





























Working on intensive data tasks in Databricks? You rely on Databricks clusters to run your workloads. Think of clusters as on-demand data processing powerhouses. They're just groups of compute resources that run your jobs, notebooks, or dashboards. Each Databricks cluster gets a unique tag when it starts up—the Databricks Cluster ID. This ID is like a fingerprint, unique to each cluster, making it easy to manage, track, and identify within your workspace. Now, you might wonder why you'd need to get this ID programmatically. It's because it's essential for automating processes. You can use the Cluster ID in scripts for REST API interactions, plug it into your CI/CD pipelines, or even use it in custom monitoring tools. Automating these processes will help your data operations run more efficiently, accurately, and with far fewer mistakes.
In this article, we'll look at four distinct methods to programmatically access your Databricks Cluster ID within Databricks. We'll provide practical examples of using built-in utilities in your Databricks Notebook and calling the REST API, so you can work with your Databricks Cluster ID in a way that fits your environment.
What is a Databricks Cluster ID?
A Databricks Cluster ID is a unique identifier that Databricks assigns to each cluster instance you create. It's like a "one-of-a-kind" tag—each cluster gets its own, no matter what it's called or how it's configured. That ID is crucial for identifying and managing your clusters in Databricks.
So why do you need to get the Databricks Cluster ID programmatically? Here's why.
➥ Automation: Having the Databricks Cluster ID lets you automate tasks like starting, stopping, or resizing clusters when needed. You can set up scripts to adjust resources based on the workload, which saves time and reduces mistakes.
➥ Logging: Adding the Databricks Cluster ID to your logs allows you to track actions to specific clusters. This is useful for debugging and reviewing data activities.
➥ Monitoring: Databricks Cluster ID allows you to pull specific metrics or check the health of your clusters. Monitoring tools can alert you to performance issues, so you can respond quickly.
➥ Auditing: Knowing which cluster handled data is crucial for compliance and internal inspections. The Cluster ID in Databricks enables you to generate audit trails for data governance.
➥ Resource Management: If you manage resources like memory or CPU across multiple clusters, the Databricks Cluster ID helps you see where resources are allocated. You can adjust allocations to optimize cost or performance.
➥ Integration with CI/CD: In continuous integration and deployment (CI/CD), you can use the Cluster ID in Databricks to automate testing or deployment on specific clusters.
Now in the next section, we will dive right into how you can programmatically access Cluster ID in Databricks.
Save up to 50% on your Databricks spend in a few minutes!


Step-by-Step Guide to Programmatically Access Databricks Cluster ID (Multiple Techniques)
Let's go right into the specifics of programmatically obtaining your Databricks Cluster ID. Each technique has a specific use case, so select the one that best suits your requirements and environment. We'll cover 4 different techniques:
- Technique 1—Programmatically Access Databricks Cluster ID Using Databricks Utilities (Databricks dbutils)
- Technique 2—Accessing Apache Spark Configuration within a Databricks Notebook
- Technique 3—Programmatically Access Databricks Cluster ID Using Databricks REST API
- Technique 4—Using Databricks CLI (Command Line Interface)
Let’s dive right into it!
Prerequisite:
Before you dive in, make sure you've got these things covered:
- Databricks account and access to a Databricks workspace.
- Access to Databricks workspace with the right permissions to run Databricks Notebooks and manage clusters.
- Familiarity with Python is helpful since most of the examples use Python code. If you prefer SQL or shell scripting, similar concepts apply.
- For REST API and Databricks CLI methods, you’ll need to generate an API token from your user settings or install and configure the Databricks CLI.
- For methods that run within a Databricks Notebook (using Databricks dbutils or Apache Spark configuration), your notebook must be attached to an active interactive Databricks cluster.
Double-check these items so you have everything you need to follow along smoothly.
