





























Apache Spark has emerged as a dominant platform for big data processing and analytics. It’s known for handling massive amounts of data quickly and efficiently. Spark's unified platform supports batch/real-time streaming, machine learning, and graph processing while also offering APIs for Java, Scala, Python, R, and SQL. This flexibility has led to widespread adoption across industries, with major tech players like Databricks, IBM, Qubole, Cloudera, and others are integrating Spark into their data platforms. This growing adoption reflects the increasing demand for data-driven insights, which is driving the Apache Spark market to expand at a compound annual growth rate (CAGR) of 33.9% through 2030. Because of this, the demand for professionals with Apache Spark skills is rising, making Spark certification and training essential for advancing careers in this field.
In this article, we will guide you through the top Apache Spark certifications, Apache Spark training programs, and badges available today, as well as the benefits you'll gain from earning them.
Table of Contents
- 🌟 Databricks Certified Associate Developer for Apache Spark
- 🌟 O’Reilly Developer Certification for Apache Spark
- 🌟 Simplilearn: Introduction to Big Data Hadoop and Spark Developer
- 🌟 Cloudera Certified Associate (CCA) Spark and Hadoop Developer
- 🌟 HDP Certified Developer (HDPCD) Spark Certification
- 🌟 MapR Certified Spark Developer
- 🌟 Comparison of Apache Spark Certifications
- 🌟 IBM (Coursera): Introduction to Big Data with Spark and Hadoop
- 🌟 IBM (Coursera): Scalable ML on Big Data using Apache Spark
- 🌟 LinkedIn Learning: Advance Your Data Skills in Apache Spark
- 🌟 Udemy: Taming Big Data with Apache Spark and Python - Hands On!
- 🌟 Datacamp: Introduction to PySpark
- 🌟 Duke University: Spark, Hadoop, and Snowflake for Data Engineering
- 🌟 Pluralsight: Apache Spark Fundamentals
- 🌟 Comparison of Apache Spark Training Programs & Courses
What is Apache Spark?
Apache Spark is an open source distributed computing framework designed for big data processing. It provides a unified analytics engine capable of handling batch processing, streaming data, machine learning, and graph processing. Apache Spark's high-level APIs in Java, Scala, Python, and R make it accessible to a wide range of developers.
Let's explore Apache Spark's key features.
1) 100x Speed — Spark's in-memory computing enables high-speed execution. By caching data in memory, Spark processes data faster than traditional disk-based systems. Also, compared to Apache Hadoop, Apache Spark can process data a whole lot faster—about 100 times faster.
2) Support for Multiple Languages — Spark, written in Scala, also natively supports Python through PySpark and Java natively. Also, it offers SparkR for R programmers and SparkSQL, which allows data querying using SQL syntax, making it versatile and accessible to a wide range of developers.
3) Real-time data processing — Spark Streaming lets engineers and scientists process real-time data from sources like Kafka, HDFS, and others. They can then push this processed data to databases, live dashboards, file systems, and reports.
4) Built-in libraries — Spark includes libraries for machine learning (MLlib), graph processing (GraphX), and streaming (Spark Streaming). They serve diverse analytical needs.
5) Scalability — Spark is built on the concept of cluster computing, making it horizontally scalable. As more nodes are added to the cluster, it can handle large datasets.
6) Distributed Computing — Spark distributes data processing tasks across a cluster, allowing the system to process in parallel and scale up easily.
Why Get an Apache Spark Certification?
Getting Apache Spark certified can be a major career booster in the big data field. It doesn't just make you more employable, but also verifies your skills and can increase your earning potential. Certified professionals stand out in the competitive job market, demonstrating expertise in a highly demanded field. The certification isn't just about proving you're good with Spark—it also gives you hands-on experience, so you're ready for the real world. It establishes credibility, which can lead to recognition in the industry and new networking opportunities. As Spark keeps shaping data processing, staying certified helps keep your skills current, preparing you for future jobs in data engineering and machine learning.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Top Apache Spark Certifications, Training Programs, and Badges
1) Apache Spark Certifications:
Databricks Certified Associate Developer for Apache Spark
╰➤ Certification Details:
Databricks Certified Associate Developer for Apache Spark certification exam assesses your understanding of the Spark DataFrame API and your ability to apply it to complete basic data manipulation tasks within a Spark session. The certification is designed to test your proficiency in data manipulation tasks such as selecting, renaming, and manipulating columns; filtering, dropping, sorting, and aggregating rows; handling missing data; combining, reading, writing, and partitioning DataFrames with schemas; and working with UDFs and Spark SQL functions. It also covers the basics of the Spark architecture, including execution/deployment modes, the execution hierarchy, fault tolerance, garbage collection, and broadcasting.

╰➤ Exam Domains:
Databricks Certified Associate Developer for Apache Spark certification exam covers these domains:
- Apache Spark Architecture Concepts: 17%
- Apache Spark Architecture Applications: 11%
- Apache Spark DataFrame API Applications: 72%
╰➤ Prerequisites
- Working knowledge of either Python or Scala
- Familiarity with the Spark DataFrame API
To fully prepare for the Databricks Certified Associate Developer for Apache Spark certification exam, candidates should take one of the following Databricks Academy courses:
- Apache Spark Programming with Databricks (instructor-led)
- Apache Spark Programming with Databricks (self-paced, available in Databricks Academy)
Note: Instructor-led course is not free at all and can cost around $1500.
╰➤ Exam Structure
Databricks Certified Associate Developer for Apache Spark exam is made up of 60 multiple-choice questions and you've got 120 minutes to finish it.
╰➤ Minimum Passing Score
A minimum passing score of 65% is required.
╰➤ Certification Validity
Databricks Certified Associate Developer for Apache Spark certification is valid for a period of 2 years.
╰➤ Certification Status
Databricks Certified Associate Developer for Apache Spark certification is active.
╰➤ Spark Certification Cost
Databricks Certified Associate Developer for Apache Spark certification exam costs $200 USD, not including tax.
How to Register for Databricks Certified Associate Developer for Apache Spark?
Step 1—Create a Databricks Certification Account
First, head over to the Webassessor website and create an account if you don't have one already.
Step 2—Access the Certification Page
Sign up/Log in to your account and navigate to the certification page.

