





























Metadata plays a crucial role in data engineering—providing context, organization, and clarity to raw data. It helps teams understand the structure and purpose of data, which in turn enhances data pipeline efficiency and usability. Without proper metadata, managing and interpreting data can be both time-consuming and prone to errors. In Databricks, one effective method to document datasets is by adding comments to table columns. These comments serve as metadata, making datasets more self-explanatory, thereby simplifying data management, maintenance, and collaboration.
In this article, we'll cover everything you need to know about the process of adding multiple column comments in Databricks. Here, you'll learn how to use SQL commands for this task, as well as a programmatic approach with PySpark. On top of that, we'll also cover the benefits of adding comments, practical steps for implementation, and address common limitations.
Why Add Comments in Databricks Tables?
Comments act as annotations to explain code or data—providing context, instructions, or documentation without altering functionality, or structure. They do not alter how the code or data operates but provide context or instructions for future reference or for other team members. Think of them as notes you leave for yourself or others to clarify why you've made certain decisions or what specific data means.
In Databricks, comments act as metadata that significantly enhance the documentation of your data assets. They make your data more understandable, manageable, and compliant with data governance standards.
Databricks supports a few commenting methods:
➥ Inline Comments — These are used in SQL, Python, Scala, and R queries to provide explanations within the code. They don't affect the data itself but help in understanding complex queries or scripts.
- In SQL, single-line comments use
--, and multi-line comments are enclosed by/* */. - Python uses
#for comments. - Scala uses
//for single-line comments and/* */for multi-line comments. - R uses
#for comments.
➥ Object Level Comments — These are metadata annotations tied directly to Databricks objects like tables, columns, schemas, and catalogs. Object-level comments reside in the Unity Catalog or Hive metastore and describe the purpose, structure, or use of specific data components.
For example, you can use the Databricks COMMENT ON statement to add a description to a column, explaining what the data represents or its purpose within the table. Similarly, comments can be added to tables with Databricks COMMENT ON TABLE, schemas with COMMENT ON SCHEMA, and catalogs with COMMENT ON CATALOG.
This article focuses on object-level comments, specifically column-level comments. We will highlight two different approaches to add them efficiently using simple and straightforward SQL commands and the more automated approach with PySpark. Also, we will dive into adding multiple random comments so you can get a thorough understanding of how to add multiple column comments in Databricks easily.
Save up to 50% on your Databricks spend in a few minutes!


Why Add Column Comments in Databricks?
Column-level comments specifically target individual table columns, serving as lightweight, embedded documentation. They help clarify ambiguous names, describe the logic or purpose behind calculated fields, and provide instant context to collaborators or downstream users without relying on external documentation.
Now, let's proceed to the practical methods for adding these comments in Databricks.
Step-by-Step Guide to Adding Multiple Column Comments in a Databricks Table
Let's get straight to business and dive into how you can add multiple column comments in a Databricks table. We'll start with a step-by-step guide on how to add multiple column comments. We will explore three different techniques:
- Technique 1—Adding Multiple Column Comments in Databricks Using SQL Commands
- Technique 2—Adding Multiple Column Comments in Databricks Using PySpark
- Advanced Example—Adding random column comments to multiple Databricks table columns
Prerequisite:
Before starting, make sure you have:
- Access to a Databricks workspace.
- Necessary permissions to modify table schemas.
- A running Databricks compute cluster where you'll execute your commands.
- Basic familiarity with SQL and Python.
🔮 Technique 1—Adding Multiple Column Comments in Databricks Using SQL Commands
Let's start with the technique of adding multiple column comments in Databricks using SQL commands. Before we dive in, there's something important to keep in mind: SQL commands work, but Databricks has a limitation—it doesn't support batch updating multiple column comments in one go. Instead, you'll need to update each column one by one, which can be a real pain for tables with lots of columns. Here's a step-by-step guide to get you started.
Step 1—Configure Databricks Environment
First thing first, start by logging into your Databricks account. Once logged in, navigate to the Workspace section in the Databricks UI. This is where you’ll manage your Databricks notebooks, clusters, and datasets.