🔮 Technique 1—Programmatically Access Databricks Cluster ID Using Databricks Utilities (dbutils)
Prerequisite:
- Access to a Databricks workspace with a running interactive Databricks cluster.
- Make sure your Databricks Notebook is attached to the specific Databricks cluster.
Step 1—Login to Databricks
Start by logging into your Databricks workspace.
Step 2—Configure Databricks Compute
Once you’re in, you need an active Databricks compute cluster. To set this up, go to the "Compute" section on the left sidebar. If you don't have a cluster or need a new one, click on "Create Compute".
Then, customize the cluster settings according to your needs.
If the cluster isn't already running, start it.
Step 3—Open Databricks Notebook
Launch a new or existing Databricks Notebook and make sure it’s attached to your active cluster.
Step 4—Access Databricks Cluster ID via Databricks Utilities (Databricks dbutils)
Head over to your Databricks Notebook, and use the following Python snippet to retrieve the Cluster ID in Databricks:
# Retrieve the Databricks Notebook context
context = dbutils.entry_point.getDbutils().notebook().getContext()
# Access the tags and get the clusterId tag
cluster_id = context.tags().get("clusterId").get()
print(f"Databricks Cluster ID: {cluster_id}")dbutils.entry_point.getDbutils() command returns an entry point that contains the Databricks Notebook context. The context includes a set of tags that hold metadata about your cluster. One of these tags is "clusterId". Because the Databricks Notebook is attached to the cluster, Databricks dbutils knows exactly which Databricks Cluster ID to fetch.
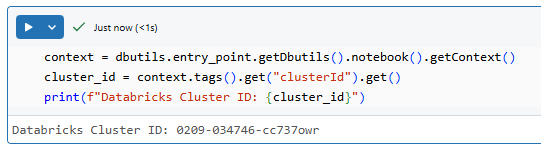
Step 5—Execute the Databricks Notebook Cell
Run the cell to see if your Cluster ID in Databricks is printed in the output.
Optional—Error Handling (Just in Case)
If you want your code to be more robust, wrap the retrieval code in a try–except block. This way, if your Databricks Notebook is detached or the tag is missing, your code will catch the error and provide a clear message instead of failing silently.
try:
context = dbutils.entry_point.getDbutils().notebook().getContext()
cluster_id = context.tags().get("clusterId").get()
print(f"Databricks Cluster ID: {cluster_id}")
except Exception as e:
print(f"Error retrieving the Databricks Cluster ID: {e}")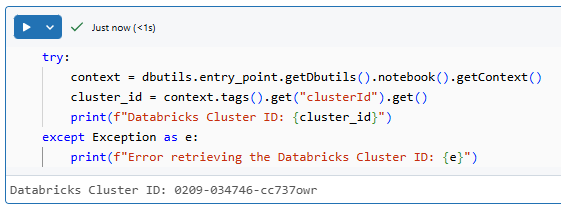
🔮 Technique 2—Accessing Apache Spark Configuration within Databricks Notebook
Now, this technique is for when you are already working with Apache Spark inside a Databricks Notebook. Apache Spark, the powerful engine underneath Databricks, holds configuration details about the environment it is running in, and guess what? That includes the Databricks Cluster ID. We can access Apache Spark configuration to get the Cluster ID in Databricks.
Prerequisite:
- Just like with Databricks dbutils method , your Databricks Notebook must be attached to the interactive cluster from which you intend to retrieve the Cluster ID in Databricks.
Step 1 to Step 3—Setup Your Databricks Environment – Same as Before
These setup steps for this technique are exactly the same as what you did for the Databricks dbutils method. If you've already gone through those steps, you can skip it. If not, no worries, let's recap:
- Step 1—Login to Databricks: Head over to your Databricks workspace in your browser and log in. Need a refresher? Check back in the "Step 1—Login to Databricks" section of the Databricks dbutils technique for a quick reminder.
- Step 2—Configure Databricks Compute: Make sure you have a running interactive Databricks cluster. Either verify an existing one is running, or create a new one. Again, if you need a step-by-step, peek at "Step 2—Configure Databricks Compute" in the Databricks dbutils section.