Step 3—Pick the Certification Exam With Your Choice of Programming Language (Python or Scala)
Select the Databricks Certified Associate Developer for Apache Spark certification exam from the available options.
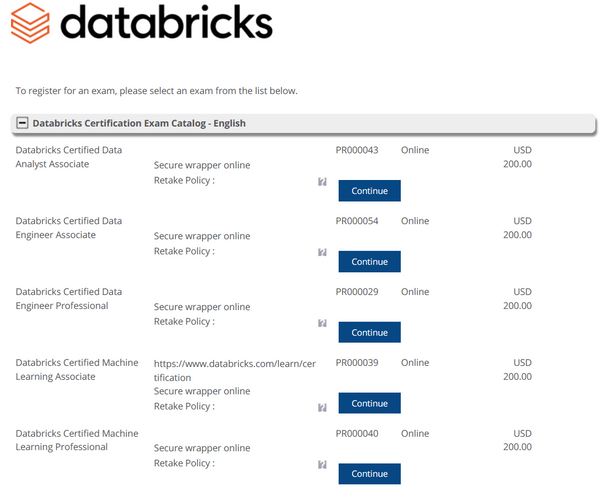
Step 4—Register for the Exam
Fill out the registration form with your personal and contact information.
Step 6—Schedule Your Exam
Once you’ve created your Databricks account, browse the catalog of available certifications and pick the one that aligns with your career goals. Click "Continue" to proceed to the next step.

Step 5—Complete the Registration Process and Pay the Exam Fee
Proceed with the payment of the exam fee, which is $200 per attempt.
Step 6—Receive Confirmation
After successful registration and payment, you will receive a confirmation email with further instructions.
Step 7—Prepare for the Exam
Use the resources provided below, to prepare for the certification exam.
Step 9—Take the Exam
On the scheduled date, log in to the exam platform and complete the certification exam within the allotted time of 120 minutes.
O’Reilly Developer Certification for Apache Spark
╰➤ Certification Details
O'Reilly Developer Certification for Apache Spark is a professional credential designed to validate a developer's expertise in using Apache Spark. This certification was created through a collaboration between O'Reilly Media and Databricks. It aims to set a standard for measuring and validating skills in Spark development. The certification is for those who want to prove they can build data pipelines and apps using Spark.

╰➤ Exam Domains
O'Reilly Developer Certification for Apache Spark exam covers various domains related to Apache Spark, which includes:
- Understanding Spark's architecture and components
- Data processing and manipulation using Spark DataFrames and RDDs
- Writing and optimizing Spark jobs
- Utilizing Spark SQL for querying structured data
- Implementing Spark Streaming for real-time data processing
╰➤ Prerequisites
There are no formal prerequisites to take the exam, but it is highly recommended that candidates must have:
- Hands-on experience with Apache Spark
- Familiarity with programming languages commonly used with Spark, such as Scala, Python, or Java
- Strong understanding of big data concepts and data processing techniques
╰➤ Exam Structure
O'Reilly Developer Certification for Apache Spark exam is made up of 40 multiple-choice questions and you've got 1 hour and 30 minutes (90 Minutes) to finish it.
╰➤ Minimum Passing Score
The minimum passing score for the O'Reilly Developer Certification for Apache Spark is typically around 70%.
╰➤ Certification Validity
O'Reilly Developer Certification for Apache Spark does not have a specified expiration date, but staying updated with the latest developments in Apache Spark is advisable.
╰➤ Certification Status:
As of the latest updates, the O'Reilly Developer Certification for Apache Spark is no longer available (discontinued). If you're interested in getting certified in Spark, you may want to look into alternative certifications from Databricks or other organizations.
╰➤ Certification Cost
The cost for the O'Reilly Developer Certification for Apache Spark was $300 at the time it was active.
Simplilearn: Introduction to Big Data Hadoop and Spark Developer
╰➤ Certification Details
Simplilearn's Introduction to Big Data Hadoop and Spark Developer certification is designed for professionals looking to work with big data technologies, focusing on both Apache Hadoop and Apache Spark. This certification is particularly beneficial for IT professionals, data analysts, and aspiring data scientists.

╰➤ Exam Domains
Simplilearn's Introduction to Big Data Hadoop and Spark Developer certification covers a variety of domains essential for big data development, including:
- Introduction to Big Data and Hadoop
- Hadoop architecture and its ecosystem
- Hadoop Distributed Storage (HDFS) and Apache YARN
- Data ingestion techniques using tools like Apache Sqoop and Apache Flume
- Distributed processing using the MapReduce framework
- Real-time data processing with Spark
- Spark SQL and RDD optimization techniques
╰➤ Prerequisites
No strict prerequisites, but a basic understanding of programming concepts is beneficial.
╰➤ Exam Structure
Simplilearn's Introduction to Big Data Hadoop and Spark Developer certification exam consists of performance-based tasks that assess practical skills in using Hadoop and Spark. The certification course usually takes anywhere from 11 to 35 hours to complete, depending on the training format you choose. During the exam, you'll typically get 8 to 12 hands-on tasks that you need to complete within a set time frame.
╰➤ Minimum Passing Score
Generally, a minimum score of 70% is required.
╰➤ Certification Validity
Simplilearn's Introduction to Big Data Hadoop and Spark Developer certification is valid for a lifetime, meaning that once obtained, it does not expire.
╰➤ Certification Status: Active
Simplilearn's Introduction to Big Data Hadoop and Spark Developer certification is currently active.
╰➤ Certification Cost
The cost to take the certification exam is free (90-day access).
Cloudera Certified Associate (CCA) Spark and Hadoop Developer (CCA175)
╰➤ Certification Details
Cloudera Certified Associate (CCA) Spark and Hadoop Developer certification is a recognized credential that validates a candidate's skills in using Apache Spark and Hadoop for data processing and analysis. This certification is specifically targeted at professionals who wish to demonstrate their expertise in the big data ecosystem.

╰➤ Exam Domains
The exam assesses the following domains:
- Data Ingestion: Using tools like Sqoop, Flume, and Kafka to import and export data into HDFS.
- Data Transformation and Storage: Using Spark with Scala or Python to perform ETL processes, including reading/writing data, filtering, aggregating, and joining datasets.
- Data Analysis: Using Spark SQL to analyze data and generate reports.
- Configuration and Optimization: Understanding command-line options for Spark job submissions and optimizing performance.
╰➤ Prerequisites
No prerequisites are needed to take the Cloudera Certified Associate (CCA) Spark and Hadoop Developer exam. That said, having a few things down will definitely help.
For starters, basic programming skills are a must. Ideally, you'll be proficient in Scala or Python. You should also know the basics of big data and the Hadoop ecosystem.
Finally, it's a good idea to have access to a development environment where you can practice. Cloudera Quickstart VM is a great option, or you can set up something similar on your own.
╰➤ Exam Structure
Cloudera Certified Associate (CCA) Spark and Hadoop Developer certification is performance-based tasks that assess practical skills in using Hadoop and Spark. During the exam, you'll typically get 8 to 12 hands-on tasks that you need to complete within 120 minutes.
╰➤ Minimum Passing Score
The minimum passing score for the Cloudera Certified Associate (CCA) Spark and Hadoop Developer exam is 70%.
╰➤ Certification Validity
Cloudera Certified Associate (CCA) Spark and Hadoop Developer certification is valid for 2 years. To maintain the certification, candidates must retake the exam before the expiration date.
╰➤ Certification Status: Retried/Expired
Cloudera Certified Associate (CCA) Spark and Hadoop Developer certification is currently active and recognized in the industry, especially as organizations increasingly adopt big data technologies.
╰➤ Certification Cost
The cost of the Cloudera Certified Associate (CCA) Spark and Hadoop Developer certification exam is $295. This fee is applicable for the exam registration and does not include any preparatory courses or materials.
HDP Certified Developer (HDPCD) Spark certification
╰➤ Certification Details
HDP Certified Developer (HDPCD) Spark certification is designed to validate the skills of developers in creating applications using Apache Spark on the Hortonworks Data Platform (HDP). This certification emphasizes hands-on experience and practical knowledge over theoretical understanding. The exam format of this certification is Hands-on, performance-based assessment.

