Acyclic Graph (DAG) scheduler. This logical DAG represents the sequence of operations, with each stage containing multiple tasks scheduled across executors based on data locality and available resources.
Tasks, the smallest unit of work in Spark, are distributed to executors on worker nodes where they process data. The task scheduler manages this distribution to ensure tasks are executed efficiently, minimizing data movement by prioritizing tasks close to where data is stored. As tasks complete, executors return intermediate results to the driver, which aggregates and finalizes the computation.
Throughout this process, Spark uses several optimizations such as lazy evaluation—delaying computations until necessary—enhance Spark's efficiency. Other key optimizations include data locality (to reduce network load), in-memory computing (to avoid disk I/O), and speculative execution (launching redundant tasks to counteract slow nodes). This distributed, optimized architecture enables Spark to handle large datasets with fault tolerance and high performance, maximizing throughput across nodes in the cluster.
For more in-depth details, see Apache Spark architecture.
Apache Spark on EMR—Architecture and Components
The architecture of Apache Spark on EMR (Elastic MapReduce) builds on EMR's managed ecosystem, offering efficient cluster management, flexible storage integration, and optimized Spark runtime. Below is a detailed overview of the architecture of Apache Spark on EMR, highlighting its key components and features.
Cluster Architecture
Apache Spark on EMR uses a cluster with a master node and multiple core and task nodes, all hosted on EC2 (Elastic Compute Cloud) instances:
- Master Node — Manages YARN (Yet Another Resource Negotiator) for resource allocation, handles job scheduling, and oversees HDFS NameNode functions when using HDFS.
- Core Nodes — Perform both data processing and storage. They handle HDFS or EMRFS storage and are vital for managing core data.
- Task Nodes — Provide extra, processing-only capacity without storage, allowing compute resources to scale flexibly without impacting the cluster’s storage layer.
Resource Management Layer
By default, AWS EMR leverages YARN (Yet Another Resource Negotiator) to allocate resources dynamically, ensuring tasks are efficiently distributed across nodes. EMR also supports advanced node labeling, assigning the "CORE" label to nodes that must maintain running jobs—a feature especially useful when using Spot Instances for cost savings since it ensures job continuity even if some Spot Instances are interrupted
Storage Layer
Spark on AWS EMR integrates deeply with Amazon S3 via EMRFS (EMR File System), allowing direct data access from S3 while leveraging HDFS on the core nodes for intermediate data during Spark jobs. This setup combines the scalability of S3 with the high-speed, temporary caching of HDFS for in-job processing. Additionally, local storage on EC2 instances (ephemeral storage) can be used for short-term caching, adding flexibility based on workload requirements.
Data Processing Framework Layer
Spark on EMR features AWS-optimized runtime configurations, offering up to 3x faster performance than standard Spark setups. These optimizations include pre-configured settings for enhanced parallelism, network communication, and resource allocation, particularly advantageous for iterative processing and real-time analytics, which improve job execution speeds and reduce costs.
Application Layer
AWS EMR offers compatibility with Spark’s data processing libraries—such as Spark SQL, MLlib, and Spark Streaming—allowing users to implement diverse analytics, from real-time data processing to machine learning. EMR also allows custom configurations tailored to specific processing frameworks and workload demands, crucial for optimizing large, complex tasks.
Apache Spark on EMR is designed for flexibility and cost-efficiency on AWS’s managed infrastructure. With support for streaming, machine learning, and SQL analytics, it’s a powerful choice for scalable data engineering workloads.
Now that you're familiar with Apache Spark, EMR, and the core architecture of Apache Spark on EMR, let's dive into the next section. Here, we'll walk through a step-by-step guide to getting Apache Spark up and running on EMR.
Step-by-Step Guide to Configure Apache Spark on EMR
Setting up Spark on AWS EMR involves several main steps that help your cluster run Spark workloads smoothly. This guide breaks it down into three main parts: setting up your AWS environment, launching an EMR cluster with Spark, and running Spark jobs.
Prerequisites:
Before getting started, make sure you've got everything you need in place. Have the following set up beforehand:
- AWS Account — A valid AWS account with billing setup.
- IAM Permissions — Sufficient IAM permissions to access EMR, S3, EC2 (Elastic Compute Cloud), and VPC.
- Basic Knowledge of Spark and AWS — Familiarity with Spark’s operation and AWS services such as S3 and VPC will be beneficial.
- Data Storage in S3 — Storing data in S3 is often necessary for input and output of Spark jobs on EMR.
- AWS CLI (Optional) — The AWS Command Line Interface (CLI) is useful for scripting and managing AWS services, though it’s optional.
Step 1—Log in to AWS Management Console
Go to the AWS Management Console and enter your credentials.
