





























Data is often referred to as the new gold. Currently, the volume of data generated globally is experiencing unprecedented growth. Organizations rely on this data to extract valuable insights, which necessitates effective data processing. The problem is, modern datasets are huge and complex, making it tough to process and analyze them quickly. To address these challenges, Hadoop came along in 2006 as a leading framework for distributing data processing. But Hadoop had some major downsides particularly in terms of speed and real-time processing capabilities, largely due to its disk-intensive MapReduce paradigm. That's why Apache Spark was designed to fix these flaws.
In this article, we're going to peel back the layers of Apache Spark architecture—exploring its origins of Apache spark, key features, understanding its benefits, and see why it's become the go-to tool for data scientists and engineers around the world.
How Did Apache Spark Originate?
Apache Spark was born out of a necessity to address the inefficiencies of existing big data processing frameworks like Hadoop. It was developed at UC Berkeley's AMPLab (Algorithms, Machines, and People Lab) in 2009. The project aimed to create a fast and general-purpose cluster computing system that could outperform existing solutions. The primary architect of Apache Spark, Matei Zaharia, and his team developed Apache Spark as a response to the limitations of Hadoop MapReduce, particularly its inefficiency in handling iterative algorithms and interactive data processing.
In 2010, Apache Spark was open sourced under a BSD license, allowing developers worldwide to contribute to its growth. By 2013, Apache Spark joined the Apache Software Foundation, a major milestone. Soon, Apache Spark became a top-level Apache project in 2014, making it a leader in the big data ecosystem.
Save up to 50% on your Databricks spend in a few minutes!


What Is Apache Spark?
Apache Spark is an open source distributed data processing engine that enables users to perform complex data analysis across large datasets. It is designed to be fast, flexible, and easy to use, making it suitable for various applications in data science and analytics.
Key Features of Apache Spark
1) In-Memory Computing
Apache Spark's ability to store intermediate data in memory allows it to process data much faster than traditional disk-based systems. This is Spark's secret sauce.
2) Unified Analytics
Apache Spark provides a single platform for batch processing, real-time streaming, machine learning, and interactive queries, reducing the need for multiple tools.
3) Support for Multiple Languages (Polyglot Programming)
Apache Spark supports several programming languages, including Java, Scala, Python, and R, making it accessible to a wide range of developers.
4) Built-in Libraries
Apache Spark comes with a rich set of built-in libraries that cater to various data processing needs:
These libraries are tightly integrated into the Spark ecosystem, which guarantees seamless interoperability and high performance.
5) Fault Tolerance
Apache Spark's fault tolerance is achieved through a concept known as Resilient Distributed Datasets (RDDs). RDDs are immutable collections of objects that can be distributed across a cluster. If a partition of an RDD is lost due to node failure, Spark can automatically recompute it using the lineage information stored for each RDD, guaranteeing that the system remains robust even in the face of hardware failures.
6) Lazy Evaluation
Apache Spark doesn't execute your commands immediately. Instead, it creates a logical plan and waits until an action operation explicitly triggers computation.
7) Advanced DAG Execution Engine
Under the hood, Apache Spark uses a Directed Acyclic Graph (DAG) to represent your data processing workflow. This allows it to optimize complex chains of operations.
TL;DR: Apache Spark is a powerful, flexible, and user-friendly engine for processing big data. It's designed to be fast, scalable, and versatile, capable of handling a wide range of data processing tasks that would make traditional systems struggle.
Check out this video if you want to learn more about Apache Spark in depth.
What is Apache Spark?
What Is Apache Spark Used For?
Apache Spark's versatility makes it suitable for a wide range of applications in data processing and analytics. Here are some of the most common use cases:
1) Big Data Analytics
Apache Spark excels in processing large datasets quickly and efficiently. Its in-memory processing capabilities allow for faster analysis compared to traditional systems, making it ideal for big data analytics tasks such as aggregation, filtering, and transformation of data.