╰➤ Exam Domains
HDP Certified Developer (HDPCD) Spark certification exam encompasses several key areas, which includes:
- Data Ingestion: Techniques for importing data into Spark.
- Data Transformation: Utilizing Spark's capabilities to manipulate and transform data.
- Data Analysis: Performing analysis and querying data using Spark SQL.
╰➤ Prerequisites
Candidates should have:
- A foundational understanding of the Hadoop ecosystem, including HDFS and YARN.
- Proficiency in programming languages such as Scala or Python.
- Basic SQL skills for data manipulation and querying.
╰➤ Exam Structure
HDP Certified Developer (HDPCD) Spark certification exam puts your Apache Spark skills to the test in a real-world setting. You'll have 2 hours to work through tasks in a live HDP environment, where you'll have access to a single-node cluster. Your job is to complete a series of tasks that check your ability to use Spark—from processing data to implementing its key features.
╰➤ Minimum Passing Score
To achieve HDP Certified Developer (HDPCD) Spark certification, candidates must successfully complete a specified number of tasks. There is no partial credit; all tasks must be executed correctly.
╰➤ Certification Validity
The certification does not have a specified expiration date, but candidates are encouraged to stay updated with the latest versions of the technology.
╰➤ Certification Status:
As of the latest updates, the HDP Certified Developer (HDPCD) Spark certification is no longer available (discontinued).
╰➤ Certification Cost
The cost for the HDP Certified Developer (HDPCD) Spark certification was $250 at the time it was active.
MapR Certified Spark Developer
╰➤ Certification Details
MapR Certified Spark Developer certification was designed to validate professionals’ skills in working with Apache Spark. It primarily focuses on Spark’s core functionalities, including Resilient Distributed Datasets (RDDs), DataFrame operations, and Spark Streaming, while emphasizing proficiency in Scala for Spark programming.

╰➤ Exam Domains
Key domains covered by the MapR Certified Spark Developer certification include:
- RDDs and Pair RDDs: Creating, manipulating, and optimizing RDDs.
- DataFrames: Performing operations such as filtering, joining, and aggregating data using Spark SQL.
- Spark Execution Model: Understanding Spark's execution engine, optimizations, and configurations.
- Spark Streaming: Building real-time data processing pipelines.
- Machine Learning: Basic knowledge of machine learning with Spark MLlib.
╰➤ Prerequisites
Candidates are expected to have a solid understanding of Spark, especially in using Scala (as opposed to Python), as well as experience in developing Spark-based applications. Familiarity with distributed computing and big data processing concepts is also crucial.
╰➤ Exam Structure
MapR Certified Spark Developer certification exam consists of objective-type questions with code snippets. The candidate is tested on various Spark concepts and scenarios, mostly revolving around the use of Scala for Spark. The exam lasts 120 minutes.
╰➤ Minimum Passing Score
The minimum passing score for the MapR Certified Spark Developer certification exam is not publicly disclosed by MapR. But, it is generally recommended to aim for a score of at least 70% or higher to increase the chances of passing the exam.
╰➤ Certification Validity
Did not have an expiration date, but staying updated is advisable.
╰➤ Certification Status:
MapR Certified Spark Developer (MCSD) certification has been retired as of 2021. MapR was acquired by Hewlett Packard Enterprise (HPE) in 2019, and the certification program has been discontinued since then.
╰➤ Certification Cost
The cost of the MapR Certified Spark Developer exam was $250.
Comparison of Apache Spark Certifications
| Certification name | Provider | Prerequisites | Exam details | Target audience | Difficulty level | Certification cost |
| Databricks Certified Associate Developer for Apache Spark | Databricks | ✦ Working knowledge of Python or Scala ✦ Familiarity with Spark DataFrame API |
✦ 60 multiple-choice questions ✦ 120 minutes ✦ Minimum passing score: 65% |
Developers looking to demonstrate Spark DataFrame API skills | Intermediate | $200 |
| O'Reilly Developer Certification for Apache Spark | O'Reilly Media and Databricks | ✦ Hands-on experience with Apache Spark ✦ Familiarity with Scala, Python, or Java |
✦ 40 multiple-choice questions ✦ 90 minutes ✦ Minimum passing score: ~70% |
Developers who build data pipelines and apps using Spark | Intermediate | $300 (discontinued) |
| Simplilearn: Introduction to Big Data Hadoop and Spark Developer | Simplilearn | ✦ Basic understanding of programming concepts | ✦ Performance-based tasks ✦ Minimum passing score: 70% ✦ 11-35 hours of course content |
IT professionals, data analysts, aspiring data scientists | Beginner to Intermediate | Free (90-day access) |
| Cloudera Certified Associate (CCA) Spark and Hadoop Developer (CCA175) | Cloudera | ✦ Basic programming skills in Scala or Python ✦ Understanding of big data concepts |
✦ Performance-based tasks ✦ 120 minutes ✦ Minimum passing score: 70% |
Developers using Spark and Hadoop for data processing | Intermediate | $295 |
| HDP Certified Developer (HDPCD) Spark Certification | Hortonworks | ✦ Foundational understanding of Hadoop ecosystem ✦ Proficiency in Scala, Python, or SQL |
✦ Performance-based tasks in a live HDP environment ✦ 2 hours |
Developers creating Spark apps on Hortonworks Data Platform | Intermediate | $250 (discontinued) |
| MapR Certified Spark Developer | MapR | ✦ Solid understanding of Spark, especially in Scala ✦ Experience developing Spark apps |
✦ Objective-type questions with code snippets ✦ 120 minutes ✦ Minimum passing score: ~70% |
Developers proficient in Scala for Spark programming | Advanced | $250 (retired) |
2) Apache Spark Badges & Credentials:
IBM: Spark - Level 1
╰➤ Badges Details
The IBM: Spark - Level 1 badge is an entry-level credential that recognizes an individual's foundational knowledge and skills in Apache Spark. It demonstrates the learner's understanding of Spark's architecture, core concepts, and programming model. To obtain this badge, learners must complete relevant coursework, hands-on labs, and assessments offered through IBM's training programs or the Cognitive Class platform