Make sure you have the necessary permissions to access the workspace and modify table metadata.
Step 2—Set Up Databricks Compute Cluster
Now, a running Databricks compute cluster is essential for executing SQL commands in Databricks. To set up a cluster, go to the Compute tab on the left sidebar. If you don’t already have a cluster configured, click Create Cluster.
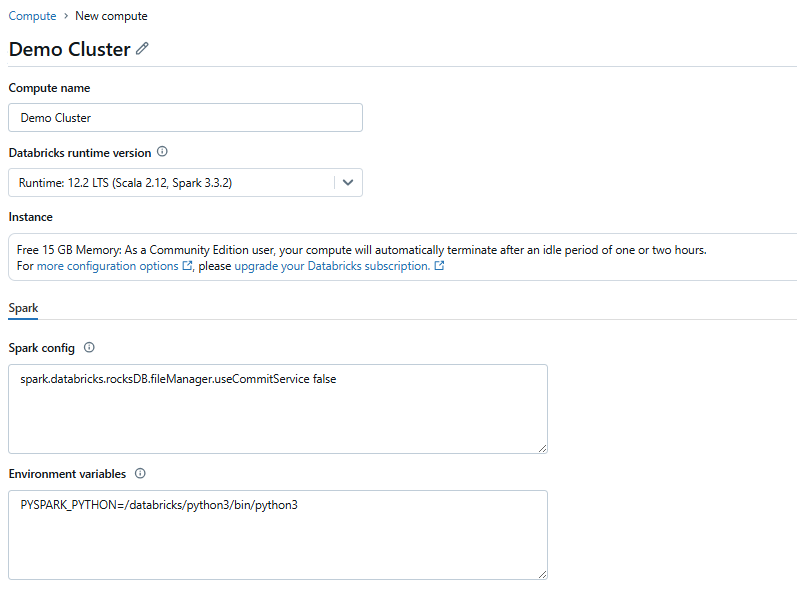
Choose the desired configurations, such as the cluster size and runtime version. Once the cluster is created, start it and make sure it remains active throughout the process.
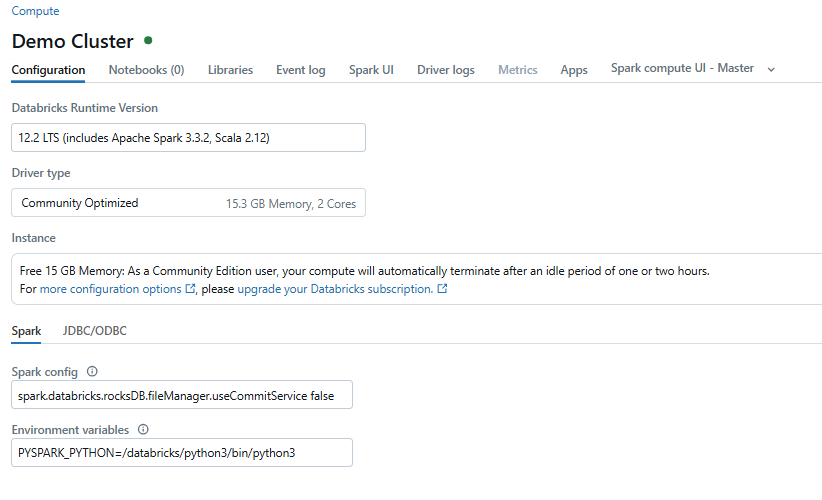
Step 3—Open Databricks Notebook
Next, create a Databricks notebook to execute your SQL commands. In the Workspace, click the + New button and select Notebook.
Choose SQL as the default language for this notebook. Name your notebook appropriately, such as Add Column Comments with SQL.
Step 4—Attach Databricks Compute to Notebook
At the top of the notebook interface, select the cluster you configured in Step 2. This step connects your notebook to the compute cluster, allowing you to run SQL commands.
Step 5—Create Databricks Table (if not already created)
If the Databricks table you want to modify doesn’t already exist, you’ll need to create it. Use the following SQL command as an example:
CREATE TABLE multi_col_comment_sql (
column1 INT,
column2 STRING,
column3 STRING,
column4 STRING,
column5 STRING,
column6 STRING,
column7 STRING,
column8 STRING
);
As you can see, this command creates a table named multi_col_comment_sql with eight columns of different data types.