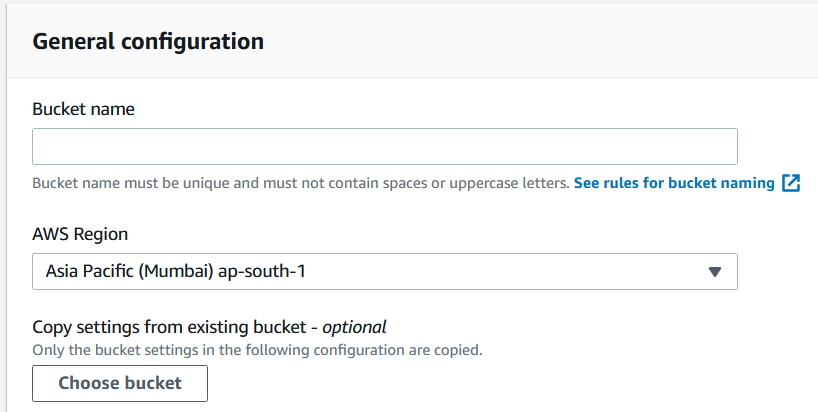
Step 2—Create an S3 Bucket
Amazon S3 is commonly used for data storage with EMR clusters. Set up an S3 bucket where you will store input data, Spark scripts, and log files:
In the AWS Console, navigate to S3 by searching for S3 in the search bar.
Click Create Bucket.
Provide a unique name for your bucket and select a region close to your EMR cluster for lower latency.
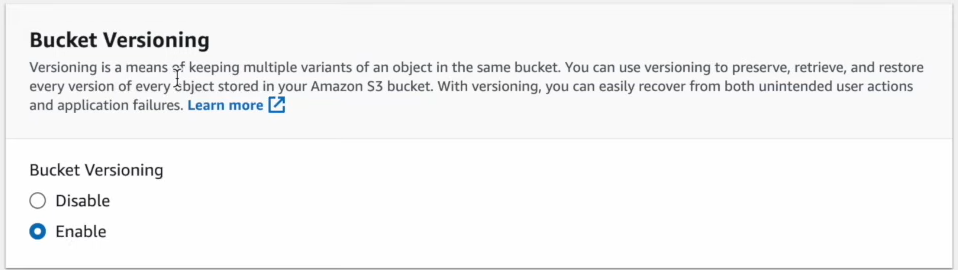
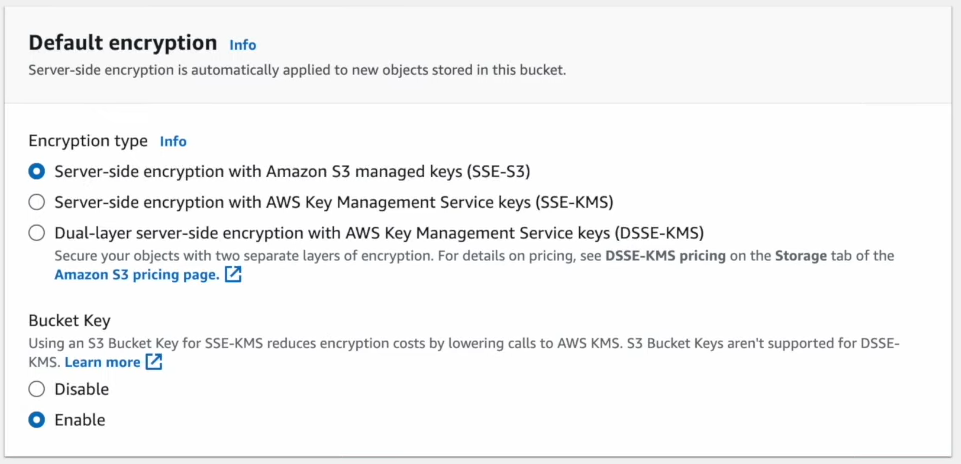
Configure Versioning and Server-Side Encryption as needed.
Create folders within the bucket for organizing data and logs (optional but recommended).