╰➤ Target Audience
The target audience for the IBM: Spark - Level 1 badge includes:
- Data Engineers: Professionals seeking to start or advance their careers in data engineering and analytics
- Data Scientists: Individuals looking to enhance their data processing skills using Spark
- Students and Recent Graduates: Those pursuing academic qualifications in data science, computer science, or related fields who want to gain practical experience with big data technologies
- Business Analysts: Professionals aiming to leverage big data for better decision-making
╰➤ Platform
The IBM: Spark - Level 1 badge is offered through Cognitive Class, a free online learning platform that offers courses on data science and big data technologies.
╰➤ Exam Structure
The exam structure for the IBM: Spark - Level 1 badge typically includes:
- Coursework: Completion of a series of online courses that cover the fundamentals of Apache Spark, including its architecture, core concepts, and programming model.
- Hands-on Labs: Practical exercises that allow learners to apply their knowledge in real-world scenarios, reinforcing their understanding of Spark's capabilities.
- Assessment: A final assessment or project that tests the learner's ability to use Spark for data processing tasks.
The format can vary, but it usually focuses on both the theory and the practical side of things.
╰➤ Skill Focus
The IBM: Spark - Level 1 badge focuses on developing the following skills:
- Knowledge of how Spark operates, including its components and how it processes data.
- Proficiency in using Spark's APIs for data manipulation, including operations on Resilient Distributed Datasets (RDDs) and DataFrames.
- Familiarity with programming in Spark using languages such as Python or Scala.
- Skills in applying Spark for various data processing tasks, such as filtering, aggregating, and transforming data.
- Basic understanding of querying structured data using Spark SQL.
IBM: Spark - Level 2
╰➤ Badges Details
IBM Spark - Level 2 badge is a credential that signifies foundational knowledge in Apache Spark.

╰➤ Target Audience
The IBM Spark Level 2 badge is designed for individuals who are new to Spark and want to build a solid foundation in the platform. It targets data engineers, data analysts, and developers seeking to enhance their ability to handle big data processing using Spark.
╰➤ Platform
The IBM Spark Level 2 badge is also primarily offered through CognitiveClass.ai, an IBM platform that provides free learning paths. The associated courses on CognitiveClass.ai offer hands-on experiences, helping users become proficient with Spark's features and operations.
╰➤ Exam Structure
To earn the IBM Spark Level 2 badge, learners must successfully complete the following courses on CognitiveClass.ai:
- Spark Fundamentals I & II
- Spark MLlib
- Exploring Spark's GraphX
- Analyzing Big Data in R using Apache Spark
These courses cover essential topics such as Spark's core architecture, machine learning with Spark's MLlib, and graph-parallel processing with GraphX.
╰➤ Skill Focus
The IBM Spark Level 2 badge focuses on developing the following skills:
- Basic understanding of Apache Spark and its architecture
- Proficiency in RDD and DataFrame operations
- Familiarity with Spark MLlib for machine learning tasks
- Basic memory management and performance tuning in Spark
- Introduction to GraphX for graph-parallel computations
This credential provides a strong foundation for further specialization in big data and machine learning with Spark.
IBM: Big Data with Spark and Hadoop Essentials
╰➤ Badges Details
The IBM Big Data with Spark and Hadoop Essentials badge signifies a foundational understanding of Big Data concepts and technologies like Apache Spark and Apache Hadoop.

╰➤ Target Audience
The IBM Big Data with Spark and Hadoop Essentials badge targets individuals interested in getting started with big data technologies, specifically professionals like data engineers, data analysts, and developers looking to expand their skills in processing large-scale data using Spark and Hadoop. It's also suitable for those transitioning from traditional databases or systems to big data frameworks.
╰➤ Platform
IBM Big Data with Spark and Hadoop Essentials is awarded through IBM's training programs and can be pursued via platforms like CognitiveClass.ai or Coursera. The courses associated with this badge offer hands-on experiences and focus on real-world applications.
╰➤ Exam Structure
The badge is earned by completing the Introduction to Big Data with Spark and Hadoop course, which includes a series of graded assignments and assessments. Upon passing all assessments, learners receive the course completion certificate, which qualifies them for the badge.
╰➤ Skill Focus
Key skills covered by this badge include:
- Understanding Big Data ecosystems and the ability to articulate their impact and use cases.
- Proficiency with Hadoop components (HDFS, HBase, MapReduce) and Spark’s RDDs and DataFrames.
- Knowledge of SparkSQL optimization with Catalyst and Tungsten.
- Basic skills in SparkML and cluster management.
IBM: Scalable Machine Learning with Apache Spark
╰➤ Badges Details
The IBM: Scalable Machine Learning with Apache Spark badge is awarded to individuals who demonstrate proficiency in solving large-scale machine learning and data science problems using Apache Spark. This badge recognizes the ability to leverage Spark's capabilities to scale machine learning tasks that involve big data, focusing on essential skills in Spark’s MLlib and advanced distributed computing techniques necessary for both supervised and unsupervised machine learning.