- Step 3—Open a Databricks Notebook: Launch a Databricks Notebook, either create a new one or open an existing one. And yes, the "Step 3—Open a Notebook" section of the Databricks dbutils guide has the details if you need them.
If you've already got your Databricks Notebook open and attached to a running cluster, then you're all set for the next step—grabbing that Databricks Cluster ID!
Step 4—Access Databricks Cluster ID from Apache Spark Configuration
Okay, with your Databricks Notebook ready and connected, here’s the magic line of code you'll use to pull the Cluster ID in Databricks using the Apache Spark configuration key spark.databricks.clusterUsageTags.clusterId. Add this snippet to your Databricks Notebook:
databricks_cluster_id = spark.conf.get("spark.databricks.clusterUsageTags.clusterId")
print(f"Databricks Cluster ID: {databricks_cluster_id}")As you can see, the code snippet retrieves the Databricks Cluster ID in a Databricks Notebook. The spark object, available by default, accesses Spark's configuration settings using .conf. The .get("spark.databricks.clusterUsageTags.clusterId") method fetches the Cluster ID in Databricks, which is then stored in the variable and printed to the output.
Step 5—Execute the Databricks Notebook Cell
Run the cell. If everything is set up correctly, you’ll see your Cluster ID in Databricks printed in the output. You should see something like: Databricks Cluster ID: <your-cluster-id>. And there you have it—another way to programmatically get your Databricks Cluster ID inside a Databricks Notebook!

Optional—Error Handling
Now, to enhance your code's robustness, add error handling by wrapping the retrieval code in a try-except block to manage unexpected scenarios.
try:
databricks_cluster_id = spark.conf.get("spark.databricks.clusterUsageTags.clusterId")
print(f"Databricks Cluster ID: {databricks_cluster_id}")
except Exception as e:
print("Failed to retrieve Cluster ID in Databricks from Spark configuration:", e)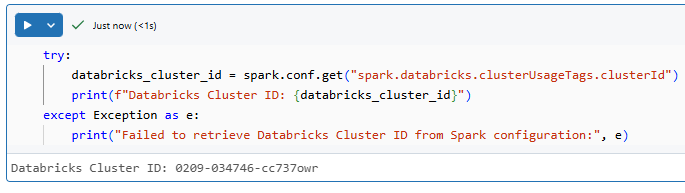
So, that's technique number two—accessing the Cluster ID in Databricks through Spark configuration. It's another handy method to have in your toolkit, especially when you're already knee-deep in Spark code within your Databricks Notebooks.
Now, let's explore techniques that work outside of Databricks Notebooks.
🔮 Technique 3—Programmatically Access Databricks Cluster ID Using Databricks REST API (External Access)
Sometimes you may need to retrieve the Cluster ID in Databricks from an external system or a script running outside of the Databricks Notebook environment. In such cases, the REST API offers a robust method.
Prerequisite:
- You must have an API token generated from your Databricks user settings.
- Basic knowledge of cURL, Hoppscotch, Postman, or write a Python request library.
Step 1—Login to Databricks and Generate an API Token
First things first, you need to get your API access token from Databricks.
In your Databricks workspace, click on your username (usually in the top-right corner of the screen). From the dropdown menu, select "Settings".
In the Settings sidebar (often on the left), find and click on "Developer".
Look for the "Access tokens" section on the Developer Settings page.