Step 6—Add Databricks Comments to Columns Using Databricks COMMENT ON Statement
Databricks allows you to add comments to individual columns using the Databricks COMMENT ON statement. The syntax is as follows:
COMMENT ON COLUMN table_name.column_name IS 'Your comment here';For example:
COMMENT ON COLUMN multi_col_comment_sql.column1 IS 'This column stores integer data.';This statement adds a descriptive comment to the column column1.
Alternatively, you can use the following method as well.
Step 7—Add Columns Comment Using ALTER TABLE Command
You can make use of Databricks ALTER TABLE command to add or update the existing comments to columns. Here is how:
ALTER TABLE example_table ALTER COLUMN column1 COMMENT 'Some comment';For example:
ALTER TABLE multi_col_comment_sql ALTER COLUMN column1 COMMENT 'Updated integer column comment.';
Step 8—Add Multiple Comments Using ALTER TABLE Command
To add comments to multiple columns, execute a series of ALTER TABLE statements. For the table created earlier, you can use the following commands:
Note: Since batch updates aren't supported, you'll have to chain ALTER TABLE statements.
ALTER TABLE multi_col_comment_sql ALTER COLUMN column1 COMMENT 'Comment for column1';
ALTER TABLE multi_col_comment_sql ALTER COLUMN column2 COMMENT 'Comment for column2';
ALTER TABLE multi_col_comment_sql ALTER COLUMN column3 COMMENT 'Comment for column3';
ALTER TABLE multi_col_comment_sql ALTER COLUMN column4 COMMENT 'Comment for column4';
ALTER TABLE multi_col_comment_sql ALTER COLUMN column5 COMMENT 'Comment for column5';
ALTER TABLE multi_col_comment_sql ALTER COLUMN column6 COMMENT 'Comment for column6';
ALTER TABLE multi_col_comment_sql ALTER COLUMN column7 COMMENT 'Comment for column7';
ALTER TABLE multi_col_comment_sql ALTER COLUMN column8 COMMENT 'Comment for column8';
⚠️ Note that the following approach will not work because Databricks does not support batch updating multiple column comments in a single SQL statement:
ALTER TABLE multi_col_comment_sql
ALTER COLUMN column1 COMMENT 'Comment for column1',
ALTER COLUMN column2 COMMENT 'Comment for column2',
ALTER COLUMN column3 COMMENT 'Comment for column3',
ALTER COLUMN column4 COMMENT 'Comment for column4',
ALTER COLUMN column5 COMMENT 'Comment for column5',
ALTER COLUMN column6 COMMENT 'Comment for column6',
ALTER COLUMN column7 COMMENT 'Comment for column7',
ALTER COLUMN column8 COMMENT 'Comment for column8';Step 9—Verify Added Databricks Column Comments
Finally, to confirm that your comments were successfully added, use the DESCRIBE EXTENDED command. This command displays detailed metadata for the table, including column comments.
DESCRIBE EXTENDED multi_col_comment_sql;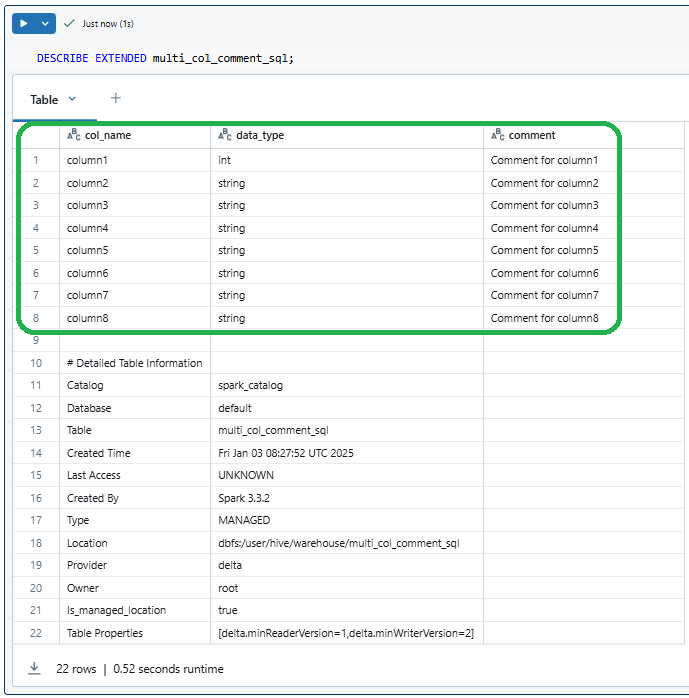
And that's it! You have successfully added multiple column comments in Databricks using SQL commands. However, note that this is a bit of a manual process currently, as Databricks does not support batch updating multiple column comments in a single SQL statement; each column must be updated individually.