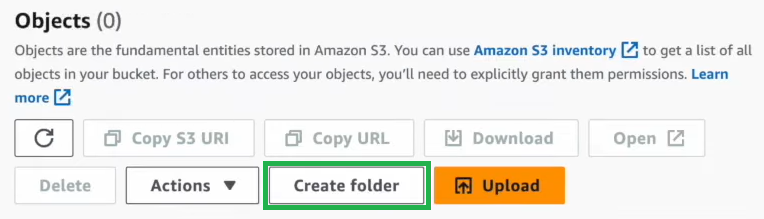
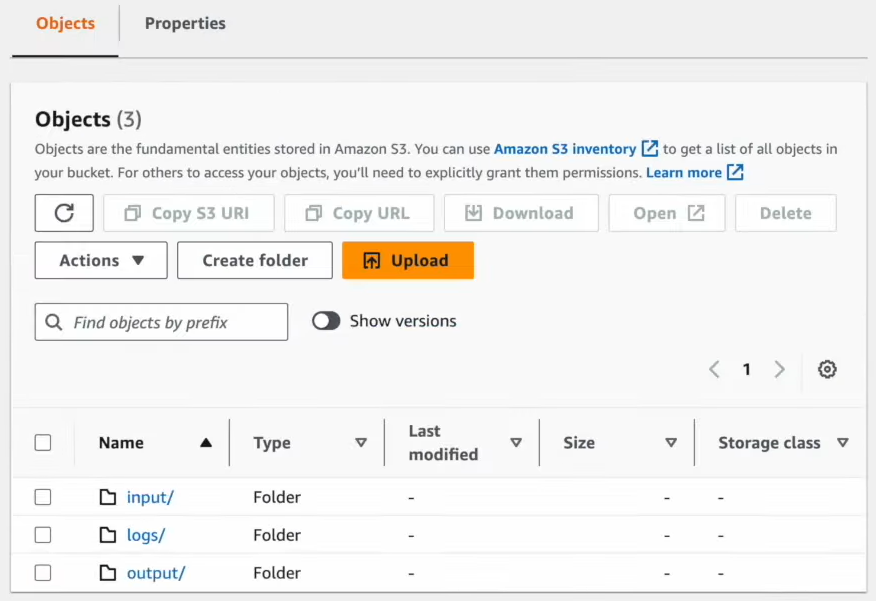
Create 3 different folders for organizing your data:
- input for data sources
- output for results
- logs for logging information
Step 3—Configure AWS VPC for Network Isolation
Configuring your VPC ensures network isolation and security for your EMR cluster.
Go to the VPC Dashboard in the AWS Management Console.
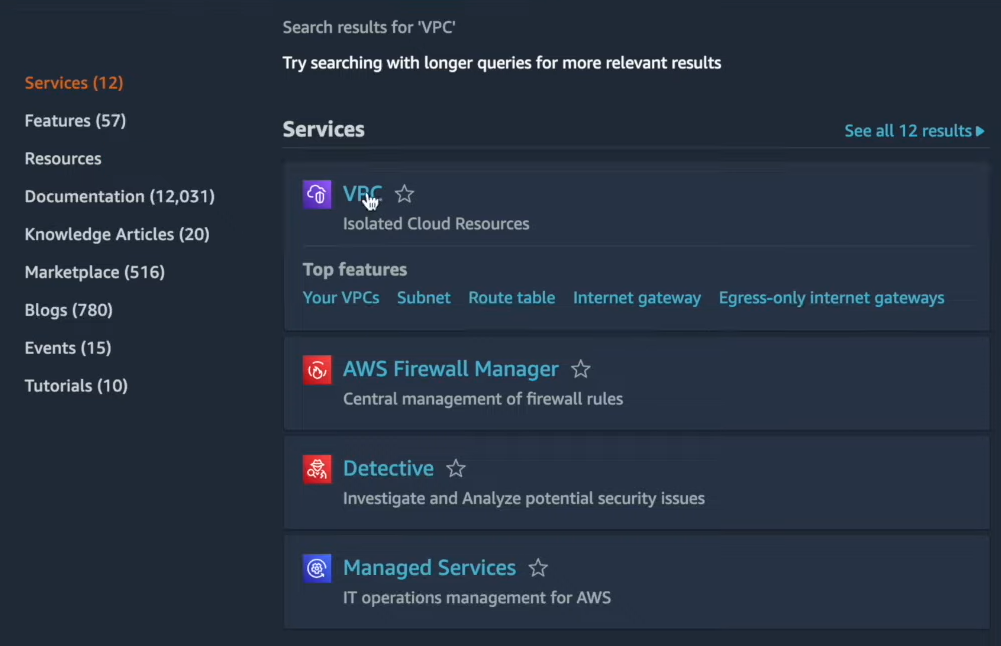
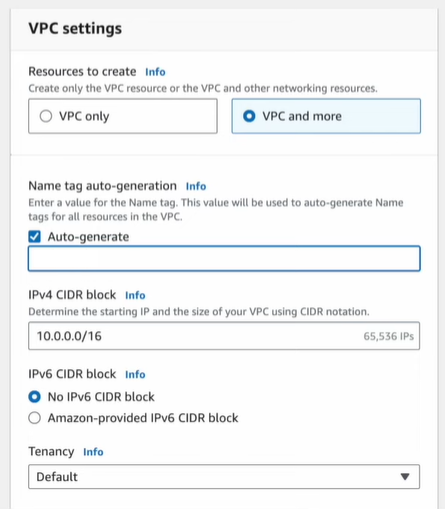
Click on Create VPC:
- Name it.
- Choose a CIDR block (e.g., 10.0.0.0/16).

Set up Public and Private Subnets. EMR’s master node typically resides in a public subnet if you need internet access; however, private subnets enhance security.

Step 4—Launch an EMR Cluster with Spark
Navigate to the EMR Dashboard by searching for EMR in the search bar.
Click on Create Cluster.