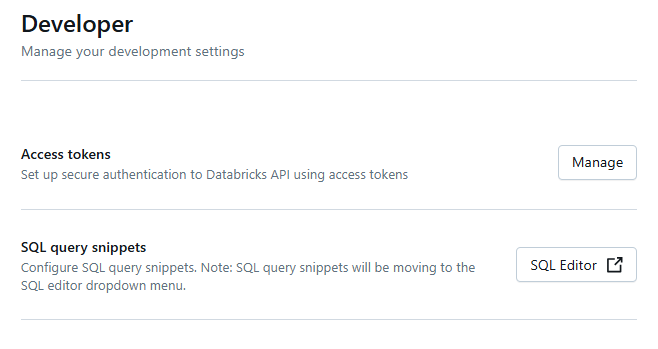
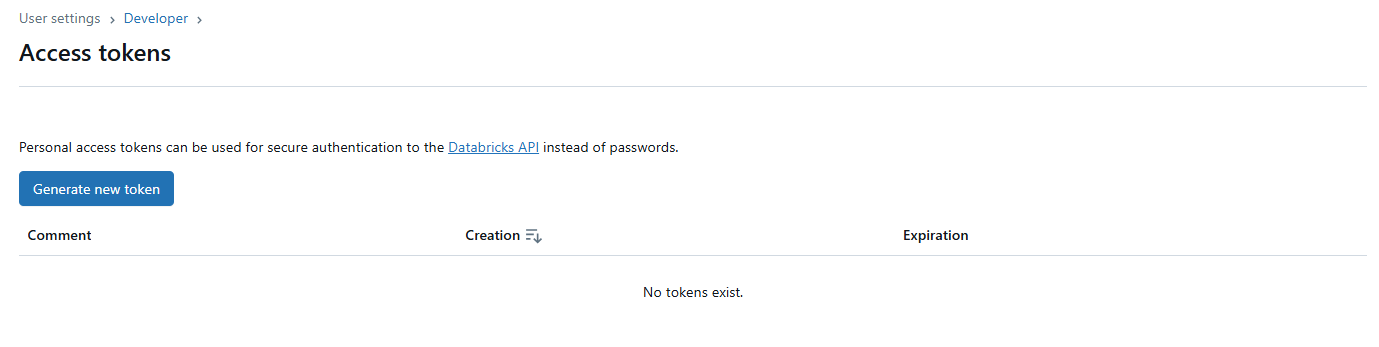
Click the button that says "Generate New Token". It is labeled something like "Generate New Token". A dialog will appear. Give your token a descriptive name—something that reminds you what it's for (e.g., "Databricks Cluster ID"). You can also set an optional expiration for the token.
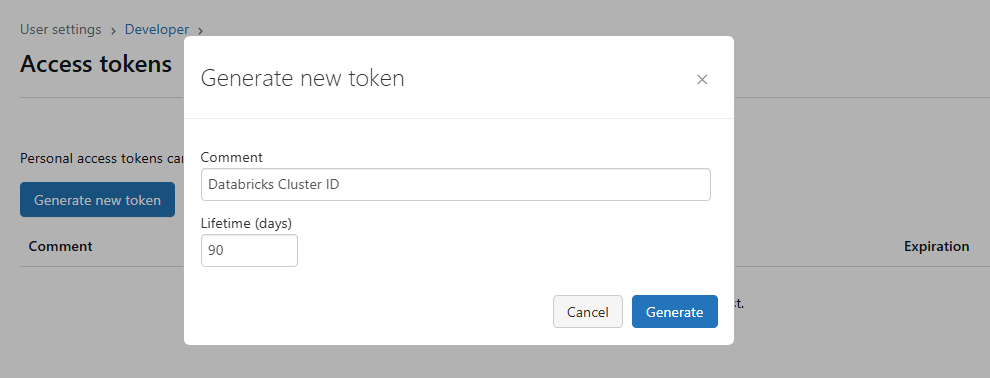
Click the "Generate" button. Databricks will display the generated token only once. Copy this token immediately and store it in a secure place.
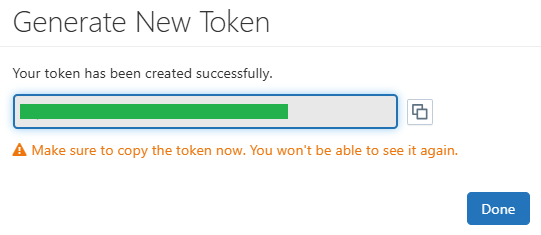
You won't be able to see the token again after you close the dialog. If you lose it, you'll have to generate a new one. Treat this token like a password—keep it secret!