╰➤ Target Audience
The target audience for the IBM: Scalable Machine Learning with Apache Spark badge includes data scientists, machine learning engineers, and data engineers who need to develop and scale machine learning models on big datasets. It is suitable for professionals seeking to enhance their capabilities in handling complex, distributed ML tasks across large-scale environments using Apache Spark.
╰➤ Platform
The badge is primarily offered through Coursera and is authorized by IBM. The associated course provides hands-on training, enabling learners to work directly with Apache Spark to develop and implement machine learning models effectively.
╰➤ Exam Structure
To earn the IBM: Scalable Machine Learning with Apache Spark badge, learners must complete the course titled "Scalable Machine Learning on Big Data using Apache Spark". This course includes multiple assignments and practical exercises. Successful completion of these tasks, along with passing the final assessments, qualifies participants for the badge.
╰➤ Skill Focus
This badge emphasizes key skills in:
- Scaling machine learning models using Apache Spark’s MLlib.
- Handling Big Data and applying distributed computing concepts to machine learning problems.
- Building and optimizing both supervised and unsupervised learning models in Spark.
- Leveraging Spark’s distributed environment to overcome memory and computational limits typical of single-node ML tasks
This credential is ideal for professionals aiming to deepen their understanding of scalable ML practices within the Spark ecosystem.
Comparison of Apache Spark Badges
| Apache Spark Badge Name | Provider | Target Audience | Skill Focus |
| IBM: Spark - Level 1 | Cognitive Class | Data Engineers, Data Scientists, Students, Business Analysts | Understanding Spark Architecture, Data Manipulation, Basic Spark Programming, Data Processing Techniques, Introduction to Spark SQL |
| IBM: Spark - Level 2 | Cognitive Class | Data Engineers, Data Analysts, Developers | Basic understanding of Apache Spark, Proficiency in RDD and DataFrame operations, Familiarity with Spark MLlib, Basic memory management, Introduction to GraphX |
| IBM: Big Data with Spark and Hadoop Essentials | IBM's Training Programs | Data Engineers, Data Analysts, Developers transitioning to Big Data | Understanding Big Data ecosystems, Proficiency with Hadoop components, Knowledge of SparkSQL optimization, Basic skills in SparkML and cluster management |
| IBM: Scalable Machine Learning with Apache Spark | Coursera | Data Scientists, Machine Learning Engineers, Data Engineers | Scaling machine learning models using Spark’s MLlib, Handling Big Data, Building and optimizing ML models, Leveraging Spark’s distributed environment |
3) Apache Spark Training Programs & Courses:
IBM (Coursera): Introduction to Big Data with Spark and Hadoop
╰➤ Training Details
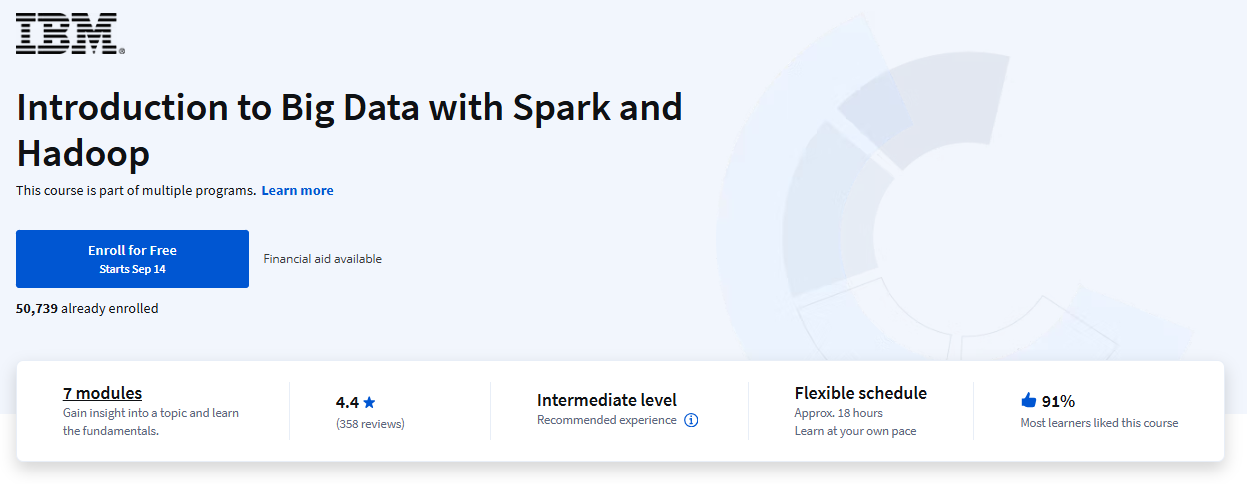
The Introduction to Big Data with Spark and Hadoop course is offered by IBM on the Coursera platform, targeting intermediate learners. This course delves into essential concepts and tools related to big data analytics and is designed to be self-paced, allowing completion in approximately 5 to 13 hours, depending on individual learning speed. It is part of several professional programs, including the IBM Data Engineering Professional Certificate and the NoSQL, Big Data, and Spark Foundations Specialization.
╰➤ Modules
The course consists of 7 comprehensive modules that cover various aspects of big data, Hadoop, and Spark:
1) Introduction to Big Data
- Definition and characteristics of big data
- Impact of big data on business and personal tasks
- Overview of big data tools and ecosystems
2) Introduction to Hadoop
- Hadoop architecture and ecosystem
- Key components: HDFS, MapReduce, Hive, and HBase
- Hands-on labs to query data using Hive and run MapReduce jobs
3) Introduction to Apache Spark
- Overview of Spark and its architecture
- Benefits of using Spark for big data processing
4) Parallel Programming with Resilient Distributed Datasets (RDDs)
- Basics of parallel programming
- Working with RDDs and their significance in Spark
5) DataFrames and SparkSQL
- Introduction to DataFrames and their operations
- Using SparkSQL for data manipulation
6) Development and Runtime Environment Options
- Running Spark applications
- Configuration settings and options for Spark
7) Monitoring & Tuning
- Techniques for monitoring Spark applications
- Performance tuning strategies for optimizing Spark jobs
╰➤ Prerequisites
No strict requirements are in place for enrollment, but you'll get a lot more out of it if you already know the basics of Python, SQL, and Data engineering.
╰➤ Exam Structure
The course includes various assessments, such as quizzes and hands-on labs, to evaluate learners' understanding of the material. There is no formal exam structure; instead, learners are assessed through graded assignments and practical exercises integrated within each module.
╰➤ Validity
Upon successful completion of the course, participants receive a certificate that can be shared on professional platforms like LinkedIn. The course does not impose a specific validity period for the certificate, but the skills acquired can be applied immediately in relevant job roles.
╰➤ Cost
The course is offered for free, although a fee may be required for obtaining a certificate upon completion. Coursera typically provides options for financial aid or subscription plans, which may influence the overall cost for learners seeking certification.
IBM (Coursera): Scalable ML on Big Data using Apache Spark
╰➤ Training Details
The Scalable Machine Learning on Big Data using Apache Spark course is offered by IBM on the Coursera platform. This online course is designed to equip learners with the skills necessary to apply machine learning techniques to large datasets using Apache Spark. It is an intermediate-level course that requires ~6 hours to complete.