Cluster Name: Provide a name that identifies this Spark cluster.
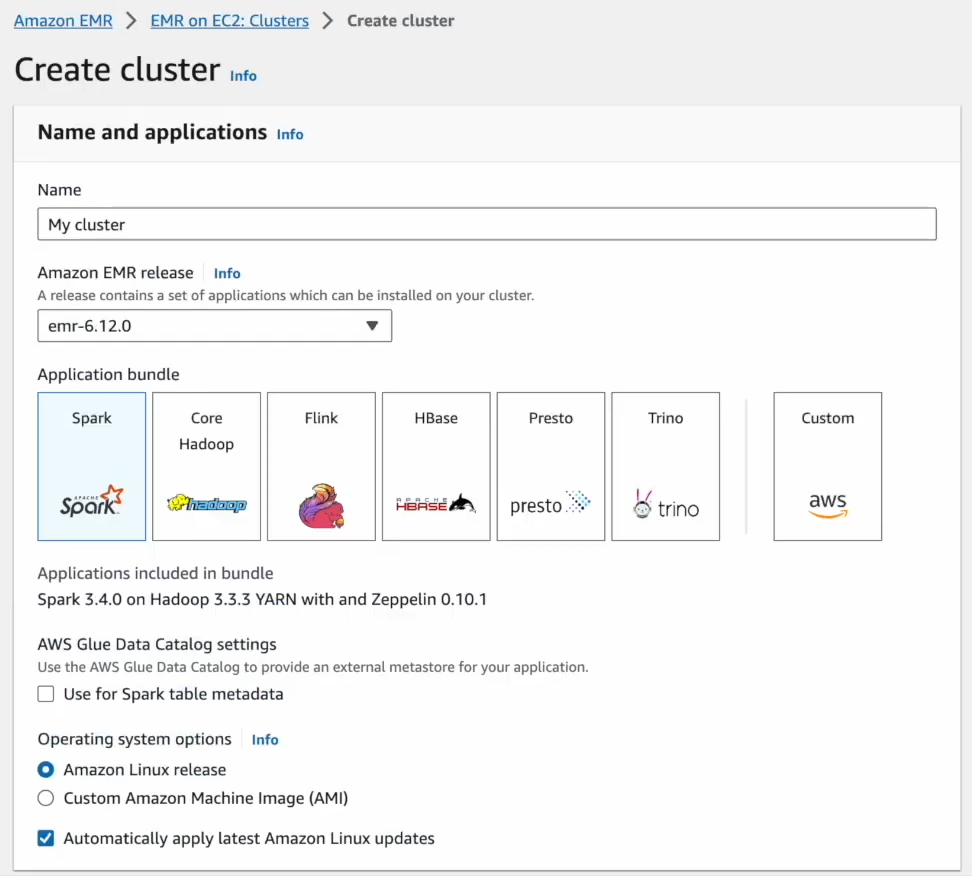
Applications: Select Apache Spark under the list of applications.

Now, choose instance types based on your workload (e.g., m5.xlarge for general use or r5.xlarge for memory-heavy tasks).
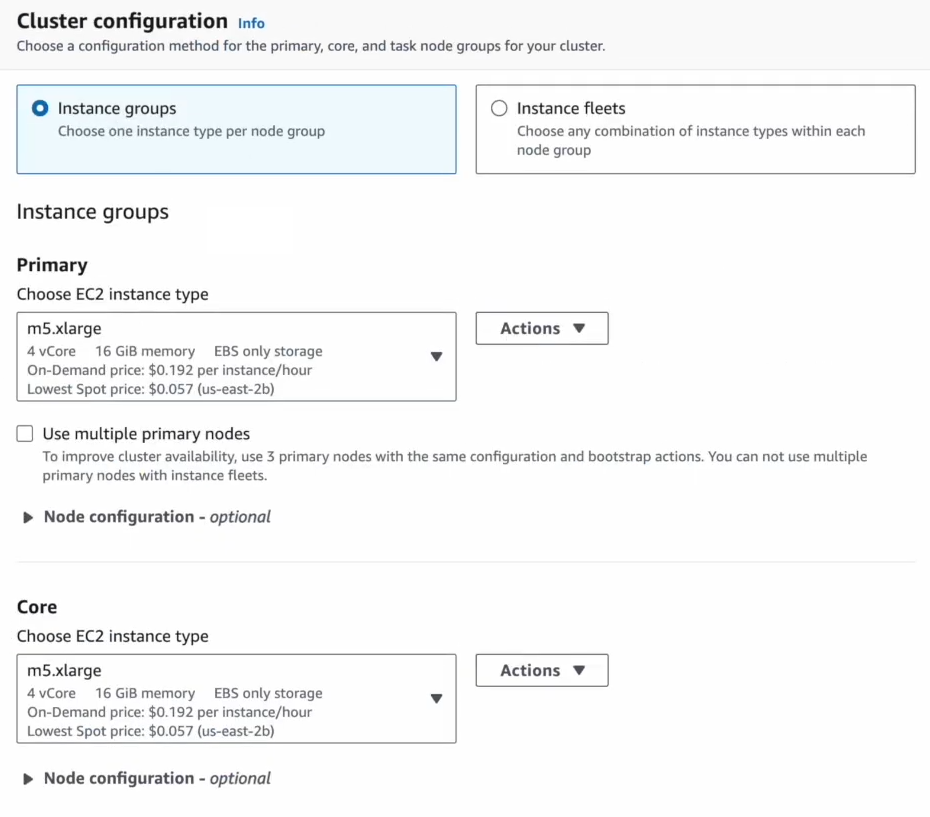
Next, configure the number of core and task nodes based on your Spark workload.