Step 2—Configure Your REST Client
Now that you have your API token, you need to configure your chosen REST client to use it for authentication when talking to the Databricks API. How you do this depends on the client you picked. For quick tests, you can use cURL, Hoppscotch, Postman, or Python request library.
Step 3—List Clusters via REST API
1) Using cURL:
Open your terminal or command prompt and run a command like this, making sure to replace <api_token> with your actual API token you generated in Step 1 and <your-databricks-instance> with your Databricks workspace URL ( …..cloud.databricks.com or similar—just the hostname part, without https://)
curl -X GET \
-H "Authorization: Bearer <api_token>" \
https://<your-databricks-instance>/api/2.1/clusters/list2) Using Python requests
Here's how you'd make the same API request using a Python script:
import requests
DATABRICKS_TOKEN = "<YOUR_API_TOKEN>" # Replace with your API token
DATABRICKS_WORKSPACE_URL = "https://<YOUR_WORKSPACE_URL>" # Replace with your workspace URL
api_version = "2.1"
api_command = "/clusters/list"
url = f"{DATABRICKS_WORKSPACE_URL}/api/{api_version}{api_command}"
headers = {"Authorization": f"Bearer {DATABRICKS_TOKEN}"}
response = requests.get(url, headers=headers)
response.raise_for_status() # Raise HTTPError for bad responses (4xx or 5xx)
clusters_list = response.json()
print(clusters_list) # Print the raw JSON response to see what it looks like2) Using Hoppscotch
To list Databricks clusters using Hoppscotch, start by opening Hoppscotch in your browser. Select GET as the request method and enter the Databricks API endpoint:
https://<databricks-instance>/api/2.1/clusters/listReplace <databricks-instance> with your Databricks workspace URL. Next, navigate to the Authorization tab, set the Authorization Type to Bearer, and enter your Databricks Personal Access Token (PAT) in the input field. Once everything is set up, click Send to execute the request. If successful, you will receive a 200 OK status along with a JSON response containing a list of clusters in your Databricks workspace. The response will include cluster details. If you encounter issues, verify that your API endpoint and PAT are correct.

Step 4—Retrieve Specific Databricks Cluster ID Details
The API response returns a JSON object that includes details of all clusters. Look for the field cluster_id in the JSON. If you have multiple clusters, you might need to search through the list by matching on a cluster name or another attribute to find the one you want.
Step 5—Parse the JSON Response and Find Your Databricks Cluster ID
The /api/2.1/clusters/list API call returns a JSON response. You need to process this JSON to extract the cluster_id for the specific cluster you're interested in. Usually, you'll want to find a cluster based on its name.
If you used curl in Step 3, the output is raw JSON text in your terminal. You can use jq to parse this and extract the cluster_id. We already showed an example of this in the curl section of Step 3, where we used jq to find the cluster_id of a cluster with a specific name:
CLUSTER_NAME_TO_FIND="target-cluster"
CLUSTER_ID=$(curl -X GET -H "Authorization: Bearer <YOUR_API_TOKEN>" "https://<YOUR_WORKSPACE_URL>/api/2.0/clusters/list" | jq -r ".clusters[] | select(.cluster_name == \"${CLUSTER_NAME_TO_FIND}\") | .cluster_id")
echo "Cluster ID for '${CLUSTER_NAME_TO_FIND}': $CLUSTER_ID"If you use Python requests, the JSON response is already parsed into a Python dictionary (or list of dictionaries) in the clusters_list variable. You can now use a standard Python dictionary and list operations to navigate this data structure and find your Cluster ID in Databricks. We also showed an example of this in the Python code in Step 3:
cluster_name_to_find = "YourTargetClusterName" # Replace with the actual cluster name
target_cluster_id = None
for cluster in clusters_list.get("clusters", []): # Handle case where 'clusters' key might be missing
if cluster.get("cluster_name") == cluster_name_to_find:
target_cluster_id = cluster.get("cluster_id")
break # Exit loop once found
if target_cluster_id:
print(f"Cluster ID for '{cluster_name_to_find}': {target_cluster_id}")
else:
print(f"Cluster '{cluster_name_to_find}' not found.")Optional—Error Handling (API calls, JSON parsing)
Making calls to external APIs and parsing responses is always a place where things can go wrong. Network issues, incorrect API tokens, API rate limits, or unexpected response formats can all cause problems. It's crucial to implement error handling in your scripts or applications that use the Databricks REST API.