2) Machine Learning at Scale
Apache Spark's MLlib library provides a scalable machine learning framework suitable for large-scale machine-learning operations. It supports a wide range of techniques, including classification, regression, clustering, and collaborative filtering, and is easily linked with other machine-learning frameworks.
3) Real-time Stream Processing
Apache Spark’s Structured Streaming (and the legacy Spark Streaming) allow for real-time processing of data streams. This is crucial for applications like fraud detection, real-time monitoring, and dynamic pricing, where timely data processing is essential.
4) Interactive Data Analysis
Apache Spark provides tools like Spark SQL and DataFrames, which enable interactive data analysis. This is particularly useful for exploratory data analysis, where users need to quickly run queries and inspect results to guide their analysis.
5) ETL (Extract, Transform, Load) Operations
Apache Spark is widely used for ETL processes, where data is extracted from various sources, transformed to fit the desired format, and loaded into a data warehouse or data lake. Its ability to handle large datasets and perform complex transformations makes it a popular choice for ETL workflows.
6) Graph Processing
Apache Spark's GraphX library provides a set of tools for working with graph-structured data. Imagine you're analyzing a social network to find influencers or communities. With Spark GraphX, you can run algorithms like PageRank or connected components on massive graphs with billions of edges. Or perhaps you're optimizing a supply chain network...GraphX can help you find the shortest paths or identify bottlenecks in your distribution system.
How Does Apache Spark Work?— An Overview of Apache Spark Architecture
Alright, now, it's time to pop the hood and take a look at the engine that powers Apache Spark.
Apache Spark operates on a master-worker architecture, which consists of a driver program that manages the execution of tasks across a cluster of worker nodes.
Apache Spark architecture relies on two main abstractions:
1) Resilient Distributed Datasets (RDDs)
RDDs are the fundamental data structure in Spark. They are immutable collections of objects that are distributed across the cluster. RDDs can be created from data in storage (such as HDFS or S3) or from existing RDDs through transformations. RDDs support fault tolerance by tracking lineage information, allowing Spark to recompute lost partitions if necessary.
2) Directed Acyclic Graph (DAG)
Apache Spark architecture relies on DAG to represent the sequence of transformations applied to RDDs. When a user submits a Spark application, the system constructs a DAG of stages and tasks. The DAG scheduler then divides the DAG into stages, each consisting of multiple tasks that can be executed in parallel. This DAG-based approach allows Spark to optimize the execution plan and improve performance.
Brief Overview of Apache Spark Architecture and Components
1) Driver Program
The Driver Program is the central coordinator of a Spark application. It contains the SparkContext, which is the entry point to Spark's execution environment. The driver program:
- Translates your apps logical plan into a physical execution plan, which is then divided into stages and tasks.
- Coordinates with the Cluster Manager to schedule tasks across executors.
- Monitors and manages the overall execution of your Spark job.
2) Cluster Manager
The Cluster Manager is responsible for allocating resources (such as CPU and memory) across the cluster. Spark can run on various cluster managers, including:
- Standalone — Spark’s built-in cluster manager.
- YARN — The resource management layer for Hadoop.
- Apache Mesos — A general-purpose cluster manager.
- Kubernetes — For deploying Spark in containerized environments.
The cluster manager decides which worker nodes your application gets to use.
3) Executors
Executors are worker processes that run on worker nodes. Each executor is responsible for executing the tasks (a unit of work assigned to one executor) assigned to it by the driver and reporting the results back to the driver. Executors also store cached data in memory or on disk, depending on the application's requirements, and handle shuffle operations.
4) Worker Nodes
Worker nodes are the machines in the cluster where executors run. Each worker node can host multiple executors, and the tasks are distributed among these executors for parallel processing.