╰➤ Modules
The course is structured into 4 main modules, covering the following topics:
1) Introduction to Apache Spark for Machine Learning on Big Data
- Overview of Apache Spark and its importance in handling big data.
- Introduction to Resilient Distributed Datasets (RDDs) and DataFrames.
2) Big Data and Data Storage Solutions
- Understanding what constitutes big data.
- Exploring various data storage solutions and their implications for processing.
3) Parallel Data Processing Strategies
- Learning about parallel programming and functional programming concepts.
- Implementing parallel data processing using Apache Spark.
4) Machine Learning with Apache Spark
- Applying machine learning algorithms using SparkML Pipelines.
- Techniques for optimizing performance and avoiding out-of-memory errors.
Each module includes video lectures, readings, and quizzes to reinforce learning.
╰➤ Prerequisites
To enroll in this course, participants should have:
- Basic knowledge of Python programming.
- Understanding of machine learning concepts.
- Familiarity with SQL for data manipulation.
╰➤ Exam Structure
The evaluation process includes:
- Quizzes: There are 11 quizzes throughout the course to assess understanding of the material.
- Final Assessment: A comprehensive final test at the end of the course to evaluate the knowledge gained.
Students must pass these assessments to receive a verified certificate.
╰➤ Validity
The course is available on Coursera with flexible deadlines, allowing learners to progress at their own pace. Once enrolled, students can access the course material indefinitely. However, the verified certificate must be completed within a specified timeframe to be awarded.
╰➤ Cost
The course is offered for free during a 7-day trial period. After this period, learners must pay a fee to obtain a verified certificate. The exact cost may vary based on promotions or subscription plans offered by Coursera.
LinkedIn Learning: Advance Your Data Skills in Apache Spark
╰➤ Training Details
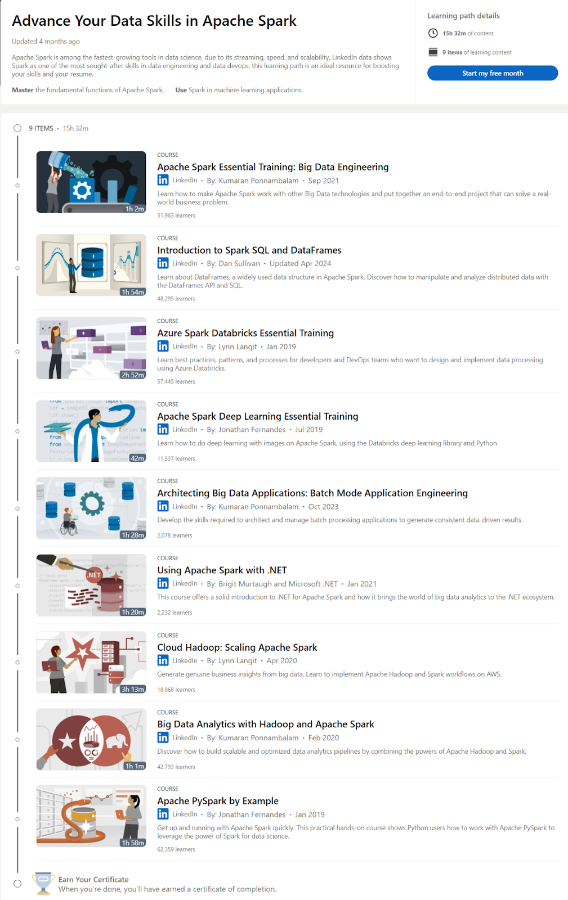
The Advance Your Data Skills in Apache Spark learning path on LinkedIn Learning is designed to help professionals enhance their skills in Apache Spark, a rapidly growing tool in data science. The path consists of several courses that cover various aspects of Apache Spark, including its fundamental functions, machine learning applications, and more.
╰➤ Modules
The learning path includes the following courses:
- Apache Spark Essential Training: Big Data Engineering (1h 2m)
- Introduction to Spark SQL and DataFrames (1h 54m)
- Azure Spark Databricks Essential Training (2h 52m)
- Apache Spark Deep Learning Essential Training (42m)
- Architecting Big Data Applications: Batch Mode Application Engineering(1h 28m)
- Using Apache Spark with .NET (1h 20m)
- Cloud Hadoop: Scaling Apache Spark (3h 13m)
- Big Data Analytics with Hadoop and Apache Spark (1h 1m)
- Apache PySpark by Example (1h 58m)
╰➤ Prerequisites
To maximize learning from this learning path, students are expected to have the following prerequisite skills:
- Familiarity with the basics of Apache Spark and the ability to set up code and deploy applications with Spark
- Familiarity with structured streaming and SQL capabilities for Apache Spark
- Familiarity with Java concepts, programming, and Maven builds
- Knowledge of third-party data stores like Kafka, MariaDB, and Redis
- Knowledge of Docker operations for deploying and using data stores
╰➤ Exam Structure
There is no specific exam associated with this learning path. However, upon completion, learners will receive a certificate of completion that can be shared on their LinkedIn profile under the "Licenses and Certificates" section.
╰➤ Validity
The learning path and its associated courses are available indefinitely on LinkedIn Learning. Learners have access to the course materials for as long as they maintain their LinkedIn Learning subscription.
╰➤ Cost
The cost of the learning path depends on the subscription plan chosen. LinkedIn Learning offers various subscription options, including monthly and annual plans. Pricing may vary by region and is subject to change. You can check the current pricing on the LinkedIn Learning website.
Udemy: Taming Big Data with Apache Spark and Python - Hands On!
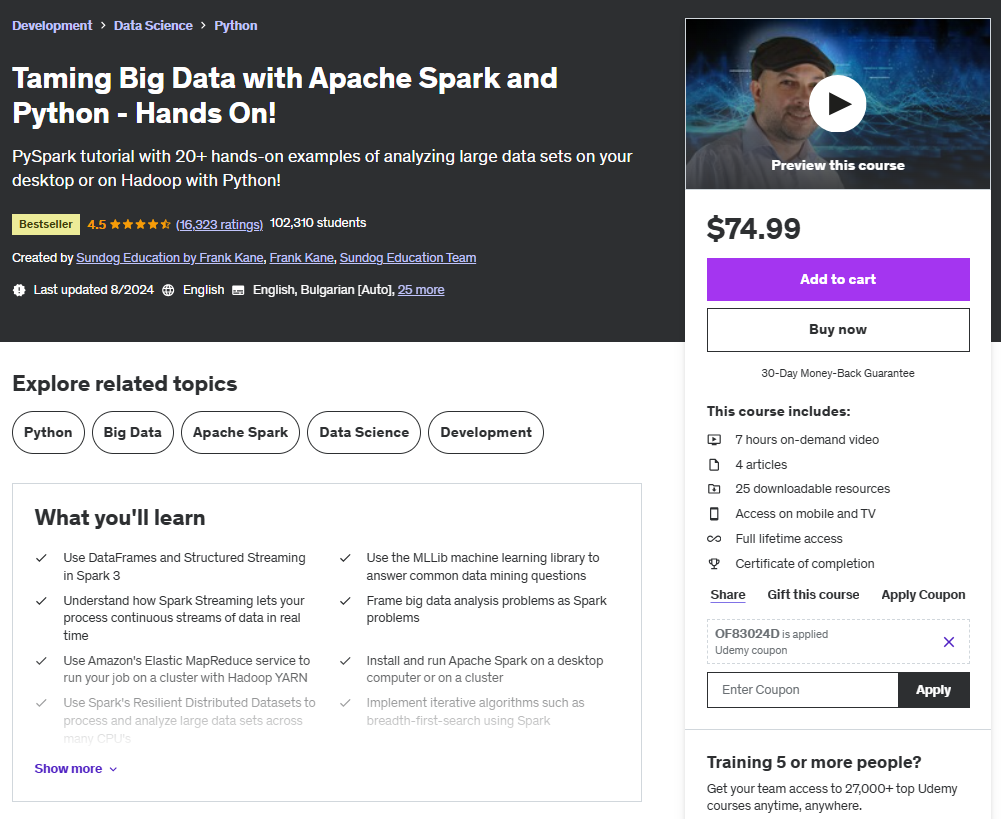
╰➤ Training Details
The course, Taming Big Data with Apache Spark and Python - Hands On!, is specifically designed to equip learners with practical skills for big data analysis using Apache Spark. Aimed at individuals with a software development background, the course helps participants dive into big data technologies and apply Spark to real-world use cases.
The training includes approximately 7 hours of on-demand video content, offered entirely online to accommodate learners' varied schedules. Participants have the flexibility to learn at their own pace and receive a certificate of completion upon finishing the course. Additionally, lifetime access to course materials and updates ensures that learners can continue to benefit from the content long after the course is completed.
╰➤ Modules
The course is structured into several key modules, which include:
1) Getting Started with Spark
- Introduction to the course and Spark installation (Python, JDK, Spark, and dependencies).
- Running initial Spark programs.
2) Spark Basics and Simple Examples
- Overview of Spark 3 features.
- Introduction to Resilient Distributed Datasets (RDDs) and basic examples.
- Activities include filtering RDDs and counting word occurrences.
3) Advanced Examples of Spark Programs
- Finding popular movies and superheroes using Spark.
- Implementing collaborative filtering and breadth-first search algorithms.
4) Running Spark on a Cluster
- Introduction to Elastic MapReduce and setting up AWS accounts.
- Practical exercises on partitioning and managing dependencies.
5) Machine Learning with Spark ML
- Introduction to MLLib
- Practical examples of using Spark ML to Produce Movie Recommendations
6) Spark Streaming, Structured Streaming, and GraphX
- Overview of how Spark Streaming works
- Example of Spark structured streaming in Python
The course incorporates over 20 hands-on examples, allowing learners to apply concepts in real-world scenarios.
╰➤ Prerequisites
- Technical Background: Prior programming experience, particularly in Python, is recommended.
- Hardware Requirements: Access to a personal computer (Windows, Linux, or Mac) is necessary for running Spark.
╰➤ Exam Structure
While the course does not include a formal exam, learners are encouraged to complete various exercises and activities throughout the modules to reinforce their understanding. These activities serve as practical assessments of their skills.
╰➤ Validity
The course content is regularly updated to reflect the latest developments in Apache Spark, particularly focusing on Spark 3 and its features. Enrollees enjoy lifetime access to course materials, allowing for ongoing reference.
╰➤ Cost
The course is priced at approximately $74.99.
Datacamp: Introduction to PySpark
╰➤ Training Details
The Introduction to PySpark course offered by DataCamp is designed to provide learners with a foundational understanding of using PySpark for big data processing and machine learning. Spanning approximately 4 hours, the course combines theoretical instruction with practical, hands-on exercises. Participants will learn to implement distributed data management and machine learning in Spark using the PySpark package, which integrates seamlessly with Python.