Now, let's move on to the next technique, which is a more practical and programmatic way to update multiple column comments in Databricks.
🔮 Technique 2—Adding Multiple Column Comments in Databricks Using PySpark
For a more programmatic approach to adding column comments, PySpark provides flexibility and scalability. Unlike the SQL-based method, this approach is well-suited for scenarios involving dynamic column updates or larger tables. Below is a step-by-step guide to implementing this technique.
Step 1—Configure Databricks Environment
As mentioned in the previous technique, start by logging into your Databricks account. Navigate to the Workspace section, where you will manage notebooks, clusters, and datasets. Check whether you have sufficient permissions to modify metadata within your environment.
Step 2—Set Up Databricks Compute Cluster
Now, again an active compute cluster is required to execute PySpark code. To set up a cluster. Open the Compute tab from the sidebar. Click Create Cluster if no cluster is available.
Configure the cluster with the desired specifications, such as the runtime version (make sure to check it's compatible with PySpark).
Start the cluster and confirm it remains active throughout the session.
Step 3—Open Databricks Notebook
Next, head over to Workspace, click + New and select Notebook. Choose Python as the default language for this notebook, as PySpark operates within Python. Name the notebook appropriately, e.g., Add Column Comments with PySpark.
Step 4—Attach Databricks Compute to Notebook
At the top of the notebook interface, select the cluster you created in Step 2. This links the notebook to the compute resources, enabling code execution.
Step 5—Create Databricks Table (if not already created)
If you're starting anew, create your table using SQL within a PySpark session. For instance:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("AddComments").getOrCreate()
spark.sql("""
CREATE TABLE IF NOT EXISTS multi_col_comment_pyspark (
col1 INT,
column2 STRING,
column3 STRING,
column4 STRING,
column5 STRING,
column6 STRING,
column7 STRING,
column8 STRING
);
""")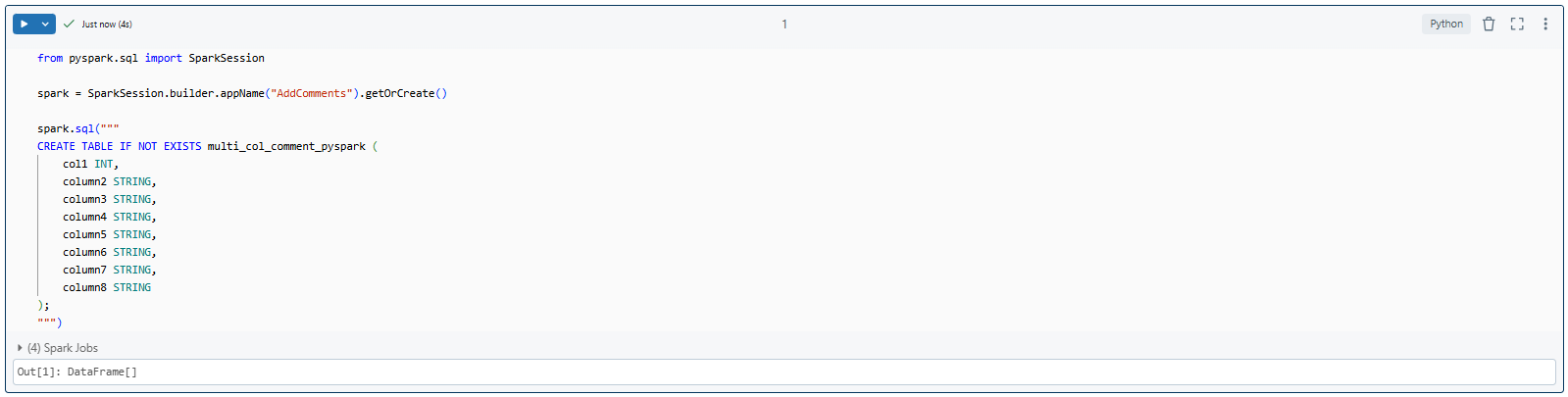
As you can see, this command creates a table named multi_col_comment_pyspark with eight columns of various data types.