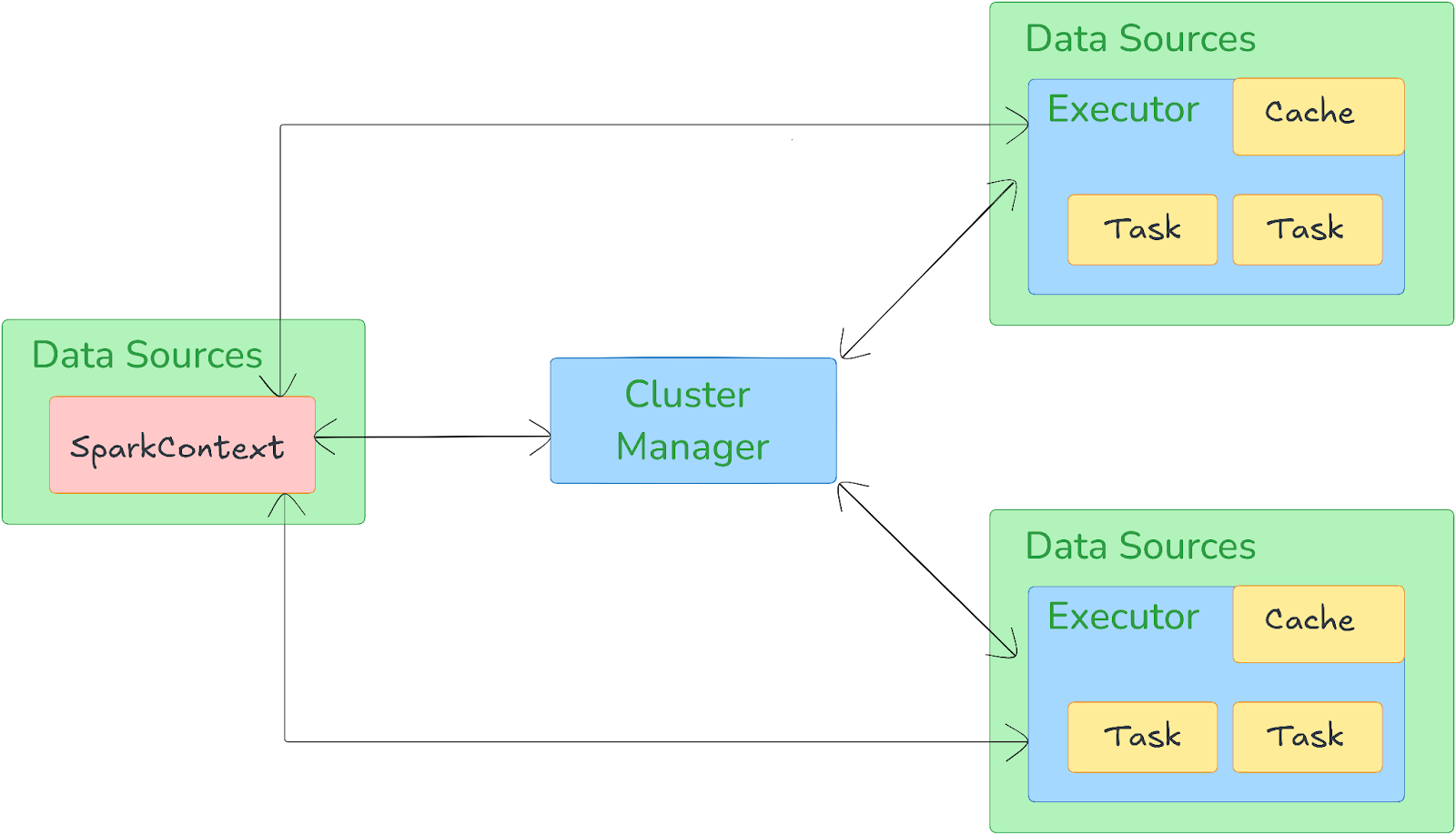
Execution Flow of a Spark Application
➥ App Submission
When a user submits a Spark application, the driver program is launched. The driver communicates with the cluster manager to request resources for the application.
➥ Job Creation and DAG Creation
The driver translates the user's code into a logical execution plan, which is then optimized and transformed into a physical execution plan. This physical plan is represented as a DAG of stages, with each stage comprising multiple tasks.