╰➤ Modules
The course is structured into several key modules that cover the following topics:
- Getting Started with PySpark: Introduction to the PySpark environment and its capabilities.
- Data Manipulation: Techniques for reading, writing, and manipulating data using PySpark DataFrames.
- Data Wrangling: Practical skills for cleaning and preparing data for analysis.
- Machine Learning Pipelines: Building and tuning machine learning models using PySpark's MLlib library.
- Case Study: Applying learned skills to a real-world scenario, such as predicting flight delays based on historical data.
Each module includes interactive coding challenges and exercises to reinforce learning and ensure practical application of concepts.
╰➤ Prerequisites
This course is perfect for beginners, but it helps if you already know the basics of Python programming. It's also a plus if you're familiar with data science concepts and have used Python for data manipulation (with libraries like Pandas), but it's not necessary.
╰➤ Exam Structure
The course doesn't have a traditional exam setup. Learners are assessed with interactive exercises and projects that are part of the course. These assessments let participants apply what they've learned in real-life scenarios and get instant feedback on how they're doing.
╰➤ Validity
The course content is available to learners as long as they maintain an active subscription to DataCamp. Upon completion, participants can download a certificate of completion, which can be shared with potential employers or added to professional profiles.
╰➤ Cost
DataCamp operates on a subscription model. The cost for individual access to the course is approximately $29 per month, billed annually at around $84 ($7 per month) but the cost of every first chapter is free. This subscription provides access to the entire DataCamp library, including all courses, projects, and certifications, making it a cost-effective option for those looking to expand their data science skills comprehensively.
Duke University: Spark, Hadoop, and Snowflake for Data Engineering
╰➤ Training Details
Duke University's course, Spark, Hadoop, and Snowflake for Data Engineering, is crafted to teach learners to build scalable data pipelines and optimize workflows with top industry tools. Ideal for those seeking to enhance their data engineering skills, the course focuses on popular platforms like Apache Spark, Hadoop, and Snowflake. This 29-hour course on Coursera allows learners to set their own pace.
╰➤ Modules
The course consists of four comprehensive modules:
1) Overview and Introduction to PySpark:
- Covers big data platforms like Hadoop and Spark.
- Introduces concepts such as Resilient Distributed Datasets (RDD), Spark SQL, and PySpark DataFrames.
2) Snowflake Fundamentals:
- Explores Snowflake's architecture, layers, and web interface.
- Teaches how to create and manage tables, warehouses, and utilize Python connectors.
3) Azure Databricks and MLFlow:
- Focuses on using Databricks for data analytics and machine learning.
- Covers MLOps and the MLFlow framework for managing machine learning workflows.
4) DataOps and Operations Methodologies:
- Introduces methodologies like Kaizen, DevOps, and DataOps.
- Emphasizes continuous integration and deployment practices.
╰➤ Prerequisites
- Basic Programming Knowledge: Familiarity with Python is recommended.
- Experience with Data Engineering Tools: Prior exposure to Git for version control, Docker for containerization, and Kubernetes for deployment is beneficial but not mandatory.
╰➤ Exam Structure
The course has 21 quizzes that check learners' knowledge of each module's material. There aren't any final exams - assessments are actually part of the course through quizzes and hands-on labs.
╰➤ Validity
Once you're done, you'll get a certificate from Duke University that you can show off on LinkedIn and put on your resume.
╰➤ Cost
The course is offered for free, although there may be a fee for obtaining the certification upon completion. Coursera often provides options for financial aid or subscription plans, which may affect the overall cost for learners seeking certification.
Pluralsight: Apache Spark Fundamentals
╰➤ Training Details
The Apache Spark Fundamentals course on Pluralsight is a great way to get a solid grasp of Apache Spark. If you need to efficiently process huge datasets, this course is especially useful, as it teaches you how to leverage Spark's performance benefits over traditional frameworks like Hadoop. Taught by Justin Pihony, the course emphasizes hands-on skills to help you become proficient in using Spark for big data processing. The course is around 4.15 hours long, requiring a decent time commitment. You can find it on Pluralsight as part of their paid subscription service, with the added benefit of accessing the content at your convenience - perfect for busy professionals who prefer flexible learning options.