In cURL scripts
Check the exit code of the curl command. A non-zero exit code usually indicates an error.
In Python requests
The response.raise_for_status() line in the Python example is crucial. It will raise an HTTPError exception if the API response status code indicates an error (4xx or 5xx). You can wrap your code in try-except blocks to catch these exceptions and handle them carefully.
import requests
# ... (API token and URL setup as before) ...
try:
response = requests.get(url, headers=headers)
response.raise_for_status() # Raise exception for HTTP errors
clusters_list = response.json()
# ... (JSON parsing and Cluster ID extraction from Step 4) ...
except requests.exceptions.RequestException as e: # Catch network errors, timeouts, etc.
print(f"API Request Error: {e}")
except ValueError as e: # Catch JSON parsing errors
print(f"JSON Parsing Error: {e}")
except Exception as e: # Catch any other unexpected errors
print(f"An unexpected error occurred: {e}")And that wraps up Technique 3—using the Databricks REST API. It's a powerful approach for external access, giving you control from anywhere you can make HTTP requests. Next up, we'll look at using the Databricks CLI, another command-line option for external interaction.
🔮 Technique 4—Programmatically Access Databricks Cluster ID Using Databricks CLI (Command Line Interface)
This technique lets you retrieve your Cluster ID in Databricks from the command line using the Databricks CLI. Databricks CLI is a versatile tool that puts Databricks control right at your fingertips in your terminal. For automating tasks, system administration, and DevOps workflows, the CLI is a fantastic option. And guess what? It's also great for programmatically fetching Databricks Cluster IDs.
Prerequisite:
- You need to download and install the Databricks CLI on your local machine from where you'll be running the commands. The installation process varies slightly depending on your operating system:
- Once installed, the Databricks CLI needs to be configured to connect to your Databricks workspace.
Step 1—Install and Configure Databricks CLI
Let's walk through how to install and configure the Databricks CLI. For this article, we will be installing it on the Windows operating system.
Here’s how to get the Databricks CLI running on Windows. You can use package managers like WinGet or Chocolatey, use Windows Subsystem for Linux (WSL), or download the executable from the source.
Using PowerShell as Administrator:
Open Windows PowerShell by searching for it, right-click, and select “Run as Administrator”. Check for Package Managers. To do so, run:
winget --versionOr
choco --version to see if WinGet or Chocolatey is available on your system.
Refer to this article to learn how to install these tools:
Installing Databricks CLI using:
1) WinGet:
Open a command prompt and run:
winget search databricksThen, install with:
winget install Databricks.DatabricksCLI2) Chocolatey:
Open a command prompt and run:
choco install databricks-cli3) WSL:
If you use WSL, follow this guide.
4) Manual Install from Source:
Check your Windows version by running in PowerShell:
$env:PROCESSOR_ARCHITECTUREor in CMD:
echo %PROCESSOR_ARCHITECTURE%Then download the appropriate zip file from the GitHub releases page, extract it, and run the CLI executable.
Verify Installation:
After installing, open a new terminal or PowerShell window and run:
databricks --versionThis command prints the CLI version, confirming that the installation worked.
For Mac or Linux, refer to this article:
After installing the CLI, you need to configure authentication so it can connect to your Databricks workspace.
Check out this article on how to configure Databricks CLI.