Step 6—Prepare a Dictionary of Comments for Multiple Columns
In PySpark, create a dictionary that maps column names to their respective comments. This step is crucial for automating the comment-adding process.
list_of_comments = {
"col1": "Primary key identifier",
"column2": "Description of the second column",
"column3": "Another comment",
"column4": "Yet another comment",
"column5": "Fifth column commentary",
"column6": "Sixth column note",
"column7": "Seventh column explanation",
"column8": "Eighth column description"
}
Here keys are column names and values are their corresponding comments. This dictionary enables you to manage comments programmatically.
Step 7—Add Multiple Column Comments in Databricks Programmatically Using a Loop
Now this is the crucial step by using PySpark, iterate through the dictionary and execute ALTER TABLE commands for each column. Here’s the code:
for column, comment in list_of_comments.items():
spark.sql(f"""
ALTER TABLE multi_col_comment_pyspark
ALTER COLUMN {column}
COMMENT '{comment.replace("'", "''")}'
""")Note: The comment string is escaped to handle any single quotes in comments which would otherwise break the SQL syntax.

This loop dynamically applies the comments to each column in the table. The spark.sql() function runs the SQL command within PySpark, making it an efficient approach for large-scale updates.
With Error Handling:
for column, comment in list_of_comments.items():
try:
# Escape single quotes in comments
escaped_comment = comment.replace("'", "''")
spark.sql(f"""
ALTER TABLE multi_col_comment_pyspark
ALTER COLUMN {column}
COMMENT '{escaped_comment}'
""")
print(f"Successfully added comment to column: {column}")
except Exception as e:
# If an error occurs, log it and continue with the next column
print(f"Error adding comment to column {column}: {str(e)}")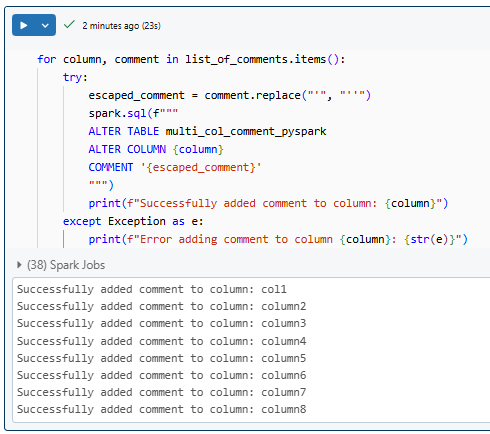
Here:
- Try Block: Attempts to execute the SQL command for adding a comment to a column.
- Except Block: If an exception occurs (e.g., column doesn't exist, permission issues), it catches the error, prints a message about which column failed, and what the error was.
Step 8—Verify Added Databricks Column Comments
Finally, to confirm that the comments were successfully added, use the DESCRIBE EXTENDED command. This command displays the table’s metadata, including column comments.
result = spark.sql("DESCRIBE EXTENDED multi_col_comment_pyspark")
result.show(truncate=False)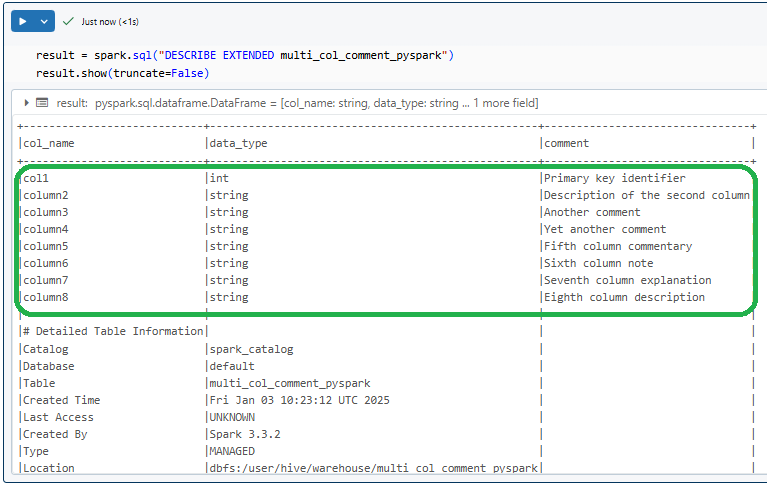
As you can see, this command will display all metadata including the comments you've added, with truncate=False to ensure full visibility of the comments.