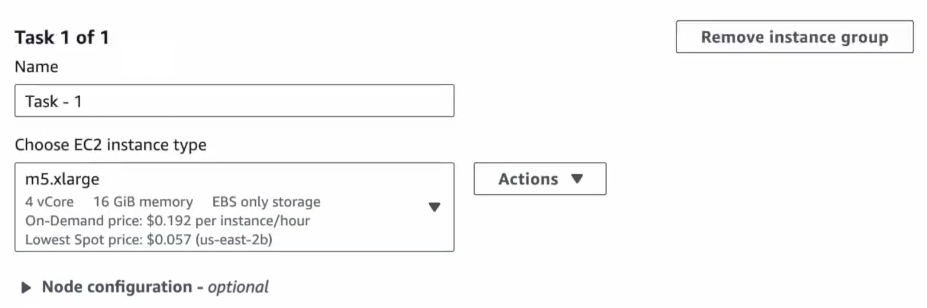
Remove the default one and set the number of instances based on your workload needs.
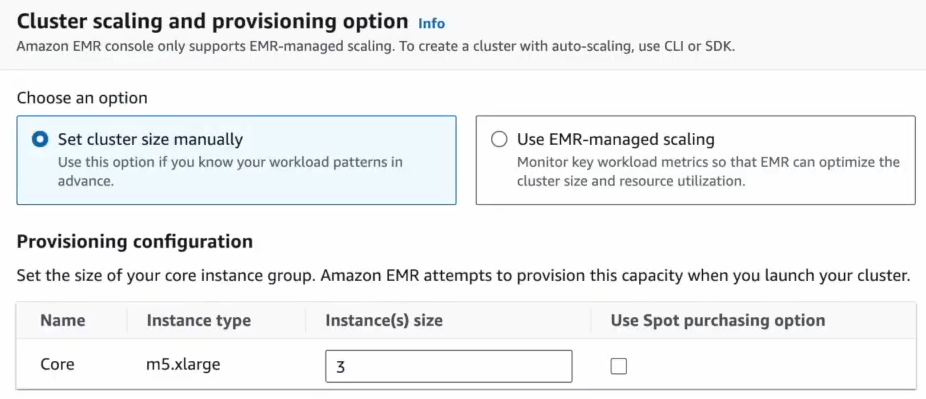
For Network and Security Configuration:
Select the VPC and subnet configured in Step 3.
Configure security settings (EC2 key pair for SSH access).
Create and assign appropriate service roles to manage permissions for EC2 (Elastic Compute Cloud) and EMR roles.

Create an EC2 instance profile. Choose "Create an instance profile", then head to the S3 bucket access section. From there, select "All s3 buckets in this account with read and write access".
For Logging Configuration:
Enable logging and set the destination to the S3 bucket created in Step 2. This setup captures cluster logs, useful for debugging and auditing.
Review the configurations, then click Create Cluster to launch.
Step 5—Upload Data and Spark Scripts
Upload any necessary datasets to your S3 bucket under the input folder.
Next, create a Spark script locally using Python and save it as main.py. Here’s a very simple example:
# Demo
from pyspark.sql import SparkSession
def transform_data(data_source, output_uri):
spark = SparkSession.builder.appName("MyFirstApplication").getOrCreate()
df = spark.read.option("header", "true").csv(data_source)
# Perform transformations
transformed_df = df.groupBy("column_name").count()
transformed_df.write.mode("overwrite").parquet(output_uri)
if __name__ == "__main__":
transform_data("s3://your-bucket-name/input/data.csv", "s3://your-bucket-name/output/")Now, upload this script to the root folder in your S3 bucket.