╰➤ Modules
The course is structured into several key modules, each focusing on different aspects of Apache Spark:
1) Introduction to Apache Spark
- Overview of Spark's history and architecture
- Understanding the Spark UI and essential libraries
2) Core Concepts
- Introduction to Resilient Distributed Datasets (RDDs)
- Working with DataFrames and SparkSQL
3) Cluster Management
- Techniques for managing Spark clusters effectively
4) Machine Learning with Spark
- Basics of implementing machine learning algorithms using Spark's MLlib
5) Real-World Application
- Practical project: Creating a Wikipedia analysis application to apply learned concepts
6) Setting Up Spark on AWS
- Guidance on configuring Spark in a cloud environment
╰➤ Prerequisites
To maximize the learning experience, participants should have:
- Basic programming knowledge (preferably in Scala or Python)
- Familiarity with big data concepts and distributed computing
╰➤ Exam Structure
This course skips the formal exam in favor of hands-on learning through projects and exercises. It lets learners show what they know by applying concepts to real-life situations instead of traditional testing methods.
╰➤ Validity
This course is part of a subscription service, so you can access the course materials as long as your subscription is active.
╰➤ Cost
The course is available through a paid subscription model. Pluralsight offers monthly and annual subscription options, which grant access to a wide range of courses, including the Apache Spark Fundamentals course. Specific pricing details may vary, so it's advisable to check Pluralsight's website for the most current subscription rates.
Comparison of Apache Spark Training Programs & Courses
| Apache Spark Training Program name | Provider | Course content | Prerequisites | Duration | Cost |
| Introduction to Big Data with Spark and Hadoop | IBM (Coursera) | ✦ Big data concepts
✦ Hadoop ecosystem ✦ Spark architecture and benefits ✦ RDDs, DataFrames, SparkSQL ✦ Spark configuration and tuning |
✦ Basic data engineering concepts
✦ Python ✦ SQL |
5-13 hours (self-paced) | Free (certificate may have cost) |
| Scalable ML on Big Data using Apache Spark | IBM (Coursera) | ✦ Spark for machine learning on big data
✦ Parallel data processing strategies ✦ Applying ML algorithms using SparkML |
✦ Python programming
✦ Machine learning concepts ✦ SQL |
6 hours | Free trial, then subscription |
| Advance Your Data Skills in Apache Spark | LinkedIn Learning | ✦ Spark fundamentals
✦ Spark SQL and DataFrames ✦ Spark ML applications ✦ Architecting big data apps ✦ Stream processing with Spark |
✦ Basics of Spark
✦ Structured streaming ✦ SQL ✦ Java, Maven, Docker |
21+ hours | Subscription |
| Taming Big Data with Apache Spark and Python - Hands On! | Udemy | ✦ Spark installation and setup
✦ RDDs and examples ✦ Advanced Spark programs ✦ Running Spark on clusters ✦ ML with Spark ML |
✦ Software development background
✦ Python programming |
7 hours | $74.99 |
| Introduction to PySpark | DataCamp | ✦ PySpark environment
✦ Data manipulation with DataFrames ✦ Data wrangling ✦ ML pipelines with MLlib |
- Python programming | 4 hours | Subscription ($29/month) |
| Spark, Hadoop, and Snowflake for Data Engineering | Duke University (Coursera) | - PySpark and Hadoop overview
✦ Snowflake fundamentals ✦ Azure Databricks and MLFlow ✦ DataOps methodologies |
✦ Python
✦ Git, Docker, Kubernetes |
29 hours | Free (certificate may have cost) |
| Apache Spark Fundamentals | Pluralsight | ✦ Spark architecture and libraries
✦ RDDs, DataFrames, SparkSQL ✦ Cluster management ✦ Spark ML ✦ Real-world project |
✦ Programming (Scala or Python)
✦ Big data concepts |
4.15 hours | Subscription |
Additional Resources for Learning Apache Spark
Books
- Learning Spark: Lightning-Fast Data Analytics
- Spark: The Definitive Guide: Big Data Processing Made Simple
- High Performance Spark: Best Practices for Scaling and Optimizing Apache Spark
Databricks Academy
Online tutorials and blogs
- Chaos Genius Blogs
- Medium Blogs
- Field notes for the Databricks Certified Spark Developer Exam
- Databricks Official Blogs
- Towards Data Science
YouTube videos
- Apache Spark Playlist
- Databricks Official Channel
- Databricks Playlist
- Advanced Apache Spark Training - Sameer Farooqui (Databricks)
Community forums
Save up to 50% on your Databricks spend in a few minutes!


Conclusion
Apache Spark certifications, training programs, and badges are great for data professionals who want to boost their skills and get ahead in big data processing. Getting certified by major players like Databricks, O'Reilly, and IBM shows you're an expert in Apache Spark and gives you a leg up in the job market.
In this article, we have covered:
- What is Apache Spark?
- Available Apache Spark Certifications
- Apache Spark Training Programs & Courses
- Apache Spark Badges & Credentials
- Additional Resources for Learning Apache Spark
… and so much more!
FAQs
Is there an Apache Spark certification?
Yes, there are several Apache Spark certifications available, such as the Databricks Certified Associate Developer for Apache Spark, O'Reilly Developer Certification for Apache Spark, Simplilearn's introduction to Big Data Hadoop and Spark Developer, Cloudera Certified Associate (CCA) Spark and Hadoop Developer, HDP Certified Developer (HDPCD) Spark certification and MapR Certified Spark Developer.
Which certification is best for Spark?
The best certification for you depends on your goals and experience level. The Databricks Certified Associate Developer for Apache Spark is a popular choice for beginners and intermediate users looking to showcase their proficiency in Spark DataFrame API and architecture.
What is the salary of an Apache Spark expert?
According to Glassdoor, the average base salary for an Apache Spark Developer in the United States is around $111K - $179K per year. But, salaries can vary based on factors such as location, experience, and industry.
Is Apache Spark worth learning?
Yes, learning Apache Spark is worth it for data professionals looking to advance their careers in big data processing, machine learning, and real-time data analytics. Spark's growing popularity and demand for skilled professionals make it a valuable skill to acquire.