This technique—while more complex to set up—provides a scalable solution for managing column metadata in Databricks using PySpark.
🔮 Advanced Example—Adding Random Column Comments to Multiple Databricks Table Columns
Finally let's dive into this advanced example where you’ll learn how to programmatically generate and apply random comments to multiple columns in a Databricks table. It is particularly useful for testing or simulating scenarios involving dynamic metadata updates.
Before proceeding, make sure you’ve completed the foundational steps outlined in Technique 1 and Technique 2, such as setting up your Databricks environment, creating a compute cluster, and attaching it to your notebook.
Step 1—Define Schema for the Test Databricks Table
First, lets create a schema with a large number of columns to simulate a complex table:
from pyspark.sql.types import StructType, StructField, IntegerType
# Define the number of columns for the test table
num_columns = 50
# Dynamically generate a schema with numbered columns
schema = StructType([
StructField(f"col{i}", IntegerType(), True) for i in range(1, num_columns + 1)
])
print(schema);
As you can see, this code creates a schema with 50 integer columns named col1, col2, ..., col50.
Step 2—Create a Test Databricks Table
Using the schema defined above, create an empty DataFrame and save it as a Delta table in Databricks.
# Create an empty DataFrame using the defined schema
df = spark.createDataFrame([], schema)
# Write the DataFrame as a Delta table
df.write.format("delta").mode("overwrite").saveAsTable("multi_random_col_comment")
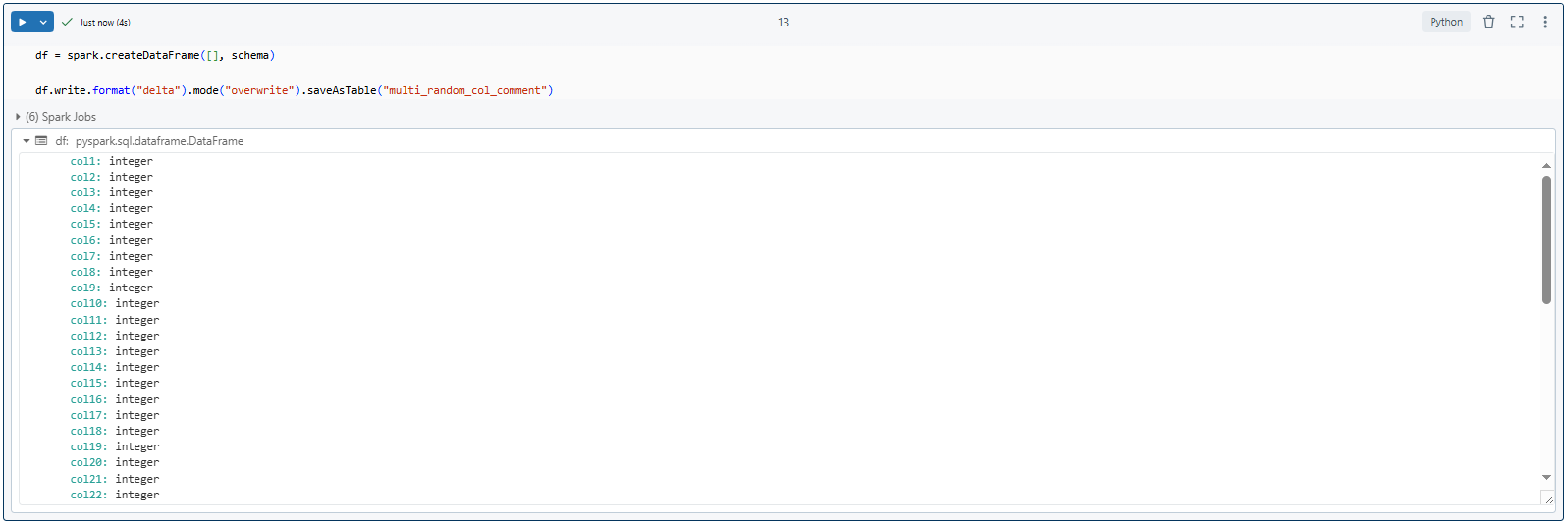
Here it creates a Delta table named multi_random_col_comment with the specified schema.