Step 2—List Clusters Using the Databricks CLI
With the Databricks CLI installed and configured, list your clusters by running:
databricks clusters listThis command returns a table with details like cluster names, IDs, and states. The output might look like this:

Cluster ID Cluster Name State
1234-567890-abcde <cluster_name> RUNNINGStep 3—Identify Your Cluster from the List
Review the output and look for your target cluster by its name or state. If you have multiple clusters, you can use standard command-line tools like grep (or Windows equivalents) to filter the results. For example, in PowerShell, you might run:
databricks clusters list | Select-String "<YourCluster>"This command helps you find the line with your cluster details, including the Cluster ID in Databricks.
Step 4—Retrieve Specific Cluster Details (and extract Databricks Cluster ID)
Once you identify your cluster, note the Cluster ID in Databricks from the output. If you need more details about a specific cluster, you can use another CLI command to fetch them. For instance:
databricks clusters get CLUSTER_ID 1234-567890-abcdeYou will see that this command returns a JSON response with all available details for the specified cluster. You can then parse this JSON output to confirm the Cluster ID along with other configuration details.
Step 5—Confirm/Validate Databricks CLI Output Detail
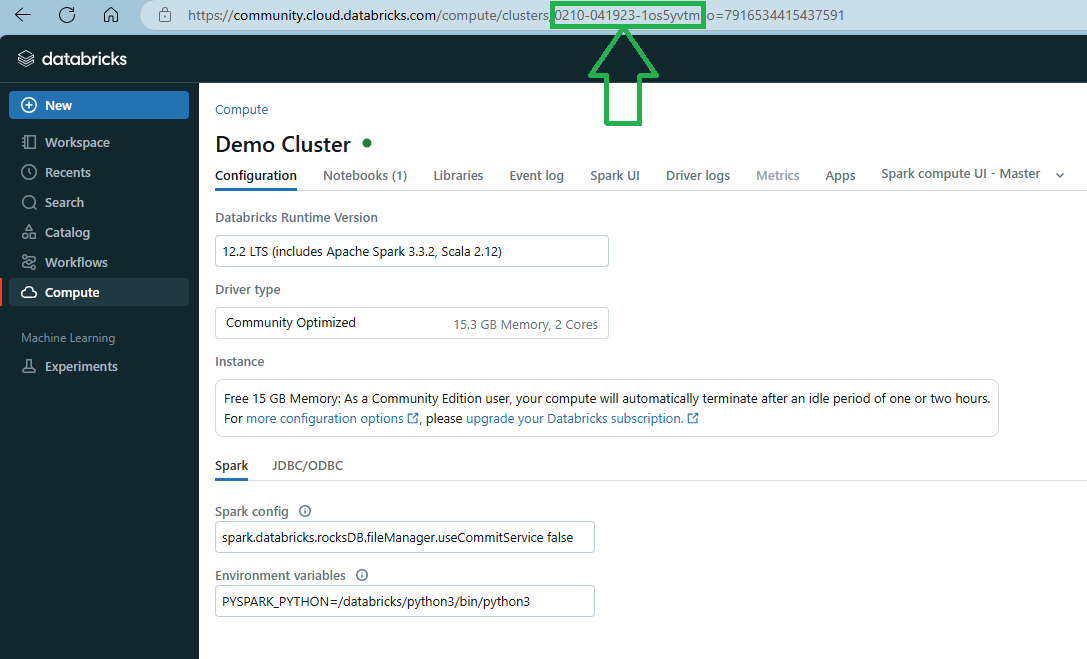
After running the CLI command, always double-check that the Cluster ID in Databricks you obtained is correct. The easiest way to validate it is to compare it to the Cluster ID shown in the Databricks UI for the same cluster. To do so, go to the 'Compute' section in Databricks, find your target cluster, click on its name to open the cluster details page, and check the URL of the same page. You will be able to see the ID there. Make sure the ID you got from the CLI matches the ID in the URL.
Want to take Chaos Genius for a spin?