➥ Stage Division and Task Scheduling
The DAG scheduler divides the DAG into stages, each containing multiple tasks. The task scheduler assigns tasks to executors based on the available resources and data locality.
➥ Task Execution on Worker Nodes
Executors run the tasks on the worker nodes, process the data, and return the results to the driver. The driver aggregates the results and presents them to the user.
Throughout this process, Spark uses several optimizations:
- Lazy Evaluation: Apache Spark doesn't process data until absolutely necessary, building an optimized plan first.
- Data Locality: Apache Spark tries to perform computations as close to the data as possible, minimizing data movement across the network.
- In-memory Computing: Apache Spark keeps intermediate results in memory when possible, avoiding costly disk I/O.
- Speculative Execution: If a task is running slowly, Apache Spark can launch a duplicate task on another node and use the result from whichever finishes first.
This architecture allows Spark to process massive amounts of data in a distributed, fault-tolerant manner.
What Are the Benefits of Apache Spark?
Apache Spark offers numerous benefits that make it a compelling choice for big data processing. Here are some of the key advantages of Apache Spark:
1) Speed—Up to 100x Faster Than Hadoop
Apache Spark's in-memory computing capabilities allow it to process data much faster than traditional disk-based systems like Apache Hadoop. This speed advantage is particularly noticeable in iterative algorithms and interactive queries.
2) High-Level APIs in Java, Scala, Python, and R
Apache Spark provides high-level APIs in multiple programming languages, making it accessible to a wide range of developers. These APIs simplify the development process and allow users to work in their preferred language.
3) Versatility
Apache Spark’s unified framework supports a variety of data processing tasks, including batch processing, real-time streaming, machine learning, and graph processing. This versatility allows users to manage all their data processing needs within a single platform.
4) Real-Time Processing
With Structured Streaming and the legacy Spark Streaming, Spark supports real-time data processing, enabling applications to handle live data streams and make real-time decisions.
5) Scalability and Fault Tolerance
Apache Spark’s architecture is designed to scale horizontally, allowing it to handle large datasets across a cluster of nodes. Its fault tolerance is achieved through RDD lineage, which ensures that data can be recomputed if partitions are lost.
6) Extensive Library Support
Apache Spark includes a rich set of built-in libraries for various data processing needs, including Spark SQL for querying structured data, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for real-time data streams.
What Are Apache Spark Workloads?
Apache Spark is designed to handle various types of workloads, each tailored to specific data processing needs. Here’s a breakdown of the main workloads that Spark supports:
1) Batch Processing with Spark Core
Apache Spark Core is the platform's foundation, managing memory, fault recovery, job scheduling, and interaction with storage systems. It provides a set of application programming interfaces (APIs) for Java, Scala, Python, and R, which simplify distributed processing with high-level operators.
2) Machine Learning with MLlib
MLlib is Apache Spark's machine learning library, offering a scalable suite of algorithms for large-scale data analysis. Data scientists can leverage MLlib's algorithms through Spark's APIs (PySpark, SparkR, Scala, Java) to train machine learning models on large datasets, including those stored in Hadoop-compatible file systems. These models can then be saved and integrated into various applications. Spark's design allows for fast, in-memory computation, enabling quick execution of various algorithms, including classification, regression, clustering, and pattern mining.
3) Near Real-Time Processing with Structured Streaming
Spark Structured Streaming (the modern API, building upon the legacy Spark Streaming) provides low-latency, near real-time data processing by utilizing Spark Core's efficient scheduling. It processes data in micro-batches, enabling developers to use the same DataFrame/Dataset API for both batch and streaming analytics. Structured Streaming can ingest data from a wide array of sources like Kafka, Kinesis, files (HDFS, S3), and sockets.