Step 3—Generate Random Comments for Columns
Now, let's generate random comments programmatically using Python’s random module. This guarantees each column has a unique, random comment.
Here is how to do it:
import random
import string
# Function to generate a random alphanumeric comment
def generate_comment():
return ''.join(random.choices(string.ascii_letters + string.digits, k=30))
# Create a dictionary mapping columns to random comments
list_of_comments = {
f"col{i}": generate_comment() for i in range(1, num_columns + 1)
}
print(list_of_comments);
You can see that this generates random 30-character alphanumeric comments for each column, stored in a dictionary.
Step 4—Apply Random Comments Programmatically
Now, use a loop (as we did in Technique 2) to iterate through the dictionary and apply the random comments to the table columns using the Databricks ALTER TABLE SQL command.
# Loop through the dictionary and apply comments
for column, comment in list_of_comments.items():
spark.sql(f"ALTER TABLE multi_random_col_comment ALTER COLUMN {column} COMMENT '{comment}'")
This programmatically updates the comments for all columns in the multi_random_col_comment table.
Step 6—Verify Added Databricks Column Comments
Finally, confirm that the comments were successfully applied by describing the table metadata.
spark.sql("DESCRIBE EXTENDED multi_random_col_comment").show(truncate=False)
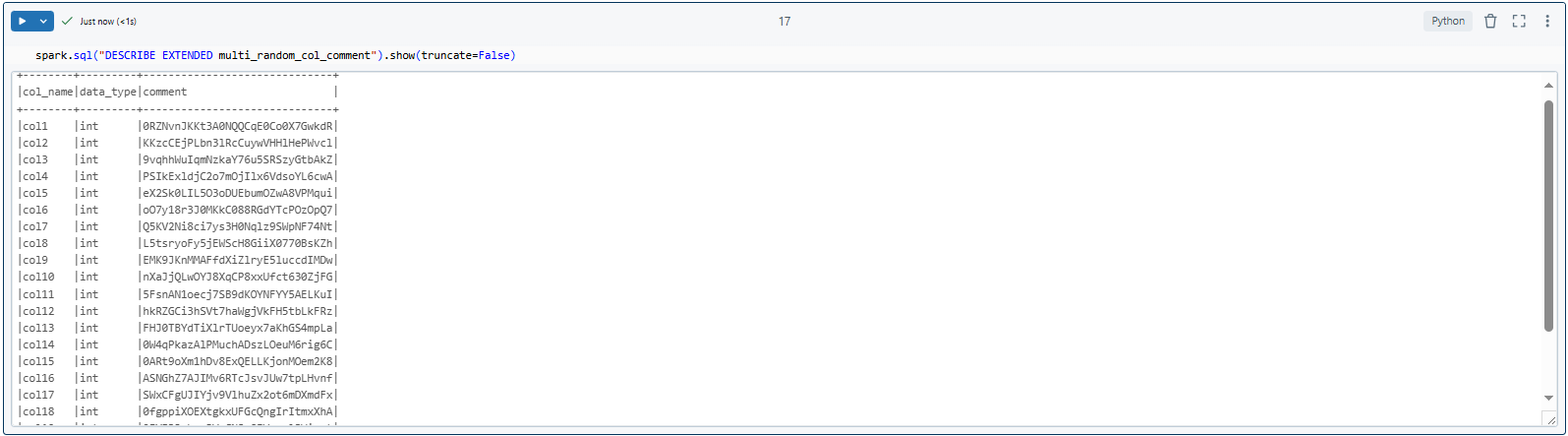
This advanced example shows how to generate and apply random comments to multiple columns in a Databricks table on the fly. It's super useful for testing and it shows off PySpark's flexibility when it comes to automating metadata updates. With some minor tweaks, you can also use it for real-world scenarios where you need to manage metadata dynamically.