It takes less than 5 minutes.

Conclusion
And that's a wrap! You can now programmatically access your Cluster ID in Databricks. We've gone over some hands-on ways to get that Cluster ID in Databricks. With it, you can automate tasks, log data, and manage resources with a lot less hassle. Take what you've learned here and you'll be able to boost your cluster management in no time.
In this article, we have covered:
- What a Databricks Cluster ID is and its role in distinguishing your clusters
- Step-by-Step Guide to Programmatically Access Databricks Cluster ID
- Technique 1—Programmatically Access Databricks Cluster ID Using Databricks Utilities (Databricks dbutils)
- Technique 2—Accessing Apache Spark Configuration within a Databricks Notebook
- Technique 3—Programmatically Access Databricks Cluster ID Using Databricks REST API
- Technique 4—Using Databricks CLI (Command Line Interface)
These techniques will help streamline your automation and integration tasks, so your cluster management stays on track.
FAQs
What is a Databricks cluster?
Databricks cluster is a collection of computing resources that runs Spark applications in your Databricks workspace. It consists of a driver node and one or more worker nodes, and it supports tasks like interactive data analysis, scheduled jobs, and automated processing.
How do you find the Cluster ID in Databricks?
You can locate the Databricks Cluster ID in several ways. Manually, it appears in the URL when you select a cluster in the Databricks UI (the string following /clusters/). Programmatically, you can retrieve it using methods such as Databricks Utilities (Databricks dbutils), Spark configuration (via spark.conf.get("spark.databricks.clusterUsageTags.clusterId")), the REST API, or the Databricks CLI.
How do I know my Cluster ID?
The Cluster ID is the same as the Databricks Cluster ID mentioned above. You identify it by checking the URL in the cluster settings or by running one of the programmatic methods described in this article. It’s a unique string, like 1234-567890-abcde, automatically assigned to your cluster when it’s created.
How do you get the Databricks instance ID?
Databricks instance ID is embedded in your Databricks workspace URL. For example, in a URL like https://dbc-60f1b2b9-1f77.cloud.databricks.com, the instance ID is the numeric part immediately following dbc-. You can also extract it programmatically via Spark configuration or by parsing the Databricks workspace URL.
How do I find my Databricks account ID?
Your Databricks account ID is a unique identifier for your account or Databricks workspace. In Azure Databricks, you can find it in the Azure portal under your Databricks resource’s properties or by checking the URL parameters (often after o= in legacy regional URLs). In other deployments, it might be provided via API responses or documentation specific to your provider.
Is the Cluster ID the same as the Cluster Name?
No, they are different. The Cluster Name is a label that you assign for easy identification, while the Cluster ID is an automatically generated, unique identifier used by the system to reference your cluster in code, API calls, and logs.
How long does a Cluster ID remain valid?
A Cluster ID remains valid for the lifetime of the cluster. Once a cluster is terminated, its ID is no longer in use. If you recreate a cluster, it will receive a new Cluster ID.
Can I change a Cluster ID?
No, you cannot change a Cluster ID in Databricks. It is automatically generated when the cluster is created and remains constant throughout the cluster’s active period. To have a different ID, you must create a new cluster.
When should I use the REST API to get the Cluster ID?
Use the REST API when you need to access cluster details from outside the Databricks Notebook environment or integrate with external systems. It is ideal for automation pipelines and monitoring tasks that run in your own scripts or third-party systems.
What are common use cases for programmatically accessing the Databricks Cluster ID?
Accessing the Cluster ID in Databricks programmatically lets you tag logs with the correct cluster reference, automate scaling and termination of clusters, integrate cluster information into CI/CD pipelines, and track resource usage accurately.
What potential pitfalls should I watch out for when retrieving the Cluster ID?
Some pitfalls include missing configuration keys in Spark or changes in internal APIs between Databricks runtime versions. You should add error handling in your scripts and test your code in both interactive and job-run environments to catch any discrepancies early.