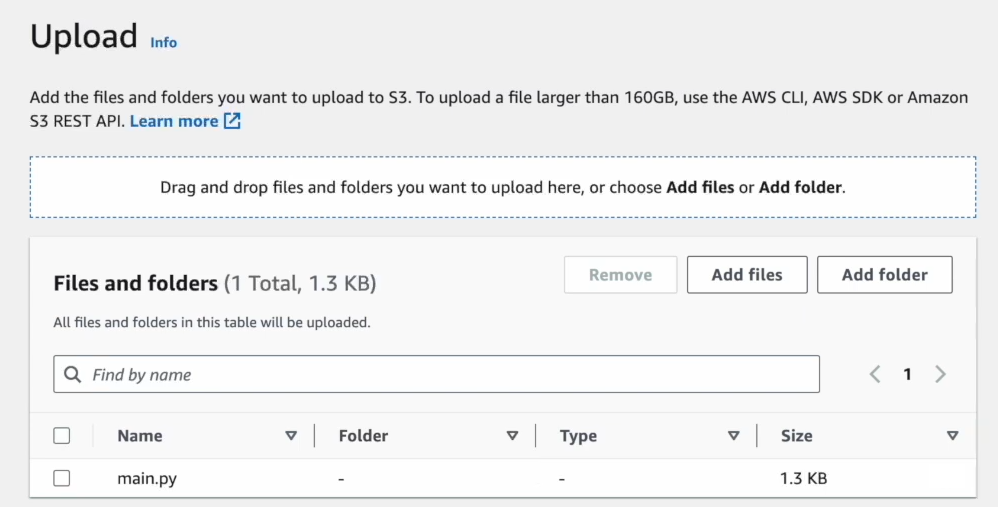
Step 6—Add Steps to Your EMR Cluster
Steps allow you to add Spark jobs for execution within the EMR cluster. Follow these steps to add and configure your Spark jobs:
Go back to your EMR cluster in the AWS console. Click on Steps, then click Add Step.
Configure the step as follows:
- Step Type: Select Spark Application.
- Script Location: Specify the S3 path to the Spark script (e.g., s3://your-bucket/scripts/main.py).
- Arguments: If your Spark job requires parameters, specify them here.
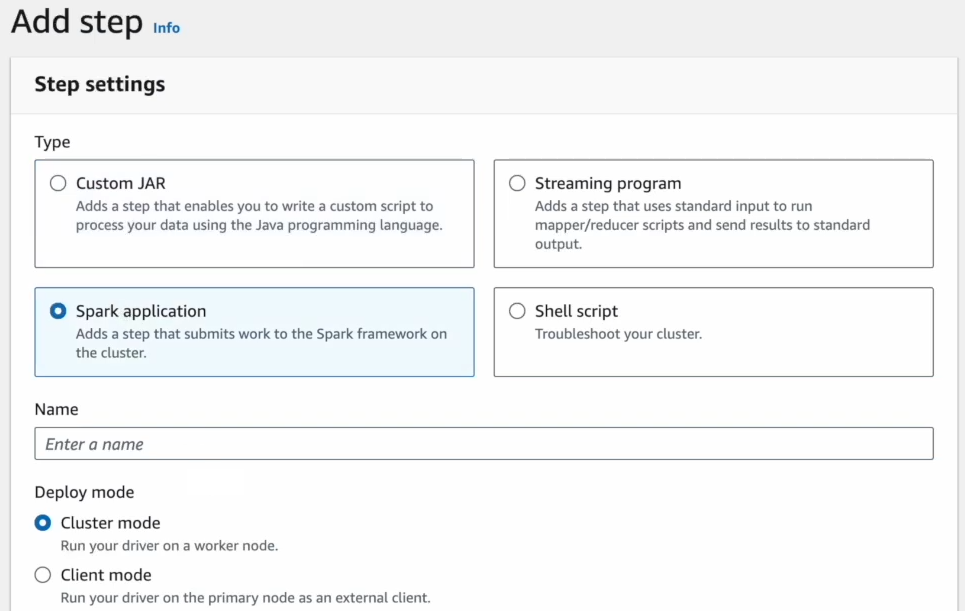

Click Add to queue the Spark job in the cluster.
Step 7—Monitor Your Spark Job Progress
You can monitor the status of each Spark job, including real-time status (pending, running, or completed) through the EMR console under the Steps tab. You can also check logs in the S3 bucket under the logs folder or view them directly in the EMR console.
Optional—SSH into Your Cluster
To SSH into your primary node, go to EC2 (Elastic Compute Cloud) Dashboard, find your primary node instance, and note its public DNS or IP address. Make sure your security group allows inbound SSH traffic from your IP address. Use SSH to connect:
ssh -i /path/to/your-key.pem hadoop@<Primary-Node-Public-DNS>Once connected, you can run commands or scripts directly on the cluster if needed.
Step 8—Clean Up Resources
Once your Spark jobs are completed, it’s essential to terminate your EMR cluster to avoid unnecessary charges. Go to your EMR Dashboard, pick your cluster, and hit Terminate. This will close down the cluster. Also, take a look at the S3 resources you're not using anymore and get rid of them to save on storage costs.
If you go through these steps thoroughly, you'll end up with a solid Apache Spark setup on AWS EMR in no time.