Benefits of Adding Comments to Columns in Databricks Tables
Adding comments to columns in Databricks tables makes managing your data easier. Here's how it benefits you:
1) Data Documentation
Comments on columns clarify what the data represents, making cryptic names (like cust_id, cust_name or prod_qty) understandable without context. This aids collaboration where different team members access the data.
Example: A column named order_status might have a comment like "Status of the order: pending, completed, or canceled" explains the column's purpose.
2) Data Collaboration
Good comments streamline collaboration by providing immediate clarity about data structure and purpose. This cuts down on time spent explaining data, allowing more focus on analysis.
Example: A comment on conversion_rate like "The percentage of users who completed a purchase" helps everyone understand its role.
3) Streamlined Data Governance
Comments can include notes on data sensitivity, usage rights, or compliance needs, supporting governance efforts.
4) Easy Data Exploration
Comments guide you through data exploration, offering quick insights into column meanings, which is vital for navigating large datasets.
5) Easier Troubleshooting and Debugging
If data issues arise, comments provide necessary context for troubleshooting, helping you quickly identify problem areas in complex queries.
6) Better Performance Tuning and Optimization
Comments might hint at data characteristics useful for query optimization or indexing decisions, aiding performance tuning.
Limitation of Adding Multiple Column Comments in Databricks
Adding multiple column comments in Databricks comes with a few limitations:
1) No Batch Update
Databricks does not support adding comments to multiple columns in a single SQL statement. You need to execute a separate Databricks ALTER TABLE command for each column. This can become tedious for tables with many columns.
2) Performance Impact
Adding comments to numerous columns can slow down operations; each ALTER TABLE command affects metadata, potentially impacting performance.
3) Manual Process
Even with PySpark, you manually manage each comment addition, which isn't efficient for large-scale automation.
4) Error Handling
If you're scripting comments, there's a risk of errors if column names change or if there are typos in your script. You'll need to implement error handling to manage exceptions, which adds complexity to your workflow.
5) Versioning and History
Databricks doesn't track comment history like data changes. You must manually manage this if historical context is important.
6) Impact on Table Locks
Adding comments can lock tables, causing issues in high-concurrency settings where tables are frequently accessed.
7) Scalability
For very large datasets, scalability becomes an issue. While adding comments is not typically a performance bottleneck, when combined with other operations or in environments with strict performance requirements, the additional metadata operations can accumulate.
8) Metadata Overhead
Too many or overly detailed comments can bloat the metadata of your tables, potentially impacting query planning or the efficiency of metadata operations within Databricks.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Conclusion
And that's a wrap! Adding comments to columns in Databricks tables really comes in handy. It helps document what each column is for and what's inside, making your datasets easy to understand and use. As a result, you'll have a much simpler time with data management and maintenance, both for yourself and your team.
In this article, we have covered:
- Why add comments in Databricks tables?
- Why add column comments in Databricks?
- Step-by-step guide to adding multiple column comments in a Databricks table
- Benefits of adding comments to columns in Databricks tables
- Limitations of adding multiple column comments in Databricks
...and so much more!
FAQs
What are the benefits of adding comments to columns in Databricks tables?
Adding comments to columns in Databricks helps in documentation, collaboration, governance, exploration, troubleshooting, and optimization.
Can I add comments to multiple columns simultaneously in Databricks using SQL?
Not in one command, but you can chain multiple Databricks ALTER TABLE commands.
Can I add comments to columns in views within Databricks?
No, but you can comment on the source table columns, which views will inherit.
Can I programmatically add comments to multiple columns using PySpark in Databricks?
Yes, using a loop that executes Databricks ALTER TABLE commands for each column.
How can I verify that column comments have been successfully added in Databricks?
You can use DESCRIBE TABLE <table_name> or DESCRIBE EXTENDED <table_name> on your table to see all column comments.