4) Interactive Queries with Spark SQL
Spark SQL is a distributed query engine that enables low-latency, interactive queries, often up to 100x faster than traditional MapReduce. It features a cost-based optimizer, columnar storage, and code generation for efficient querying. Users can query data using standard SQL or Hive Query Language, with support for various data sources such as JDBC, ODBC, JSON, HDFS, Hive, ORC, and Parquet. Also, data stores like Amazon Redshift, Amazon S3, and MongoDB are also supported through the Spark Packages ecosystem.
5) Graph Processing with GraphX
GraphX is Spark's framework for distributed graph processing. It allows users to perform ETL (Extract, Transform, Load), exploratory analysis, and iterative computations on graph data. GraphX offers a flexible API and a variety of distributed graph algorithms, making it suitable for large-scale graph processing tasks.
What Is Apache Spark vs Hadoop?
This is the age-old question in the big data world: Apache Spark or Apache Hadoop? It's like asking whether you prefer coffee or tea - both have their merits and often the answer is "it depends". Let's break down the differences between these two big data heavyweights.
| Apache Spark | Apache Hadoop |
| Processing speed of Apache Spark is faster due to in-memory processing | Processing speed of Apache Hadoop is slower, as it relies on disk storage |
| Apache Spark supports both batch and real-time processing | Apache Hadoop primarily focuses on batch processing |
| It is user-friendly and supports multiple programming languages | Apache Hadoop is more complex and primarily uses Java |
| Apache Spark uses Resilient Distributed Datasets (RDD) for fault tolerance | Apache Hadoop has built-in fault tolerance through data replication |
| The cost of running Apache Spark is higher because it uses more RAM | Apache Hadoop is generally lower in cost due to its reliance on disk storage |
| Apache Spark is scalable on clusters | Apache Hadoop is highly scalable as well |
| It provides low latency processing capabilities | Apache Hadoop is designed for high latency processing |
| Apache Spark works well with Hadoop and other systems for data processing | Apache Hadoop works with its own Hadoop Distributed File System (HDFS) |
| Apache Spark supports near real-time processing | Apache Hadoop does not support real-time processing |
| Apache Spark provides MLlib for machine learning tasks | Apache Hadoop requires Apache Mahout for machine learning capabilities |
| Apache Spark supports interactive queries | Apache Hadoop is not designed for interactive processing |
| Resource management in Apache Spark can be done through standalone, YARN, or Mesos | Apache Hadoop primarily uses YARN for resource management |
| Apache Spark supports multiple languages including Scala, Java, Python, R, and SQL | Apache Hadoop primarily supports Java, with some support for Python |
Which Is Better Spark or Hive?
Now, let's tackle another common comparison in the big data world: Apache Spark vs Apache Hive. This is a bit like comparing a Swiss Army knife to a really good can opener. Both are useful, but they're designed for different purposes.
| Apache Spark | Apache Hive |
| Apache Spark is an analytics framework designed for large-scale data processing, providing high-level APIs in languages like Java, Python, Scala, and R. It excels in in-memory processing, enabling it to perform complex analytics significantly faster than traditional systems | Apache Hive is a distributed data warehouse system built on top of Hadoop, designed for managing and querying large datasets using a SQL-like interface known as HiveQL. It organizes data in tables and is optimized for batch processing |
| Apache Spark can process data up to 100x faster in memory and 10x faster on disk compared to Hadoop. It efficiently handles real-time data analytics and supports various libraries for machine learning, graph processing, and stream processing | Apache Hive's performance is slower due to its reliance on disk-based storage and the overhead of MapReduce. It is not ideal for real-time analytics but is effective for batch processing and ad-hoc queries on large datasets |
| Apache Spark offers Spark SQL, which is also SQL-like, but it also provides programmatic APIs in Scala, Java, Python, and R | Apache Hive uses HiveQL, which is very similar to SQL. If you're comfortable with SQL, you'll find Hive easy to use |
| Apache Spark's architecture allows it to perform operations in memory, which reduces the number of read/write operations on disk, making it suitable for iterative algorithms and complex computations | Apache Hive operates on Hadoop's HDFS and is optimized for read-heavy operations. It is primarily used for data warehousing tasks and does not support real-time data processing efficiently |