Optimizing Spark Performance on AWS EMR
To get the most out of Apache Spark on EMR, effective configuration and fine-tuning are essential. Here are critical strategies and configurations tailored for optimal performance:
Cluster Configuration and Instance Selection
Choosing appropriate Amazon EC2 instance types impacts Spark’s performance. Generally:
- Compute-Optimized Instances (e.g.,
c5,c6a): Best for compute-intensive tasks like transformations and aggregations. - Memory-Optimized Instances (e.g.,
r5,r6g): Ideal for memory-heavy workloads such as iterative machine learning and join operations. - Storage-Optimized Instances (e.g.,
i3,i4i): Provide high IOPS for shuffle-intensive operations; these are excellent for temporary data storage and reduce I/O bottlenecks.
Recommended Practices
- Use instance fleets to mix On-Demand, Spot, and Reserved Instances for cost efficiency and fault tolerance.
- Configure Amazon Elastic Block Store (EBS) for additional storage needs, balancing throughput and cost based on workload demands.
Enable Auto Scaling
Dynamic cluster resizing improves resource utilization:
- Vertical Scaling: Increase instance types for resource-hungry jobs.
- Horizontal Scaling: Adjust the number of task nodes during peak and idle times.
- Instance Fleet Configuration: Use diverse instance types and spot allocations to maintain performance during spot interruptions.
Spot Instances for Cost Efficiency
Spot Instances are useful for non-critical task nodes to reduce costs. By configuring Spot Instances for transient or parallel tasks, you can maintain performance with base On-Demand instances while taking advantage of lower-cost Spot instances for additional capacity. Configure instance fleets for fault tolerance by specifying multiple instance types, increasing the likelihood of maintaining capacity during spot interruptions.
Choosing Optimal Storage and Compute Resources
Selecting the right combination of storage and compute can have a considerable impact on both performance and cost:
EMRFS with Amazon S3 EMRFS (Elastic MapReduce File System) enables seamless integration with Amazon S3, allowing Spark to directly read and write from S3. Recommendations include:
- Using consistent file naming conventions and organizing data into logical directories for efficient querying and retrieval.
- Configuring S3 Transfer Acceleration for faster data transfer in distributed systems.
Local Storage (EBS or NVMe)
EC2 (Elastic Compute Cloud) instance storage (e.g., NVMe drives on i3 instances) provides low-latency, high-throughput storage suitable for intermediate data like shuffle files. However, local storage is ephemeral—only use it for temporary data. For persistent storage needs, consider using S3.
Balancing EMRFS and Local Storage
Combining EMRFS (for persistent storage) with instance storage (for temporary, high-I/O operations) provides both durability and performance efficiency.
Use S3 Select and S3-Optimized Committer
S3 Select
Use S3 Select to filter JSON or CSV data directly in S3, reducing the amount of data transferred to the EMR cluster. This can reduce latency and speed up jobs by only loading the necessary data into Spark.
S3-Optimized Committer
Enable the EMRFS S3-optimized committer for efficient writes to S3, particularly with formats like Parquet and ORC. This committer reduces I/O operations during Spark’s output write phase, lowering overhead by handling temporary files more efficiently.
Selecting the Optimal Data Format
Using efficient data formats reduces I/O and boosts Spark’s performance:
Columnar Formats (Parquet, ORC)For analytical workloads, columnar formats like Parquet and ORC are recommended as they:
- Enable optimized read operations due to their columnar structure.
- Reduce memory load, as Spark loads only the columns needed for analysis.
Row-Oriented Formats (CSV, JSON)Row-oriented formats, such as CSV and JSON, are beneficial for write-heavy workloads or when structure is less strict. However, these formats typically increase memory usage and processing time. Use them sparingly in Spark jobs, as columnar formats generally yield better performance in analytics workloads.
Leveraging Parallelism and Data Caching (Spark-Specific Optimizations)
Adjusting default configurations in spark-defaults.conf can lead to significant performance gains. Optimizing parallelism and caching configurations allows Spark to maximize resource utilization and reduce unnecessary data transfers:
Parallelism
Set spark.default.parallelism and spark.sql.shuffle.partitions based on your cluster size. A good rule of thumb is to set parallelism values to 2-3 times the total number of executor cores.
Data Caching
Use Spark’s caching mechanism (.cache() and .persist()) for frequently accessed datasets within iterative jobs. Caching reduces data retrieval times, especially when the data is reused across multiple Spark stages.
Leverage Adaptive Query Execution (AQE)
Spark 3 on EMR supports AQE, which dynamically optimizes queries based on runtime statistics. AQE can:
- Transform sort-merge joins to broadcast joins when possible.
- Coalesce shuffle partitions to reduce shuffling, improving performance for complex joins and aggregations.
Implement Query Optimizations in Spark
Dynamic Partition Pruning: For filter-based queries, dynamic partition pruning selectively loads only relevant partitions at runtime, drastically reducing I/O for ETL processes involving partitioned datasets.