| Apache Spark supports multiple programming languages and integrates seamlessly with various data sources, including NoSQL databases. It is designed for high-speed analytics and can handle unstructured data | Apache Hive is mainly used for structured data and requires data to be in a tabular format. It does not support real-time streaming or complex data processing tasks as effectively as Spark |
| Apache Spark can handle both batch and real-time data processing, making it suitable for a wide range of applications, including streaming data analytics | Apache Hive is primarily used for batch processing and is not designed for real-time analytics, making it less suitable for scenarios requiring immediate data insights |
| Apache Spark is more memory-intensive and can lead to higher hardware costs due to its in-memory processing capabilities. It is ideal for scenarios where speed and performance are critical | Apache Hive is more cost-effective in terms of memory usage but can become expensive when processing large datasets due to its slower performance. It is better suited for environments where data is processed in large batches rather than in real-time |
| Apache Spark is developed and maintained by the Apache Software Foundation. It has grown in popularity because to its speed and versatility in large data analytics | Apache Hive was originally developed by Facebook and later contributed to the Apache Software Foundation. It is now widely used in data warehousing solutions across a variety of sectors |
So, which one should you use?
Use Apache Hive when:
- You have mostly structured data.
- Your primary users are comfortable with SQL.
- You're mainly doing batch processing or data warehousing.
- You need a data warehousing solution that integrates tightly with Hadoop's storage.
Use Apache Spark when:
- You need to process a variety of data types (structured, semi-structured, unstructured).
- You require near real-time processing capabilities.
- You're doing iterative processing, complex computations, or machine learning.
- You need more programming flexibility beyond SQL.
- You want a unified engine for various data processing tasks.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Conclusion
And that’s a wrap! Apache Spark has become a go-to tool for handling massive amounts of data. It's way better than old-school batch-processing systems. Spark's superpower is that it can process data in memory, which makes it fast. It's also a one-stop shop for all your data needs, and it can handle various tasks. That's why it has become an attractive choice for organizations dealing with large-scale data.
In this article, we have covered:
- How Apache Spark originated
- What Apache Spark is
- What Apache Spark is used for
- How Apache Spark works: An overview of Apache Spark architecture
- The benefits of Apache Spark
- Apache Spark workloads
- Apache Spark vs Hadoop
- Which is better—Spark or Hive?
… and so much more!!
FAQs
Who created Apache Spark?
Apache Spark was created by Matei Zaharia and his team at UC Berkeley's AMPLab.
Where was Apache Spark created?
Apache Spark was developed at UC Berkeley's AMPLab.
Who is the creator of Apache Spark?
Matei Zaharia is credited as the primary creator of Apache Spark.
What is Apache Spark used for?
Apache Spark is used for big data analytics, machine learning, near real-time stream processing, interactive data analysis, ETL operations, and graph processing.
Is Spark written in Scala or Java?
Apache Spark is primarily written in Scala, but it also provides APIs for Java, Python, and R.
What is the latest version of Apache Spark?
As of September 2025, the latest major stable version of Apache Spark is 4.0.0, released in May 2025. Apache Spark 3.5.6 is also a recent stable maintenance release in the 3.x series.
Can Spark replace Hadoop entirely?
While Spark can function independently, it is often used alongside Hadoop for storage and processing of large datasets.
Is Apache Spark difficult to learn?
Apache Spark has a moderate learning curve compared to some other big data technologies, but it is manageable with proper training and resources.
How does Spark achieve its speed?
Spark achieves its speed through in-memory processing, efficient data structures like RDDs and DataFrames/Datasets, optimized execution plans via its DAG scheduler, lazy evaluation, and whole-stage code generation.
Can Spark work with cloud storage systems?
Yes, Apache Spark can work seamlessly with various cloud storage systems like Amazon S3, Google Cloud Storage, and Azure Blob Storage.