Optimize Scalar Subqueries and Aggregates: Flatten scalar subqueries to avoid repetitive reads. Vectorized execution of aggregates also enhances performance, as it processes rows in batches rather than individually.
Leverage AWS Data Services for Enhanced Performance
AWS Glue for Data Integration
AWS Glue provides serverless ETL and integrates seamlessly with Spark on EMR, streamlining data preparation and transformation for both Spark and non-Spark jobs.
Amazon SageMaker for Machine Learning
When training machine learning models, combine EMR with Amazon SageMaker to distribute training across large datasets, leveraging both Spark for data preprocessing and SageMaker for model training.
Real-Time Data Ingestion with Kinesis and Lambda
Use Amazon Kinesis for real-time data streaming and AWS Lambda for serverless processing to complement Spark’s batch and streaming capabilities, creating a comprehensive data pipeline.
Optimize Resource Allocation and Configuration
Executor and Driver Configuration
Fine-tune parameters like spark.executor.memory, spark.executor.cores, and spark.driver.memory according to the instance types and workload demands. Avoid setting excessive memory, as this may lead to memory contention.
Dynamic Allocation
Enable Dynamic Allocation (spark.dynamicAllocation.enabled) to automatically scale the number of executors based on workload demands. This feature reduces idle resources and improves cost-efficiency.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Conclusion
And that’s a wrap! Setting up and running Apache Spark on EMR is easy. It's efficient and scalable. EMR gives you the flexibility to manage your Spark clusters, control how resources are used, and customize things to get the best performance possible.
In this article, we have covered:
- What is AWS EMR?
- What is Apache Spark?
- Spark on EMR—Architecture and Components
- Step-by-Step Guide to Configure Spark on EMR
- Optimizing Spark Performance on EMR
… and so much more!
FAQs
What is Apache Spark used for?
Apache Spark is a distributed data processing framework designed to handle large-scale data processing tasks across multiple nodes. It’s widely used for data engineering, analytics, machine learning, and real-time data streaming. Spark’s in-memory processing capabilities make it especially efficient for iterative and interactive applications, such as data transformations, ETL processes, and model training.
What is AWS EMR?
Amazon EMR (Elastic MapReduce) is a managed service from AWS that simplifies the deployment and management of big data frameworks like Apache Spark, Hadoop, and HBase. EMR enables you to process large data volumes on clusters of EC2 instances with automatic provisioning, scaling, and optimization. It’s highly flexible and integrates well with AWS services.
Is AWS EMR based on Hadoop?
Yes, AWS EMR was initially built around Hadoop and its ecosystem of tools, including HDFS (Hadoop Distributed File System), YARN (Yet Another Resource Negotiator), and MapReduce. Over time, AWS EMR expanded to support additional frameworks like Apache Spark, Presto, and Flink.
What is EMR Spark?
EMR Spark refers to the deployment of Apache Spark on Amazon EMR clusters. By running Spark on EMR, you can take advantage of EMR’s managed infrastructure for scaling, fault tolerance, and integration with AWS storage and analytics services like S3, Athena, and Glue.
How do you check the Spark version on EMR?
To check the version of Apache Spark on an EMR cluster. First, log in to the EMR cluster’s master node using SSH and run the following command to display the Spark version:
spark-submit --versionOR,
you can check the EMR cluster’s application list in the AWS Console under Cluster Details, where the installed version of Spark is listed.
How do you run a PySpark script on EMR?
Running a PySpark script on EMR involves adding a Spark step to your cluster:
Step 1—Upload your PySpark script to an S3 bucket.
Step 2—Go to the EMR Console, select your cluster, and navigate to the Steps tab.
Step 3—Click Add Step and choose Spark application as the step type.
Step 4—Provide the S3 path to your script under Script location and specify any arguments.
Step 5—Add the step, and EMR will execute the PySpark script.
OR,
you can SSH into the master node and run the PySpark script directly using:
spark-submit s3://your-bucket/path/to/your-script.pyWhat is EMR used for?
EMR is used for processing large data volumes in a scalable and cost-effective way. Typical use cases include:
- Data processing and ETL
- Data analytics
- Machine learning
- Streaming data processing
What does EMR stand for in AWS?
In AWS, EMR stands for Elastic MapReduce. The name originates from the service’s initial design around Hadoop’s MapReduce processing framework, though it now supports additional engines like Spark, Flink, and Presto for more versatile data processing.
How can I reduce costs when using EMR for Spark?
Here are some strategies to reduce costs when running Spark on EMR:
- Use Spot Instances
- Right-size the cluster
- Terminate clusters promptly
- Optimize storage
Can I use Jupyter Notebooks with Spark on EMR?
Yes, Amazon EMR supports Jupyter Notebooks as part of EMR Notebooks. EMR Notebooks provides an interactive interface to write and execute Spark code, ideal for data exploration and model development.















